






经典工作,第一次阅读。
Abstract
这篇论文介绍了Grounding DINO,这是一个开放集目标检测器,它把基于Transformer的检测器DINO和grounded预训练结合在一起。它可以根据人类的输入(比如类别名称或指代表达)来检测任意目标。关键的创新点是将语言引入到封闭集检测器中,以实现开放集概念的泛化。作者提出了一个紧密的融合解决方案,包括特征增强器、语言引导的查询选择和跨模态解码器。Grounding DINO在大规模数据集上进行预训练,并在开放集目标检测和指称目标检测基准上进行评估。
知识点:checkpoints
指的是模型训练过程中的中间状态。具体来说,它包含了模型的参数、优化器的状态以及训练的进度信息。这些检查点通常在训练过程中定期保存,以便在需要时可以恢复训练,或者用于模型的评估和推理。用户可以直接下载并使用这些模型进行目标检测任务,而无需从头开始训练模型。
1 Introduction
-
开放世界目标检测(Open-Set Object Detection):这是一个任务,旨在检测由人类语言输入指定的任意目标。这种任务非常有用,因为它可以作为一个通用的目标检测器,例如与生成模型合作进行图像编辑。
-
基于DINO的紧密模态融合:开放集检测的关键是引入语言来泛化未见过的目标。大多数现有的开放集检测器是通过将封闭集检测器扩展到开放集场景,并结合语言信息来开发的。
-
Backbone(主干网络):用于特征提取,例如ResNet、Swin等。
-
Neck(颈部网络):用于特征增强,例如DyHead、Encoder等。
-
Head(头部网络):用于区域细化(或框预测),例如ROIHead、Decoder等。
-
-
从封闭集到开放集的扩展
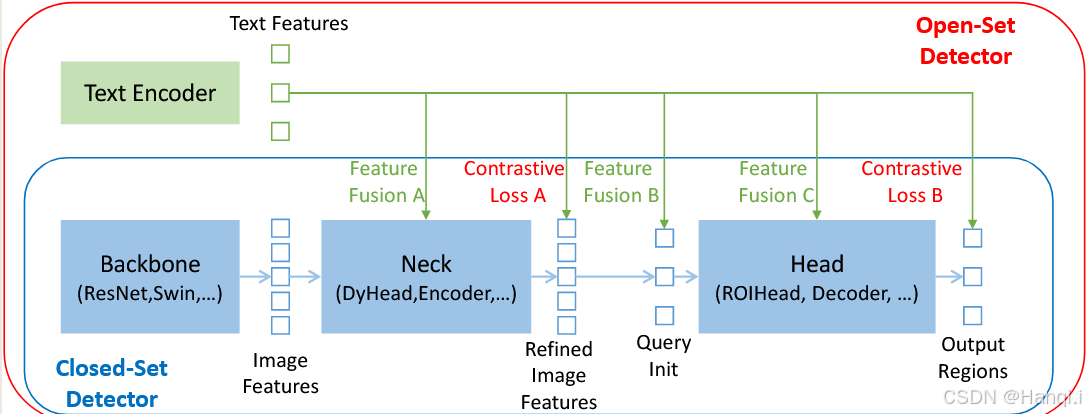 特征融合的三个阶段:
特征融合的三个阶段:-
Head(阶段C):在头部网络中进行特征融合。
-
Query Initialization(阶段B):在查询初始化阶段进行特征融合。
-
Neck(阶段A):在颈部网络中进行特征融合。
-
示例:
-
GLIP:在颈部网络(阶段A)进行早期融合。
-
OV-DETR:使用语言感知查询作为头部输入(阶段B)。
-
-
-
大规模预训练以实现零样本迁移
Grounding DINO在大规模数据集上进行预训练,并在主流的目标检测基准(如COCO)上评估性能。作者倡导完全零样本的方法,以增强实际应用性
Grounding DINO采用了并改进了GLIP的预训练方法。GLIP的方法是将所有类别以随机顺序拼接成一个句子,但这种直接拼接类别名称的方法没有考虑到不相关类别在特征提取时的相互影响。为了解决这个问题,Grounding DINO引入了一种子句级别的文本特征技术,消除了不相关类别之间的注意力,从而在预训练过程中提高了模型性能。
知识点:GLIP
GLIP(Grounded Language-Image Pre-training)是一个将目标检测任务转换为短语定位任务的模型,通过联合训练图像encoder和语言encoder来预测区域和单词的正确配对,从而实现对图像中物体的精确定位和描述。它在零样本学习和小样本学习方面表现出色,能够识别训练数据中未包含的新类别,特别适合在数据有限的情况下进行目标检测。
