






 本文利用机器学习技术,以Kaggle数据集为基础,用pandas进行数据清洗、转换和特征提取,用sklearn构建逻辑回归模型预测员工离职概率。经过数据准备、处理缺失值和异常值、预处理、建模、验证等步骤,识别出影响离职的关键因素,并在测试集上完成预测。
本文利用机器学习技术,以Kaggle数据集为基础,用pandas进行数据清洗、转换和特征提取,用sklearn构建逻辑回归模型预测员工离职概率。经过数据准备、处理缺失值和异常值、预处理、建模、验证等步骤,识别出影响离职的关键因素,并在测试集上完成预测。
数据集可以在我发布的资源里面找到
背景介绍
员工离职预测
为什么我们最好和最有经验的员工过早离职?数据来自Kaggle(大数据机器学习网站)中的,想并尝试预测下一个什么样的有价值的员工将离开。通过分析数据,了解影响员工辞职的因素有哪些,以及最主要的原因,预测哪些优秀员工会离职。
本文用pandas进行数据清洗,数据转换,以及特征提取;用sklearn进行模型构建,模型评估,并进行相关预测。(用特征工程和相关分析的方法),从给定的影响员工离职的因素和员工是否离职的记录(训练集),建立一个逻辑回归模型预测有可能离职的员工。并在测试集上进行预测,给出每位员工离职的概率
模型搭建
数据准备
因为要根据训练积极搭建模型,首先要做的就是导入训练集:
import pandas as pd
data = pd.read_csv('D:/学习资料/机器学习/pfm_train.csv') # 查看数据
data.head()
data.head()是用于查看这个csv文件的前几行,我用的是jupyter notebook,如果你用的是python,需要改为print(data.head())
得到结果:

接下来就是分类和数值列:
categorical_cols = data.select_dtypes(include=['object']).columns.tolist()
numerical_cols = data.select_dtypes(exclude=['object']).columns.tolist()
numerical_cols.remove('Attrition') # 移除目标列,这个Attrition是员工是否离职,是我们的目标变量,肯定是不进行清理处理的
Attrition这一列是我们的目标列,也就是员工是否离职,用0和1表示
检查是否存在缺失值和异常值
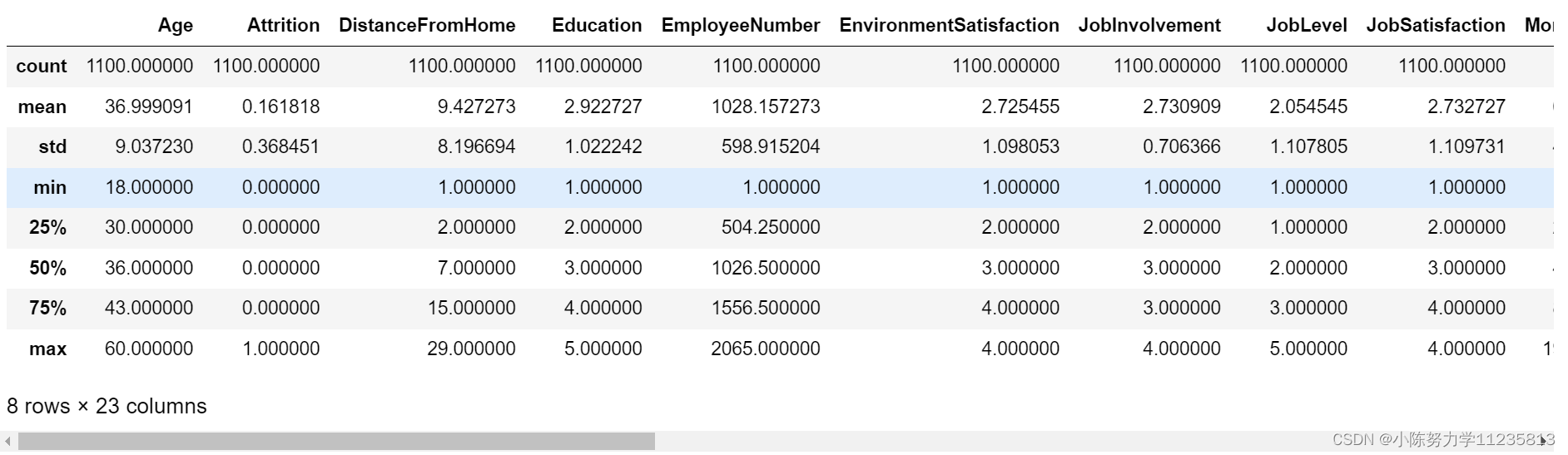
在检查的前后查看一下其描述性统计信息,可以更直观的看到是否处理了异常值
numerical_stats = data.describe() # 查看一下其描述性统计信息
numerical_stats # 同理,也是打印,python的话就加一个print
得到结果如下:
处理缺失值
isnull()判断是否有缺失值,把缺失值的个数加起来
# 查看是否有缺失值
missing_data = data.isnull().sum()
missing_data[missing_data > 0]
得到结果:

从结果可以看到,其实并没有缺失值,所以就不处理了
处理异常值
计算Z-score来检测数值列的潜在异常值,通常认为Z-score的绝对值大于3是异常值。
使用的是中位数来处理异常值,也可以使用平均数等,都可以。
import numpy as np
# 异常值检测和处理
# 计算Z-score来检测数值列的潜在异常值,通常认为Z-score的绝对值大于3是异常值。
z_scores = np.abs((data[numerical_cols] - data[numerical_cols].mean()) / data[numerical_cols].std())
print("异常值数量:", (z_scores > 3).sum()) #打印查看一下异常值数量
# 如果有异常值,则替换为中位数
for column in numerical_cols:
median_val = data[column].median()
extreme_vals = (z_scores[column] > 3)
data.loc[extreme_vals, column] = median_val
print("异常值处理成功!")
得到结果:
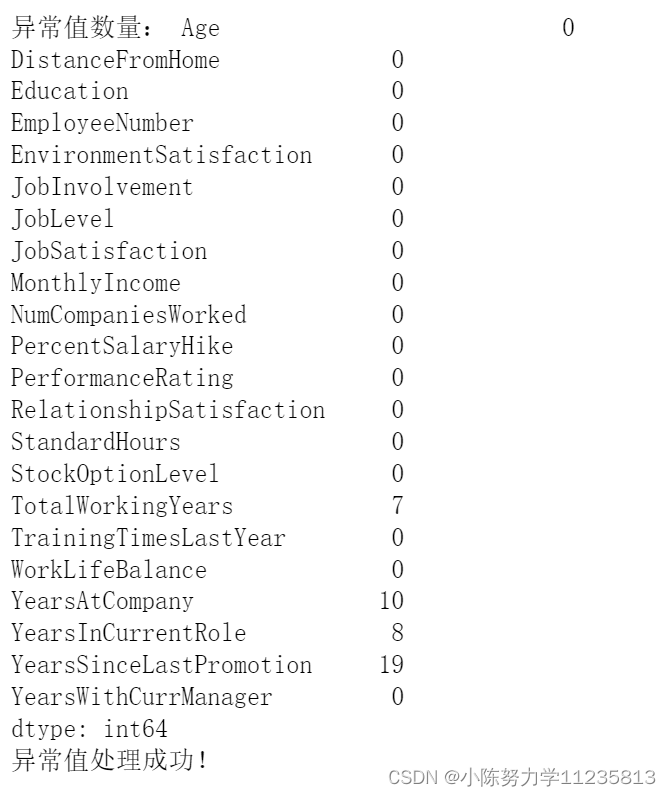
从上面可以看出,这四列确实存在缺失值:TotalWorkingYears、YearsAtCompany、YearsInCurrentRole、YearsSinceLastPromotion。
并且使用中位数处理异常值成功了
检验
数据处理前后进行比对:
