






一.基本概念
1.1降维技术
常见的降维技术有三种,分别是主成分分析(PCA),因子分析(FA)和独立成分分析(ICA),本文旨在讲述PCA,因为PCA的应用目前最为广泛。
1.2 PCA
1.2.1PCA的介绍
PCA(Principal Component Analysis,主成分分析)是一种常用的数据分析方法,用于在多个变量中识别出主要的模式或趋势,并减少数据集的维度。PCA 通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,这些新的变量称为主成分。
1.2.1.1主成分
通过PCA转换得到的新变量。这些主成分是按照其“重要性”或“信息量”进行排序的,通常第一个主成分包含了数据集中最大的方差(即信息)。
1.2.1.2方差
在统计学中,方差是衡量数据集中各个数值与其均值之间差异程度的一个指标。在PCA中,方差被用作衡量主成分包含信息量的度量。
1.2.1.3正交变换
PCA使用一种正交变换来转换原始数据。正交变换意味着变换后的变量(即主成分)之间是线性不相关的。
1.2.1.4降维
由于PCA能够识别出数据中的主要模式或趋势,因此它可以用于降低数据集的维度。这通常是通过选择包含最大方差的前几个主成分来实现的。
1.2.1.5解释性
每个主成分都是原始变量的线性组合,因此它们可以解释为原始变量的加权和。这有助于理解数据中的模式和趋势。
PCA在许多领域都有广泛的应用,包括机器学习、模式识别、图像处理、生物信息学等。通过减少数据集的维度,PCA可以降低计算复杂性,同时保留数据中的关键信息。然而,需要注意的是,PCA是一种无监督学习方法,因此在转换过程中不会考虑数据的标签或目标变量。
二.算法流程
2.1伪代码展示
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值从大到小排序
保留最上面的N个特征向量
将数据转换到上述N个特征向量构建的新空间中
2.2算法实现
2.2.1数据中心化
在PCA(主成分分析)中,数据中心化是一个重要的步骤,它涉及到对每个特征(或维度)的数据减去该特征的均值。这样处理后的数据,其均值将为0,这个过程也被称为零均值化或均值归零。
对于数据集中的每个样本,将其每个特征值减去该特征的均值,从而得到中心化后的数据。
中心化后的数据集 X' 可以通过以下公式得到:
X' = X - μ
其中 μ 是一个向量,其每个元素是对应特征的均值(即 [μ_1, μ_2, ..., μ_n])。 X 为原始数据集。
2.2.2计算协方差矩阵
协方差矩阵用于衡量特征之间的相关性。协方差矩阵![]() 的计算公式如下:
的计算公式如下:
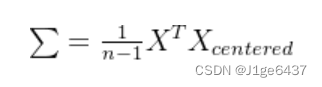
2.2.3计算特征值和特征向量
协方差矩阵的特征值和特征向量用于确定数据的主要方向和重要性。通过计算协方差矩阵的特征值和特征向量,我们可以找到数据在不同方向上的方差。
特征值(eigenvalue)表示主成分的重要性,而特征向量(eigenvector)表示主成分的方向。设协方差矩阵的特征值为![]() ,(从大到小排列),对应的特征向量为
,(从大到小排列),对应的特征向量为![]() 。
。
2.2.4选择主成分
选择前 ![]() 个最大的特征值对应的特征向量,构成新的低维空间。这里的
个最大的特征值对应的特征向量,构成新的低维空间。这里的 ![]() 通常是通过累积解释方差(cumulative explained variance)来确定的。
通常是通过累积解释方差(cumulative explained variance)来确定的。
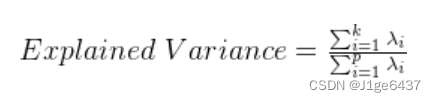
2.2.5数据投影
将原始数据投影到选择的主成分方向上,得到降维后的数据。降维后的数据矩阵 Z 计算如下:

其中, ![]() 是包含前
是包含前 ![]() 个特征向量的矩阵。
个特征向量的矩阵。
2.3算法目的
PCA的目标是找到数据在新的坐标系下的最优表示,使得数据在该坐标系下的投影方差最大化。通过选择最大的特征值对应的特征向量,PCA能够最大限度地保留数据的主要变化趋势,从而实现降维和去噪的目的。
2.4算法实现
2.4.1代码展示
import numpy as np
import matplotlib.pyplot as plt
from sklearn .datasets import make_blobs
from sklearn.decomposition import PCA
def create_data(num_samples=100, num_features=2, centers=2, random_state=42):
X, y = make_blobs(n_samples=num_samples, n_features=num_features, centers=centers, random_state=random_state)
return X, y
def show_data(X, y):
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
def visualize_svm(X, y, svm):
def get_hyperplane_value(x, w, b, offset):
return (-w[0] * x + b + offset) / w[1]
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0], xlim[1], 30)
y_pred = get_hyperplane_value(x, svm.w, svm.b, 0)
margin_plus = get_hyperplane_value(x, svm.w, svm.b, 1)
margin_minus = get_hyperplane_value(x, svm.w, svm.b, -1)
plt.plot(x, y_pred, 'k-')
plt.plot(x, margin_plus, 'k--')
plt.plot(x, margin_minus, 'k--')
plt.legend()
plt.show()
class SVM:
def __init__(self, lr=0.001, lambda_param=0.01, num_step=1000):
'''
:param lr: 学习率
:param lambda_param: 正则化参数
:param num_step: 步数
'''
self.lr = lr
self.lambda_param = lambda_param
self.num_step = num_step
self.w = None
self.b = None
def fit(self, X, y):
#初始化权重和偏置
num_samples, num_features = X.shape
self.w = np.zeros(num_features)
self.b = 0
#将标签从 0/1 转换为 -1/1。SVM 要求标签为 -1 和 1。
y_ = np.where(y <= 0, -1, 1)
#梯度下降
for _ in range(self.num_step):
for idx, x_i in enumerate(X):
#检查样本是否满足分类条件,更新权重和偏置
if y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1:
self.w -= self.lr * (2 * self.lambda_param * self.w)
else:
self.w -= self.lr * (2 * self.lambda_param * self.w - np.dot(x_i, y_[idx]))
self.b -= self.lr * y_[idx]
def predict(self, X):
pred = np.dot(X, self.w) + self.b
return np.sign(pred)
X, y = create_data(num_features=10)
y = np.where(y==0, -1, 1)
print(X.shape)
pca = PCA(n_components=2)
X = pca.fit_transform(X)
show_data(X, y)
svm = SVM()
svm.fit(X, y)
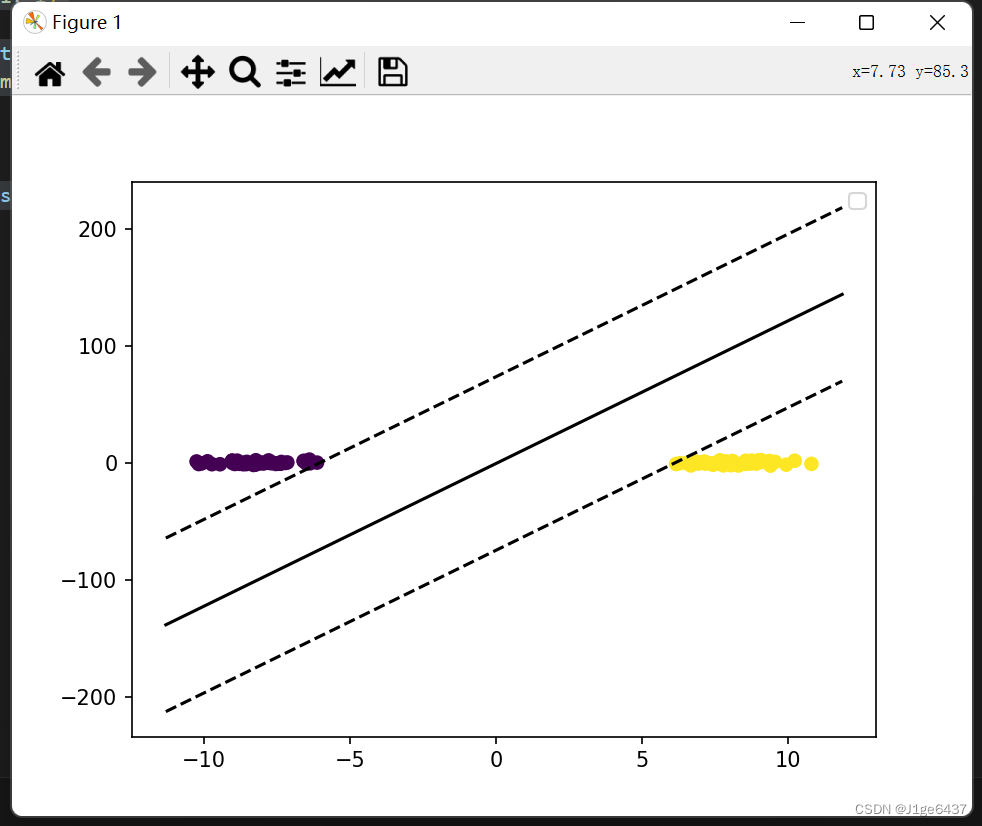
visualize_svm(X, y, svm)2.4.2结果展示
转换前
![]()
转换后
![]()

三.实验总结
PCA算法是一种广泛使用的算法,用于降维、特征提取和数据压缩等。它可以使数据集更易于处理,并提供更好的可视化效果。但是,PCA也有一些限制,例如不能更好地理解非线性数据集。这次实验让我对主成分分析有了一定的了解和认识,能运用其解决实际问题,但还不能熟练使用,要继续加强对机器学习相关知识的学习。总的来说是一次收获满满的实验。















 1884
1884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









