







视频教程:
从0开始科普人工智能、神经网络、AI生成、ChatGPT一口气理解AI的来龙去脉和底层原理
1 前言
达特茅斯会议:(祖师爷)
达特茅斯会议(Dartmouth Conference)是人工智能领域的奠基性会议,通常被视为人工智能学科的“诞生”时刻。该会议于1956年在美国新罕布什尔州达特茅斯学院(Dartmouth College)举行,是由约翰·麦卡锡(John McCarthy)、马文·闵斯基(Marvin Minsky)、奈瑟姆·卡普尔(Nathaniel Rochester)和克劳德·香农(Claude Shannon)等科学家发起的。

达特茅斯会议的召开旨在探讨 “如何制造出一种不断学习并模拟人类智能的机器?”
达特茅斯会议正式标志着人工智能这一学科的诞生。会议上,科学家们提出了多种方法论和框架,讨论了如何实现人工智能, 达特茅斯会议不仅是人工智能学科的起点,还成为了象征人工智能持续探索和发展的重要标志。
1.1 什么是智能?
智能本质上就是针对不同情境给出针对性的输出反应, 换句话说,智能就是找到情景信息的输入和我们想要的聪明行为的输出之间的函数对应关系。人工智能的目标是建立一个系统,这个系统能根据不同的环境信息提供合适的输出和回应。
“世界万物都被函数所描绘”
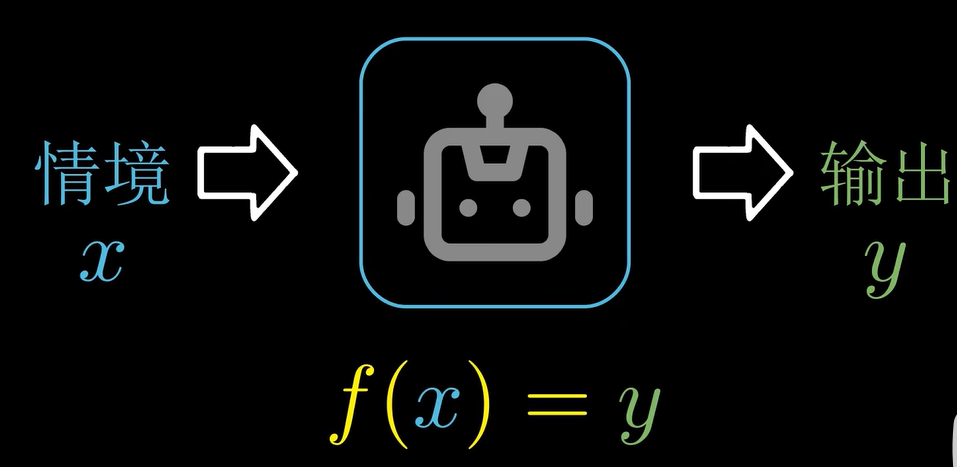
人工智能=人工搭建的智能
人工智能的目标就是,搭建一个根据不同的环境信息给出针对性的输出和回应的系统
(动作语言或判断预测)
1.2 图灵测试
图灵测试是衡量AI是否具备智能的标准。如果一个人无法确定自己在与人类还是AI进行对话,那么这个AI就可以被认为具备了人工智能。
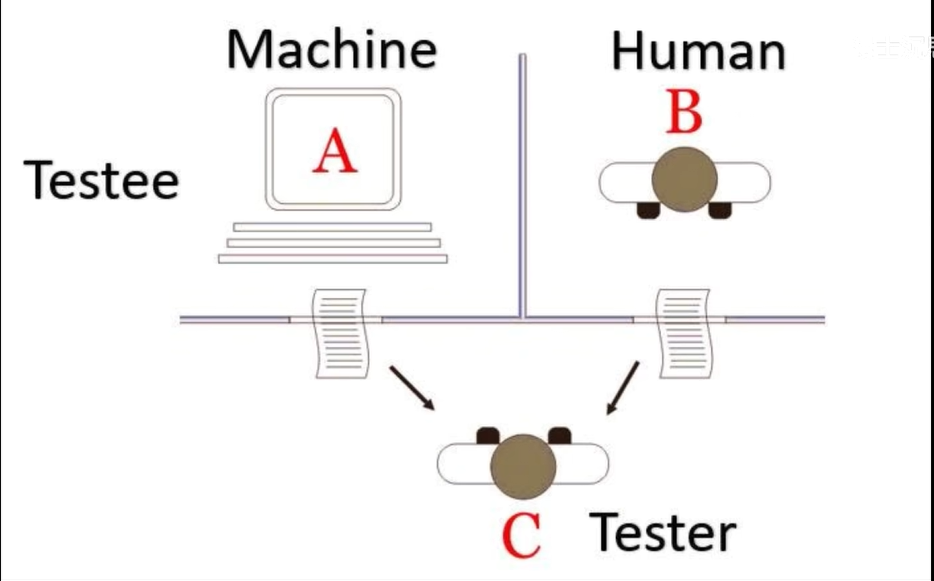
如果人无法确实是跟人还是AI聊天,那么这个AI就实现了人工智能【AI在黑盒中定义的函数关系给出的输出结果和人没有任何区别】
2 怎么做出这个聪明的黑箱?
2.1 思路一:符号主义[流派一]
符号主义主张使用符号推理模拟人类的智能,知识通过“如果A,那么B”的规则进行存储和推理。 不断通过逻辑推演,就可以实现接近人类的智能。
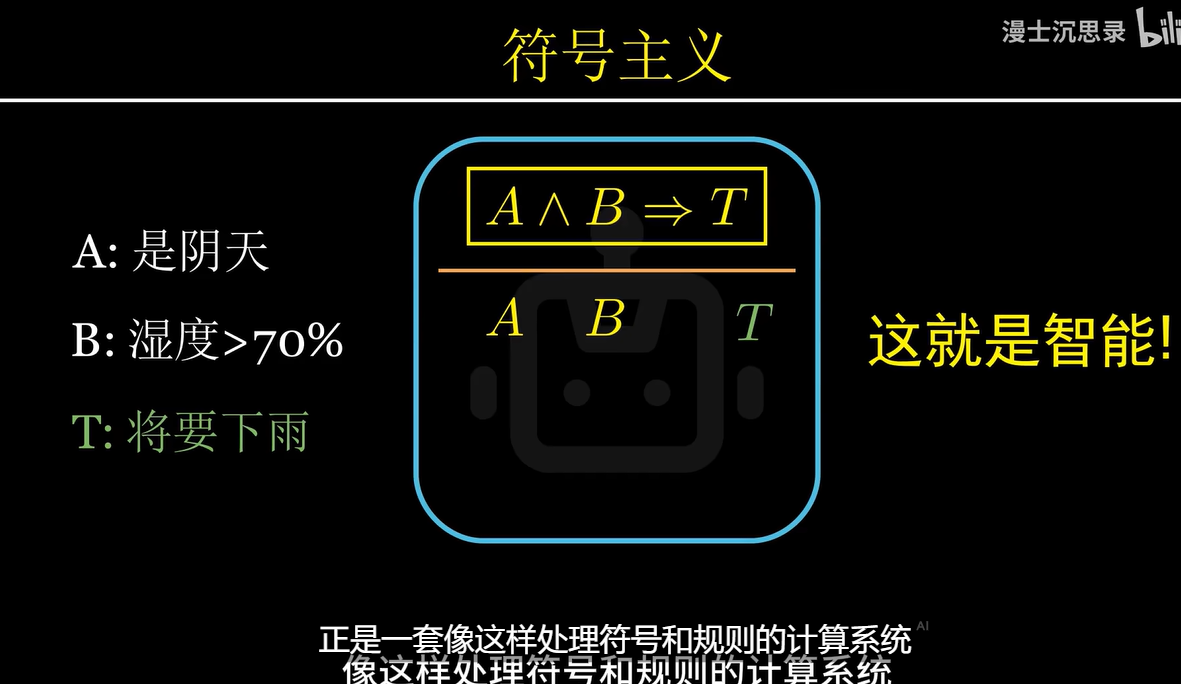
成功系统代表:专家系统

