






一、KNN算法概述
什么是KNN?
KNN算法,也称为K最近邻算法,是一种基础且常用的机器学习算法,它既可用于分类问题,也适用于回归预测。
KNN算法的核心思想十分直观:近朱者赤,近墨者黑。对于一个未知类别的样本,我们只需观察它在特征空间中的k个最相邻的样本,如果这些近邻中的大多数样本属于某一个类别,那么我们就认为该未知样本也属于这个类别。在回归任务中,KNN算法则是通过计算待预测点附近的k个邻居的实际数值来预测该点的值。
总的来说,KNN算法以其简单易懂的原理和广泛的应用场景成为了机器学习领域中一个非常重要的算法。
KNN算法步骤
- 收集数据:这一步涉及获取适用于问题的数据。数据可以来源于各种途径,如数据库、数据仓库、数据集等。
- 准备数据:将数据整理成适合算法处理的格式。对于KNN算法,通常需要结构化数据,以便计算样本之间的距离。
- 计算距离:对于测试集中的每一个样本,计算它与训练集中所有样本之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离和明可夫斯基距离等。
- 选择近邻:根据上一步骤计算出的距离,选出最近的k个邻居。k是一个用户定义的正整数,通常较小的k值会导致模型过拟合,较大的k值则可能导致欠拟合。
- 进行分类或回归:如果当前问题是分类任务,那么待分类样本将被归为k个近邻中出现最多的类别;如果是回归任务,则输出k个近邻的平均值或加权平均值作为预测结果。
- 评估模型:通过测试集来评估KNN模型的性能,通常会计算错误率或其他评价指标。
- 应用模型:将训练好的KNN模型应用于实际问题的解决中。
二、KNN算法python代码实现
1、准备工作
本实验是使用鸢尾花数据集进行实验,可以在浏览器搜索“鸢尾花数据集”就可以找到很多博主的分享,可以直接下载到自己的电脑中,在本实验中我下载的是csv格式的数据集。
2、导入数据集
import numpy as np
import pandas as pd # 导入包
pd.set_option('display.max_rows', 1000)
pd.set_option('display.max_columns',1000)
pd.set_option('display.width', 1000) #增加表格的列数行数和每行的宽度以此让数据集完整表示
data = pd.read_csv(r"D:\ML\data\Iris.csv",header=0) #读取数据集,header参数用来指定标题的行,默认值是0。如果没有标题则使header=None
print (data)
# print(data.head(10)) # 显示数据集前十行
# print(data.tail(10)) # 显示数据集后十行
# print(data.sample(2)) # 随机抽取2个样本
这段代码主要是用于读取和显示一个名为"Iris.csv"的数据集。具体步骤如下:
-
导入numpy和pandas两个Python库,这两个库是数据分析中常用的库,numpy主要用于进行数值计算,而pandas主要用于数据处理和分析。
-
设置pandas的显示选项,使得在显示数据时,可以显示更多的行、列和宽度,以便完整地展示整个数据集。
-
使用pandas的read_csv函数读取位于"D:\ML\data\Iris.csv"路径下的csv文件(也就是刚刚所下载的鸢尾花数据集,这里读者需要把它替换为自己电脑中的文件路径)并将其存储在变量data中。其中,header参数设置为0,表示第一行是数据的标题行。
-
打印出读取到的数据。
3、处理数据集
data["Species"] = data["Species"].map({"setosa": 0,"versicolor": 1,"virginica": 2}) #把花的种类名称映射成数字
print(data.sample(20))
这段代码的作用是将数据框(DataFrame)中的"Species"列中的花的种类名称映射成数字。具体来说,它将"setosa"映射为0,"versicolor"映射为1,"virginica"映射为2,以便于后面数据的使用然后,它使用print(data.sample(20))打印出数据框中随机选择的20个样本。
data.drop("Unnamed: 0",axis=1,inplace=True) # 删除没有用的 Unamed: 0 的那一列
这段代码是为了删除没有用的列。
print(data.duplicated().any()) #检查数据集中有没有重复的数据
