






一.算法简介
1.1算法概述
Logistic回归是一种广义的线性回归分析模型,它常用于数据挖掘、疾病自动诊断、经济预测等领域。虽然其名字中包含“回归”二字,但实际上它是一种分类方法,主要用于二分类问题。
逻辑回归=线性回归+Sigmoid函数
在逻辑回归中,因变量(dependent variable)为二分类的类别变量(如0和1,是或否,真或假),而自变量(independent variable)可以是连续的,也可以是分类的。不过,二项逻辑回归的自变量一般是连续的,其因变量则是二分类的。
1.2线性回归
线性回归(Linear Regression)是一种统计学中的回归分析方法,用于研究一个或多个自变量(也称为预测变量、解释变量或特征)与一个因变量(也称为响应变量、目标变量或标签)之间的关系。线性回归模型假设因变量与自变量之间存在线性关系,即因变量可以通过一个线性方程来预测。
其线性回归方程经常表示为
 线性回归的目标是找到最佳的回归系数 β0β1β2……βp),使得预测值与实际值之间的误差最小。这通常通过最小二乘法(Least Squares Method)来实现,即最小化预测值与实际值之间的平方误差之和。
线性回归的目标是找到最佳的回归系数 β0β1β2……βp),使得预测值与实际值之间的误差最小。这通常通过最小二乘法(Least Squares Method)来实现,即最小化预测值与实际值之间的平方误差之和。
1.3sigmoid函数
逻辑回归使用sigmoid函数(也叫逻辑函数)将任意实数映射到[0,1]区间,并设定一个阈值(如0.5),如果sigmoid函数的值大于这个阈值,则判为正类(1),否则为负类(0)。其中sigmoid函数表达为
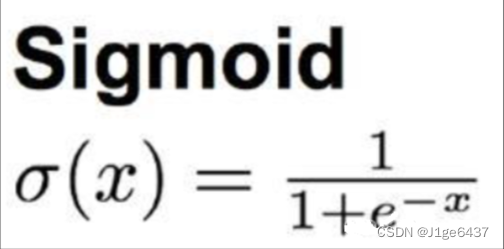
其图像表现为

小tips:
为什么不采取分段函数呢?如x≥0时取1,x<0时取-1呢?
因为上述分段函数并不连续,不连续即不可导,不可微,显然不符合实验需求。
1.4梯度上升算法
- 梯度上升算法是一种迭代优化算法,其核心思想是通过沿着目标函数梯度的方向进行迭代更新,以达到最大化目标函数的目的。在每次迭代中,算法会计算目标函数在当前点的梯度。
- 梯度是一个向量,指向函数值增长最快的方向。
- 算法会沿着这个梯度的方向移动一定的步长(学习率),以期望找到目标函数的更大值。
其中函数f(x,y)的梯度表示为

向x方向移动![]() ,向y方向移动
,向y方向移动![]() ,其中函数必须可微,最终将移动量大小定义为α,梯度上升公式为
,其中函数必须可微,最终将移动量大小定义为α,梯度上升公式为![]() .
.
例如
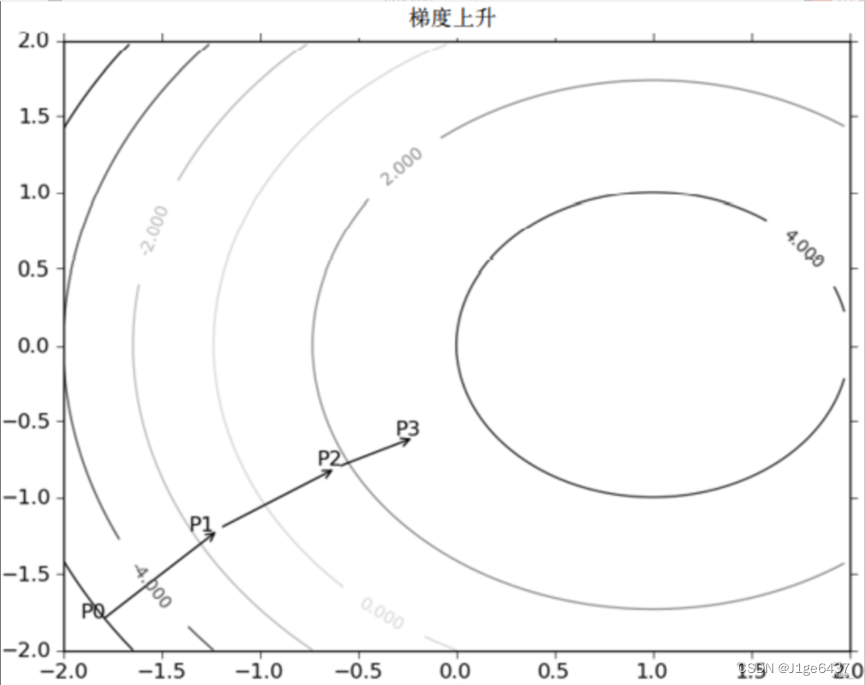
二.算法实现
2.1Logistic回归的一般过程
(1)收集数据:采用任意方法收集数据
(2)准备数据:需要进行距离计算,因此要求数据类型为数值型。结构化数据格式最佳
(3)分析数据:采用任意方法对数据进行分析
(4)训练算法:训练的目的是为了找到最佳的分类回归系数
(5)测试算法:一旦训练步骤完成,分类将会很快
(6)使用算法:通过训练好的回归系数进行简单的回归计算
2.2训练算法:使用梯度上升找到最佳参数
其中梯度上升的伪代码如下:
每个回归系数初始化为1
重复R次:
def loadDataSet():
dataMat=[]; labelMat=[]
fr=open("testSet.txt")
for line in fr.readlines():#逐行读取
lineArr=line.strip().split()#对testSet文件进行分割
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#默认X0=1.0,文件中每行的前两个值X1和X2
labelMat.append(int(lineArr[2])) #每行的第三个值(数据的类别标签)
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))#对应Sigmoid函数
def gradAscent(dataMatIn,classLabels):
dataMatrix=mat(dataMatIn)#dataMatIn作为二维数组,每列代表不同的特征,每行代表每个训练样本
labelMat=mat(classLabels).transpose()#类别标签,1*100的行向量进行转置变成列向量再赋值给labelMat
m,n=shape(dataMatrix)
alpha=0.001#目标移动的步长
maxCycles=500#迭代次数为500
weights=ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error#梯度上升算法迭代公式
return weights#返回训练好的回归系数
if __name__=='__main__':
dataArr,labelMat=loadDataSet()
print(dataArr)
print(labelMat)
weights1=gradAscent(dataArr,labelMat)
print(weights1)
运行成果:编辑器中形成了100分行向量以(x1,x2,x3)的形式展示出来,也输出了梯度上升算法的部分参数。

