







机器学习入门案例-鸢尾花
简介:本文讲解一个机器学习里面的经典案例,鸢尾花,鸢尾花案例是指一种虚构的情景,假设我们在一片花园里寻找鸢尾花。这种花的特点是两种颜色的花瓣呈现出鸢尾的形状,即黑白相间,如阴阳符号一般。我们的目标是通过花瓣的形状和颜色来识别这种特殊的花朵。
- 作者简介:一名后端开发人员,每天分享后端开发以及人工智能相关技术,行业前沿信息,面试宝典。
- 座右铭:未来是不可确定的,慢慢来是最快的。
- 个人主页:极客李华-CSDN博客
- 合作方式:私聊+
- 这个专栏内容:用最低价格鼓励和博主一起在寒假打卡高频大厂算法题,连续一个月,提升自己的算法实力,为了算法比赛或者春招。
- 我的CSDN社区:https://bbs.csdn.net/forums/99eb3042821a4432868bb5bfc4d513a8
- 微信公众号,抖音,b站等平台统一叫做:极客李华,加入微信公众号领取各种编程资料,加入抖音,b站学习面试技巧,职业规划
首先需要在jupyter中安装对应的环境。
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sklearn -i https://pypi.tuna.tsinghua.edu.cn/simple
数学公式
假设函数(Hypothesis Function):
逻辑回归的假设函数使用sigmoid函数将线性函数的输出转换为0到1之间的概率值:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
其中,( z ) 是输入特征的线性组合,即:
z = θ 0 + θ 1 x 1 + θ 2 x 2 + … + θ n x n z = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \ldots + \theta_n x_n z=θ0+θ1x1+θ2x2+…+θnxn
损失函数(Loss Function):
我们使用对数似然损失函数(log-likelihood loss function)来衡量模型预测与真实标签之间的差距:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} [y^{(i)} \log(h_{\theta}(x^{(i)})) + (1 - y^{(i)}) \log(1 - h_{\theta}(x^{(i)}))] J(θ)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
其中, h θ ( x ) h_{\theta}(x) hθ(x) 是假设函数, y y y是真实标签, m m m是样本数量。
参数更新:
我们使用梯度下降法来最小化损失函数,更新参数 θ \theta θ:
θ j = θ j − α ∂ J ( θ ) ∂ θ j \theta_j = \theta_j - \alpha \frac{\partial J(\theta)}{\partial \theta_j} θj=θj−α∂θj∂J(θ)
其中, α \alpha α是学习率。
Sigmoid函数:
Sigmoid函数用于将线性函数的输出映射到0到1之间的概率值,其数学公式如下:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
实现代码
-
Sigmoid 函数:Sigmoid 函数用于将线性模型的输出转换为概率值,其公式如下:
sigmoid ( z ) = 1 1 + e − z \text{sigmoid}(z) = \frac{1}{1 + e^{-z}} sigmoid(z)=1+e−z1
这里 ( z ) 是线性模型的输出,是输入特征的加权和加上偏置项。 -
逻辑回归模型的线性模型:在逻辑回归模型中,线性模型的表达式为:
z = w 0 + w 1 × X 1 + w 2 × X 2 + … + w n × X n z = w_0 + w_1 \times X_1 + w_2 \times X_2 + \ldots + w_n \times X_n z=w0+w1×X1+w2×X2+…+wn×Xn