data.drop_duplicates(inplace=True) # 删除数据集中的重复数据
这段代码是为了检查数据集中有无重复的数据,并删除无用的数据。
删除没用的列和重复的数据有以下几个原因:
-
数据清洗:在数据分析和机器学习中,数据的质量非常重要。无用的列可能包含无关的信息,这些信息可能会干扰模型的训练和预测结果。通过删除这些列,可以确保只保留与分析目标相关的数据。
-
减少冗余:重复的数据可能会导致数据的冗余和浪费存储空间。删除重复的数据可以减少数据集的大小,提高处理速度,并节省存储资源。
-
避免误导:无用的列和重复的数据可能会误导分析结果。例如,如果一个无用的列包含了错误的或不准确的数据,那么基于这个列的分析结果可能是不可靠的。删除这些列可以避免这种误导。
-
提高效率:删除无用的列和重复的数据可以提高数据处理和分析的效率。较小的数据集更容易处理和分析,同时也减少了计算资源的消耗。
4、初始化
class KNN:
"""使用Python语言实现k近邻算法。(实现分类)"""
def __init__(self, k):
"""初始化方法
parameters
-----
k : int
邻居的个数。
"""
self.k = k #用当前的k来初始化KNN对象中的k
在这段代码中,__init__方法是一个初始化方法,用于创建KNN对象时设置邻居个数k。参数k表示邻居的个数,它是一个整数。在初始化方法中,将传入的k值赋给KNN对象的k属性,以便后续在KNN类的其他方法中使用。
5、训练方法
def fit(self, X, y): # 训练样本中X是大写的,而标签y是小写的,因为矩阵习惯用大写字母表示,向量习惯用小写字母来表示。
"""训练方法
Parameters
-----
X: 类数组类型,形状为:[样本数量,特征的数量]
带训练的样本特征(属性)
y:类数组类型,形状为:[样本数量]
每个样本的目标值(标签)
"""
self.X = np.asarray(X) # 把X,y转化成ndarray数组类型。
self.y = np.asarray(y)
这段代码的作用是将输入的训练样本特征X和目标值y转换为NumPy数组类型,并将它们分别存储在类的属性self.X和self.y中。这样做的目的是为了方便后续的计算和处理。
6、预测
def predict(self,X):
"""根据参数传递的样本,对样本数据进行预测。
Parameters
------
X: 类数组类型,形状为:[样本数量,特征的数量]
带训练的样本特征(属性)
Returns
------
result:数组类型
预测的结果
"""
X = np.array(X)
result = []
# 对ndarray数组进行遍历,每次取数组中的一行。
for x in X:
# 求测试集中的每个样本与训练集中所有点的距离。
# x代表测试集中的一行,X代表训练集中的所有行。ndarray数组可以自己广播扩展然后对位运算。
dis = np.sqrt(np.sum((x - self.X) ** 2,axis=1))
# argsort可以将数组排序后,每个元素在原数组中的索引位置。
index = dis.argsort()
# 进行截断,只取前k个元素【取距离最近的k个元素的索引】
index = index[:self.k]
# 返回数组中每个元素出现的次数。元素必须是非负的整数。
count = np.bincount(self.y[index])
# 返回ndarray数组中,值最大的元素对应的索引,该索引就是我们判定的类别。
result.append(count.argmax())
return np.asarray(result)
这段代码的作用是根据输入的样本特征X,对每个样本进行预测。具体步骤如下:
- 将输入的样本特征X转换为NumPy数组类型。
- 创建一个空列表result,用于存储预测结果。
- 遍历输入的样本特征X中的每一个样本x。
- 计算测试集中的每个样本与训练集中所有点的距离,使用欧氏距离公式进行计算。
- 对距离进行排序,并取前k个最近的样本的索引。
- 统计这k个最近样本中各个类别出现的次数。
- 选择出现次数最多的类别作为当前样本的预测结果,并将其添加到result列表中。
- 返回预测结果result,将其转换为NumPy数组类型。
7、测试KNN的分类结果
# 提取出每个类别花的数据
t0 = data[data["Species"] == 0]