# 数据处理之后再查看一下其描述性统计信息,看看清理的结果怎么样
numerical_stats = data.describe()
numerical_stats
就着重看看那些存在异常值的列:
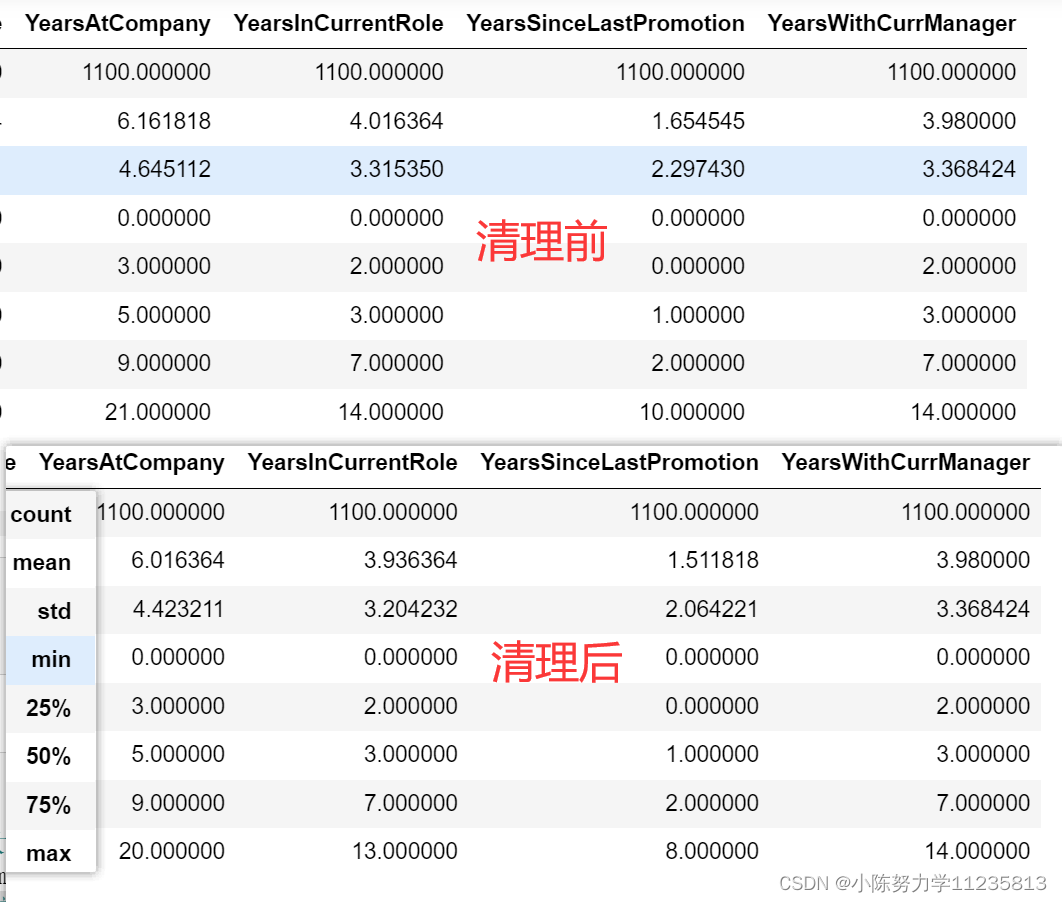
可以看出,数据清理前后确实有变化,说明清理是成功的!
数据预处理
首先是导包,主要导的就是sklearn库,因为这个库里有很好用的逻辑回归
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
数据预处理操作,就是将数据转换成适合机器学习算法处理的形式,确保模型能够有效地学习和进行预测。
然后进行数据预处理操作,分别对数值数据、分类数据进行预处理:
# 数值数据的处理
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')), # 缺失值填充,用中位数填充缺失值
('scaler', StandardScaler()) # 数据标准化,将数据缩放到均值为0和标准差为1的状态。不然某些数值过大,学习器会更关注于那些从而忽略了值较小的部分
])
# 分类数据的处理
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')), # 缺失值填充,用最频繁出现的值填充缺失值。
('onehot', OneHotEncoder(handle_unknown='ignore')) # 对分类数据进行独热编码,将类别型特征转换成机器学习算法易于处理的形式
])
# 组合预处理操作
# 将数值和分类的处理步骤结合起来 使得可以在一个转换器中同时处理所有的数据预处理需求。
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
代码的注释里面写的很清楚了,这里就不过多赘述了。
接下来是准备数据,使特征(X),目标变量(y),X也就是除了Attrition以外的都是特征:
# 准备数据
X = data.drop('Attrition', axis=1)
y = data['Attrition']
X_transformed = preprocessor.fit_transform(X) # 这个是组合后的数据
构建模型
这里就是创建逻辑回归模型并进行评估。
LogisticRegression就是scikit-learn 提供的逻辑回归模型实现,我们直接调用即可。
# 创建逻辑回归模型并评估
model = LogisticRegression(max_iter=1000, random_state=42) # 设置迭代次数为1000,随机数种子为42,确保一致不变,有助于复现代码
cv_scores = cross_val_score(model, X_transformed, y, cv=5, scoring='accuracy') # 这是个库函数,用交叉验证来评估模型性能,cv=5是交叉折叠5次,然后把评估标准设置成了准确度(accuracy)
print("Cross-validated accuracy:", cv_scores.mean()) # 打印交叉验证的结果
代码注释写的也很详细,不赘述了,得到的运行结果:

从结果可以看出:交叉验证准确率 0.8709090909090909,约等于 87.1%,代表了这个逻辑回归模型在多个不同子集上预测员工是否离职的平均性能。
交叉验证准确度:
交叉验证是一种评估模型性能的技术,它将数据分为 k 个“折”或子集。在这个过程中,模型会进行 k 次训练和测试,每次使用不同的折作为测试集,而其余的折则用于训练。这种方法有助于确保模型的评估不受特定数据划分方式的影响,从而提供了更可靠和稳定的性能估计。
验证模型,找到相关变量
先是计算相关矩阵,注意,这里一定要多加一步转化,不然文件中存在非数值列,是无法计算其两列的相似度,会报错的。
# 计算相关矩阵
# 选择数据集中的数值类型列
numerical_data = data.select_dtypes(include=[np.number]) # 只能计算数值列的,不然会报错,一定要转
correlation_matrix = numerical_data.corr() # .corr() #计算每列两两之间的相似度。
print("Correlation matrix:\n", correlation_matrix)
# 显示与离职相关的特征
attrition_correlation = correlation_matrix['Attrition'].sort_values()
print("Correlation of features with Attrition:\n", attrition_correlation)
