







一、DeepLab v1——空洞卷积【扩大感受野+保持空间尺寸】
1.背景:
在 DeepLab v1 提出之前,语义分割的主流方法是 FCN(Fully Convolutional Network),它将分类任务扩展为像素级别的预测。然而,FCN 存在两个主要问题:
- 分辨率降低问题
连续的下采样(池化或 stride 卷积)导致特征图空间分辨率急剧下降,最终分割图非常粗糙。 - 上下文感受野不够
深层特征虽然语义强,但由于下采样和卷积核限制,感受野不足,难以捕捉大范围上下文。
目标:
设计一种方法,在不降低分辨率的情况下增大感受野。
2.创新点
Unet——局部,小目标
deeplab——全局,目标是增大感受野
传统增大感受野的方法有两种:
1.增大卷积核 (如 5×5、7×7)→ 参数增多,每层要加BN(激活函数)计算量变大 (VGG网络出发点:用小卷积完成特征提取的任务)
2.卷积核大小不变,池化后再卷积 (如 max pooling,stride=2)→ 尺寸减小,导致空间信息丢失
于是出现了需求:
有没有一种方法,能够扩大感受野,又不缩小特征图的空间尺寸?
答案就是:空洞卷积(Atrous Convolution / Dilated Convolution)
膨胀卷积:1.增大感受野2.保持原图尺寸大小不变
(1)空洞卷积
- 目的:增大感受野,但不降低特征图空间分辨率。
- 做法:在卷积核元素之间插入“空洞”(即跳过若干像素),引入“扩张率 dilation rate”参数。
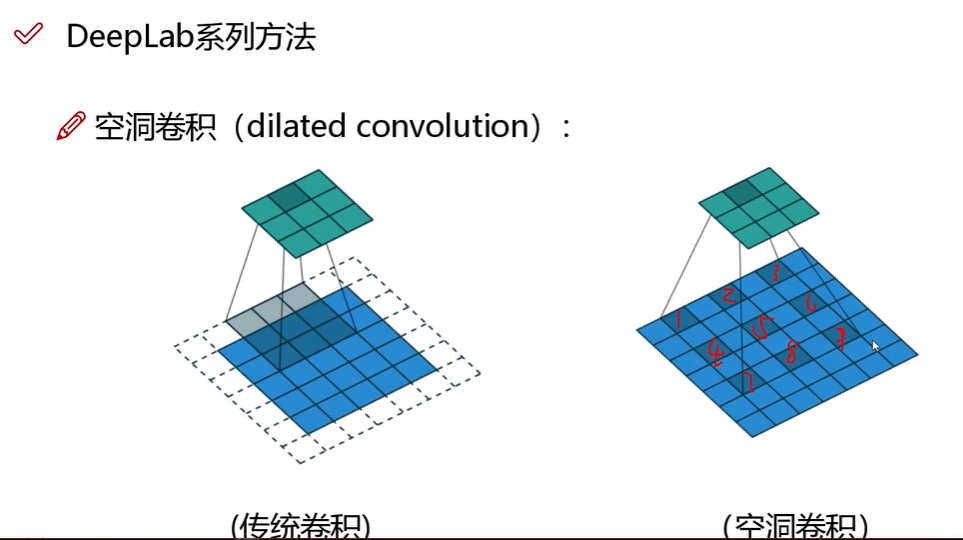