举例:你有一张海滩的图片,你给GLIP的提示是“beach. ocean. palm tree.”,GLIP不仅能够识别出海滩、海洋和棕榈树这些具体的物体,还能理解它们之间的关系,比如“海滩上有棕榈树,旁边是海洋”。这就像是你告诉GLIP:“找找看,图片里有海滩、海洋和棕榈树。”GLIP就会在图片中找到这些元素,并且用框框标出来,甚至还能理解它们之间的关系。
文本编码器(Language Encoder)
功能:文本编码器负责处理输入的文本提示(如“Detect: person, bicycle, car, …, toothbrush”),并将其转换为数值特征向量。这些特征向量包含了文本的语义信息,用于与图像特征进行对齐。
实现:GLIP使用基于BERT的模块作为文本编码器。BERT是一种强大的语言模型,能够理解自然语言的语义和语法结构。文本编码器会将输入的文本提示编码成一系列的上下文token特征,这些特征将用于后续的融合过程。
图像编码器(Image Encoder)
功能:图像编码器负责从输入图像中提取视觉特征。这些特征描述了图像中不同区域的视觉信息,如颜色、纹理、形状等。
实现:GLIP通常使用Vision Transformer(ViT)或Swin Transformer作为图像编码器。这些基于Transformer的模型能够有效地捕捉图像中的全局和局部特征。图像编码器会将输入图像转换为一系列的视觉特征向量,这些向量将用于与文本特征进行对齐。
深度融合模块(Deep Fusion Module)
功能:深度融合模块负责将文本编码器和图像编码器提取的特征进行融合,以生成最终的特征表示。这些融合后的特征将用于计算图像区域和文本短语之间的对齐分数。
实现:GLIP在图像编码器和语言编码器之间引入了深度融合,具体来说,它在最后几层编码层中融合图像和文本信息。这种融合通过跨模态多头注意力机制(Cross-Modality Multi-Head Attention, X-MHA)实现,允许图像特征和文本特征在各自的上下文中进行注意力加权融合。
知识点:预训练
预训练阶段(Pre-training Stage)
定义:预训练阶段是指在大规模数据集上训练模型,以学习通用的特征表示。这些数据集通常是通用的、大规模的,并且与具体任务无关。
目的:预训练的目的是让模型学习到通用的、可迁移的知识,这些知识可以在后续的具体任务中发挥作用。通过预训练,模型可以学习到数据的底层结构和模式,从而在具体任务中更快地收敛和更好地泛化。
数据:预训练通常使用大规模的、通用的数据集,例如ImageNet(用于图像识别)、BookCorpus和Wikipedia(用于自然语言处理)。
模型:预训练的模型通常是基础模型(Foundation Model),例如ResNet、BERT、GPT等。这些模型在预训练阶段学习到的特征表示可以用于多种下游任务。
训练方式:预训练通常使用无监督学习或自监督学习,例如图像的自编码、文本的掩码预测等。
训练阶段(Training Stage,通常指的是微调阶段)
定义:训练阶段(微调阶段)是指在具体任务的数据集上训练预训练模型,以适应特定任务的需求。
目的:微调的目的是让模型在具体任务上达到更好的性能。通过在具体任务的数据集上继续训练,模型可以学习到与任务相关的特定特征和模式,从而提高在该任务上的准确性和泛化能力。
数据:微调通常使用与具体任务相关的数据集,例如COCO(用于目标检测)、SQuAD(用于问答)等。
