









文章目录
- 思维导图
- 第一阶段
- 第二阶段
- 第三阶段:PySpark案例实战
思维导图
Python基础知识图谱
面向对象
SQL入门和实战
Python高阶技巧
第一阶段
第九章:Python异常、模块与包
1.9.1异常的捕获
1.9.1.1 为什么要捕获异常

1.9.1.2 捕获常规的异常
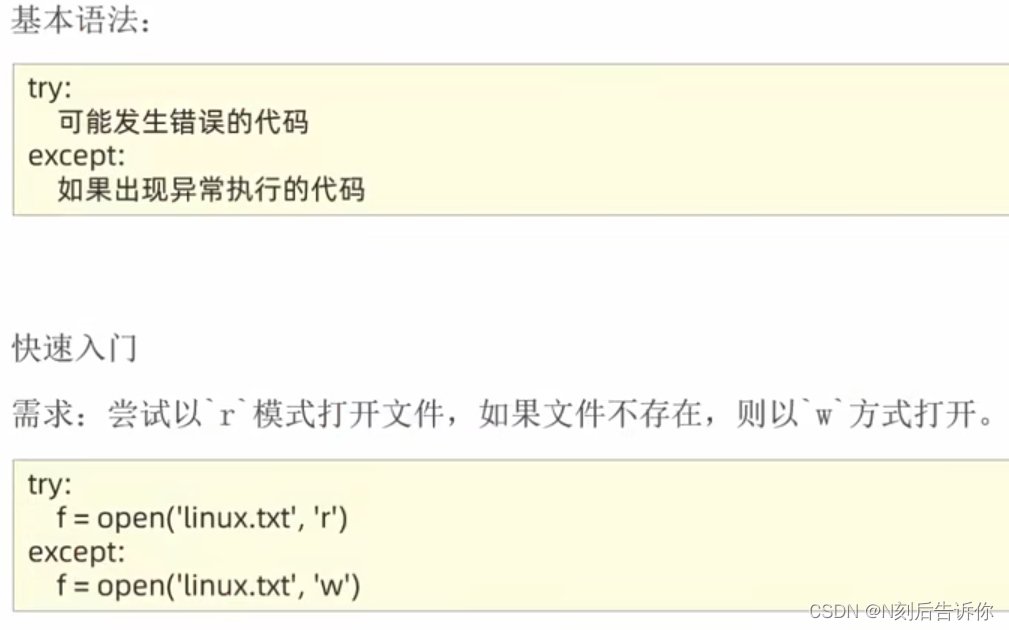
1.9.1.3 捕获指定的异常

e是接受异常信息的变量
1.9.1.4 捕获多个异常

1.9.1.5 捕获全部异常
try:
代码
except Exception as e:
处理异常
1.9.1.6 异常的else

1.9.1.7 异常的finally

1.9.2 异常的传递


如果异常是在某一层产生,但是没有被catch,那么会继续往上层抛出,此时这一层的后续代码就不会执行。直到异常在某一层被catch,这一层的后续代码能继续执行。
1.9.3 Python模块
1.9.3.1 什么是模块

1.9.3.2 模块的导入

一般不要用from 模块名 import *,因为这样相当于把模块里的全部代码都导入python程序内,可能会出现重名问题。
1.9.3.3 自定义模块
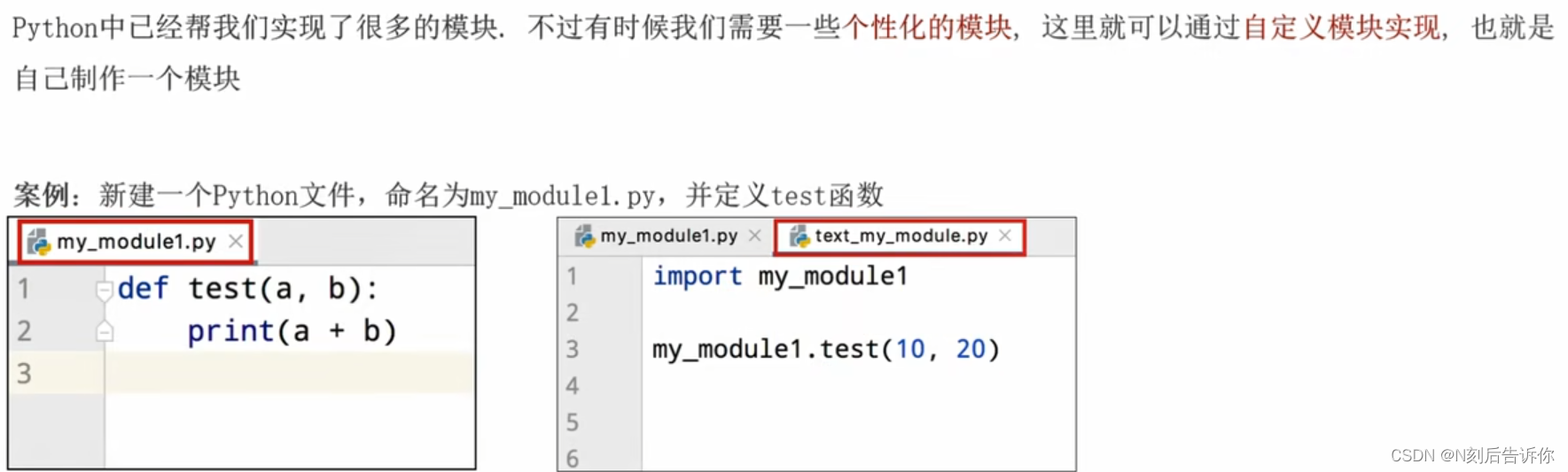
注意:当导入多个模块时,且模块内有同名功能。当调用这个同名功能时,调用的是后面导入的模块的功能。
- __main__

- __all__变量

指定导入不受__all__影响
1.9.4 Python包
1.9.4.1 什么是Python包
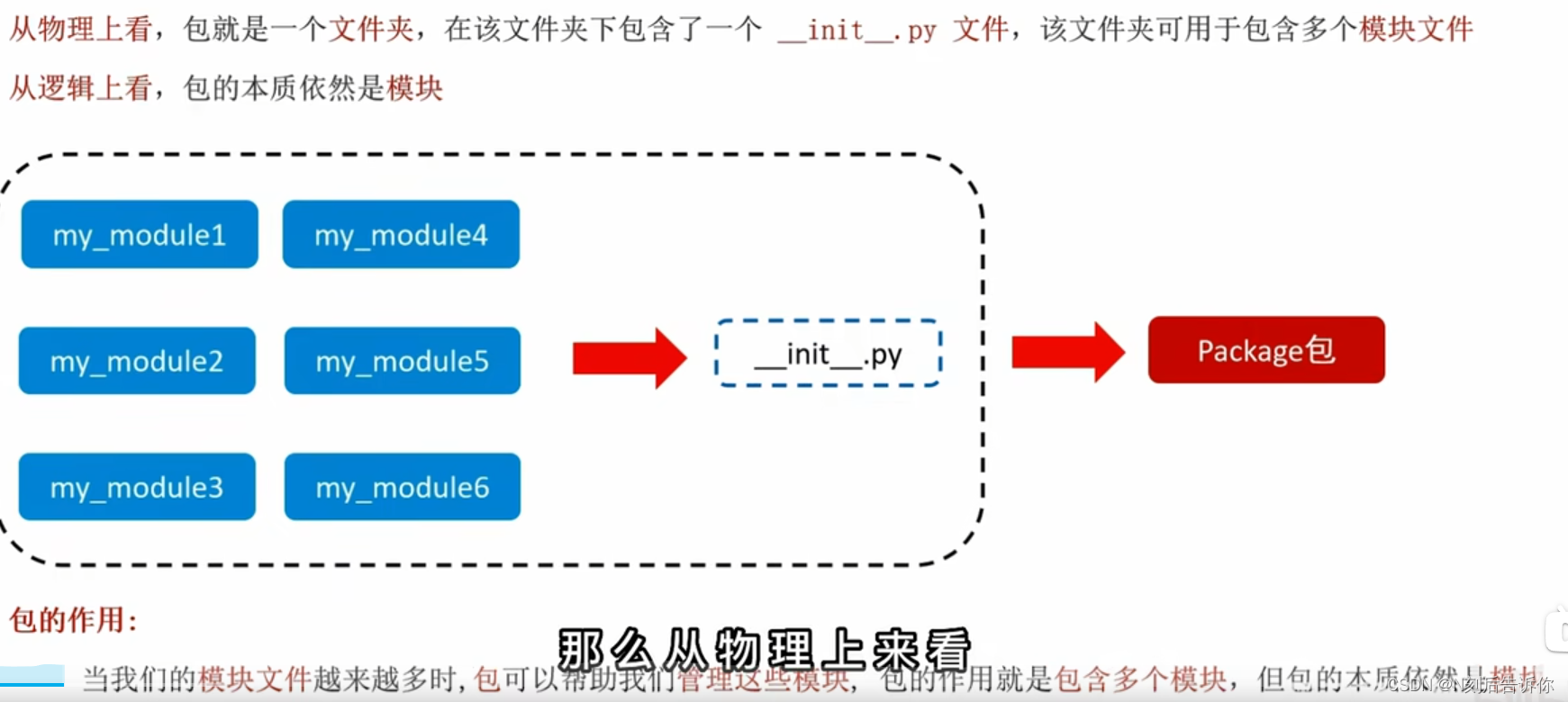
必须有__init__.py文件才是python包
1.9.4.2 导入包
- 方式一:
import 包名.模块名
包名.模块名.功能
from 包名 import 模块名
模块名.功能
from 包名.模块名 import 功能
功能
- 方式二:
必须在__init__.py文件中添加__all__ = [],来控制from 包名 import *允许导入的模块列表
1.9.4.3 安装第三方包

- 如何安装第三方包
pip install 包名
- pip的网络优化
pip默认连接国外的服务器下载包,可以通过命令在国内的镜像服务器下载包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
pycharm也可以在右下角“解释器设置”中添加新的python包,下载时可以添加option参数来通过国内镜像服务器下载包
第十章:数据可视化-折线图可视化
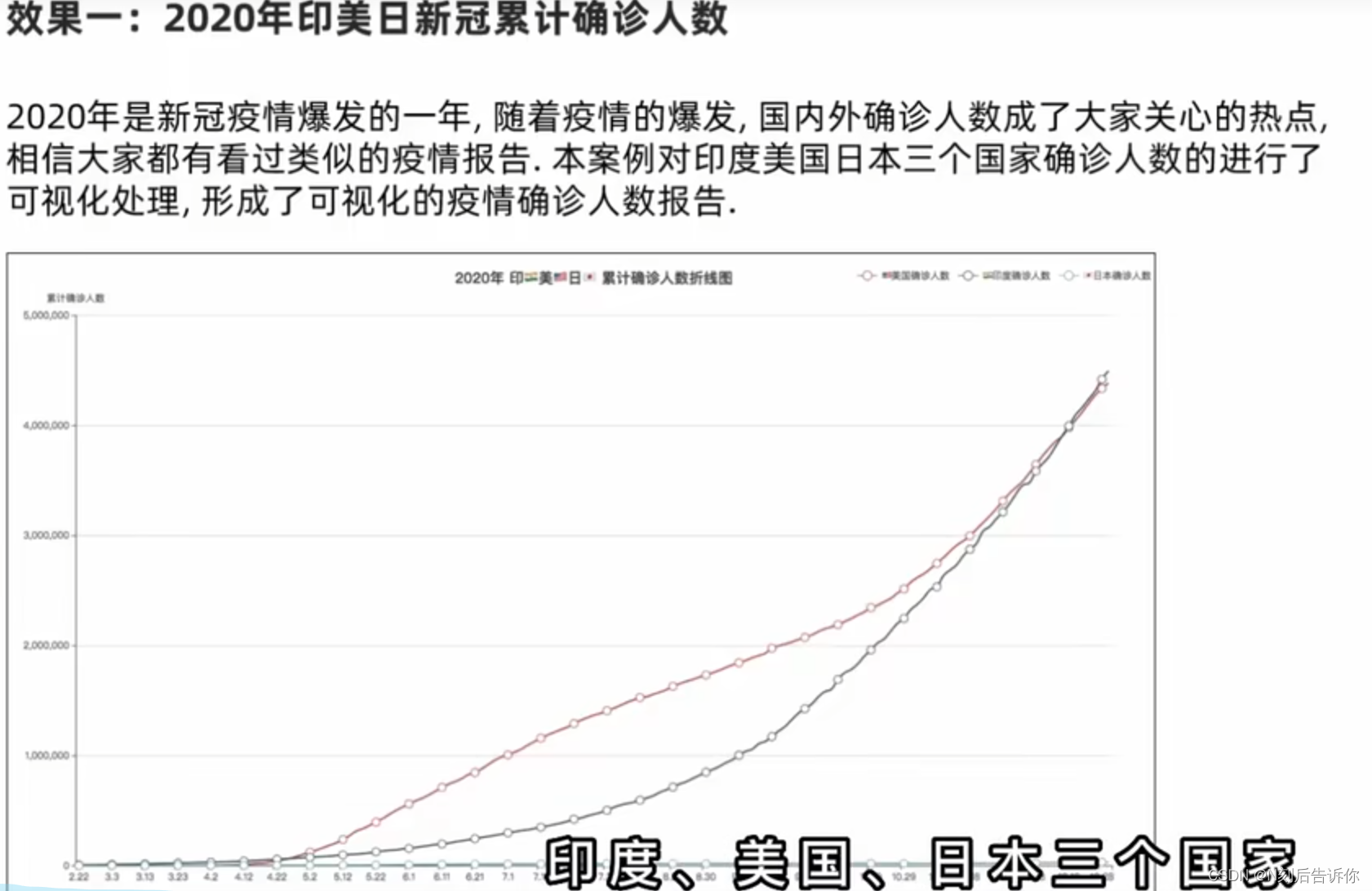
1.10.1 json数据格式


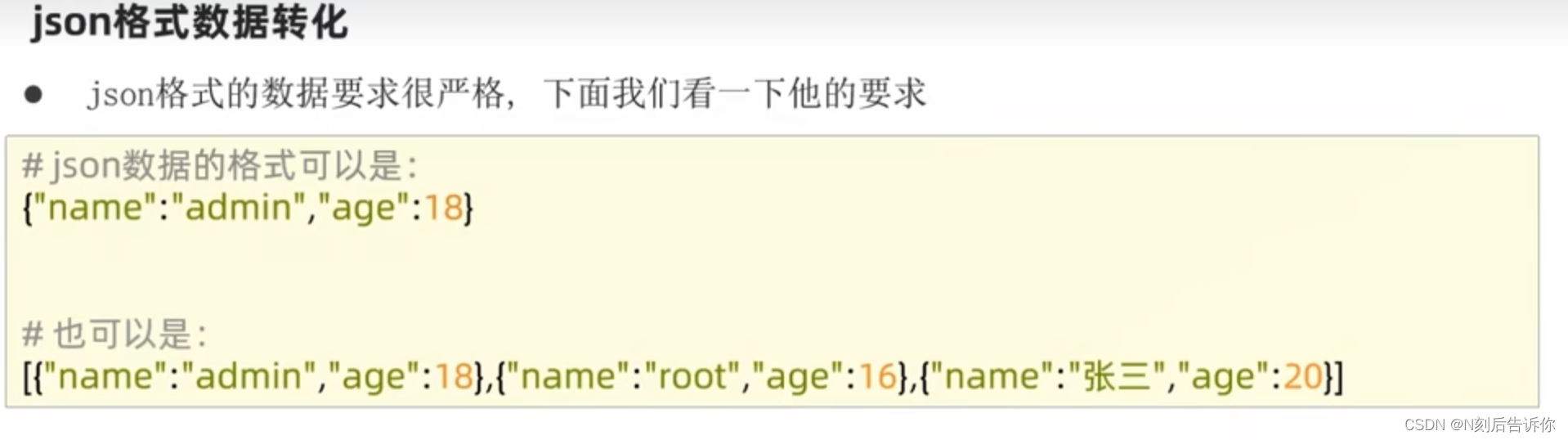
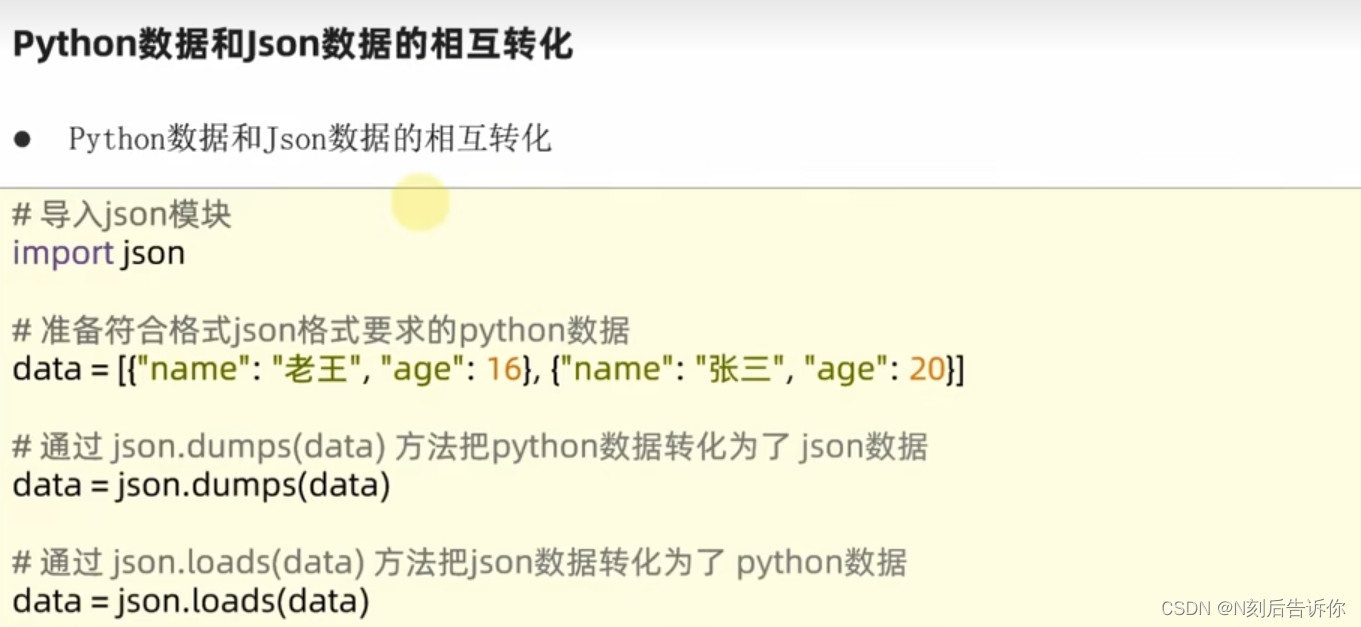
为了将含中文的python数据转化为json字符串,需要使用参数ensure_ascii为False,表明不使用ascii码进行转化,而把内容直接输出出去,为True,则中文会转化为Unicode的字符
json_str = json.dumps(data, ensure_ascii=False)
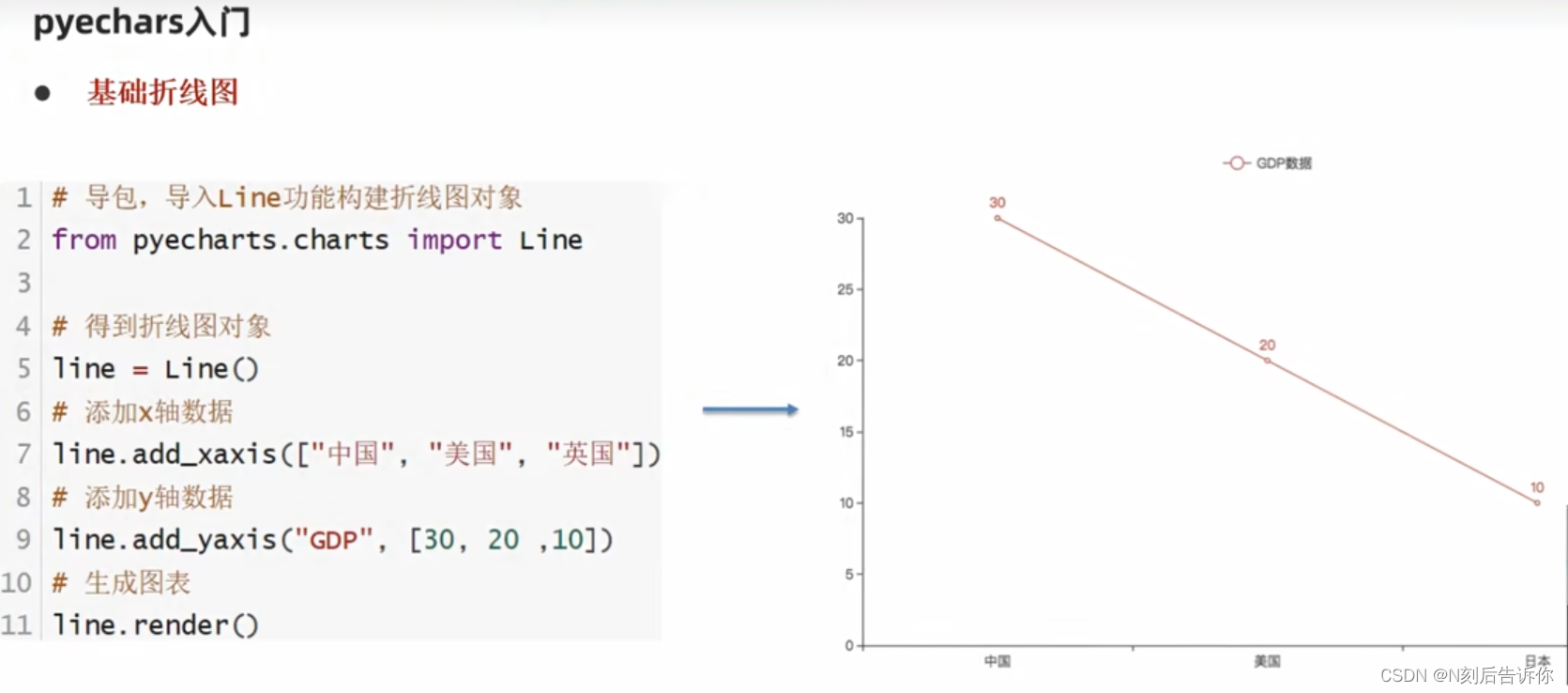
1.10.2 pyecharts模块
pyecharts官网:pyecharts.org
pyecharts画廊官网:gallery.pyecharts.org(类似美术的展览会)

