






一、Python环境下载安装
pip install -q langchain二、OpenAl接口使用
2.1.下载安装
pip install -q openai2.2.导入openai
import os
import openai
openai_api_key="fsdfbsdifsdnfisdfnisdfn"
openai.api_key=openai_api_key
2.3.简单定义函数使用openai接口
def get_completion(prompt,model="gpt-3.5-turbo"):
message=[{"role":"user","content":prompt}]
reponse=openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0
)
return response.choices[0].message['content']
# temperature 表示内容丰富度,想象力,0更加严谨
# model 选择使用的模型
get_completion("1+1是什么?")三、langchain框架的使用
3.1.快速构建消息
from langchain.chat_models import ChatOpenAI #导入langchain使用的大语言模型
from langchain.schema import HumanMessage,SystemMessage,AIMessage
chat=ChatOpenAI(temperature=7,openai_api_key=openai_api_key)
chat(
[
SystemMessage(content="你是一个点餐机器人,可以帮助用户弄清楚吃什么")
HumanMessage(content="我喜欢吃西红柿,你喜欢吃什么?")
AIMessage(content="你应该去广州深圳")
HumanMessage(content="我去那里做什么")
]
)3.2.llm与chat_models
3.2.1.两者的区别
llm:是一个语言模型,它将字符串作为输入并且返回一个字符串
chat_models: 是一个语言模型,他将消息列表传入,并返回一个消息
3.2.2.chat_models的介绍
chat_models中的消息类型:
- AIMessage(content="你好") 人类对话语言
- SystemMessage(content="你是一个旅游攻略家,快速生成一个旅游攻略")系统对话语言
- HumanMessage(content="我想去南京") 机器人生成语言
chat_models通过传入一个包含他们的列表,返回一个消息体
chat_models基本函数使用:
- chat(message) 通过调用__call__()函数来生成消息
- predict("请你介绍一下山西") 传入的要求是字符串
- predict_message(message) 传入的要求是一个消息
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from zhipu_llm import Zhipuai_LLM
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
zhipuai_api_key = "3f871d79fdbe9af013fa1073c769c0bf.ShzmR3HzZjRmiQao"
# 通过chat_models来定义chat
chat = ChatZhipuAI(
temperature=0.5,
api_key=zhipuai_api_key,
model="chatglm_turbo",
)
messages = [
AIMessage(content="你好"),
SystemMessage(content="你是一个旅游攻略家,可以快速生成一个旅游攻略"),
HumanMessage(content="我想去南京"),
]
result1=chat(messages) #方式一
result=chat.predict("请介绍一下南京") #方式二
chat.predict_message(messages) #方式三
print(result) 3.2.3.llm的介绍
llm基本函数使用:
- llm("请你介绍一下山西") 传入的要求是字符串
- predict("请你介绍一下山西") 传入的要求是字符串
- predict_message(message) 传入的要求是一个消息列表
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
messages = [
AIMessage(content="你好"),
SystemMessage(content="你是一个旅游攻略家,可以快速生成一个旅游攻略"),
HumanMessage(content="我想去南京"),
]
llm=Zhipuai_LLM(model="chatglm_turbo",zhipuai_api_key=zhipu_llm.api_key)
result1=llm.predict("请介绍一下南京") #方式一
result2=llm.predict_messages(messages) #方式二
result3=llm("请你介绍一下山西") #方式三
print(result1)3.2.模版使用
- ChatPromptTemplate 聊天模版
- SystemMessagePromptTemplate 系统模版
- HumanMessagePromptTemplate 人类语言模版
使用提示词
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from zhipu_llm import Zhipuai_LLM
llm = Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipuai_api_key)
prompt = """ 今天是星期一,明天是星期三,有问题吗"""
llm(prompt)
提示模版
帮助根据用户输入,其他非静态信息和固定模版字符串的组合创建提示的对象
3.2.1.PromptTemplate的实操案例
模版使用方法:
(1)PromptTemplate.from_messages("你的角色是{role}")
(2)PromptTemplate(
input_variables=["location"], # 多个可用数组
template=template)
注意使用第二种方式的时候,他会对输入的变量进行验证,如果与模版中的变量一致,才会继续向下执行,否则就会报错
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain.prompts import PromptTemplate
import zhipu_llm
from zhipu_llm import Zhipuai_LLM
llm = Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipu_llm.api_key)
template="""我想去{location}旅行,我应该在哪里做什么?"""
prompt=PromptTemplate(
input_variables=["location"], # 多个可用数组
template=template,
)
final_prompt=prompt.format(location='广东深圳')
print(llm(final_prompt))3.2.2.ChatPromptTemplate、SystemMessagePromptTemplate、HumanMessagePromptTemplate的使用
HumanMessagePromptTemplate通过其他模版初始化
HumanMessagePromptTemplate.from_template(template)
SystemMessagePromptTemplate通过其他模版初始化
SystemMessagePromptTemplate.from_template(template)
ChatMessagePromptTemplate通过from_messages函数将传入的HumanMessagePromptTemplate和SystemMessagePromptTemplate作为一个数组进行传入来完成初始化
ChatMessagePromptTemplate.from_messages([system_message_prompt,human_message_prompt])
ChatMessagePromptTemplate通过传入二元组实例化
ChatMessagePromptTemplate.from_messages([
('system',' {name} '),('human',' '),('ai',' '),('human',' ')
])
ChatMessagePromptTemplate经过格式化之后其实就是一个消息列表

如果聊天模型支持使用任意角色接受聊天消息,则可以使用ChatMessagePromptTemplate,它允许用户指定任意角色名称。
from langchain.prompts import ChatMessagePromptTemplate
prompt="I love you {subject}"
chat_template=ChatMessagePromptTemplate.from_template(role="tom",template=prompt)
chat_prompt=chat_template.format(subject="aim")
print(chat_prompt) LangChain提供了MessagePlaceholder,他使你可以完全控制在格式化过程中呈现的消息,当你不确定应该为提示词模版使用什么角色的时候,或者希望你格式化过程中插入邮件列表时起到关键作用。
LangChain提供了MessagePlaceholder,他使你可以完全控制在格式化过程中呈现的消息,当你不确定应该为提示词模版使用什么角色的时候,或者希望你格式化过程中插入邮件列表时起到关键作用。
from langchain.prompts import MessagesPlaceholder,HumanMessagePromptTemplate,AIMessagePromptTemplate,ChatPromptTemplate,ChatMessagePromptTemplate,SystemMessagePromptTemplate
prompt="I love you {subject}"
human_template="11111111-----human {name}"
human_message_template=HumanMessagePromptTemplate.from_template(human_template)
# 这里相当于是嵌套的作用
chat_template=ChatPromptTemplate.from_messages([MessagesPlaceholder(variable_name="conversation"),human_message_template])
from langchain.schema import HumanMessage,AIMessage
human_message=HumanMessage(content="2222222222-----human")
ai_message=AIMessage(content="33333333-------ai")
chat_prompt=chat_template.format(conversation=[human_message,ai_message],name="liuhuan")
print(chat_prompt)
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from zhipu_llm import Zhipuai_LLM
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
zhipuai_api_key = "3f871d79fdbe9af013fa1073c769c0bf.ShzmR3HzZjRmiQao"
chat = ChatZhipuAI(
temperature=0.5,
api_key=zhipuai_api_key,
model="chatglm_turbo",
)
template="你是一个有用的助手,可以将{input_language}转化为{output_language}"
system_message_prompt=SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt=HumanMessagePromptTemplate.from_template(human_template)
chat_prompt=ChatPromptTemplate.from_messages([system_message_prompt,human_message_prompt])
chat_prompt=chat_prompt.format_messages(input_language="英文",output_language="中文",text="I love you")
llm = Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipuai_api_key)
result=llm.predict_messages(chat_prompt)
print(result)3.3.3.自定义提示词模版
from enum import Enum
from typing import Any
#导入一个获取源码的库
import inspect
def get_source_code(function_name):
return inspect.getsource(function_name)
def test_add():
return 1+1
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel,validator
PROMPT="""
Give the function name and source code,generate the English explanation of the function
Function Name:{function_name}
Source Code:
{source_code}
Explanation:
"""
class FunctionExplanationPromptTemplate(StringPromptTemplate,BaseModel):
@validator("input_variables")
def validate_input_variables(cls,v):
if len(v)!=1 or "function_name" not in v:
raise ValueError("function_name must be one of the following")
return v
def format(self, **kwargs: Any) -> str:
source_code = get_source_code(kwargs["function_name"])
prompt=PROMPT.format(function_name=kwargs["function_name"].__name__, source_code=source_code)
return prompt
def _prompt(self) -> str:
return "function-explanation"
function_explain=FunctionExplanationPromptTemplate(input_variables=["function_name"])
prompt=function_explain.format(function_name=test_add)
print(prompt)3.3.4.带例子的提示词模版
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""
},
{
"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""
},
{
"question": "Who was the maternal grandfather of George Washington?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""
},
{
"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""
}
]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question1: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
 3.3.5.事例选择器
3.3.5.事例选择器
# 导入相似度案例选择器
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
# 导入向量
from langchain.vectorstores import Chroma
# 使用OpenAI的相似度计算算法
from langchain.embeddings import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 这是可供选择的示例列表。
examples,
# 这是用于生成嵌入的嵌入类,用于衡量语义相似度。
OpenAIEmbeddings(),
# 这是用于存储嵌入并进行相似度搜索的向量存储类。
Chroma,
# 这是要生成的示例数量。
k=1
)
# 选择与输入最相似的示例。
question = "Who was the father of Mary Ball Washington?"
selected_examples = example_selector.select_examples({"question": question})
print(f"Examples most similar to the input: {question}")
for example in selected_examples:
print("\n")
for k, v in example.items():
print(f"{k}: {v}")
我们还可以将示例选择器应用于FewShotPromptTemplate。创建一个FewShotPromptTemplate对象。该对象接收示例选择器和用于Few-Shot示例的格式化程序:
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt.format(input="Who was the father of Mary Ball Washington?"))

