






1.
# 用来单行注释
""" 用来多行注释 """
2.定义变量的格式
变量名 = 变量值
3. print("abc", num) 输出多个数据并换行
# print(内容1, 内容2, 内容3)
print(内容, end = '')
#加上end = ‘ ’后 不再进行换行操作
4.查看数据的类型使用 type(...)
5.Pyhton中特殊的运算符
// 表示取整除
# 例如: 9//2 = 4(得到的是整数部分)
/ 表示除法
# 例如: 5 / 2 = 2.5
**表示指数运算
# 例如 2**2 = 2的2次方= 4
6. Pyhton中的字符串定义可以用单引号,双引号,三引号
7.转义字符/可以解除特殊含义
8.
name = "大帅哥"
age = 18
print("我的名字是%s, 年龄是%d" % (name, age))
sum = "我的名字是%s, 年龄是%d" % (name, age) # 这也是合理的
9.
print(f"我是{name}, 我的年龄是{age}") # 这种方法不会对精度进行控制,适合在对精度无要求的=情况下使用
10. %5.2f 表示宽度设置为5 小数点的精度设置为2(会进行四舍五入)
11. num = input() 或者 num = input(请输入数字)
#数据输入的语句 input语句无论你输入的数据类型 均会当做字符串来对待
12. if 要判断的条件1 :
(四个空格) 条件1成立时,执行的语句
elif 要判断的条件2 :
(四个空格) 条件2成立时,执行的语句
else :
(四个空格) 条件不成立时,执行的语句
13.通过空格的缩进来进行判断语句的嵌套
14.随机数的产生
import random
num = random.randint(1,10) # 产生范围1-10内的一个随机整数
15.while循环
while 条件 :
条件符合执行的语句
16. range语句
① range(num) : 获取一个从0开始到num的数据集,不包含num
②range(num1, num2) : 获取一个从num1开始到num2的数据集,不包含num2
③range(num1, num2, step) :获取一个从num1开始到num2的数据集,但实际长度取决于step
17.for循环 (临时变量不必提前定义)
①for 临时变量 in 待处理数据集 (将数据集里面的数据挨个取出)
循环满足条件的时候执行的语句
②for 临时变量 in range(num) (for循环配合range语句使用)
循环满足条件的时候执行的语句
18.函数
def 函数名(参数)
函数执行的语句
return 返回值
格式:
def add(a, b) :
return a + b
def main() :
print(add(1,2)) # 调用add()函数
main() # 调用main函数
19.变量前加上global 代表全局变量
(在外部定义了一个变量num,在函数体内部加上global num 这时就会使两个global变成一个东西)
20.pyhton的容器类型:列表(list), 元组(tuple), 字符串(str), 集合(set), 字典(dict)
(1)(list)列表(可以储存不同的多个数据类型,列表的上限为 2 ** 63 - 1个,支持嵌套定义,内容可以重复)
①变量名称 = [元素1, 元素2, 元素3, 元素4....]
②空列表
变量名称 = []
变量名称 = list()
③利用下标索引进行访问
可以正向访问下标从0开始 从左往右
可以反向访问下标从-1开始 从右往左
④嵌套列表可以使用 list[0][1] 来访问
⑤方法的使用: list.方法()
⑥方法种类
list.index(num) 查找的元素的下标,若元素不存在会报错
list.insert(下标,元素) 在指定的下标位置插入指定的元素
list.append(元素) 在列表尾部追加一个元素
list.extend(其他数据容器) 将其他数据容器的元素追加在列表list后面
del list[下标] 删除制定下标的元素
list.pop(下标)将指定下标的元素取出并返回
list.remove(元素) 移除某元素在列表中的第一个匹配项
list.clear() 清空整个列表
list.count(元素) 统计元素在列表list中出现的次数
len(list) 计算列表的长度
(2)(tuple)元组(定义元组使用小括号,数据可以是不同的数据类型,元组不可以修改,内容可以重复)
①变量名称 = (元素1, 元素2, 元素3, 元素4....)