dilated=1,间隔一个格子
dilated=3,间隔三个格子
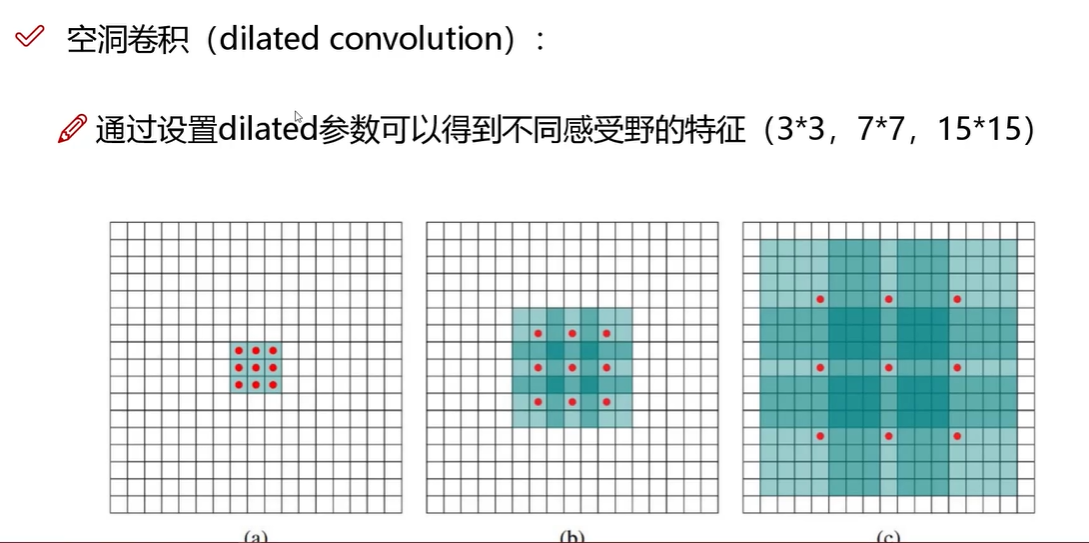
空洞卷积本质:卷积层增加了一个额外参数
| 卷积类型 | 样式 | 感受野 |
| 普通 3×3 | ● ● ● | 3×3 |
| 空洞卷积 r=2 | ● 0 ● 0 ● | 7×7 |
- 优势:
-
- 增大感受野 → 捕捉更大上下文
- 不降采样 → 保留空间细节
- 不引入额外参数
(2)条件随机场(CRF)后处理
CNN 的缺点(语义分割中的问题)
尽管 CNN 很擅长提取语义特征(比如知道某一块是“人”),但它有一个致命弱点:
它不擅长处理细节,比如边缘或小目标。
原因:
- 卷积和池化操作会不断下采样,导致图像细节(特别是边缘)丢失。
- CNN 更关注“是什么”,而不是“在哪里”。
结果就是,CNN 的输出可能像这样:
🟦🟦🟦🟦🟦
🟦🟦🟦🟦🟦
🟦🟦🟥🟥🟥 ← 实际边界是斜的
🟦🟦🟥🟥🟥
🟦🟦🟥🟥🟥
→ 模糊的、方块状的边界。
什么是 CRF ?
CRF,全称是 Conditional Random Field(条件随机场),是一种图模型,常用于序列/图像的标签优化问题。
在图像中我们可以把每个像素看成一个节点,CRF 就在这些节点之间建立关系,进行“全图优化”。
目标:根据图像的原始颜色、纹理等低级信息,把 CNN 的粗糙预测边界“拉回来”,更精细地拟合真实边界。
全连接CRF
意思是:
图像中的每一对像素(哪怕离得很远)都建立了联系,并共同影响最终的标签预测。
它考虑两个主要因素:
- 相邻像素颜色是否相似?