这种方法的局限性在于人类世界并非所有情况都有清晰的规则,而且它只能模仿专家的知识和经验。
2.2 思路二:机器学习
与符号主义不同,机器学习允许通过调整黑箱模型的参数来学习,模型不必预设任何规则,而是通过数据和奖励机制来自我调整。
机器学习的核心问题在于如何设计强大的模型(例如神经网络),如何通过损失函数进行优化,以及如何训练机器形成适应性反应(例如条件反射)。
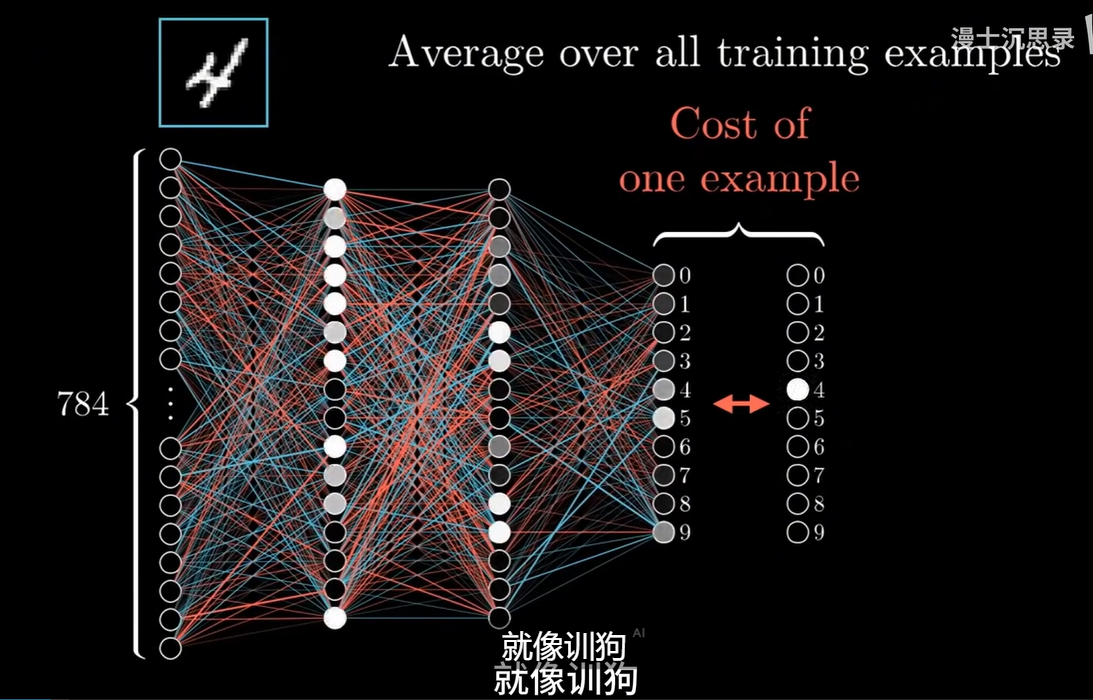
机器学习只需要两种要素:1.一个强大且有学习能力的黑箱 2.足够多的数据
引发三个方向的问题:
一个强大且有学习能力的黑箱怎么来?——模型结构
怎么奖惩一个机器?——损失函数
机器如何建立条件反射?——训练过程