3.3.6.带例子的连天提示词
from langchain.prompts import PromptTemplate,ChatPromptTemplate
import zhipu_llm
from zhipu_llm import Zhipuai_LLM
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.few_shot import FewShotChatMessagePromptTemplate
examples = [
{"input": "1+1", "output": "2"},
{"input": "2+2", "output": "4"},
]
example_template = ChatPromptTemplate.from_messages(
[
("human","{input}"),
("ai","{output}"),
]
)
fewshot_prompt=FewShotChatMessagePromptTemplate(examples=examples,example_prompt=example_template)
print(fewshot_prompt.format())
3.3.7.部分提示模版
from langchain.prompts import MessagesPlaceholder,HumanMessagePromptTemplate,AIMessagePromptTemplate,ChatPromptTemplate,ChatMessagePromptTemplate,SystemMessagePromptTemplate
from langchain.schema import HumanMessage,AIMessage
from langchain.prompts import PromptTemplate
template="{foo} {bar}"
template1="{foo1} {bar1}"
prompt_template1=PromptTemplate.from_template(template)
# 给部分变量赋值
newPrompt_template=prompt_template1.partial(foo="liuhuan")
prompt=newPrompt_template.format(bar="111111")
print(prompt)
# 初始化prompt_template,来直接指定
prompt_template1 = PromptTemplate(template=template1,input_variables=["bar1"],partial_variables={"foo1":"foo1"})
prompt1 = prompt_template1.format(bar1="bar1")
print(prompt1)部分带函数
from langchain.prompts import MessagesPlaceholder,HumanMessagePromptTemplate,AIMessagePromptTemplate,ChatPromptTemplate,ChatMessagePromptTemplate,SystemMessagePromptTemplate
from langchain.schema import HumanMessage,AIMessage
from langchain.prompts import PromptTemplate
from datetime import datetime
def fun():
date=datetime.now()
return date.strftime("%d/%m/%Y : %H:%M:%S")
def fun1():
date=datetime.now()
return date.strftime("%d/%m/%Y : %H:%M:%S")
template="{name} 正处于的时间是 {fun}"
template1="{name1} 正处于的时间是 {fun1}"
prompt_template1=PromptTemplate.from_template(template)
# 给部分变量赋值
newPrompt_template=prompt_template1.partial(fun=fun)
prompt=newPrompt_template.format(name="liuhuan")
print(prompt)
# 初始化prompt_template,来直接指定
prompt_template1 = PromptTemplate(template=template1,input_variables=["name1"],partial_variables={"fun1":fun1})
prompt1 = prompt_template1.format(name1="liuhuan1")
print(prompt1)模版组合
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplate
full_template="""
{aa}
{bb}
{cc}
"""
full_prompt = PromptTemplate.from_template(full_template)
aa_prompt = PromptTemplate.from_template("you are a person {name}")
bb_prompt = PromptTemplate.from_template("this is a book {book_name1} {book_name2} {book_name3}")
cc_prompt = PromptTemplate.from_template("it is a dog {dog_name}")
input_prompt = [
("aa",aa_prompt),("bb",bb_prompt),("cc",cc_prompt)
]
pipe_prompt = PipelinePromptTemplate(final_prompt=full_prompt,pipeline_prompts=input_prompt)
print(pipe_prompt.input_variables)
print(pipe_prompt.format(name="liuhuan",book_name1="book_name1",book_name2="book_name2",book_name3="book_name3",dog_name="dog_name"))
3.3.输出解释器
LangChain框架提供了基础的解析器类BaseOutputParser,其他的解析器都是继承自该类,
3.3.1.实现的两个主要方法
- get_format_instructions: 返回包含指令的字符串,关于语言模型如何格式化的输出
- parse: 输入一个字符串(如语言模型的响应消息)解析成其他的结构
3.3.2.列表解析器(List parser)
将逗号分隔的文本解析为列表,使用CommaSeparatedListOutputParser类,按逗号处理
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import (
PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
)
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
# 实例化解析器output_parser
output_parser = CommaSeparatedListOutputParser()
# 生成format_instructions
format_instructions = output_parser.get_format_instructions()
# 查看format_instructions
print(format_instructions)
# 实例化prompt
prompt = PromptTemplate(
template="列出5个{subject}\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
# 生成模板_input
_input = prompt.format(subject="开发语言")
llm=Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipu_llm.api_key)
# 模型输出为文本
out_put = llm(_input)
print(out_put)
print('\n')
# 解析器输出为列表
out_put_parser = output_parser.parse(out_put)
print(out_put_parser)
3.3.3.Enum Parser
枚举输出解析器来自EnumOutputParser类
from langchain.output_parsers import CommaSeparatedListOutputParser,EnumOutputParser
from langchain.prompts import (
PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
)
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
class Genders(Enum):
MALE = "male"
FEMALE = "female"
output_parser = EnumOutputParser(enum=Genders)
format_instructions=output_parser.get_format_instructions()
print(format_instructions)
# 实例化prompt
prompt = PromptTemplate(
template="Tell me the gender of the celebrity {subject}\n{format_instructions}\n",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
# 生成模板_input
_input = prompt.format(subject="Michael Jordan")
llm=Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipu_llm.api_key)
# 模型输出为文本
out_put = llm(_input)
print(out_put)
print('\n')
result=output_parser.parse(out_put)
print(type(result), result)3.3.4.Structured Output Parser
当我们想要多个字段,如JSON数据结构,使用该解析器。
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
response_schemas = [
ResponseSchema(name="answer", description="answer the user's question"),
ResponseSchema(name="source", description="source referred the user's answer, should be the website")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
prompt = PromptTemplate(
template="the users questions as best as possible.\n{format_instructions}\n{question}",
input_variables=["question"],
partial_variables={"format_instructions": format_instructions}
)
_input = prompt.format(question="what are the ingredients of milk?")
llm=Zhipuai_LLM(model="chatglm_pro", zhipuai_api_key=zhipu_llm.api_key)
# 模型输出为文本
out_put = llm(_input)
print(out_put)
print('\n')
output_parser.parse(out_put)输出 Structured Output Parser结合响应结构之后产生的指令
3.3.4.解析器执行步骤
不同的解析器都会内置产生不同的指令,而这个指令是用来规范大模型的输出结果,当大模型输出结果之后,解析器就可以根据提前内置的解析器将按自己要求输出的文本内容进行解析,如果文本内容不符合自己的要求,一般也会抛出错误。
四、序列化存储
将提示信息存储为文件而不是Python代码通常更好。可以方便共享、存储和版本控制提示信息。
在高层次上,序列化遵循以下设计原则:
支持JSON和YAML。LangChain希望支持在磁盘上易于阅读的序列化方法,而YAML和JSON是其中两种最受欢迎的方法。需要注意的是,此规则适用于提示信息。对于其他内容(例如示例),可能支持不同的序列化方法。
LangChain提供了一个单一的入口点,用于从磁盘加载提示信息,轻松加载任何类型的提示信息。
# All prompts are loaded through the `load_prompt` function.
from langchain.prompts import load_prompt
4.1.PromptTemplate序列化存储
从YAML加载
下面是从YAML加载PromptTemplate的示例:
本地文件:simple_prompt.yaml
_type: prompt
input_variables:
["adjective", "content"]
template:
Tell me a {adjective} joke about {content}.
从JSON加载
下面是从JSON加载PromptTemplate的示例:
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template": "Tell me a {adjective} joke about {content}."
