






一、项目介绍
使用selenium模块进行我国主要城市年度数据的爬取,爬取相关数据到数据集中,实现根据年份分门别类。
二、项目过程
1. 数据源:国家统计局

2.爬取字段:
[
"地区生产总值", # 1
"第一产业增加值", # 2
"第二产业增加值", # 3
"第三产业增加值", # 4
"年末户籍人口", # 5
"城镇非私营单位在岗职工平均工资", # 6
"房地产开发投资额", # 7
"房地产开发住宅投资额", # 8
"房地产开发办公楼投资额", # 9
"房地产开发商业营业用房投资额", # 10
"房地产开发企业施工房屋面积", # 11
"房地产开发企业竣工房屋面积", # 12
"房地产开发企业住宅竣工房屋面积", # 13(不知道为什么报错)
"商品房销售面积", # 14
"住宅商品房销售面积", # 15
"商品房平均销售价格", # 16
"住宅商品房平均销售价格", # 17
"房地产开发企业购置土地面积", # 18
"地方一般公共预算收入", # 19
"地方一般公共预算支出", # 20
"住户存款余额", # 21
"旅客运输量", # 22
"货物运输量", # 23
"年末邮政局", # 24
"年末固定电话用户", # 25
"社会消费品零售总额", # 26
"货物进出口总额", # 27
"普通本专科在校学生数", # 28
"医院数", # 29
"执业(助理)医师数", # 30
"剧场、影剧院数", # 31
"开发区高新技术企业数", # 32
"开发区高新技术企业从业人员", # 33
"开发区高新技术企业总产值", # 34
"开发区高新技术企业总收入", # 35
"开发区高新技术企业出口总额", # 36
"道路交通等效声级dB", # 37
"环境噪声等效声级dB" # 38
]
我们需要爬取上述所有的字段在36个城市里从2003年到2022年任意的数据。
3. 爬取思路(重点)
爬取思想:封装函数
先了解一下selenium爬虫的特点:在浏览器上直接模拟用户的一系列行为,很适合进行比如说我马上要爬取的元素在点击另一个按钮加载的页面下,我可以使用代码模拟用户点击行为,点击到该页面上。但是缺点也很明显,我们需要注意元素加载和元素遮挡的相关问题,比如网络不好,一些按钮加载失败了,selenium模块就会判定找不到元素,从而报错退出程序,所以尽量保证电脑网落良好。
3.1 安装Chrome模块以及对应chromedriver
1.安装selenium模块及其相关驱动
安装selenium模块(以PyCharm为例)
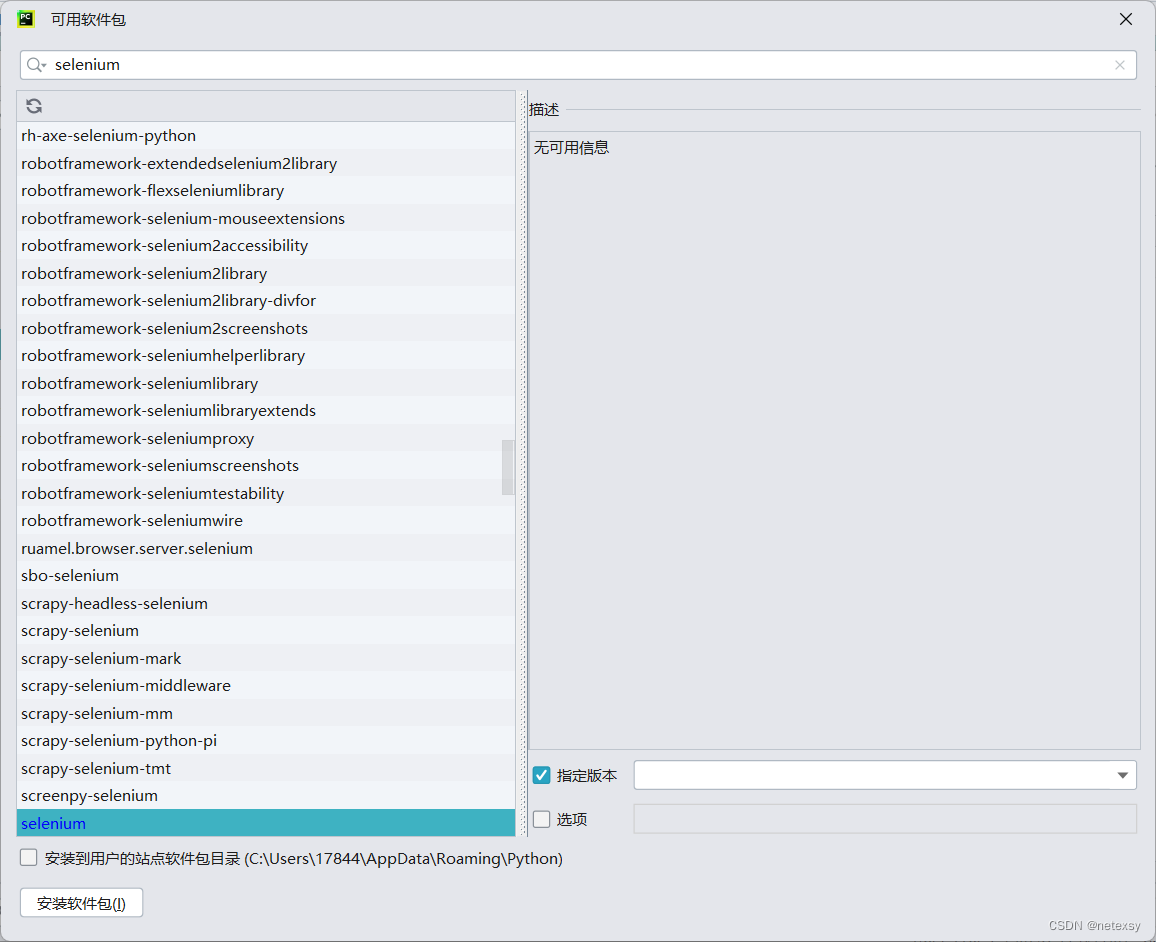
方法一:打开PyCharm,依次点击 “文件”--->“设置”--->“python解释器”--->选择适合的环境(环境可以自己新建,也可以使用基础环境,不过建议新建一个)--->“加号”进入如下页面,
输入“selenium”,选择版本为“3.141.0”(这里一定要使用这个版本或者附近的版本,不要用最新的版本,最新的版本有些老的指令被废掉了,使用起来不方便,用这个版本就行了)
方法二:打开命令行,进入自己指定的环境或者基础环境,输入“pip install selenium==3.141.0”,一样也可以下载selenium模块。
2.安装chrome以及chromedriver(以chrome为例,firefox等等参考其他教程吧,这里我只用了chrome)
chrome可以随便百度搜索安装一下,但是要注意版本问题,最好使用114版本及以下的,因为chromedriver的目前版本114以上的不好用,很少,chromedriver版本要和chrome版本对应,不然运行的时候会报错。
我使用的是114版本的chrome