-
- 如果两个像素颜色差不多,那它们更可能属于同一个类别
- 像素之间的空间位置
-
- 近的像素影响力更大,远的像素影响小

原图:
⬜⬜⬜🧍⬜⬜⬜
CNN 输出:
⬛⬛🟨🟨🟨⬛⬛ (把背景也误判成人)
CRF 结果:
⬛⬛⬛🟨⬛⬛⬛ (清晰分出边界,只保留真正的人像像素)3.网络结构设计
(1)基础网络:修改 VGG-16 架构
- 将全连接层
fc6、fc7、fc8改为卷积形式 → 使网络可处理任意大小输入 - 将后两层池化(
pool4、pool5)的步长改为 1 → 不缩小尺寸 - 使用空洞卷积补足感受野(代替上采样):
| 卷积层 | 修改前 | 修改后 |
| conv5_x | 普通卷积 | 空洞卷积,rate=2 |
| fc6 | 7×7 卷积,4096通道 | 改为 3×3 空洞卷积,rate=12,通道数降为1024 |
| fc8 | 输出类别数 | 改为 21(PASCAL VOC 中的类别数) |
(2)后处理:DenseCRF(全连接条件随机场)
- 根据图像的颜色相似性和空间位置细化边界
- 能有效修复模糊边界、错分区域
二、Deeplab v2:——ASPP【多尺度特征融合】
1.背景:
- DeepLab v1 使用了空洞卷积(Atrous Conv)来扩大感受野、不降低分辨率;
- 但它仍然有两个限制:
| 限制 | 描述 |
| ✅ 单一尺度感知 | 只有一个固定 dilation rate,难以同时适配大物体和小物体 |
| ✅ 缺乏多尺度上下文 | 不能有效融合全局与局部信息 |
“多尺度核”:指使用多个不同感受野(尺寸/尺度)的卷积核或空洞卷积来提取图像中的不同尺度的特征;
