






项目简介:
项目功能说明:
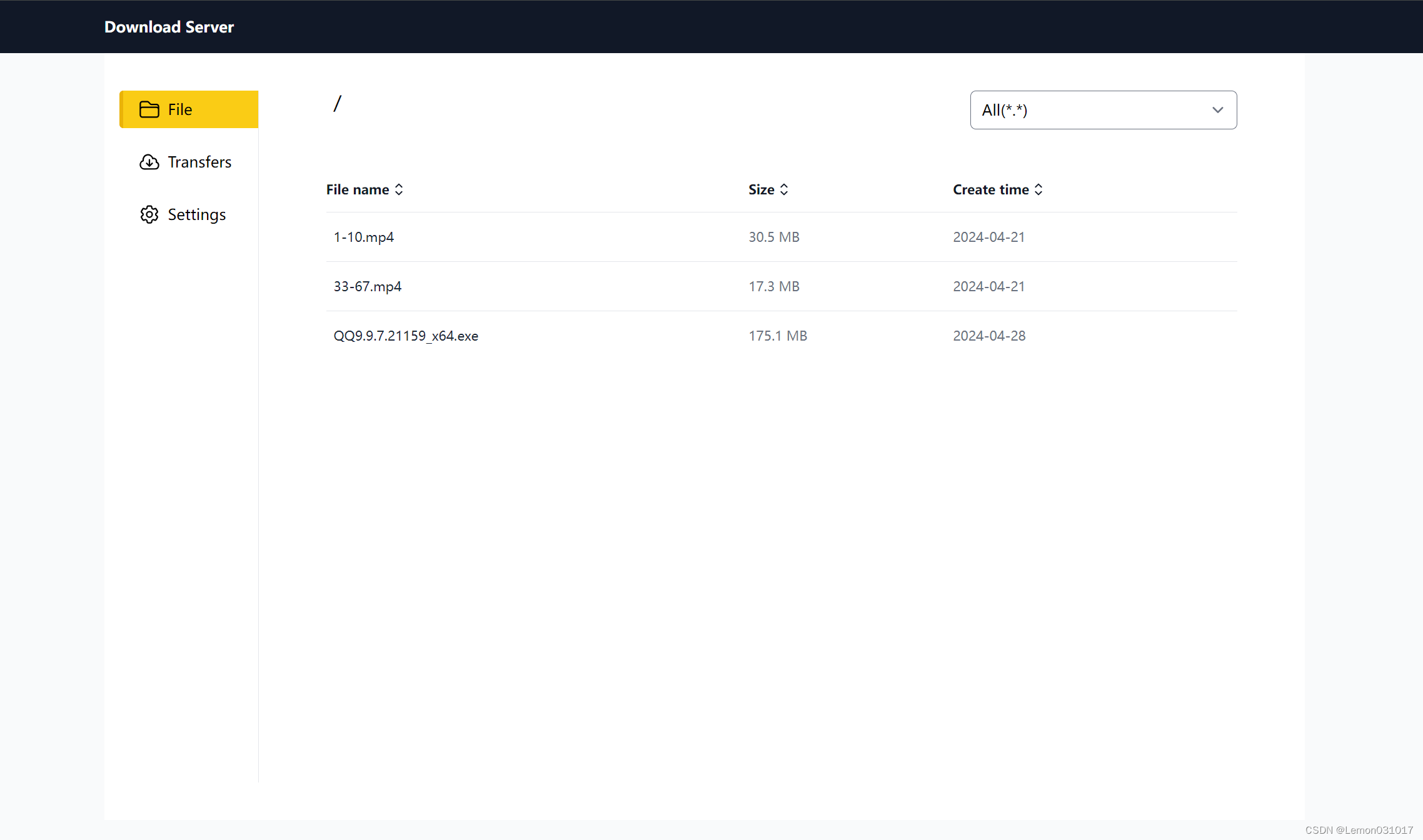
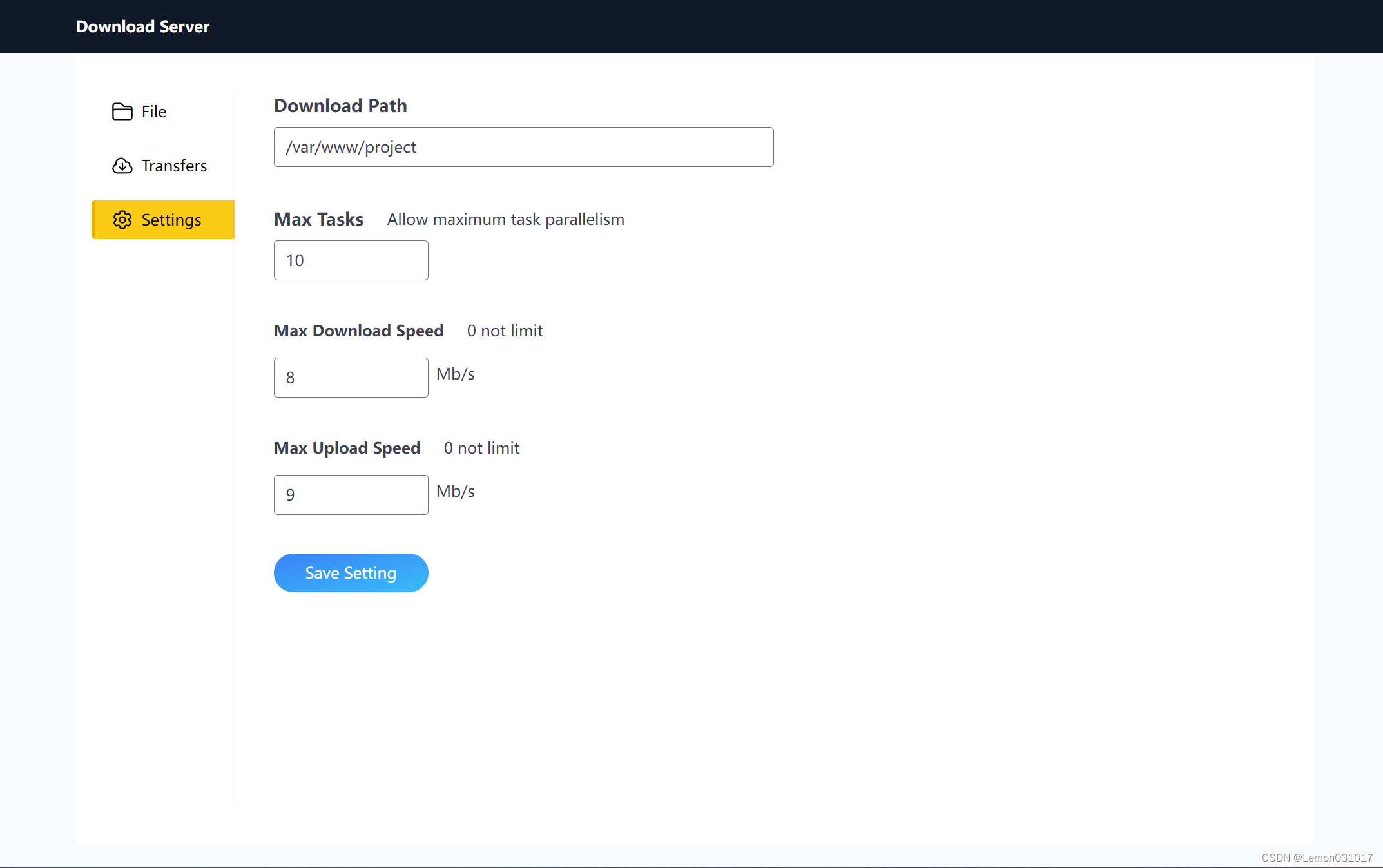
- 该网站包括file页面、transfer页面和settings页面。其中,file页面用于显示指定目录下的所有文件,可根据文件类型、名称或者大小进行排序筛选;transfer页面主要的使用场景是实现提交HTTP地址后下载到服务器上,这个服务器可以作为NAS或者云盘使用;settings页面用于设置下载路径、限速大小、最大并行任务数。
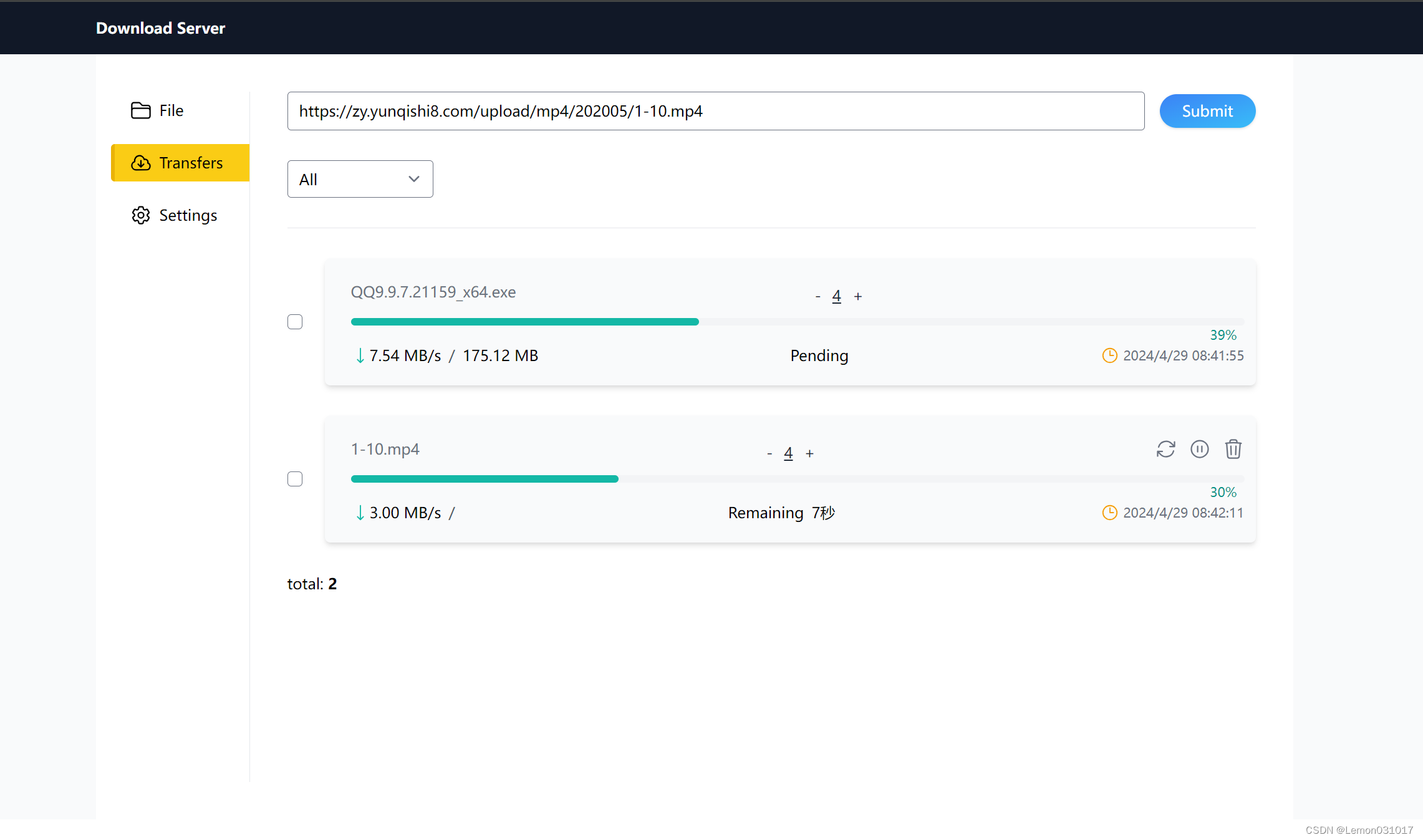
- transfer页面能够查看每个任务的下载进度、下载速度和下载剩余时间,用户可自行控制并发线程数。
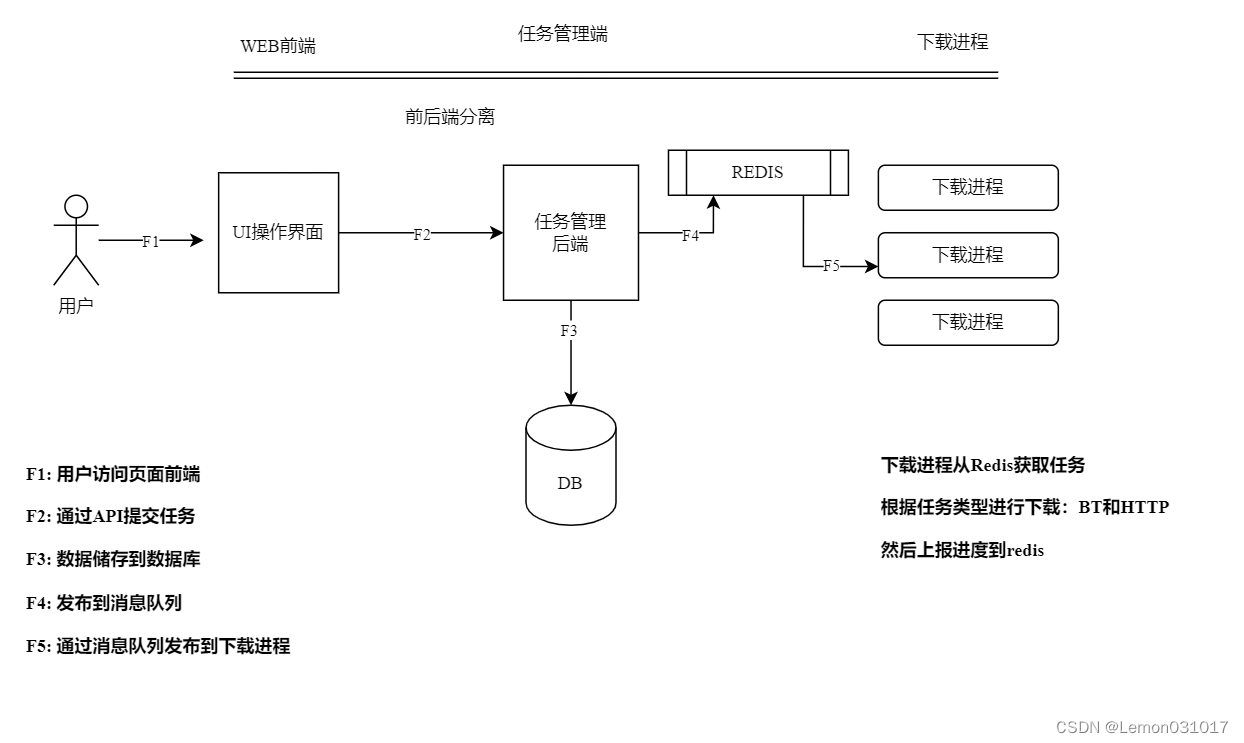
项目特点:本项目需要定时获取每个下载任务的实时状态,当系统需要大量并发请求时,如果直接在数据库上执行轮询可能会导致数据库连接池耗尽或数据库性能下降。因此我们利用redis消息队列来缓存任务状态,避免了轮询数据库,可以显著提高响应速度。
技术栈:SpringBoot + Spring + Mybatis + Mysql + Redis + SSE
完整项目及代码见gitee:https://gitee.com/Liguangyu1017/HTTP-download-server.git (项目已上线)
WebUI:
项目架构:
如何实现一个分片算法:
HTTP下载本质是发起一个GET的HTTP请求,在发起的GET请求中设置Range字段,比如:Range:bytes = 0 - 499表示请求文件的前 500 个字节。
- 确定分片策略:
本项目采用固定分片大小,即根据文件大小来决定分片数量。
根据文件大小,文件大小小于等于10MB的按照32KB,10MB~100MB按照1MB,超过100MB按照10MB进行分片。
// The shard size is determined by the file size private int determineChunkSize(long fileSize) { if (fileSize <= 10 * 1024 * 1024) { return urlConfig.getMinChunkSize(); } else if (fileSize <= 100 * 1024 * 1024) { return urlConfig.getMidChunkSize(); } else { return urlConfig.getMaxChunkSize(); } } - 计算分片大小和数量,确定分片范围:
获取分片大小后,计算出分片数量 = 文件大小 / 分片大小 (向上取整)
确定分片范围: 每个分片的起始位置为片索引乘以分片大小,结束位置为当前分片的起始 位置+分片大小 - 1;但在最后一个分片时,结束位置是分片大小 - 1。
// Calculate the size of each shard long chunkSize = determineChunkSize(fileSize); // Number of shards = File size/shard size (rounded up) long chunkNum = (long)Math.ceil((double) fileSize / (double) chunkSize); - 提交分片给下载线程池执行下载:
// Submit the download task to the thread pool for (int i = 0; i < chunkNum; i++) { // Gets the number of bytes downloaded by the current shard long downloadedBytesOneChunk = chunkDownloadBytes[i]; // sp indicates the start location of fragment download sp[i] = chunkSize * i; // ep indicates the end location of fragment download ep[i] = (i < chunkNum - 1) ? (sp[i] + chunkSize) - 1 : fileSize - 1; chunkDownloadBytesShould[i] = ep[i] - sp[i] + 1; // LOG.info("正在下载:" + sp[i] + " -> " + ep[i]); // Start the thread pool to perform the fragment download executor.submit(new Download(urlString, outputFile.getPath(), sp[i], ep[i],totalDownloadedBytesMap.get(taskDO.getId()), downloadedBytesOneChunk,i,rateLimiter,taskDO.getId(),redisService)); }
补充:
一个下载任务对应一个redis记分牌(用于标记每个分片是否下载完成,true/false,初始化每个分片全为false),下载过程中会不断更新记分牌,每个分片下载完成后,这个分片就被标记为true,这样暂停下载任务后再次开启下载时就可以跳过已经下载好的分片,从而实现断点续传。
根据任务id初始化redis记分牌:
@Override
public void initializeScoreboard(String taskId,long chunkNum){
Map<String,Boolean> scoreboard=new HashMap<>();
for (long i = 0;i < chunkNum; i++){
scoreboard.put(String.valueOf(i),false);
}
redisTemplate.opsForHash().put(KEY_CHUNK_HASHMAP,taskId,scoreboard);
}根据任务id更新redis记分牌:
@Override
public void updateScoreboard(String taskId, long chunkId) {
Map<String,Boolean> scoreboard=(Map) redisTemplate.opsForHash().get(KEY_CHUNK_HASHMAP,taskId);
scoreboard.put(String.valueOf(chunkId),true);