t1 = data[data["Species"] == 1]
t2 = data[data["Species"] == 2]
# 对每个类别的数据进行洗牌,random_state是对这个打乱顺序的一个记录。
t0 = t0.sample(len(t0), random_state=0)
t1 = t1.sample(len(t1), random_state=0)
t2 = t2.sample(len(t2), random_state=0)
#构建训练集和测试集
train_X = pd.concat([t0.iloc[:40,:-1],t1.iloc[:40,:-1],t2.iloc[:40,:-1]],axis=0)
train_y = pd.concat([t0.iloc[:40,-1],t1.iloc[:40,-1],t2.iloc[:40,-1]],axis=0)
text_X = pd.concat([t0.iloc[40:,:-1],t1.iloc[40:,:-1],t2.iloc[40:,:-1]],axis=0)
text_y = pd.concat([t0.iloc[40:,-1],t1.iloc[40:,-1],t2.iloc[40:,-1]],axis=0)
这段代码的作用是从给定的数据集中提取每个类别的花的数据,并对每个类别的数据进行洗牌。然后构建训练集和测试集,其中训练集包含每个类别的前40个样本,测试集包含每个类别的剩余样本。
# 创建KNN对象,进行训练与测试
knn = KNN(k=3)
# 进行训练
knn.fit(train_X,train_y)
# 进行测试获得测试的结果
result = knn.predict(test_X)
print(result) # 打印预测的结果
print(test_y) # 打印原来测试的答案
print(result == test_y) # 直接判断是否预测正确
print(np.sum(result == test_y)) # 进行求和运算看分类对了多少个
print(len(result))
print(np.sum(result == test_y)/len(result))
这段代码的作用是创建一个KNN(K-Nearest Neighbors)对象,使用训练集进行训练,然后对测试集进行预测。最后打印出预测结果、原始测试答案、预测是否正确的结果、分类正确的数量、预测结果的数量以及分类准确率。
8、可视化操作
#可视化操作
import matplotlib as mpl
import matplotlib.pyplot as plt
# 默认情况下,matplotlib不支持中文显示,我们需要进行设置
# 设置字体为黑体,以支持中文显示。
mpl.rcParams["font.family"] = "SimHei"
# 设置在中文字体时,能够正常的显示负号(-)
mpl.rcParams["axes.unicode_minus"] = False
# {"setosa": 0, "versicolor": 1, "virginica": 2}
# 绘制训练集数据
plt.scatter(x=t0["Sepal.Length"][:40],y=t0["Petal.Length"][:40],color='r',label="setosa")
plt.scatter(x=t1["Sepal.Length"][:40],y=t1["Petal.Length"] [:40],color='g',label="versicolor")
plt.scatter(x=t2["Sepal.Length"][:40],y=t2["Petal.Length"][:40],color='b',label="virginica")
plt.show() # 显示图片得有这一句
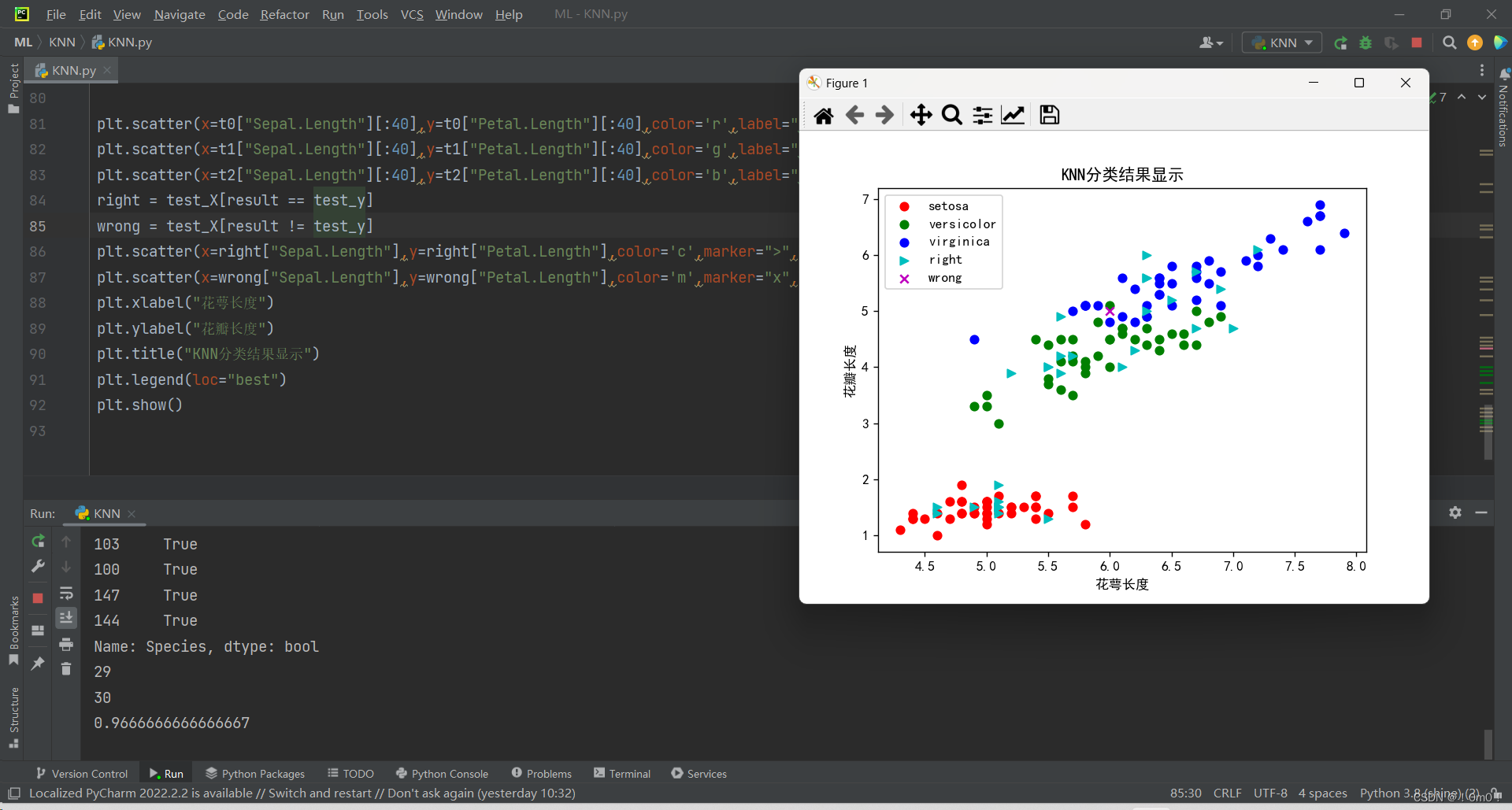
这段代码的作用是使用matplotlib库绘制散点图,将训练集中的三种鸢尾花(setosa、versicolor和virginica)的花瓣长度和萼片长度进行可视化展示。其中,红色代表setosa,绿色代表versicolor,蓝色代表virginica。通过这个散点图可以直观地观察不同种类鸢尾花在花瓣长度和萼片长度上的差异。
9、完整代码
import numpy as np
import pandas as pd
