






XGBoost 是一个非常流行的梯度提升框架,它在机器学习领域中被广泛使用,特别是在处理大规模数据集和复杂模型时表现出色。以下是一篇关于 XGBoost 模型的博客,其中详细介绍了 XGBoost 的基本概念、使用方法以及一些高级特性。
引言
在机器学习的世界里,XGBoost(eXtreme Gradient Boosting)以其出色的性能和灵活性,成为了众多数据科学家的首选算法之一。本文将深入探讨 XGBoost 的内部机制,并提供一份详细的 Python 实践指南,帮助读者更好地理解和应用这一强大的工具。
XGBoost 简介
XGBoost 是基于梯度提升决策树(GBDT)的算法,它通过构建多个决策树并逐步优化,以最小化一个可微分的损失函数。XGBoost 的主要优势在于其对计算效率和模型性能的优化,以及对多种数据类型的支持。
核心概念
1. 梯度提升(Gradient Boosting)
梯度提升是一种集成学习算法,它通过逐步添加弱预测模型(通常是决策树)来最小化损失函数。每个新模型都是为了纠正前一个模型的错误而设计的。
2. 损失函数(Objective Function)
XGBoost 允许用户定义自己的损失函数,这使得它能够适应不同类型的问题,如分类、回归等。例如,对于二分类问题,可以使用 binary:logistic 损失函数。
3. 正则化(Regularization)
XGBoost 在损失函数中加入了 L1(LASSO)和 L2(Ridge)正则化项,以防止模型过拟合。
4. 树构建策略
XGBoost 采用了多种树构建策略,如:
- 剪枝(Pruning):构建更深的树,然后剪枝到适当的大小。
- 列抽样(Column Subsampling):随机选择一部分特征进行树构建,以增加模型的多样性。
5. 并行处理
XGBoost 支持多线程处理,可以利用多核 CPU 来加速训练过程。
6. 缺失值处理
XGBoost 可以自动处理缺失值,通过学习来决定缺失值的默认方向。
7. 特征重要性(Feature Importance)
XGBoost 提供了一种方法来评估特征的重要性,这对于特征选择和模型解释非常有帮助。
8. 早停法(Early Stopping)
在训练过程中,如果验证集的性能在连续多个迭代中没有改善,则停止训练,这是一种避免过拟合的技术。
9. 模型保存与加载
XGBoost 支持将训练好的模型保存到磁盘,并在需要时加载模型进行预测或进一步训练。
10. Python 接口
XGBoost 提供了 Python 接口,使得在 Python 环境中使用 XGBoost 变得非常方便。
安装与配置
在 Python 中使用 XGBoost 非常简单。首先,你需要安装 xgboost 包:
pip install xgboost
然后,你可以导入 XGBoost 并开始构建模型:
import xgboost as xgb
# 基本配置
params = {
'max_depth': 3, # 树的最大深度
'learning_rate': 0.01, # 学习率
'n_estimators': 100, # 树的数量
'objective': 'binary:logistic' # 目标函数
}
# 训练数据
X_train, y_train = ... # 你的训练数据
# 训练模型
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
下面是一个简单的 Python 代码示例,展示如何使用 pickle 保存和加载 XGBoost 模型:
import pickle
# 保存模型
with open('model.pkl', 'wb') as file:
pickle.dump(model, file)
# 加载模型
with open('model.pkl', 'rb') as file:
loaded_model = pickle.load(file)
# 使用加载的模型进行预测
predictions = loaded_model.predict(X_new)
使用 XGBoost 回归问题的 Python 示例代码:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据
data = load_boston()
X, y = data.data, data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将数据转换为 DMatrix,这是 XGBoost 的数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 设置参数
param = {
'max_depth': 3, # 树的最大深度
'eta': 0.3, # 学习率
'objective': 'reg:squarederror' # 回归问题使用均方误差作为损失函数
}
# 训练模型
num_round = 50
model = xgb.train(param, dtrain, num_round)
# 预测
preds = model.predict(dtest)