redisTemplate.opsForHash().put(KEY_CHUNK_HASHMAP,taskId,scoreboard);
}注意事项:
每个分片下载完成之后,存储到分片的起始位置中,这个过程由于文件句柄只有一个,需要加锁(synchronized)后进行seek,保证存储位置的准确性。
HttpURLConnection connection;
// Establish a connection to the download address and set the download range
connection = (HttpURLConnection) new URL(fileURL).openConnection();
// Configure the range
String byteRange = sp + "-" + ep;
connection.setRequestProperty("Range", "bytes=" + byteRange);
// Create an input stream
BufferedInputStream in = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(new File(outputFile), "rw");
synchronized (lock) {
try {
raf.seek(sp);
}catch (IOException e) {
LOG.error("outputFile定位开始下载位置时出现错误");
e.printStackTrace();
}
}分片下载的完整代码如下:
package cn.ykd.actualproject.service.impl;
import cn.ykd.actualproject.config.UrlConfig;
import cn.ykd.actualproject.dao.SettingsDAO;
import cn.ykd.actualproject.dao.TaskDAO;
import cn.ykd.actualproject.dataobject.TaskDO;
import cn.ykd.actualproject.model.Settings;
import cn.ykd.actualproject.service.RedisService;
import cn.ykd.actualproject.service.TaskManagerService;
import cn.ykd.actualproject.service.DownloadService;
import cn.ykd.actualproject.utils.SharedVariables;
import com.google.common.util.concurrent.RateLimiter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.atomic.AtomicLong;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Service
public class DownloadServiceImpl implements DownloadService {
@Autowired
private TaskManagerService taskManagerService;
@Autowired
private RedisService redisService;
@Autowired
private SettingsDAO settingsDAO;
@Autowired
private UrlConfig urlConfig;
@Autowired
private TaskDAO taskDAO;
private static final Logger LOG= LoggerFactory.getLogger(DownloadServiceImpl.class);
// Secure parallel downloads
private static final ConcurrentHashMap<String,AtomicLong> totalDownloadedBytesMap = new ConcurrentHashMap<>();
private static final Object lock = new Object(); // Synchronous lock
private static long[] chunkDownloadBytes; // Used to record the number of bytes downloaded per shard
private static long[] chunkDownloadBytesShould; // Used to record the number of bytes that each shard should download
@Override
public boolean download(TaskDO taskDO) {
// Obtain and process raw data
int threadNum = taskDO.getThreads();
String urlString = taskDO.getUrl(); // Get the download address
Settings settings = settingsDAO.get().convertToModel(); // Obtain the setting information
double maxDownloadSpeedMBps = settings.getMaxDownloadSpeed(); // Get the maximum download speed
if (maxDownloadSpeedMBps<=0) maxDownloadSpeedMBps=100;
String savePath = settings.getDownloadPath(); // Obtain the download save path
String fileName = taskDO.getName(); // Extract the file name from the download address
RateLimiter rateLimiter = RateLimiter.create(maxDownloadSpeedMBps*1024*1024); // One token corresponds to one byte of data