}
代码展示:
from langchain.prompts import load_prompt
# 通过yaml文件获取prompt
simple_prompt=load_prompt("store/simple_prompt.yaml")
prompt = simple_prompt.format(adjective="adjective",content="content")
# 通过json方式获取模版
simple_prompt1 = load_prompt("store/simple_prompt2.json")
prompt1 = simple_prompt1.format(adjective="adjective",content="content")
print(prompt)
print(prompt1)
从文件加载
将模板存储在单独文件中,在配置中引用文件的示例,键从template更改为template_path。
simple_prompt_with_template_file.json
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template_path": "store/simple_template.txt"
}
4.2.FewShotPromptTemplate
加载FewShotPromptTemplate的示例
通过json的方式存储事例
!cat examples.json
[
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"}
]
通过yaml的方式存储事例
!cat examples.yaml
- input: happy
output: sad
- input: tall
output: short
从YAML加载模版
!cat few_shot_prompt.yaml
_type: few_shot
input_variables:
["adjective"]
prefix:
Write antonyms for the following words.
example_prompt:
_type: prompt
input_variables:
["input", "output"]
template:
"Input: {input}\nOutput: {output}"
examples:
examples.json
suffix:
"Input: {adjective}\nOutput:"
从JSON加载
这是一个从JSON加载Few-Shot Example的示例。
!cat few_shot_prompt.json
{
"_type": "few_shot",
"input_variables": ["adjective"],
"prefix": "Write antonyms for the following words.",
"example_prompt": {
"_type": "prompt",
"input_variables": ["input", "output"],
"template": "Input: {input}\nOutput: {output}"
},
"examples": "examples.json",
"suffix": "Input: {adjective}\nOutput:"
}
配置中的示例
这是一个直接在配置中引用示例的示例
!cat few_shot_prompt_examples_in.json
{
"_type": "few_shot",
"input_variables": ["adjective"],
"prefix": "Write antonyms for the following words.",
"example_prompt": {
"_type": "prompt",
"input_variables": ["input", "output"],
"template": "Input: {input}\nOutput: {output}"
},
"examples": [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"}
],
"suffix": "Input: {adjective}\nOutput:"
}
从文件加载示例提示
这是一个从单独的文件加载用于格式化示例的PromptTemplate的示例。需要注意的是,键名从example_prompt更改为example_prompt_path。
!cat example_prompt.json
{
"_type": "prompt",
"input_variables": ["input", "output"],
"template": "Input: {input}\nOutput: {output}"
}
!cat few_shot_prompt_example_prompt.json
{
"_type": "few_shot",
"input_variables": ["adjective"],
"prefix": "Write antonyms for the following words.",
"example_prompt_path": "example_prompt.json",
"examples": "examples.json",
"suffix": "Input: {adjective}\nOutput:"
}
4.3.带有OutputParser的PromptTemplate
这是一个从文件加载PromptTemplate和OutputParser的示例。
! cat prompt_with_output_parser.json
{
"input_variables": [
"question",
"student_answer"
],
"output_parser": {
"regex": "(.*?)\\nScore: (.*)",
"output_keys": [
"answer",
"score"
],
"default_output_key": null,
"_type": "regex_parser"
},
"partial_variables": {},
"template": "Given the following question and student answer, provide a correct answer and score the student answer.\nQuestion: {question}\nStudent Answer: {student_answer}\nCorrect Answer:",
"template_format": "f-string",
"validate_template": true,
"_type": "prompt"
}
4.4.LLM的序列化存储
演示如何将LLM配置写入磁盘并从磁盘读取。如果我们想保存给定LLM的配置(比如:the provider、the temperature等),这个方法将非常有用。
LLM可以以两种格式保存在磁盘上:json或yaml。无论扩展名如何,它们都以相同的方式加载。
{
"model_name": "text-davinci-003",
"temperature": 0.7,
"max_tokens": 256,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"n": 1,
"best_of": 1,
"request_timeout": null,
"_type": "openai"
}
_type: openai
best_of: 1
frequency_penalty: 0.0
max_tokens: 256
model_name: text-davinci-003
n: 1
presence_penalty: 0.0
request_timeout: null
temperature: 0.7
top_p: 1.0
加载方式
from langchain.llms import OpenAI
from langchain.llms.loading import load_llm
llm = load_llm("llm.json")
五、提示词流水线
公开一个用户友好的界面,用于将提示的不同部分组合起来,每个模版都连接在一起,可以直接使用提示或者字符串(列表中的第一个元素必须是提示)
将提示词连接在一起
from langchain.prompts import PromptTemplate
prompt=(
PromptTemplate.from_template(" i am a boy {name}")
+ ",make it funny"
+ ",and in {language}"
)
print(prompt.format(name="liuhuan",language="english"))
将不同的角色的消息体进行连接
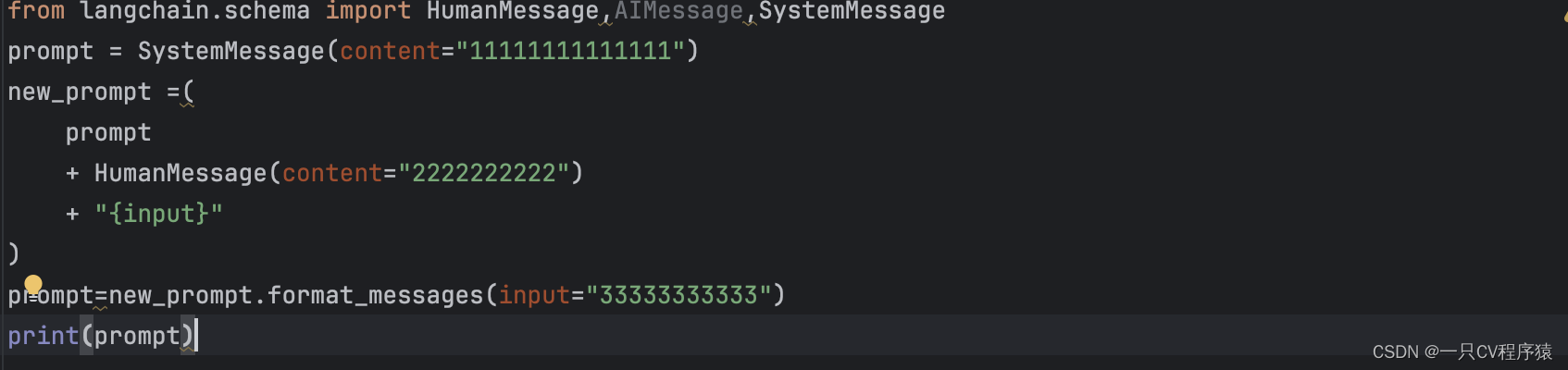
 验证模版
验证模版
指定了传入变量有两个,如果只传入一个,会直接报错,校验不通过
from langchain.schema import HumanMessage,AIMessage,SystemMessage
from langchain.prompts import PromptTemplate
template="{foo}{bar}"
prompt=PromptTemplate(template=template,input_variables=["foo","bar"])
prompt.format(foo="foo")指定了传入变量有两个,如果只传入一个,不会报错
from langchain.schema import HumanMessage,AIMessage,SystemMessage
from langchain.prompts import PromptTemplate
template="{foo}{bar}"
prompt=PromptTemplate(template=template,input_variables=["foo","bar"]
,validate_template=false)
prompt.format(foo="foo")LLMChain的使用
LLMChain可以看成一个胶水,用来连接大模型和提示词的进行执行操作
from langchain.prompts import PromptTemplate
prompt=(
PromptTemplate.from_template(" i am a boy {name}")
+ ",make it funny"
+ ",and in {language}"
)
print(prompt.format(name="liuhuan",language="english"))
from langchain.chains import LLMChain
from langchain_community.chat_models import ChatZhipuAI
zhipuai_api_key = "3f871d79fdbe9af013fa1073c769c0bf.ShzmR3HzZjRmiQao"
chat = ChatZhipuAI(
temperature=0.5,
api_key=zhipuai_api_key,
model="chatglm_turbo",
)
chain=LLMChain(llm=chat,prompt=prompt)
print(chain.run(name="liuhuan",language="english"))六、大型语言模型LLM
6.1.函数使用方式
(1)llm("讲一个笑话")
(2)generate进行批量调用,输出更加丰富,通过generations来看执行结果
(3)llm_result.llm_output 打印程序调用中的特定信息
from langchain.schema import HumanMessage,AIMessage,SystemMessage
from langchain.prompts import PromptTemplate
from zhipu_llm import Zhipuai_LLM
import zhipu_llm
llm=Zhipuai_LLM(model="chatglm_turbo",zhipuai_api_key=zhipu_llm.api_key)
print(llm("讲一个笑话")) # 通过调用__call__函数来执行
llm_result=llm.generate(["给我讲个笑话","给我讲个古诗词"]*2)
print(len(llm_result.generations))
print(llm_result.generations[0])六、异步接口
LangChain可以通过asynico库可以实现异步使用接口
通过异步支持可以同时异步使用多个llm大模型
import time
import asyncio
import zhipu_llm
from zhipu_llm import Zhipuai_LLM
llm=Zhipuai_LLM(model="chatglm_turbo",zhipuai_api_key=zhipu_llm.api_key)
# 通过串行化方式来进行调用
def generate_serially(llm):
for _ in range(10):
resp=llm.generate(["hello liuhuan"])
print(resp.generations)
async def generate_serially_async(llm):
resp = await llm.generate(["hello"])
print(resp.generations[0][0])
async def generate_concurrently(llm):
task = [ generate_serially(llm) for _ in range(10) ]
await asyncio.gather(*task)
七、大语言模型中的缓存
如果经常多次请求相同的任务,它可以通过减少您对LLM提供程序调用次数来节省资金,它可以通过减少对LLM提供程序进行的API调用次数来加速应用程序。
7.1.内存缓存
from zhipu_llm import Zhipuai_LLM
import langchain
import time
import zhipu_llm
llm=Zhipuai_LLM(model="chatglm_turbo",zhipuai_api_key=zhipu_llm.api_key)
from langchain.cache import InMemoryCache
langchain.llm_cache=InMemoryCache()
start_time = time.time()
print(llm.predict("tell me a joker"))
end_time = time.time()
start_time = time.time()
print(llm.predict("tell me a joker"))
end_time = time.time()
print(end_time-start_time)
SQLite数据库缓存
from zhipu_llm import Zhipuai_LLM
import langchain
import time
import zhipu_llm
llm=Zhipuai_LLM(model="chatglm_turbo",zhipuai_api_key=zhipu_llm.api_key)
from langchain.cache import SQLiteCache
langchain.llm_cache=SQLiteCache(database_path="store/zhipu_llm.db")
start_time = time.time()
print(llm.predict("tell me a joker"))
end_time = time.time()
start_time = time.time()
print(llm.predict("tell me a joker"))
end_time = time.time()
print(end_time-start_time)
八、大语言模型流式输出
某些LLM提供流式处理响应,这意味着我们可以在响应可用时立即开始处理,而不是等待整个响应结束才返回。
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
HumanMessage,
)
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = chat([HumanMessage(content="Write me a song about sparkling water.")])