模型:微调的模型通常是预训练模型的变体,例如在BERT的基础上添加特定任务的头部(Head)。
训练方式:微调通常使用有监督学习,例如分类、回归等。
举例
假设你有一个预训练的图像分类模型(如ResNet),它在ImageNet上进行了预训练,学习到了通用的图像特征。现在你想用这个模型来检测COCO数据集中的目标。
预训练阶段:模型在ImageNet上学习到了通用的图像特征,例如边缘、纹理、形状等。
微调阶段:你在COCO数据集上继续训练这个模型,使其学习到与目标检测相关的特定特征,例如不同目标的形状和位置。
通过预训练和微调,模型可以在COCO数据集上达到更好的目标检测性能,因为预训练提供了通用的特征表示,而微调则让模型适应了具体任务的需求。
2 Related Work
Detection Transformers
-
Grounding DINO基于DINO模型,而DINO是一种基于Transformer的端到端检测器。
-
DETR(DEetectron TRansformer)是最先提出的Transformer-based检测器,近年来在多个方面得到了改进,如DAB-DETR引入锚框进行更精确的框预测,DN-DETR提出了一种查询去噪的方法。
-
DINO进一步发展了一些技术,如对比去噪,并在COCO目标检测基准上创下了新记录。
-
然而,这些检测器主要专注于封闭集检测,并且由于预先定义的类别有限,很难推广到新的类别。
Open-Set Object Detection
-
开放集目标检测的训练使用现有的边界框注释,其目标是借助语言泛化来检测任意类别。
-
OV-DETR在DETR框架内以CLIP模型编码的图像和文本嵌入作为查询,用于解码类别特定的边界框。
-
ViLD将CLIP教师模型的知识提炼到一个类似R-CNN的检测器中,从而使学习到的区域嵌入包含语言语义。
-
GLIP将目标检测视为一种接地问题,并利用额外的接地数据来帮助学习短语和区域层面的对齐语义,并且在完全监督的检测基准上表现出色。
-
DetCLIP引入了大规模的图像标注数据集,并使用生成的伪标签来扩展知识数据库。这些生成的伪标签有效地帮助扩展了泛化能力。
3 Grounding DINO
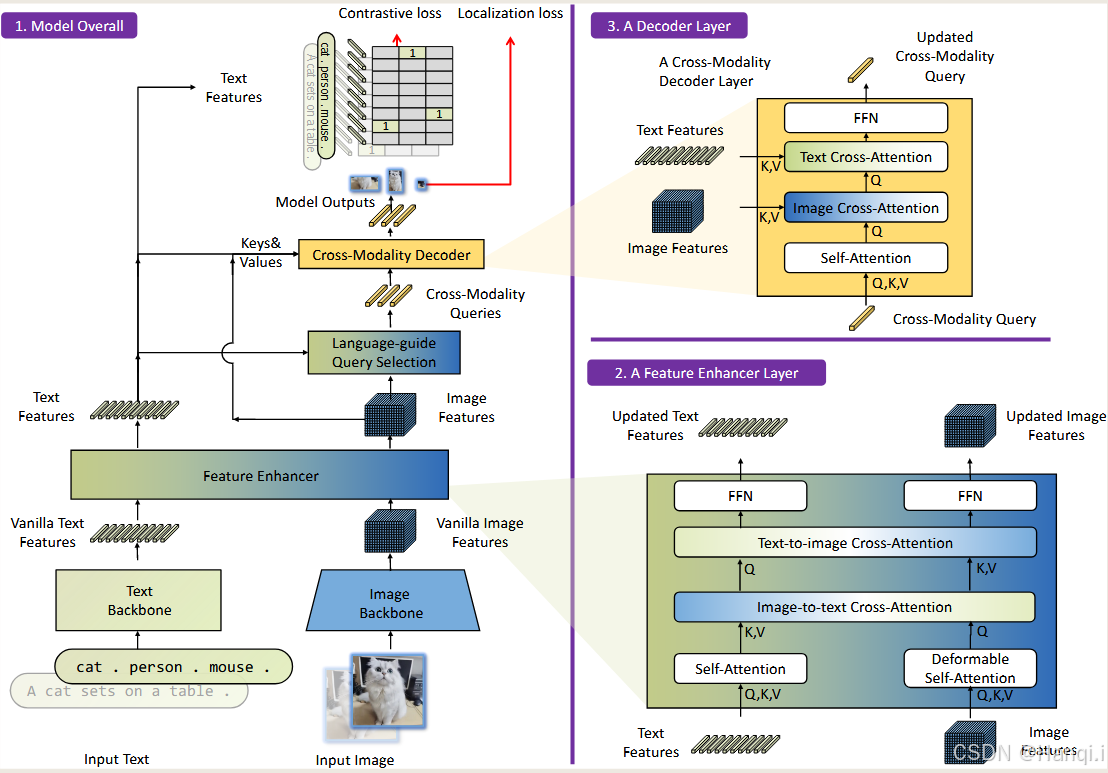
-
双编码器单解码器架构:Grounding DINO模型采用了双编码器单解码器的架构。它包含一个图像主干网,用于提取图像特征;一个文本主干网,用于提取文本特征;一个特征增强器,用于融合图像和文本特征;一个语言引导的查询选择模块,用于初始化查询;以及一个跨模态解码器,用于对边界框进行细化。
-
特征提取:对于给定的图像和文本对,首先使用图像主干网和文本主干网分别提取原始的图像特征和文本特征。这两个特征被输入到特征增强器模块中,进行跨模态特征融合。
-
特征融合:特征增强器模块负责将图像和文本的特征进行融合,生成跨模态的文本和图像特征。这个过程就像是将图像和文本的信息结合起来,让模型能够更好地理解它们之间的关系。
-
查询选择与初始化:语言引导的查询选择模块用于从图像特征中选择跨模态查询。这些查询类似于其他DETR类模型中的目标查询,将被输入到跨模态解码器中。
-
解码与预测:跨模态解码器对这些查询进行处理,从两个模态的特征中提取所需的特征,并更新查询。解码器的最后一层的输出查询将用于预测物体框,并提取相应的短语。