AtomicLong totalDownloadedBytes = new AtomicLong(0); // Used to record the number of bytes downloaded by all threads
totalDownloadedBytesMap.put(taskDO.getId(),totalDownloadedBytes);
try {
// Establish a connection to the download address and get the file size
URL url = new URL(urlString);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// Get the binary data length of the file
long fileSize = connection.getContentLength();
// Calculate file size (Mb)
double size = (double)fileSize/1024/1024;
taskDO.setPath(settings.getDownloadPath());
taskDO.setSize(String.format("%.2f",size) + " MB");
taskDO.setStatus("Downloading");
taskDAO.update(taskDO);
// Create an output stream of the downloaded file
File outputFile = new File(savePath, fileName);
// Create a thread pool for multithreaded sharding downloads
ExecutorService executor = Executors.newFixedThreadPool(threadNum);
// Calculate the size of each shard
long chunkSize = determineChunkSize(fileSize);
// Number of shards = File size/shard size (rounded up)
long chunkNum = (long)Math.ceil((double) fileSize / (double) chunkSize);
String msg = "fileSize = " + fileSize + ",chunkSize = " + chunkSize + ",chunkNum = " + chunkNum;
LOG.info(msg);
// Record the download start time
long startTime = System.currentTimeMillis();
// Record the downloads of each shard
chunkDownloadBytes = new long[(int) chunkNum];
chunkDownloadBytesShould = new long[(int) chunkNum];
// Initialize the state of each shard (True: shards are downloaded False: shards are not downloaded)
redisService.initializeScoreboard(taskDO.getId(),chunkNum);
// Initializes the sp and ep
long[] sp = new long[(int) chunkNum];
long[] ep = new long[(int) chunkNum];
// Submit the download task to the thread pool
for (int i = 0; i < chunkNum; i++) {
// Gets the number of bytes downloaded by the current shard
long downloadedBytesOneChunk = chunkDownloadBytes[i];
// sp indicates the start location of fragment download
sp[i] = chunkSize * i;
// ep indicates the end location of fragment download
ep[i] = (i < chunkNum - 1) ? (sp[i] + chunkSize) - 1 : fileSize - 1;
chunkDownloadBytesShould[i] = ep[i] - sp[i] + 1;
// LOG.info("正在下载:" + sp[i] + " -> " + ep[i]);
// Start the thread pool to perform the fragment download
executor.submit(new Download(urlString, outputFile.getPath(), sp[i], ep[i],totalDownloadedBytesMap.get(taskDO.getId()),
downloadedBytesOneChunk,i,rateLimiter,taskDO.getId(),redisService));
}
// Call task management module to synchronize database and sse in real time
taskManagerService.updateDownloadStatus(executor,totalDownloadedBytesMap.get(taskDO.getId()),fileSize,
taskDO,startTime,outputFile,
chunkNum,chunkSize,chunkDownloadBytes,chunkDownloadBytesShould,rateLimiter,sp,ep);
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
// Inner classes are used to implement the download function
static class Download implements Runnable {
private String fileURL; // File url
private String outputFile; // Output stream file