九、langchain使用的令牌统计信息
跟踪tokens使用情况
下面介绍如何跟踪特定调用的tokens使用情况。目前,这个方法仅适用于OpenAI API。首先让我们看一个极其简单的示例,跟踪token在单个LLM调用中的使用情况:
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
with get_openai_callback() as cb:
result = llm("Tell me a joke")
print(cb)
输出信息
Tokens Used: 42
Prompt Tokens: 4
Completion Tokens: 38
Successful Requests: 1
Total Cost (USD): $0.00084
上下文管理器中的任何内容都将被跟踪。以下是使用它来跟踪多次连续调用的示例。
with get_openai_callback() as cb:
result = llm("Tell me a joke")
result2 = llm("Tell me a joke")
print(cb.total_tokens)
如果使用了具有多个步骤的链或代理,它将跟踪所有这些步骤:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
with get_openai_callback() as cb:
response = agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")
输出信息
> Entering new AgentExecutor chain...
I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: Sudeikis and Wilde's relationship ended in November 2020. Wilde was publicly served with court documents regarding child custody while she was presenting Don't Worry Darling at CinemaCon 2022. In January 2021, Wilde began dating singer Harry Styles after meeting during the filming of Don't Worry Darling.
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
Thought: I need to calculate 29 raised to the 0.23 power.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: I now know the final answer.
Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.
> Finished chain.
Total Tokens: 1506
Prompt Tokens: 1350
Completion Tokens: 156
Total Cost (USD): $0.03012
十、索引
10.1.文档加载器
Langchain的文档加载器是一项令人赞叹的技术,旨在将来自不同源的数据加载为文档对象。这些文档对象不仅包含文本内容,还携带着相关的元数据。无论是简单的文本文件、网页内容,甚至是YouTube视频的信息,Langchain的文档加载器都能轻松应对。
10.1.1.主要特点:
1.加载方法:通过配置的源加载数据为文档对象。
2.延迟加载选项:延迟将数据加载到内存中,以优化资源的使用。
3.加载和拆分:加载文档并使用指定的文本拆分器进行拆分。
10.1.2.支持加载的文件类型
加载器将把文件的内容和元数据封装到文档对象中,支持的数据格式
- CSV:从CSV文件加载数据。
- 文件目录:从文件目录加载数据。
- HTML:从HTML文件或网页加载数据。
- JSON:从JSON文件加载数据。
- 降价:从Markdown文件加载数据。
- PDF:从PDF文件加载数据。
加载指定的 txt 文件
from langchain_community.document_loaders import TextLoader
loader=TextLoader("store/a.txt")
print(loader.load())CSVLoader
使用CSVLoder加载csv类型的文件,加载出的每一行都作为一个文档对象
from langchain.document_loaders.csv_loader import CSVLoader
csv_loder=CSVLoader("store/bb.csv")
print(csv_loder.load())
file_path: 必需参数,表示要加载的 CSV 文件的路径。
csv_args: 可选参数,是一个字典,用于指定加载 CSV 文件时的一些参数。在这个例子中,我们指定了以下参数:
-
delimiter: 可选参数,表示字段之间的分隔符。在这个例子中,我们将其设置为逗号,。 -
quotechar: 可选参数,表示引用字符的字符。在这个例子中,我们将其设置为双引号"。 -
fieldnames: 可选参数,表示 CSV 文件中的列名。在这个例子中,我们将其设置为['title', 'result']。
对于quotechar解释,补充说明一下:
在CSV文件中,某些字段可能包含特殊字符(如逗号或换行符),为了区分这些特殊字符与字段的分隔符,可以使用引用字符(quote character)将字段进行引用。
在这个例子中,我们将quotechar参数设置为双引号",意味着在CSV文件中,如果一个字段包含特殊字符,该字段将用双引号括起来。例如,假设我们有以下两行数据:
title,result
"apple, orange",1 在这个例子中,字段title的值为"apple, orange",它被双引号括起来,表明逗号是字段的一部分而不是数据的分隔符。使用CSVLoader类时,设置quotechar参数为双引号可以帮助正确解析包含特殊字符的字段,并保留这些字段的完整性。
csv_loder2=CSVLoader(file_path="store/bb.csv",source_column="result")
print(csv_loder2.load())source_column 的作用是修改source属性,使用source_column参数指定从每一行创建的文档的来源。否则,file_path将用作从CSV文件创建的所有文档的来源。使用从CSV文件加载的文档回答使用来源的链时,这很有用。

DirectoryLoader
使用DirectoryLoader来加载目录中的所有文档。默认情况,用 UnstructuredLoader 进行操作。使用 glob 参数来控制加载哪些文件。请注意,这里不加载 .rst 文件或 .ipynb 文件。
加载指定目录下的文档
loader3=DirectoryLoader("store",glob="**/*.md")
print(len(loader3.load()))默认情况下,不会显示进度条。要显示进度条,请安装 tqdm 库(例如 pip install tqdm),并将 show_progress 参数设置为 True 。
使用进度条来查看加载情况
loader4=DirectoryLoader("store",glob="**/*.md",show_progress=True)
print(len(loader4.load()))更改加载器类
默认情况下,它使用 UnstructuredLoader 类。但是,你可以相当容易地改变加载器的类型。
from langchain.document_loaders import TextLoader
loader = DirectoryLoader('../', glob="**/*.md", loader_cls=TextLoader)
docs = loader.load()
len(docs)
如果您需要加载Python源代码文件,请使用 PythonLoader。
from langchain.document_loaders import PythonLoader
loader = DirectoryLoader('../../../../../', glob="**/*.py", loader_cls=PythonLoader)
docs = loader.load()
len(docs)
使用多线程来加载目录下的文档
loader5=DirectoryLoader("store",glob="**/*.md",use_multithreading=True)
print(len(loader5.load()))Python文档加载器
from langchain_community.document_loaders import PythonLoader
loader6=DirectoryLoader("/Users/tal/PycharmProjects/LangChainStudy",glob="*.py",loader_cls=PythonLoader)
print(loader6.load())UnstructuredHTMLLoader
HTML文档加载器1
from langchain_community.document_loaders import UnstructuredHTMLLoader
html_loader=UnstructuredHTMLLoader("a.html")
print(html_loader.load())BSHTMLoader
HTML文档加载器2
from langchain.document_loaders import BSHTMLLoader
bs_html_loader=BSHTMLLoader("a.html")
print(bs_html_loader.load())JSONLoader
JSON文件加载方式
import json
from pathlib import Path
from pprint import pprint
file="store/llm.json"
data=json.loads(Path(file).read_text())
pprint(data) #用json的方式来输出文件10.2.文本分割器
在高层次上,文本分割器的工作如下:
-
将文本拆分为小的、语义上有意义的块(通常是句子)。
-
开始将这些小块组合成一个较大的块,直到达到一定的大小(由某些函数测量)。
-
一旦达到该大小,将该块作为自己的文本块,然后开始创建一个新的文本块,其中包含一些重叠(以保持文本块之间的上下文)。
这意味着您可以沿两个不同的轴自定义文本分割器:
-
文本如何拆分
-
如何测量块大小
10.2.1. 默认文本分割器 RecursiveCharacterTextSplitter
该文本分割器需要一个字符列表。它尝试根据第一个字符分割创建块,但如果任何块太大,则移动到下一个字符,依此类推。默认情况下,它尝试分割的字符是[" ", "\n", " ", ""]
除了控制可以分割的字符之外,您还可以控制其他一些内容:
-
length_function: 如何计算块的长度。默认情况下只计算字符数,但通常在此处传递令牌计数器。 -
chunk_size: 块的最大大小(由长度函数测量)。 -
chunk_overlap: 不同文本块之间的最大重叠部分。保持文本块之间的一定连续性可能非常有用(例如,使用滑动窗口),因此一些重叠是很好的。
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])我们可以将元数据与文档一起传递的示例,注意它与文档一起拆分。
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas)
print(documents[0])
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. Last year COVID-19 kept us apart. This year we are finally together again. Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. With a duty to one another to the American people to the Constitution. And with an unwavering resolve that freedom will always triumph over tyranny. Six days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. He thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. He met the Ukrainian people. From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.' lookup_str='' metadata={'document': 1} lookup_index=0
10.2.2.PythonCodeTextSplitter
- 文本如何拆分:通过Python特定字符列表进行拆分