2.3分析数据:画出决策边界
上述代码已经解决出了一组回归系数,现在的任务便是画出不同类别数据之间的分隔线。
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()#获取数据集dataMat和标签集labelMat
dataArr=array(dataMat)#数据集转换为数组操作
n=shape(dataArr)[0]#n为数据集的行数
xcord1=[];ycord1=[]#xcord1和ycord1存储类别为1的数据点
xcord2=[];ycord2=[]#xcord2和ycord2存储类别为2的数据点
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig=plt.figure()#创建图形对象fig
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]#根据weights计算纵坐标y
ax.plot(x,y)
plt.xlabel('X1');plt.ylabel('X2')
plt.show()
代码成果:调用后得出初步的分隔线,其中分裂效果已经初步起色。

2.4训练算法:随机梯度上升
如果每次更新回归系数都要遍历整个数据集那么运算量过于庞大了,因此我们采用随机梯度上升算法。其伪代码如下:
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
令α*梯度更新回归值
返回回归值
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
for i in range(m):
h=sigmoid(sum(dataMatrix[i]*weights))#数值
error=classLabels[i]-h#数值
weights=weights+alpha*error*dataMatrix[i]
return weights
代码成果:遗憾是错分的样本比上述算法多太多了,但是后者显然更加简单。

2.5整体代码展示
#Logistic 回归
from numpy import *
import matplotlib.pyplot as plt
#加载数据集
def loadDataSet():
dataMat=[]; labelMat=[]
fr=open("testSet.txt")
for line in fr.readlines():#逐行读取
lineArr=line.strip().split()#对testSet文件进行分割
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#默认X0=1.0,文件中每行的前两个值X1和X2
labelMat.append(int(lineArr[2])) #每行的第三个值(数据的类别标签)
return dataMat,labelMat
#Sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))#对应Sigmoid函数
#梯度上升算法
def gradAscent(dataMatIn,classLabels):
dataMatrix=mat(dataMatIn)#dataMatIn作为二维数组,每列代表不同的特征,每行代表每个训练样本
labelMat=mat(classLabels).transpose()#类别标签,1*100的行向量进行转置变成列向量再赋值给labelMat
m,n=shape(dataMatrix)
alpha=0.001#目标移动的步长
maxCycles=500#迭代次数为500
weights=ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)#变量h是列向量而不是数值
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error#梯度上升算法迭代公式,这里的error是向量
return weights#返回训练好的回归系数
#绘制图像显示数据集的分布和最佳拟合直线
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()#获取数据集dataMat和标签集labelMat
dataArr=array(dataMat)#数据集转换为数组操作
n=shape(dataArr)[0]#n为数据集的行数
xcord1=[];ycord1=[]#xcord1和ycord1存储类别为1的数据点
xcord2=[];ycord2=[]#xcord2和ycord2存储类别为2的数据点
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig=plt.figure()#创建图形对象fig
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]#根据weights计算纵坐标y
ax.plot(x,y)
plt.xlabel('X1');plt.ylabel('X2')
plt.show()
#随机梯度上升算法
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
for i in range(m):
h=sigmoid(sum(dataMatrix[i]*weights))#数值
error=classLabels[i]-h#数值
weights=weights+alpha*error*dataMatrix[i]
return weights
#改进后的随机梯度上升算法
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n=shape(dataMatrix)
weights=ones(n)
for j in range(numIter):
dataIndex=list(range(m))
for i in range(m):
alpha=4/(1.0+j+i)+0.01#alpha在每次迭代时都会调整
randIndex=int(random.uniform(0,len(dataIndex)))#随机选取样本
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
#main函数调用各个相关函数
if __name__=='__main__':
dataArr,labelMat=loadDataSet()
print(dataArr)
print(labelMat)
weights1=gradAscent(dataArr,labelMat)
print(weights1)
plotBestFit(weights1.getA())
weights2=stocGradAscent0(array(dataArr),labelMat)
plotBestFit(weights2)
weights3=stocGradAscent1(array(dataArr),labelMat)
plotBestFit(weights3)三.实验分析
3.1实验小结
Logistic回归进行分类的主要思想是:根据训练数据利用Logistic回归生成最佳回归系数,并以此进行待测数据的分类。逻辑回归假设数据服从伯努利分布,通过极大似然估计的方法,运用(随机)梯度下降来求解参数,来达到数据二分类的目的。这次实验让我对Logistic回归有了一定的了解和认识,能运用其解决实际问题,但还不能熟练使用,要继续加强对机器学习相关知识的学习。总的来说是一次收获满满的实验。
3.2参照书籍
《机器学习实战》 Peter Harrington















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