②空元组
变量名称 = ()
变量名称 = tuple()
③元组不可以修改 但是在元组里面嵌套了一个list后 可以对嵌套的list进行修改
④方法种类
tuple.index()
tuple.count()
len(tuple)
(3)(str)字符串 (只能存储字符串的类型, 长度任意,不可以修改,内容可以重复)
①变量名称 = “内容”
②支持下标访问,字符串是不可修改的
③方法种类
str.index()
str.count()
len(str)
str.replace(字符串1,字符串2)将str中的字符串1全部替换成字符串2
str.split(分隔符) 以分隔符来分割字符串 返回的是一个列表list
str.strip() 字符串的规整操作 去除字符串前后的空格
str.strip(字符串) 去除前后指定的字符串中的每一个字符
str.count(字符串) 统计字符串在str中出现的次数
len(str) 统计字符串的长度
--------------------------------------------------------------------------------
扩展 切片的操作(list, tuple,str均支持)
list[起始下标:终止下标:步长]
#终止下标可以用负数(-1,-2)来表示倒数第一个 倒数第二个等等
# list[1:4:2] 表示从1开始 到4结束 步长为2
# 如果省略起始下标和终止下标表示的是整个序列
#list[::-1] 这样可以进行序列的颠倒操作
--------------------------------------------------------------------------------
(4)(set)集合 (内容是无序的,不支持下标访问,允许修改,内容不可以重复)
①变量名称 = {元素,元素.......元素}
②空集合 变量名称= set()
③方法种类
set.add(元素) #向set中添加元素
set.remove(元素) #在set中移除元素
set.pop() #从set中随机取出一个元素
set.clear() #清空集合
set_1.difference(set_2) #得到一个新集合 里面装的是集合1里面有的但是集合2中没有的(集合1 和 集合2 没有改变)
set_1.difference_update(set_2) # 在集合1中删除与集合2相同的元素(集合1 发生了改变, 集合2 没有改变)
set_1.union(set_2) # 合并两个集合 得到一个新集合 (集合1 和 集合2 没有改变)
len(set)
④遍历操作(因为不支持下标访问 所以不能用while遍历)
for elem in set :
print(f"集合的元素有:{elem}")
(4)(dict) 字典(字典可以嵌套定义,key值不可以重复)
①dict = {key:value, key:value,........ key:value}
②空字典 my_dict = {} or my_dict = dict()
③不支持下标索引 但是支持key值索引
dict[key值] 得到的就是对应的value值
④嵌套定义示例