得到的结果如下,太多太大了,我就放在代码块里面了:
Correlation matrix:
Age Attrition DistanceFromHome Education \
Age 1.000000 -0.175393 0.007081 0.198558
Attrition -0.175393 1.000000 0.088563 -0.046494
DistanceFromHome 0.007081 0.088563 1.000000 0.011437
Education 0.198558 -0.046494 0.011437 1.000000
EmployeeNumber -0.010953 -0.045168 0.029930 0.055979
EnvironmentSatisfaction 0.011803 -0.097003 -0.010308 -0.032698
JobInvolvement 0.066528 -0.122722 0.012333 0.022843
JobLevel 0.513882 -0.168775 0.016470 0.084075
JobSatisfaction -0.003744 -0.125568 -0.009641 -0.010201
MonthlyIncome 0.500163 -0.155521 -0.017757 0.079834
NumCompaniesWorked 0.291211 0.025889 -0.016378 0.118484
PercentSalaryHike -0.011259 0.026604 0.042627 -0.008828
PerformanceRating -0.029613 0.046762 0.021042 -0.000045
RelationshipSatisfaction 0.063489 -0.051749 0.018112 -0.006346
StandardHours NaN NaN NaN NaN
StockOptionLevel -0.002413 -0.138498 0.050356 0.035881
TotalWorkingYears 0.598799 -0.201310 0.003631 0.088424
TrainingTimesLastYear -0.051702 -0.043395 -0.041208 -0.021629
WorkLifeBalance -0.001042 -0.048794 -0.050950 0.003099
YearsAtCompany 0.182355 -0.177498 0.035721 0.055822
YearsInCurrentRole 0.182972 -0.173931 0.020818 0.064057
YearsSinceLastPromotion 0.091140 -0.027641 0.007284 0.046357
YearsWithCurrManager 0.187984 -0.150619 0.004100 0.051873
EmployeeNumber EnvironmentSatisfaction \
Age -0.010953 0.011803
Attrition -0.045168 -0.097003
DistanceFromHome 0.029930 -0.010308
Education 0.055979 -0.032698
EmployeeNumber 1.000000 0.030428
EnvironmentSatisfaction 0.030428 1.000000
JobInvolvement -0.008589 -0.028467
JobLevel -0.006121 -0.015355
JobSatisfaction -0.042443 0.000212
MonthlyIncome -0.007147 -0.026410
NumCompaniesWorked -0.014460 -0.010743
PercentSalaryHike 0.003462 -0.008882
PerformanceRating -0.023701 -0.025044
RelationshipSatisfaction -0.073687 0.033515
StandardHours NaN NaN
StockOptionLevel 0.049967 0.008874
TotalWorkingYears -0.006900 -0.050043
TrainingTimesLastYear 0.017175 -0.045686
WorkLifeBalance 0.000548 0.026477
YearsAtCompany 0.038991 0.006921
