







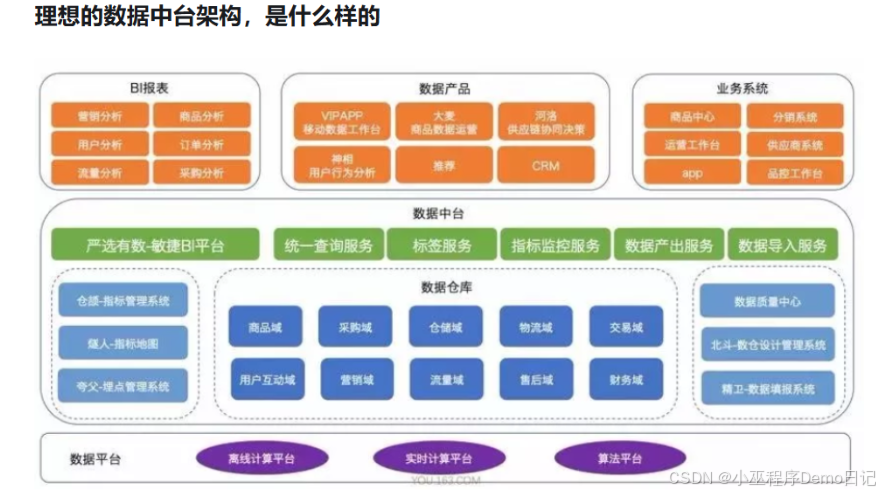
我们先来看下网易严选的数据体系(上图),就更清楚数据中台的定位了。
- 数据中台的下层是数据平台,数据平台主要解决跟业务无关的问题,主要是大数据的存储和计算问题。
- 数据中台的上层就是数据前台,主要包括 BI 报表、数据产品和业务系统。
- 数据中台首先赋能分析师通过 BI 报表的形式来驱动业务精细化运营。
数据中台的主要作用在于将企业内部所有数据统一处理形成标准化数据,挖掘出对企业最有价值的数据,构建企业数据资产库,对内对外提供一致的、高可用大数据服务。
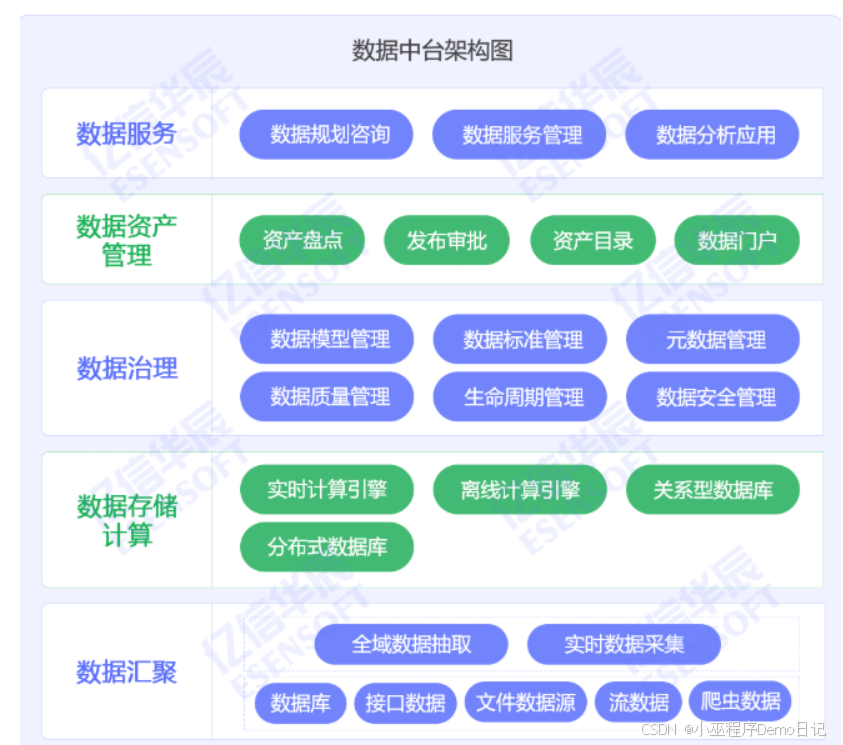
那么数据汇聚的原理是什么呢,我们从下往上逐个剖析
首先是数据汇聚:
因为数据源包括业务系统,数据库,网络环境,以及爬虫数据,这些数据存储在不同的地方,结构上存在差异,而且系统之间独立,很难直接使用,那么,我们数据汇聚的实现,理应是对这些数据进行一个抽取,采集,整合和处理,然后存储到统一的平台,在通过建模加工成有用的数据资源。
数据汇聚是数据中台建设的核心环节,本质上就是通过技术手段将分散,异构,多源的数据整合成统一的可用的资源池,
那么我们可以根据技术原理对这个数据汇聚实现一个技术分层:
- 异构数据源适配层:
- 采用Connector插件化架构(如Flink CDC)
- 采用关系型数据库MySQL,NoSQL(Redis),日志文件(Kafka),API接口(REST)
- 实现协议转换(JDBC/HTTP/ODBC)和编码转换(UTF-8/GBK)
- 数据采集传输层:
- 批处理引擎:Sqoop/DataX支持TB级数据迁移
- 流处理引擎:Flink/Kafka Streams实现毫秒级延迟
- 混合传输模式:Lambda架构结合批流特性
- 数据湖存储层:
- 分布式文件系统(HDFS/OSS)存储原始数据
- 列式存储(Parquet/ORC)提升压缩比
- 元数据管理(Hive Metastore/DataHub)实现数据目录
二、标准化实施流程
- 数据探查阶段
- 执行数据画像(Data Profiling)
- 分析字段空值率(Null Ratio)、基数(Cardinality)、值域分布
- 识别敏感数据(PII检测)和合规风险
- 数据清洗转换
- 结构化处理:JSON/XML解析(Jackson/XStream)
- 质量修复:正则表达式校验、字典映射
- 标准化处理:时间格式转换(UTC时区统一)、单位统一(货币汇率换算)
- 数据建模阶段
- 维度建模(Kimball模型)
- 构建一致性维度(Conformed Dimension)
- 建立事实表(Transaction/Grainularity定义)
- 数据资产地图(Data Asset Matrix)可视化
三、关键技术挑战与解决方案
- 数据一致性难题
-
分布式事务补偿(Saga Pattern)
-
增量同步(CDC)+ 全量校验(Checksum)
-
数据版本控制(Delta Lake/Hudi)
-
实时性要求
-
流批一体架构(Apache Iceberg)
-
状态管理(Flink State Backend)
-
端到端Exactly-Once语义保障
-
系统性能优化
-
列裁剪(Column Pruning)减少IO
-
谓词下推(Predicate Pushdown)
-
动态分区(Dynamic Partitioning)