dict = { "A":{"语文" : 99, "数学" : 90, "英语": 100}, "B":{"语文" : 89, "数学" : 80, "英语": 82}, "C":{"语文" : 79, "数学" : 70, "英语": 77} }
⑤常用方法种类
dict[key] = value #当key不存在的时候表示新增元素 当key存在的时候表示修改元素
dict.clear() # 清空字典
dict.pop(key值) # 删除元素
dict.keys() # 得到字典的全部key值
len(dict) # 字典元素数量
⑥遍历字典
方法一
for key in dict.keys()
print(f"字典的key是{key}")
print(f"字典的value是{dict[key]}")
方法二
for key in dict
print(f"字典的key是{key}")
print(f"字典的value是{dict[key]}")
五类容器总结 列表(list), 元组(tuple), 字符串(str), 集合(set), 字典(dict)
① list用[]定义, tuple用()定义, set用{}定义, dict也用{}定义 但是里面的元素是一个键值对
②不支持修改:字符串(str), 元组(tuple)
③不支持重复元素: 集合(set), 字典(dict)
④
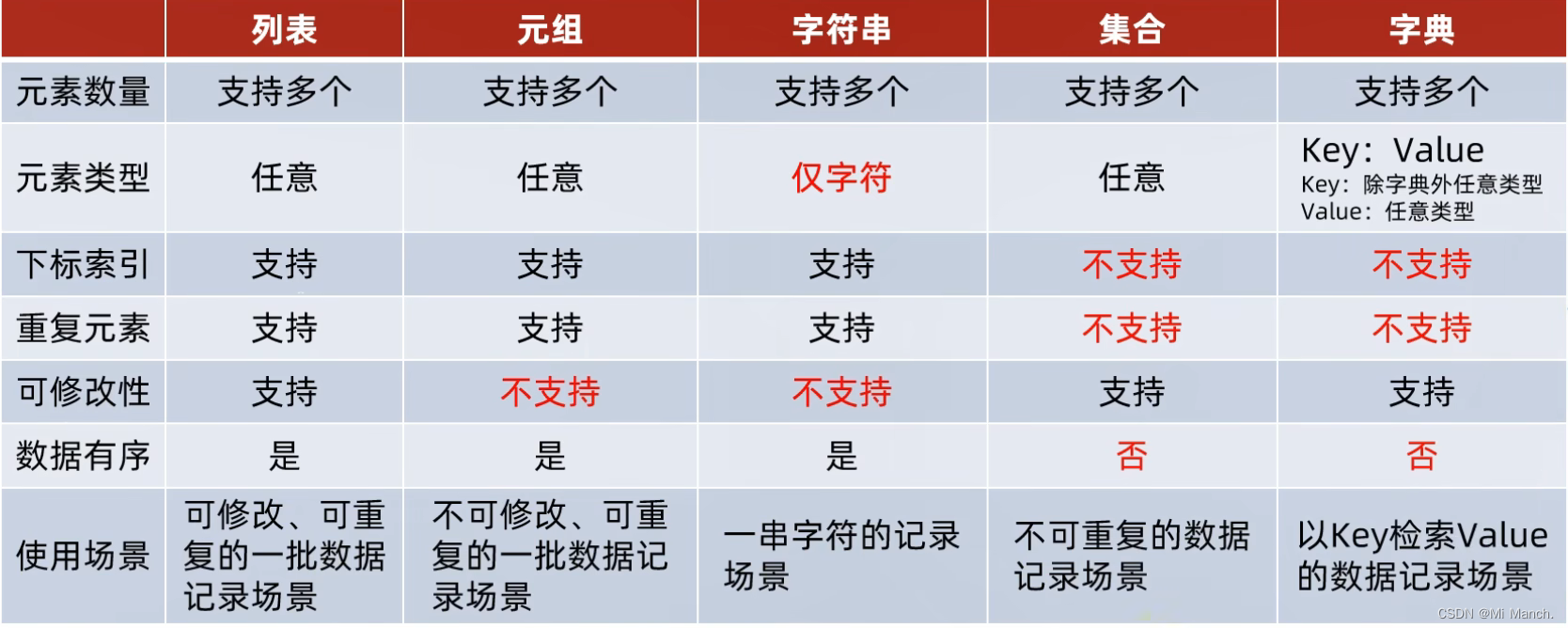
⑤五类容器都支持for循环遍历 ( for elem in 容器 : )
但是集合(set), 字典(dict)不支持while循环(因为不支持下标索引)
⑥容器的通用操作
Len(容器) #求容器的元素个数
max(容器) #求容器的最大元素
min(容器) #求容器的最小元素
str(容器) #将给定的容器转换为str 字典dict转成字符串value不会丢失 转成其他的会丢失
tuple(容器) #将给定的容器转换为tuple
set(容器) #将给定的容器转换为set
list(容器) #将给定的容器转换为list
sorted(容器, reverse = True) #reverse默认为FALSE,对内容进行排序并放在list容器中
列表.sort(key = 选择排序依据的函数,reverse = True|False)
- 函数的多个返回值
def func()
Return 1,”Helllo”,3
x,y,z = func()
- 函数传参方式
①可以通过位置对应传参数
②可以通过关键字对应传参 关键字对应传参过程中可以不按照位置进行传参
③不定长传参
方式1
def func(* args) #args就是一个元组类型的参数
print(args)
func(‘tom’)
func(‘tom’, 18)
方式2
def func(** kwargs) #kwargs就是一个字典类型的参数
print(args)
func(name = ‘tom’)
func(name = ‘tom’, age = 18)
注意:必须按照“键 = 值”的形式进行传参
- 函数作为参数传递
def func(compute)
result = compute(1,2)
print(result)
def compute(x, y)
retrurn x + y
func(compute)
24.