# 导入包
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000) # 增加表格的列数行数和每行的宽度以此让数据集完整表示
data = pd.read_csv(r"D:\ML\data\Iris.csv", header=0) # 读取数据集,header参数用来指定标题的行,默认值是0。如果没有标题则使header=None
data["Species"] = data["Species"].map({"setosa": 0, "versicolor": 1, "virginica": 2}) # 把花的种类名称映射成数字
data.drop("Unnamed: 0", axis=1, inplace=True) # 删除没有用的 Unamed: 0 的那一列
class KNN:
'''使用Python语言实现k近邻算法。(实现分类)'''
def __init__(self, k):
"""初始化方法
parameters
-----
k : int
邻居的个数。
"""
self.k = k #用当前的k来初始化KNN对象中的k
def fit(self, X, y): # 训练样本中X是大写的,而标签y是小写的,因为矩阵习惯用大写字母表示,向量习惯用小写字母来表示。
"""训练方法
Parameters
-----
X: 类数组类型,形状为:[样本数量,特征的数量]
带训练的样本特征(属性)
y:类数组类型,形状为:[样本数量]
每个样本的目标值(标签)
"""
self.X = np.asarray(X) # 把X,y转化成ndarray数组类型。
self.y = np.asarray(y)
def predict(self,X):
"""根据参数传递的样本,对样本数据进行预测。
Parameters
------
X: 类数组类型,形状为:[样本数量,特征的数量]
带训练的样本特征(属性)
Returns
------
result:数组类型
预测的结果
"""
X = np.array(X)
result = []
for x in X:
dis = np.sqrt(np.sum((x - self.X) ** 2,axis=1))
index = dis.argsort()
index = index[:self.k]
count = np.bincount(self.y[index],weights=1/dis[index])
result.append(count.argmax())
return np.asarray(result)
t0 = data[data["Species"] == 0]
t1 = data[data["Species"] == 1]
t2 = data[data["Species"] == 2]
t0 = t0.sample(len(t0), random_state=0)
t1 = t1.sample(len(t1), random_state=0)
t2 = t2.sample(len(t2), random_state=0)
train_X = pd.concat([t0.iloc[:40,:-1],t1.iloc[:40,:-1],t2.iloc[:40,:-1]],axis=0)
train_y = pd.concat([t0.iloc[:40,-1],t1.iloc[:40,-1],t2.iloc[:40,-1]],axis=0)
test_X = pd.concat([t0.iloc[40:,:-1],t1.iloc[40:,:-1],t2.iloc[40:,:-1]],axis=0)
test_y = pd.concat([t0.iloc[40:,-1],t1.iloc[40:,-1],t2.iloc[40:,-1]],axis=0)
knn = KNN(k=3)
knn.fit(train_X,train_y)
result = knn.predict(test_X)
print(result) # 打印预测的结果
print(test_y) # 打印原来测试的答案
print(result == test_y) # 直接判断是否预测正确
print(np.sum(result == test_y)) # 进行求和运算看分类对了多少个
print(len(result))
print(np.sum(result == test_y)/len(result))
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