YearsInCurrentRole 0.004523 0.037960
YearsSinceLastPromotion 0.018256 0.030337
YearsWithCurrManager 0.016041 -0.016985
JobInvolvement JobLevel JobSatisfaction \
Age 0.066528 0.513882 -0.003744
Attrition -0.122722 -0.168775 -0.125568
DistanceFromHome 0.012333 0.016470 -0.009641
Education 0.022843 0.084075 -0.010201
EmployeeNumber -0.008589 -0.006121 -0.042443
EnvironmentSatisfaction -0.028467 -0.015355 0.000212
JobInvolvement 1.000000 0.005983 -0.016382
JobLevel 0.005983 1.000000 -0.005894
JobSatisfaction -0.016382 -0.005894 1.000000
MonthlyIncome 0.006114 0.950776 -0.009752
NumCompaniesWorked 0.053557 0.157068 -0.061091
PercentSalaryHike 0.002377 -0.066353 0.019032
PerformanceRating 0.000742 -0.046019 -0.011615
RelationshipSatisfaction 0.048363 0.042156 -0.033138
StandardHours NaN NaN NaN
StockOptionLevel 0.029483 0.002638 0.021123
TotalWorkingYears 0.018176 0.705627 -0.017597
TrainingTimesLastYear -0.018001 -0.034620 0.002754
WorkLifeBalance -0.025862 0.041258 -0.042767
YearsAtCompany 0.019758 0.312715 0.018132
YearsInCurrentRole -0.026468 0.334476 -0.007091
YearsSinceLastPromotion 0.004055 0.161269 0.003366
YearsWithCurrManager 0.009974 0.358012 -0.035997
MonthlyIncome ... RelationshipSatisfaction \
Age 0.500163 ... 0.063489
Attrition -0.155521 ... -0.051749
DistanceFromHome -0.017757 ... 0.018112
Education 0.079834 ... -0.006346
EmployeeNumber -0.007147 ... -0.073687
EnvironmentSatisfaction -0.026410 ... 0.033515
JobInvolvement 0.006114 ... 0.048363
JobLevel 0.950776 ... 0.042156
JobSatisfaction -0.009752 ... -0.033138
MonthlyIncome 1.000000 ... 0.050121
NumCompaniesWorked 0.164627 ... 0.067295
PercentSalaryHike -0.056469 ... -0.024349
PerformanceRating -0.036086 ... -0.011516
RelationshipSatisfaction 0.050121 ... 1.000000
StandardHours NaN ... NaN
StockOptionLevel -0.006320 ... -0.060822
TotalWorkingYears 0.687480 ... 0.051639
TrainingTimesLastYear -0.039713 ... -0.004741
WorkLifeBalance 0.032247 ... 0.033513
YearsAtCompany 0.277928 ... -0.041418
YearsInCurrentRole 0.305542 ... -0.032732
YearsSinceLastPromotion 0.158702 ... 0.030564