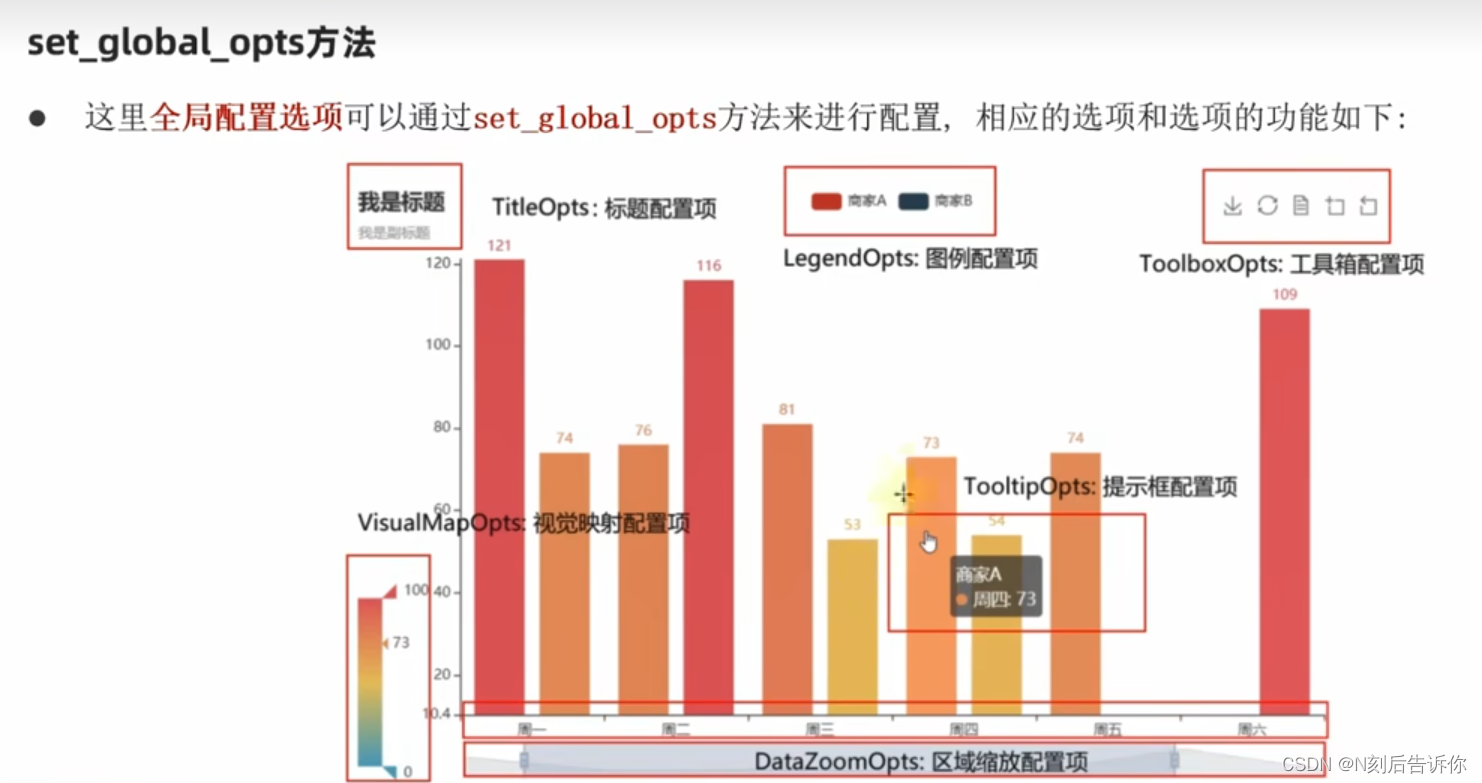
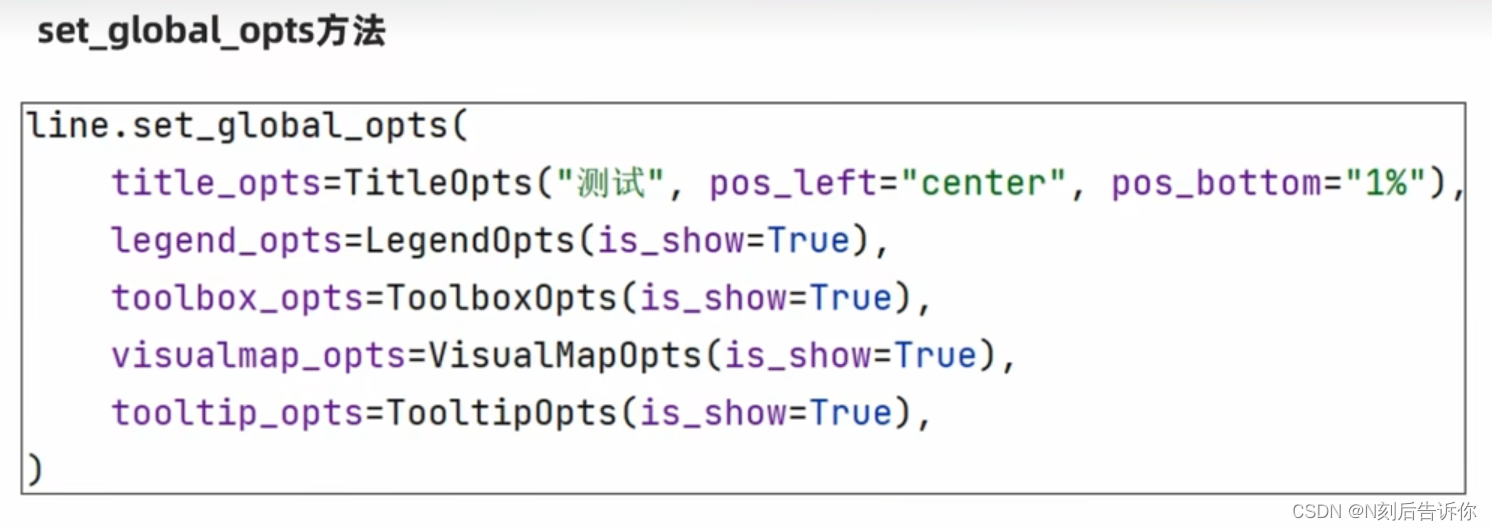
全局配置:针对图像进行设置,如标题、图例、工具箱
系列配置:针对具体轴数据进行设置
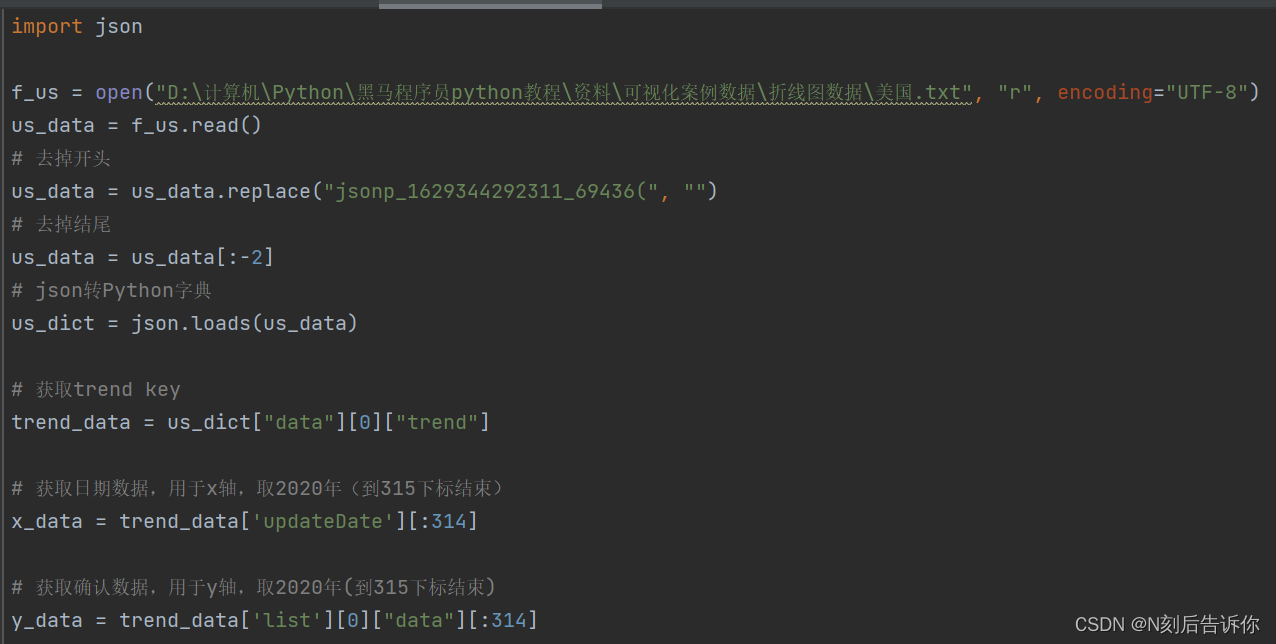
1.10.3 数据处理

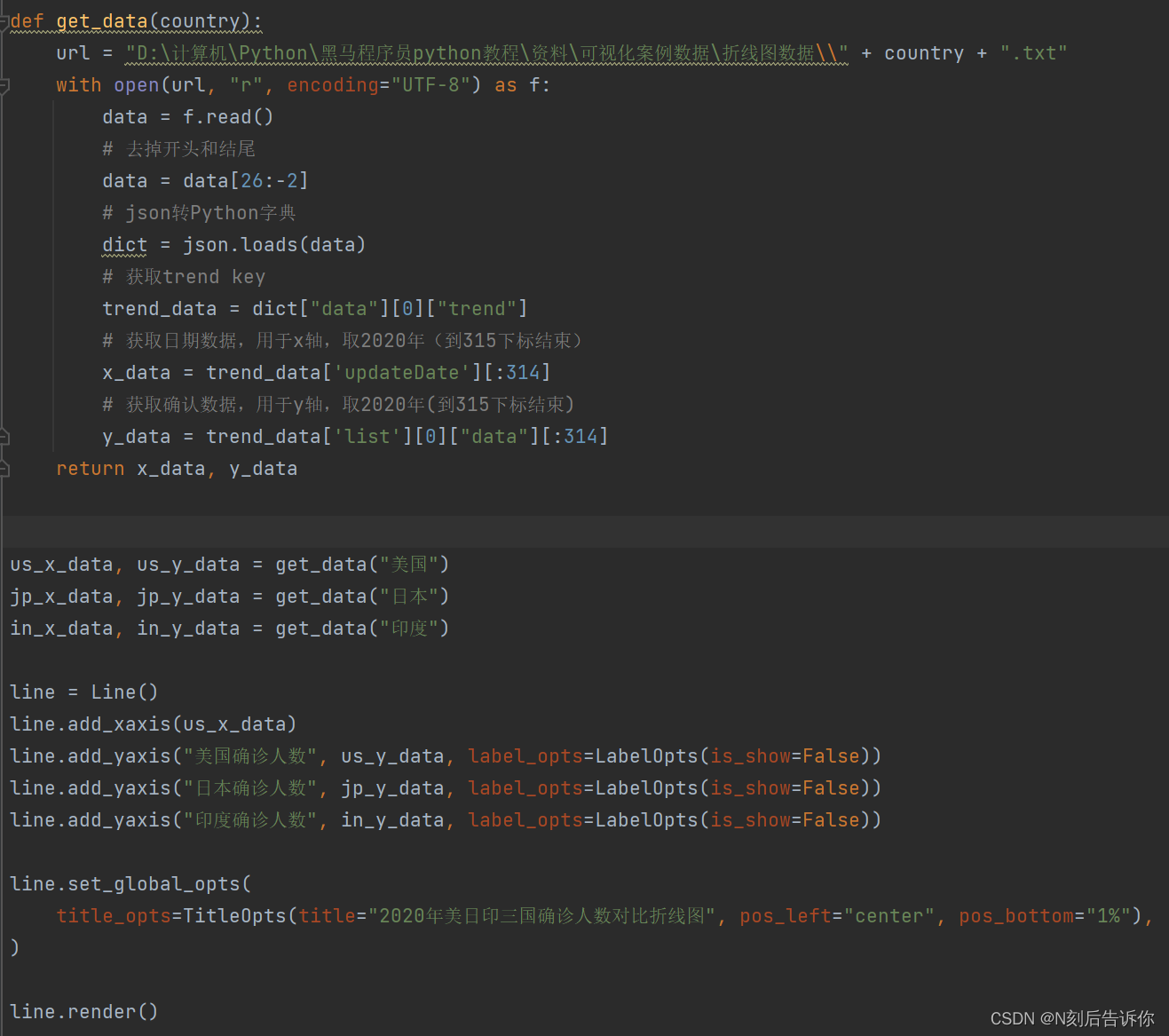
1.10.4 创建折线图
第十一章:数据可视化-地图可视化

1.11.1 基础地图使用
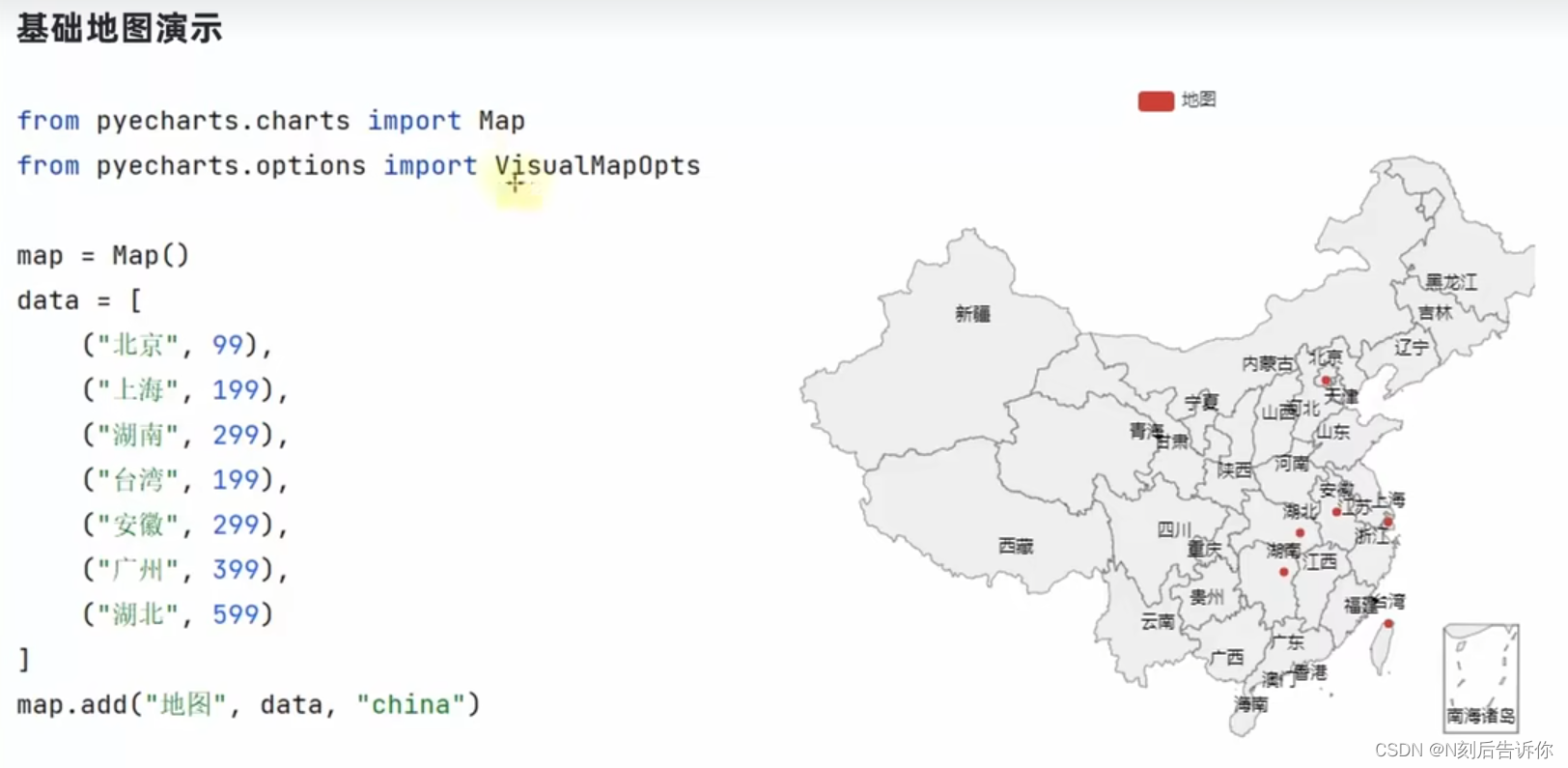
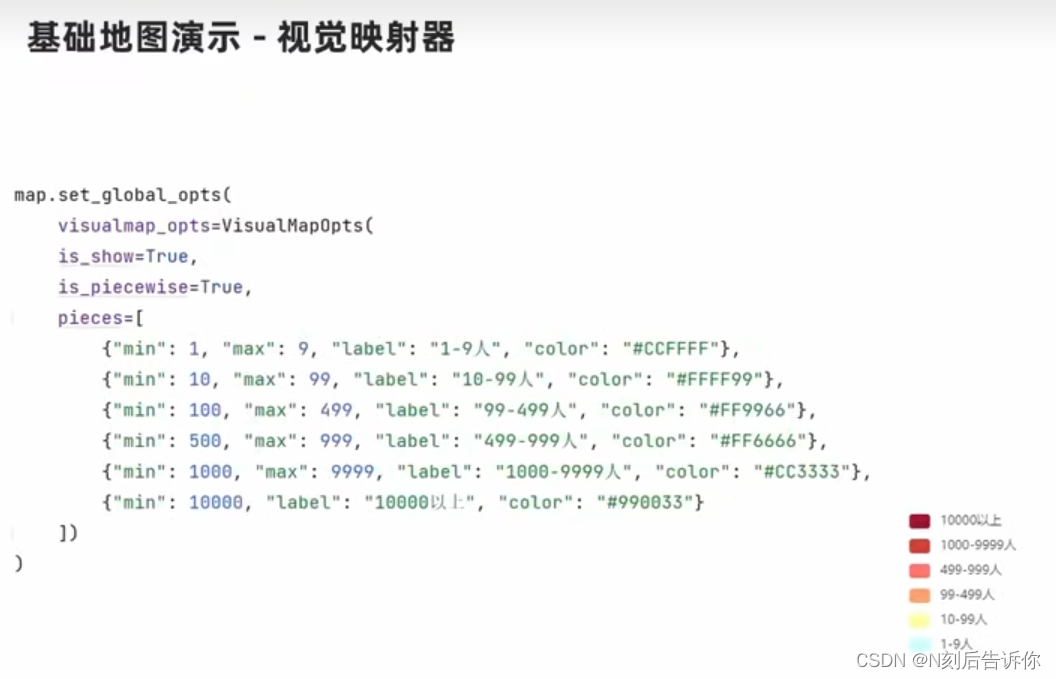
is_piecewise=True表示开始手动校准范围
pieces表示具体的范围是多少
可以通过ab173.com的前端rgb颜色对照表来查看某种颜色对应的16位的颜色代码
1.11.2 国内疫情地图
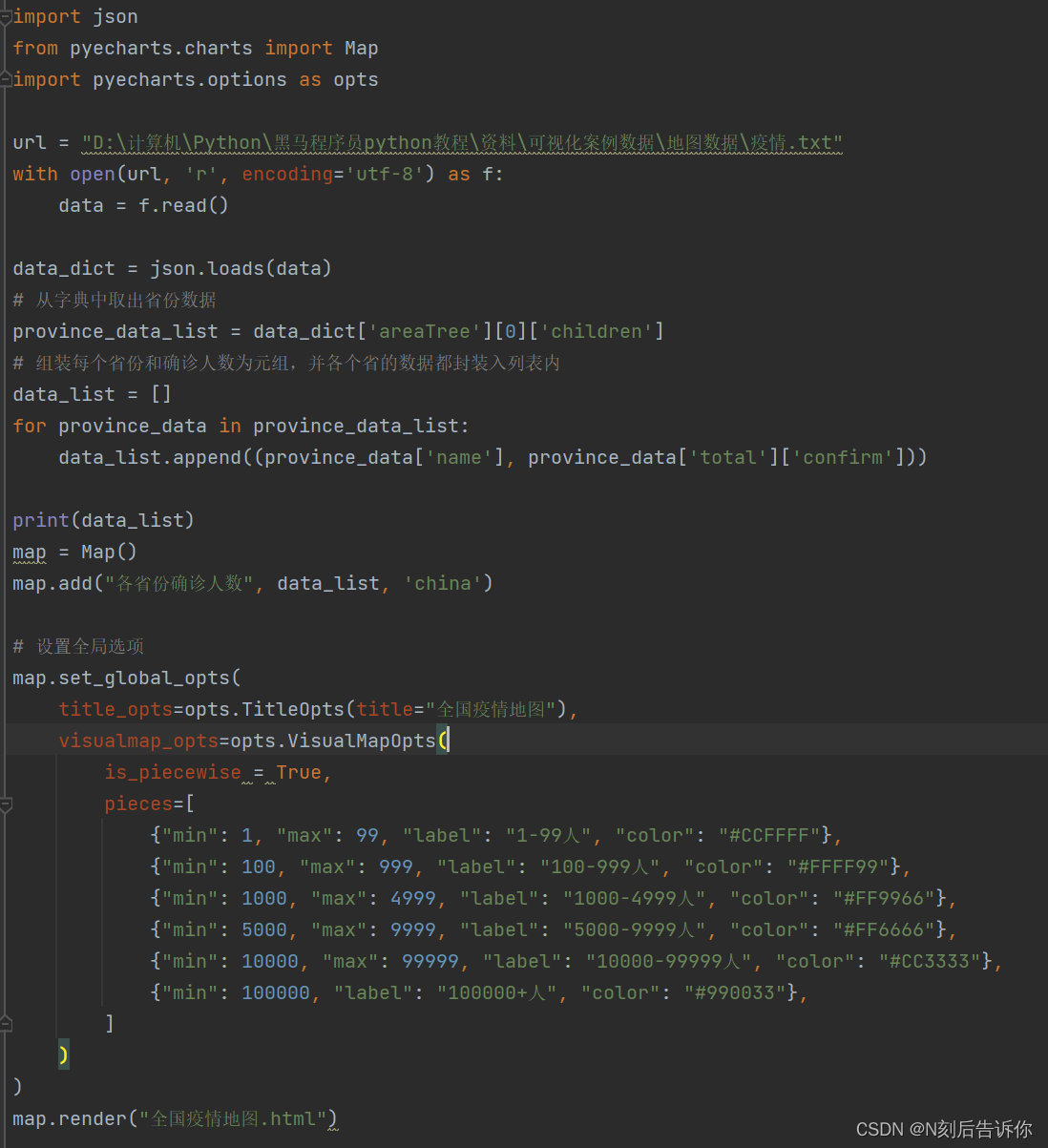
1.11.3 省级疫情地图-河南省
略
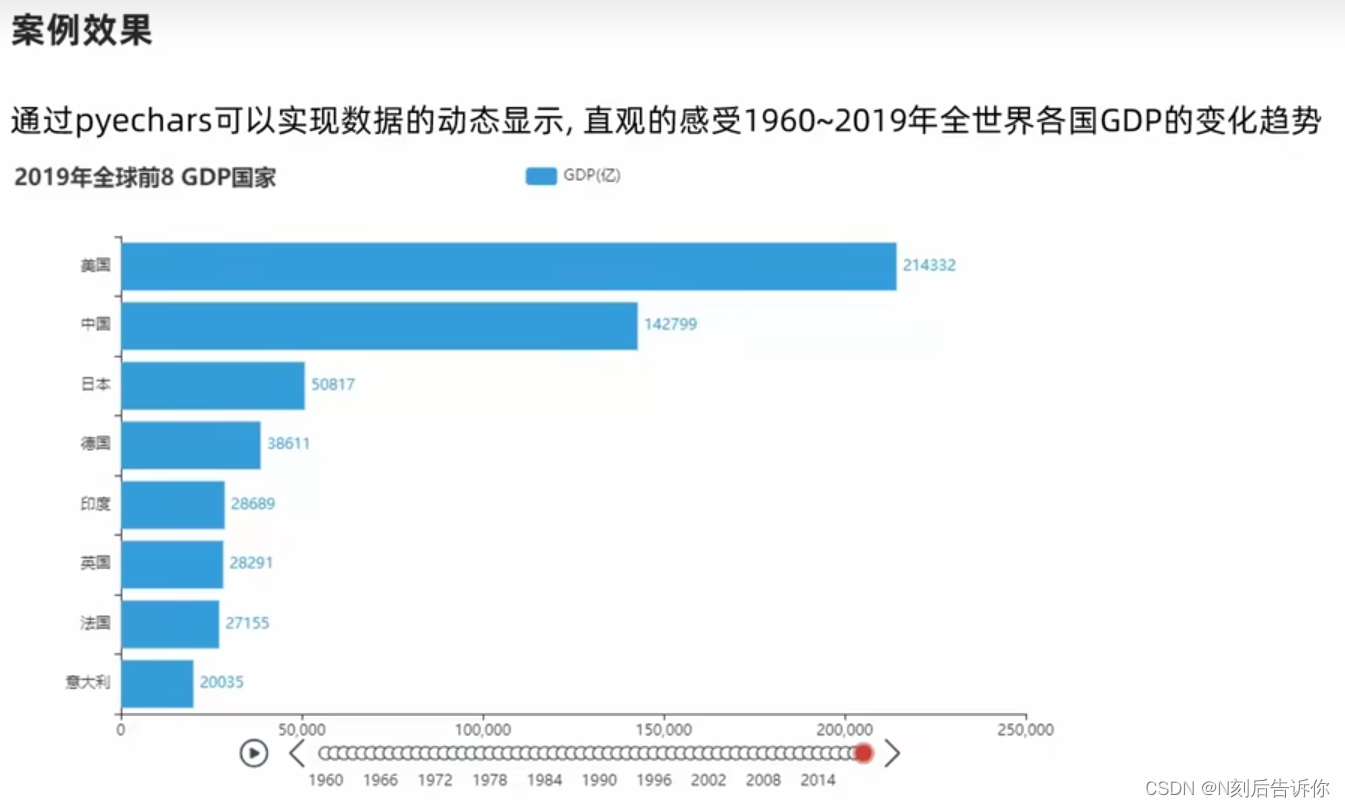
第十二章:数据可视化-动态柱状图
1.12.1 基础柱状图
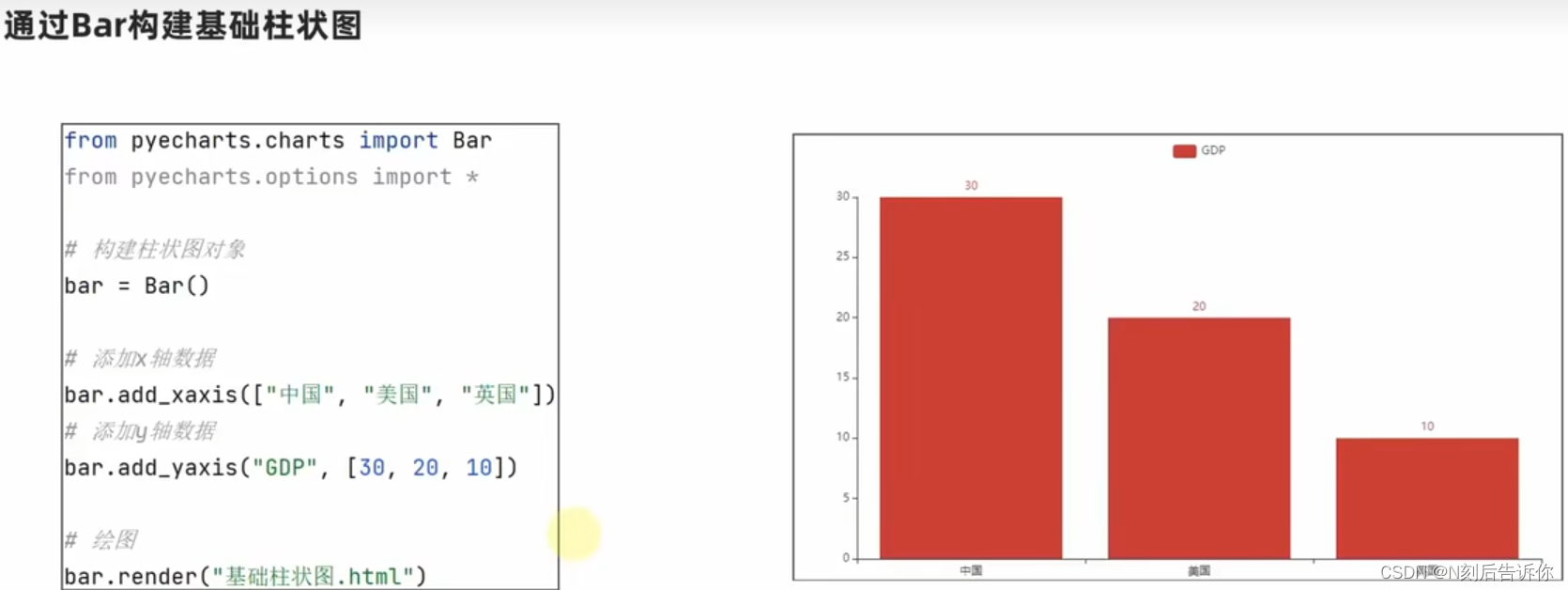
- 反转柱状图,同时将数值标签放在右边
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
bar.reversal_axis()
1.12.2 基础时间线柱状图
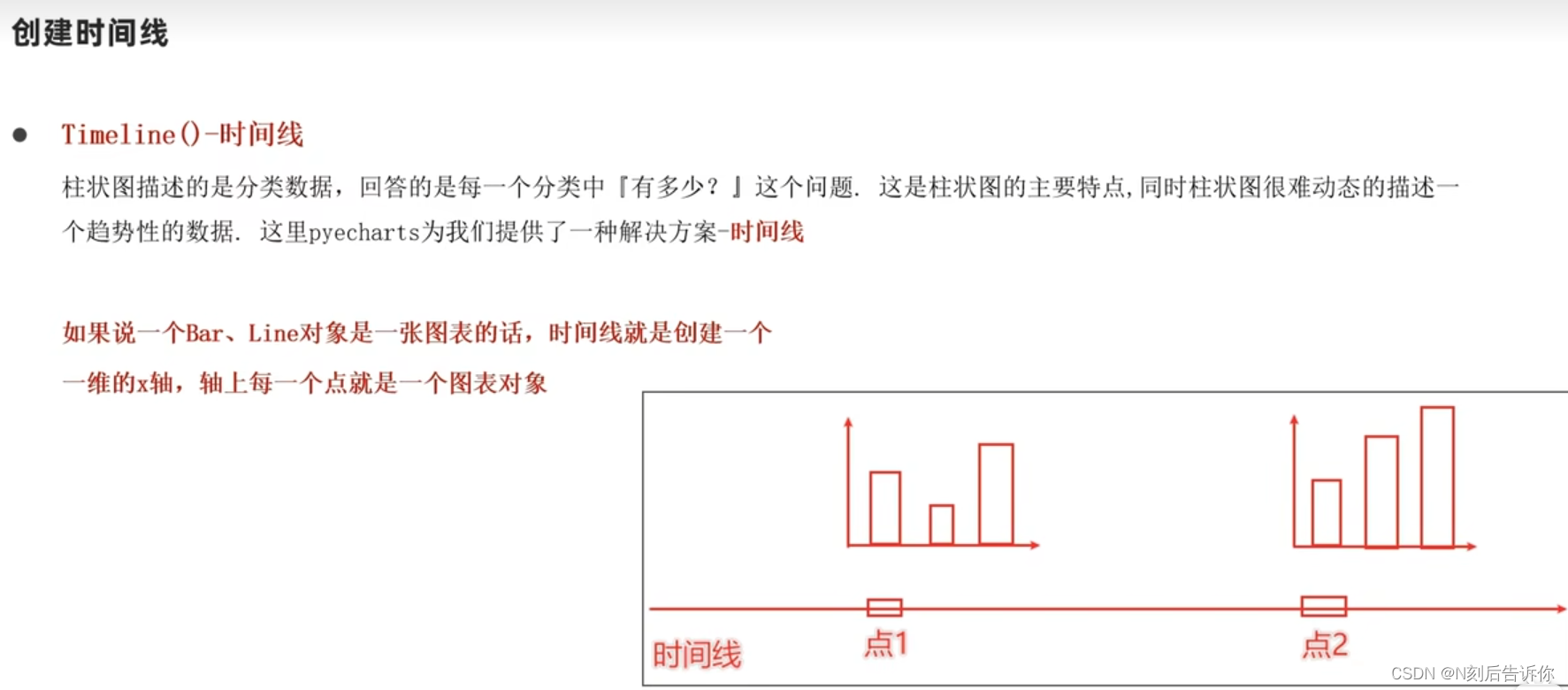