其中, w 0 w_0 w0 是偏置项, w 1 , w 2 , … , w n w_1, w_2, \ldots, w_n w1,w2,…,wn 是特征的权重参数, X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn 是输入特征。 -
最大似然估计(Maximum Likelihood Estimation,MLE):最大似然估计是用来估计模型参数的方法之一,在这个代码中,通过最大似然估计来求解逻辑回归模型的参数。最大似然估计的目标是最大化观测数据的联合概率密度函数,这里是最大化观测数据的概率,即使得观测数据出现的概率最大。
-
线性代数运算:代码中使用了一些线性代数运算,如矩阵的转置(
X.T)、矩阵的乘法(X @ Y)、矩阵的逆(np.linalg.inv())等。
import numpy as np
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data[:, :2], (iris.target == 0).astype(int) # 我们只使用两个特征和两个类别
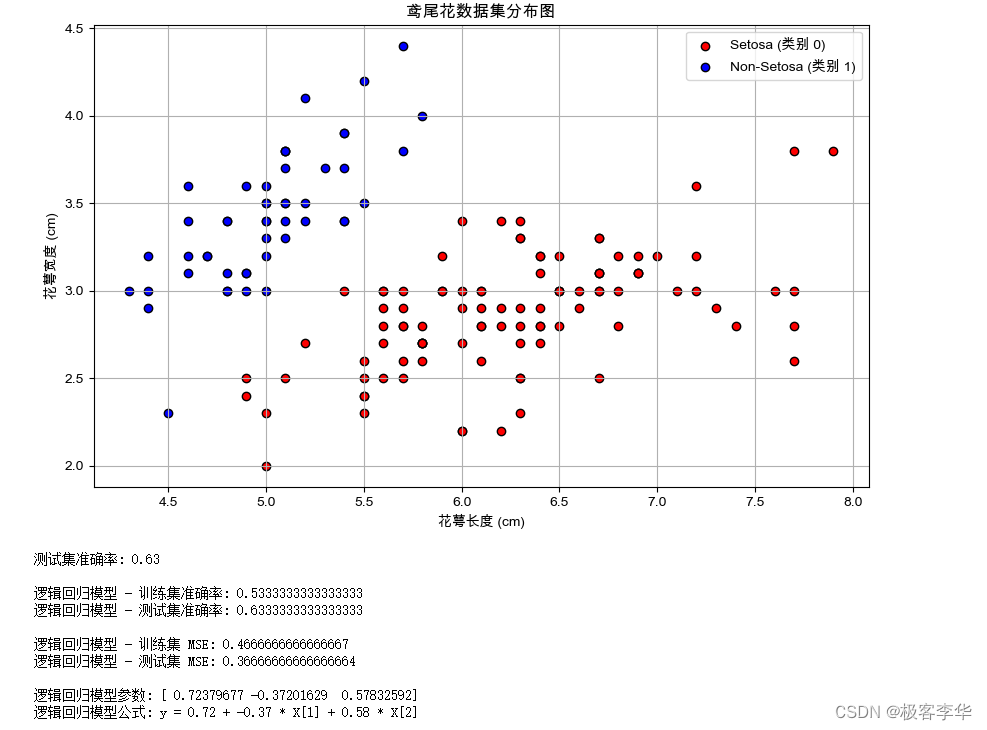
# 绘制鸢尾花数据集分布图
plt.figure(figsize=(10, 6))
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], label='Setosa (类别 0)', color='red', edgecolors='k')
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], label='Non-Setosa (类别 1)', color='blue', edgecolors='k')
# 横轴(X轴):花萼长度(单位:厘米)。花萼是鸢尾花的一个部分,位于花朵的底部,通常是一朵花的最外层。花萼长度是从花朵的底部到顶部的最长距离,以厘米为单位进行测量。
# 纵轴(Y轴):花萼宽度(单位:厘米)。花萼宽度是花萼在最宽处的宽度,以厘米为单位进行测量。
plt.xlabel('花萼长度 (cm)')
plt.ylabel('花萼宽度 (cm)')
plt.title('鸢尾花数据集分布图')
plt.legend()
plt.grid(True)
plt.show()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 简单的逻辑回归实现
class LogisticRegression:
def __init__(self):
self.weights = None
# Sigmoid函数
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
# 拟合(训练)逻辑回归模型
def fit(self, X, y):
num_samples, num_features = X.shape
self.weights = np.zeros(num_features + 1) # 初始化参数为0,加1是因为需要加上偏置项
X = np.hstack((np.ones((num_samples, 1)), X)) # 加入偏置项,即全部置为1
# 使用最大似然估计求解参数(此处没有使用梯度下降,而是直接求解参数)
self.weights = np.linalg.inv(X.T @ X) @ X.T @ y
# 预测新样本的类别
def predict(self, X):
num_samples = X.shape[0]
X = np.hstack((np.ones((num_samples, 1)), X)) # 加入偏置项
# 计算线性模型的输出,并将其通过Sigmoid函数转换为概率
linear_model = X @ self.weights
y_predicted = self.sigmoid(linear_model)
# 将概率值转换为类别标签(0或1)
y_predicted_cls = [1 if i > 0.5 else 0 for i in y_predicted]
return np.array(y_predicted_cls)
# 实例化和拟合逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测测试集样本的类别
y_pred_test = model.predict(X_test)
