






目录
一、贝叶斯算法概述
贝叶斯算法是一种基于概率论的分类方法,它通过计算先验概率和条件概率来预测样本的类别。贝叶斯算法的核心思想是利用已知的信息(如训练数据集)来估计未知参数的概率分布,从而对新的样本进行分类。贝叶斯算法在机器学习、数据挖掘和自然语言处理等领域有着广泛的应用。
二、样本的先验概率
在贝叶斯算法中,先验概率通常指在不考虑特征条件下,样本属于某个类别的概率。例如,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P(c)
* ∣D∣ 是训练集 D 中的总样本数量
* ∣Dc∣ 是类别 c 中的总样本数量。
例子:假设我们有100个西瓜,其中有80个是好瓜,20个是坏瓜。那么好瓜的先验概率为80/100=0.8,坏瓜的先验概率为20/100=0.2。
三、样本的条件概率
条件概率是指在一个事件发生的条件下,另一个事件发生的概率。在贝叶斯算法中,条件概率表示在给定类别的情况下,样本具有某种特征的概率。例如,求的先验概率后,对于离散属性而言,令Dcixi表示Dc中在第i个属性上取值为Xi的样本组成的集合,则条件概率
* Dc,xi 是数据集 Dc 中在第 i 个属性上取值为 xi 的样本组成的集合
* ∣Dc,xi∣ 是集合Dc,xi 中的样本数量。
* ∣Dc∣ 是类别 c 中的总样本数量。
四、样本的后验概率
* P(C|X)是事件C在事件X发生后的后验概率。
* P(X|C)是事件X在事件C发生后的条件概率
* P(C) 是事件C的先验概率
* P(X)是事件X的边缘概率
在本实验中,后验概率等于先验概率和条件概率的乘积
五、代码的实现
5.1 准备数据集
data = {
'好瓜': [
['青绿', '蜷缩', '浊响'],
['乌黑', '蜷缩', '沉闷'],
['乌黑', '稍蜷', '浊响'],
['青绿', '硬挺', '清脆'],
['浅白', '稍蜷', '浊响'],
['青绿', '稍蜷', '浊响']
],
'坏瓜': [
['浅白', '硬挺', '清脆'],
['乌黑', '稍蜷', '浊响'],
['乌黑', '稍蜷', '浊响'],
['青绿', '蜷缩', '沉闷']
]
}
5.1计算先验概率
由公式求好瓜和坏瓜的先验概率
调用函数并传入数据集data,得到"好瓜"和"坏瓜"的先验概率。
# 计算先验概率
def xianyangailv(dataset):
total_good = len(dataset['好瓜']) # 数据集中好瓜的数量
total_bad = len(dataset['坏瓜']) # 数据集中坏瓜的数量
total = total_good + total_bad # 数据集的总数量
good = total_good / total # 计算好瓜的先验概率
bad = total_bad / total # 计算坏瓜的先验概率
return good, bad # 返回好瓜和坏瓜的先验概率
# 调用函数计算先验概率
good, bad = xianyangailv(data)
# 打印结果
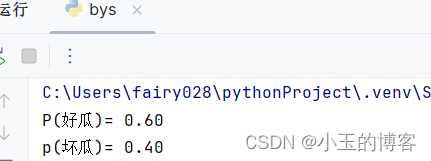
print(f"P(好瓜)= {good:.2f}")
print(f"p(坏瓜)= {bad:.2f}")运行结果,输出好瓜和坏瓜的先验概率
5.3计算条件概率
根据公式计算给定数据集中每个特征在好瓜和坏瓜情况下的条件概率,并逐个输出每个特征是好瓜和坏瓜的概率
# 初始化字典来存储每个特征的条件概率
dictionary_1 = {}
for feature in features:
#判断当前元素x中是否包含特征feature,如果包含特征feature,则生成一个值为1的元素,对生成的1的个数进行求和,得到满足条件的元素个数。
good_count = sum(1 for x in data['好瓜'] if feature in x)
bad_count = sum(1 for x in data['坏瓜'] if feature in x)
total_good = len(data['好瓜'])
total_bad = len(data['坏瓜'])
dictionary_1 [feature] = { #字典1中记录了在好瓜和坏瓜的情况下,每一个特征值是好瓜和坏瓜的条件概率
'好瓜': good_count / total_good,
'坏瓜': bad_count / total_bad
}
# 逐个输出每个特征是好瓜和坏瓜的概率
counter = 1
for feature in features:
print("p{0}({1}|好瓜)={2}".format(counter,feature, dictionary_1[feature]['好瓜']))
print("p{0}({1}|坏瓜)={2}".format(counter + 1, feature, dictionary_1[feature]['坏瓜']))
counter += 2运行结果,输出每一个特征的条件概率

