






基本概念
超平面:超平面是SVM中用于分割不同类别数据的决策边界。在线性可分的情况下,SVM试图找到一个超平面,使得不同类别之间的间隔最大化。这个最大间隔确保了模型具有良好的泛化能力,即使面对未知数据也能做出准确的分类
支持向量:支持向量机的核心概念之一是支持向量。在SVM中,支持向量是指距离超平面最近的几个数据点,这些点正是最难分类的数据点,同时也是对决策边界最有影响力的点。如果这些支持向量发生变化,那么超平面的位置也会随之改变,从而影响整个模型的分类效果。
过拟合和欠拟合
1、理解
经验误差:模型对训练集数据的误差
泛化误差:对测试集数据的误差称
模型的泛化能力:模型对训练集以外样本的预测能力,追求这种泛化能力始终是机器学习的目标
拟合(Fitting):就是说这个曲线能不能很好的描述某些样本,并且有比较好的泛化能力。
过拟合(Over Fitting):算法所训练的模型过多的表达了数据间的噪音关系 。
欠拟合(Under Fitting):算法所训练的模型不能完全表述数据关系。
过拟合(overfitting)和欠拟合(underfitting)是导致模型泛化能力不高的两种常见原因,都是模型学习能力与数据复杂度之间失配的结果。“欠拟合”常常在模型学习能力较弱,而数据复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致泛化能力弱。与之相反,“过拟合”常常在模型学习能力过强的情况中出现,此时的模型学习能力太强,以至于将训练集单个样本自身的特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化能力下降。过拟合与欠拟合的区别在于,欠拟合在训练集和测试集上的性能都较差,而过拟合往往能较好地学习训练集数据的性质,而在测试集上的性能较差。在神经网络训练的过程中,欠拟合主要表现为输出结果的高偏差,而过拟合主要表现为输出结果的高方差
核函数
支持向量机算法分类和回归方法的中都支持线性性和非线性类型的数据类型。非线性类型通常是二维平面不可分,为了使数据可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易区分,这样就达到数据分类或回归的目的,而实现这一目标的函数称为核函数。
工作原理:当低维空间内线性不可分时,可以通过高位空间实现线性可分。但如果在高维空间内直接进行分类或回归时,则存在确定非线性映射函数的形式和参数问题,而最大的障碍就是高维空间的运算困难且结果不理想。通过核函数的方法,可以将高维空间内的点积运算,巧妙转化为低维输入空间内核函数的运算,从而有效解决这一问题。
- 线性核:适用于线性可分问题。
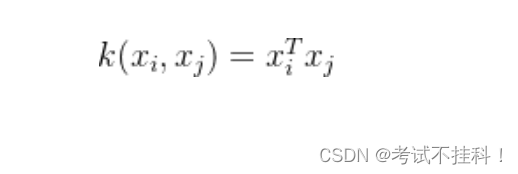
- 多项式核:适用于非线性数据。

- 高斯核(RBF 核):适用于复杂非线性数据。
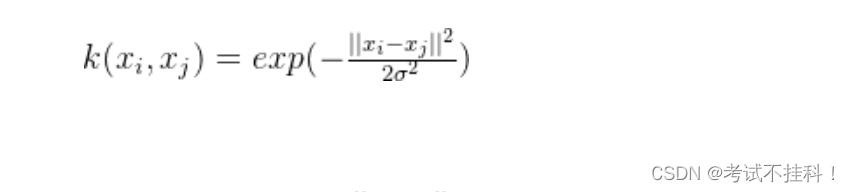
软间隔和硬间隔
假如数据是完全的线性可分的,那么学习到的模型可以称为硬间隔支持向量机。换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误。
硬间隔:
1.求解间隔
求解目的
假设两类数据可以被H={x:wTx+b≥ε}分离,垂直于法向量w,移动H直到碰到某个训练点,可以得到两个超平面H1和H2,两个平面称为支撑超平面,它们分别支撑两类数据。而位于H1和 H2正中间的超平面是分离这两类数据最好的选择
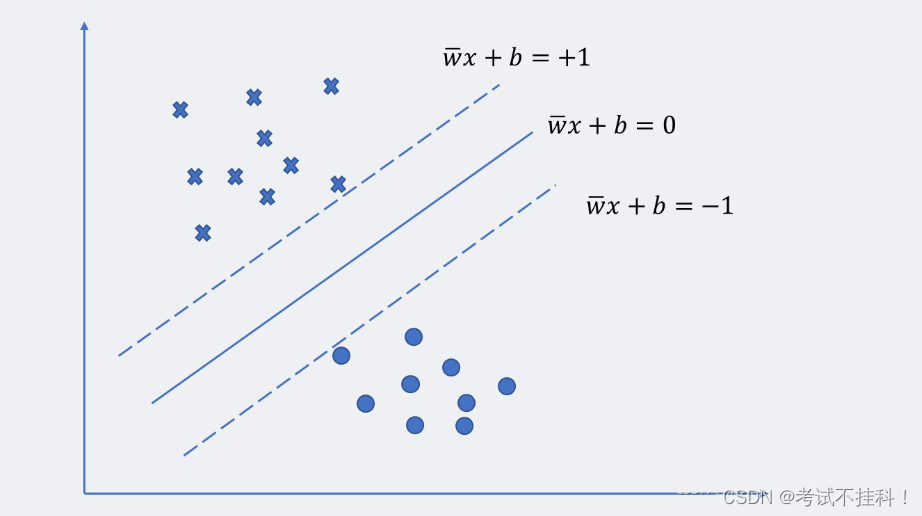
法向量w有很多中选择,超平面H1和H2之间的距离称为间隔,这个间隔是w的函数,目的就是寻找这样的 w 使得间隔达到最大。
2.对偶问题(拉格朗日函数)
利用拉格朗日优化方法可以把可以2.2中的最大间隔问题转换为比较简单的对偶问题,首先定义凸二次规划的拉格朗日函数:
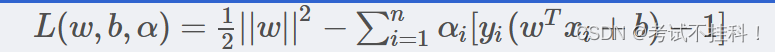