# 计算测试集准确率
test_accuracy = accuracy_score(y_test, y_pred_test)
print(f"测试集准确率: {test_accuracy:.2f}")
# 在训练集和测试集上进行预测
train_predictions = model.predict(X_train)
test_predictions = model.predict(X_test)
# 计算逻辑回归模型的准确率
train_accuracy = accuracy_score(y_train, train_predictions)
test_accuracy = accuracy_score(y_test, test_predictions)
print("\n逻辑回归模型 - 训练集准确率:", train_accuracy)
print("逻辑回归模型 - 测试集准确率:", test_accuracy)
# 计算MSE
train_mse = mean_squared_error(y_train, train_predictions)
test_mse = mean_squared_error(y_test, test_predictions)
print("\n逻辑回归模型 - 训练集 MSE:", train_mse)
print("逻辑回归模型 - 测试集 MSE:", test_mse)
# 输出训练得到的参数
print("\n逻辑回归模型参数:", model.weights)
# 输出逻辑回归模型的表达式
print("逻辑回归模型公式: y = ", end='')
for i, w in enumerate(model.weights):
if i == 0:
print(f"{w:.2f}", end='')
else:
print(f" + {w:.2f} * X[{i}]", end='')
print()
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode MS']
# 绘制逻辑回归模型的预测结果轮廓图
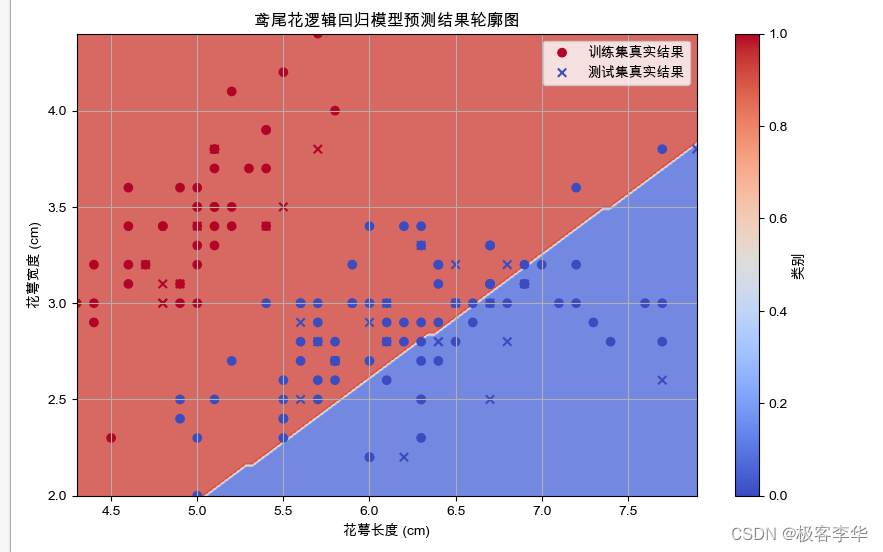
plt.figure(figsize=(10, 6))
# 生成网格点
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
# 使用模型预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制轮廓图
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
# 绘制训练集和测试集的真实结果
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='coolwarm', label='训练集真实结果')
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='coolwarm', marker='x', label='测试集真实结果')
plt.xlabel('花萼长度 (cm)')
plt.ylabel('花萼宽度 (cm)')
plt.title('鸢尾花逻辑回归模型预测结果轮廓图')
plt.colorbar(label='类别')
plt.legend()
plt.grid(True)
plt.show()
- 运行结果
- 运行结果分析
- 测试集准确率为0.63,这表示模型在未见过的数据上的预测准确率为63%。
- 训练集准确率为0.53,这表示模型在训练集上的预测准确率为53%。
- 训练集 MSE 为0.47,测试集 MSE 为0.37,这些是模型在训练集和测试集上的均方误差,即模型预测值与实际值之间的平方差的均值。
逻辑回归模型参数为:
- 偏置项为0.72。
- 特征1的系数为-0.37。
- 特征2的系数为0.58。
逻辑回归模型的表达式为: y = 0.72 − 0.37 × X [ 1 ] + 0.58 × X [ 2 ] y = 0.72 - 0.37 \times X[1] + 0.58 \times X[2] y=0.72−0.37×X[1]+0.58×X[2]
这个表达式描述了模型如何根据输入特征 X [ 1 ] X[1] X[1] 和 X [ 2 ] X[2] X[2] 来预测输出类别 y y y。
