






看了好几个月的爬虫,今天终于进入实战:爬一本小说练练手。备忘吧。
第一次爬,要找一个‘简单点’的网站,否则爬不下来,比较打击信心。
第一项技能:requests.get
headers:从网页响应头里copy

注意:get的网页内容,一定要print出来和人家原版的内容比对一下,尤其是小说正文内容缺不缺。
第一次get、print出来,眼前闪现一片,特激动,根本就没认真对比,其实根本没有小说正文。
各种骚操作后,啥也没有,沮丧了好久,觉得自己不行啊。这点自信很久才找回来。
所以,第一次弄,找个简单点的网站,切记,切记。
第二项技能:搞定乱码
先找小说目录页。里面有各章节链接。get下来的网页全部是乱码,急啊。
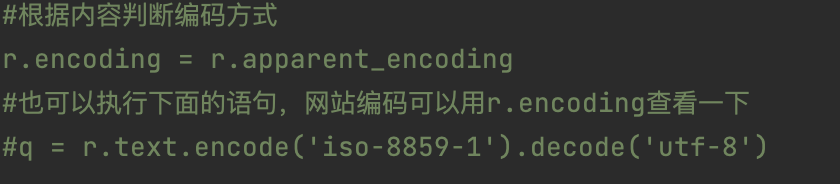
备注:从网上找了很多方法,有的管用,有的很拉胯。这两个最有效,尤其第一个,那叫一个爽。
第三项技能:内容提取
无论是目录页,还是各章节内容,都需要把想要的内容,在一大堆网页代码中抽离出来
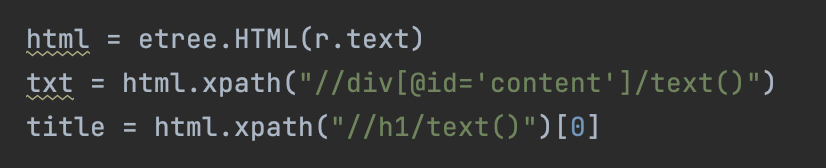

备注:xpath吧。符合我的个性。
'//' :全文搜索
'@' :后面是标签或属性值
'text()' :标签的内容
'dt' 里面的'contanins' :表示匹配的内容是后面的字符串
'following' :很管用。表示后面同级的所有标签。目录页最前面是最新章节链接,咱们不需要。通过dt匹配,再加上这个,就把从第一章的所有章节链接都弄下来了。
'@href' :a标签的值,就是章节的链接。
第四项技能:保存小说
找到各章节链接后,把链接和网站名组合一下,再一个个get,下载各章节,再用xpath解析小说内容。
写入文件就可以了。这块没遇到什么坑,就不记录了。

第五项技能:断点续传
利用excel,拿到各章节链接后,保存到excel中。用循环。
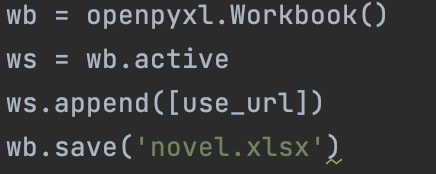
#读取excel中的第一行。
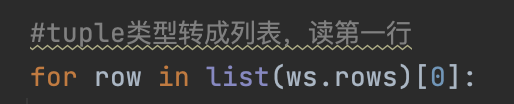
#下载完成后,再删掉这一行。

以后再用数据库试一试
第六项技能:selenium
针对'复杂的'网站,其实也挺简单的。
# 隐藏浏览器窗口
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')# 实例化webdriver
browser = webdriver.Chrome(options=chrome_options)#打开浏览器,访问网页
browser.get(url)#提取小说章节名称
title = browser.find_element(By.TAG_NAME,'h1').text#通过class属性值定位小说内容
content = browser.find_element(By.CLASS_NAME,'showtxt').text为了这么几行代码,折腾了很久。网上东西虽然多,但想要找到你需要的,真真不容易。蓦然回首,那几行代码竟在灯火阑珊处。

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









