







仓库部署
仓库地址:https://github.com/Plachtaa/VALL-E-X
安装命令(python3.10.0)
git clone https://github.com/Plachtaa/VALL-E-X.git
cd VALL-E-X
pip install -r requirements.txt
启动命令
python -X utf-8 launch-ui.py
运行后会自动下载模型文件
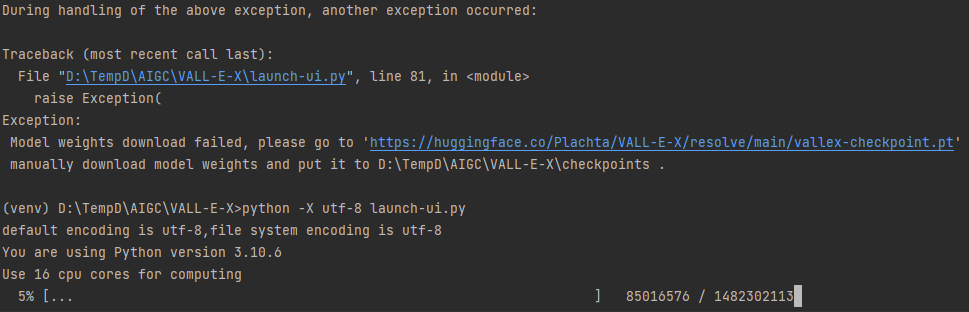
这里可能需要科x上w,不然下载会报错。也可以根据readme的提示手动下载checkpoint文件
启动后的界面
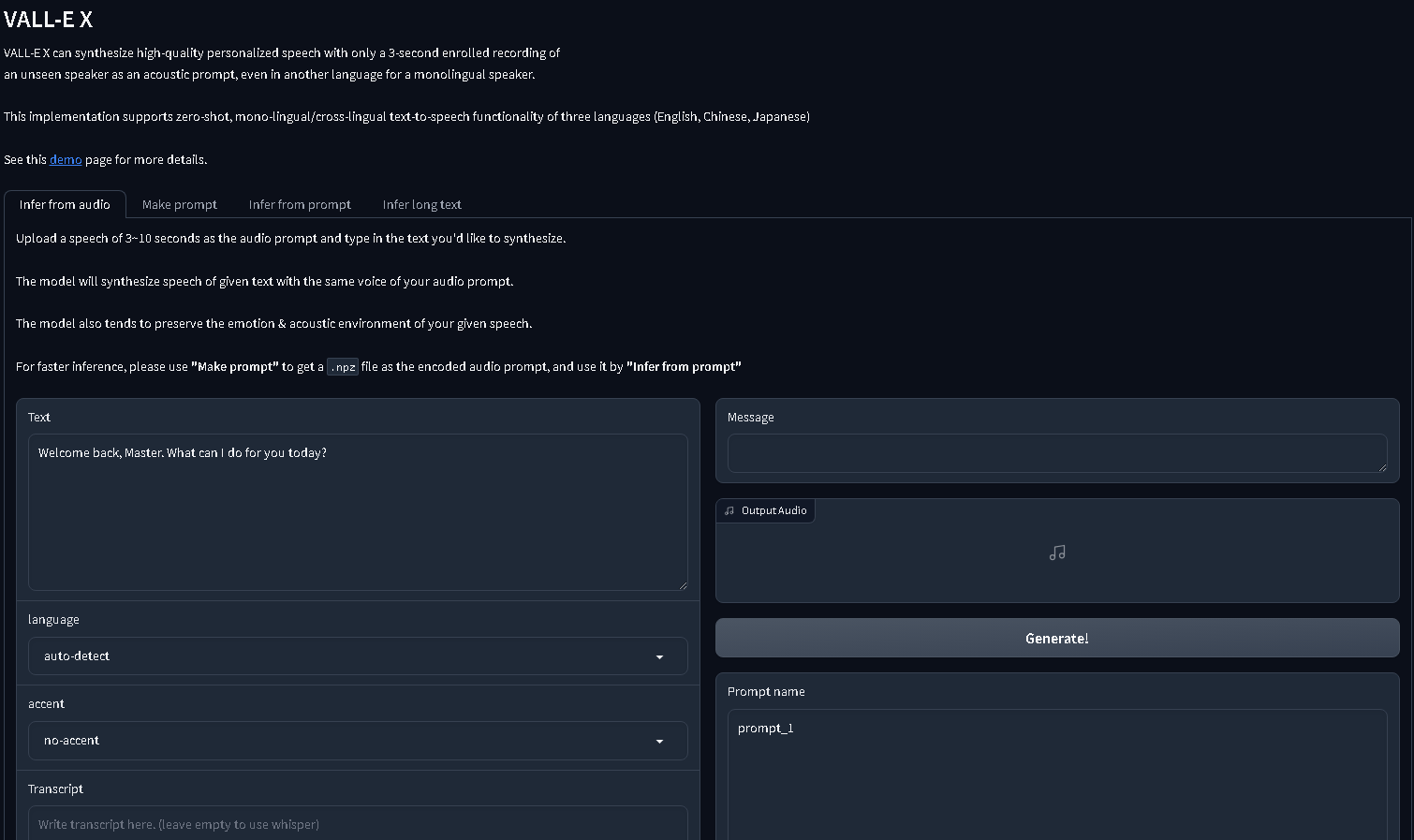
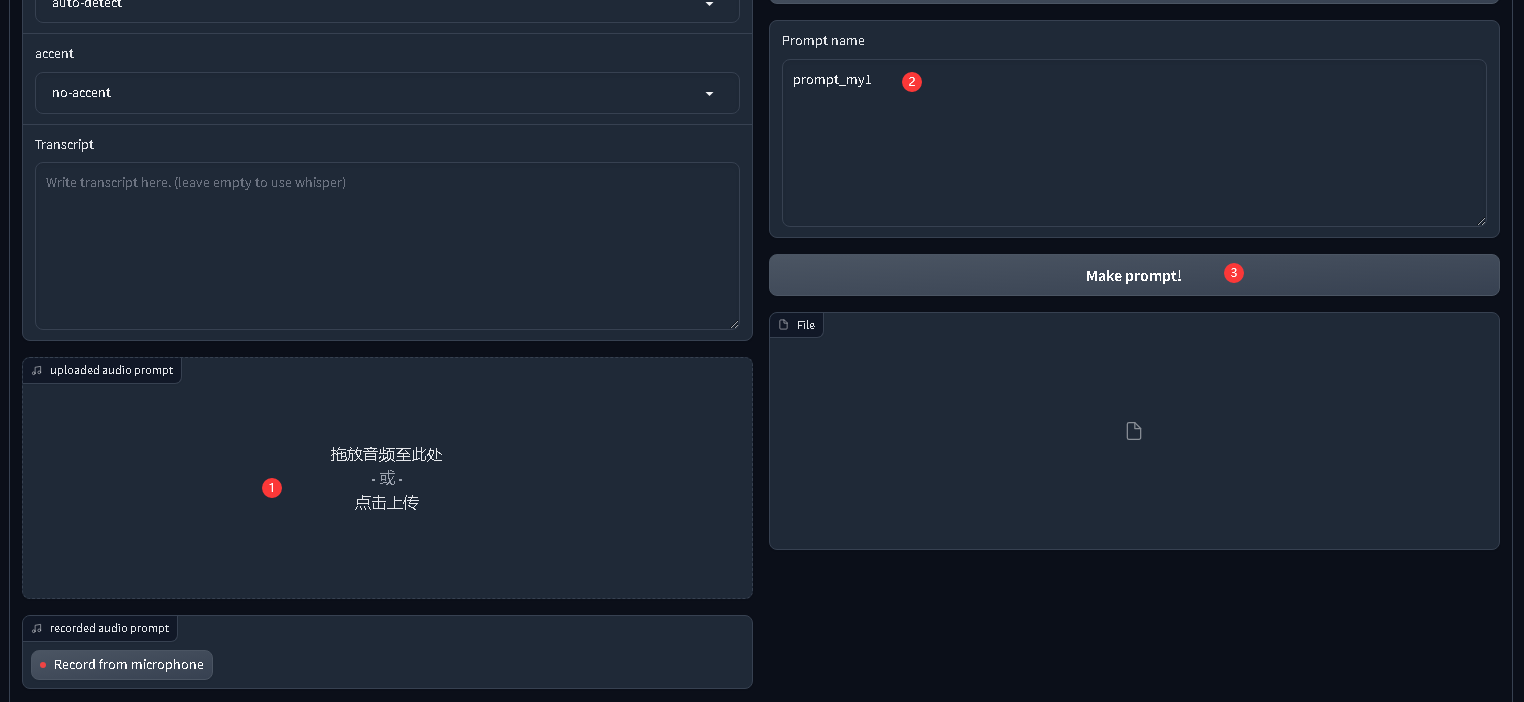
克隆声音
序号1上传自己录制的音频,序号2起一个名称,点击make开始克隆