根据给定的参数:
- 偏置项为 0.72 (β₀ = 0.72)
- 特征1的系数为 -0.37 (β₁ = -0.37)
- 特征2的系数为 0.58 (β₂ = 0.58)
我们可以代入逻辑回归模型公式计算类别 0 和类别 1 的概率。
逻辑回归模型的公式为:
P ( 类别 0 ) = 1 1 + e − ( β 0 + β 1 × 特征1 + β 2 × 特征2 ) P(\text{类别 0}) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 \times \text{特征1} + \beta_2 \times \text{特征2})}} P(类别 0)=1+e−(β0+β1×特征1+β2×特征2)1
P ( 类别 1 ) = 1 − P ( 类别 0 ) P(\text{类别 1}) = 1 - P(\text{类别 0}) P(类别 1)=1−P(类别 0)
假设我们有以下特征值:
- 花萼长度 (特征1) = 5.0 cm
- 花萼宽度 (特征2) = 3.5 cm
代入公式进行计算:
P ( 类别 0 ) = 1 1 + e − ( 0.72 − 0.37 × 5.0 + 0.58 × 3.5 ) P(\text{类别 0}) = \frac{1}{1 + e^{-(0.72 - 0.37 \times 5.0 + 0.58 \times 3.5)}} P(类别 0)=1+e−(0.72−0.37×5.0+0.58×3.5)1
P ( 类别 1 ) = 1 − P ( 类别 0 ) P(\text{类别 1}) = 1 - P(\text{类别 0}) P(类别 1)=1−P(类别 0)
- 计算演示
首先,我们计算线性模型的输出:
z
=
β
0
+
β
1
×
特征1
+
β
2
×
特征2
z = \beta_0 + \beta_1 \times \text{特征1} + \beta_2 \times \text{特征2}
z=β0+β1×特征1+β2×特征2
z
=
0.72
−
0.37
×
5.0
+
0.58
×
3.5
z = 0.72 - 0.37 \times 5.0 + 0.58 \times 3.5
z=0.72−0.37×5.0+0.58×3.5
z = 0.72 − 1.85 + 2.03 z = 0.72 - 1.85 + 2.03 z=0.72−1.85+2.03
z = 0.72 − 1.85 + 2.03 = 0.9 z = 0.72 - 1.85 + 2.03 = 0.9 z=0.72−1.85+2.03=0.9
然后,我们将 z z z的值代入 sigmoid 函数计算类别 0 的概率:
P ( 类别 0 ) = 1 1 + e − z P(\text{类别 0}) = \frac{1}{1 + e^{-z}} P(类别 0)=1+e−z1
P ( 类别 0 ) = 1 1 + e − 0.9 P(\text{类别 0}) = \frac{1}{1 + e^{-0.9}} P(类别 0)=1+e−0.91
P ( 类别 0 ) ≈ 1 1 + e − 0.9 ≈ 1 1 + 0.4065697 ≈ 1 1.4065697 ≈ 0.7116 P(\text{类别 0}) ≈ \frac{1}{1 + e^{-0.9}} ≈ \frac{1}{1 + 0.4065697} ≈ \frac{1}{1.4065697} ≈ 0.7116 P(类别 0)≈1+e−0.91≈1+0.40656971≈1.40656971≈0.7116
最后,我们计算类别 1 的概率:
P ( 类别 1 ) = 1 − P ( 类别 0 ) P(\text{类别 1}) = 1 - P(\text{类别 0}) P(类别 1)=1−P(类别 0)
P ( 类别 1 ) = 1 − 0.7116 = 0.2884 P(\text{类别 1}) = 1 - 0.7116 = 0.2884 P(类别 1)=1−0.7116=0.2884
因此,根据给定的参数和特征值,类别 0 的概率约为 0.7116,而类别 1 的概率约为 0.2884。

















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