private long sp; // Download start location
private long ep; // Download end location
private AtomicLong totalDownloadedBytes; // Records the number of bytes downloaded
private long downloadedBytes; // Records the number of bytes actually downloaded by the current fragment
private int chunkId; // Fragment id
private RateLimiter rateLimiter; // Governor
private String taskId; // Task Id
private RedisService redisService; // redis service
public Download(String fileURL, String outputFile, long sp,long ep, AtomicLong totalDownloadedBytes,
long downloadedBytes,int chunkId,RateLimiter rateLimiter,String taskId,RedisService redisService) {
this.fileURL = fileURL;
this.outputFile = outputFile;
this.sp = sp;
this.ep = ep;
this.totalDownloadedBytes = totalDownloadedBytes;
this.downloadedBytes = downloadedBytes;
this.chunkId = chunkId;
this.rateLimiter = rateLimiter;
this.taskId= taskId;
this.redisService = redisService;
}
@Override
public void run() {
try {
// Establish a connection to the download address and set the download range
HttpURLConnection connection = (HttpURLConnection) new URL(fileURL).openConnection();
// Configure the range
String byteRange = sp + "-" + ep;
connection.setRequestProperty("Range", "bytes=" + byteRange);
// Create an input stream
BufferedInputStream in = new BufferedInputStream(connection.getInputStream());
// Create an output stream
RandomAccessFile raf = new RandomAccessFile(new File(outputFile), "rw");
synchronized (lock) {
try {
raf.seek(sp);
}catch (IOException e) {
LOG.error("outputFile定位开始下载位置时出现错误");
e.printStackTrace();
}
}
// Number of bytes actually read
int bytesRead;
// Read 1024 bytes of cache
byte[] buffer = new byte[1024];
// Start writing to the file
while ((bytesRead = in.read(buffer)) != -1) {
synchronized (lock) {
// Check whether the task is suspended
if (SharedVariables.getIsPaused()) {
raf.close();
in.close();
break;
}
rateLimiter.acquire(bytesRead);
raf.write(buffer, 0, bytesRead);
downloadedBytes += bytesRead;
chunkDownloadBytes[chunkId] = downloadedBytes;
// Update the scoreboard if the current shard is downloaded
if (chunkDownloadBytes[chunkId] == chunkDownloadBytesShould[chunkId]) {
redisService.updateScoreboard(taskId, chunkId);
}
totalDownloadedBytes.addAndGet(bytesRead);// Updates the number of downloaded bytes stored in the atomic class
}
}
raf.close();
in.close();
connection.disconnect();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// The shard size is determined by the file size
private int determineChunkSize(long fileSize) {
if (fileSize <= 10 * 1024 * 1024) {
return urlConfig.getMinChunkSize();
} else if (fileSize <= 100 * 1024 * 1024) {
return urlConfig.getMidChunkSize();
} else {
return urlConfig.getMaxChunkSize();
}
}
}
如何实现断点续传:
什么是断点续传:
断点续传是一种网络传输技术,允许在文件下载或上传过程中,当传输中断或失败时,能够从断点处恢复传输,而不是重新开始传输整个文件。
优点:
- 节省带宽和时间:断点续传允许在传输中断或失败时恢复传输,避免重新下载整个文件,节省了带宽和时间。
- 提高用户体验:用户无需重新开始下载,可以在中断的地方恢复下载,提高了用户体验和满意度。
适用场景:
- 大文件下载:对于大文件下载,断点续传能够有效减少下载时间和带宽消耗。