2.3.1 问题一:搭建黑箱
联结主义[流派二][神经网络的提出流派、也就是深度学习](Connectionism): 核心思想是通过模拟神经元之间的连接方式来实现智能。人类大脑是通过神经元之间的复杂连接和相互作用产生意识、思维和行为的。联结主义试图通过数学模型和算法来模仿这些连接,从而让计算机也能“思考”并作出智能决策。
深度学习的课题的课题就是如何设计强大的神经元网络模型,任何一种网络模型都是由某种网络的基础框架结构,有大量的参数需要去决定
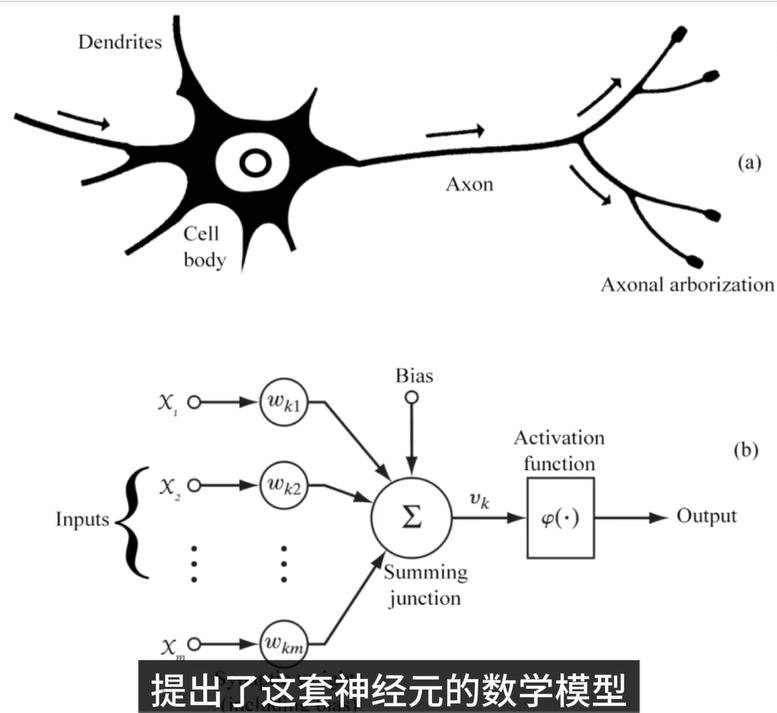
2.3.1.1 感知机搭建——模式识别(最简单方式)
感知机是一个最基础的神经网络模型,相当于一个神经元,它通过给输入特征赋予权值来进行预测。在这个过程中:
- 正向特征加:如果特征对分类有正面影响,那么它的权值增加;
- 负向特征减:如果特征对分类有负面影响,权值减少。
- 通过计算所有特征的加权和,并与一个阈值进行对比,最终决定该输入属于哪个类别。
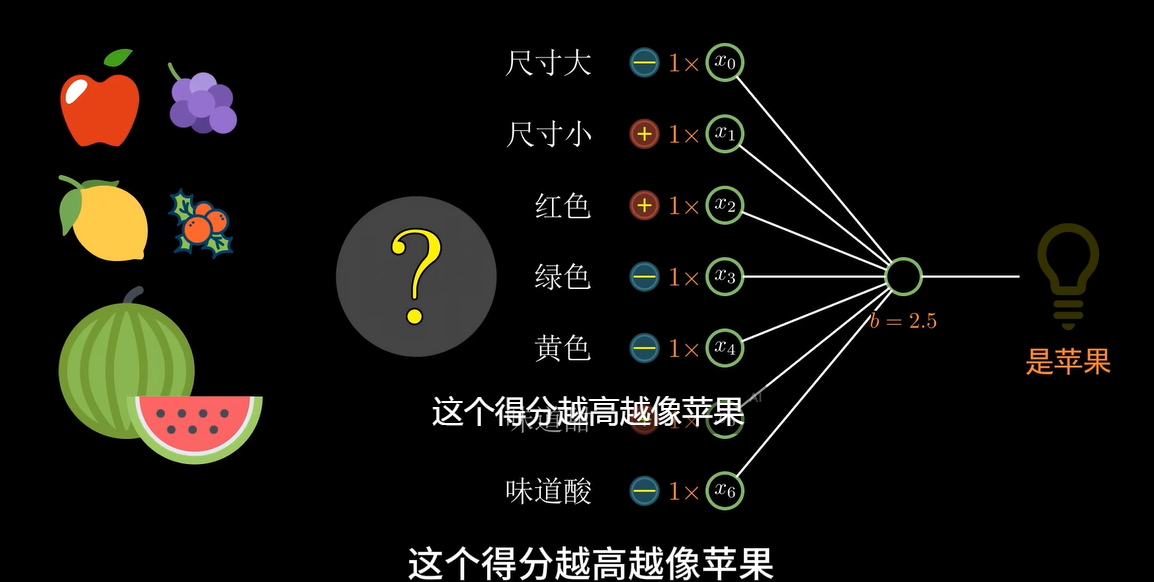
这个过程类似于一个决策函数,判断一个水果是苹果还是橙子。只要调整连接的系数(权重),就能让感知机在不同水果的分类任务中做出正确的判断。
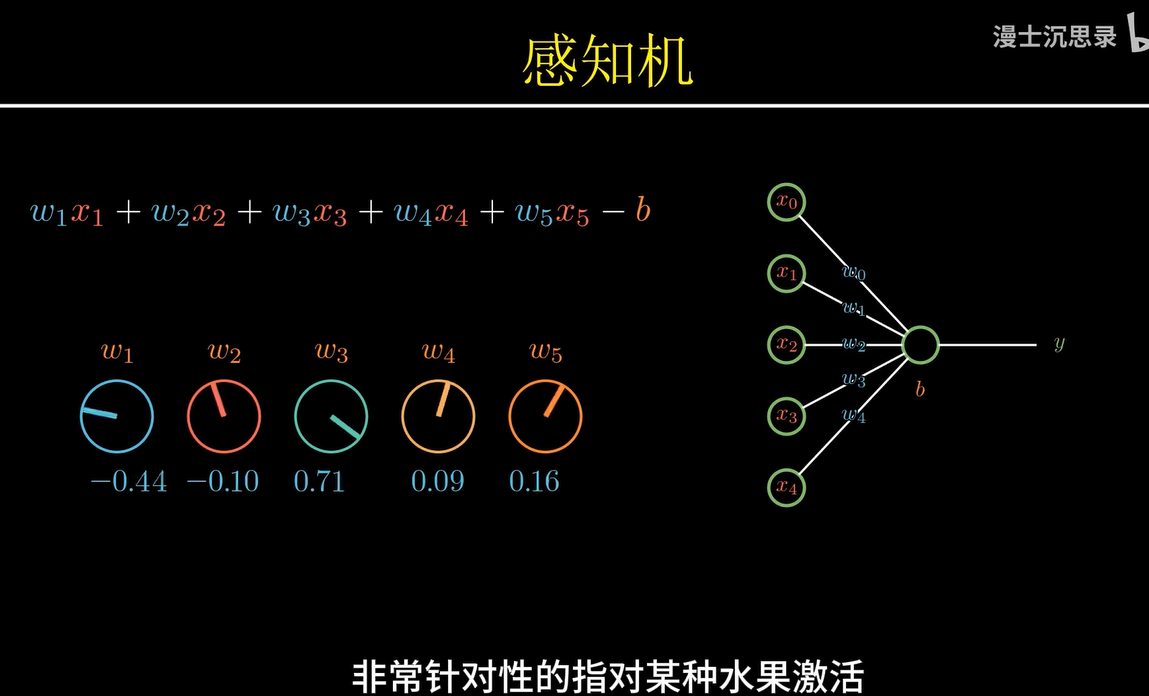
随着感知机模型的扩展,我们可以组合不同的特征条件来进行推理。对于图像识别任务,计算机通过将不同特征(如颜色、形状、大小等)转化为数字形式,通过数值计算来做出最终的判断。
下图是最初神经网络提出的模型:
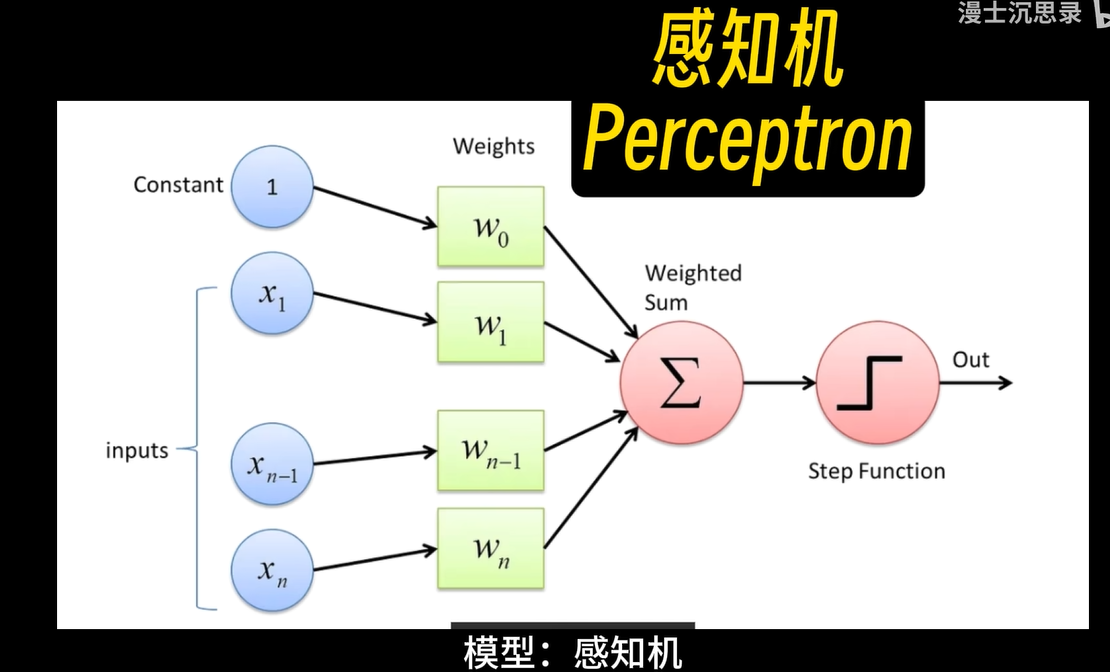
例如,在图像识别中,计算机通过“狗”这一概念将图片转化为数字信号,然后使用这些数字信号通过神经网络来判断图像中是否为狗。
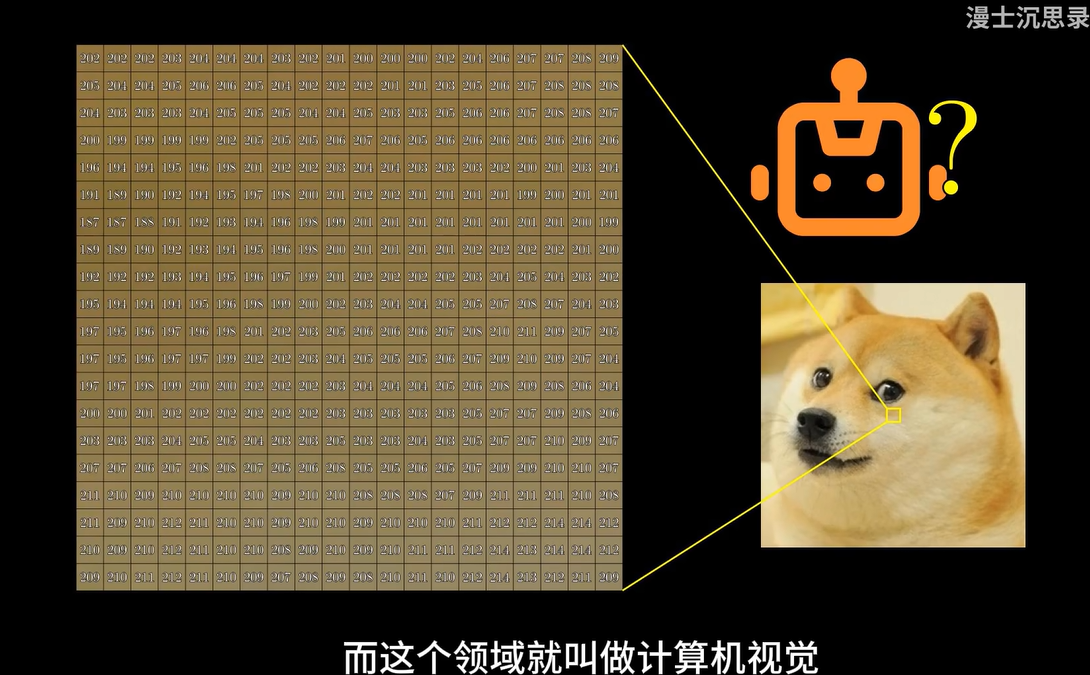
在计算机视觉中,计算机通过将图像数据转化为数字信息来分析图像。对于计算机来说,每一张图片就是由大量的像素和颜色值组成的数字网格,通过分析这些数字,它可以识别图像中的物体。这个过程就是通过感知机等神经网络来进行特征识别,最终做出是否“狗”的判断。
“人对自己不了解的东西就很容易浪漫,也很容易对未来过分乐观”在二战的时候就提出了下面图片里的设想,我们直到最近几年才真正实现。