- 如何测量块大小:通过传递的长度函数测量(默认为字符数)
from langchain.text_splitter import PythonCodeTextSplitter
python_text = """
class Foo:
def bar():
def foo():
def testing_func():
def bar():
"""
python_splitter = PythonCodeTextSplitter(chunk_size=30, chunk_overlap=0)
docs = python_splitter.create_documents([python_text])
docs
[Document(page_content='Foo: def bar():', lookup_str='', metadata={}, lookup_index=0),
Document(page_content='foo(): def testing_func():', lookup_str='', metadata={}, lookup_index=0),
Document(page_content='bar():', lookup_str='', metadata={}, lookup_index=0)]
除此之外还支持javascript、java等多种语言的拆分器(用来保持拆分后代码的逻辑性)
10.3.向量存储
Chroma(opens in a new tab)是用于构建具有嵌入的人工智能应用程序的数据库。
!pip install chromadb
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
loader = TextLoader('../../../state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# 将文档进行向量存储,向量存储也支持查询的功能
db = Chroma.from_documents(docs, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
# 使用向量存储的查询功能
docs = db.similarity_search(query)
Using embedded DuckDB without persistence: data will be transient
print(docs[0].page_content)
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. 带有分数相似度的搜索
docs = db.similarity_search_with_score(query)
docs[0]
(Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'source': '../../../state_of_the_union.txt'}),
0.3949805498123169)初始化 PeristedChromaDB
为每个块创建嵌入并将其插入 Chroma 向量数据库。persist_directory 参数告诉 ChromaDB 在持久化时将数据库存储在何处。
persist_directory = 'db'
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=docs, embedding=embedding, persist_directory=persist_directory)
Running Chroma using direct local API.
No existing DB found in db, skipping load
No existing DB found in db, skipping load我们可以直接保存到本地
db.save_local("faiss_index"). #保存到本地
FAISS.load_local("faiss_index",OpenAIEmbeddings()). #FAISS向量存储从本地加载持久化数据库
调用 persist() 确保嵌入被写入磁盘。
vectordb.persist()
vectordb = None  从磁盘加载数据库并创建链,确保传递与实例化数据库时相同的persist_directory和embedding_function。初始化我们将用于问题回答的链。
从磁盘加载数据库并创建链,确保传递与实例化数据库时相同的persist_directory和embedding_function。初始化我们将用于问题回答的链。
# Now we can load the persisted database from disk, and use it as normal.
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
Running Chroma using direct local API.
loaded in 4 embeddings
loaded in 1 collections使用Chroma作为检索器的不同选项。
MMR#
除了在检索器对象中使用相似性搜索之外,您还可以使用mmr。
retriever = db.as_retriever(search_type="mmr")
retriever.get_relevant_documents(query)[0]
Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', metadata={'source': '../../../state_of_the_union.txt'})
10.4.文本嵌入模型
嵌入创建文本的向量表示会很有用,因为这意味着我们可以在向量空间中表示文本,并执行类似语义搜索这样的操作。LangChain中的基本Embedding类公开两种方法:
- embed_documents:适用于多个文档
- embed_query:适用于单个文档
文本嵌入相关的方法:
- OpenAIEmbeddings().embed_query(query) 将query串转化为向量
- 向量存储可使用方法 db.similarity_search_by_vector(embedding_vector)进行相似度的查找
将这两种方法作为两种不同的方法的另一个原因是一些嵌入提供商对于需要搜索的文档和查询(搜索查询本身)具有不同的嵌入方法,下面是文本嵌入的集成示例:
Aleph Alpha
使用Aleph Alpha的语义嵌入有两种可能的方法。如果我们有不同结构的文本(例如文档和查询),则我们使用非对称嵌入。相反,对于具有可比结构的文本,则建议使用对称嵌入的方法:
from langchain.embeddings import AlephAlphaAsymmetricSemanticEmbedding
document = "This is a content of the document"
query = "What is the content of the document?"
embeddings = AlephAlphaAsymmetricSemanticEmbedding()
doc_result = embeddings.embed_documents([document])
query_result = embeddings.embed_query(query)
Amazon Bedrock
Amazon Bedrock是一个完全托管的服务,通过API提供了来自领先AI初创公司和亚马逊的FMs,因此您可以从广泛的FMs中选择最适合您的用例的模型。
%pip install boto3
from langchain.embeddings import BedrockEmbeddings
embeddings = BedrockEmbeddings(credentials_profile_name="bedrock-admin")
embeddings.embed_query("This is a content of the document")
embeddings.embed_documents(["This is a content of the document"])
10.5.文本检索器
检索器(Retrievers)是一个通用的接口,方便地将文档与语言模型结合在一起。该接口公开了一个get_relevant_documents方法,接受一个查询(字符串)并返回一组相关文档。
10.5.1.VectorStore Retriever
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
docs = retriever.get_relevant_documents("what did he say about ketanji brown jackson")search_type="mmr" 表示检索器将使用 MMR(Maximal Marginal Relevance)算法来进行文档检索。MMR 算法是一种基于互信息的文档排序算法,它通过对每个文档的相关度和差异度进行加权,从而得出最终的排序结果。
retriever = db.as_retriever(search_type="mmr")
docs = retriever.get_relevant_documents("what did he say abotu ketanji brown jackson")search_kwargs={"k": 1} 是一个参数,传递给检索器的 search() 方法。这个参数指定了检索器在搜索相关文档时需要考虑的文档数量。在这个例子中,k=1 表示只返回最相关的一个文档作为答案。如果需要返回更多相关的文档,可以适当调整这个参数的值。
retriever = db.as_retriever(search_kwargs={"k": 1})
docs = retriever.get_relevant_documents("what did he say abotu ketanji brown jackson")
len(docs)
1十一、链chain
在本文中,我们将学习如何在LangChain中创建简单的链式连接并添加组件以及运行它。链式连接允许我们将多个组件组合在一起,创建一个统一的应用程序。例如,我们可以创建一个链式连接,接收用户输入,使用PromptTemplate对其进行格式化,然后将格式化后的响应传递给LLM。我们可以通过将多个链式连接组合在一起或将链式连接与其他组件组合来构建更复杂的链式连接。
11.1.LLMChain
查询 LLM 对象最流行的方式之一。它使用提供的输入键值(以及可用的内存键值)格式化提示模板,将格式化后的字符串传递给 LLM 并返回 LLM 输出。
from langchain import PromptTemplate, OpenAI, LLMChain
prompt_template = "What is a good name for a company that makes {product}?"
llm = OpenAI(temperature=0)
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
llm_chain("colorful socks")
如果有多个变量,我们可以使用字典一次输入它们。
prompt = PromptTemplate(
input_variables=["company", "product"],
template="What is a good name for {company} that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run({
'company': "ABC Startup",
'product': "colorful socks"
}))
在LLMChain中使用聊天模型:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))
调用链式连接的不同方式
所有继承自Chain的类都提供了几种运行链式连接逻辑的方式。其中最直接的一种方式是使用 __call__:
chat = ChatOpenAI(temperature=0)
prompt_template = "Tell me a {adjective} joke"
llm_chain = LLMChain(
llm=chat,
prompt=PromptTemplate.from_template(prompt_template)
)
llm_chain(inputs={"adjective":"corny"})
 默认情况,
默认情况,__call__ 方法会返回输入和输出的键值对,我们可以通过将return_only_outputs设置为True来配置它仅返回输出的键值对。
llm_chain("corny", return_only_outputs=True)
{'text': 'Why did the tomato turn red? Because it saw the salad dressing!'}
如果Chain只输出一个输出键(即其output_keys中只有一个元素),则可以使用run方法。需要注意的是,run方法输出一个字符串而不是字典。
llm_chain.run({"adjective":"corny"})
'Why did the tomato turn red? Because it saw the salad dressing!'