那么接下来就是数据存储和计算了,对于数据的存储和计算, 我们都应该尽量避免元数据上的数据实现数据丢失,并且尽可能减轻存储压力,对存储的元数据实现列式存储,压缩存储空间,并且使用合适的流式处理,实现低延迟的事件处理,而不是直接基于SQL实现集中式的存储,这样对于海量数据而言处理的效率极低,并且扩展性差,由于垂直扩展的成本高了,企业的成本也上去了。那么我们就走进数据存储和计算的世界,看看这个技术的演进和发展,以及我们应该怎么用。
技术演进与核心原理剖析
一、技术演进背景
| 阶段 | 特点 | 局限性 |
|---|---|---|
| 传统关系型数仓 | - 基于SQL的集中式存储 - ACID事务保证 - 结构化数据处理 | - 扩展性差(垂直扩展成本高) - 海量数据(TB/PB级)处理效率低 |
| Hadoop分布式架构 | - 横向扩展(Scale-out) - HDFS分布式存储 + MapReduce批处理 | - 实时性差(分钟/小时级延迟) - 复杂SQL支持不足 |
| 实时流式计算架构 | - 流处理引擎(Flink/Storm) - 低延迟(毫秒/秒级) - 事件驱动处理 | - 事务一致性管理复杂 - 需要与批处理系统整合 |
二、关键技术原理与融合
1. MPP(大规模并行处理)
- 原理:将查询任务拆分到多个节点并行执行,通过高速网络交换中间结果
- 典型系统:Greenplum、Vertica
- 优势
- 高性能复杂查询
- 支持PB级数据分析
- 应用场景:企业级OLAP分析
2. SQL on Hadoop
-
原理:在Hadoop生态上实现SQL接口,将SQL查询转换为分布式计算任务
-
典型技术:Hive、Impala、Presto
-
优势
- 兼容传统SQL技能
- 利用HDFS存储扩展性
-
示例
-- HiveQL 查询示例 SELECT user_id, COUNT(*) FROM logs WHERE date = '2023-10-01' GROUP BY user_id;
3. 流处理引擎
- 原理:采用流水线处理模型,实时处理无界数据流
- 核心组件
- 流处理框架:Apache Flink、Spark Streaming
- 状态管理:Checkpoint/Savepoint
- 时间窗口:Event Time vs Processing Time
- 应用案例:实时风控、IoT设备监控
4. Lambda/Kappa架构融合
| 架构 | 特点 | 技术组合 |
|---|---|---|
| Lambda | 批流分离:批处理层(Hadoop) + 速度层(Storm/Flink) | HDFS + HBase + Kafka + Flink |
| Kappa | 全流式处理:统一使用流处理引擎处理历史和实时数据 | Kafka(长期存储) + Flink(统一计算) |
三、技术整合架构示例
+-------------------+ +-------------------+ +-------------------+
| 数据源 | | 实时流处理 | | 批处理 |
| (IoT/DB/日志) +----->+ Flink/Spark +----->+ Hadoop/MPP |
+-------------------+ | - 复杂事件处理 | | - Hive/Presto |
| - 状态管理 | | - 离线分析 |
+-------------------+ +--------+----------+
|
v
+-------------------+
| 统一数据服务层 |
| - 混合查询引擎 |
| - 数据湖(Delta Lake)|
+-------------------+
四、企业级应用价值
| 场景 | 技术实现 | 业务价值 |
|---|---|---|
| 实时决策 | Flink CEP(复杂事件处理) + Kafka | 欺诈检测响应时间 <100ms |