联结主义的信念:模型本身确定了函数输出形式,但未确定整个函数,有一系列需要调节和设定的数值(参数),所以让这个模型不断调整自己的参数,面向函数输出形式变换,就可以让他最终实现强大的智能。
联结主义通过模拟神经元的连接和信息传递机制,构建了神经网络模型,但它也有局限性。尤其是早期的感知机模型在处理一些复杂问题(比如“异或”问题)时无能为力。这导致神经网络一度被称为“垃圾”,并且经历了所谓的“寒冬”。
异或问题指的是两个输入的真值组合,它无法通过简单的感知机(单层网络)来解决,因为感知机无法处理非线性问题。这促使了神经网络的进一步发展。
2.3.1.2 多层神经元嵌套——多层感知机MLP
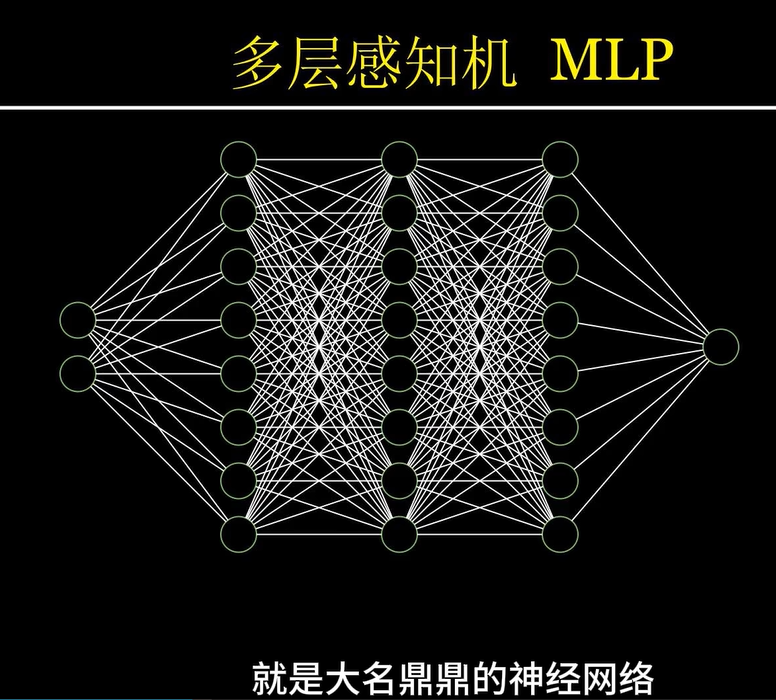
多层感知机(MLP)是最基本的深度神经网络架构,包含多个层次(输入层、隐藏层和输出层)。每一层中的神经元与上一层中的神经元相连,每个连接都有一个权重值(连接系数),这些权重在训练过程中被不断调整。通过这种方式,神经网络可以学习输入数据与目标输出之间的复杂关系。
MLP的核心思想是通过“层次化”的结构进行特征的逐层提取,每个神经元根据上一层的输出和它的连接权重来计算自己的输出。
2.3.1.3 卷积神经网络(CNN)
在深度学习中,卷积神经网络(CNN)特别适合处理图像数据,它的设计灵感来自于生物神经网络。CNN的特点在于:
- 局部连接:每个神经元只与上一层中局部区域的神经元连接,而不是与所有神经元连接。这样大大减少了模型的参数量,并且有助于捕捉局部特征,如图像中的边缘、纹理等。
- 共享权重:卷积核(filter)会在不同位置共享相同的权重,使得网络能够在不同位置提取相同的特征。共享权重减少了参数量,提高了计算效率。