软间隔:
1.松弛变量

2.对偶问题
硬间隔SVM要求训练数据是线性可分的,对噪声敏感;而软间隔SVM允许一定程度上的分类错误,提高了模型的泛化能力。
python实现
svm分类
案例分析:鸢尾花分类
Python 实现:
# 导入所需库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建 SVM 模型
svm = SVC(kernel='linear', C=1, random_state=42)
svm.fit(X_train, y_train)
# 预测测试集
y_pred = svm.predict(X_test)
# 输出分类报告和混淆矩阵
print("Classification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
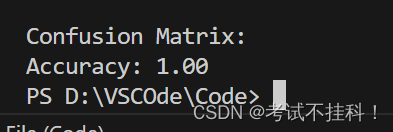
print("Confusion Matrix:")
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
# 输出准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")结果:
案例分析:使用非线性核(RBF 核)进行分类
Python 实现:
# 导入所需库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建 SVM 模型(使用 RBF 核)
svm_rbf = SVC(kernel='rbf', C=1, gamma=0.1, random_state=42)
svm_rbf.fit(X_train, y_train)
# 预测测试集
y_pred_rbf = svm_rbf.predict(X_test)
# 输出分类报告和混淆矩阵
print("\nClassification Report (RBF Kernel):")
print(classification_report(y_test, y_pred_rbf, target_names=iris.target_names))
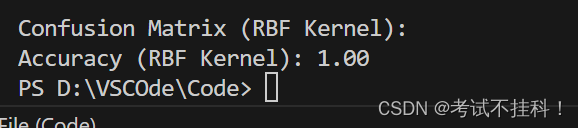
print("Confusion Matrix (RBF Kernel):")
cm_rbf = confusion_matrix(y_test, y_pred_rbf)
sns.heatmap(cm_rbf, annot=True, fmt="d", cmap="Blues", xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
# 输出准确率
accuracy_rbf = accuracy_score(y_test, y_pred_rbf)
print(f"Accuracy (RBF Kernel): {accuracy_rbf:.2f}")结果:
实际应用案例:手写数字识别
我们可以将 SVM 应用于手写数字识别问题。MNIST 数据集是一个常见的基准测试数据集,包含 0 到 9 的手写数字图像。
Python 实现:手写数字识别案例
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用 GridSearchCV 进行超参数调优
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [0.01, 0.1, 1, 10],
'kernel': ['linear', 'rbf']
}
svm = SVC(random_state=42)
grid_search = GridSearchCV(estimator=svm, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数组合