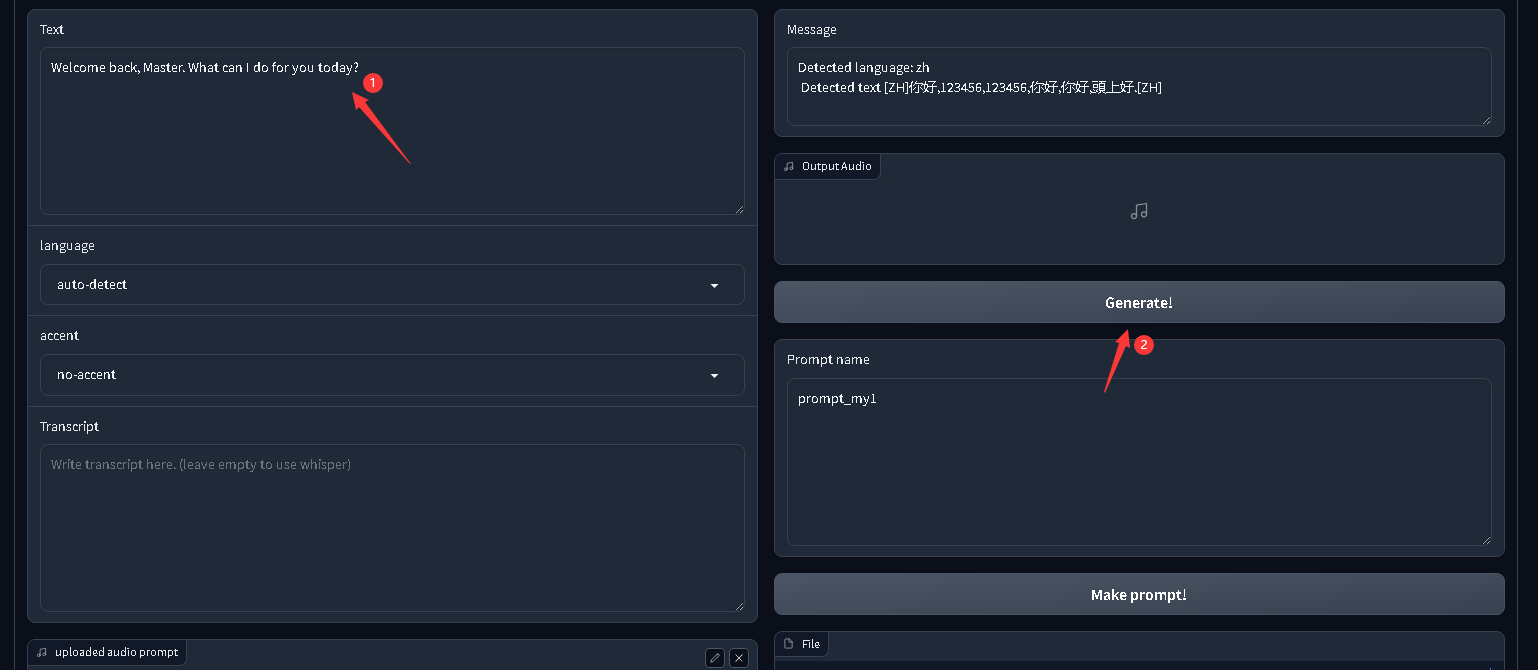
克隆完成后,按下图操作,输入朗读文本,点击生成
显卡加速
默认是用cpu,建议开启显卡加速使用gpu提升速度
先卸载原来的torch
pip uninstall torch torchvision torchaudio
重新安装,cu120表示cuda的版本
pip install torch torchvision torchaudio index-url https://download.pytorch.org/whl/cu121
windows查看cuda版本命令:nvcc --version
重新运行
python -X utf-8 launch-ui.py
现在就可以使用显卡加速了
声音处理
推荐几个声音处理工具
背景音分离:https://github.com/Anjok07/ultimatevocalremovergui
windows下载https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.6/UVR_v5.6.0_setup.exe
声音切片工具:https://github.com/flutydeer/audio-slicer
windows下载https://github.com/flutydeer/audio-slicer/releases
参考
- https://www.cnblogs.com/wuliytTaotao/p/11453265.html#%E6%9F%A5%E7%9C%8B-cuda-%E7%89%88%E6%9C%AC-1
- https://www.youtube.com/watch?v=D8tFRIF92WY
欢迎关注破晓一代公众号,获取最新ai开源工具使用教程

原文博客:https://blog.abyssdawn.com/archives/236.html















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