下载链接:google浏览器下载-google浏览器电脑版下载v114.0.5735.199 - 安下载
安装完成后大多数人会遇到一个问题------chrome会自动升级,它会自动升级到116版本甚至116版本以上,这个时候就需要我们手动设置来阻止chrome自动升级。(这个方法也不是都适用,可能你安装后找不到update文件夹,这种情况就再换几个Chrome下载)
如何阻止chrome自动升级呢:
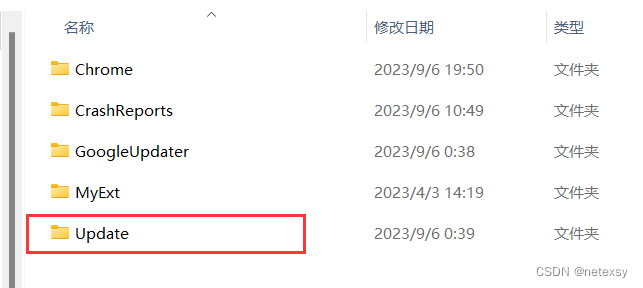
在下载完chrome后,先别急着打开chrome。一般下载完chrome后桌面会自动创建快捷方式,右键点击快捷方式,然后点击“打开文件所在位置”,进入程序所在根目录
之后,按照操作,选择>>>Google目录

