









文本解码原理--以MindNLP为例
回顾:自回归语言模型
根据前文预测下一个单词
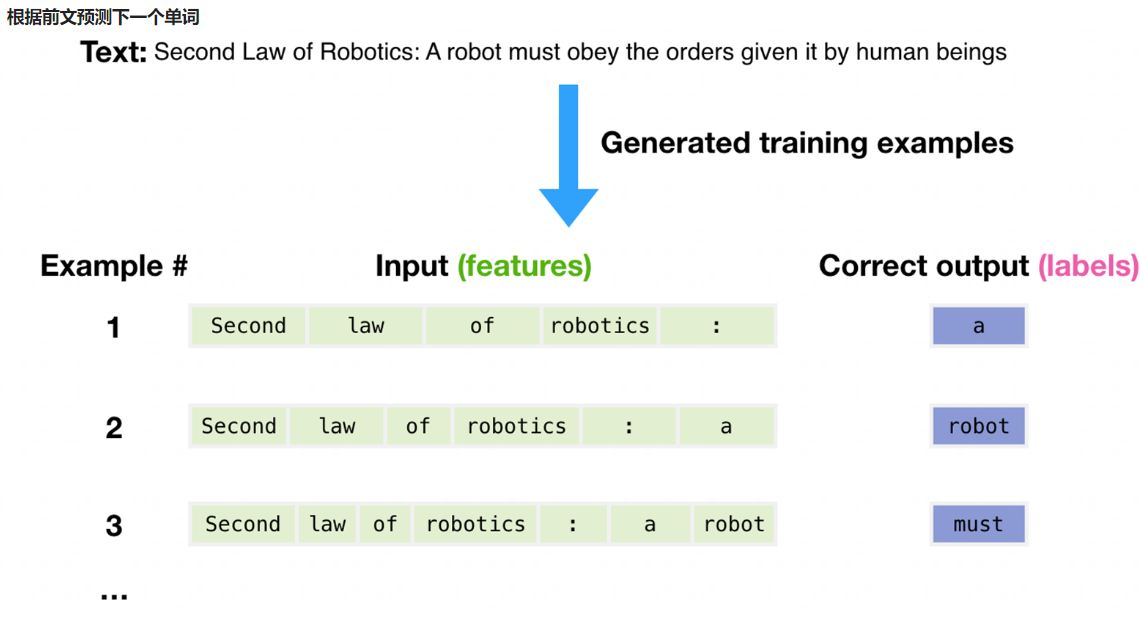
一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积

- 𝑊_0:初始上下文单词序列
- 𝑇: 时间步
- 当生成EOS标签时,停止生成。
MindNLP/huggingface Transformers提供的文本生成方法
Greedy search
在每个时间步𝑡都简单地选择概率最高的词作为当前输出词:
𝑤𝑡=𝑎𝑟𝑔𝑚𝑎𝑥_𝑤 𝑃(𝑤|𝑤(1:𝑡−1))
按照贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 x 0.4 = 0.2
缺点: 错过了隐藏在低概率词后面的高概率词,如:dog=0.5, has=0.9 
Beam search
Beam search通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。如图以 num_beams=2 为例:
("The","dog","has") : 0.4 * 0.9 = 0.36
("The","nice","woman") : 0.5 * 0.4 = 0.20
优点:一定程度保留最优路径
缺点:1. 无法解决重复问题;2. 开放域生成效果差

Sample
根据当前条件概率分布随机选择输出词𝑤_𝑡

("car") ~P(w∣"The") ("drives") ~P(w∣"The","car") 
优点:文本生成多样性高
缺点:生成文本不连续
Temperature 降低softmax 的temperature使 P(w∣w1:t−1)分布更陡峭

TopK sample
选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词中采样
TopK sample problems
将采样池限制为固定大小 K :
- 在分布比较尖锐的时候产生胡言乱语
- 在分布比较平坦的时候限制模型的创造力
Top-P sample
在累积概率超过概率 p 的最小单词集中进行采样,重新归一化

采样池可以根据下一个词的概率分布动态增加和减少
代码实例
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Beam search with ngram, Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("return_num_sequences, Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
print(100 * '-')
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=5,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))运行代码



学习小结:
文本解码通常指的是将编码后的文本信息还原为原始可读形式的过程。这个过程在计算机科学和信息处理中非常重要,因为数据在存储和传输过程中往往需要进行编码以节省空间或保证数据的完整性。以下是一些常见的文本编码和解码原理:
ASCII编码:这是最早的字符编码标准之一,使用7位二进制数表示128个字符,包括英文字母、数字和一些特殊符号。
Unicode编码:为了解决ASCII编码无法表示世界上所有语言字符的问题,Unicode提供了一个更广泛的字符集。Unicode可以采用多种编码形式,如UTF-8、UTF-16等。
UTF-8编码:这是一种变长编码方式,使用1到4个字节来表示一个字符。它与ASCII编码兼容,并且可以表示世界上几乎所有语言的字符。
Base64编码:这是一种用于在网络上安全传输二进制数据的编码方式。它将二进制数据转换成64个可打印的ASCII字符,以确保数据在传输过程中不会因为非打印字符而损坏。
URL编码:也称为百分比编码,用于确保URL中的字符能够被正确解释。例如,空格会被编码为
%20。HTML实体编码:在HTML中,某些字符具有特殊含义,如
<和>。为了在网页中显示这些字符,可以使用HTML实体编码,如<和>。压缩编码:如ZIP、GZIP等,这些编码方式不特定于文本,但可以用于压缩文本文件以节省存储空间和加快传输速度。
加密编码:如AES、RSA等,这些编码方式用于保护数据的安全性,防止未授权访问。
解码过程通常与编码过程相反,需要根据所使用的编码方式将数据转换回原始形式。例如,如果文本使用UTF-8编码,解码过程就是将UTF-8编码的字节序列转换回对应的字符。如果文本被Base64编码,解码过程就是将Base64编码的字符串转换回原始的二进制数据。















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