| 混合负载 | Presto联邦查询(Hive + MySQL + Kafka) | 跨系统数据关联分析效率提升70% |
| 数据湖治理 | Delta Lake(ACID事务) + Spark | 数据版本管理,修复效率提升60% |
| 资源优化 | YARN/K8s统一调度(批处理 + 流处理) | 集群资源利用率从40%提升至85% |
五、性能优化关键指标
-
存储优化:
- 列式存储(Parquet/ORC)
- 数据分区(时间/地域)
- 压缩算法(Zstandard/LZ4)
-
计算优化:
- 向量化执行(Apache Arrow)
- 动态代码生成(Spark Catalyst)
- 资源动态分配(Flink Slot共享)
-
查询优化:
-- 分桶优化示例(Hive) CREATE TABLE user_actions PARTITIONED BY (dt STRING) CLUSTERED BY (user_id) INTO 50 BUCKETS;
通过融合批处理、流处理、MPP等技术,企业可构建弹性可扩展的数据架构,实现从 T+1 到实时的决策能力跃升,同时通过统一存储计算层降低运维复杂度。
数据治理体系深度解析
一、数据治理核心模块
| 模块 | 功能定位 | 关键技术/工具示例 |
|---|---|---|
| 数据模型管理 | 结构化数据资产,建立业务与技术的桥梁 | ERWin、PowerDesigner、维度建模(Kimball) |
| 元数据管理 | 记录数据血缘、定义、关系,实现数据可追溯 | Apache Atlas、Alation、数据目录(Data Catalog) |
| 数据标准管理 | 统一数据定义、格式、规则,消除歧义 | 数据字典、ISO 8000 标准体系 |
| 数据质量管理 | 监控和提升数据准确性、完整性、一致性 | Great Expectations、Talend DQ、自定义规则引擎 |
| 生命周期管理 | 管理数据从产生到归档/销毁的全过程 | Hadoop 分层存储(热/温/冷)、自动归档策略 |
| 数据安全管理 | 保障数据隐私、合规性、访问控制 | RBAC、数据脱敏(如 Protegrity)、加密(AES) |
二、数据模型管理详解
1. 分层架构
+------------------------+ +------------------------+ +------------------------+
| 操作层 (ODS) | | 整合层 (DWD/DWS) | | 应用层 (ADS) |
| - 原始数据镜像 | ----> | - 数据清洗、标准化 | ----> | - 面向主题的汇总数据 |
| - 近实时/批量同步 | | - 业务过程建模 | | - 报表、API 接口 |
+------------------------+ +------------------------+ +------------------------+
2. 建模方法
-
范式建模(3NF):
- 适用于事务型系统(OLTP)
- 减少数据冗余,保证一致性
-
维度建模(星型/雪花模型):
-
适用于分析型系统(OLAP)
-
提升查询性能
-
示例:
-- 事实表 CREATE TABLE fact_sales ( product_id INT, date_id INT, store_id INT, amount DECIMAL(10,2), FOREIGN KEY (product_id) REFERENCES dim_product(id), FOREIGN KEY (date_id) REFERENCES dim_date(id) ); -- 维度表 CREATE TABLE dim_product ( id INT PRIMARY KEY, name VARCHAR(100), category VARCHAR(50) );