5.4 计算后验概率
根据给定的预测样本,计算好瓜和坏瓜的概率。它通过遍历预测样本中的每个特征,并根据特征在字典中对应的好瓜和坏瓜的条件概率进行乘积运算,得到好瓜和坏瓜的后验概率。最后,将先验概率与后验概率相乘,输出好瓜和坏瓜的概率。
new_sample = ['乌黑', '稍蜷', '沉闷'] #预测样本
isgood = 1
isbad = 1
counter = 1
for feature in new_sample:
if counter % 2 == 1:
isgood *= dictionary_1[feature]['好瓜']
else:
isbad *= dictionary_1[feature]['坏瓜']
counter += 1
#后验概率等于先验概率和条件概率的乘积
print("好瓜概率:", good*isgood)
print("坏瓜概率:", bad*isbad)运行结果,输出好瓜和坏瓜的后验概率

六、完整代码
import numpy as np
# 假设数据集
data = {
'好瓜': [
['青绿', '蜷缩', '浊响'],
['乌黑', '蜷缩', '沉闷'],
['乌黑', '稍蜷', '浊响'],
['青绿', '硬挺', '清脆'],
['浅白', '稍蜷', '浊响'],
['青绿', '稍蜷', '浊响']
],
'坏瓜': [
['浅白', '硬挺', '清脆'],
['乌黑', '蜷缩', '浊响'],
['乌黑', '稍蜷', '浊响'],
['青绿', '蜷缩', '沉闷']
]
}
# 计算先验概率
def xianyangailv(dataset):
total_good = len(dataset['好瓜']) # 数据集中好瓜的数量
total_bad = len(dataset['坏瓜']) # 数据集中坏瓜的数量
total = total_good + total_bad # 数据集的总数量
good = total_good / total # 计算好瓜的先验概率
bad = total_bad / total # 计算坏瓜的先验概率
return good, bad # 返回好瓜和坏瓜的先验概率
# 调用函数计算先验概率
good, bad = xianyangailv(data)
# 打印结果
print(f"P(好瓜=是)= {good:.2f}")
print(f"p(坏瓜=是)= {bad:.2f}")
# 初始化特征列表
features = ['青绿', '乌黑', '浅白', '蜷缩', '稍蜷', '硬挺', '清脆', '浊响', '沉闷']
# 初始化字典来存储每个特征的条件概率
dictionary_1 = {}
for feature in features:
good_count = sum(1 for x in data['好瓜'] if feature in x)#遍历 data['好瓜'] 中的每个元素,将每个元素赋值给变量 x,通过列表推导式生成一个由数字1组成的列表,然后使用 sum() 函数对列表中的所有元素求和,得到满足条件的元素的总数。
bad_count = sum(1 for x in data['坏瓜'] if feature in x)#计算在 data['好瓜'] 中包含特定特征 feature 的元素个数。
total_good = len(data['好瓜'])
total_bad = len(data['坏瓜'])
dictionary_1 [feature] = {
'好瓜': good_count / total_good,
'坏瓜': bad_count / total_bad
}
# 逐个输出每个特征是好瓜和坏瓜的概率
counter = 1
for feature in features:
print("p{0}({1}|好瓜)={2}".format(counter,feature, dictionary_1[feature]['好瓜']))
print("p{0}({1}|坏瓜)={2}".format(counter + 1, feature, dictionary_1[feature]['坏瓜']))
counter += 2
new_sample = ['青绿', '稍蜷', '浊响'] #预测样本
isgood = 1
isbad = 1
counter = 1
for feature in new_sample:
if counter % 2 == 1:
isgood *= dictionary_1[feature]['好瓜']
else:
isbad *= dictionary_1[feature]['坏瓜']
counter += 1
# 后验概率等于先验概率乘条件概率,通过比较后验概率的大小来分类
if good * isgood > bad * isbad:
print("好瓜概率 > 坏瓜概率,所以预测样本是好瓜")
else:
print("好瓜概率 < 坏瓜概率,所以预测样本是坏瓜")# 输出好瓜概率和坏瓜概率的比较结果
print("好瓜概率:", good*isgood)
print("坏瓜概率:", bad*isbad)6.1 运行结果

七、实验小结
通过本次实验,我对贝叶斯分类器有了更深刻的理解,对于如何求先验概率和条件概率、后验概率更加熟悉,本次实验中也出现许多问题,通过不断地查看相关博主的思路,慢慢修改的代码的不足之处,在本次实验中让我学会了字典这一知识点,通过字典来存储数据,方便后续查找数据和修改数据,通过通过初始化特征方便后续代码的遍历,让代码更加流畅的使用,实验结果表明,在特定条件下,如小样本数据集上,贝叶斯分类器能够提供较好的分类性能。















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