- 设置自动播放
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
- 时间线设置主题
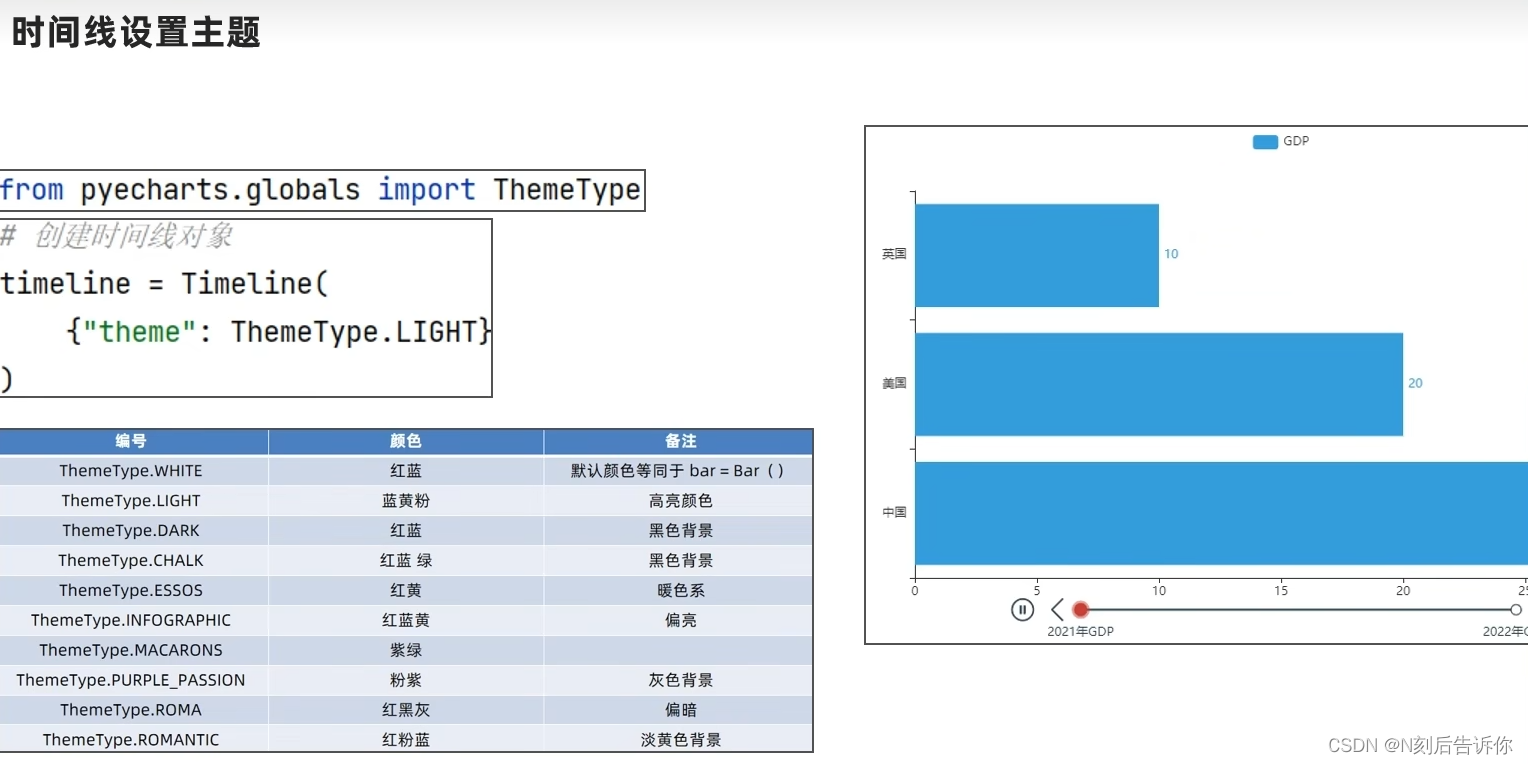
import pyecharts.globals import ThemeType
timeline = Timeline(
{"theme": ThemeType.LIGHT}
)
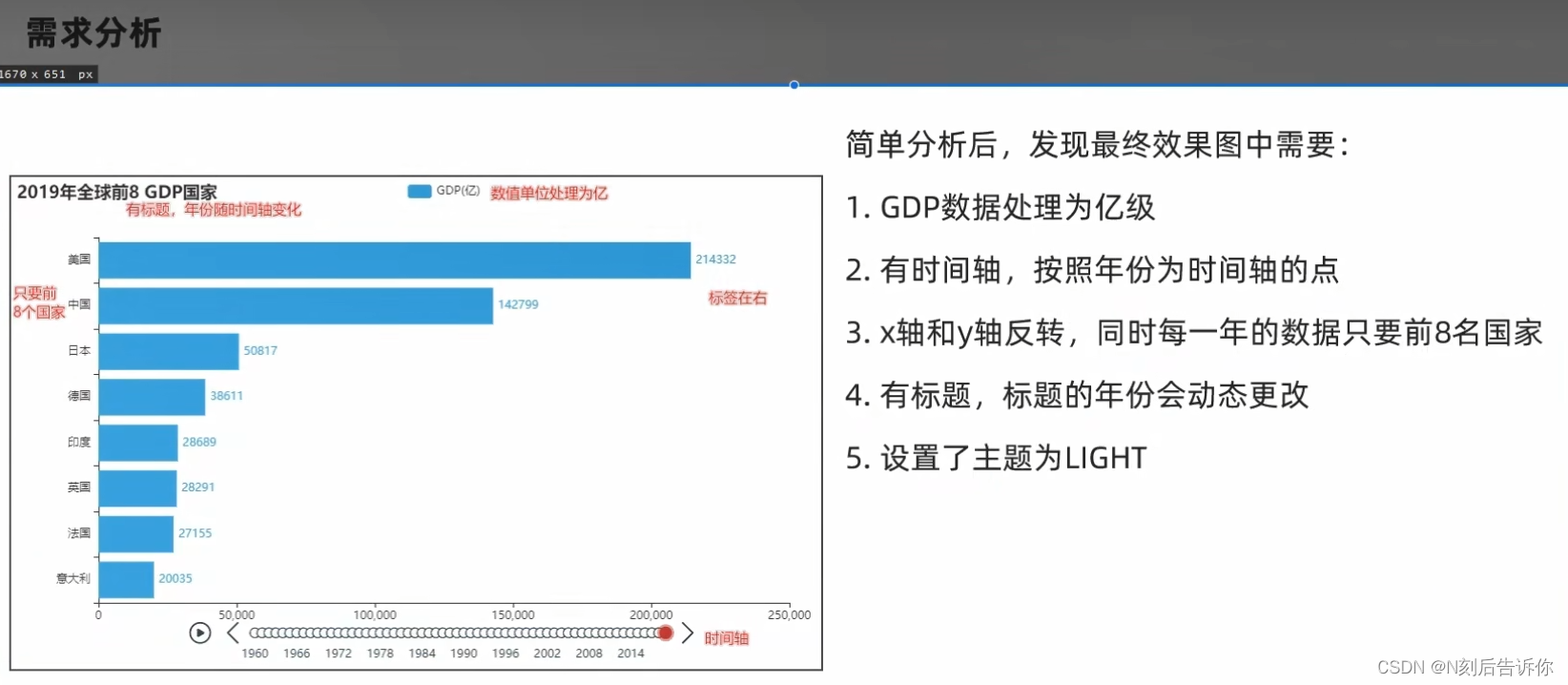
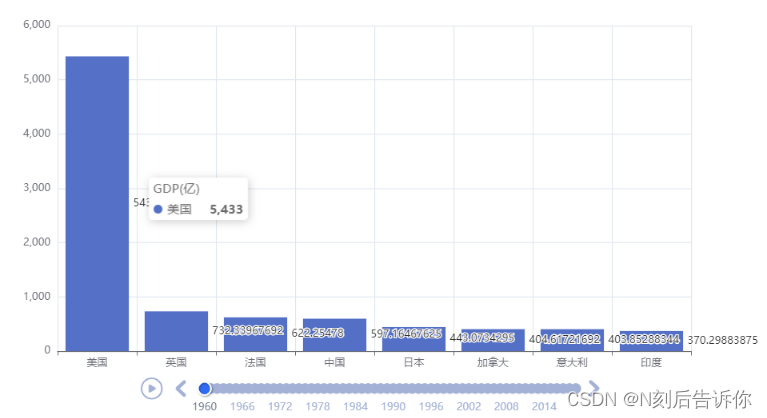
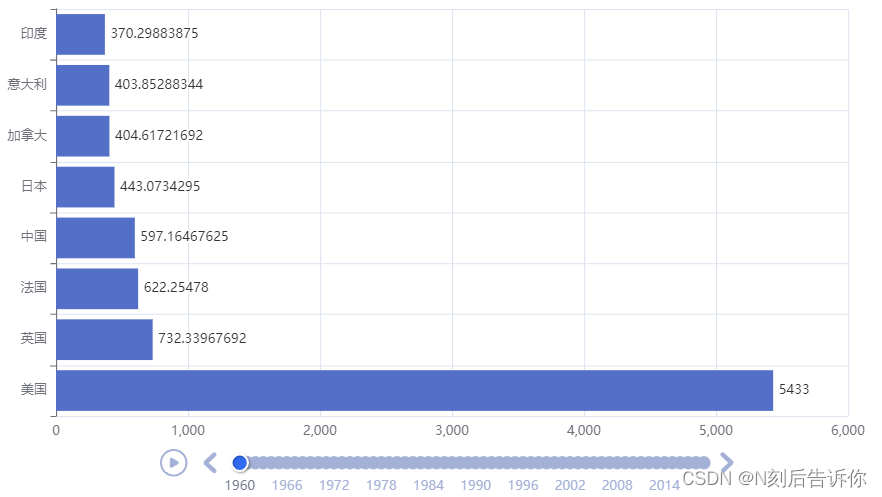
1.12.3 GDP动态柱状图绘制
1.12.3.1 列表的sort方法

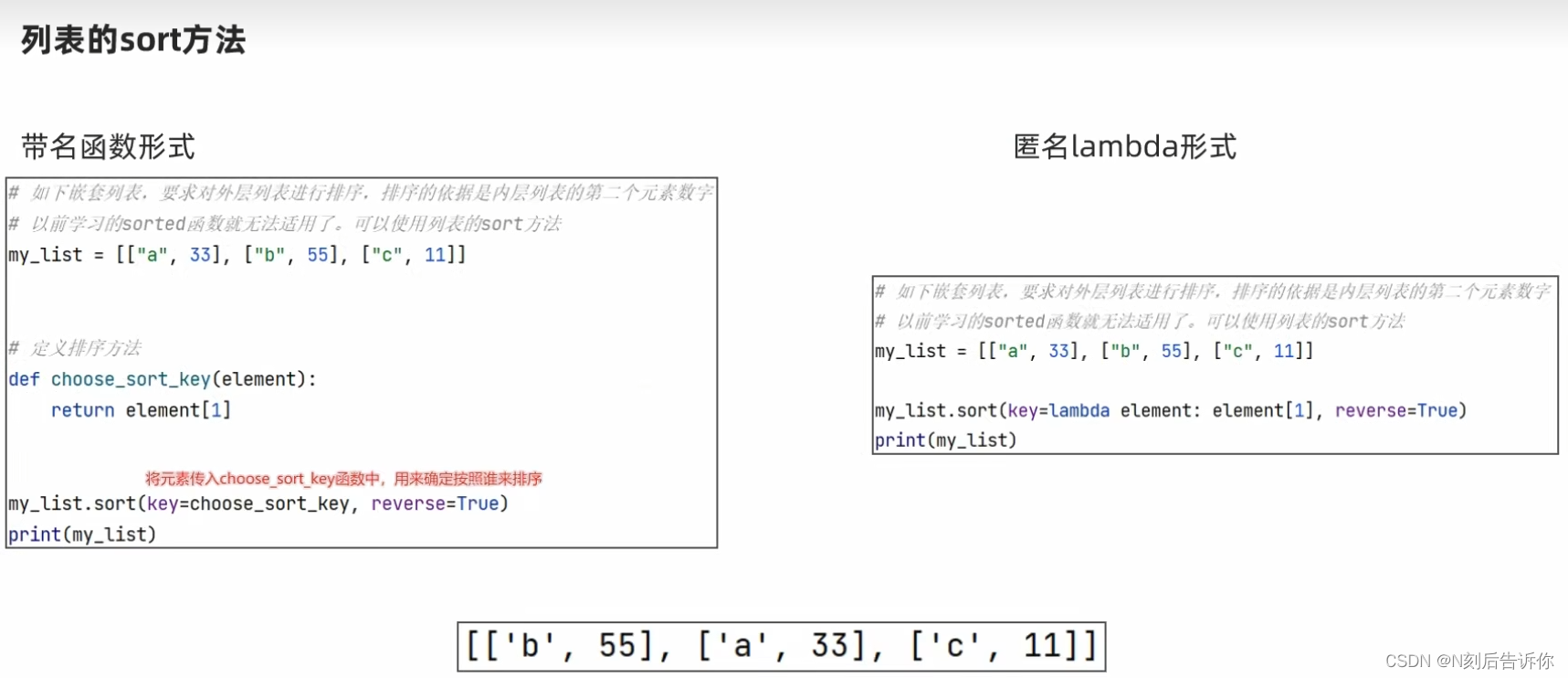
1.12.3.2 数据处理
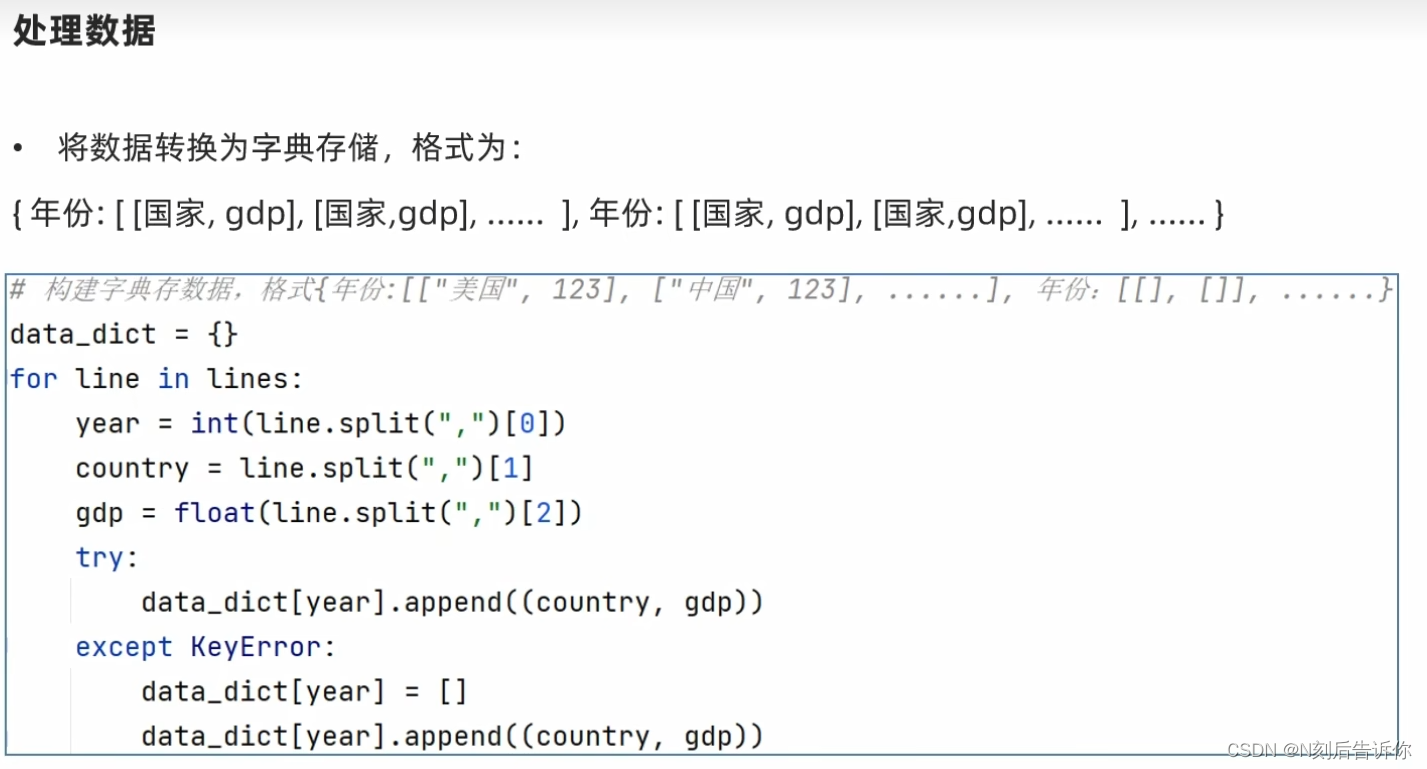
python3.6后,字典是有序的,参考:https://juejin.cn/post/7041433783362387982
由于bar.reversal_axis()会将从左到右从大到小变成从上到下,从小到大,所以在绘制柱状图之前需要将x_data和y_data都反转一下
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts, TitleOpts
from pyecharts.globals import ThemeType
with open("D:\计算机\Python\黑马程序员python教程\资料\可视化案例数据\动态柱状图数据\\1960-2019全球GDP数据.csv", "r", encoding="GB18030") as f:
data_lines = f.readlines()
data_lines.pop(0)
data_dict = {}
for line in data_lines:
line_list = line.split(",")
year = int(line_list[0])
country = line_list[1]
gdp = float(line_list[2])
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = [[country, gdp]]
timeline = Timeline(
{"theme": ThemeType.LIGHT}
)
for year in data_dict:
data_dict[year].sort(key = lambda x: x[1], reverse=True)
year_data = data_dict[year][:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0])
y_data.append(country_gdp[1] / 1E8)
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
bar.reversal_axis()
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
)
timeline.add(bar, str(year))
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
timeline.render("1960-2019全球GDP前8国家.html")
第二阶段
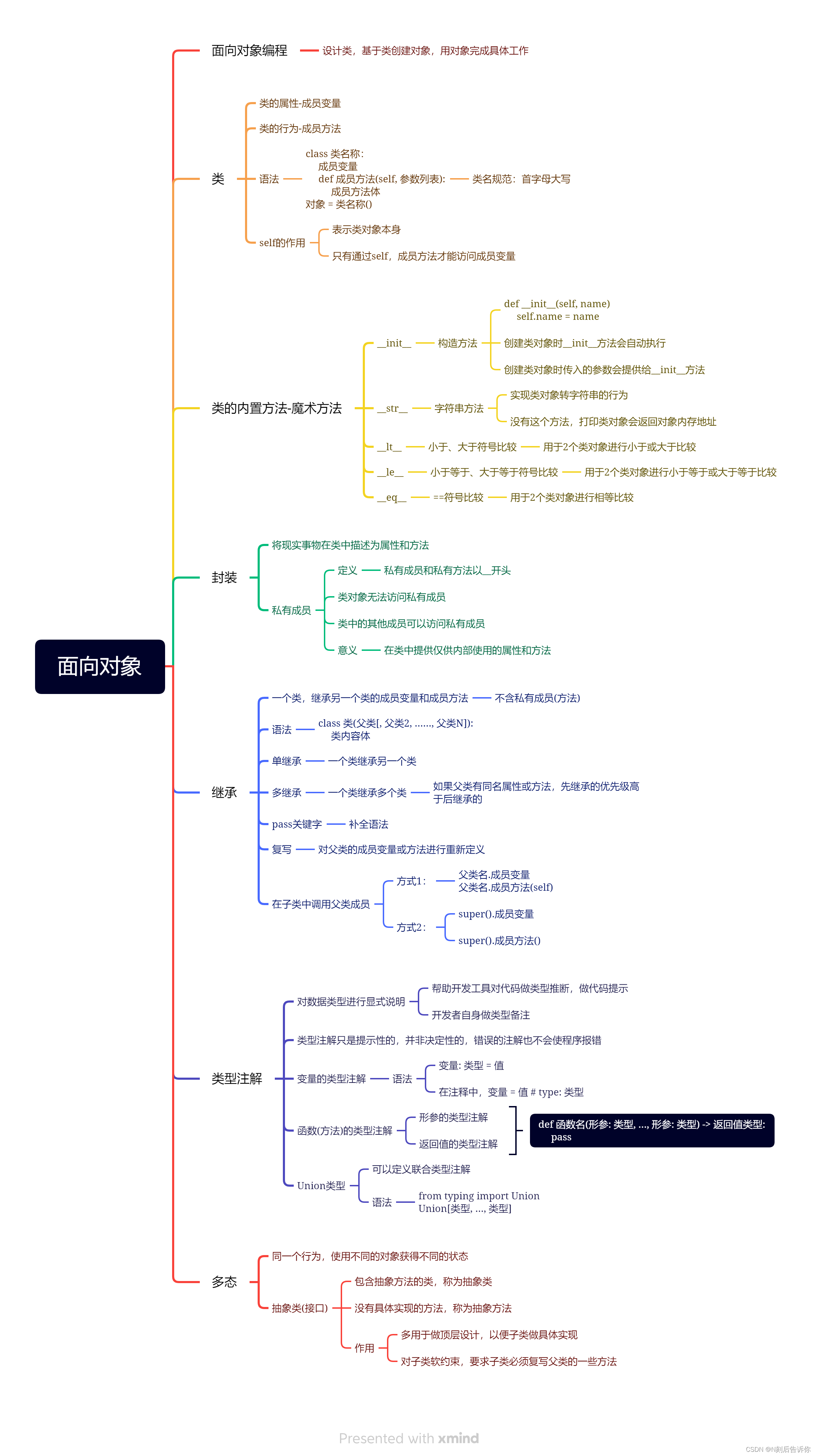
第一章:面向对象
2.1.1 初识对象

