






栈区是什么?
栈区是计算机内存的其中一部分,用于存储函数调用时存储该函数的局部变量、函数形参、返回地址等信息,栈是一种后进先出的结构。
栈区的定义和使用?
相信小伙伴们都会很困惑栈区既然是存储数据的,那么应该要怎么样去使用栈去存储呢?其实栈的使用在我们平时运行程序的时候就已经使用了,下面XxxHe来给小伙伴们说说叭~
首先,栈区的内存不是我们人为去控制的,而是由操作系统自动分配和释放的
在程序运行的时候系统就已经自动创建了一个主函数(main函数)的栈区,所以我们使用栈区其实就是在主函数内定义所有的局部变量和函数等数据都是存储在这个栈区(压入这个栈中)也叫压栈,也可以理解成栈就是一个水杯,往里面装水,后面装进来的水,会被先喝掉。下面给小伙伴们看 代码以及画图 感受一下


注意:在主函数中调用函数的时候,程序会创建一个新的栈,首先把该函数中的返回地址先存入栈底中,(这个返回地址时再物理内存中的)
这是因为调用的函数执行完毕后,程序需要知道返回到哪里继续执行代码,所有,调用函数的时候程序会新建一个栈,首先把 返回地址 先存入栈中(也叫压入栈中),然后在跳转到该函数的入口开始执行这个函数,当被调用函数被执行完毕后,程序会从栈中取出返回地址,跳转回原来的函数继续执行代码。
下面我来给小伙伴们用代码演示一下:
int fun(int x)
{
int y = x + 1;
return y;
}
#include<stdio.h>
int main()
{
int a = 5;
int b = 0;
-> fun(a);
int c = 1;
return 0;
}
当程序运行到->位置(fun(a) )的时候,程序会自动创建一个新的栈,首先把返回地址存入这块空间,然后跳转到函数的入口
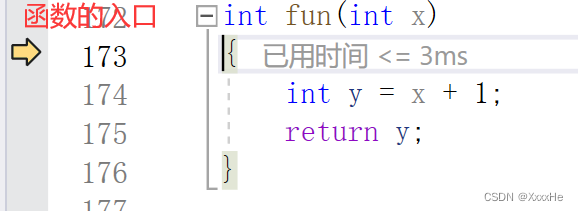
然后再把函数的形参、局部变量等信息存入栈中


 新创建的栈
新创建的栈
当被调用函数执行到完后,也就是执行到了ruturn y,程序会把y放进返回地址中。然后通过返回地址带着y的值返回到了主函数中。
















 9371
9371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