plt.scatter(x=t0["Sepal.Length"][:40],y=t0["Petal.Length"][:40],color='r',label="setosa")
plt.scatter(x=t1["Sepal.Length"][:40],y=t1["Petal.Length"][:40],color='g',label="versicolor")
plt.scatter(x=t2["Sepal.Length"][:40],y=t2["Petal.Length"][:40],color='b',label="virginica")
right = test_X[result == test_y]
wrong = test_X[result != test_y]
plt.scatter(x=right["Sepal.Length"],y=right["Petal.Length"],color='c',marker=">",label="right")
plt.scatter(x=wrong["Sepal.Length"],y=wrong["Petal.Length"],color='m',marker="x",label="wrong")
plt.xlabel("花萼长度")
plt.ylabel("花瓣长度")
plt.title("KNN分类结果显示")
plt.legend(loc="best")
plt.show()
10、最后结果截图
11、实验结果分析
- 预测结果为:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2]
- 原测试的答案为:
- 类别 0 的样本:36, 21, 19, 9, 39, 46, 3, 0, 47, 44
- 类别 1 的样本:86, 71, 69, 59, 89, 96, 53, 50, 97, 94
- 类别 2 的样本:136, 121, 119, 109, 139, 146, 103, 100, 147, 144
- 判断是否预测正确的结果为:
- 类别 0:全部预测正确
- 类别 1:全部预测正确
- 类别 2:有一个样本预测错误
- 正确分类的数量为 29 个,总样本数量为 30 个。
- 准确率为 0.9666666666666667,即 96.67%。
根据对比分析:
- 从预测结果和原测试的答案可以看出,大部分样本被正确分类,只有一个样本被错误分类。
- 通过判断是否预测正确的结果可以看到,对类别 0 和类别 1 的样本都有很好的分类效果,而对类别 2 的一个样本进行了错误分类。
- 总体准确率为 96.67%,表明该 KNN 算法在鸢尾花数据集上表现良好,但仍有改进的空间,可以进一步优化算法或调整参数以提高分类准确率。
综上所述,该 KNN 算法在鸢尾花数据集上取得了较高的分类准确率,但仍需进一步优化和改进。
三、模型评估
1、为什么要进行模型评估?
模型评估是机器学习领域中至关重要的一环,它有助于我们了解模型的性能和泛化能力。以下是进行模型评估的几个关键原因:
(1)衡量预测误差:模型评估可以告诉我们模型在预测新数据时的准确度,即预测误差的大小。
(2)检测拟合程度:通过评估,我们可以判断模型对训练数据的拟合程度,以及是否出现过拟合或欠拟合的情况。
(3)评估模型稳定性:模型评估还可以帮助我们了解模型在不同数据集上的表现是否稳定,即模型的健壮性。
(4)选择评估指标:根据不同的机器学习任务和应用场景,我们需要选择合适的评估指标来衡量模型的性能。
(5)实验设计与优化:模型评估指导我们如何设计实验,以及如何根据评估结果对模型进行优化。
(6)保证泛化能力:最终目标是选择一个泛化能力强的模型,即在未知样本上也能表现良好的模型。
(7)实际需求匹配:模型评估确保我们选择的模型和评估方法与实际应用场景相匹配,满足实际需求。
(8)多方面的考量:除了准确性外,模型的预测速度、资源消耗、可解释性等也是评估时需要考虑的因素。
综上所述,模型评估不仅是为了衡量模型的性能,更是为了确保模型能够在实际应用中达到预期的效果。通过评估,我们可以不断调整和优化模型,直至满足实际应用的需求。
2、常见的分类模型评估指标
(1)基本术语

混淆矩阵是用于评估分类模型性能的一个工具,通常是一个m行m列的表格。这个表格中的元素CMi,j表示原本属于类别i的元组被分类器预测为类别j的数量。
-
P:正元组,感兴趣的主要类的元组
-
N:负元组,其他元组
-
TP(True Positive):真正例,指的是分类器正确预测的正元组数量,即实际为正元组且被预测为正元组的情况。