- 不稳定的网络环境:在网络连接不稳定的情况下,比如下载过程中网络中断,当恢复网络时不需要从头开始下载,直接从上次下载中断处开始,断点续传能够保证下载的可靠性和稳定性。
具体实现:
上文中已经提到了redis记分牌,每个任务所对应的每个分片都存储在redis中,在下载过程中不断更新记分牌,当一个分片下载完成时,将其标记为true。
当一个下载任务被终止,此时redis已经记录了该任务每个分片的下载情况,如果要恢复下载,只需读取未下载完的分片(false),确定范围(start_position和end_position),重新提交给线程池执行下载即可。
根据任务id获取记分牌:
@Override
public List<Long> getScoreboard(String taskId){
List<Long> chunkIds=new ArrayList<>();
Map<String,Boolean> scoreboard=(Map) redisTemplate.opsForHash().get(KEY_CHUNK_HASHMAP,taskId);
scoreboard.forEach((key,value)->{
if (!value){
chunkIds.add(Long.valueOf(key));
}
});
return chunkIds;
}确定范围,然后提交重新提交给线程池下载:
LOG.info("正在执行恢复下载操作");
// Obtain the id of the unfinished fragment
List<Long> unDownloadedChunkId = redisService.getScoreboard(taskDO.getId());
// Submit the unfinished shard to the thread pool
for (int i = 0;i < unDownloadedChunkId.size(); i++) {
// Get the index and ensure a one-to-one correspondence
int index = Math.toIntExact(unDownloadedChunkId.get(i));
long downloadedBytesOneChunk = chunkDownloadBytes[index];
// Obtain the sp and ep of the remaining fragments
long resumeSp = sp[index] + chunkDownloadBytes[index];
long resumeEp = ep[index];
// LOG.info("剩余的第" + index + "个分片正在下载" + resumeSp + "->" + resumeEp);
newExecutor.submit(new DownloadServiceImpl.Download(urlString,outputFile.getPath(),resumeSp,
resumeEp,totalDownloadedBytes,
downloadedBytesOneChunk,index,rateLimiter,taskDO.getId(),redisService));
如何实现限速:
本项目通过使用RateLimiter工具实现限速下载功能。
工作原理:
RateLimiter基于令牌桶算法(Token Bucket)实现。它维护了一个稳定的速率(rate),以及一个令牌桶,令牌桶中的令牌数量代表了当前可用的请求次数。当有请求到来时,RateLimiter会根据当前的令牌桶状态来决定是否立即执行请求,或者需要等待一段时间后再执行。
<!-- Guava限流 --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>18.0</version> </dependency>
具体实现:
- 创建RateLimiter对象:通过RateLimiter类的静态工厂方法来创建RateLimiter对象,传入一个速率参数(这里限速的单位是MB/s)。
RateLimiter rateLimiter = RateLimiter.create(maxDownloadSpeedMBps*1024*1024); // One token corresponds to one byte of data- 请求令牌:调用RateLimiter的acquire(bytesRead)方法来请求bytesRead个令牌,该方法会阻塞当前线程直到获取到令牌为止。
// Number of bytes actually read
int bytesRead;
// Read 1024 bytes of cache
byte[] buffer = new byte[1024];
// Start writing to the file
while ((bytesRead = in.read(buffer)) != -1) {
synchronized (lock) {
// Check whether the task is suspended
if (SharedVariables.getIsPaused()) {
raf.close();
in.close();
break;
}
rateLimiter.acquire(bytesRead);
raf.write(buffer, 0, bytesRead);
downloadedBytes += bytesRead;
chunkDownloadBytes[chunkId] = downloadedBytes;
// Update the scoreboard if the current shard is downloaded
if (chunkDownloadBytes[chunkId] == chunkDownloadBytesShould[chunkId]) {
redisService.updateScoreboard(taskId, chunkId);
}
totalDownloadedBytes.addAndGet(bytesRead);// Updates the number of downloaded bytes stored in the atomic class
}
}
如何定时获取任务的状态、下载速度、剩余时间、下载进程以及对用户操作(暂停、删除、重新下载)进行处理:
可以创建一个单线程用于定时(500ms)获取任务的信息,并同时将数据传给数据库和前端。
这里特别讲一下暂停操作:
当后端接受到pause参数时,首先会关闭文件的输入流和输出流,即:
if (SharedVariables.getIsPaused()) { raf.close(); in.close(); break; }然后会关闭下载线程池:
// Pause download private void pauseDownload(ExecutorService executor) { SharedVariables.setIsPaused(true); // If downloading for the first time executor.shutdownNow(); // Until the download thread closes while (!executor.isTerminated()) { try { Thread.sleep(200); } catch (InterruptedException e) { throw new RuntimeException(e); } } LOG.info("任务已暂停"); // Reset is Pause SharedVariables.setIsPaused(false); }接下来会一直阻塞更新任务状态的线程,直到有新的任务状态(删除、重新下载、恢复下载)被获取到:
while (status == null) { try { Thread.sleep(500); status = redisSubscribersTaskOptions.getOptionsForId(taskDO.getId()); } catch (InterruptedException | NullPointerException e) { throw new RuntimeException(e); } LOG.info("暂停下载任务,线程阻塞中"); }
完整代码如下:
package cn.ykd.actualproject.service.impl;
import cn.ykd.actualproject.dao.TaskDAO;
import cn.ykd.actualproject.dataobject.TaskDO;
import cn.ykd.actualproject.service.DownloadService;
import cn.ykd.actualproject.service.RedisService;
import cn.ykd.actualproject.service.TaskManagerService;
import cn.ykd.actualproject.utils.SharedVariables;
import com.google.common.util.concurrent.RateLimiter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.io.File;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.atomic.AtomicLong;
@Service
public class TaskManagerServiceImpl implements TaskManagerService {
@Autowired
private TaskDAO taskDAO;
@Autowired
private RedisSubscribersTaskOptions redisSubscribersTaskOptions;
@Autowired
private DownloadService downloadService;
@Autowired
private RedisService redisService;
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedisSubscribersThreads redisSubscribersThreads;
private static final String KEY_MESSAGE_PARALLEL_DOWNLOAD = "DOWNLOAD_THREAD_QUEUE";
private static final String KEY_CHUNK_HASHMAP = "CHUNK_HASHMAP";
private static final Logger LOG= LoggerFactory.getLogger(TaskManagerServiceImpl.class);
@Override
public void updateDownloadStatus(ExecutorService executor, AtomicLong totalDownloadedBytes, long fileSize,
TaskDO taskDO, long startTime, File outputFile,long chunkNum,long chunkSize,
long[] chunkDownloadBytes,long[] chunkDownloadBytesShould,RateLimiter rateLimiter,
long[] sp,long[] ep) {
ExecutorService statusUpdater = Executors.newSingleThreadExecutor();
ExecutorService newExecutor = Executors.newFixedThreadPool(taskDO.getThreads());
String urlString = taskDO.getUrl();
statusUpdater.submit(() -> {
while (true) {
long downloadedBytes = totalDownloadedBytes.get();
long currentTime = System.currentTimeMillis();
long elapsedTime = currentTime - startTime;
double downloadSpeedMBps = (downloadedBytes / 1024.0 / 1024.0) / (elapsedTime / 1000.0);
int remainingTimeSeconds = (int) (((fileSize - downloadedBytes) / 1024.0 / 1024.0) / downloadSpeedMBps);
int progressPercent = (int) ((downloadedBytes / (fileSize * 1.0)) * 100);
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
threadPoolExecutor.setMaximumPoolSize(10);