2.1.2 类的成员方法

定义在类内部的函数称之为类的方法
self相当于以后会创建但在定义类时还不存在的对象

2.1.3 类和对象

面向对象编程:设计类,基于类创建对象,由对象做具体的工作
2.1.4 构造方法

2.1.5 其他内置方法-魔术方法

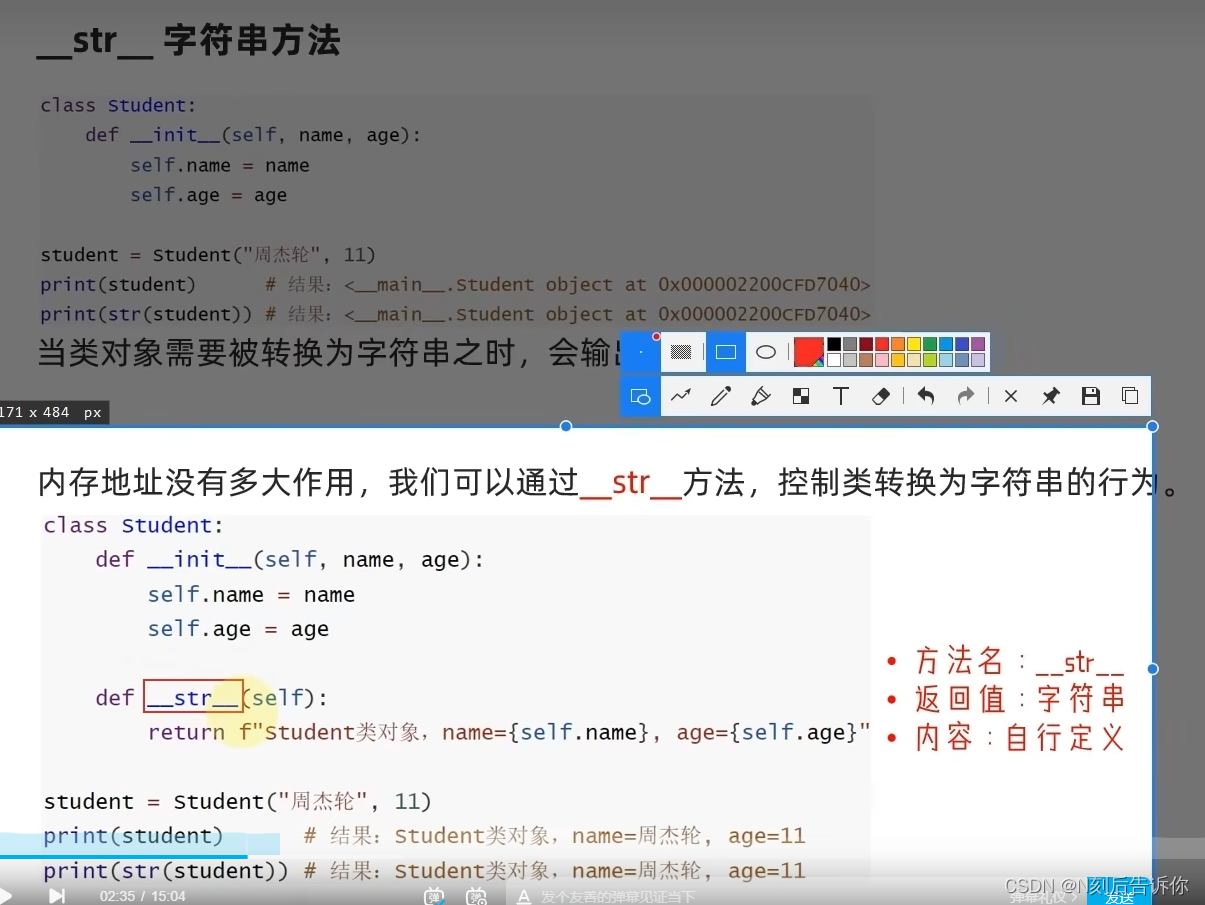
2.1.5.1 __str__字符串方法
2.1.5.2 __lt__小于符号比较方法

2.1.5.3 __le__小于等于比较符号方法

2.1.5.4 __eq__比较运算符实现方法

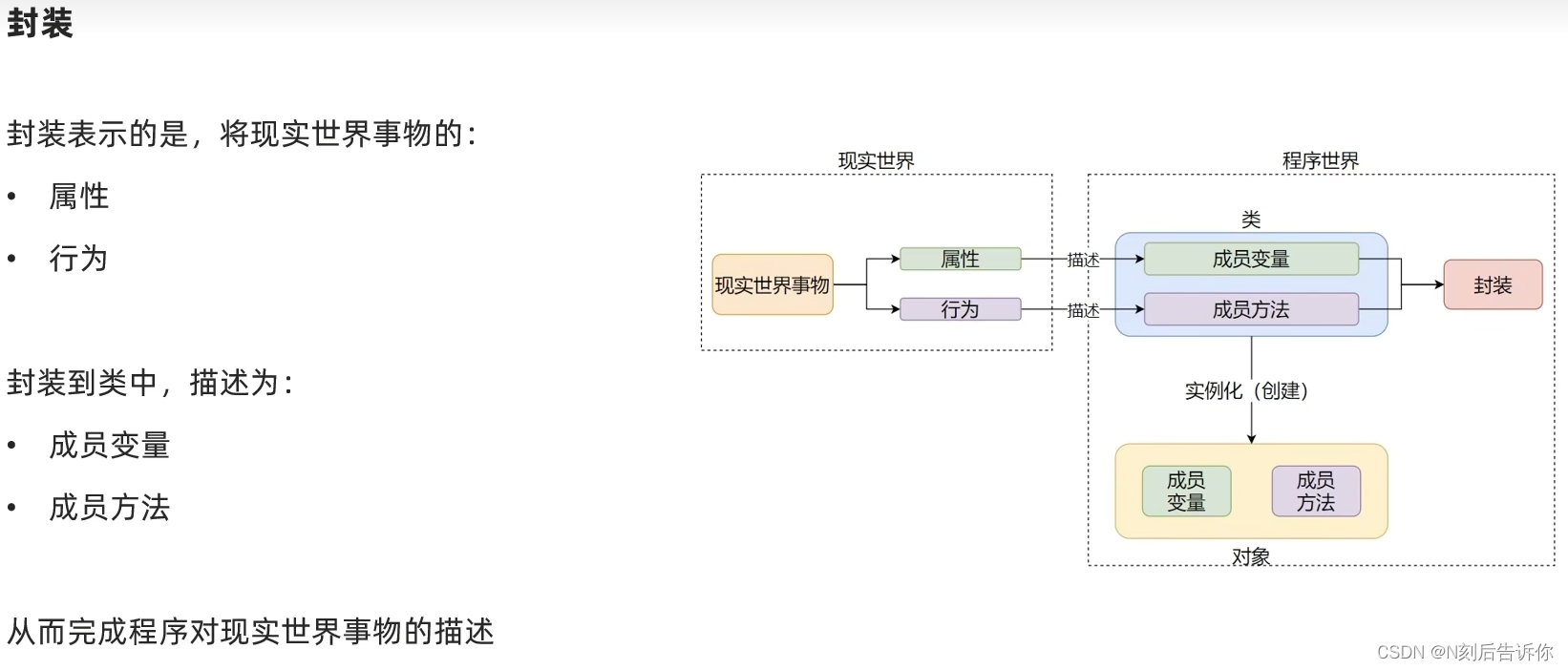
2.1.6 封装
面向对象包含3大特性:封装、继承、多态
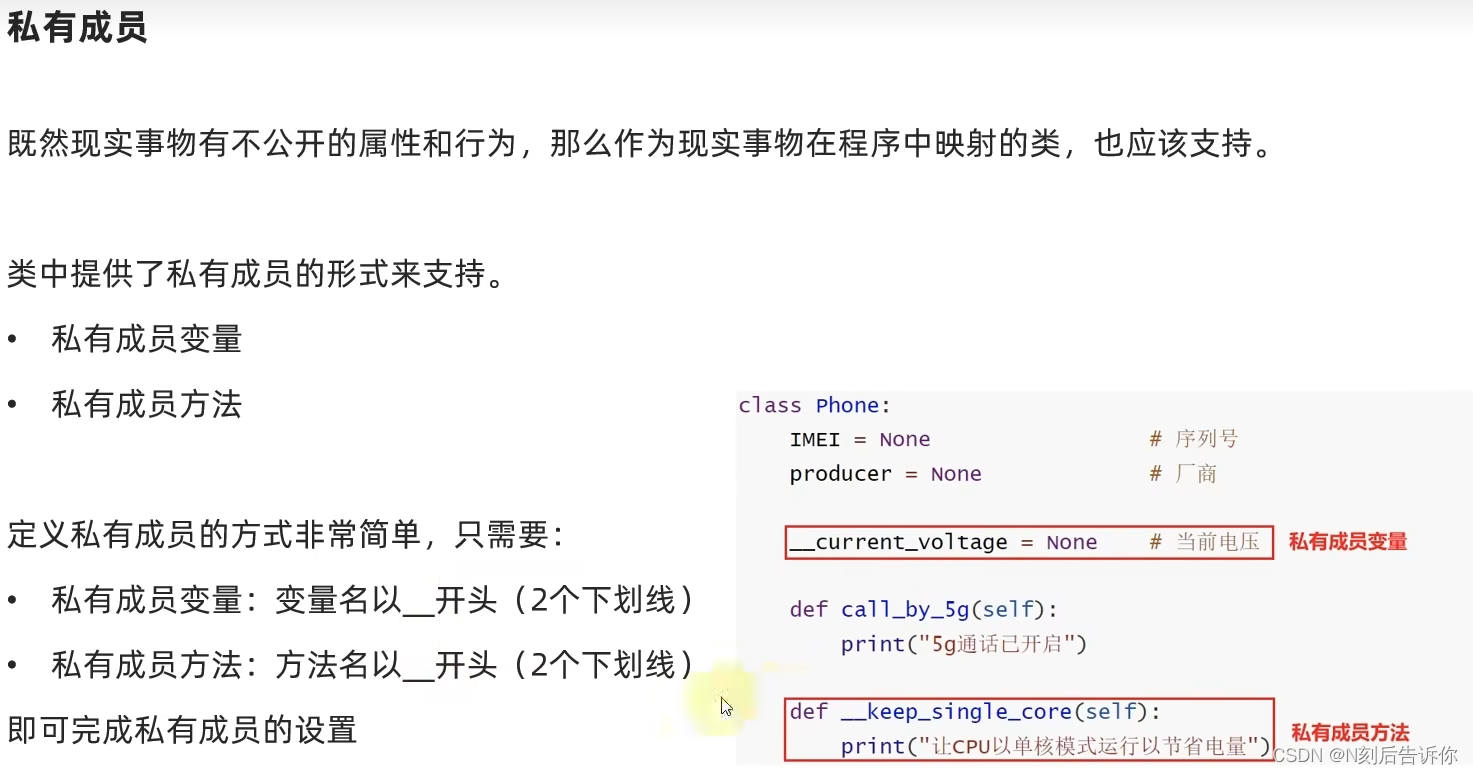
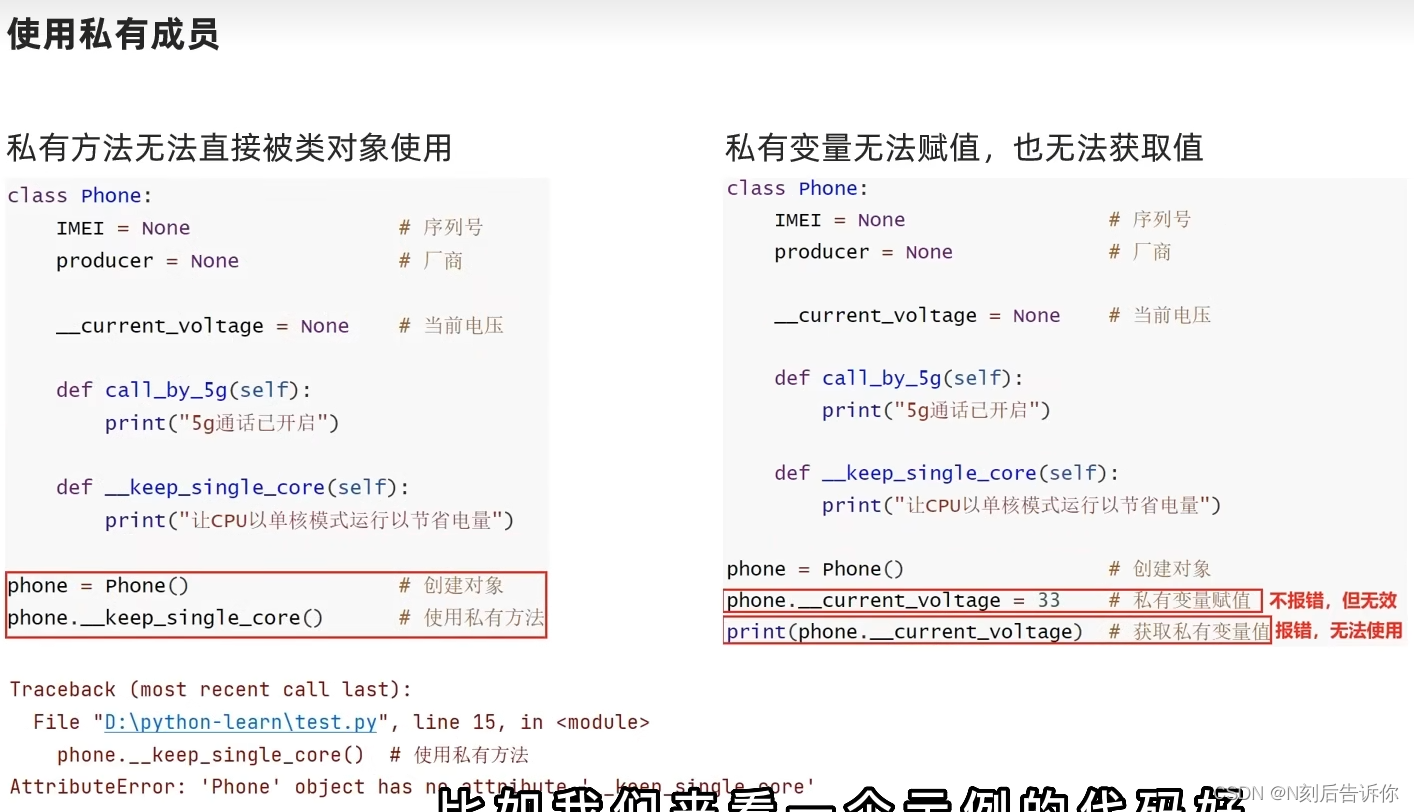
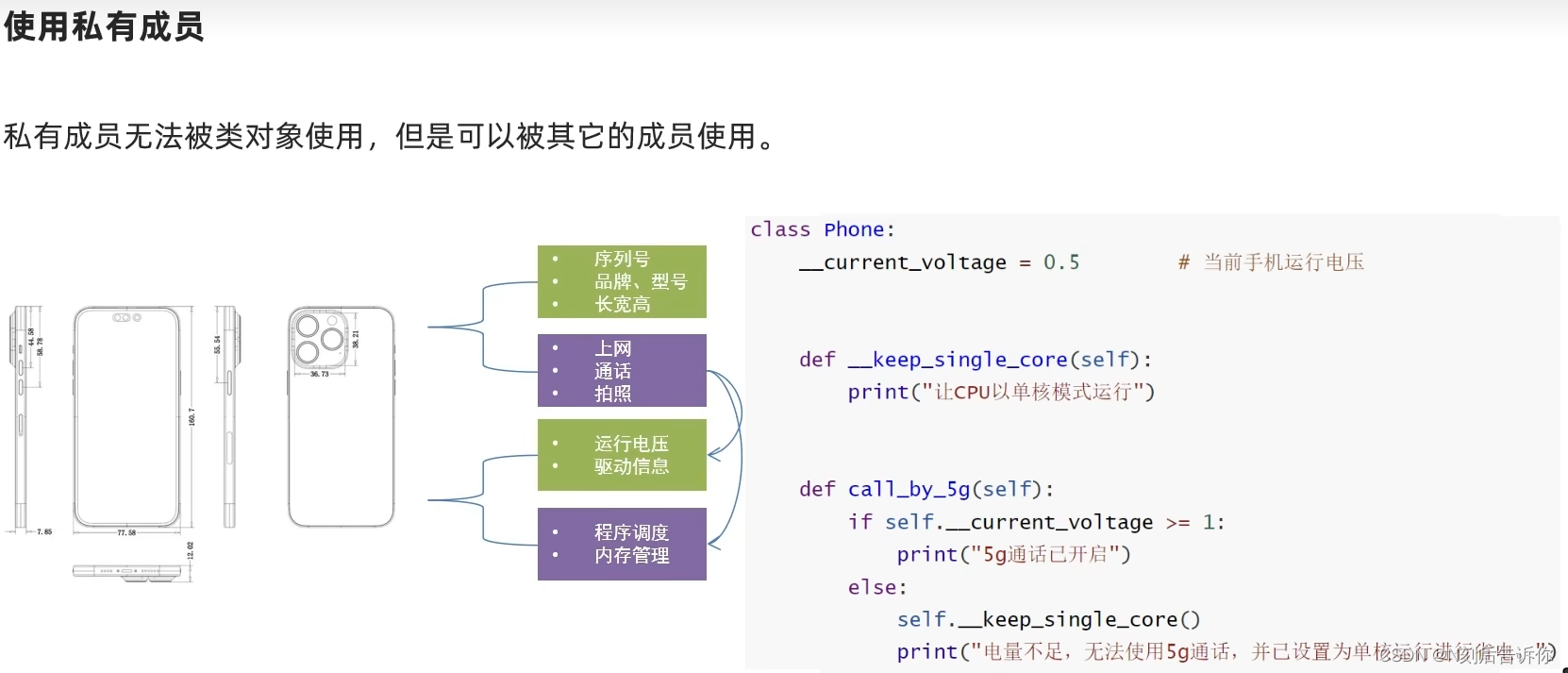
2.1.6.1 私有成员
2.1.7 继承
2.1.7.1 单继承