“单一尺度”:指只用一种大小的卷积核(或一个 dilation rate)提特征,只关注一个尺度的对象。
想象你拿着放大镜看风景:
| 工具 | 看得见什么 | 类比 |
| 小放大镜 | 看清蚂蚁、小草 | 小尺度特征(细节) |
| 中等镜 | 看清狗、车轮 | 中尺度特征(常见目标) |
| 广角镜头 | 看整片草地、大楼 | 大尺度特征(背景或大目标) |
现在回到语义分割任务:
假如你只用 3×3 普通卷积 提特征(或空洞率 = 6):
| 网络提到的物体 | 占图比例 | 是否能被识别 |
| 🐶 小狗耳朵 | 小 | ✅能看到 |
| 🐶 整只狗 | 中 | ❌感受野可能不够 |
| 🌳 大树 | 大 | ❌看不到全貌 |
这时候你只能看到“一个尺度”的世界 —— 单一尺度。
1.创新点:
多尺度特征改进方法:
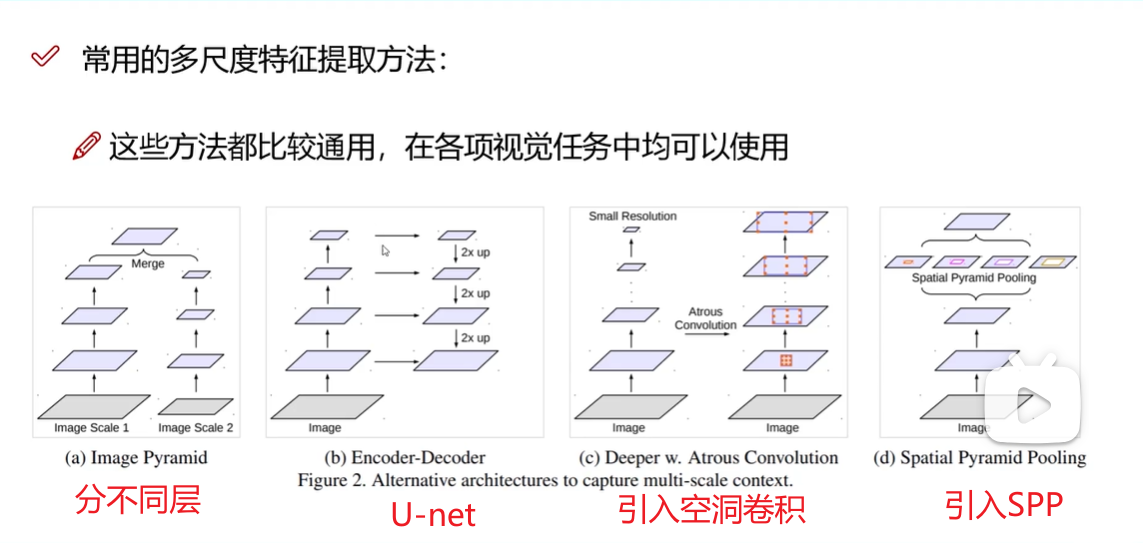
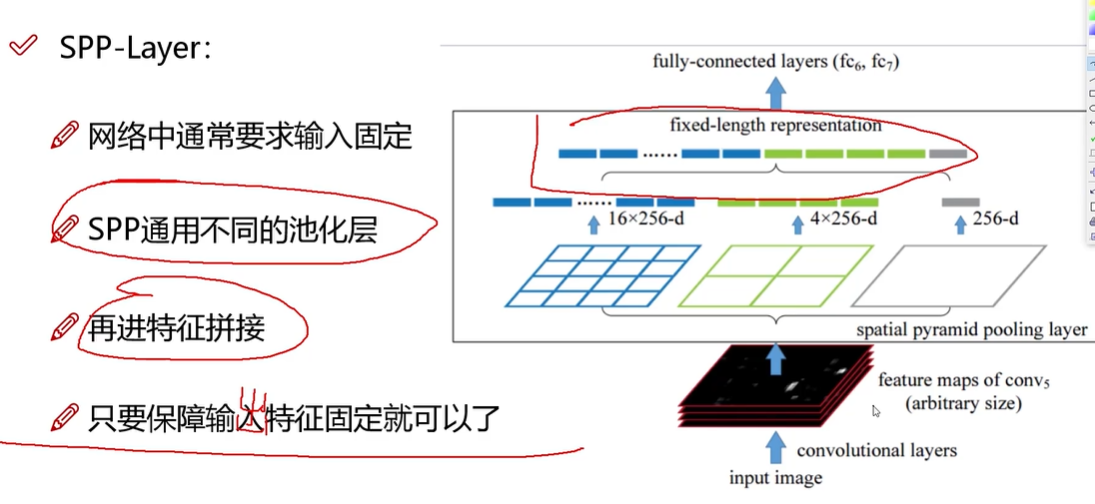
SPP层(特征融合):空间金字塔池化
图像金字塔:
1.分成16个格子做max pooling,每个特征图得到16个特征值,最后得到16*256(通道数)个特征
2.分成四个格子做max pooling
3.最后一个做全局
最后放到一起,得到(16+4+1)*256(张图)
(1)ASPP模块 ≈ 并联的多个空洞卷积层 + 特征拼接融合
ASPP:在SPP中引入空洞卷积,本质是并行的多个空洞卷积
ASPP 就是用多个 不同膨胀率(dilation rate) 的空洞卷积 并行卷一遍,提取不同尺度的特征。 最后把这些分支的输出 拼接起来(concatenate),就得到了融合了多个尺度上下文信息的特征图。