Integer threadNum = redisSubscribersThreads.getThreadsForId(taskDO.getId());
if (threadNum != null) {
threadPoolExecutor.setCorePoolSize(threadNum); // Dynamically resize thread pools
}
String msg = "id = " + taskDO.getId() + ",剩余时间 = " + remainingTimeSeconds + "s," +
"下载速度 = " + String.format("%.2f",downloadSpeedMBps) + "MB/s,下载进度 = " + progressPercent;
LOG.info(msg);
// Download speed is converted to a string
String downloadSpeedStr = String.format("%.2f MB/s", downloadSpeedMBps);
// Update database and synchronize sse
int isUpdate = taskDAO.updateDownloadProgress(taskDO.getId(), downloadSpeedStr, remainingTimeSeconds,
progressPercent);
/*
Delete: The update fails, that is, isUpdate == 0 is triggered
step1: Close all download threads
step2: Delete the local file
*/
if (isUpdate == 0) {
LOG.info("正在执行删除任务操作");
pauseDownload(executor);
deleteFile(outputFile);
deleteRedisInfo(taskDO);
statusUpdater.shutdown();
break;
}
// Get task status
String status = redisSubscribersTaskOptions.getOptionsForId(taskDO.getId());
/**
* PAUSE download: Triggered when the task obtained from redis is in Pause state
* step1: Close all download threads
* step2: Update the scoreboard
*/
if (status != null && status.equals("Pause")) {
LOG.info("正在执行暂停下载操作");
pauseDownload(executor);
status = null;
// Do not exit the loop until the task state changes
while (status == null) {
try {
Thread.sleep(500);
status = redisSubscribersTaskOptions.getOptionsForId(taskDO.getId());
} catch (InterruptedException | NullPointerException e) {
throw new RuntimeException(e);
}
LOG.info("暂停下载任务,线程阻塞中");
}
// After a task is suspended, you can delete it, resume downloading it, and download it again
if (status.equals("Delete")) {
LOG.info("正在执行删除任务操作");
deleteFile(outputFile);
deleteRedisInfo(taskDO);
statusUpdater.shutdown();
break;
}else if (status.equals("Resume")) {
/*
RESUME download: triggered when the status of the task obtained from redis is Resume
Step p1: Obtain the undownloaded fragment Id from redis
step2: Enumerate all ids in step1, and recalculate sp and ep.(sp = original sp + number of
bytes downloaded before the current fragment is paused, ep remains unchanged)
step3: Submit to the download thread pool and recurse the updateDownloadStatus method
*/
LOG.info("正在执行恢复下载操作");
// Obtain the id of the unfinished fragment
List<Long> unDownloadedChunkId = redisService.getScoreboard(taskDO.getId());
// Submit the unfinished shard to the thread pool
for (int i = 0;i < unDownloadedChunkId.size(); i++) {
// Get the index and ensure a one-to-one correspondence
int index = Math.toIntExact(unDownloadedChunkId.get(i));
long downloadedBytesOneChunk = chunkDownloadBytes[index];
// Obtain the sp and ep of the remaining fragments
long resumeSp = sp[index] + chunkDownloadBytes[index];
long resumeEp = ep[index];
// LOG.info("剩余的第" + index + "个分片正在下载" + resumeSp + "->" + resumeEp);
newExecutor.submit(new DownloadServiceImpl.Download(urlString,outputFile.getPath(),resumeSp,
