






可做毕设的网站+星火大模型
目录
下载文档
找到星火文档并下载,我用的是“Python 带上下文调用示例”
 https://www.xfyun.cn/doc/spark/Web.html#_2-function-call%E8%AF%B4%E6%98%8E
https://www.xfyun.cn/doc/spark/Web.html#_2-function-call%E8%AF%B4%E6%98%8ESparkPythondemo.py 代码,记得修改appid、api_secret、api_key
代码,记得修改appid、api_secret、api_key
# coding: utf-8
import SparkApi
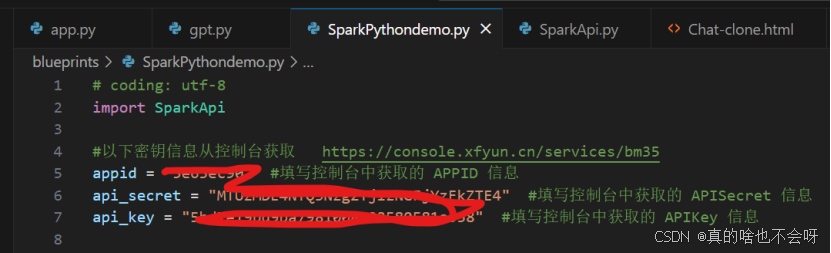
#以下密钥信息从控制台获取 https://console.xfyun.cn/services/bm35
appid = "自己的appid " #填写控制台中获取的 APPID 信息
api_secret = "自己的api_secret " #填写控制台中获取的 APISecret 信息
api_key = "自己的api_key " #填写控制台中获取的 APIKey 信息
domain = "generalv3.5" # Max版本
#domain = "generalv3" # Pro版本
#domain = "general" # Lite版本
Spark_url = "wss://spark-api.xf-yun.com/v3.5/chat" # Max服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v3.1/chat" # Pro服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v1.1/chat" # Lite服务地址
#初始上下文内容,当前可传system、user、assistant 等角色
text = [
# {"role": "system", "content": "你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} , # 设置对话背景或者模型角色
# {"role": "user", "content": "你是谁"}, # 用户的历史问题
# {"role": "assistant", "content": "....."} , # AI的历史回答结果
# # ....... 省略的历史对话
# {"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题
]
def getText(role, content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text
# 调用函数
def spark_api(question):
"""
"param question:
:return:
"""
question = checklen(getText("user", question))
SparkApi.answer = ""
SparkApi.main(appid, api_key, api_secret, Spark_url, domain, question)
text.clear()
print(SparkApi.answer)
return SparkApi.answer
if __name__ == '__main__':
while (1):
Input = input("\n" + "我:")
question = checklen(getText("user", Input))
SparkApi.answer = ""
print("星火:", end="")
SparkApi.main(appid, api_key, api_secret, Spark_url, domain, question)
# print(SparkApi.answer)
getText("assistant", SparkApi.answer)
print("================")
print(question)
验证使用
打开SparkPythondemo.py文件,把appid、api_secret、api_key填写完整
此时可以验证,大模型是可用的

下面是重点
增加调用函数
在SparkPythondemo.py文件增加一个调用函数
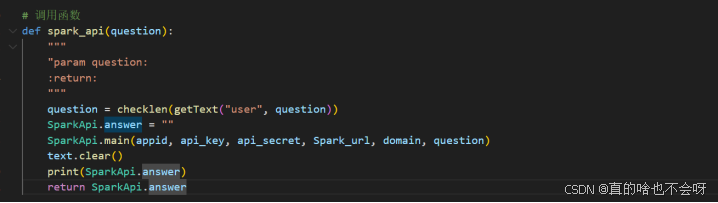
代码如下
# 调用函数
def spark_api(question):
"""
"param question:
:return:
"""
question = checklen(getText("user", question))
SparkApi.answer = ""
SparkApi.main(appid, api_key, api_secret, Spark_url, domain, question)
text.clear()
print(SparkApi.answer)
return SparkApi.answer创建路由
创建gpt.py文件并构建路由,如图所示