YearsWithCurrManager 0.320800 ... -0.012252
StandardHours StockOptionLevel TotalWorkingYears \
Age NaN -0.002413 0.598799
Attrition NaN -0.138498 -0.201310
DistanceFromHome NaN 0.050356 0.003631
Education NaN 0.035881 0.088424
EmployeeNumber NaN 0.049967 -0.006900
EnvironmentSatisfaction NaN 0.008874 -0.050043
JobInvolvement NaN 0.029483 0.018176
JobLevel NaN 0.002638 0.705627
JobSatisfaction NaN 0.021123 -0.017597
MonthlyIncome NaN -0.006320 0.687480
NumCompaniesWorked NaN 0.007861 0.248913
PercentSalaryHike NaN 0.016313 -0.048320
PerformanceRating NaN -0.007239 -0.019032
RelationshipSatisfaction NaN -0.060822 0.051639
StandardHours NaN NaN NaN
StockOptionLevel NaN 1.000000 0.011119
TotalWorkingYears NaN 0.011119 1.000000
TrainingTimesLastYear NaN 0.005927 -0.035564
WorkLifeBalance NaN 0.015239 0.007526
YearsAtCompany NaN 0.045569 0.444789
YearsInCurrentRole NaN 0.070433 0.392720
YearsSinceLastPromotion NaN 0.004837 0.169821
YearsWithCurrManager NaN 0.042390 0.403129
TrainingTimesLastYear WorkLifeBalance \
Age -0.051702 -0.001042
Attrition -0.043395 -0.048794
DistanceFromHome -0.041208 -0.050950
Education -0.021629 0.003099
EmployeeNumber 0.017175 0.000548
EnvironmentSatisfaction -0.045686 0.026477
JobInvolvement -0.018001 -0.025862
JobLevel -0.034620 0.041258
JobSatisfaction 0.002754 -0.042767
MonthlyIncome -0.039713 0.032247
NumCompaniesWorked -0.078332 0.003999
PercentSalaryHike 0.015905 0.017415
PerformanceRating -0.007090 0.023840
RelationshipSatisfaction -0.004741 0.033513
StandardHours NaN NaN
StockOptionLevel 0.005927 0.015239
TotalWorkingYears -0.035564 0.007526
TrainingTimesLastYear 1.000000 0.046454
WorkLifeBalance 0.046454 1.000000
YearsAtCompany -0.011712 0.011609
YearsInCurrentRole 0.005169 0.025616
YearsSinceLastPromotion 0.024405 -0.010816
YearsWithCurrManager -0.015110 0.007097
YearsAtCompany YearsInCurrentRole \
Age 0.182355 0.182972
Attrition -0.177498 -0.173931
DistanceFromHome 0.035721 0.020818
Education 0.055822 0.064057
EmployeeNumber 0.038991 0.004523
EnvironmentSatisfaction 0.006921 0.037960