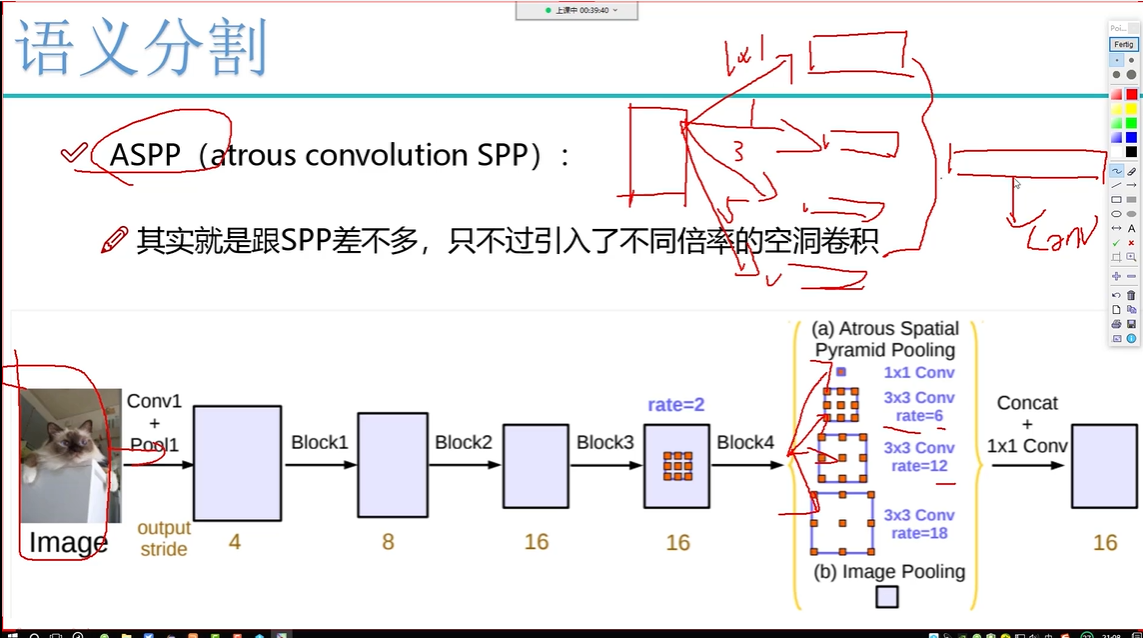
构成模块:
| 分支名称 | 操作类型 | 空洞率 (dilation rate) | 感受野 | 作用 |
| Branch 1 | 1×1 卷积 | 1 | 小 | 保留原始特征 |
| Branch 2 | 3×3 空洞卷积 | 6 | 中 | 感受中等区域 |
| Branch 3 | 3×3 空洞卷积 | 12 | 大 | 感受较大区域 |
| Branch 4 | 3×3 空洞卷积 | 18 | 更大 | 感受最广区域 |
| Branch 5 | 全局平均池化 + 1×1卷积 | - | 极大 | 感受全图(可选) |
将同一个特征图走不同rate的空洞卷积,在通道维度拼接,得到的特征图拼在一起再做卷积融合,形成最终多尺度特征图。
输入特征图(来自 backbone)
│
┌────────┴────────────┐
↓ ↓ ↓ ↓ ↓
1x1 空洞6 空洞12 空洞18 全局池化
↓ ↓ ↓ ↓ ↓
conv1 conv2 conv3 conv4 conv5
└────────┬────────────┘
↓
特征图拼接(concatenate)
↓
1×1卷积融合
↓
ASPP输出
3.网络结构 (基于 VGG / ResNet)
和 DeepLab v1 类似,v2 的主干可以是:
- VGG-16:改 fc 层为卷积,最后空洞卷积 + ASPP
- ResNet-101(更常见):保留残差结构,最后加 ASPP
关键是最后的输出要保持较高分辨率,所以卷积层 stride 通常被设置为 1,同时加入空洞卷积填补感受野。
三、Deeplab v3——扩充了ASPP模块,去掉CRF【细化精度】