def关键字 定义带有名称的函数(可以重复使用)
lambda关键字 定义匿名函数(临时使用一次)
lambda 传入参数:函数体(只能写一行代码)
def func(compute)
result = compute(1,2)
print(result)
func(lambda x, y : x + y) #无法二次使用
25 .Python的文件操作
①文件打开(打开已经有的文件 或者 创建一个新的文件)
open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读r,写入w,追加a等

encoding:编码格式(推荐使用UTF-8)
例如:f = open(‘python.txt’, ’r’ , encoding = “UTF-8”)
②文件读操作
read(num) # num表示要读入的数据的长度,不传num表示读入全部信息
readline() #只读取文件中的一行内容
readlines() #按照行的模式对文件的内容进行一次性读取,并且返回的是列表
#注意上次读取文件结束的结尾是下次读取的开头
循环读取文件操作
for line in open (“python.txt”, “r”) #line中存储的就是文件中每一行的数据
print(line)
with open语法 (可以自动对文件进行关闭操作)
with open(“python.txt”, “r”) as f:
f.readlines()
③文件关闭操作
f.close()
④文件的写入
f.write(内容) #文件存在时会把文件中原有的内容全部清空
f.open(‘python.txt’, ‘w’)
f.write(“hello world”)
f.flush() #将缓冲区的文件存入到文本文件中
⑤文件的追加 #在文件的最后追加内容
#只需要在文件打开的时候将模式替换成a模式
f.open(‘python.txt’, ‘a’)
f.write(“hello world”)
f.flush()
f.close()
- 捕获异常语法
try :
可能发生错误的代码
expect :
如果真的出现了异常 应该执行的语句
else :
没有出现异常所执行的语句
finally :
无论是否出现异常均会执行的语句
- 模块的导入(下载模块加上-i Simple Index 速度会变快)
[from 模块名] import [模块 | 类 | 变量 | 函数 | * ] [as 别名]
# as后面紧接着的是他的别名

例如:
import time #通过time. 来使用里面所有的功能
from time import sleep #只能使用sleep的方法
form time import * #表示的是导入time这个里面的所有方法
#这个可以直接用sleep()来使用 不再需要用time.方法 来使用
- 自定义模块导入
只需要新建一个.py的文件 在里面写好方法 再import 该文件名就可以使用
注意_ _all_ _ = [函数名] 可以控制import *中导入的内容
- _ _main_ _
在pycharm这个软件中 我们如果进行import 的导包操作 会把该包的内容执行一遍
如果我们对.py的文件右键运行pycharm就会自动将内置的_ _name_ _赋值为 _ _main_ _
所以我们只需要加上 if _ _name_ _ == _ _main_ _ 就可以防止上述情况的发生
- json数据类型 #类型要么是字典 要么是列表中嵌套着字典
import json
json.dumps(s, ensure_ascii=False) #将python中的容器s转换为json类型
#加上ensure_ascii=False 可以正常显示中文
json.loads(s) #将json类型的s转换为列表list类型or字典dict类型
- 图表设计
pyecharts.org 是pyecharts的中文使用文档
gallery.pyecharts.org是一个画廊 里面有大量的图表展示
- 绘图
Line -> 条形图
Bar -> 柱状图
Map -> 地图
TimeLine -> 时间线图
- 类对象格式
class 类名字 :
类的属性(类内的变量)(成员变量)
类的行为(类内的函数)(成员方法)
def 方法名(self , 形参1, 形参2......)
方法体
创建一个对象 : 名字 = 类对象名字()
- 类的初始化函数
def _ _init_ _(self, name, age)
self.name = name
self.age = age
- python常用内置的方法(魔术方法)
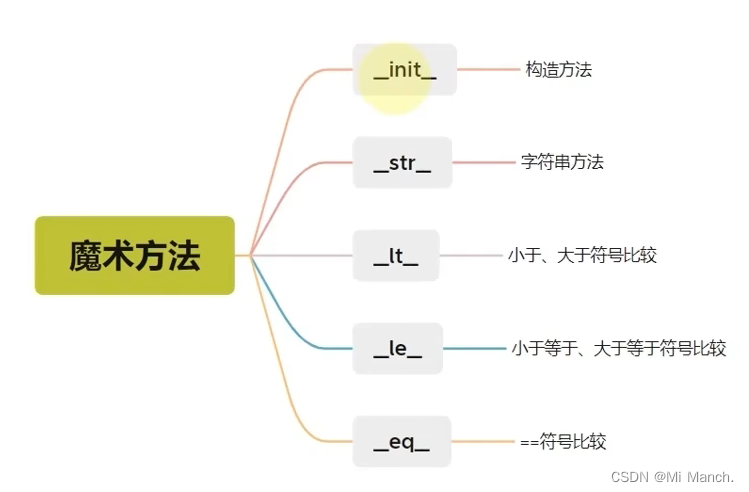
①_ _str_ _ :类对象转换为str(改变print(类名)所输出的东西)
②_ _lt_ _ : 定义 < 符号的比较方法,使得两个类可以进行比较(无法比较等于符号)
③_ _le_ _ : 定义 <= 符号的比较方法,使得两个类可以进行比较
④_ _eq_ _ : 定义=符号的比较方法(如果没有定义eq函数那么默认比较两个类的内存地址)
- 封装思想
在类中的成员变量or成员方法前加上_ _即可代表为私有变量
- 继承思想
class child( fathe1,father2....) : (继承只需要在后面加上括号 括号里面写上父类)
- 如果某个类在继承了多个父类后,自身不再需要添加新东西了,则可以在里面添加一个pass,以防止编译器报错