JobInvolvement 0.019758 -0.026468
JobLevel 0.312715 0.334476
JobSatisfaction 0.018132 -0.007091
MonthlyIncome 0.277928 0.305542
NumCompaniesWorked -0.103209 -0.091317
PercentSalaryHike -0.032669 -0.009041
PerformanceRating -0.000428 0.011592
RelationshipSatisfaction -0.041418 -0.032732
StandardHours NaN NaN
StockOptionLevel 0.045569 0.070433
TotalWorkingYears 0.444789 0.392720
TrainingTimesLastYear -0.011712 0.005169
WorkLifeBalance 0.011609 0.025616
YearsAtCompany 1.000000 0.741722
YearsInCurrentRole 0.741722 1.000000
YearsSinceLastPromotion 0.362233 0.393288
YearsWithCurrManager 0.721214 0.693625
YearsSinceLastPromotion YearsWithCurrManager
Age 0.091140 0.187984
Attrition -0.027641 -0.150619
DistanceFromHome 0.007284 0.004100
Education 0.046357 0.051873
EmployeeNumber 0.018256 0.016041
EnvironmentSatisfaction 0.030337 -0.016985
JobInvolvement 0.004055 0.009974
JobLevel 0.161269 0.358012
JobSatisfaction 0.003366 -0.035997
MonthlyIncome 0.158702 0.320800
NumCompaniesWorked -0.051612 -0.116012
PercentSalaryHike -0.069434 -0.032445
PerformanceRating -0.035502 -0.003483
RelationshipSatisfaction 0.030564 -0.012252
StandardHours NaN NaN
StockOptionLevel 0.004837 0.042390
TotalWorkingYears 0.169821 0.403129
TrainingTimesLastYear 0.024405 -0.015110
WorkLifeBalance -0.010816 0.007097
YearsAtCompany 0.362233 0.721214
YearsInCurrentRole 0.393288 0.693625
YearsSinceLastPromotion 1.000000 0.394850
YearsWithCurrManager 0.394850 1.000000
[23 rows x 23 columns]
Correlation of features with Attrition:
TotalWorkingYears -0.201310
YearsAtCompany -0.177498
Age -0.175393
YearsInCurrentRole -0.173931
JobLevel -0.168775
MonthlyIncome -0.155521
YearsWithCurrManager -0.150619
StockOptionLevel -0.138498
JobSatisfaction -0.125568
JobInvolvement -0.122722
EnvironmentSatisfaction -0.097003
RelationshipSatisfaction -0.051749
WorkLifeBalance -0.048794
Education -0.046494
EmployeeNumber -0.045168
TrainingTimesLastYear -0.043395
YearsSinceLastPromotion -0.027641
NumCompaniesWorked 0.025889
PercentSalaryHike 0.026604
PerformanceRating 0.046762
DistanceFromHome 0.088563