CNN的这种设计使得它在图像识别、物体检测等任务中表现得尤为强大,能够高效地处理图像中的局部特征。
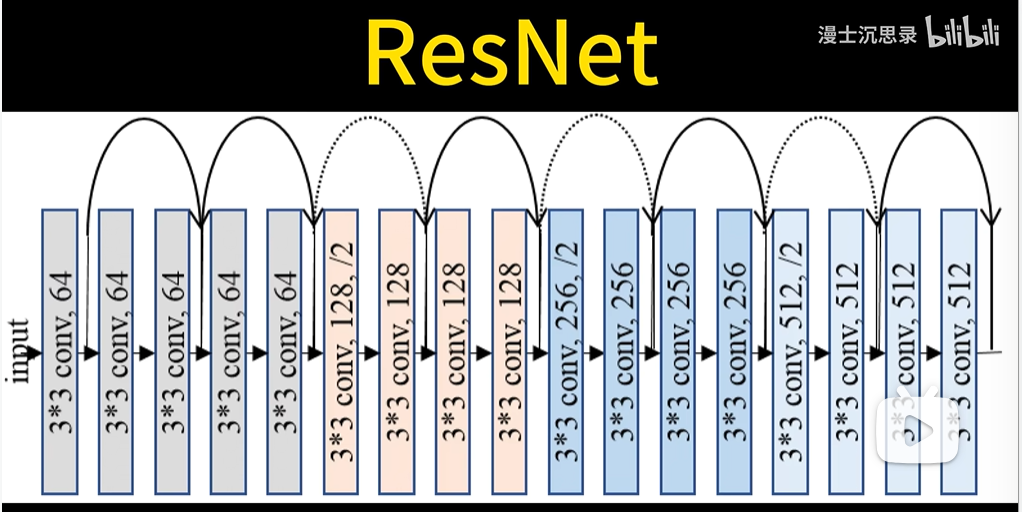
2.3.1.4 ResNet【跳跃连接】
卷随着网络层数的增加,深度神经网络在训练过程中可能面临梯度消失或梯度爆炸的问题,这会导致模型训练困难。为了克服这个问题,ResNet(残差网络)引入了跳跃连接(skip connection)。
- 跳跃连接:允许数据或梯度绕过某些层直接跳到下一层,这样即使网络很深,信息也能够顺利传播。
- 残差块:每个跳跃连接会把输入与输出的“残差”相加。这意味着网络不再学习直接映射,而是学习输入和输出之间的差异。残差块有效地缓解了深层网络中的梯度问题,使得训练更加稳定。
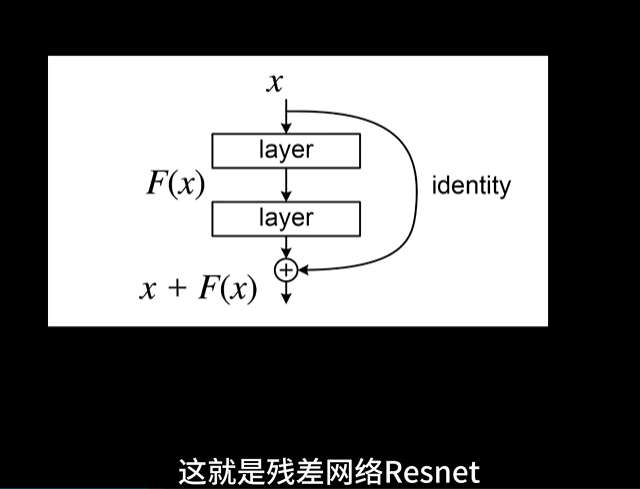
这种结构使得网络在更深的层次上也能保持较好的训练效果,极大提高了网络的性能。
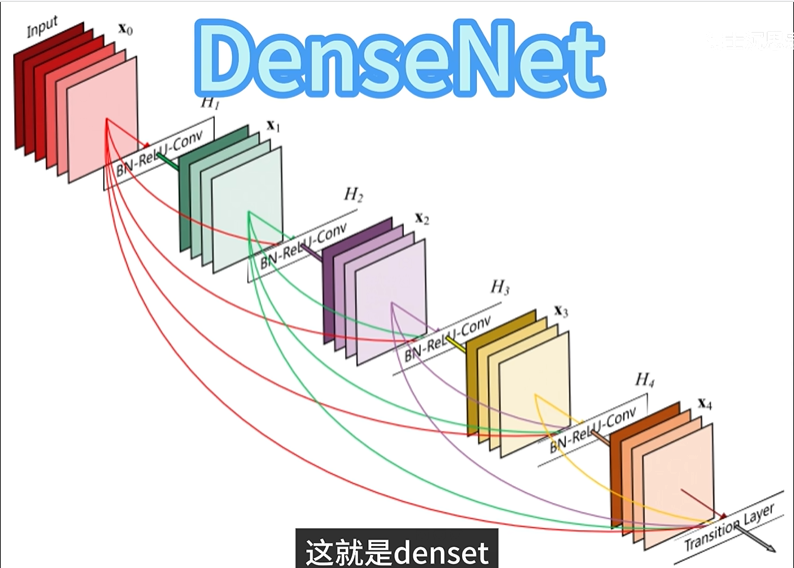
2.3.1.5 DenseNet 【任意两层都连接跳跃起来】
DenseNet(密集连接网络)是一种深度神经网络架构,它通过将每一层的输出与所有前面层的输出连接起来,来加强特征的传递和共享。与传统的卷积神经网络(CNN)不同,DenseNet通过密集的层连接方式来优化信息流动,避免了信息在网络中传递时可能出现的梯度消失和特征丢失问题。
2.3.1.6 Transformer:GPT的基础框架
Transformer架构是近年来深度学习领域的革命性进展,它特别适用于自然语言处理(NLP)任务。Transformer的核心特点是:
- 自注意力机制:Transformer通过自注意力机制(self-attention)来捕捉序列中不同位置之间的关系,而不像传统的循环神经网络(RNN)那样按顺序逐步处理。这使得Transformer能够并行处理数据,大大提高了计算效率。
- 编码器-解码器结构:Transformer采用了编码器-解码器结构,编码器负责将输入序列转化为固定大小的表示,解码器则根据这个表示生成输出序列。
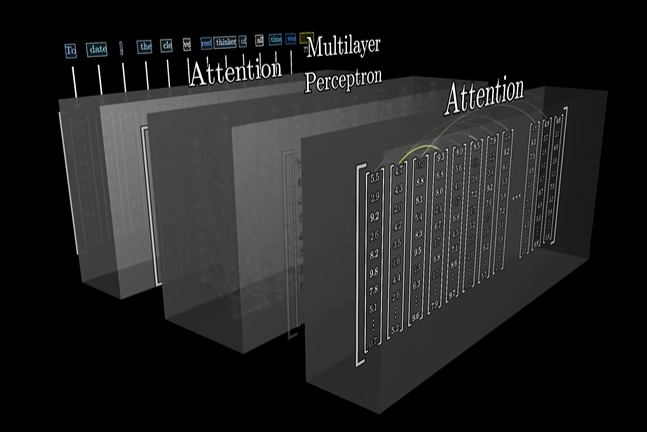
GPT(生成预训练转换器)是基于Transformer架构的预训练模型,专门用于生成自然语言文本。GPT通过自回归的方式(即根据之前的输出生成新的内容)进行文本生成,并且通过大规模预训练和微调来提升在特定任务上的性能。
2.3.1.5 神经网络结构设计的重要性
一个好的神经网络结构能够使得“黑盒”学习更加高效,从而减少所需的数据量。这涉及到两个重要的方面:
- 模型结构设计:设计合适的网络结构可以让模型更快地学习到有效的特征。比如,选择深度学习框架时,是否使用卷积层、跳跃连接、Transformer等结构都可能影响模型的表现。
- 参数优化:在深度学习中,神经网络包含大量的参数(如权重和偏置),通过优化这些参数,网络才能更好地拟合数据。梯度下降、反向传播等优化算法是训练过程中的核心部分。
通过良好的神经网络结构设计,可以提高训练效率,减少对数据的依赖,使得神经网络能够更加高效地学习复杂任务。
2.3.2 问题二:奖励惩罚一个神经网络——梯度下降算法
神经网络的目标是通过输入数据(x)来预测输出结果(y)。为了实现这个目标,我们需要调整神经网络中的参数(如权重和偏置),使得神经网络的输出尽量接近实际的目标值。这一过程的本质就是一个优化问题,通过不断调整网络的参数来最小化误差或损失函数。
简单方法:
2.3.2.1 损失函数
对于一个任意一条曲线,我们可以用五次多项式来表示它
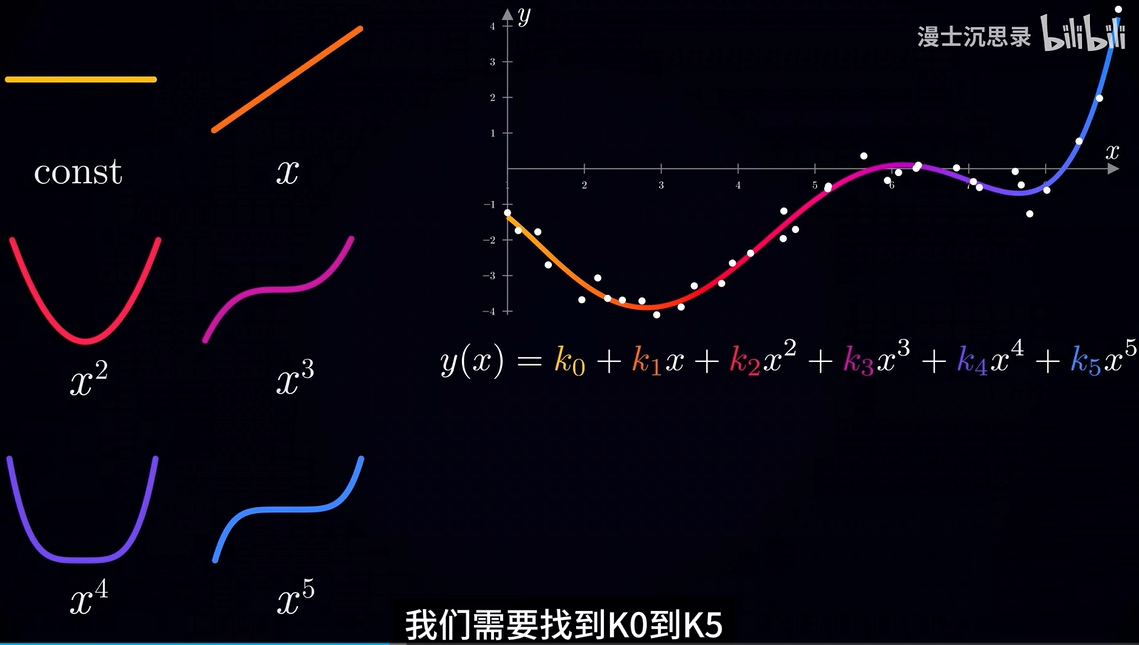
此时,我们的目标是找到K0到K5最好的参数组合,即为该曲线的函数表示
现在我们简化为先找一个未知系数:
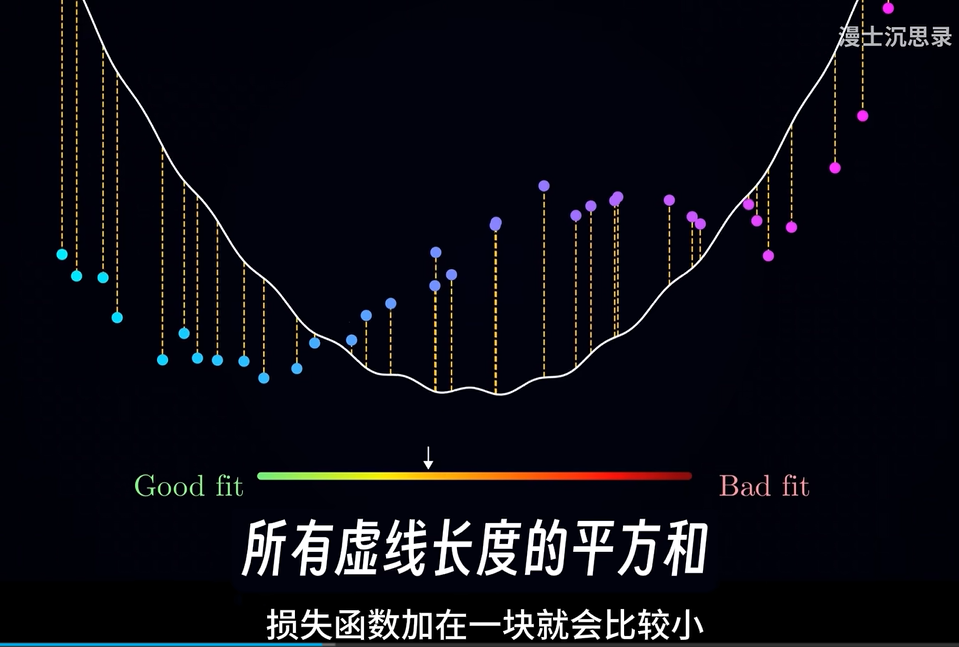
我们现在需要用一种定量方式(损失函数)定量度量这组系数拟合的好不好,才能成功表示这条曲线,所有我们关键在于计算出损失函数。
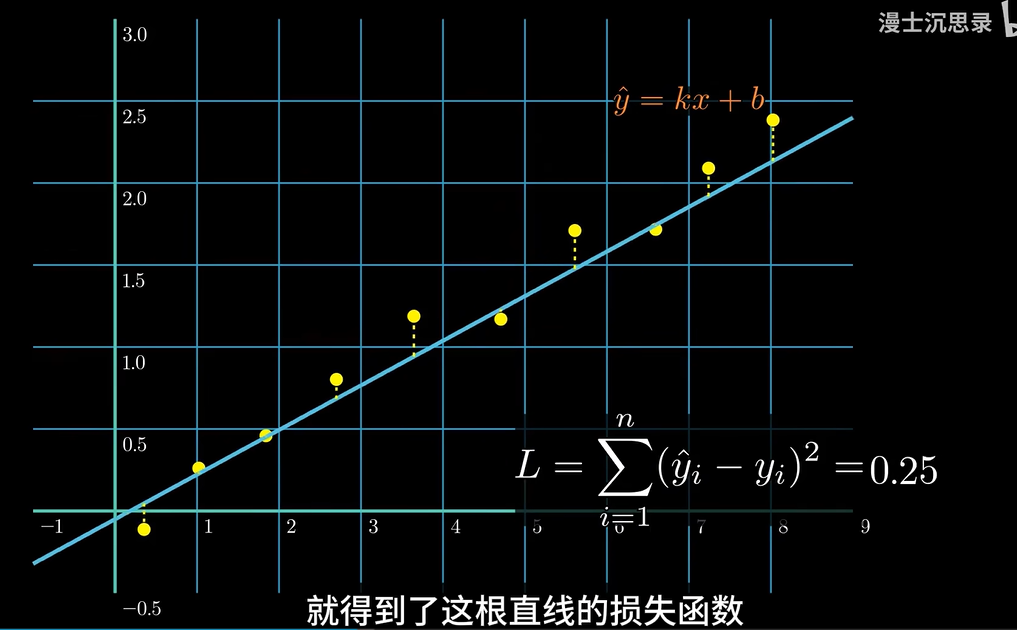
如果是线性函数: 损失函数是均方误差(MSE),它衡量的是预测值和真实值之间的平方差。
非线性同理
注意区分
损失函数是衡量预测的和真实的结果之间的偏差程度
拟合函数:拟合数据点的曲线(五次多项式)
损失函数:衡量一个拟合函数好不好,输入是多项式的6个系数,找到对应的最小偏差