代码如下,可以不用复制,后面又完整代
bp = Blueprint('gpt', __name__, url_prefix='/gpt')
@bp.route('/', methods=['GET', 'POST'])
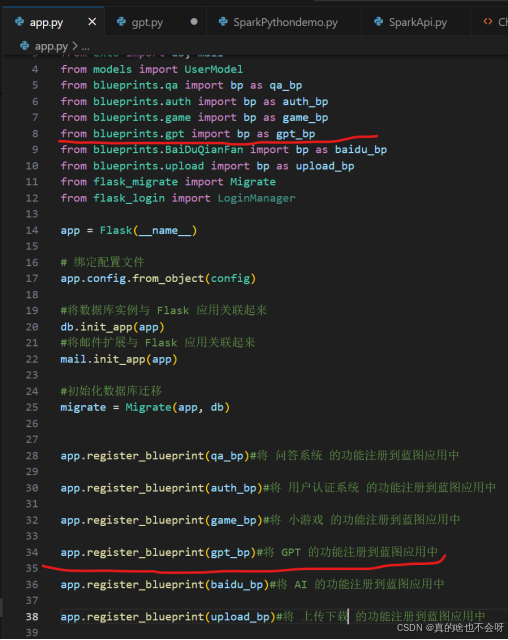
def gpt_index():解构路由
并将路由解构到app.py中,如下图
http请求
找到文档中的“HTTP调用文档”,不想找可以直接粘,如下图
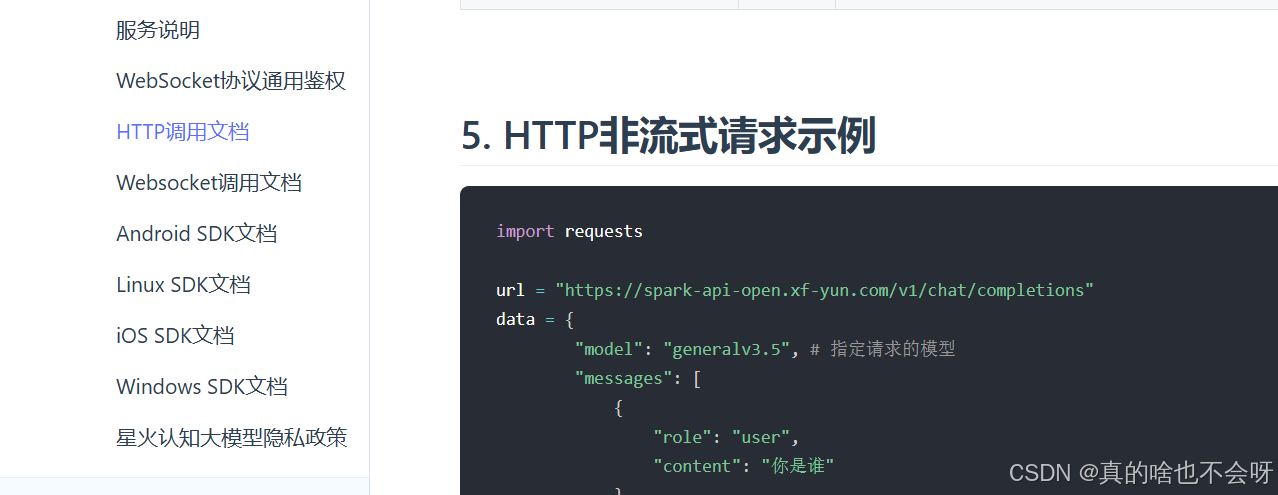 贴复制代码如下
贴复制代码如下
import requests
url = "https://spark-api-open.xf-yun.com/v1/chat/completions"
data = {
"model": "generalv3.5", # 指定请求的模型
"messages": [
{
"role": "user",
"content": "你是谁"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "返回实时天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "河北省承德市双桥区",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用本地区常用的温度单位计量",
},
},
"required": ["location", "format"],
}
}
}
]
}
header = {
"Authorization": "Bearer key123456:secret123456" # 注意此处替换自己的key和secret
}
response = requests.post(url, headers=header, json=data)
print(response.text)点击复制,并粘贴到刚才写好的gpt.py文件中,画红部分为需要增加上的,注意:html文件是引用大模型输出结果的文件
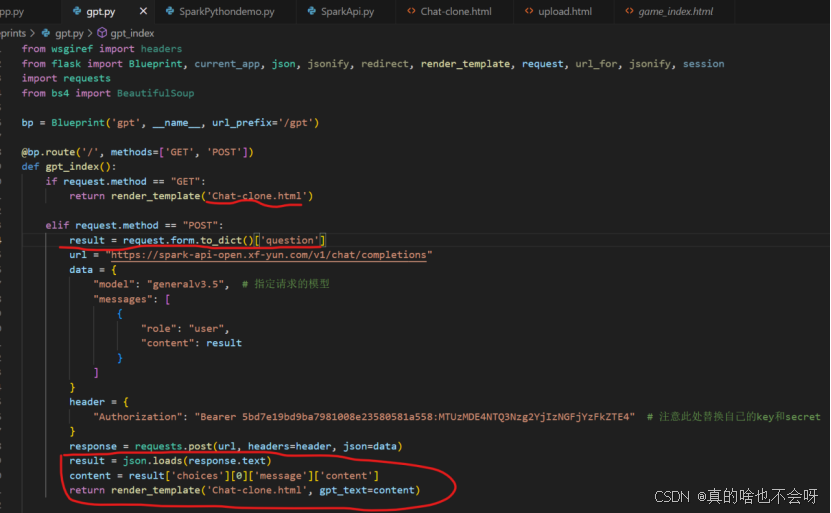
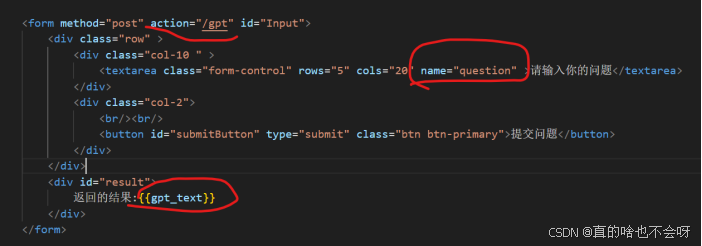
引用到html
最后在html中调用即可,如下图
注意:action中的值需要和路由的保持一致,question需要和gpt.py文件中保持一致{{gpt_text}}即为调用大模型输出
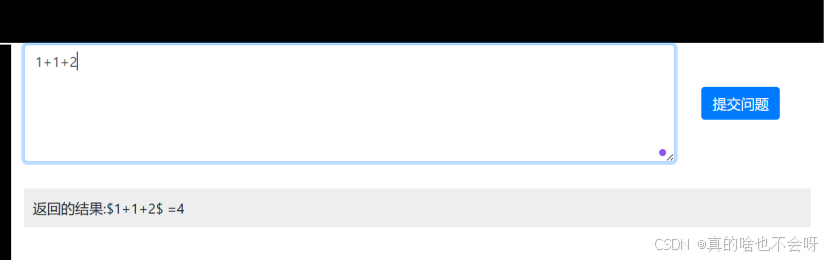
最后展示,如下图
如果有需求请留言


















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