Attrition 1.000000
StandardHours NaN
Name: Attrition, dtype: float64
分析步骤以及主要发现
分析步骤
- 查找强相关性的特征:
正相关:相关系数大于0,表示随着特征值的增加,员工离职的概率增加。
负相关:相关系数小于0,表示随着特征值的增加,员工离职的概率减少。 - 关注相关系数的绝对值较大的特征:
这些特征对于预测员工是否可能离职可能更有信息量。
主要发现
- 负相关性较强的因素
- TotalWorkingYears (-0.201310): 表明员工的总工作年限越长,离职可能性越低。这可能反映了更多经验和职业稳定性的影响。
- YearsAtCompany (-0.177498): 在公司工作的年数越多,员工离职的几率越小,这可能与对公司的忠诚度和在公司内的成长有关。
- Age (-0.175393): 较年长的员工离职率较低,这可能与工作稳定性和生活阶段的需求有关。
- YearsInCurrentRole (-0.173931): 在当前角色中工作年数越长,离职概率越低,表明角色满意度和职业成长对留住员工很重要。
- JobLevel (-0.168775): 较高的职位级别与较低的离职率相关,这可能是由于高级职位的员工享受更多的职业满足感和更好的薪酬福利。
- JobSatisfaction (-0.125568): 工作满意度较低的员工更倾向于离职,说明提高员工满意度是降低离职率的关键。
- JobInvolvement (-0.122722): 较低的工作参与度与较高的离职率相关,表明员工在日常工作中的积极参与对于留住员工至关重要。
- EnvironmentSatisfaction (-0.097003): 工作环境的满意度较低可能会增加员工的离职意愿,强调了优化工作环境对于提高员工留存率的重要性。
- 正相关性较强的因素
- DistanceFromHome (0.088563): 距离家较远的员工离职可能性较高,这可能是由于通勤压力和对家庭生活的影响。
从上面的分析可以看出,确实从这个模型的应用中找到了离职的关键影响因素
应用与测试集
预测测试集上的员工离职概率:
# 拟合模型
model.fit(X_transformed, y) # 前面只是训练的模型但是还没有拟合,不拟合会报错NotFittedError
# 加载测试数据集
test_data = pd.read_csv('D:\\学习资料\\机器学习\\pfm_test.csv')
X_test_transformed = preprocessor.transform(test_data)
predicted_probabilities = model.predict_proba(X_test_transformed)[:, 1] # 离职概率
test_data['Predicted Attrition Probability'] = predicted_probabilities # 添加一个预测列里面存其离职概率
test_data.to_csv('D:\\学习资料\\机器学习\\predicted_probabilities.csv', index=False) # 参数index=False的作用是在保存时不包括行索引,因此生成的文件只包含数据和列名,这使得文件更整洁
注意:一定要拟合模型前面只是训练的模型但是还没有拟合,不拟合会报错NotFittedError。

这个最后生成的predicted_probabilities.csv,从中可以看到,确实能够预测出离职概率,并存在predicted_probabilities这一列中。
总结
在这个实战中,我们探索了如何使用机器学习技术来预测员工的离职概率。通过此实验,我们了解了数据预处理、模型建立、评估和预测的整个流程,特别是在处理实际人力资源数据时的应用。总结一下这个的主要步骤:
- 数据预处理:
对数据集进行了细致的清洗,处理了缺失值和异常值,确保数据的质量。
应用了不同的转换策略,包括中位数填充、最频繁值填充、标准化和独热编码,使数据适合机器学习模型的需求。 - 模型训练与评估:
使用逻辑回归模型进行训练,这是一种常用的分类方法,适用于二分类问题,如预测员工是否离职。
通过交叉验证方法评估了模型的准确性,确保了模型的泛化能力和可靠性。 - 结果解读和应用:
我们计算了特征与目标变量之间的相关性,识别出对员工离职有显著影响的因素。
在测试集上应用训练好的模型,成功预测了员工的离职概率,并将结果输出到 CSV 文件,方便进行进一步分析。
希望这篇文章能对同样在学习机器学习的读者提供帮助和启发!希望您能给我点个免费的赞,谢谢!

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