3.1 Feature Extraction and Enhancer
当给定一张图像和一段文本时,我们需要从图像和文本中提取特征。首先,我们使用像Swin Transformer这样的图像主干网来提取多尺度的图像特征。Swin Transformer可以捕捉图像中的不同尺寸和细节的信息,就像是一个“视觉大师”,能够从不同的角度观察图像,并提取出各个部分的特征。
然后,我们使用像BERT这样的文本主干网来提取文本特征。BERT是一个强大的语言模型,能够理解文本中的语义和上下文信息。它将文本中的每个单词转换为数值向量,这些向量包含了单词的意思和它在句子中的作用。这就像是一种“语言魔法”,能够将文本中的信息转化为计算机可以理解的形式。
接下来,我们将提取的图像特征和文本特征送入特征增强器中进行跨模态特征融合。特征增强器包括多个特征增强层,这些层可以进一步增强和融合图像和文本的特征。在这里,我们使用变形的自注意力机制来增强图像特征,并使用普通的自注意力机制来增强文本特征。自注意力机制可以让模型关注到图像或文本中最重要和最相关的部分。
受GLIP模型的启发,我们在特征增强器中添加了图像到文本和文本到图像的交叉注意力模块。这些模块可以帮助模型更好地对齐不同模态的特征,从而使模型能够更好地理解图像和文本之间的关系。这就像是一场对话,在这场对话中,图像和文本互相交流,彼此补充,最终形成了一个更全面的理解。
3.2 Language-Guided Query Selection
-
目标:有效利用输入文本(
Text)引导对象检测,从图像特征(Image Feature)中选择与输入文本更相关的特征作为解码器的查询(Queries)。 -
原理与算法:
-
查询选择公式:
-
利用输入图像和文本的特征计算相似性矩阵,通过以下步骤选择查询:
-
计算图像特征与文本特征的点积(
X_D X_T^T),得到一个相似性矩阵。 -
沿图像特征的维度(
-1维度)对相似性矩阵取最大值(Max(-1)),这一步是为了确定每个文本特征与图像特征中最相关的部分。 -
从这些最大值中选择前
N_q个(排名前N_q)的索引作为查询选择结果(TopN_q)。
-
-
-
输出:
-
从图像特征中提取
N_q个查询(N_q=900,与DINO方法一致),这些查询用于解码器的输入。
-
-
查询结构:
-
每个解码器查询由两部分组成:
-
内容部分(Content Part):在训练过程中具有可学习性。
-
位置部分(Positional Part):初始化为动态锚框,锚框的具体尺寸和位置由编码器的输出决定。
-
-
-
3.3 Cross-Modality Decoder
简单来说,跨模态解码器就是Grounding DINO用来把图像和文本这两种不同模态的信息结合起来的工具。就像一个小侦探,要从图像和文本两个地方寻找线索,然后把它们拼在一起。
每一层解码器都有一个自注意力层,就像是小侦探在自己的记忆里搜索线索。然后,有一个图像交叉注意力层,小侦探会去图像里找线索,看看图里有什么东西。接着是一个文本交叉注意力层,小侦探也会去文本里找线索,看看文字里说了些什么。最后还有一个前馈神经网络(FFN)层,就像是小侦探在整理线索,把它们整理成一个完整的报告。
和DINO的解码器层相比,Grounding DINO的解码器层多了一个文本交叉注意力层。这是因为我们需要把文本信息注入到查询中,以便更好地对齐不同模态的特征。这就像是小侦探不仅要从图像里找线索,还要从文字里找线索,这样才能更全面地理解问题。