2.3.2.2 梯度下降算法+反向传播算法
实际过程中,我们需要调节参数(K0-K5)使得曲线贴合,更复杂的模型需要有更多的参数
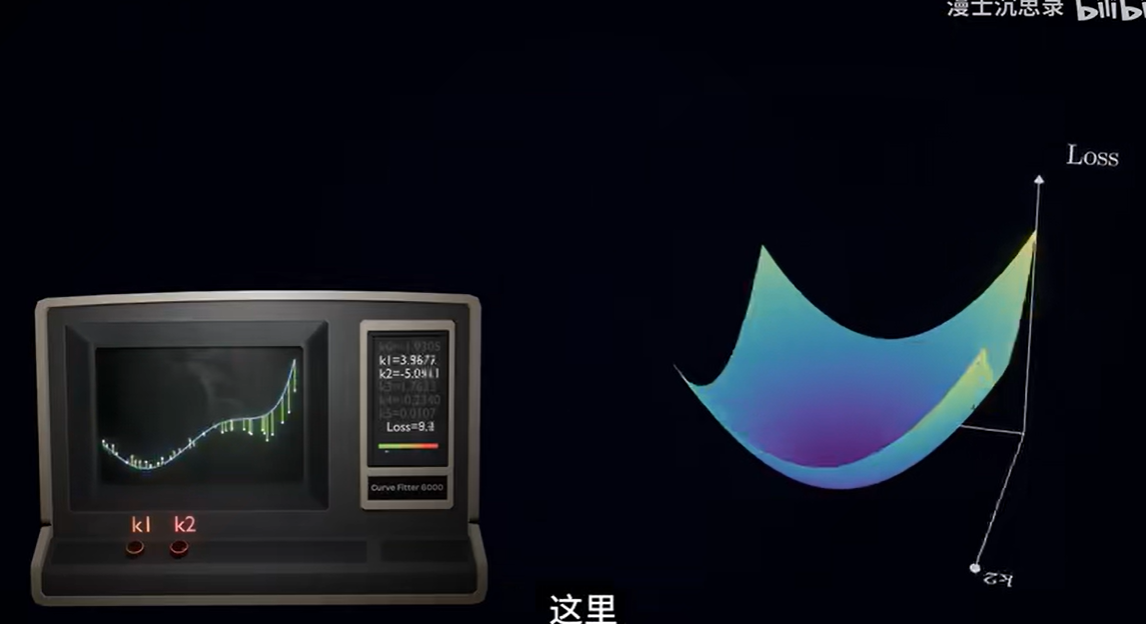
训练神经网络的过程就是通过调节参数旋钮降低损失函数的过程
gpt模型中,我们需要调节一千多亿的旋钮并使得旋钮组合起来有好的性能

求解这个问题在数学上是利用非凸优化求解,但求解难度大

我们提出了更巧妙的算法:梯度下降+反向传播算法
梯度下降:每次减小一点点看导数确定走的方向,直到走到导数不在变的位置,这个位置就是损失函数的最小值
一个旋钮可以通过上面这种方式调好
两个旋钮:也就是两个参数,在数学上是损失曲面(二元函数),我们利用偏导数来求解
求解过程:固定K2只变化k1,固定K1只变化k2,就可以找到两个面,两个面相交得到的曲线,再求这个曲线的导数,将这两个导数拼到一起就得到了梯度
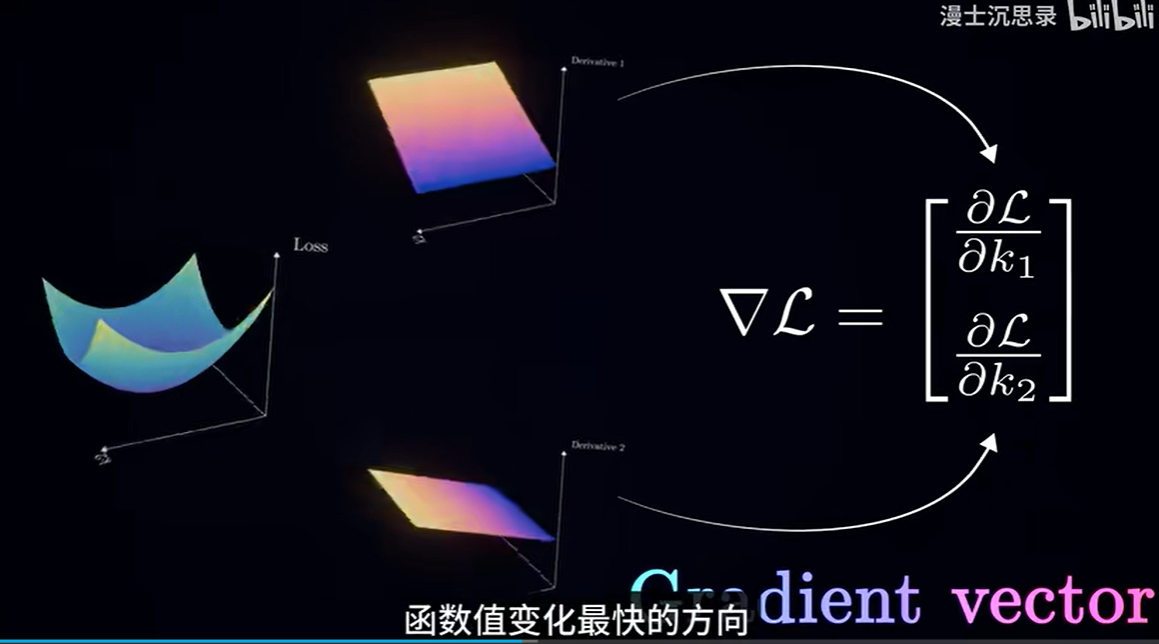
这个梯度就是二维版本的求导

然后根据上面的方式(每次减小一点点看导数确定走的方向,直到走到导数不在变的位置,这个位置就是损失函数的最小值) 得到最小的损失函数,这个就是梯度算法。
应用到6个旋钮就是6维的梯度,这样让每个旋钮都向着对应方向不断迭代得到损失函数