在只有一个输入键的情况下,我们可以直接输入字符串,无需指定输入映射。
# These two are equivalent
llm_chain.run({"adjective":"corny"})
llm_chain.run("corny")
# These two are also equivalent
llm_chain("corny")
llm_chain({"adjective":"corny"})
除了所有 Chain 对象共享的 __call__ 和 run 方法(请参见入门指南了解更多信息),LLMChain 还提供了几种调用链逻辑的方法:
input_list = [
{"product": "socks"},
{"product": "computer"},
{"product": "shoes"}
]
llm_chain.apply(input_list)

generate与apply类似,不同之处在于它返回一个LLMResult而不是字符串。LLMResult通常包含有用的生成信息,例如标记使用和完成原因。

predict与run方法类似,不同之处在于输入键是关键字参数而不是Python字典。
 输出解析
输出解析
默认情况下,即使底层prompt对象具有输出解析器,LLMChain也不会解析输出。如果您想在LLM输出上应用该输出解析器,请使用predict_and_parse代替predict和apply_and_parse代替apply。
使用predict:
from langchain.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
template = """List all the colors in a rainbow"""
prompt = PromptTemplate(template=template, input_variables=[], output_parser=output_parser)
llm_chain = LLMChain(prompt=prompt, llm=llm)
llm_chain.predict()
使用predict_and_parser
llm_chain.predict_and_parse()
直接从字符串模板构建LLMChain
template = """Tell me a {adjective} joke about {subject}."""
llm_chain = LLMChain.from_string(llm=llm, template=template)
llm_chain.predict(adjective="sad", subject="ducks")11.2.Sequential Chains
当您想要将一个调用的输出作为另一个调用的输入时,这是特别有用的。在本教程中,我们将演示使用顺序链来完成示例。顺序链被定义为一系列链,按确定的顺序调用。有两种类型的顺序链:
-
SimpleSequentialChain:最简单的顺序链形式,每个步骤都有一个单一的输入/输出,一个步骤的输出是下一个步骤的输入。 -
SequentialChain:更一般的顺序链形式,允许多个输入/输出。
11.2.1.SimpleSequentialChain
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# This is an LLMChain to write a synopsis given a title of a play.
llm = OpenAI(temperature=.7)
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
# This is an LLMChain to write a review of a play given a synopsis.
llm = OpenAI(temperature=.7)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
# This is the overall chain where we run these two chains in sequence.
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[synopsis_chain, review_chain], verbose=True)
review = overall_chain.run("Tragedy at sunset on the beach")
11.2.2.SequentialChain
当然,并不是所有的顺序链都像传递单个字符串参数并获取单个字符串输出那样简单。在下一个示例中,我们将尝试更复杂的链,涉及多个输入,以及多个最终输出。特别重要的是如何命名输入/输出变量名。在上面的例子中,我们不必考虑这个问题,因为我们只是将一个链的输出直接作为下一个链的输入传递,但在这里,我们必须考虑这个问题,因为我们有多个输入。
# This is an LLMChain to write a synopsis given a title of a play and the era it is set in.
llm = OpenAI(temperature=.7)
template = """You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.
Title: {title}
Era: {era}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title", 'era'], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="synopsis")
# This is an LLMChain to write a review of a play given a synopsis.
llm = OpenAI(temperature=.7)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review")
# This is the overall chain where we run these two chains in sequence.
from langchain.chains import SequentialChain
overall_chain = SequentialChain(
chains=[synopsis_chain, review_chain],
input_variables=["era", "title"],
# Here we return multiple variables
output_variables=["synopsis", "review"],
verbose=True)
overall_chain({"title":"Tragedy at sunset on the beach", "era": "Victorian England"})
{'title': 'Tragedy at sunset on the beach',
'era': 'Victorian England',
'synopsis': " The play follows the story of John, a young man from a wealthy Victorian family, who dreams of a better life for himself. He soon meets a beautiful young woman named Mary, who shares his dream. The two fall in love and decide to elope and start a new life together. On their journey, they make their way to a beach at sunset, where they plan to exchange their vows of love. Unbeknownst to them, their plans are overheard by John's father, who has been tracking them. He follows them to the beach and, in a fit of rage, confronts them. A physical altercation ensues, and in the struggle, John's father accidentally stabs Mary in the chest with his sword. The two are left in shock and disbelief as Mary dies in John's arms, her last words being a declaration of her love for him. The tragedy of the play comes to a head when John, broken and with no hope of a future, chooses to take his own life by jumping off the cliffs into the sea below. The play is a powerful story of love, hope, and loss set against the backdrop of 19th century England.",
'review': " The latest production from playwright X is a powerful and heartbreaking story of love and loss set against the backdrop of 19th century England. The play follows John, a young man from a wealthy Victorian family, and Mary, a beautiful young woman with whom he falls in love. The two decide to elope and start a new life together, and the audience is taken on a journey of hope and optimism for the future. Unfortunately, their dreams are cut short when John's father discovers them and in a fit of rage, fatally stabs Mary. The tragedy of the play is further compounded when John, broken and without hope, takes his own life. The storyline is not only realistic, but also emotionally compelling, drawing the audience in from start to finish. The acting was also commendable, with the actors delivering believable and nuanced performances. The playwright and director have successfully crafted a timeless tale of love and loss that will resonate with audiences for years to come. Highly recommended."}
有时您可能想传递一些上下文以在链的每个步骤或链的后面部分中使用,但维护和链接输入/输出变量可能会很快变得混乱。使用 SimpleMemory 是一种方便的方式来管理这个问题并清理您的链。举个例子,假设你使用之前介绍过的playwright SequentialChain,你想要在剧本中添加一些关于日期、时间和地点的上下文信息,并且使用生成的简介和评论来创建一些社交媒体发布文本。你可以将这些新的上下文变量添加为input_variables,或者我们可以添加一个SimpleMemory到链中来管理这个上下文:
from langchain.chains import SequentialChain
from langchain.memory import SimpleMemory
llm = OpenAI(temperature=.7)
template = """You are a social media manager for a theater company. Given the title of play, the era it is set in, the date,time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.
Here is some context about the time and location of the play:
Date and Time: {time}
Location: {location}
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:
{review}
Social Media Post:
"""
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text")
overall_chain = SequentialChain(
memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}),
chains=[synopsis_chain, review_chain, social_chain],
input_variables=["era", "title"],
# Here we return multiple variables
output_variables=["social_post_text"],
verbose=True)
overall_chain({"title":"Tragedy at sunset on the beach", "era": "Victorian England"})

11.2.3.链的序列化
将链保存到磁盘
将链保存到磁盘。这可以通过.save方法完成,并指定一个具有json或yaml扩展名的文件路径。
from langchain import PromptTemplate, OpenAI, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=OpenAI(temperature=0), verbose=True)
llm_chain.save("llm_chain.json")
从磁盘加载链
我们可以使用load_chain方法从磁盘加载链。
from langchain.chains import load_chain
chain = load_chain("llm_chain.json")
chain.run("whats 2 + 2")
Question: whats 2 + 2
Answer: Let's think step by step.
' 2 + 2 = 4'分别保存组件
我们可以看到提示和llm配置信息保存在与整个链相同的json中。或者,我们可以将它们拆分并分别保存。这通常有助于使保存的组件更加模块化。为了做到这一点,我们只需要指定llm_path而不是llm组件,以及prompt_path而不是prompt组件。
llm_chain.prompt.save("prompt.json")
!cat prompt.json
{
"input_variables": [
"question"
],
"output_parser": null,
"template": "Question: {question} Answer: Let's think step by step.",
"template_format": "f-string"
}
llm_chain.llm.save("llm.json")
!cat llm.json
{
"model_name": "text-davinci-003",
"temperature": 0.0,
"max_tokens": 256,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"n": 1,
"best_of": 1,
"request_timeout": null,
"logit_bias": {},
"_type": "openai"
}
config = {
"memory": None,
"verbose": True,
"prompt_path": "prompt.json",
"llm_path": "llm.json",
"output_key": "text",
"_type": "llm_chain"
}
import json
with open("llm_chain_separate.json", "w") as f:
json.dump(config, f, indent=2)
!cat llm_chain_separate.json
{
"memory": null,
"verbose": true,
"prompt_path": "prompt.json",
"llm_path": "llm.json",
"output_key": "text",
"_type": "llm_chain"
}
然后我们可以以相同的方式加载它。
chain = load_chain("llm_chain_separate.json")
chain.run("whats 2 + 2")
> Entering new LLMChain chain...