3.4 Sub-Sentence Level Text Feature
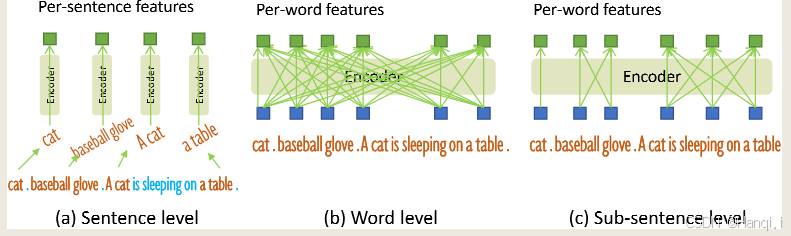
在以往的研究中,已经探索了两种文本提示的方式,我们称之为句子级表示和单词级表示,如图4所示。句子级表示将整个句子编码为一个特征,如果短语接地数据中的某些句子有多个短语,它会提取这些短语并丢弃其他单词。这样做的好处是可以快速地将文本信息转化为一个紧凑的表示,但缺点是会失去句子中的细粒度信息,同时还会移除单词之间的影响。
例如,假设原句是“猫吃鱼”,句子级表示可能将整个句子编码为一个向量,但无法区分“猫”和“鱼”这两个单词的单独特征,因此丢失了它们的细粒度信息。
单词级表示则允许在一次前向传播中对多个类别名称进行编码,但会引入类别之间的不必要依赖,尤其是在输入文本是按任意顺序拼接多个类别名称时。在图4(b)中可以看到,一些不相关的单词在注意力机制中相互作用。
例如,假设输入文本是“猫狗房子”,单词级表示将每个单词都作为独立的特征进行处理,但会引入它们之间的相互影响,比如“猫”和“狗”之间的关系可能会对“房子”的特征产生不必要的干扰。
为了避免不必要的单词相互作用,我们引入了注意力掩码,来阻止不相关的类别名称之间的注意力,这种表示方式被称为“子句”级表示。它消除了不同类别名称之间的相互影响,同时保留了每个单词的特征,以实现细粒度的理解。
例如,对于输入文本“猫狗房子”,子句级表示会将每个单词视为独立的子句,并使用注意力掩码来阻止它们之间的相互影响,从而确保每个单词的特征都是基于自身的语义,而不是受其他单词的影响。
知识点:grounding data
指的是用于训练模型的数据,这些数据包含了图像和与图像内容相关的文本描述。这类数据对于训练模型理解图像内容和文本描述之间的对应关系至关重要。
3.5 Loss Function
-
边界框回归损失:遵循之前的DETR-like工作,Grounding DINO使用L1损失和GIoU损失来处理边界框回归。L1损失用于衡量预测框与真实框之间的位置差异,GIoU损失则不仅考虑了重叠度,还考虑了包围框的尺寸差异,有助于提高检测框的平移不变性。
-
分类损失:借鉴GLIP的方法,Grounding DINO在分类任务中使用对比损失。具体来说,将每个查询与文本特征的点积用作logits预测,然后对每个logit应用focal loss。这样可以提高模型对困难样本的聚焦能力,使模型更关注稀疏类别。
-
二分匹配:首先使用边界框回归代价和分类代价,在预测和真实值之间进行二分匹配。这样可以通过最优匹配将预测和真实值对齐,确保每个预测框对应一个真实框,从而后续能够准确地计算损失。
-
最终损失计算:在确定匹配之后,使用相同的损失组件计算真实值和匹配预测之间的最终损失。这包括分类损失、边界框回归损失等,通过这些损失的反向传播,模型可以不断优化,以提高检测的准确性和稳定性。
-
辅助损失:遵循DETR-like模型的做法,在每个解码器层之后以及在编码器的输出之后添加辅助损失。这有助于确保在整个解码器网络中,各个层都能够学习到有用的信息,从而提高整个模型的训练效果和检测性能。
-
训练目标:通过上述损失函数的组合,Grounding DINO可以学习到同时优化对象检测和语言理解的模型参数,从而实现对任意对象的开放集检测和基于语言的引导检测。