1.背景
在 DeepLab v1 和 DeepLab v2 提出之后,尽管空洞卷积(Atrous Convolution)和 ASPP(Atrous Spatial Pyramid Pooling) 模块已被引入,语义分割仍面临以下挑战:
- 感受野问题:虽然使用空洞卷积扩大了感受野,但单一尺度的卷积核仍然难以同时捕捉大物体和小物体。
- 上下文信息缺失:无法有效地融合全局和局部信息,特别是在复杂背景和不同尺度物体的情况下。
- 精度问题:深度学习模型常常无法处理图像中的细节部分(如边缘)。
DeepLab v3 的提出正是为了进一步克服这些挑战,它在 DeepLab v2 的基础上进行了多项改进,特别是在 ASPP 模块 和 感受野扩展 方面。
2.创新点:
DeepLab v3 的核心创新包括:
- 扩展 ASPP 模块:在原有的 ASPP 模块基础上进行了扩展,通过多个不同膨胀率的空洞卷积并行处理输入特征图,捕捉不同尺度的上下文信息。
- 去除 CRF 后处理:与 DeepLab v1 和 v2 中的后处理方法不同,DeepLab v3 已经足够强大,可以直接生成较高质量的分割结果,无需额外的 CRF(条件随机场) 后处理。
- 更强的多尺度上下文融合能力:通过多尺度训练和推理,DeepLab v3 能够处理不同尺度的物体,改善边界精细化和小目标的分割。
- 高效的 Backbone:使用了 Xception 网络作为 backbone,进一步提高了计算效率,同时增强了模型的表现能力。
ASPP 是 DeepLab 系列中非常重要的模块,它的作用是通过多个不同膨胀率的空洞卷积并行提取不同尺度的特征。