# 评估模型
mse = mean_squared_error(y_test, preds)
print(f'MSE: {mse}')
模型评估
模型评估是机器学习工作流程中的一个关键步骤,它帮助我们了解模型在实际应用中的表现。在回归问题中,常用的评估指标之一是均方误差(Mean Squared Error, MSE),它衡量的是模型预测值与真实值之间差异的平方的平均值。MSE 能够为我们提供一个量化的误差度量,值越小表示模型的预测越准确。
均方误差(MSE)的定义:
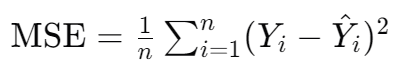
其中:
- ( n ) 是样本数量。
- ( Y_i ) 是第 ( i ) 个观测的真实值。
- ( \hat{Y}_i ) 是第 ( i ) 个观测的预测值。
MSE 的特点:
- 直观性:MSE 直观地反映了预测误差的大小,易于理解和解释。
- 敏感性:MSE 对大的预测误差给予更大的惩罚,因为它是误差的平方。
- 可导性:MSE 是可导的,这使得它适用于梯度下降等优化算法。
如何解读 MSE:
- 较低的 MSE 值:表示模型的预测值与真实值非常接近,模型的性能较好。
- 较高的 MSE 值:表示模型的预测值与真实值相差较远,可能需要进一步调整模型。
评估模型时的注意事项:
- 数据分布:确保评估数据(测试集)是从相同的分布中抽取的,以保证评估结果的准确性。
- 评估指标的选择:根据问题的性质选择合适的评估指标。除了 MSE,还有其他指标如 MAE(Mean Absolute Error)、RMSE(Root Mean Squared Error)、R² 分数等。
- 模型泛化能力:评估模型在未见过的数据上的表现,确保模型具有良好的泛化能力。
- 过拟合和欠拟合:MSE 可以帮助我们识别过拟合或欠拟合的问题。如果训练误差和测试误差都很高,可能是欠拟合;如果训练误差低而测试误差高,则可能是过拟合。
高级特性
1. 特征重要性
XGBoost 提供了一种评估特征重要性的方法,这有助于理解模型的决策过程。
如果使用的是 xgb.train 函数来训练模型,并希望获取特征重要性,你需要使用 get_fscore 方法来获取特征得分,然后自己计算重要性。以下是如何使用 get_fscore 方法的示例:
import xgboost as xgb
# 假设你已经有了训练数据 dtrain 和参数 params
# 训练模型
model = xgb.train(params, dtrain, num_boost_round=100)
# 获取特征得分
fscore = model.get_fscore()
# 特征重要性可以通过对 fscore 中的值求和来计算
feature_importances = fscore['weight'] # 假设我们使用权重作为特征重要性的度量
# 绘制特征重要性
import matplotlib.pyplot as plt
plt.barh(range(len(feature_importances)), feature_importances)
plt.show()
如果使用的是 XGBClassifier 或 XGBRegressor,并且已经拟合了模型,那么可以直接访问 feature_importances_ 属性:
# 假设 model 是一个 XGBClassifier 或 XGBRegressor 的实例
feature_importances = model.feature_importances_
# 绘制特征重要性
import matplotlib.pyplot as plt
plt.barh(range(len(feature_importances)), feature_importances)
plt.show()
2. 早停法(Early Stopping)
在训练过程中,如果验证集的性能在连续多个迭代中没有改善,则停止训练,以避免过拟合。
from xgboost import train
# 使用早停法
bst = train(params, dtrain, num_boost_round=100, evals=[(X_val, y_val)], early_stopping_rounds=10)
3. 并行处理
XGBoost 支持并行处理,可以显著加快训练速度。
# 设置 nthread 参数
params['nthread'] = 4 # 根据你的 CPU 核心数设置
结论
XGBoost 是一个功能强大且灵活的机器学习算法,它通过梯度提升和正则化等技术,提供了一种有效的方式来构建和优化决策树模型。本文提供了一个基本的入门指南,但 XGBoost 的深度和广度远远超出了这里所讨论的内容。希望读者能够通过本文对 XGBoost 有一个更深入的理解,并将其应用于实际的机器学习项目中。
相关参考
https://mp.weixin.qq.com/s/2tx6qJVqFikiF9JvPgThLg

















 2235
2235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









