






 本文详细介绍了机器学习中常用的分类模型评估指标,如准确率、精确度、召回率、F1分数、AUC-ROC以及ROC和PR曲线的概念及其应用场景。还通过示例展示了不同K值下KNN模型的ROC曲线。
本文详细介绍了机器学习中常用的分类模型评估指标,如准确率、精确度、召回率、F1分数、AUC-ROC以及ROC和PR曲线的概念及其应用场景。还通过示例展示了不同K值下KNN模型的ROC曲线。
在机器学习中,分类模型的评估指标对于衡量模型性能至关重要。以下是我对于一些常见的分类模型评估指标的理解:
一.常见的分类模型评估指标
- 准确率(Accuracy):
- 定义:准确率是分类问题中最简单也是最直观的评价指标,它表示模型预测正确的样本数占总样本数的比例。
- 计算方法:准确率 = (真正例数 + 真负例数) / 总样本数

- 局限性:当不同类别的样本数量分布极不均衡时,准确率可能无法准确反映模型的性能。例如,在二分类问题中,如果负样本数量远多于正样本,即使模型将所有样本都预测为负样本,也能获得较高的准确率,但这显然不能反映模型在识别正样本上的真实能力。
- 精确度(Precision):
- 定义:精确度衡量的是模型预测为正样本的实例中,真正为正样本的比例。它关注模型预测为正样本的可靠性。
- 计算方法:精确度 = 真正例数 / (真正例数 + 假正例数)
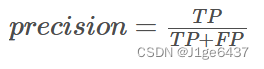
- 解读:一个高精确度的模型意味着在预测为正样本的实例中,大部分确实是正样本。这在假阳性(即错误地将负样本预测为正样本)成本高昂的应用场景中尤为重要。
- 召回率(Recall):
- 定义:召回率衡量的是模型正确识别出的正样本占所有实际正样本的比例。它关注模型找出所有正样本的能力。
- 计算方法:召回率 = 真正例数 / 实际正样本数
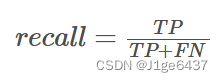
- 解读:高召回率的模型能够尽可能多地找出所有的正样本,减少漏检的情况。这在需要尽可能避免遗漏正样本(即假阴性)的场景中很有用,例如医学诊断、欺诈检测等。
- F1分数(F1 Score):
- 定义:F1分数是精确度和召回率的调和平均数,它综合考虑了精确度和召回率两个指标,用于提供一个更平衡的评估。
- 计算方法:F1分数 = 2 * (精确度 * 召回率) / (精确度 + 召回率)

- 解读:F1分数越高,说明模型在精确度和召回率两个方面都有较好的表现。当精确度和召回率都同等重要时,F1分数是一个很好的综合评估指标。
- AUC-ROC(Area Under the Receiver Operating Characteristic Curve):
- 定义:ROC曲线描绘了在不同阈值下真正例率(TPR,即召回率)和假正例率(FPR)之间的关系。AUC-ROC则是ROC曲线下的面积,用于衡量模型分类准确性的整体能力。
- 计算方法:AUC-ROC是通过计算ROC曲线下的面积得到的,其值介于0到1之间。
- 解读:AUC-ROC值越接近1,说明模型的分类性能越好。AUC-ROC不受特定分类阈值的影响,因此能够更全面地评估模型的性能。
- 特异度(Specificity):
- 定义:特异度衡量的是模型正确识别出的负样本占所有实际负样本的比例。它关注模型对负样本的识别能力。
- 计算方法:特异度 = 真负例数 / 实际负样本数
- 解读:高特异度的模型能够尽可能多地正确识别负样本,减少将负样本误判为正样本的情况。这在需要避免误报或误分类的场合中尤为重要。
在选择评估指标时,需要根据具体的应用场景和需求来确定。例如,在某些情况下,我们可能更关注避免假阳性(即误报),而在其他情况下,我们可能更关注避免假阴性(即漏报)。此外,对于多分类问题,还需要考虑其他更复杂的评估指标。
二.ROC和PR曲线的理解
在机器学习中,ROC曲线(Receiver Operating Characteristic Curve)和PR曲线(Precision-Recall Curve)都是用于评估二分类模型性能的重要工具。它们的主要差异体现在关注点和适用场景上。
ROC曲线主要关注模型对整体样本的分类效果,特别是正例与负例之间的分类。它基于模型在不同阈值下的预测结果,通过计算真正率(True Positive Rate,即召回率)和假正率(False Positive Rate)之间的关系来绘制曲线。真正率是指分类器在所有实际为正例中正确预测为正例的比例,而假正率是指分类器在所有实际为负例中错误预测为正例的比例。ROC曲线可以帮助我们进行模型选择和调整分类器的阈值,以优化模型的整体性能。
PR曲线则更加关注模型对少数类(即正例)的识别率。它通过绘制在不同阈值下精度(Precision)和召回率(Recall)之间的曲线来评估模型性能。精度是指模型预测为正例的样本中真正为正例的比例,而召回率与ROC曲线中的真正率相同。因此,PR曲线在数据不平衡的情况下更加适用,尤其是当少数类的重要性较高时。
总结来说,ROC曲线和PR曲线在机器学习中各有侧重。ROC曲线更适用于评估模型对整体样本的分类效果,而PR曲线则更关注模型对少数类的识别能力。在实际应用中,我们可以根据具体需求和数据特点选择合适的曲线进行评估。
三.不同K值下的ROC曲线
1.代码实现
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
y_bin = (y == 2).astype(np.int) # 将类别2作为正例,其他作为负例
# 划分训练集和测试集
X_train, X_test, y_train_bin, y_test_bin = train_test_split(X, y_bin, test_size=0.3, random_state=42)
# 定义一个函数来绘制ROC曲线
def plot_roc_curve(knn, X_test, y_test_bin, label):
y_score = knn.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test_bin, y_score)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, alpha=0.5, label=f'{label} (AUC = {roc_auc:.2f})')
# 绘制不同K值的ROC曲线
k_values = [1, 3, 5, 7]
colors = ['blue', 'green', 'red', 'cyan']
for k, color in zip(k_values, colors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train_bin)
plot_roc_curve(knn, X_test, y_test_bin, f'K={k}')
# 绘制对角线作为参考
plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='gray', alpha=.8)
# 设置图例、轴标签和标题
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curves for Different Values of K in KNN')
plt.legend(loc="lower right")
# 显示图形
plt.show()
2.图像展示
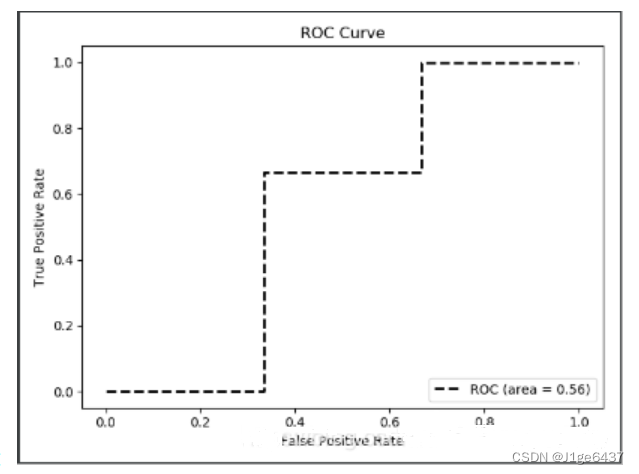















 2228
2228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