对一个层层堆叠的复杂神经网络,如何计算出梯度?——答案是“反向传播”算法
反向传播算法思想:利用链式法则逐层传播误差,计算每个参数的梯度,从而高效优化神经网络。
- 误差计算:通过前向传播计算损失函数。
- 梯度传播:利用链式法则计算梯度,从输出层逐层反传。
- 参数更新:使用梯度下降等优化算法更新权重和偏置。
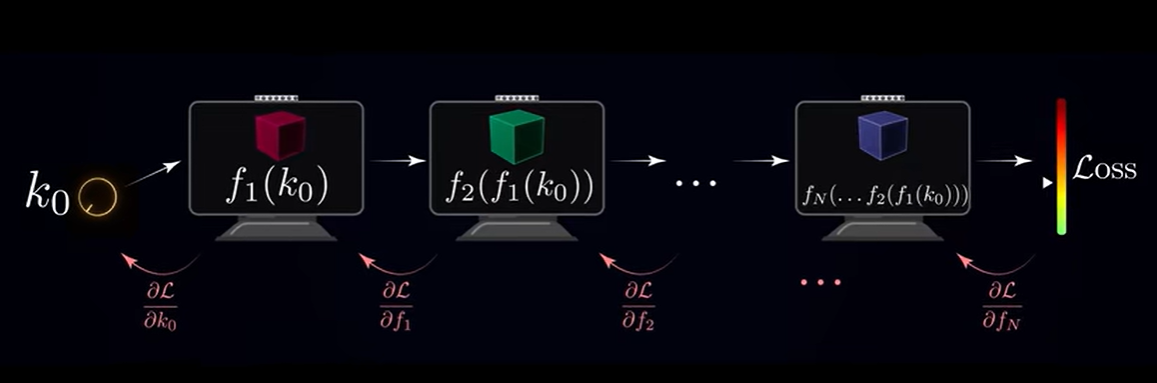
找到几亿个旋钮参数最好的设置方法就是:用反向传播算法计算出每个参数的导数,接着用梯度下降法,每次让这些参数变化一点点,不断向着更好的参数演化和移动,最后整个神经网络就会掌握变化规律,学习底层函数,获得我们想要的智能。
2.3.3 问题三:黑箱机器如何举一反三【判断机器学习是否成立的标准是泛化】
泛化:由具体的、个别的扩大为一般的,本身的含义是从有限的经验中总结出普遍性的规律,并将其应用到新的情况中。
在机器学习中,泛化指的是模型从训练数据学习到的规律能否正确适用于新数据。如果模型泛化能力强,它就能有效预测未见过的数据,而不仅仅是在训练集上表现良好。
不同情境里有一种感觉和规律,这种感觉和规律难以用简单清晰的数学来计算和描述
深度学习可以领会到这种感觉,因为深度学习的特征学习过程类似于人类大脑从感知到理解的层层抽象, 学习到模式中的隐含关系, 并推广到未见过的数据。
泛化能力的关键:
- 训练集与测试集:训练集是用来训练模型的,而测试集是用来验证模型是否能适应新的、未见过的数据。理想情况下,训练集和测试集的分布应该是相似的。
- 过拟合与欠拟合:
-
- 过拟合:当模型在训练集上表现得非常好,但在测试集上表现较差时,说明模型过拟合了训练数据,即它学习了训练集中的噪音和细节,而没有掌握普遍的规律。
- 欠拟合:当模型在训练集和测试集上都表现较差时,说明模型的学习能力不足,无法捕捉到数据中的重要规律。
一个理想的机器学习模型应具有较强的泛化能力,即它能够从训练集中的有限经验中总结出能够适用于新数据的普遍性规律。
2.3.4 深度学习的缺陷
- 泛化能力的挑战:尽管深度学习能够从大量数据中学习到丰富的特征,但它仍然面临着泛化能力的问题。深度神经网络尤其容易过拟合,当数据集较小或噪音较大时,模型可能会“记住”训练数据中的噪音和不相关的细节,而失去对数据普遍性规律的理解。
- 对数据依赖性强:深度学习的成功依赖于大量的标注数据。在缺乏足够数据的情况下,模型的泛化能力会大打折扣。训练集中的每一条数据都可能影响最终的模型表现,因此如何设计有效的数据集并进行数据增强是深度学习面临的一大挑战。
- 模型透明性差(黑箱问题):深度神经网络作为一种复杂的“黑箱”模型,很难解释每一层的输出是如何影响最终决策的。虽然深度学习在许多任务上取得了突破,但由于缺乏可解释性,当模型做出错误预测时,调试和理解原因变得非常困难。

机器学习无法把握这些微妙的差别,模型会把数据集里的共同出现当成必然练习。
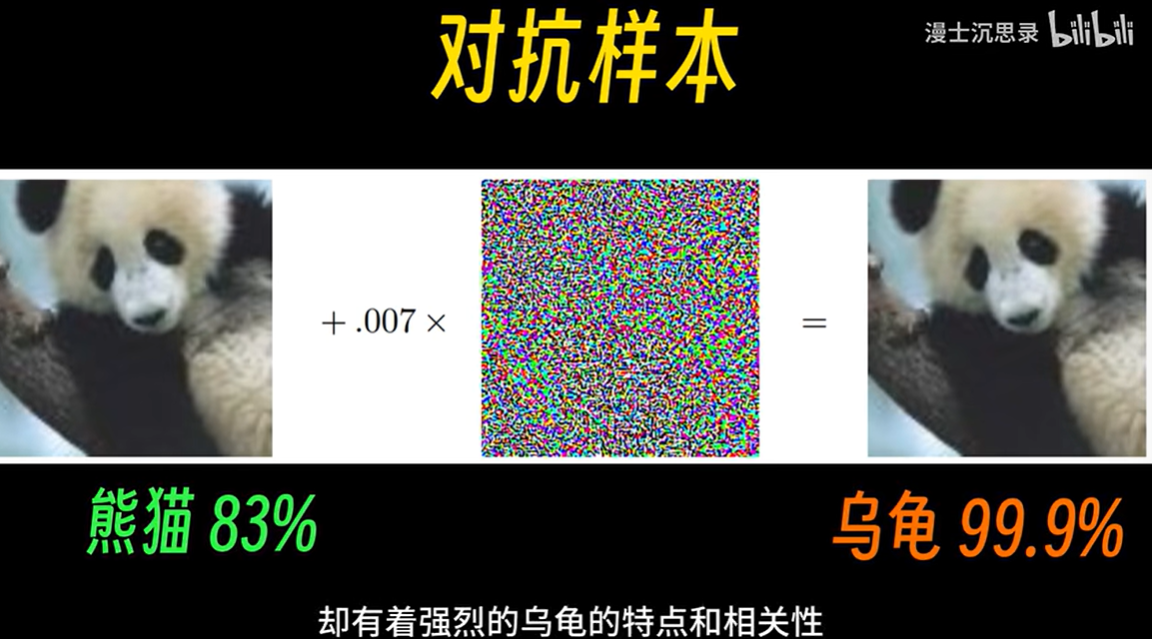
对抗样本(Adversarial Examples)是指经过故意设计和修改的输入数据,使得机器学习模型,尤其是深度学习模型,在处理这些输入时做出错误的预测或判断。对抗样本通常是在原始样本上添加了微小的扰动,这些扰动对于人类来说几乎不可察觉,但足以导致深度学习模型产生错误的输出。
3 ChatGpt语言大模型底层原理
3.1 大模型是如何实现对话的?
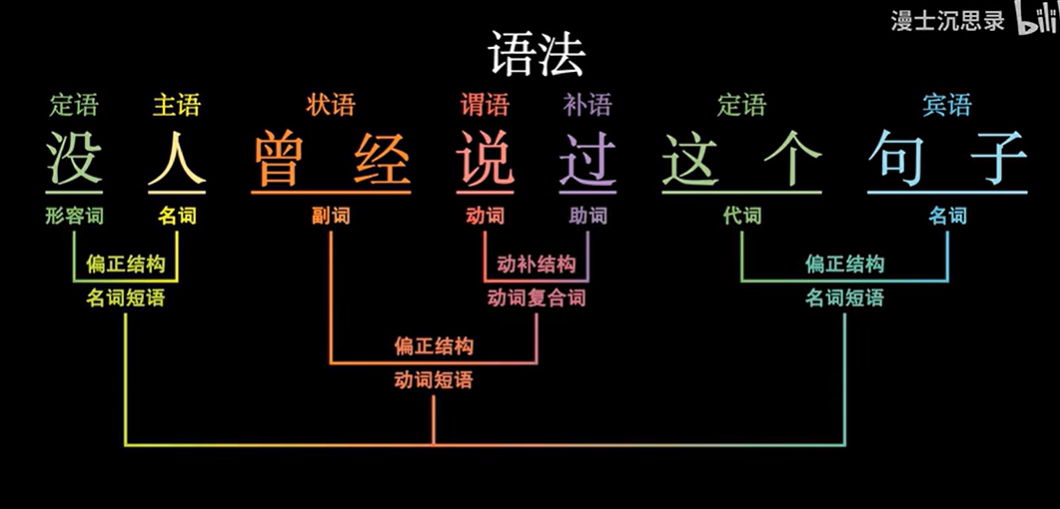
3.1.1 利用语法原理【失败】
人为语言是根据语法,有一个大概的组织结构,说出这句话
语言模型的核心目标就是理解语言规律,准确预测语句中的下一部分。这些规律不仅仅是语法结构,更多的是语义和上下文的关系。通过学习一个语言的符号(token)序列及其背后的意义传递,语言模型可以生成符合实际意义的句子或预测下一个可能出现的词。
大模型说话原理就是接话尾,每次根据之前说过的话,推测后面要说的话。