4 Experiments
(没有仔细看,若复现,后补)
1. Closed-Set Setting(封闭集设置)
-
实验内容:在COCO检测基准上进行封闭集设置的实验。
-
目的:评估模型在已知类别上的性能,这是目标检测任务中最常见的场景。
-
具体实验:在COCO数据集上进行标准的目标检测任务,模型需要检测和定位图像中的已知类别对象。
2. Open-Set Setting(开放集设置)
-
实验内容:在零样本学习(zero-shot)的COCO、LVIS和ODinW数据集上进行开放集设置的实验。
-
目的:评估模型在未见过的类别上的性能,这是开放集目标检测的核心挑战。
-
具体实验:模型需要检测和定位图像中的未见过类别对象,这些类别在训练阶段没有出现过。
3. Referring Detection Setting(指代表达检测设置)
-
实验内容:在RefCOCO/+/g数据集上进行指代表达检测的实验。
-
目的:评估模型在根据文本描述定位特定对象的能力,这是指代表达理解任务的核心。
-
具体实验:模型需要根据给定的文本描述(如“戴帽子的人”)在图像中定位相应的对象。
4. Ablation Studies(消融研究)
-
实验内容:进行消融实验以展示模型设计的有效性。
-
目的:通过移除或修改模型的某些组件,来评估这些组件对模型性能的影响。
-
具体实验:例如,移除特征增强器或语言引导的查询选择模块,观察模型性能的变化。
5. Transfer Learning(迁移学习)
-
实验内容:探索如何将预训练的DINO模型迁移到开放集场景。
-
目的:评估通过训练一些插件模块,将封闭集模型转换为开放集模型的有效性。
-
具体实验:在预训练的DINO模型上添加一些插件模块,并在开放集数据集上进行训练和评估。
6. Model Efficiency Test(模型效率测试)
-
实验内容:测试模型的效率,包括推理速度和资源消耗。
-
目的:评估模型在实际应用中的可行性和效率。
-
具体实验:在不同的硬件配置下测试模型的推理速度和资源消耗。
5 Conclusion
-
Grounding DINO模型:本文介绍了一个名为Grounding DINO的模型。Grounding DINO扩展了DINO模型,使其能够进行开放集目标检测,即根据文本查询检测任意对象。
-
开放集目标检测设计:我们回顾了开放集目标检测器的设计,并提出了一种紧密融合的方法,以更好地融合跨模态信息。
-
子句级表示:我们提出了一种子句级表示方法,以更合理的方式使用检测数据进行文本提示。
模型的扩展和局限性
-
扩展到指代表达理解(REC)任务:我们还将开放集目标检测扩展到指代表达理解(REC)任务,并进行了相应的评估。结果显示,现有的开放集检测器在没有微调的情况下对REC数据的表现不佳。因此,我们呼吁在未来的研究中特别关注REC的零样本性能。
-
局限性:
-
尽管在开放集目标检测设置上表现优异,Grounding DINO不能用于分割任务,如GLIPv2。
-
我们的训练数据量小于最大的GLIP模型,这可能限制了我们的最终性能。
-
我们发现模型在某些情况下会产生误报,这可能需要更多的技术或数据来减少幻觉。
-
开学了,冲冲冲!

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