- 多个空洞卷积并行:DeepLab v3 在 ASPP 模块 中并行使用多个不同膨胀率的空洞卷积(dilation rate),从而捕捉从局部到全局的不同尺度信息。
- 各个分支的作用:
-
- 1×1 卷积(dilation rate=1):用于保留原始的细节特征。
- 3×3 空洞卷积(dilation rate=6, 12, 18):捕获中等、较大和广阔的上下文区域。
- 全局池化:用于捕获整个图像的全局上下文。
这些分支输出的特征图会进行拼接(concatenate),然后再通过 1×1 卷积融合,最终形成包含多尺度上下文信息的输出特征图。
一句话:在ASPP最后又加了一层:全局平均池化层
四、Deeplab v3+——添加了解码器,将深层特征与浅层特征融合,更加细化了边缘处理
采用DeepLab v3作为encoder,添加decoder得到新的模型(DeepLabv3+),如图:
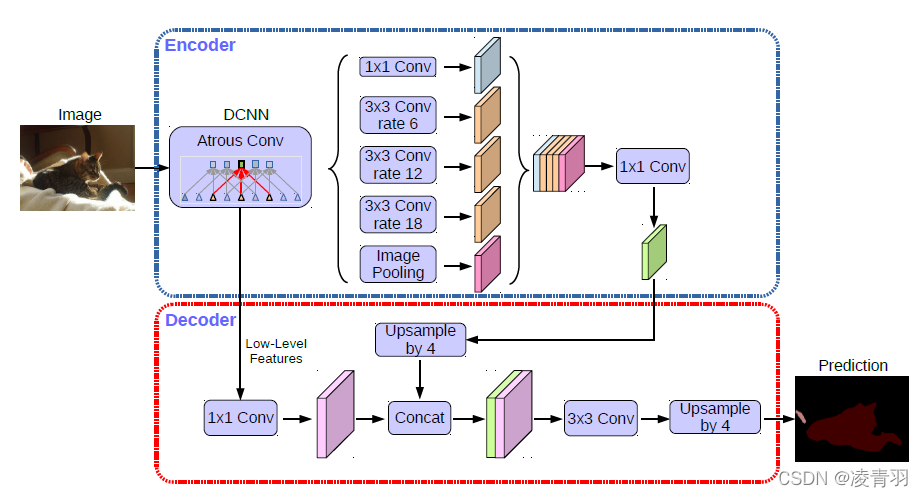
编码器(Encoder):理解图像内容,压缩信息
解码器(Decoder):恢复图像空间结构,细化信息
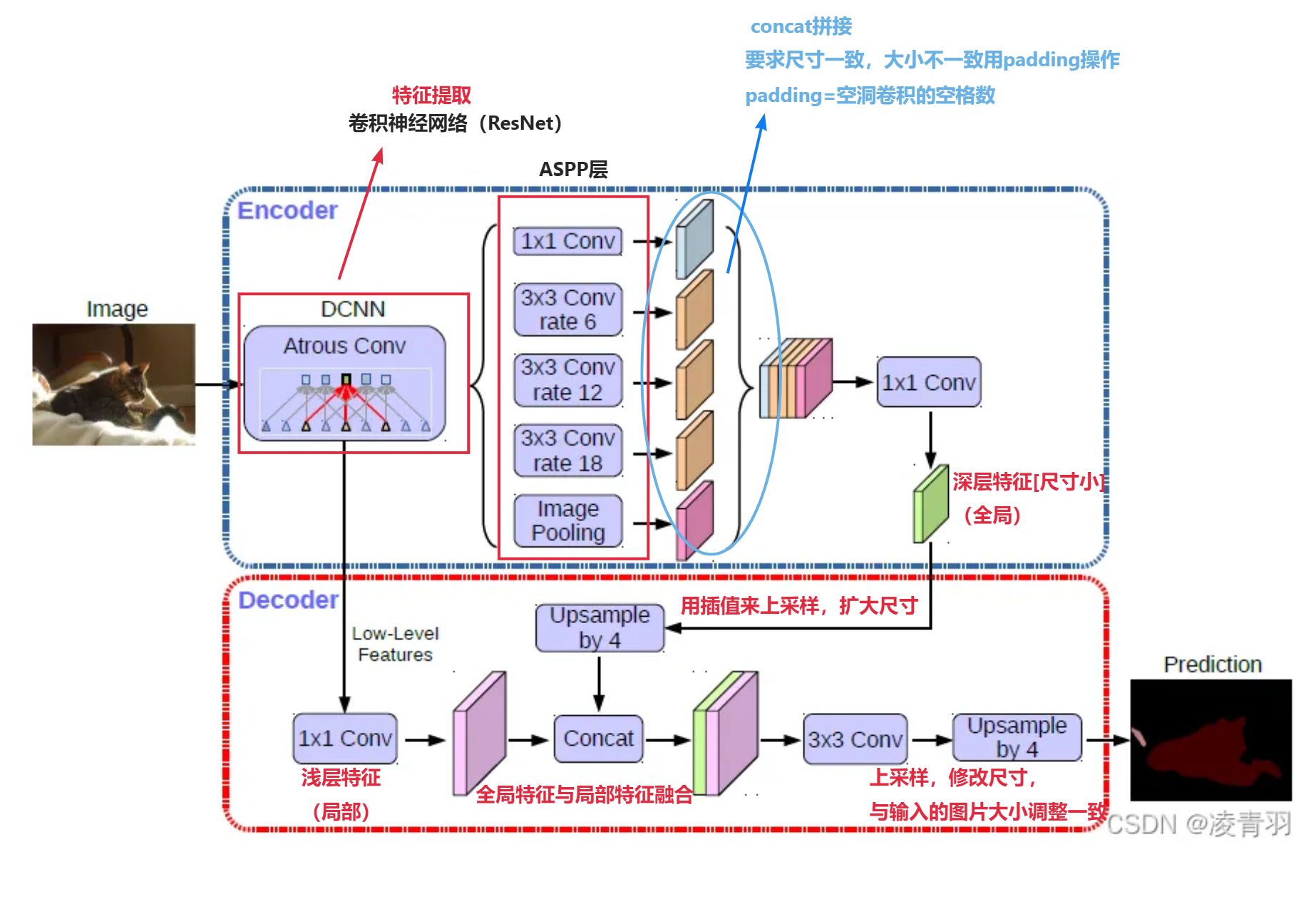
DeepLabv3+ 结合了 DeepLabv3 的强大特征提取能力和解码器模块的细化能力,提供了一种更加精准的解决方案,尤其在处理复杂图像的细节和边界时表现尤为突出。通过增加解码器,DeepLabv3+ 在保持高效多尺度特征提取的同时,显著提高了对小物体和精细边界的分割精度。
论文下面博客里有


















 7475
7475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