-
三、元数据管理核心要素
| 元数据类型 | 描述 | 管理工具功能 |
|---|---|---|
| 技术元数据 | 数据结构、存储位置、ETL作业信息 | 自动采集Hive表结构、Flink作业血缘 |
| 业务元数据 | 数据定义、业务术语、指标计算公式 | 业务术语与技术字段映射 |
| 操作元数据 | 数据访问日志、变更历史 | 审计日志、版本控制 |
血缘分析示例:
用户表 (MySQL) --> Kafka --> Flink清洗 --> Hive DWD层 --> Spark聚合 --> Hive ADS层 --> 报表系统
四、数据质量标准体系
| 质量维度 | 检测规则示例 | 工具实现 |
|---|---|---|
| 完整性 | 关键字段非空率 >99.9% | SELECT COUNT(*) WHERE user_id IS NULL |
| 一致性 | 不同系统间相同用户ID的姓名匹配率 >99% | 跨库JOIN比对 |
| 准确性 | 订单金额波动范围在历史均值 ±3σ内 | 统计学离群值检测 |
| 及时性 | 数据延迟 <5分钟 | 监控采集端时间戳 |
五、生命周期管理策略
| 数据阶段 | 存储策略 | 访问频率 | 技术方案 |
|---|---|---|---|
| 热数据 | SSD存储,保留3个月 | 高 | Alluxio缓存 + HDFS |
| 温数据 | HDD存储,保留1年 | 中 | HDFS归档目录 |
| 冷数据 | 对象存储(如S3),保留5年 | 低 | Hadoop分层存储(HSM) |
六、数据安全控制矩阵
| 控制层级 | 措施 | 实现技术 |
|---|---|---|
| 认证 | 多因素认证(MFA) | LDAP/AD集成,Kerberos |
| 授权 | 基于角色的访问控制(RBAC) | Apache Ranger、Sentry |
| 审计 | 记录所有数据访问操作 | ELK日志分析 + 审计数据库 |
| 脱敏 | 敏感字段(如手机号)动态脱敏 | 代理层改写查询(如 MySQL Proxy) |
| 加密 | 数据传输加密(TLS) + 静态数据加密(AES-256) | Hadoop Transparent Encryption |
七、实施路线图
- 现状评估:数据资产盘点,识别关键数据流
- 标准制定:统一数据定义,建立质量规则库
- 工具选型:选择元数据管理、数据质量平台
- 试点实施:在核心业务域(如用户、交易)落地治理
- 监控优化:建立数据质量仪表盘,持续改进
然后是数据资产管理体系。为了方便业务人员理解和使用数据,我们需要将这些资产转化为服务能力,供内部和外部使用,并且支持可视化的应用。首先数据资产管理包括对资产目录的创建,分类,元数据管理,权限控制等。那么数据服务则涉及API管理,服务编排,数据可视化工具等。
一、数据资产管理体系
核心目标
构建统一的数据资产目录,实现数据的可发现、可理解、可管控,提升数据利用率。
技术架构分层
关键技术组件
| 模块 | 技术方案/工具 | 功能说明 |
|---|---|---|
| 元数据管理 | Apache Atlas、LinkedIn DataHub | 自动采集Hive、MySQL等元数据 |
| 资产目录 | Collibra、Alation | 可视化目录,支持业务术语映射 |
| 数据分类 | 自定义分类引擎 + 机器学习模型 | 自动打标签(如"客户数据") |