语言规律本质在于如何传递信息和意义
语言的符号成为语素(token),语言的信息蕴含在token的序列当中
语言的规律本质在于理解每个token在现实世界对应的含义以及它们以什么样的内在规律出现,出现后整体传递了怎样的意思
计算语言学:计算出一个句子后面应该接一个怎样的词,也就是理解语言规律

语法无法来描述语言的本质,所有我们放弃了通过语法来让大模型造句。
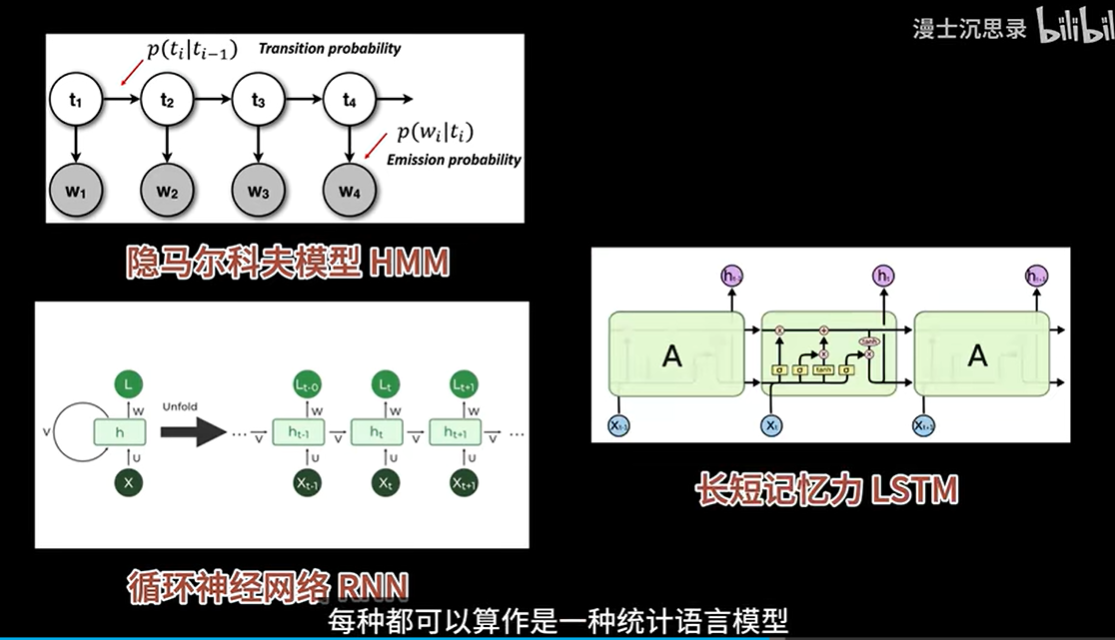
3.1.2 统计语言模型
最简单的语言模型:输入法的联想
每次只看最前面相邻的词或者字,接上一个最常见的紧跟着的搭配
这种模型通常只依赖于前面几个单词来预测下一个单词(比如N-gram模型)。尽管这种方法在短文本或某些特定场景中有用,但它的能力非常有限,因为它无法捕捉到长距离的依赖关系。
基于某一个长度的上文使用统计的方法的模式就是另一条建模道路,统计语言模型
统计语言模型通过分析大量文本的词频和共现频率,来预测给定上下文条件下下一个最可能的词。虽然这种方法相对简单,但其不足之处在于,它不能处理更长的上下文关系,也无法理解复杂的语义结构。
3.1.3 初次之外还有其他算法
3.2 GPT
训练过程就对应GPT里的P,G是模型是生成语言的任务,T是预测后面那个词是啥的模型(Transformer)

大模型是用之前所有输出的内容进行预测下一个语素,类比完形填空,这其实很难,需要理解词语含义,语法结构,以及对应的实际含义,这就是你每次做不对完形填空的原因
把前面自己输出变成输入条件的方式称为自回归生成。
自回归生成是指每一次生成一个词(token),然后将其加入到已有的上下文中,作为下一次生成的基础。这个过程依赖于模型对语言的理解,包括对词汇的意义、句子的结构和上下文的捕捉。
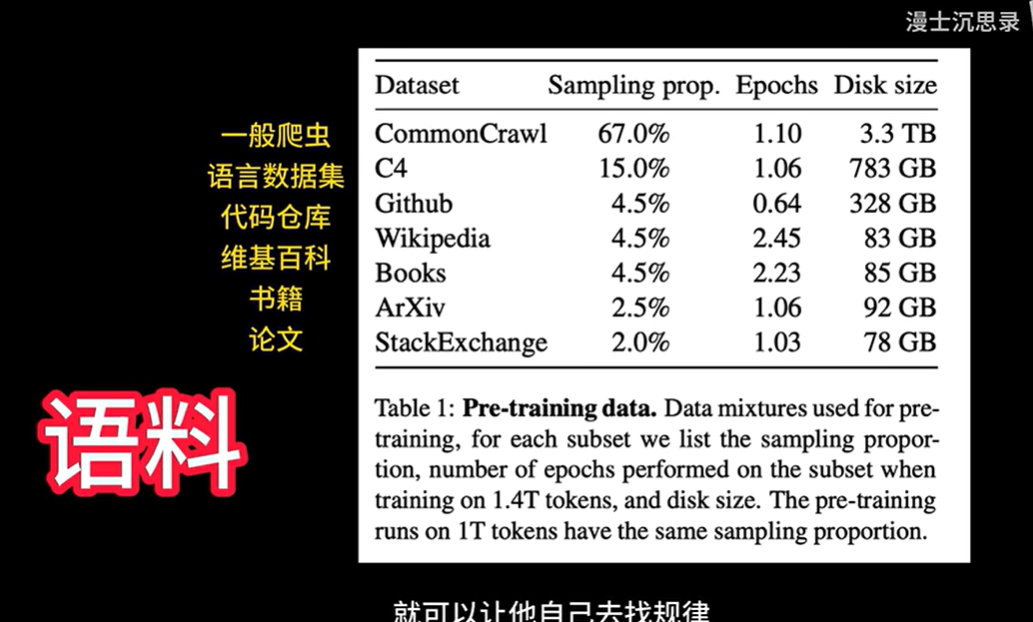
3.3 优化方式
3.3.1 监督训练
监督训练是指通过提供带有标签的训练数据(例如,输入文本和目标输出文本)来训练模型。模型通过最小化损失函数(例如交叉熵损失)来学习预测输入文本对应的输出。在训练过程中,模型根据每个词的预测误差调整参数,逐步优化其能力。
3.3.2 微调(Fine-tuning)
微调是在预训练语言模型的基础上,使用特定领域的数据进行再训练。通过在特定领域的数据上进行微调,模型可以更好地适应特定的语境,提升在某些领域(如医疗、法律等)的表现。
3.3.3 人类反馈强化学习(RLHF)
人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)是一种新兴的优化方式。它通过人类反馈来指导模型的训练过程。具体来说,模型会生成多个可能的输出,然后人类评估这些输出的质量,并给予反馈。通过强化学习的方式,模型根据这些反馈调整生成策略,从而生成更加符合人类需求的文本。
原视频博士后续还分析了SORA扩散模型的原理,感兴趣的同学可以去看看,我用了一个下午的时候看完做了笔记后又重新整理了文案和思路。
这篇文章用于AI入门的一个启蒙学习,由于本学期的专业课是人工智能导论,机器学习[西瓜书],自己的一点微薄的科研经历是深度学习,距离保研没多少时间了,本人现在(3月25日)才开始从0准备,所以后续我们一起来快快速成学习吧!
立一个flag,保证每天两篇关于专业课的博客更新,希望我们努力努力,顺利顺利!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