Prompt after formatting:
Question: whats 2 + 2
Answer: Let's think step by step.
> Finished chain.
' 2 + 2 = 4'
十二、代理人agent
12.1.工具tools
工具是代理可以用来与世界互动的功能。这些工具可以是通用工具(例如搜索),其他链,甚至是其他代理。
目前,可以使用以下代码片段加载工具:
from langchain.agents
import load_toolstool_names = [...]
tools = load_tools(tool_names) 一些工具(例如链、代理)可能需要基础LLM来初始化它们。在这种情况下,也可以传入LLM:
from langchain.agents import load_tools
tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm) 下面是所有支持的工具及相关信息的列表:
- Tool Name 工具名称:LLM用来引用该工具的名称。
- Notes 工具描述:传递给LLM的工具描述。
- Requires LLM 注意事项:不传递给LLM的工具相关注意事项。
- (Optional) Extra Parameters(可选)附加参数:初始化此工具需要哪些额外参数。
12.1.1.常用工具列表:
python_repl
- Tool Name工具名称:Python REPL
- Tool Description工具描述:Python shell。使用它来执行Python命令。输入应为有效的python命令。如果你期望输出,它应该被打印出来。
- Notes注:保持状态
- Requires LLM 需要LLM:没有
serpapi
- Tool工具名称:搜索
- Tool Description工具描述:搜索引擎。当您需要回答有关当前事件的问题时很有用。输入应为搜索查询。
- Notes注意:调用Serp API,然后解析结果。
- Requires LLM 需要LLM:没有
requests
- Tool Name工具名称:请求
- Tool Description工具描述:互联网的入口。当您需要从网站获取特定内容时,请使用此选项。输入应该是一个特定的URL,输出将是该页面上的所有文本。
- Notes注意:使用Python请求模块。
- Requires LLM需要LLM:没有
llm-math
- Tool Name工具名称:计算器
- Tool Description工具描述:当你需要回答有关数学的问题时很有用。
- Notes注释: LLMMath 链的实例。
- Requires LLM 需要LLM:是的
12.1.2.自定义工具的方法
可以定义一个args_schema来提供有关输入的更多信息。
class CalculatorInput(BaseModel):
question: str = Field()
tools.append(
Tool(
name="Calculator",
func=llm_math_chain.run,
description="在需要回答数学问题时非常有用",
args_schema=CalculatorInput
)
)从BaseTool类派生子类
```python
from typing import Type
class CustomSearchTool(BaseTool):
name = "搜索"
description = "当你需要回答有关当前事件的问题时有用"
def _run(self, query: str) -> str:
"""使用工具。"""
return search.run(query)
async def _arun(self, query: str) -> str:
"""异步使用工具。"""
raise NotImplementedError("BingSearchRun不支持异步")
class CustomCalculatorTool(BaseTool):
name = "计算器"
description = "用于进行数学计算"
def _run(self, query: str) -> str:
"""使用工具。"""
return calculator.run(query)
async def _arun(self, query: str) -> str:
"""异步使用工具。"""
raise NotImplementedError("CustomCalculatorTool不支持异步")
``` python当创建好工具之后,我们可以使用工具来进行初始化代理对象
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("谁是莱昂纳多·迪卡普里奥的女朋友?她当前的年龄上升到0.43次方是多少?")
12.1.3.修改现有工具
如何加载现有的工具并对其进行修改。在下面的示例中,我们做一些非常简单的事情,
将搜索工具的名称更改为“Google Search”。
from langchain.agents import load_tools
tools = load_tools(["serpapi", "llm-math"], llm=llm)
tools[0].name = "Google Search"
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
> 进入新的AgentExecutor链...
我需要找出Leo DiCaprio女友的名字和她的年龄。
动作:Google Search
动作输入:"Leo DiCaprio girlfriend"I draw the lime at going to get a Mohawk, though." DiCaprio broke up with girlfriend Camila Morrone, 25, in the summer of 2022, after dating for four years. He's since been linked to another famous s
```超模特——吉吉·哈迪德。现在我需要找出卡米拉·莫罗内的当前年龄。
操作:计算器
操作输入:25 ^ 0.43
答案:3.991298452658078
我现在知道了最终答案。
最终答案:卡米拉·莫罗内的当前年龄提高到0.43次方约为3.99。
> 完成链。
这可以通过添加类似于“使用这个音乐搜索引擎而不是普通搜索。如果问题是关于音乐的,比如“谁是昨天的歌手?” 或“2022年最受欢迎的歌曲是什么?”的语句来实现。
下面是一个例子。
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.llms import OpenAI
from langchain import LLMMathChain, SerpAPIWrapper
search = SerpAPIWrapper()
tools = [
Tool(
name = "搜索",
func=search.run,
description="当您需要回答当前事件的问题时很有用"
),
Tool(
name="音乐搜索",
func=lambda x: "'All I Want For Christmas Is You' by Mariah Carey.", #Mock Function
description="一个音乐搜索引擎。如果问题是关于音乐的,
请使用这个搜索引擎而不是普通搜索,比如'谁是昨天的歌手?
'或'2022年最受欢迎的歌曲是什么?'"
)
]
# 初始化代理
agent = initialize_agent(
agent_type=AgentType.OPENAI,
api_key="your_api_key_here",
llm=LLMMathChain(),
tools=tools
)
# 使用代理回答问题
response = agent.answer("法国的首都是哪里?")
# 打印回答
print(response)
```irectly instead of going through the agent's decision making process. This can be done by using the `tools.run` method. Here is an example:
```python
from deepset_ai import tools
answer = tools.run('text-classification', model_name_or_path='bert-base-uncased', data=['What is the capital of France?'])
print(answer)
``` python
在这个例子中,我们使用`text-classification`工具来使用BERT模型对给定的文本进行分类。
输出将是一个字典列表,其中每个字典代表一个可能的标签及其相关的得分。
`print`语句将输出此列表。
要直接将结果返回给用户(如果调用的话),可以通过设置LangChain中工具的`return_direct`标志为`True`来轻松实现。
# 直接在定义工具列表的时候创建工具,需要指定 name、func、description、等参数
llm_math_chain = LLMMathChain(llm=llm)
tools = [
Tool(
name="计算器",
func=llm_math_chain.run,
description="在需要回答数学问题时很有用",
return_direct=True
)
]
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("2\*\*.12是多少")
> 进入新的AgentExecutor链...
我需要计算一下
操作:计算器
操作输入:2\*\*.12答案:1.086734862526058
> 链结束。
'答案:1.086734862526058'
12.2.代理执行器
将代理和工具结合使用,并使用代理来决定调用哪些工具以及按什么顺序调用。
12.2.1.简单使用
from langchain.agents import AgentExecutor
agent_executor=AgentExecutor(agent=agent,tools=tools,verbose=True)
agent_executor.invoke({"input":"how many letters in the word educa?"})十三、记忆存储Memory
13.1.基础知识
默认情况下,链(Chains)和代理(Agents)是无状态的,这意味着它们将每个传入的查询视为独立的(底层的LLM和聊天模型也是如此)。在某些应用程序中(如:聊天机器人),记住先前的交互则非常重要。记忆(Memory)正是为此而设计的。记忆涉及了在用户与语言模型的交互过程中保持状态的概念。用户与语言模型的交互被捕捉在ChatMessage的概念中,因此这涉及到对一系列聊天消息进行摄取、捕捉、转换和提取知识。有许多不同的方法可以实现这一点,每种方法都存在作为自己的记忆类型。通常情况下,对于每种类型的记忆,有两种使用记忆的方法。一种是独立的函数,从一系列消息中提取信息,另一种是在链中使用这种类型的记忆的方法。
记忆可以返回多个信息(如:最近的N条消息和所有先前消息的摘要),返回的信息可以是字符串或消息列表。在本文中,我们将介绍最简单形式的记忆:"缓冲"记忆。它只涉及保持先前所有消息的缓冲区。我们将展示如何在这里使用模块化的实用函数,然后展示它如何在链中使用(返回字符串和消息列表两种形式)。
聊天消息历史ChatMessageHistory
在大多数记忆模块的核心实用类之一是ChatMessageHistory类。这是一个超轻量级的包装器,提供了保存人类消息、AI 消息以及获取所有消息的便捷方法。如果我们在链外管理记忆,则可以直接使用此类。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
ConversationBufferMemory
现在我们展示如何在链中使用这个简单的概念。首先展示ConversationBufferMemory,它只是一个对ChatMessageHistory的包装器,用于提取消息到一个变量中。我们可以首先将其提取为一个字符串:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
输出:
{'history': 'Human: hi!\nAI: whats up?'}
还可以将历史记录作为消息列表获取:
memory = ConversationBufferMemory(return_messages=True)
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
输出:
{'history': [HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]}
在链中使用,看看如何在链中使用这个模块,其中我们设置了verbose=True以便查看提示。
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="Hi there!")