- 多继承的时候,如果有同名函数,那么就是先继承的优先
- 复写父类属性和方法时候,只需要重新定义父类中的属性或者方法
- 在复写了父类的方法或者成员后,在调用同名的时候优先子类的,但是如果你想要使用父类原有的成员或者函数,有以下两种方法
①父类名.成员变量 | 父类名.成员方法(self)
②super.成员变量 | super.成员方法()
- 不仅可以在变量后进行注解,也可以在注释中进行注解 # type : 类型
为变量设置类型注解
名称 :类型 = 赋值 num: int = 10
为类对象设置类型注解
stu:Student = Student()
为基础容器类型注解
my_list : list = [1,2,3] or my_list : list[int] = [1,2,3]
- 函数类型注解格式(不是强制要求)
def 函数名(形参1 : 类型, 形参2 : 类型.......) -> 返回值类型 :
函数体内容
- from typing import Union
my_list : list[Union[str,int]] = [1,2,”abc”] #利用联合体进行注解
- SQL语言
①sql语句对大小写不明感 sql语句仅支持单引号’ ’
②sql语句后必须要接分号;
③注释用法

④库管理的简单语句
show databases; # 查看数据库
use 数据库名称; # 使用数据库
create database 数据库名称[charset UTF-8] #创建数据库(中括号内的内容是可写可不写的)
drop database 数据库名称; #删除数据库
select database(); #查看当前使用的数据库
⑤数据的插入删除
insert 表[(列1, 列2, 列3....)] values(值1,值2,值3....)
insert student(id,name,age) values(4, '周杰伦',31), (5,'zw', 19);
delete from 表名称 [where 条件判断];
delete from student where id = 3;
update 表名 set 列=值[where 条件判断];
update student set name = '张学友' where id = 5;
46.在pyhton中操作数据库

47.PySpark实战
import os
os.environ['PYSPARK_PYTHON'] = "C:/Users/ZW/Python/python.exe"
这个是帮助编译器连接pyspark 防止编译器报错
①需要进行导包处理
from pyspark import SparkConf, SparkContext
创建SparkConf的对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
以后只需要用sc.方法来进行调用
②数据读入
将pyhton的数据容器转换成pyspark中的rdd类型需要使用parallelize(数据容器)
如果要读取rdd的内容,需要使用rdd.collect()
可以读取文件中的数据 需要使用rdd = sc.textFile(“文件地址”)
③map方法
rdd.map(传入函数)
作用是取出rdd中的每一个数值并将数值按照传入函数进行处理后返回
def func(a):
return a * 10
print(rdd.map(func).collect())
④flatmap与map方法功能相似, 但是flatmap可以解除一个嵌套的功能
⑤reduceByKey:针对kv型RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合
def func(a,b):
return a + b
print(rdd.reduceByKey(func).collect())
⑥Filter :过滤想要的数据并进行保留
⑦distinct:对rdd数据进行去重,返回新的rdd数据(不需要传入函数)
⑧sortBy: 对rdd数据进行排序,基于你指定的排序依据
rdd.sortBy(func, ascending = False, numPartitions = 1)
func:告知按照rdd中的哪个数据进行排序,比如lambda x : x[1] (按照第二个数进行排序)
ascending 表示是否进行升序排序
numPartitions表示使用多少分区进行排序
⑨reduce :将rdd进行两两聚合运算
⑩take():取出前n个元素,组合成list返回
⑪count:计算rdd中有多少条数据
⑫savaAsTextFile:将rdd的数据写入到文本文件中
⑬pyspark写入到文件中需要配置
os.environ[‘HADOOP_HOME’] = “Hadoop的解压地址”
48.闭包(由于内部函数持续引用外部函数的值,会导致一部分空间无法被释放)
简单闭包示例:
def outer(logo):
def inner(msg):
nonlocal logo # 加上nonlocal修饰后 就可以对logo进行修改了
print(f"<{logo}>{msg}”)
return inner
fn1 = outer("abc")
fn1("大家好")















 8670
8670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