| 权限控制 | Ranger、Sentry + Kerberos | 基于角色的细粒度权限管理 |
| 数据血缘 | Apache Atlas、Manta | 追踪数据从源到应用的完整链路 |
实施步骤
- 元数据自动采集:通过 Debezium 捕获数据库变更,或 Sqoop 批量导入。
- 构建业务术语表:与业务部门协作,定义"销售额"等术语的统一定义。
- 自动化分类打标:利用 NLP 技术解析字段名注释,自动归类到目录树。
- 目录可视化:集成 Elasticsearch 提供关键字搜索,支持模糊匹配。
二、数据服务体系
核心目标
将数据资产转化为可复用的 API 服务,支持快速消费和业务创新。
服务架构设计
关键技术组件
| 模块 | 技术方案/工具 | 功能说明 |
|---|---|---|
| API开发框架 | Spring Boot、FastAPI | 快速开发RESTful/gRPC接口 |
| API网关 | Kong、Apigee | 路由、限流、熔断 |
| 数据市场 | Snowflake Data Marketplace | 发布数据集,支持订阅下载 |
| 可视化工具 | Tableau、Superset | 自助分析,生成实时报表 |
| 服务监控 | Prometheus + Grafana | 监控接口QPS、延迟等指标 |
典型数据服务模式
-
即席查询服务
通过 Presto/Trino 提供 SQL 接口,允许业务人员直接查询原始数据。
-- 示例:查询北京地区销售额TOP10客户 SELECT customer_id, SUM(amount) FROM sales WHERE region='北京' GROUP BY customer_id ORDER BY SUM(amount) DESC LIMIT 10; -
指标API服务
将常用指标(如DAU)预计算后缓存,提供低延迟查询。
# 通过FastAPI暴露指标 @app.get("/metrics/dau") def get_dau(start_date: str, end_date: str): return {"dau": calculate_dau(start_date, end_date)} -
模型推理服务
封装机器学习模型为API,实时返回预测结果。
POST /models/churn_prediction { "user_id": 12345, "last_login_days": 30, "payment_count": 2 }
三、关键技术整合
安全与合规
- 动态脱敏:使用 Apache Ranger 在查询时实时隐藏手机号后四位。
- 审计追踪:通过 Apache Atlas 记录数据访问日志,满足 GDPR 合规要求。
- 数据水印:为敏感数据添加隐形标识,防止泄露后追溯源头。
性能优化
| 场景 | 优化手段 | 效果 |
|---|---|---|
| 高频查询 | 接入 Redis 缓存热点数据 | 降低 MySQL 负载,响应时间<10ms |
| 大规模分析 | 预计算 + Druid 列式存储 | 百亿级数据亚秒级响应 |
| 实时API | Flink 流处理 + 增量更新 | 指标延迟<1秒 |
成本控制
- 冷热分层:将历史数据自动迁移到 S3 Glacier 降低存储成本。
- 自动扩缩容:基于 Kubernetes HPA 动态调整计算资源。
- 用量计费:通过 Metering 模块统计各部门数据使用量。

















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