- TN(True Negative):真负例,指的是分类器正确预测的负元组数量,即实际为负元组且被预测为负元组的情况。
- FP(False Positive):假正例,指的是分类器错误地将负元组预测为正元组的数量,即实际为负元组但被预测为正元组的情况。
- FN(False Negative):假负例,指的是分类器错误地将正元组预测为负元组的数量,即实际为正元组但被预测为负元组的情况。
理想情况下,对于高准确率的分类器,大部分元组应该被混淆矩阵从CM1,1到CMm,m的对角线上的表目(表目是指混淆矩阵中的一个元素,表示特定类别的元组被分类器标记为某个类别的个数。)表示,而其他表目为0或者接近0,也就是说FP和FN接近0。这意味着分类器的预测结果与实际类别完全一致或非常接近。
(2)评价指标
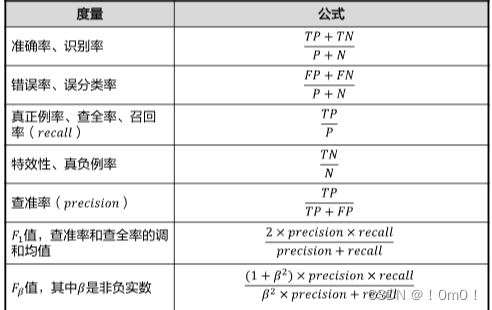
准确率(Accuracy):指模型正确预测的样本数占总样本数的比例。它是评估模型整体性能的最直观的指标;
错误率(Error Rate):与准确率相反,它指的是模型错误预测的样本数占总样本数的比例;
真正例率(True Positive Rate, TPR):又称为查全率或召回率(Recall),它表示在所有实际为正类别的样本中,被正确预测为正类别的样本所占的比例;
真负例率:通常指特异度(Specificity),即在所有实际为负类别的样本中,被正确预测为负类别的样本所占的比例;
查准率(Precision):指在所有被预测为正类别的样本中,实际为正类别的样本所占的比例;
F1分数(F-measure):是查准率和查全率的调和均值,用于同时考虑查准率和查全率,当两者之一较低时,F1分数会降低;
Fβ分数(F-beta measure):是精确率和召回率的加权调和平均,用于评估二元分类模型的性能它通过调整β参数来体现精确率和召回率在评价中的相对重要性。
(3)ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是一种用于评估二分类模型性能的图形工具。它以假正例率(False Positive Rate,FPR)为横坐标,真正例率(True Positive Rate,TPR)为纵坐标绘制。在ROC曲线中,横轴代表假正例率,纵轴代表真正例率。
-
假正例率(FPR):假设为负例的样本中被错误地预测为正例的比率。
FPR=FP/(FP+TN)
假正例率的计算告诉我们,模型在负例中被误分类为正例的频率。 -
真正例率(TPR):也称为召回率,即真实正例中被正确预测为正例的比率。
TPR=TP/(TP+FN)
真正例率的计算表明了模型在正例中被正确识别为正例的频率。
在ROC曲线中,横轴和纵轴的取值范围都是[0,1]。ROC曲线下的面积被称为AUC(Area Under the Curve),AUC的值越接近1,说明模型性能越好。
(4)PR曲线
PR曲线(Precision-Recall Curve)以精确率(Precision)为横坐标,召回率(Recall)为纵坐标绘制。在PR曲线中,横轴代表精确率,纵轴代表召回率。
PR曲线相比于ROC曲线更适用于正例非常稀少或者我们关注的是正例的情况,因为PR曲线更能够反映出正例的预测情况。
(5)ROC曲线与PR曲线的差异
- ROC曲线适用于不同类别样本的分布比较均匀的情况下,能够很好地反映出分类器的整体性能,对于类别不平衡的问题不太敏感。
- PR曲线更适用于类别不平衡的情况下,特别是在正例样本相对较少的情况下,更能够准确地评估分类器的性能,尤其是在关注正例的情况下。
3、对鸢尾花实验进行模型评估
(1)实验代码
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.metrics import accuracy_score, roc_curve, auc, precision_recall_curve
# Load the data
data = pd.read_csv(r"D:\ML\data\Iris.csv", header=0)
data["Species"] = data["Species"].map({"setosa": 0, "versicolor": 1, "virginica": 2})
data.drop("Unnamed: 0", axis=1, inplace=True)
class KNN:
'''Implementation of k-nearest neighbors algorithm for classification.'''
def __init__(self, k):
"""Initialize method
Parameters
-----
k : int
Number of neighbors.
"""
self.k = k
def fit(self, X, y):
"""Training method
Parameters
-----
X: array-like, shape [n_samples, n_features]
Training samples features
y: array-like, shape [n_samples]
Target values for each sample
"""
self.X = np.asarray(X)
self.y = np.asarray(y)
def predict(self, X):
"""Predict method
Parameters
------
X: array-like, shape [n_samples, n_features]
Samples to be predicted
Returns
------
result: array-like
Predicted results
"""
X = np.array(X)
result = []
for x in X:
dis = np.sqrt(np.sum((x - self.X) ** 2, axis=1))
index = dis.argsort()
index = index[:self.k]
count = np.bincount(self.y[index], weights=1/dis[index])
result.append(count.argmax())
return np.asarray(result)
# Split the data into train and test sets
t0 = data[data["Species"] == 0].sample(frac=1, random_state=0)
t1 = data[data["Species"] == 1].sample(frac=1, random_state=0)
t2 = data[data["Species"] == 2].sample(frac=1, random_state=0)
train_X = pd.concat([t0.iloc[:40,:-1], t1.iloc[:40,:-1], t2.iloc[:40,:-1]], axis=0)
train_y = pd.concat([t0.iloc[:40,-1], t1.iloc[:40,-1], t2.iloc[:40,-1]], axis=0)
test_X = pd.concat([t0.iloc[40:,:-1], t1.iloc[40:,:-1], t2.iloc[40:,:-1]], axis=0)
test_y = pd.concat([t0.iloc[40:,-1], t1.iloc[40:,-1], t2.iloc[40:,-1]], axis=0)
# Define the KNN classifier
def knn_classifier(k_value):
knn = KNN(k=k_value)
knn.fit(train_X, train_y)
result = knn.predict(test_X)
return result
# Calculate accuracy for different k values
k_values = [1, 3, 5, 7, 9]
for k in k_values:
result = knn_classifier(k)
accuracy = accuracy_score(test_y, result)
print(f"Accuracy for k={k}: {accuracy}")
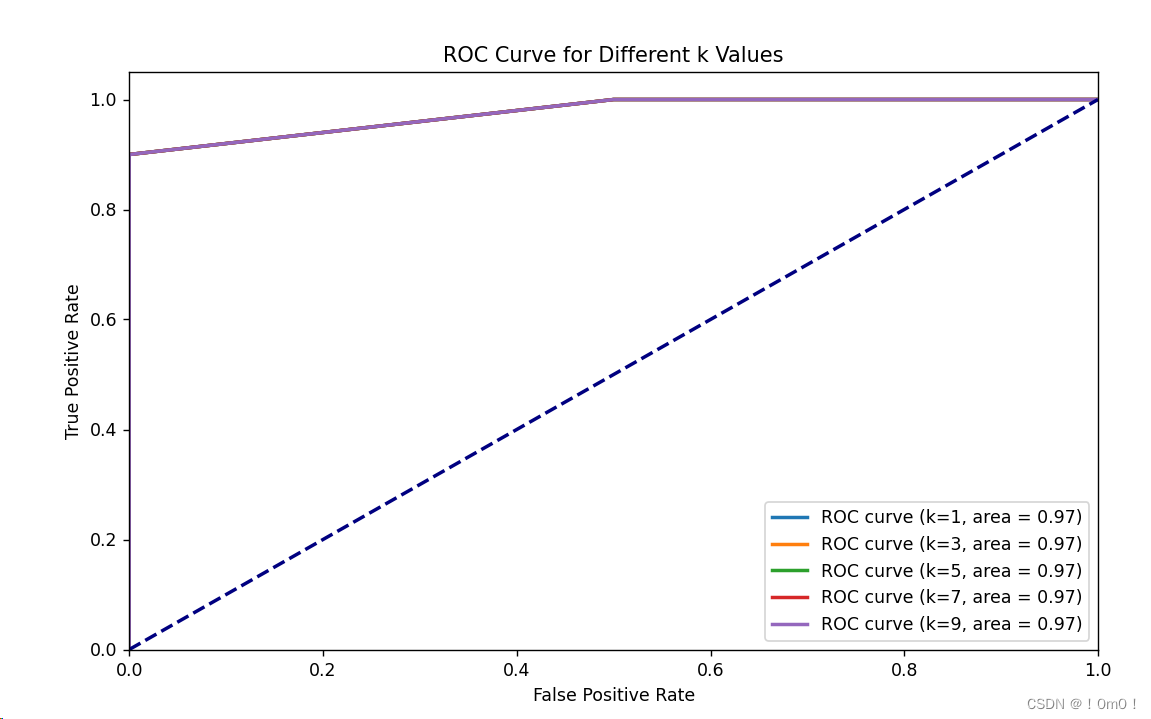
# Plot ROC curve for different k values
plt.figure(figsize=(10, 6))
for k in k_values:
result = knn_classifier(k)