继承表示:将从父类那里继承(复制)成员变量和成员方法(不含私有)
2.1.7.2 多继承
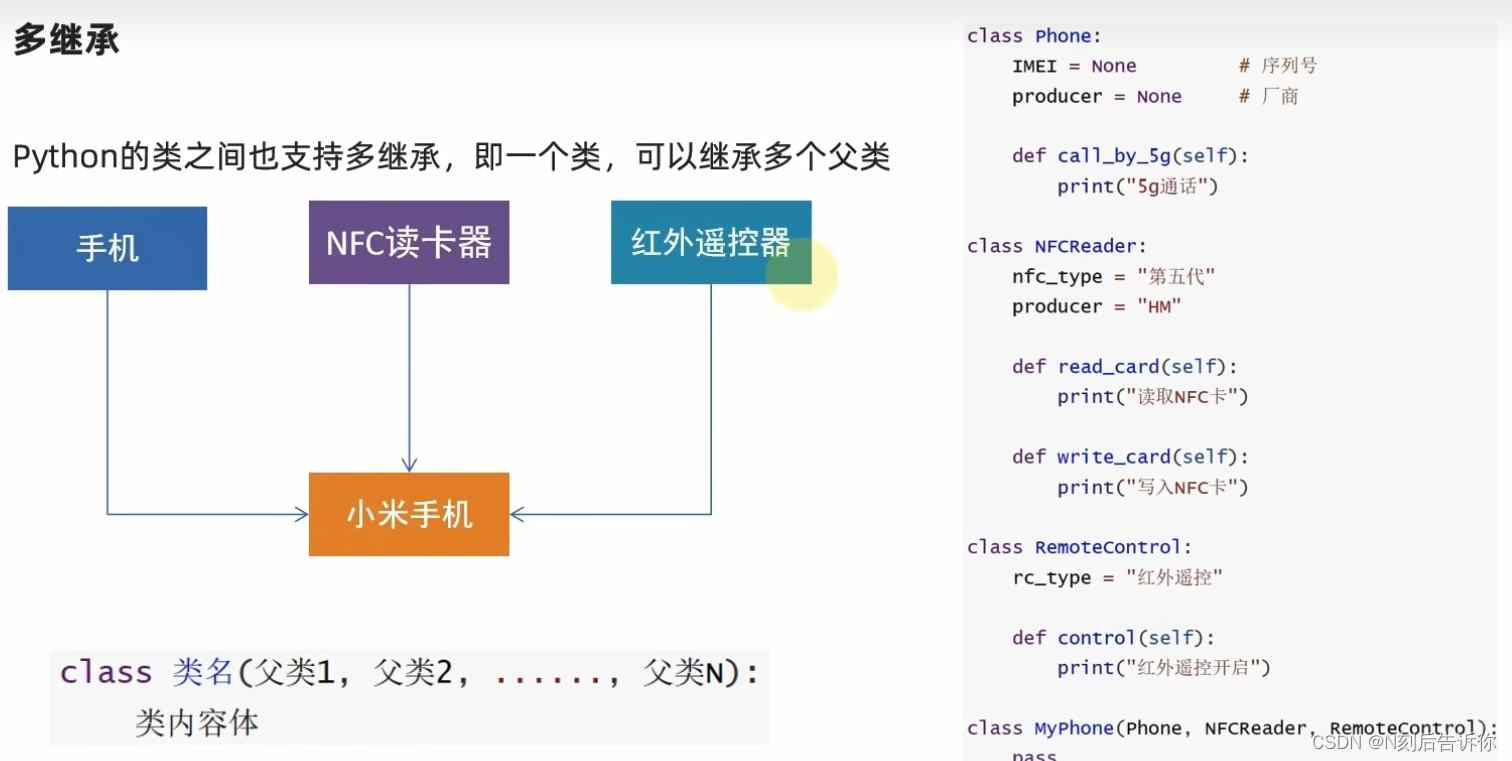

pass关键字是用来补全语法的
2.1.7.3 复写和使用父类成员


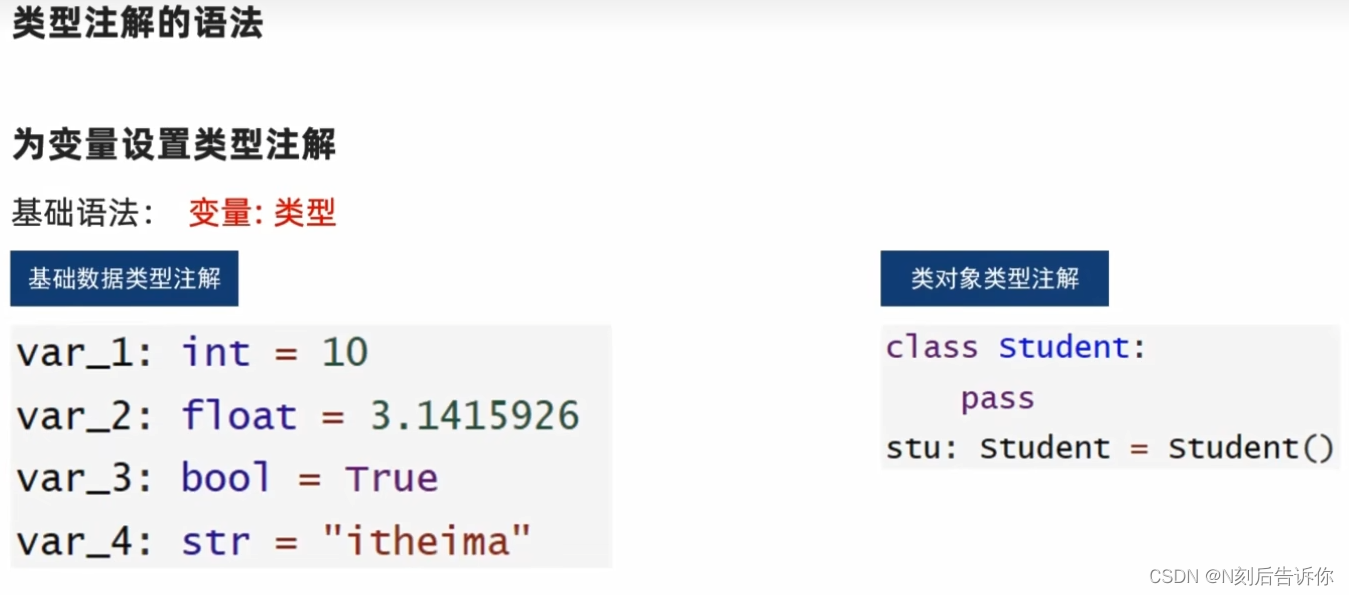
2.1.8 类型注解
2.1.8.1 变量的类型注解






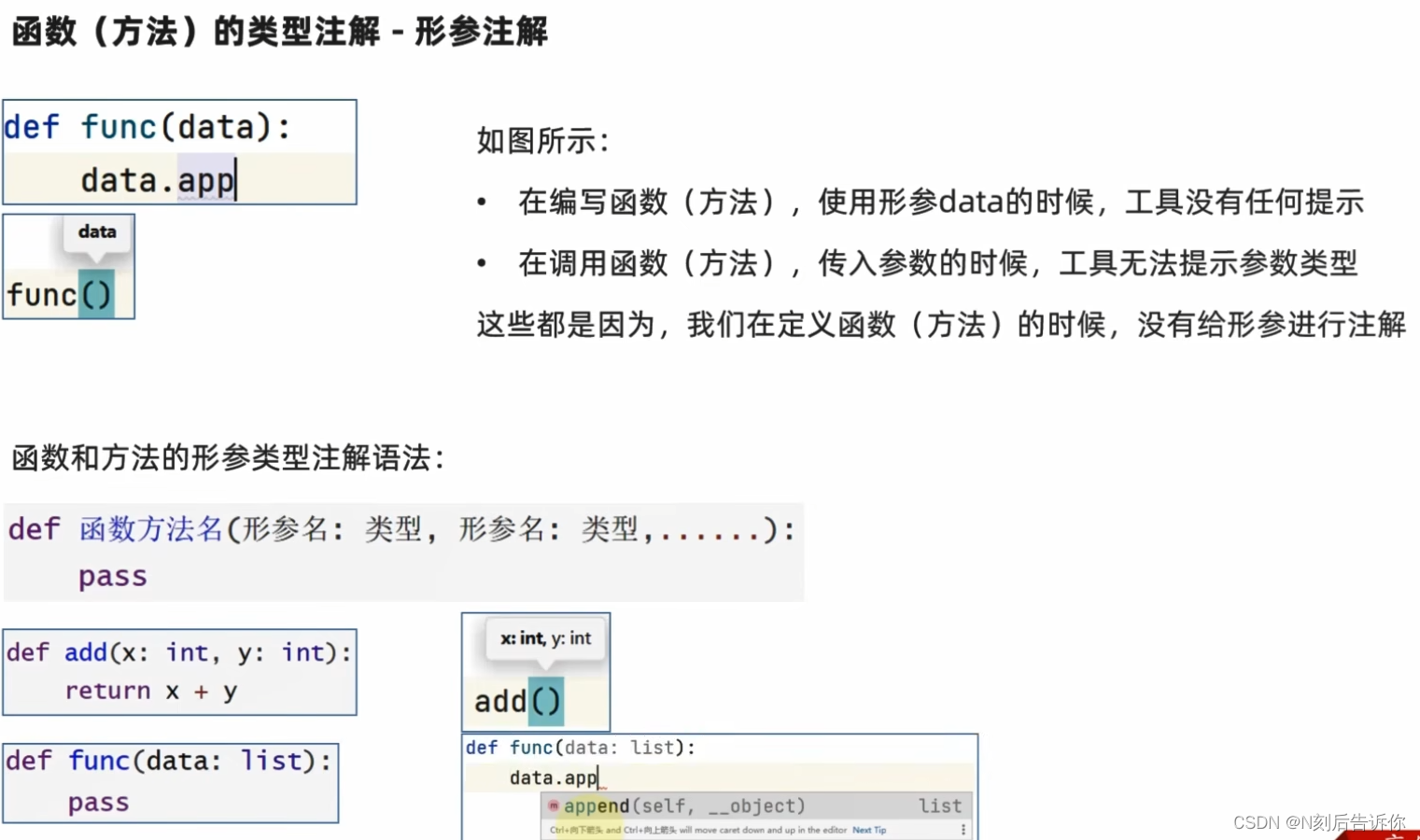
2.1.8.2 函数(方法)的类型注解
- 函数(方法)的形参的类型注解
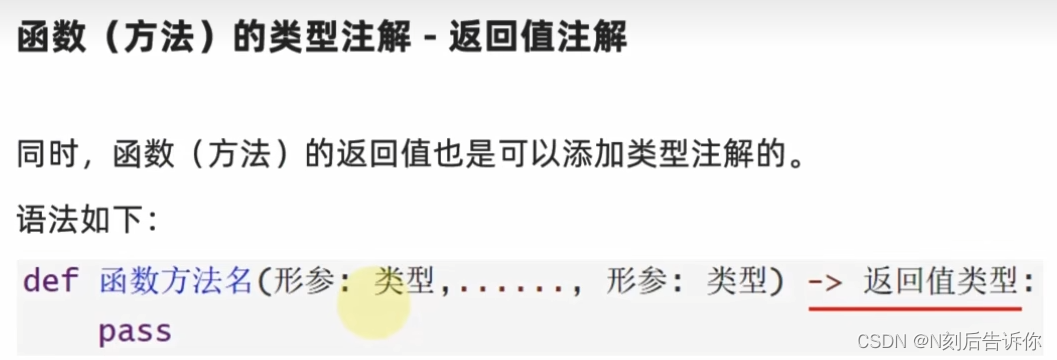
- 函数(方法)的返回值的类型注解
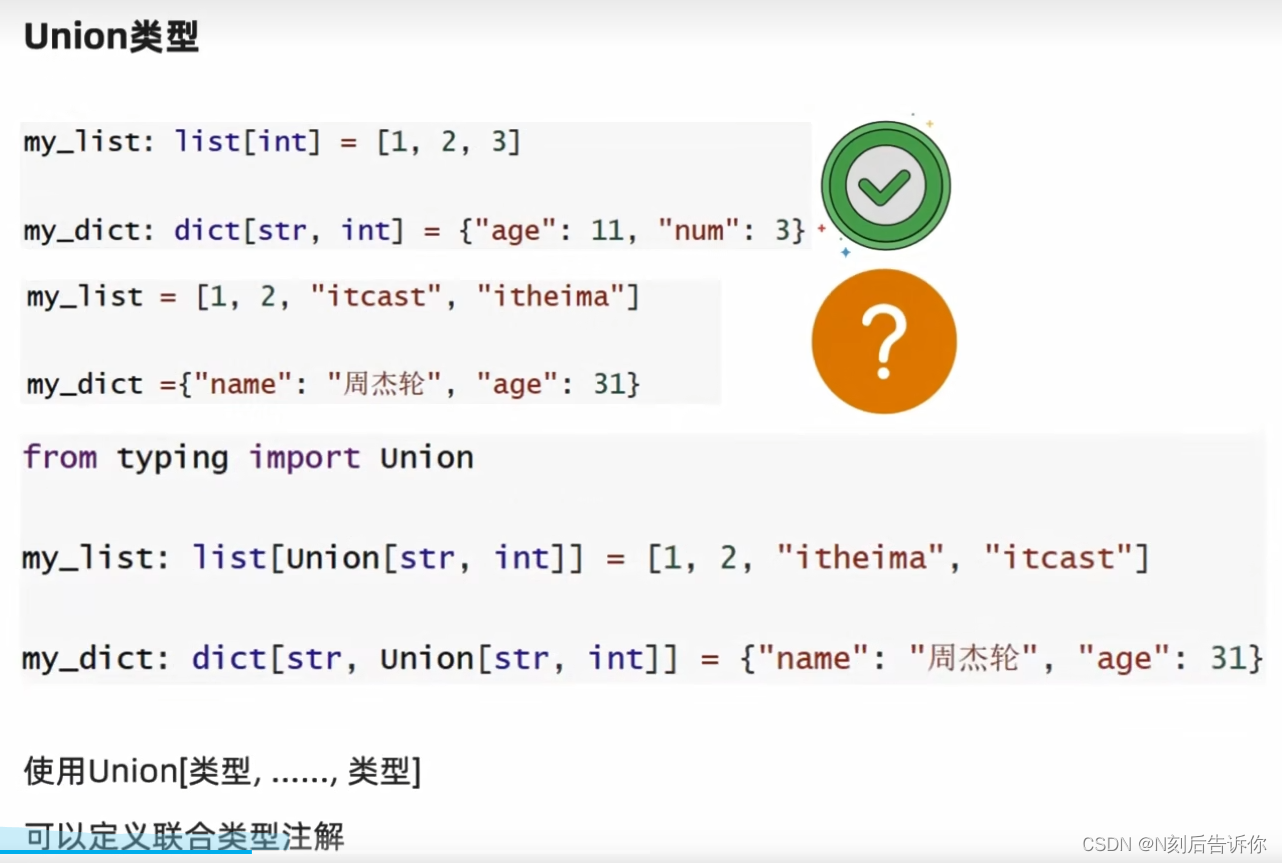
2.1.8.3 Union类型

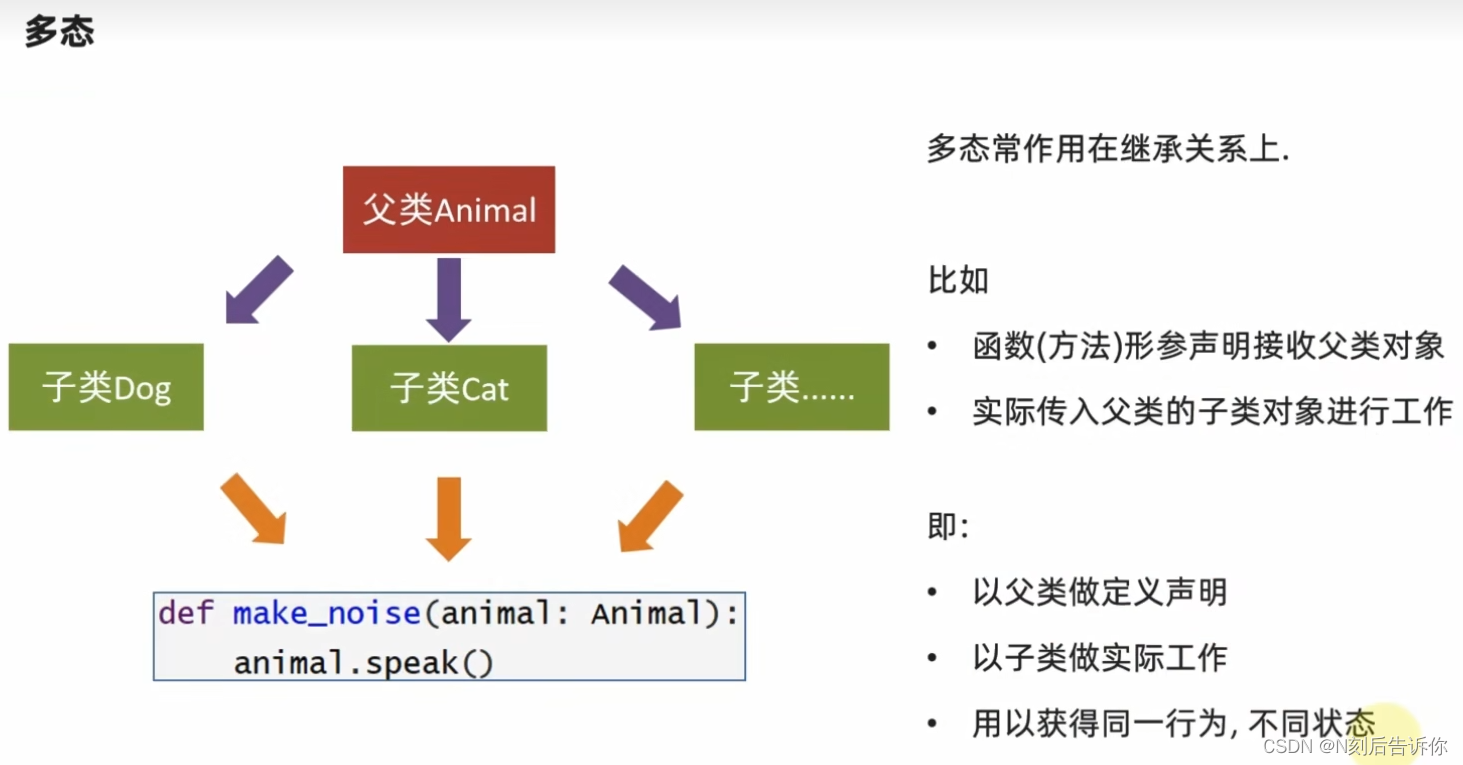
2.1.9 多态


2.1.10 综合案例
2.1.10.1 要求和数据内容
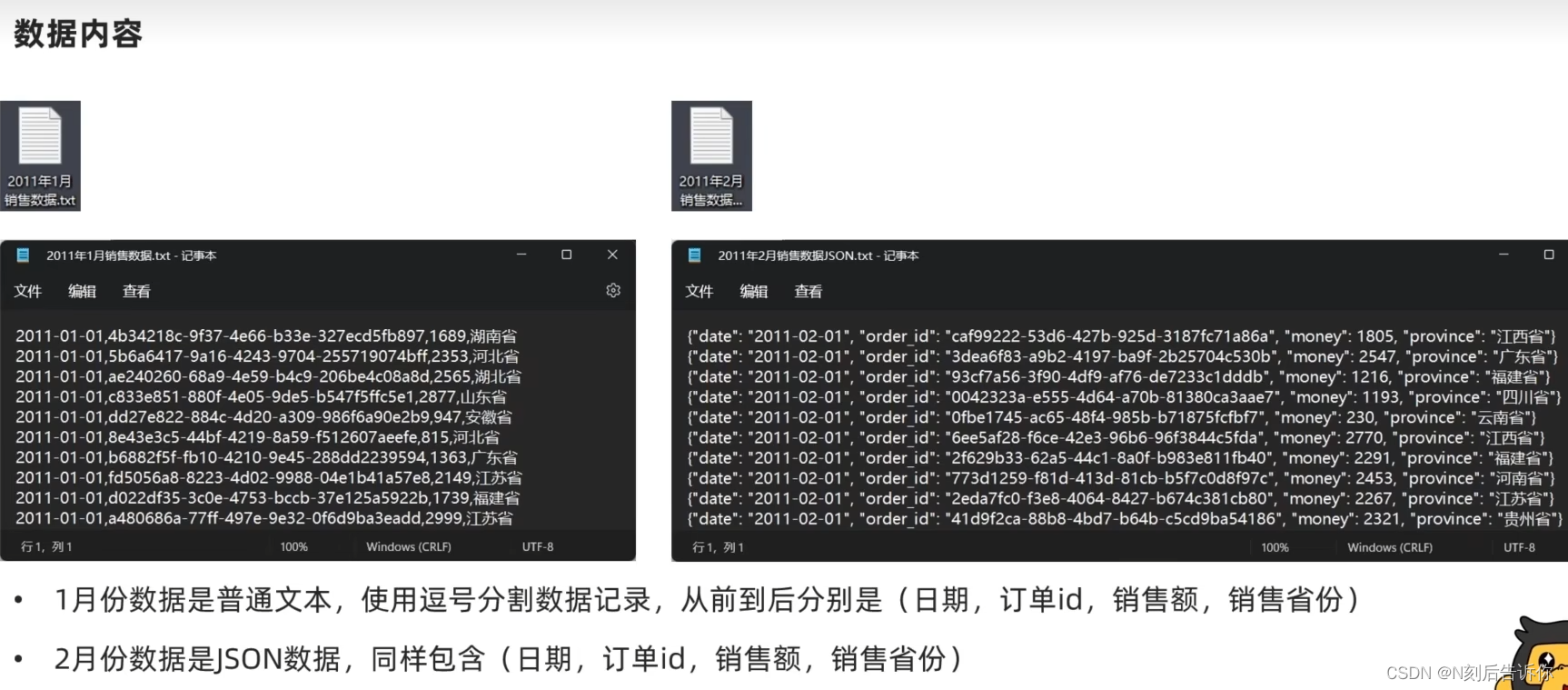
2.1.10.2 需求分析
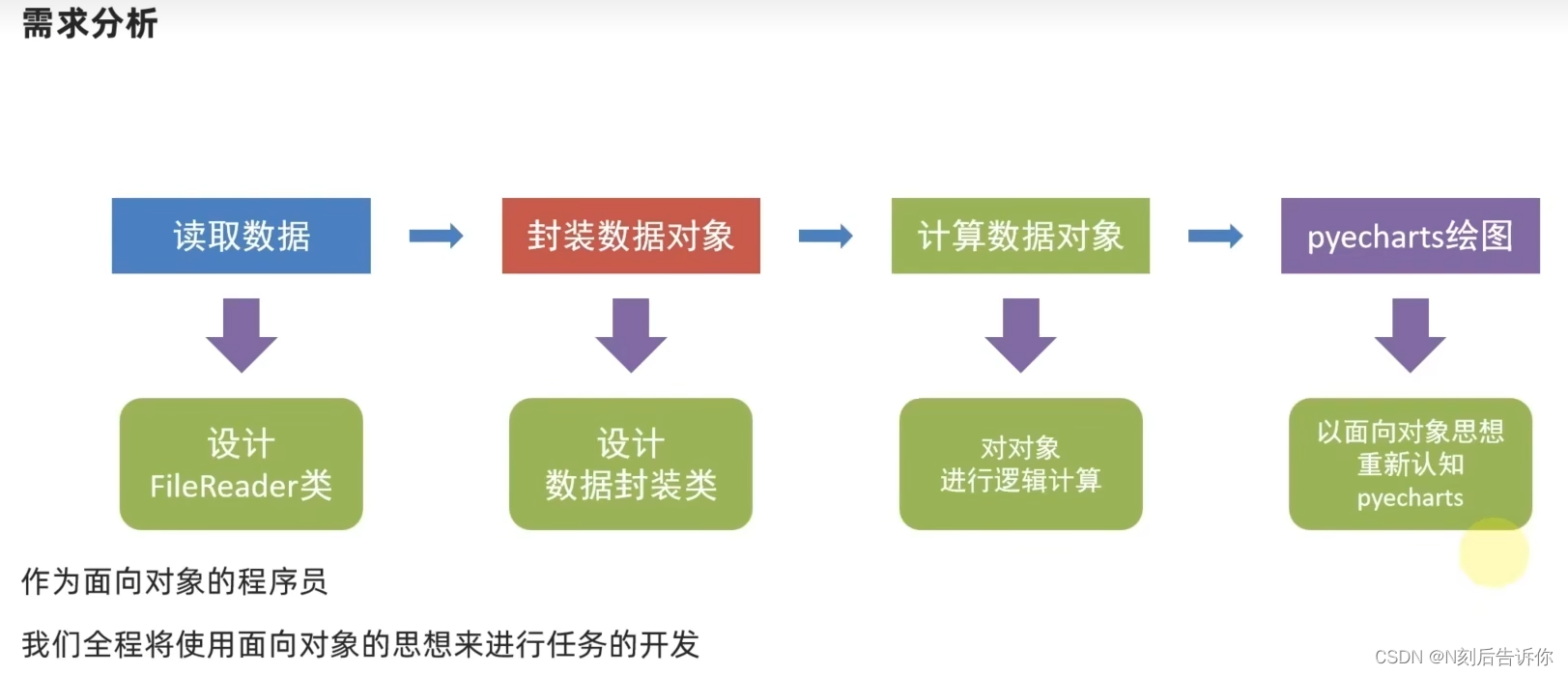
2.1.10.3 文件读取
- data_define.py
"""
数据定义的类
"""
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
- file_define.py
"""
和文件相关的类定义
"""
import json
from data_define import Record
# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:
def read_data(self) -> list[Record]:
"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
with open(self.path, 'r', encoding='utf-8') as f:
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
def read_data(self) -> list[Record]:
with open(self.path, 'r', encoding='utf-8') as f:
record_list: list[Record] = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict['date'], data_dict['order_id'], int(data_dict['money']), data_dict['province'])
record_list.append(record)
return record_list
if __name__ == '__main__':
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
list1 = text_file_reader.read_data()
list2 = json_file_reader.read_data()
for l in list1:
print(l)
for l in list2:
print(l)
2.1.10.4 数据计算
- main.py
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
# 开始进行数据计算
data_dict = {}
for record in all_data:
if record.date in data_dict:
data_dict[record.date] += record.money
else:
data_dict[record.date] = record.money
2.1.10.5 可视化开发
# 可视化图表开发
bar = Bar(init_opts=InitOpts(ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) # 添加x轴数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=TitleOpts(title="每日销售额")
)
bar.render("每日销售额柱状图.html")
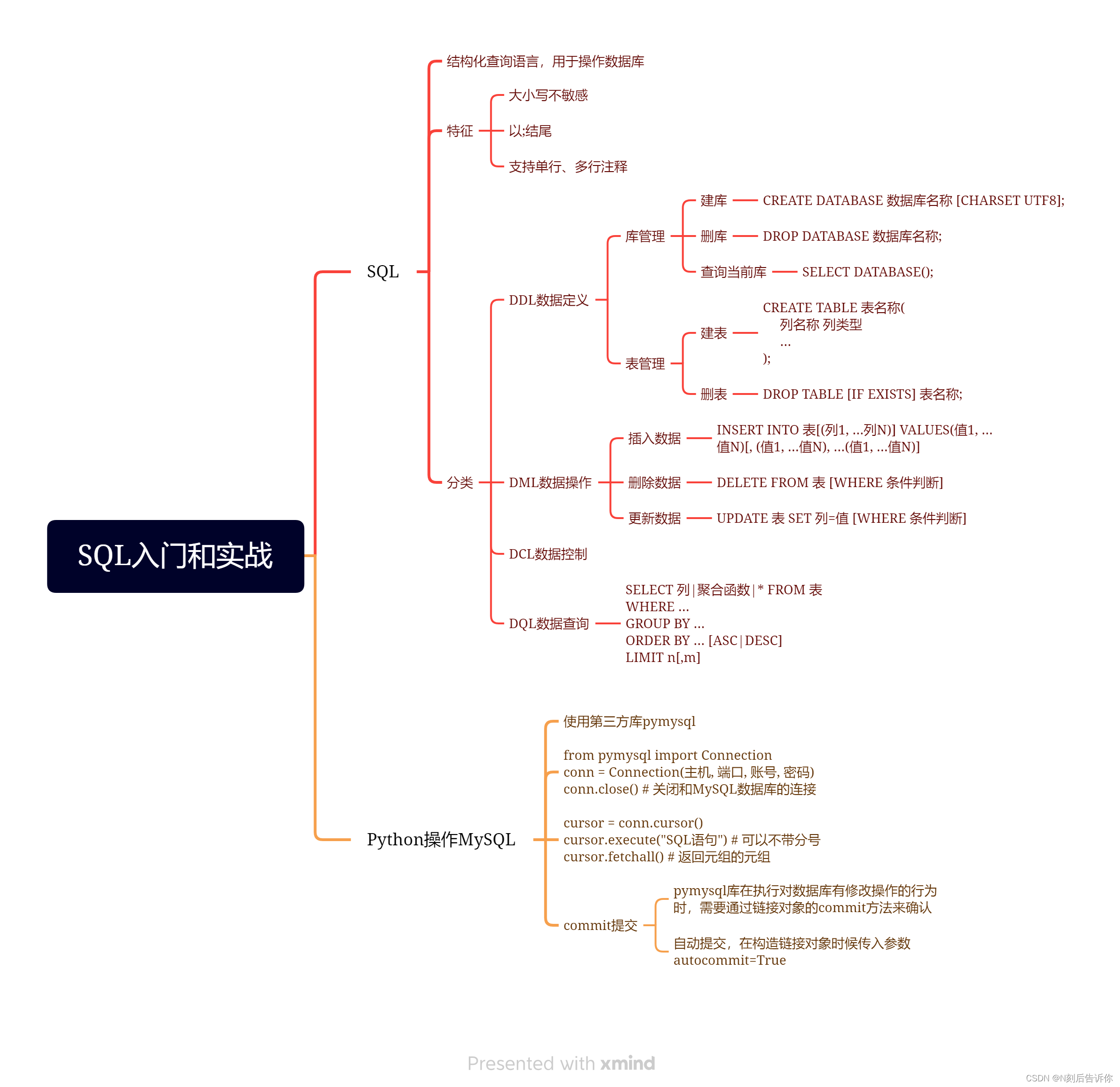
第二章:SQL入门和实战