日志输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI:
> Finished chain.
输出:
" Hi there! It's nice to meet you. How can I help you today?"
输入:
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
1
日志输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI: Hi there! It's nice to meet you. How can I help you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great! It's always nice to have a conversation with someone new. What would you like to talk about?
Human: Tell me about yourself.
AI:
> Finished chain.
输出:
" Sure! I'm an AI created to help people with their everyday tasks. I'm programmed to understand natural language and provide helpful information. I'm also constantly learning and updating my knowledge base so I can provide more accurate and helpful answers."保存消息记录到本地
我们可能经常需要保存消息,并在以后使用时加载它们。我们可以通过将消息首先转换为普通的Python字典来轻松实现此操作,然后将其保存(如:保存为JSON格式),然后再加载。以下是一个示例:
import json
from langchain.memory import ChatMessageHistory
from langchain.schema import messages_from_dict, messages_to_dict
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
dicts = messages_to_dict(history.messages)
dicts
输出:
[{'type': 'human',
'data': {'content': 'hi!', 'additional_kwargs': {}, 'example': False}},
{'type': 'ai',
'data': {'content': 'whats up?', 'additional_kwargs': {}, 'example': False}}]
输入:
new_messages = messages_from_dict(dicts)
new_messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
13.1.会话缓存记忆ConversationBufferMemory
这种记忆方式允许存储消息,并将消息提取到一个变量中,我们首先将其提取为字符串:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})
输出:{'history': 'Human: hi\nAI: whats up'}我们还可以将历史记录作为消息列表获取。如果我们与聊天模型一起使用,这非常有用:
memory = ConversationBufferMemory(return_messages=True)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})
输出:{'history': [HumanMessage(content='hi', additional_kwargs={}),
AIMessage(content='whats up', additional_kwargs={})]}13.2.会话缓存窗口记忆ConversationBufferWindowMemory
会话缓存记忆ConversationBufferWindowMemory保留了对话中随时间变化的交互列表。它只使用最后的K次交互。这对于保持最近交互的滑动窗口很有用,以防止缓冲区过大。
详细见网址:https://machinelearning.blog.csdn.net/article/details/132152216
13.3.实体记忆(Entity Memory)
使用一个记忆模块来记录有关特定实体的信息。它使用语言模型(LLMs)提取实体相关的信息,并随着时间的推移逐渐积累对该实体的知识。让我们首先通过一个例子来了解如何使用这个功能:
from langchain.llms import OpenAI
from langchain.memory import ConversationEntityMemory
llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context(
_input,
{"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'})
输出:
{'history': 'Human: Deven & Sam are working on a hackathon project\nAI: That sounds like a great project! What kind of project are they working on?',
'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}memory = ConversationEntityMemory(llm=llm, return_messages=True)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context(
_input,
{"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'})
输出:
{'history': [HumanMessage(content='Deven & Sam are working on a hackathon project', additional_kwargs={}),
AIMessage(content=' That sounds like a great project! What kind of project are they working on?', additional_kwargs={})],
'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
在链中如何使用:
from langchain.chains import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from pydantic import BaseModel
from typing import List, Dict, Any
conversation = ConversationChain(
llm=llm,
verbose=True,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm)
)
conversation.predict(input="Deven & Sam are working on a hackathon project")
检查记忆存储
我们也可以直接检查记忆存储。在下面的示例中,我们直接查看它,然后通过一些添加信息的示例来观察它的变化。
from pprint import pprint
pprint(conversation.memory.entity_store.store)
13.4.对话知识图谱记忆(Conversation Knowledge Graph Memory)
这种类型的记忆使用知识图谱来重建记忆
https://machinelearning.blog.csdn.net/article/details/132154750
这行代码加载记忆中存储的变量,并将其应用于当前的上下文。{} 表示这里没有传递额外的变量。
memory.load_memory_variables({})
13.5.对话摘要记忆ConversationSummaryMemory
现在让我们来看一下使用稍微复杂的记忆类型ConversationSummaryMemory。这种类型的记忆会随着时间的推移创建对话的摘要。这对于从对话中压缩信息非常有用。
https://machinelearning.blog.csdn.net/article/details/132154750
13.6.基于向量存储的记忆VectorStoreRetrieverMemory
VectorStoreRetrieverMemory将内存存储在VectorDB中,并在每次调用时查询最重要的前K KK个文档。与大多数其他Memory类不同,它不明确跟踪交互的顺序。在这种情况下,“文档”是先前的对话片段。这对于提及AI在对话中早些时候得知的相关信息非常有用。
https://machinelearning.blog.csdn.net/article/details/132258746
13.7.将记忆添加到LLMChain中
本节介绍如何将Memory类与LLMChain结合使用,我们将添加ConversationBufferMemory类作为示例,但实际上可以使用任何Memory类。
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI, LLMChain, PromptTemplate
最重要的步骤是正确设置提示。在下面的提示中,我们有两个输入键:一个用于实际输入,另一个用于来自Memory类的输入。重要的是需要确保PromptTemplate和ConversationBufferMemory中的键匹配chat_history。
template = """You are a chatbot having a conversation with a human.
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(
llm=OpenAI(),
prompt=prompt,
verbose=True,
memory=memory,
)
llm_chain.predict(human_input="Hi there my friend")

13.8.将记忆添加到多输入链中
大多数记忆对象假设只有一个输入。在本节中,我们将介绍如何将记忆添加到具有多个输入的链中。我们以问答链为例,向该链中添加记忆,该链的输入包括相关文档和用户提问:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))])
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query)
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
template = """You are a chatbot having a conversation with a human.
Given the following extracted parts of a long document and a question, create a final answer.
{context}
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input", "context"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt)
query = "What did the president say about Justice Breyer"
chain({"input_documents": docs, "human_input": query}, return_only_outputs=True)
print(chain.memory.buffer)
13.9.将记忆添加到代理中
本节介绍如何将记忆添加到Agent中,为了将记忆添加到Agent中,我们将执行以下步骤:
创建带有记忆的LLM链
使用该LLM链创建自定义Agent
在本示例中,我们将创建一个简单的自定义Agent,该Agent可以访问搜索工具并利用ConversationBufferMemory类。
13.10.将基于数据库的消息记忆添加到代理中
本节介绍了如何将记忆添加到使用外部消息存储的代理中,为了将带有外部消息存储的记忆添加到代理中,我们需要执行以下步骤:
创建一个RedisChatMessageHistory对象,以连接到外部数据库以存储消息
使用该聊天记录作为记忆创建一个 LLMChain
使用该LLMChain创建一个自定义代理
https://machinelearning.blog.csdn.net/article/details/132258845
13.11.自定义对话记忆
AI前缀
第一种方法是通过更改对话摘要中的AI前缀来实现。默认情况下,它设置为AI,但你可以将其设置为任何你想要的内容。需要注意的是,如果我们更改了这个前缀,我们还应该相应地更改链条中使用的提示来反映这个命名更改。让我们通过下面的示例来演示这个过程。
https://machinelearning.blog.csdn.net/article/details/132282648
人类前缀
第二种方法是通过更改对话摘要中的人类前缀来实现。默认情况下,它设置为Human,但我们可以将其设置为任何我们想要的内容。需要注意的是,如果我们更改了这个前缀,我们还应该相应地更改链条中使用的提示来反映这个命名更改。让我们通过下面的示例来演示这个过程。
https://machinelearning.blog.csdn.net/article/details/132282648
13.12.存储消息历史记录
MongoDB聊天消息记录
本节介绍如何使用MongoDB存储聊天消息记录。MongoDB是一个开放源代码的跨平台文档导向数据库程序。它被归类为NoSQL数据库程序,使用类似JSON的文档,并且支持可选的模式。MongoDB由MongoDB Inc.开发,并在服务器端公共许可证(SSPL)下许可。
Redis聊天消息历史记录
本节介绍了如何使用Redis来存储聊天消息历史记录。
from langchain.memory import RedisChatMessageHistory
history = RedisChatMessageHistory("foo")
history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
使用SQLite存储的实体记忆
我们将创建一个简单的对话链,该链使用ConversationEntityMemory,并使用SqliteEntityStore作为后端存储。使用EntitySqliteStore作为记忆entity_store属性上的参数:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationEntityMemory
from langchain.memory.entity import SQLiteEntityStore
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
entity_store=SQLiteEntityStore()
llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm, entity_store=entity_store)
conversation = ConversationChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=memory,
verbose=True,
)
conversation.run("Deven & Sam are working on a hackathon project")















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