fpr, tpr, thresholds = roc_curve(test_y, result, pos_label=2)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, label='ROC curve (k=%d, area = %0.2f)' % (k, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for Different k Values')
plt.legend(loc="lower right")
plt.show()
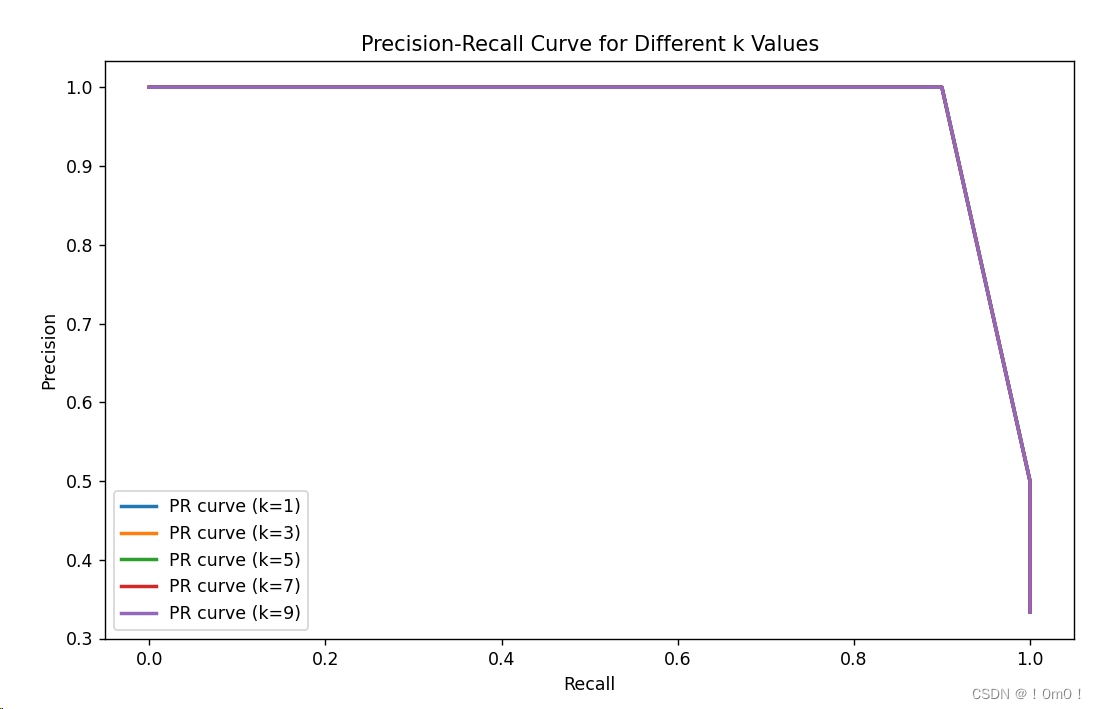
# Plot PR curve for different k values
plt.figure(figsize=(10, 6))
for k in k_values:
result = knn_classifier(k)
precision, recall, _ = precision_recall_curve(test_y, result, pos_label=2)
plt.plot(recall, precision, lw=2, label='PR curve (k=%d)' % k)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve for Different k Values")
plt.legend(loc="best")
plt.show((2)实验结果

(3)实验结果分析
根据本实验的实验结果,可以看出在Iris数据集上使用k-近邻算法进行分类时,不同的k值对准确率没有显著影响。无论k取值为1、3、5、7还是9,准确率都保持在0.9666666666666667。
这可能意味着在这个特定问题中,k的选择对模型的准确率没有明显的影响,或者数据本身具有很高的一致性,使得近邻的数量变化并不影响最终的分类结果。因此在该实验设定下,k值的变化对k-近邻算法的准确率没有显著影响。
但需要注意的是在不同实验种不同k值下的ROC曲线可能会有所不同,同时k值对准确率和ROC曲线都有影响。
首先,关于不同k值下的ROC曲线的差异,可以从以下几个方面进行分析:
模型复杂性:较小的k值意味着模型会更加复杂,因为它更多地依赖于训练数据中的局部结构。这可能导致模型对训练数据过拟合,从而在测试数据上的表现不佳。
预测稳定性:较大的k值可能会使模型更加稳定,因为它考虑了更多的邻居来做出预测。这可能减少模型对个别异常点的敏感性,从而提高其泛化能力。
近似误差与估计误差:选择较小的k值可以减小近似误差,因为模型更加贴近训练数据。然而,这也可能导致估计误差增大,因为模型对训练数据的特定特性过于敏感。
其次,关于k值对准确率的影响,可以从以下几个方面进行分析:
准确率的变化:在本次实验结果中,我们已经看到不同k值下准确率保持稳定的情况。这可能是由于Iris数据集的特性导致的,即数据点之间的区分度较高,使得k值的变化对准确率的影响不大。
泛化能力:通常情况下,k值的选择会影响模型的泛化能力。如果k值过小,模型可能会对训练数据过拟合,导致在新的数据上表现不佳。相反,如果k值过大,模型可能会忽略数据的重要特征,也会影响准确率。
总结来说,k值的选择对k-近邻算法的性能有显著影响,包括准确率和ROC曲线。在实际应用中,选择合适的k值是非常重要的,通常需要通过交叉验证等方法来确定最佳的k值,以达到最好的分类效果和模型泛化能力。
四、实验总结
本次实验的主要目的是使用K近邻算法(KNN)对鸢尾花数据集进行分类。首先,它导入了所需的库,并设置了显示选项以便于查看数据。接着,它读取了鸢尾花数据集,并将类别名称映射为数字。然后,它删除了不需要的列。
接下来,代码定义了一个名为KNN的类,该类实现了K近邻算法。在这个类中,有两个方法:fit和predict。fit方法用于训练模型,而predict方法用于对新数据进行预测。
在主程序部分,代码首先提取了每个类别的花的数据,并对每个类别的数据进行了洗牌。然后,它构建了训练集和测试集。接下来,它创建了一个KNN对象,并使用训练集对其进行了训练。最后,它使用测试集对模型进行了测试,并打印了预测结果、原始测试答案以及预测准确率等信息。
此外,代码还使用了matplotlib库绘制了散点图,以直观地展示不同种类鸢尾花在花瓣长度和花萼长度上的差异。图中的蓝色点表示正确的预测结果,橙色点表示错误的预测结果。
















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