2.2.1 数据库介绍
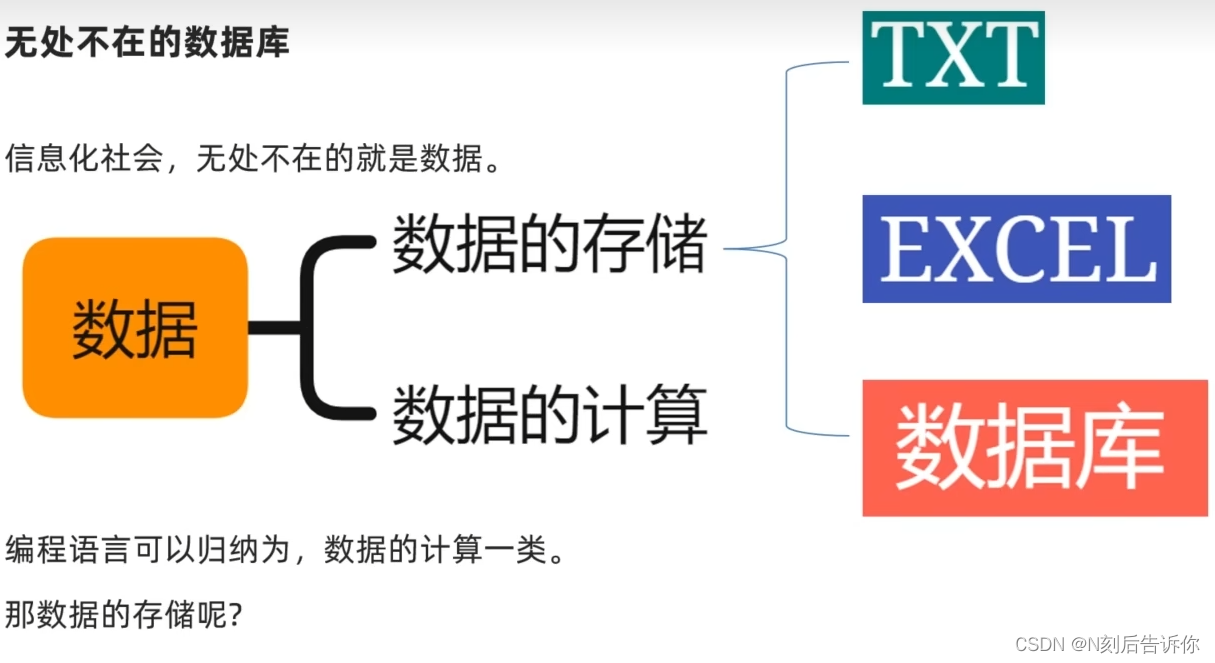
2.2.1.1 数据库管理系统

2.2.1.2 数据库和SQL的关系

2.2.2 MySQL的安装
mysql的官网:www.mysql.com
略,详细请参考视频
2.2.3 MySQL的入门使用

2.2.4 SQL基础与DDL


2.2.4.1 SQL语法特征

2.2.4.2 数据库定义语言-DDL
- DDL-库管理
# 查看数据库
SHOW DATABASES;
# 使用数据库
USE 数据库名称;
# 创建数据库
CREATE DATABASE 数据库名称 [CHARSET UTF8];
# 删除数据库
DROP DATABASE 数据库名称;
# 查看当前使用的数据库
SELECT DATABASE();
- DDL-表管理
# 查看有哪些表
show tables;
# 删除表
drop table 表名称;
drop table if exists 表名称;
# 创建表
create table 表名称(
列名称 列类型,
列名称 列类型,
......
);
-- 列类型有
int -- 整数
float -- 浮点数
varchar(长度) -- 文本,长度为数字,做最大长度限制
date -- 日期类型
timestamp -- 时间戳类型
2.2.5 SQL-DML
DML-数据操作语言。
- 插入

- 删除

- 更新

2.2.6 SQL-DQL
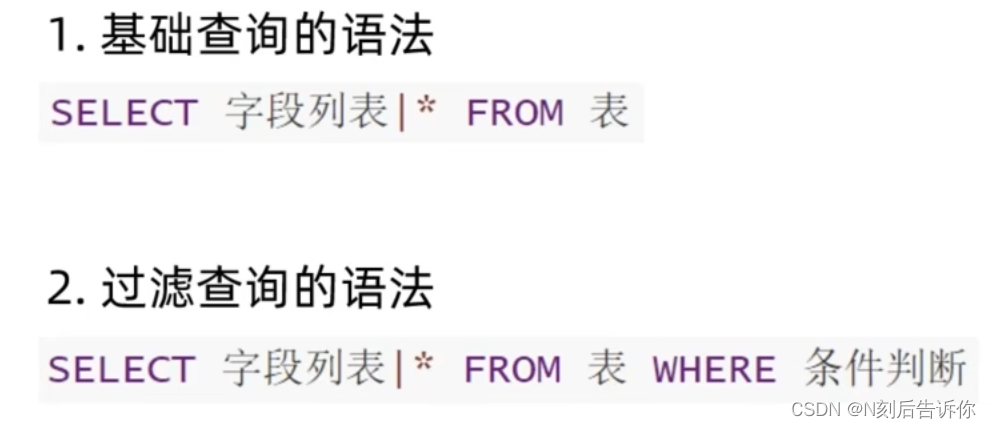
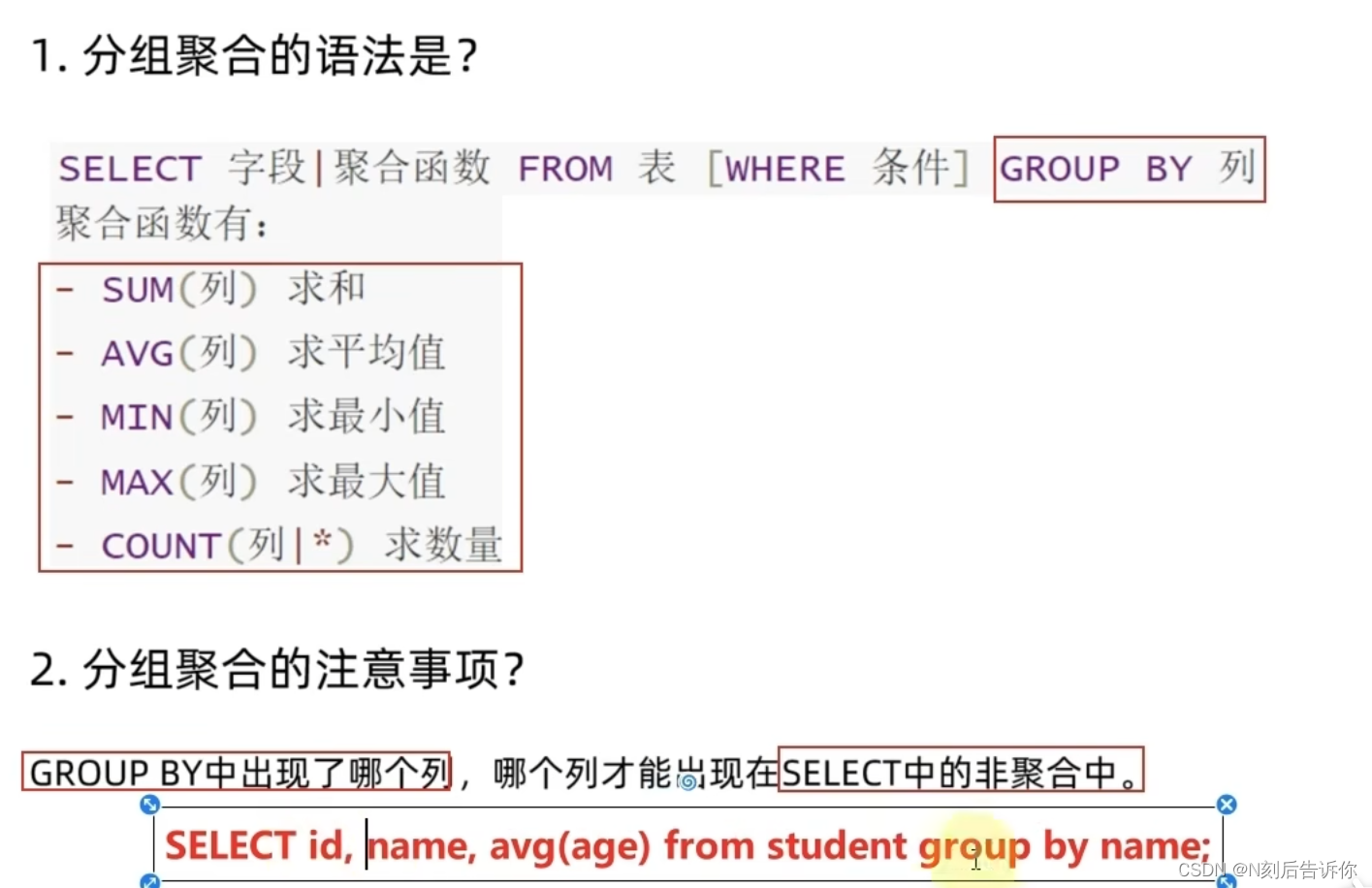

2.2.7 Python & MySQL
2.2.7.1 安装pymysql

2.2.7.2 创建到MySQL的数据库链接

2.2.7.3 执行非查询性质的SQL语句
cursor = conn.cursor()
conn.select_db("test")
cursor.execute("create table test_pymysql2(id int)")
2.2.7.4 执行查询性质的SQL语句
cursor = conn.cursor()
conn.select_db("world")
cursor.execute("select * from student")
results = cursor.fetchall()
for r in results:
print(r)
2.2.7.5 数据插入
- commit提交
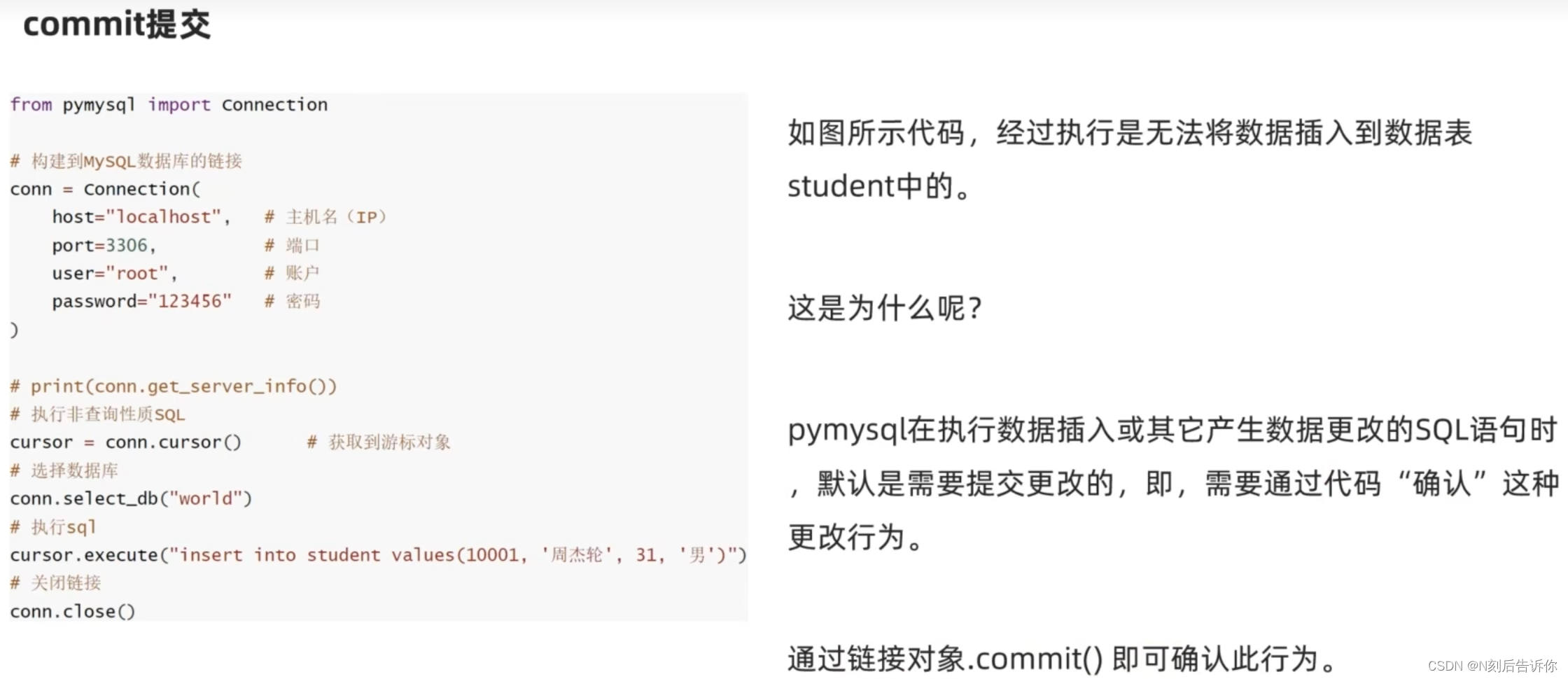
- 自动conmmit