resumeEp,totalDownloadedBytes,
downloadedBytesOneChunk,index,rateLimiter,taskDO.getId(),redisService));
}
// Get the real-time status of the task
updateDownloadStatus(newExecutor,totalDownloadedBytes,fileSize,taskDO,startTime,outputFile,
chunkNum,chunkSize,chunkDownloadBytes,chunkDownloadBytesShould,rateLimiter,sp,ep);
statusUpdater.shutdown();
break;
}else {
refreshDownload(taskDO,executor,statusUpdater,outputFile);
break;
}
}
/**
* Re-download: triggered when the task status obtained from redis is REFRESH
* step1: Close all download threads
* step2: Delete the local file
* step3: Recursive download method
*/
if (status != null && status.equals("Refresh")) {
// Pause download
SharedVariables.setIsPaused(true);
executor.shutdownNow();
while (!executor.isTerminated()) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
// reDownload
refreshDownload(taskDO,executor,statusUpdater,outputFile);
break;
}
// File download complete
if (downloadedBytes == fileSize) {
deleteRedisInfo(taskDO);
LOG.info("文件下载完成. 文件保存为: " + outputFile.getAbsolutePath());
totalDownloadedBytes.set(0);
// Close the fragment download thread pool
executor.shutdown();
// Close the update status thread pool
statusUpdater.shutdown();
LOG.info("所有线程关闭");
break;
}
try {
Thread.sleep(500); // Update every 1 second
} catch (InterruptedException e) {
LOG.info(Thread.currentThread().getName()+"被中断了");
}
}
});
}
// Delete redis information
private void deleteRedisInfo(TaskDO taskDO) {
// Delete task status
if (redisTemplate.opsForHash().delete(RedisProducer.OPTIONS_KEY,taskDO.getId())!=0L){
LOG.info(taskDO.getId()+"任务状态已删除");
}
// Delete thread instance
if(redisTemplate.opsForHash().delete(KEY_MESSAGE_PARALLEL_DOWNLOAD, taskDO.getId())!=0L){
LOG.info(taskDO.getId()+"并行线程已删除");
}
// Delete the task scoreboard
if(redisTemplate.opsForHash().delete(KEY_CHUNK_HASHMAP,taskDO.getId())!=0L){
LOG.info(taskDO.getId()+"任务记分牌已删除");
}
}
// Pause download
private void pauseDownload(ExecutorService executor) {
SharedVariables.setIsPaused(true);
// If downloading for the first time
executor.shutdownNow();
// Until the download thread closes
while (!executor.isTerminated()) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
LOG.info("任务已暂停");
// Reset is Pause
SharedVariables.setIsPaused(false);
}
// reDownload
private void refreshDownload(TaskDO taskDO,ExecutorService executor,ExecutorService statusUpdater,File outputFile) {
LOG.info("正在执行重新下载操作");
LOG.info("线程关闭中");
if (executor.isTerminated()) {
LOG.info("所有线程已关闭");
deleteFile(outputFile);
SharedVariables.setIsPaused(false);
}
downloadService.download(taskDO);
statusUpdater.shutdown();
}
// Delete temporary files
private void deleteFile(File outputFile) {
if (outputFile.delete()) {
LOG.info("文件已删除");
}else {
LOG.info("文件删除失败,请手动删除");
}
}
}
以上是对java实现分片下载、断点续传、限速等功能具体实现的说明,如果有不足的地方欢迎指正!















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