print("Best Parameters:", grid_search.best_params_)
# 使用最佳参数组合进行分类
best_svm = grid_search.best_estimator_
y_pred = best_svm.predict(X_test)
# 输出分类报告
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=[str(i) for i in range(10)]))
# 输出准确率
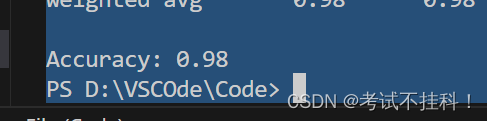
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 绘制混淆矩阵
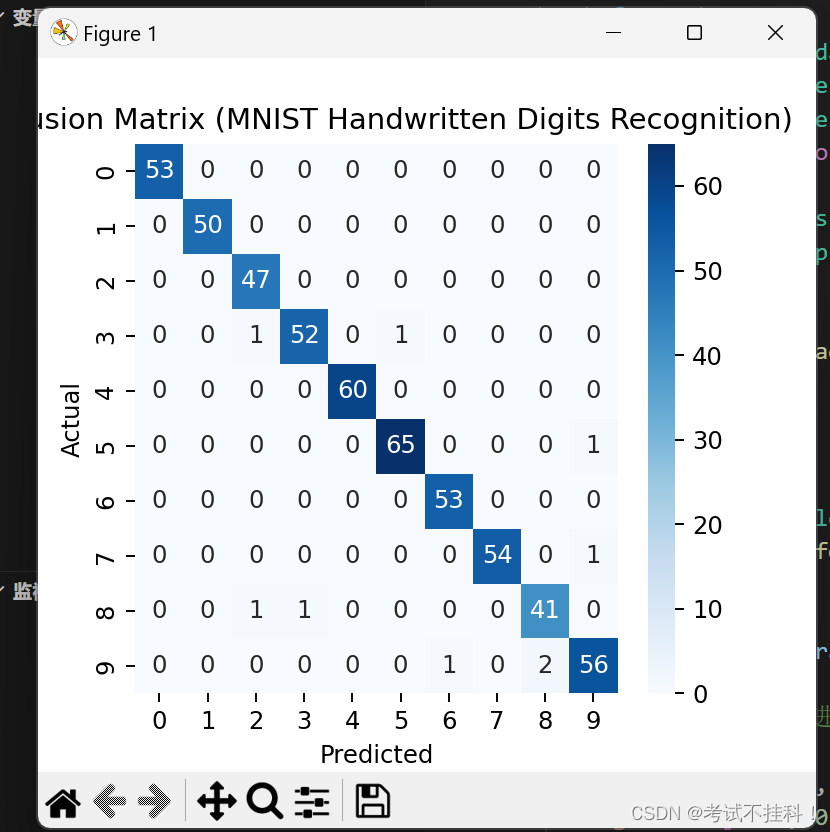
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=[str(i) for i in range(10)], yticklabels=[str(i) for i in range(10)])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix (MNIST Handwritten Digits Recognition)")
plt.show()结果:
总结
SVM的使用准则:
SVM使用准则:n 为特征数, m为训练样本数。
1.如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
2.如果n较小,而且m大小中等,例如n在 1-1000 之间,而m在10-10000之间,使用高斯核函数的支持向量机。
3.如果n较小,而m较大,例如n在1-1000之间,而𝑚大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
SVM的优缺点
支持向量机(SVM)是一种有监督的机器学习模型,主要用于分类和回归问题。它通过寻找最优的决策边界,即最大化不同类别之间的间隔,来实现对数据的分类。其优点包括解决小样本问题、避免维数灾难、解线性不可分问题等。缺点则包括难以处理大规模数据、多分类问题解决不理想、对缺失数据敏感等。
SVM的优点:
-
解决小样本问题:SVM非常适合处理小样本数据集,能够在数据量较少的情况下实现较好的分类效果。
-
避免维数灾难:通过使用核函数技术,SVM能够有效地避免维数灾难,使得在高维空间中进行分类成为可能,而不会增加计算的复杂度。
-
解决线性不可分问题:对于线性不可分的数据集,SVM可以通过引入松弛变量和核函数将数据映射到更高维度的空间中,使其变得线性可分。
-
最大化间隔分类:SVM的核心思想是寻找一个最优的超平面,以最大化不同类别之间的间隔,从而提高分类的准确性和泛化能力。
-
支持向量决定决策边界:SVM的最终决策函数只由少数的支持向量所确定,这意味着计算的复杂性取决于支持向量的数目,而不是整个样本空间的维数,这在一定程度上减少了计算量。
SVM的缺点:
-
难以处理大规模数据:由于SVM需要计算和存储核矩阵,对于大规模数据集来说,这会占用大量的内存和计算资源,导致训练过程缓慢甚至无法完成。
-
多分类问题解决不理想:经典的SVM主要针对二分类问题设计,虽然存在一些策略将其扩展到多分类问题,但效果通常不如专门的多分类算法理想。
-
对缺失数据敏感:SVM对数据的缺失和噪声非常敏感,这可能导致模型性能显著下降,因此在使用前通常需要对数据进行预处理。
-
参数和核函数选择关键:SVM的性能在很大程度上依赖于正确的参数设置和核函数的选择,这需要用户有一定的专业知识和经验。















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