2.2.8 综合案例
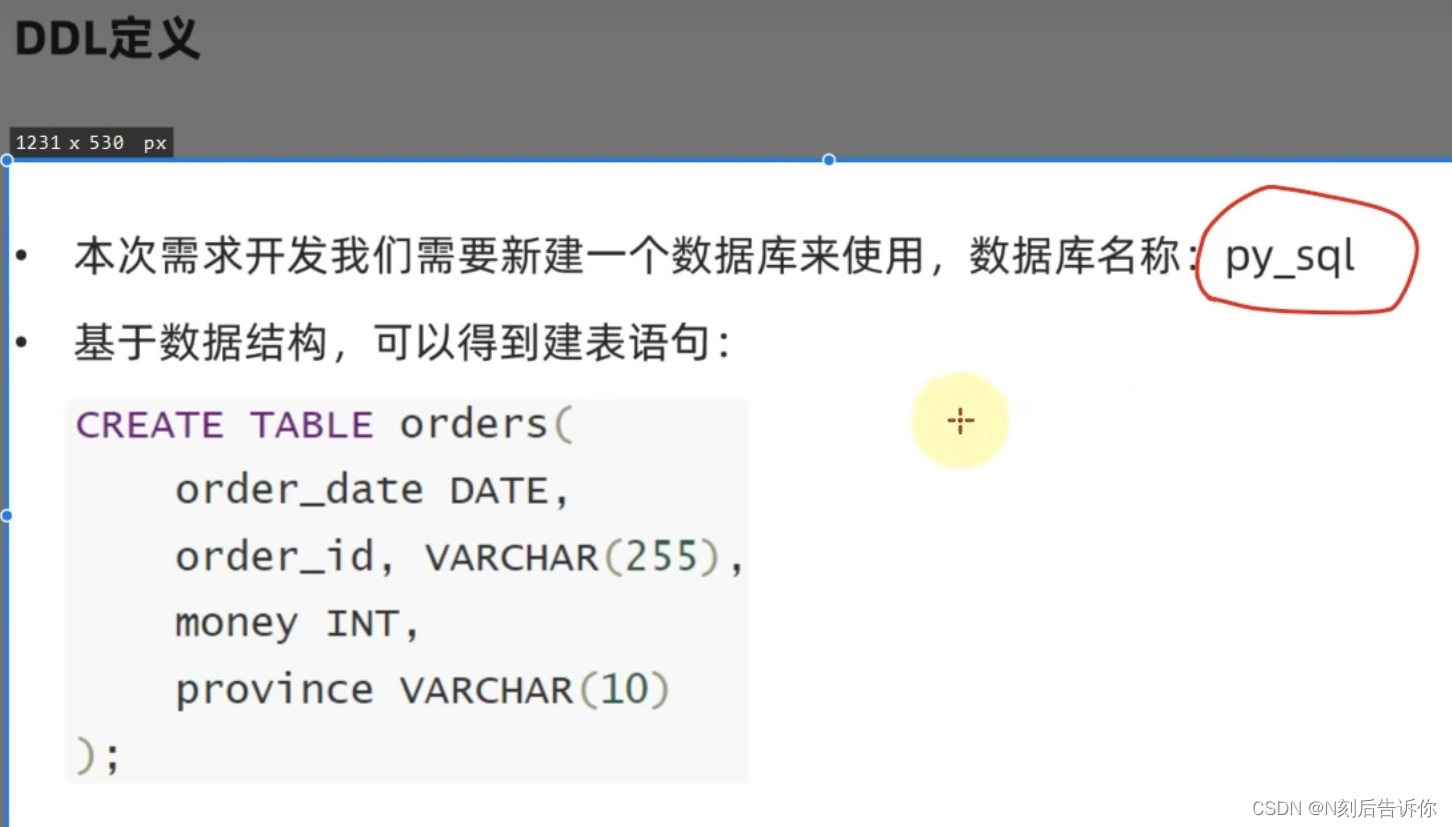
2.2.8.1 创建表
2.2.8.2 实现步骤
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connection
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
conn = Connection(
host="127.0.0.1",
port=3306,
user="root",
password="xxxxxx",
autocommit=True
)
cursor = conn.cursor()
conn.select_db("py_sql")
for record in all_data:
sql = f"INSERT INTO orders(`order_date`, `order_id`, `money`, `province`) " \
f"VALUES ('{record.date}', '{record.order_id}', {record.money}, '{record.province}')"
cursor.execute(sql)
conn.close()
2.2.8.3 作业
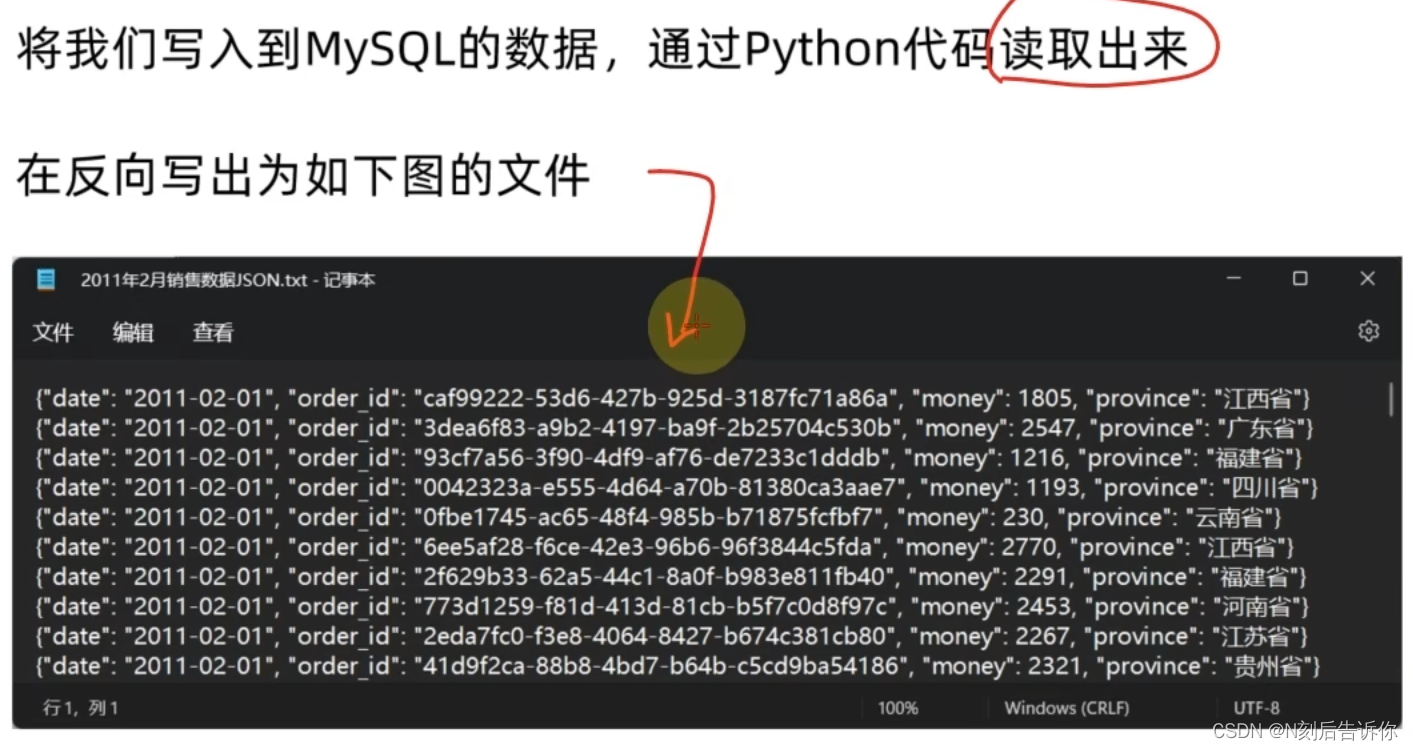
import json
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connection
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
conn = Connection(
host="127.0.0.1",
port=3306,
user="root",
password="xxxxxx",
autocommit=True
)
cursor = conn.cursor()
conn.select_db("py_sql")
sql = f"select * from orders"
cursor.execute(sql)
with open("./json.txt", 'a', encoding='utf-8') as f:
for line in cursor.fetchall():
dict = {}
dict['date'] = str(line[0])
dict['order_id'] = line[1]
dict['money'] = line[2]
dict['province'] = line[3]
tmp = json.dumps(dict, ensure_ascii=False)
f.write(tmp + '\n')
conn.close()
第三阶段:PySpark案例实战
3.1.1 Spark是什么
Apache Spark是用于大规模数据处理的统一分析引擎。简单来说,Spark是一款分布式计算框架,可以调度成百上千的服务器集群。
3.1.2 PySpark
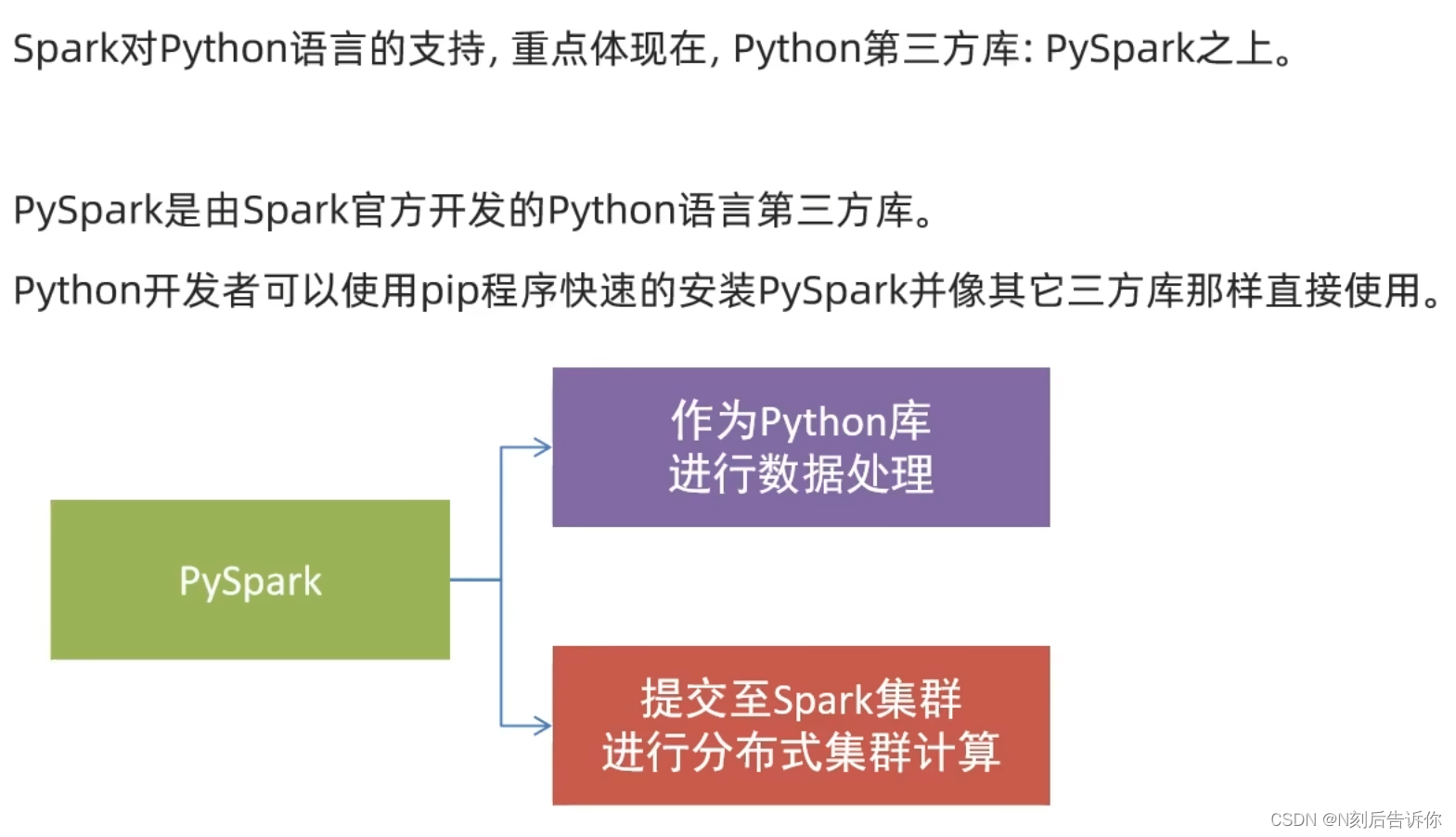
因为已经学过PySpark了,这里略。
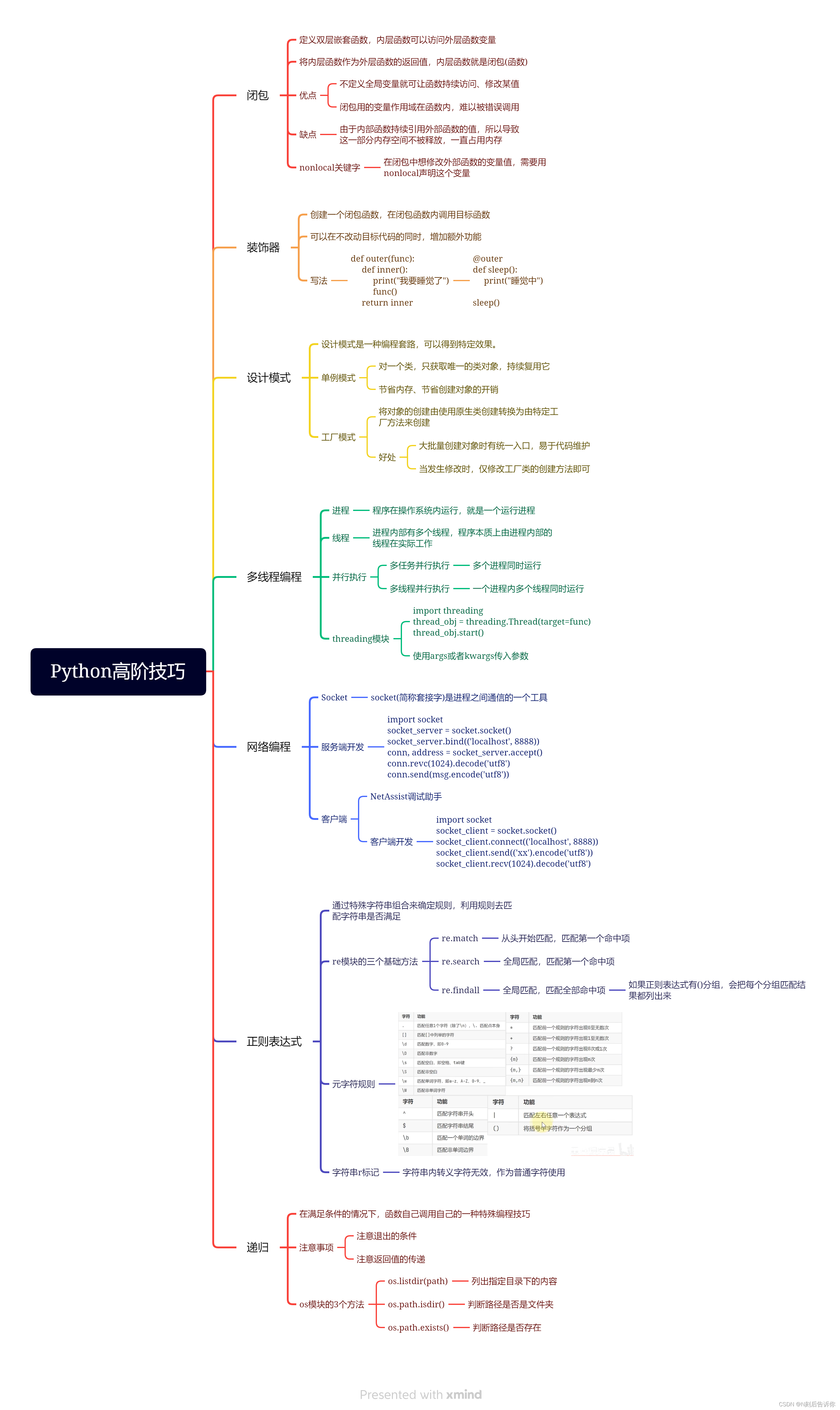
3.2 Python高阶技巧
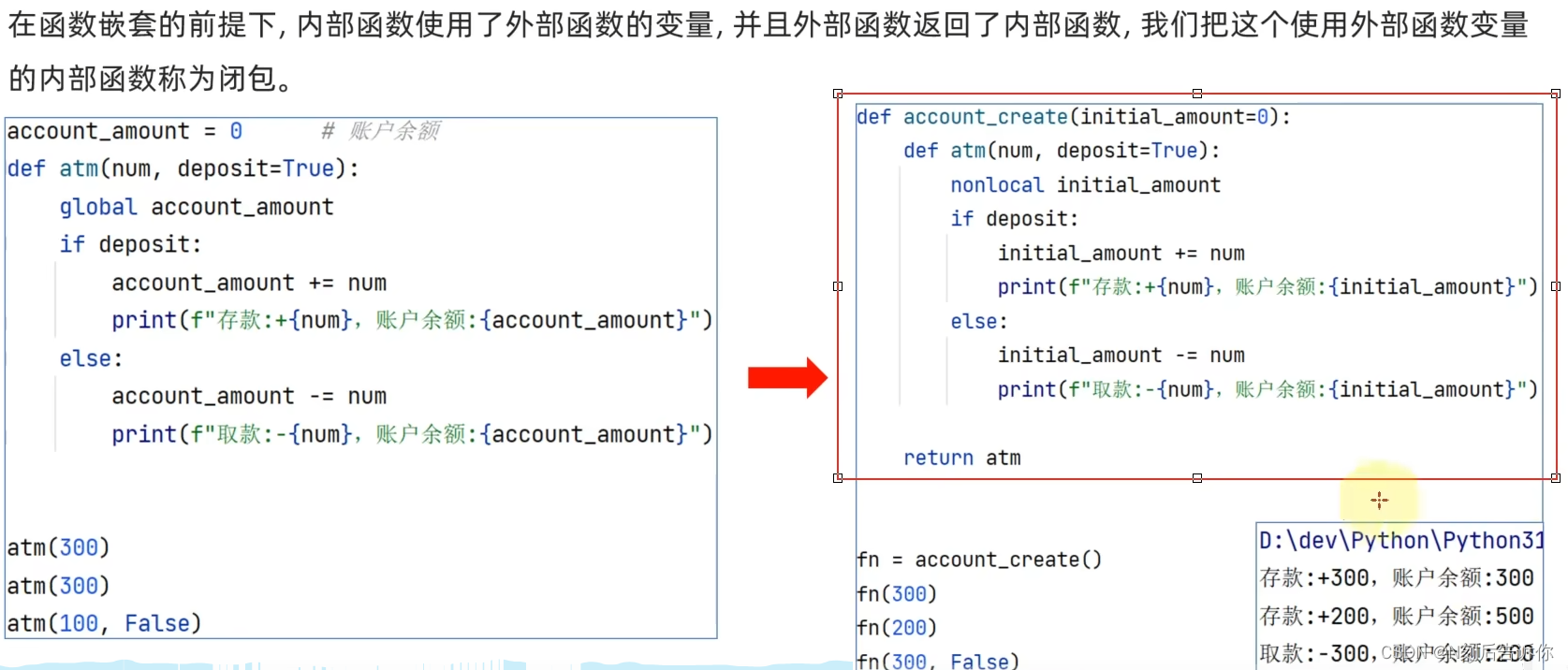
3.2.1 闭包
-
闭包(函数)
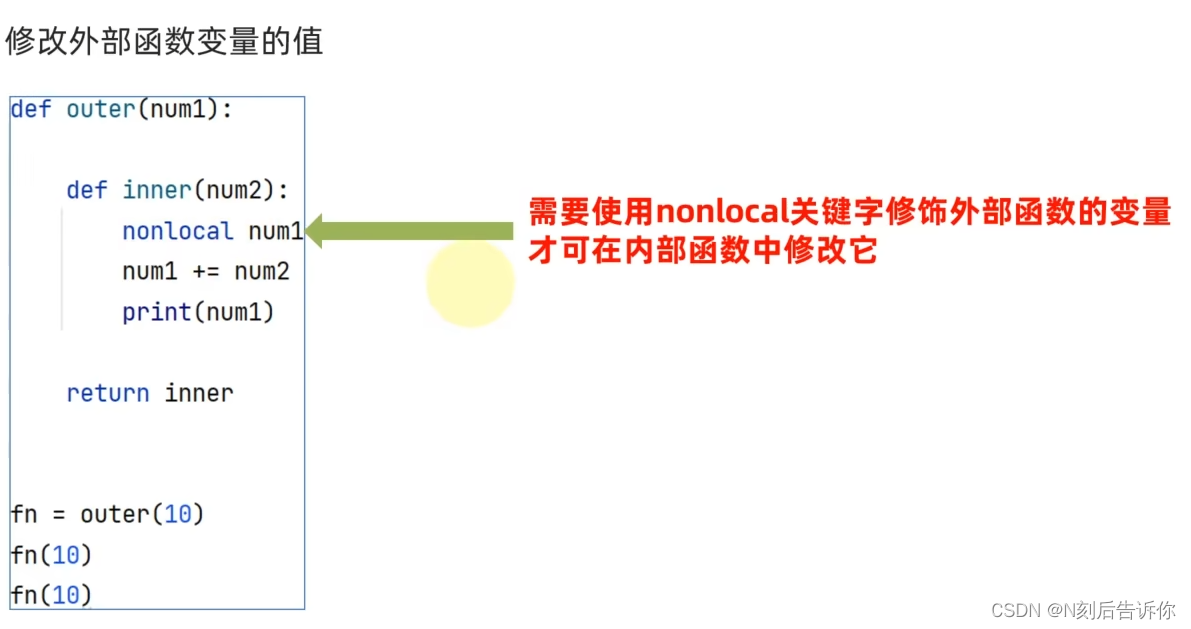
-
在闭包(函数)内修改外部函数的值-nonlocal关键字
-
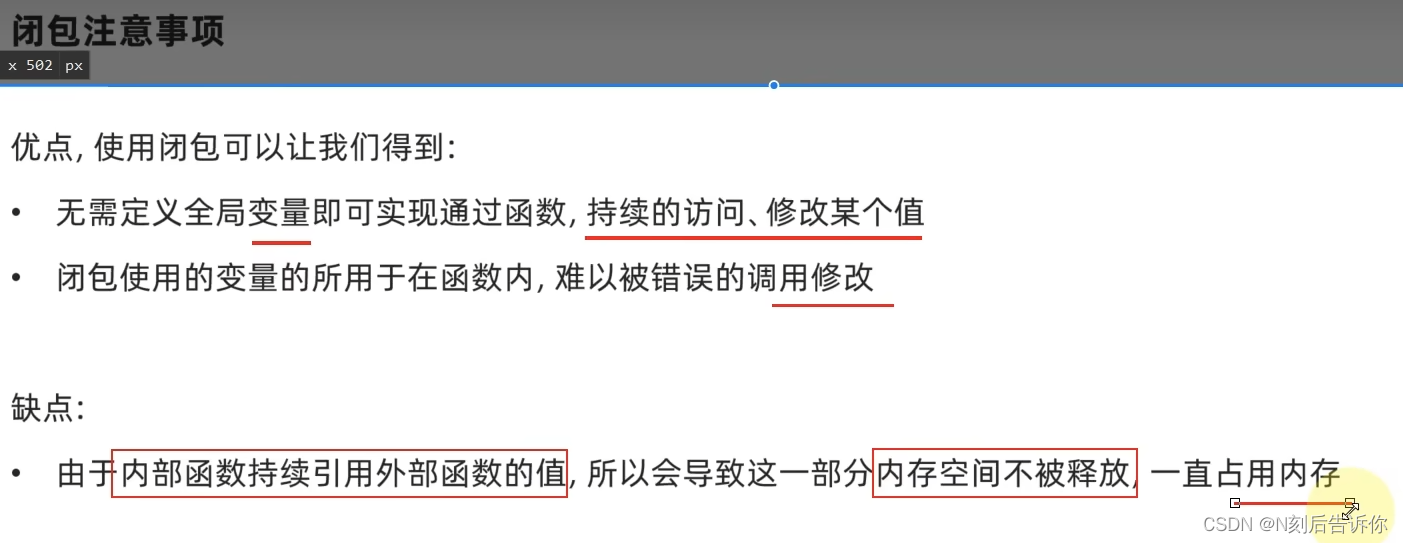
优缺点
3.2.2 装饰器

装饰器核心思想是:将需要被包装的函数作为参数传递
语法糖:也叫糖衣语法,对语言的功能并没有影响,而是更方便程序员使用

3.2.3 设计模式

3.2.3.1 单例模式


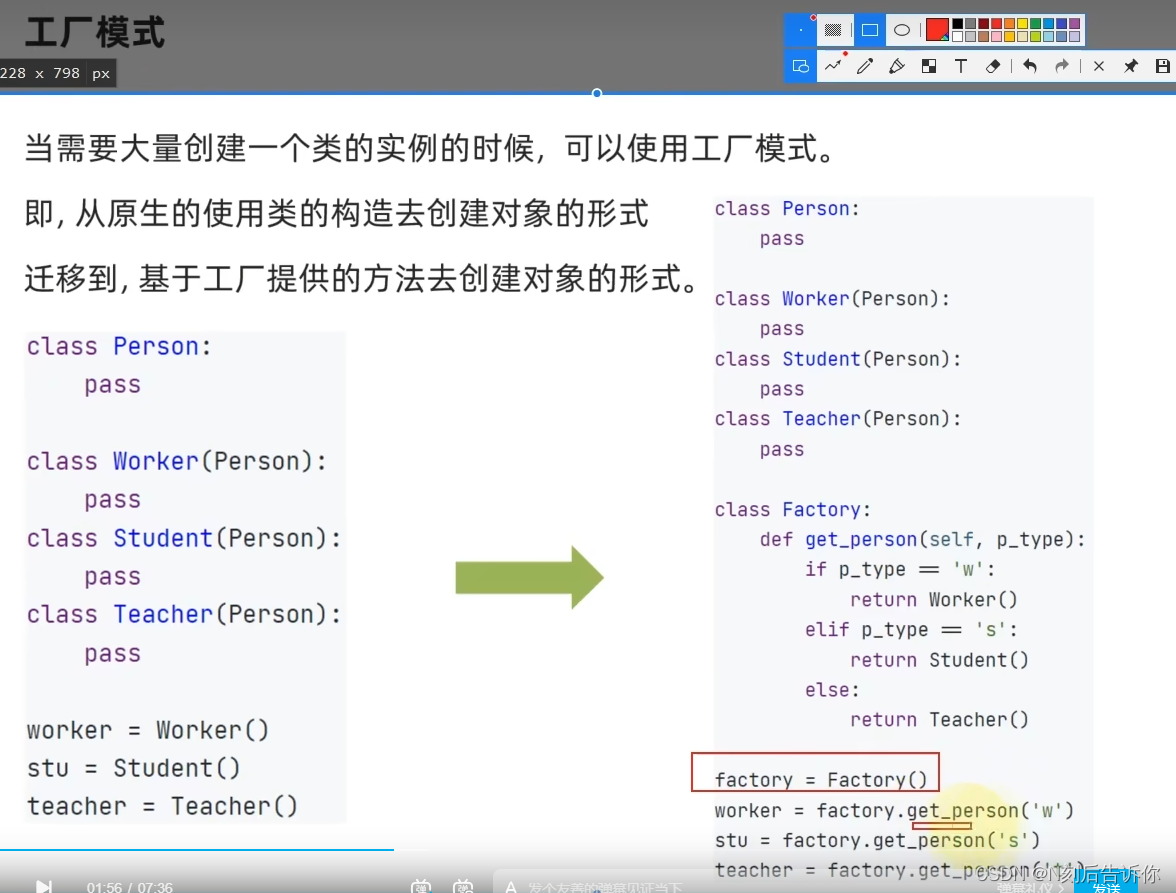
3.2.3.2 工厂模式

3.2.4 多线程
3.2.4.1 进程、线程
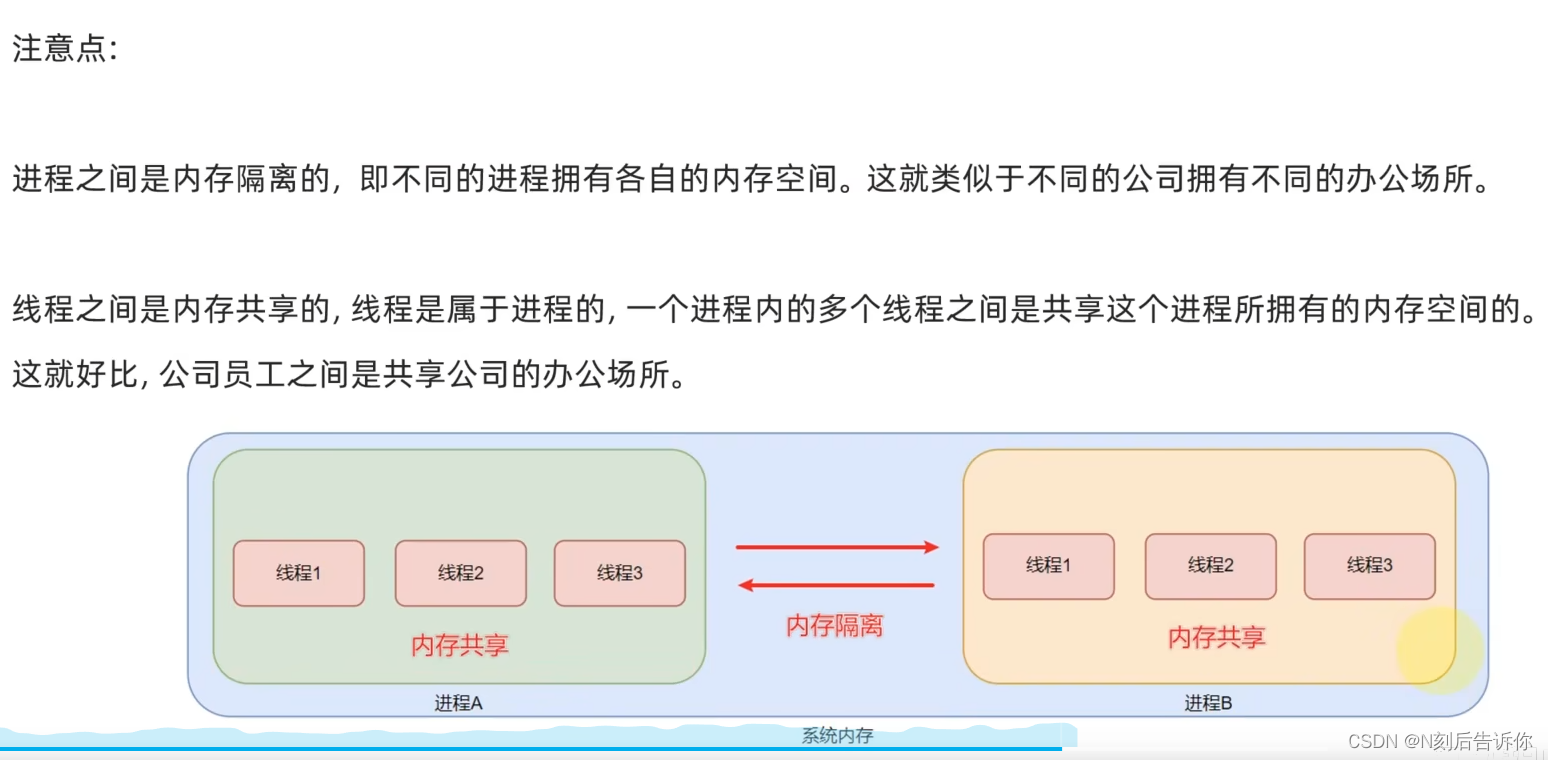
进程是系统资源调度的基本单位,线程是系统资源的最小单位
3.2.4.2 并行执行

3.2.4.3 多线程编程
- threading模块
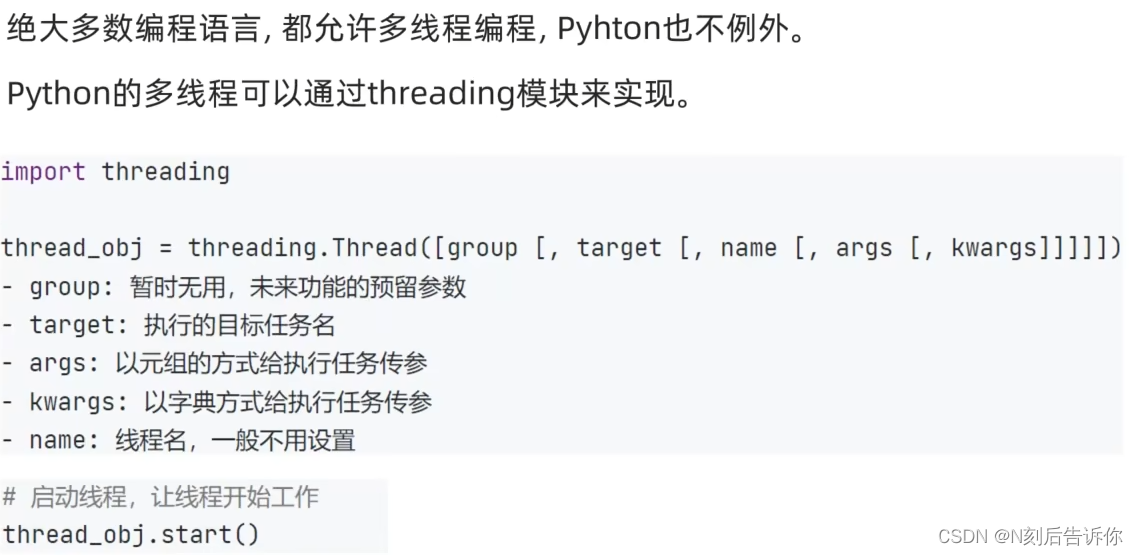
每个Thread类对象就是多线程中的一个线程
把工作封装到函数里,然后传入到target参数
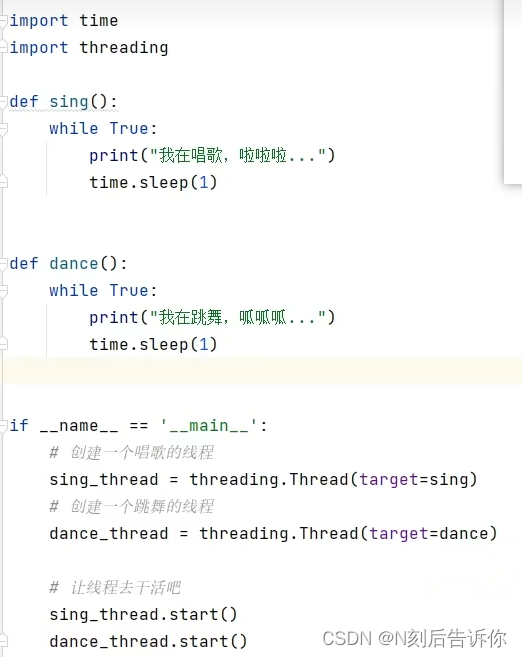
- 具体需求

- 代码实现
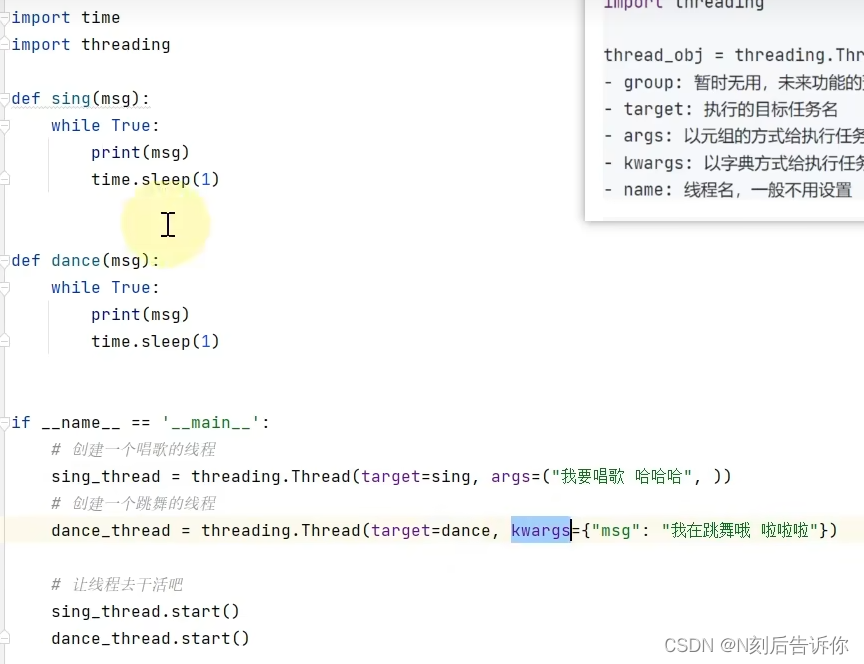
- 传参

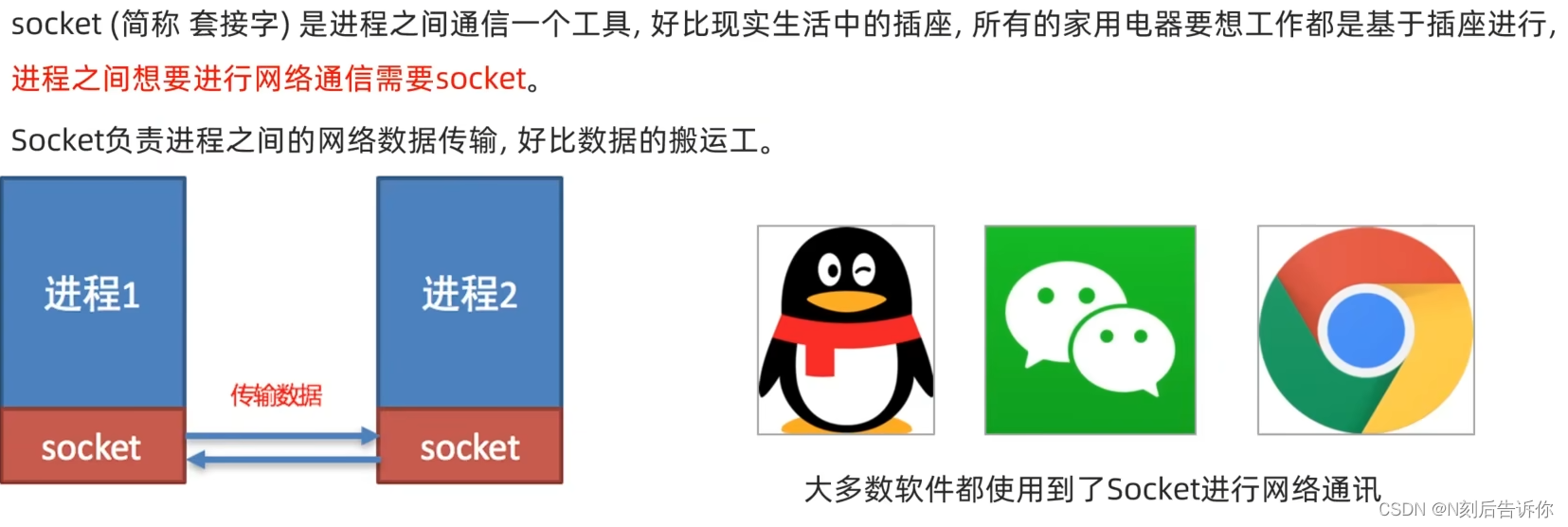
3.2.5 网络编程
3.2.5.1 Socket
3.2.5.2 客户端和服务端
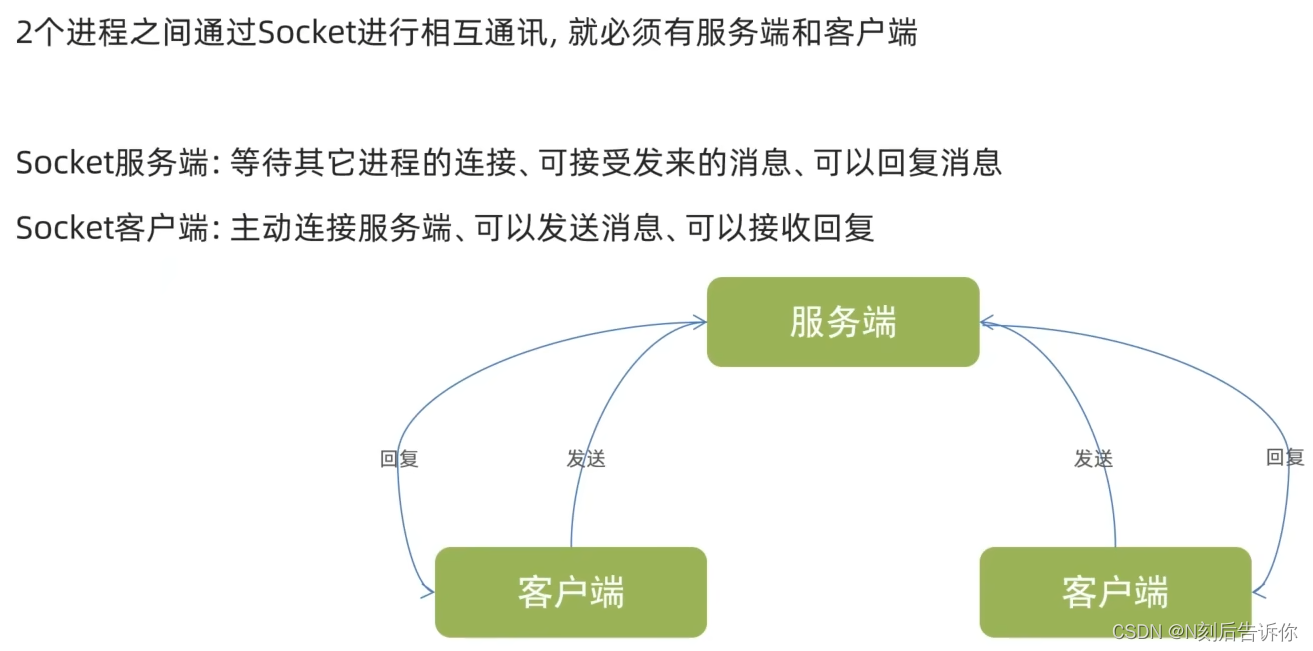
3.2.5.3 Socket服务端编程


- 实现服务端并结合客户端进行测试

import socket
# 创建Socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(('localhost', 8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受链接数量
# 等待客户端链接
conn, address = socket_server.accept()
# accpet方法返回的是二元元组(链接对象, 客户端地址信息)
# accpet方法是阻塞方法,等待客户端链接,如果没有链接,就卡在这一行不向下执行
print(f"接收到了客户端的链接,客户端的信息是:{address}")
# 接受客户端信息
data = conn.recv(1024).decode('utf8')
# recv也是阻塞方法,等待客户端发送信息
# recv接受的参数是缓冲区大小,一般给1024即可
# recv方法的返回值是一个字节数组(bytes对象),不是字符串,可以通过decode方法通过utf0编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 发送恢复消息
msg = input("请输入你要和客户端回复的消息:")
conn.send(msg.encode('utf8'))
# encode可以将字符串编码为字节数组对象
conn.close()
socket_server.close()
3.2.5.4 Socket客户端开发


3.2.6 正则表达式

3.2.6.1 正则的三个基础方法
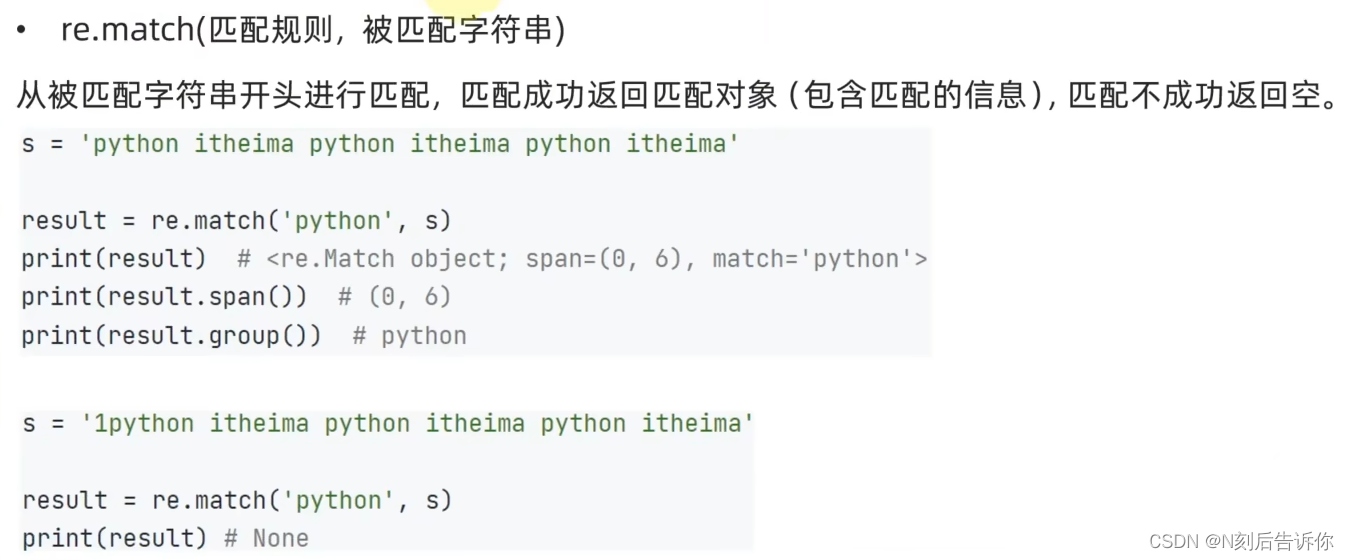
- re.match
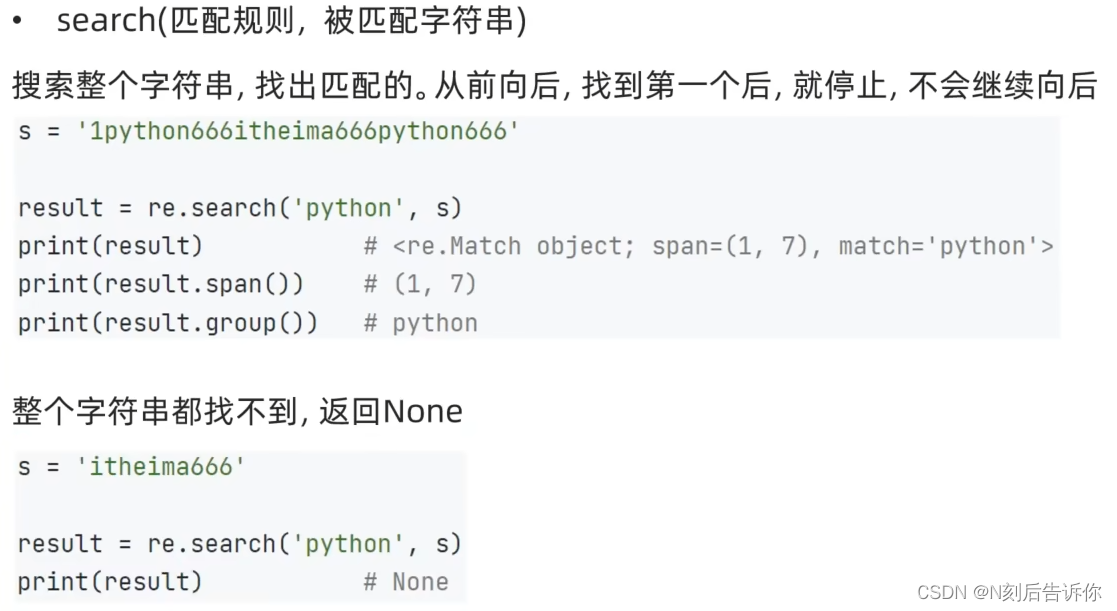
- re.search
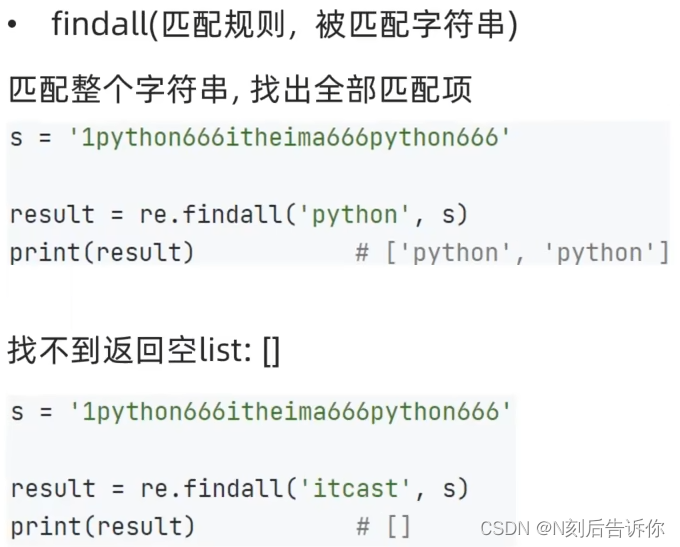
- re.findall
3.2.6.2 元字符匹配
- 单字符匹配

字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
- 数量匹配
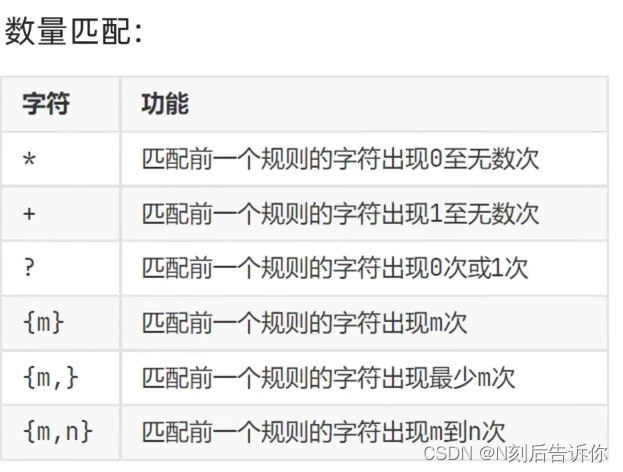
- 边界匹配
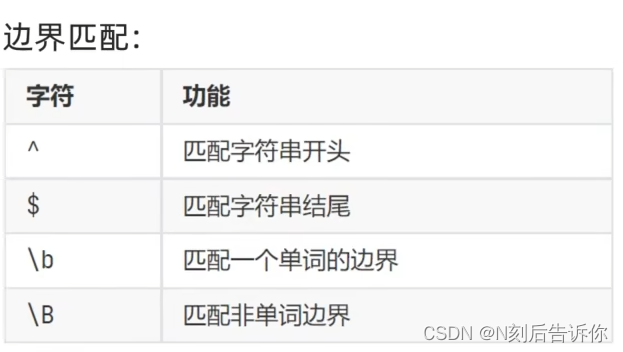
- 分组匹配

- 案例

{}中间别带空格
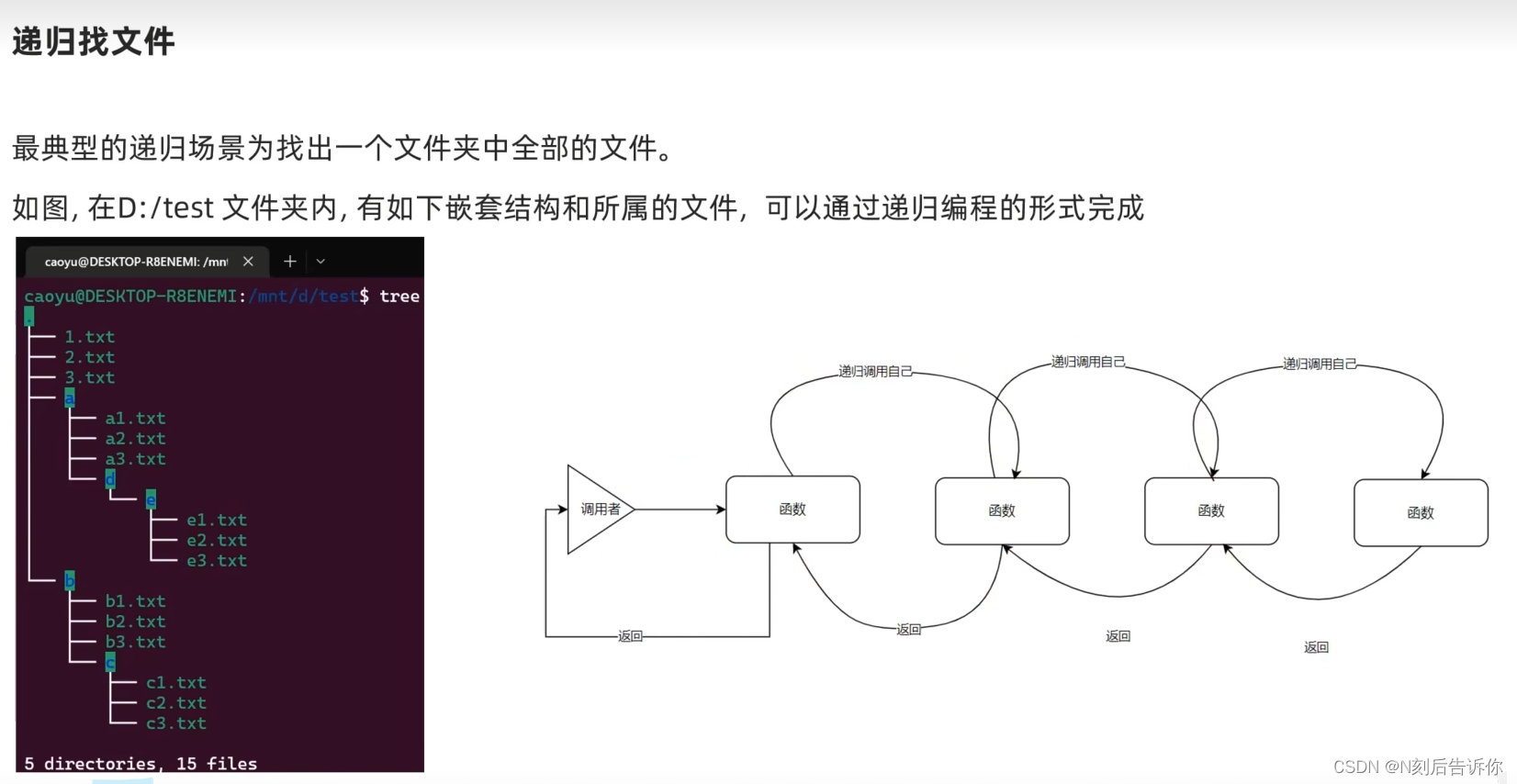
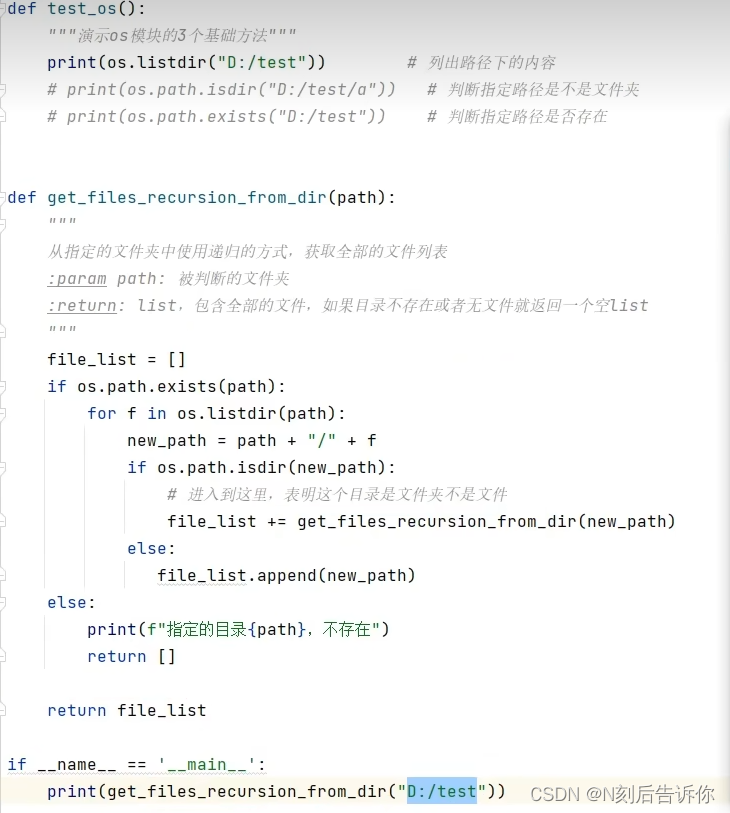
3.2.7 递归

















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