选择>>>Update
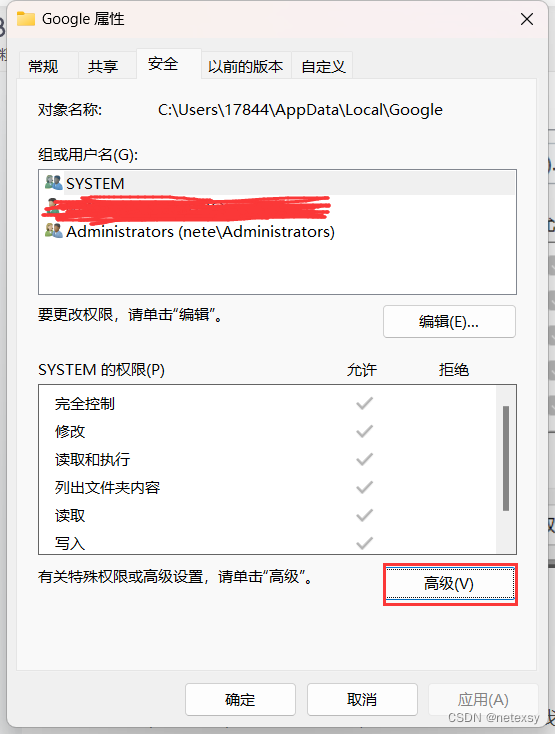
右键>>>属性

安全>>>SYSTEM>>>编辑

全部勾选拒绝

继续选择>>>高级
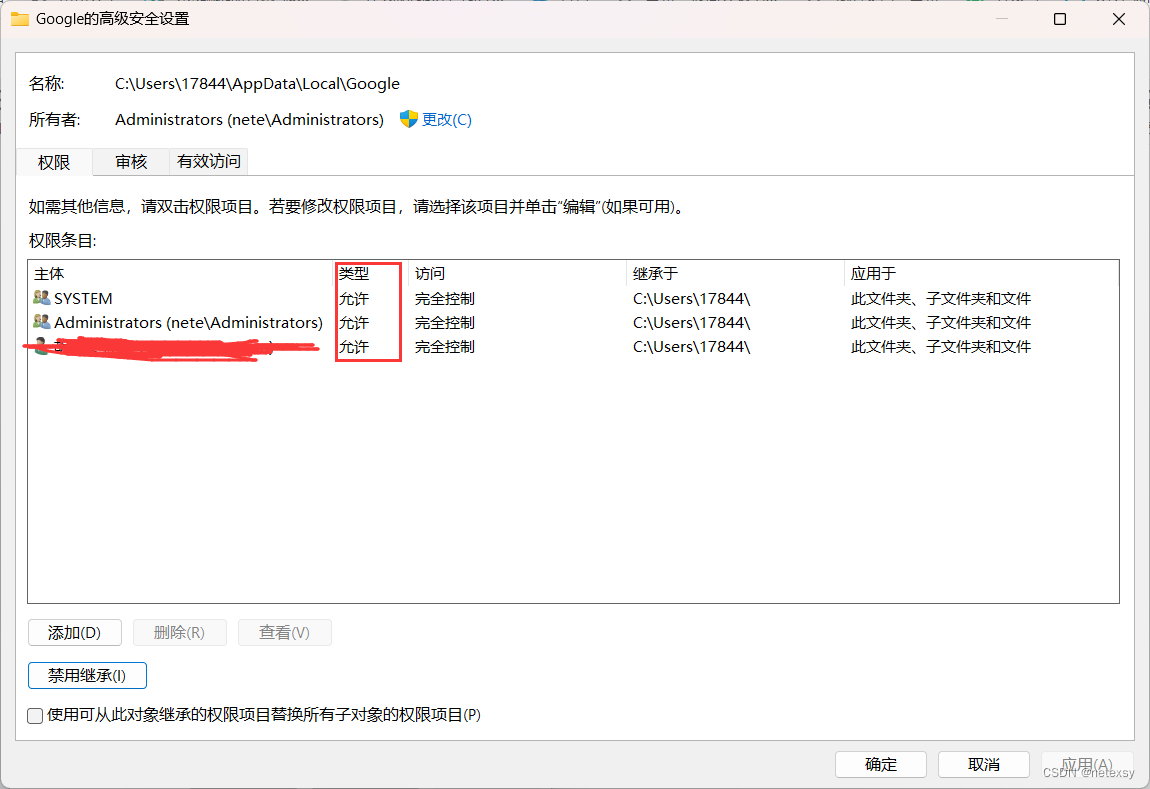
最重要的一步:
首先点击禁用继承

然后将所有类型为允许的条目删除
最后检查一下是否成功,点击Update文件夹,发现无权访问,那么就差不多成功了!
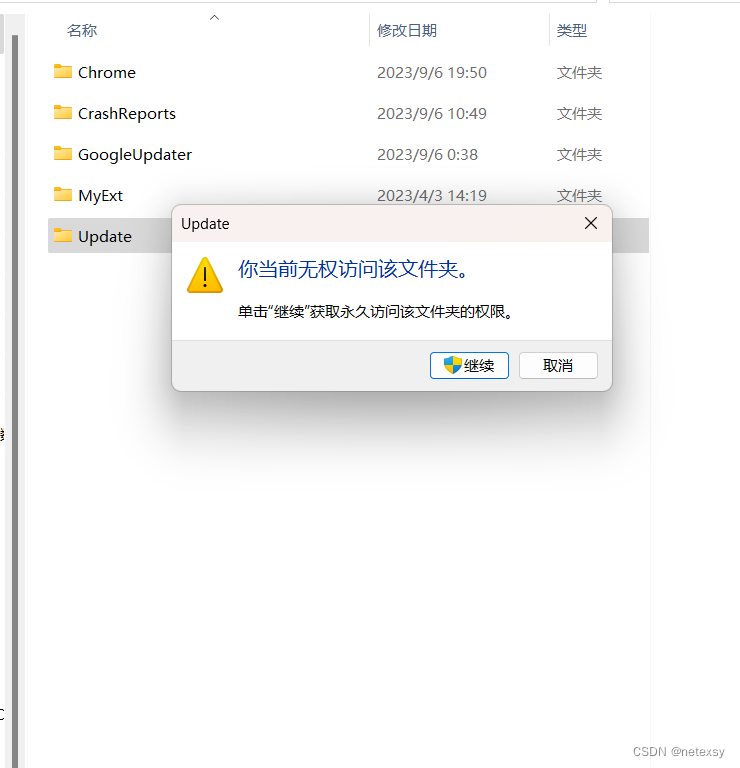
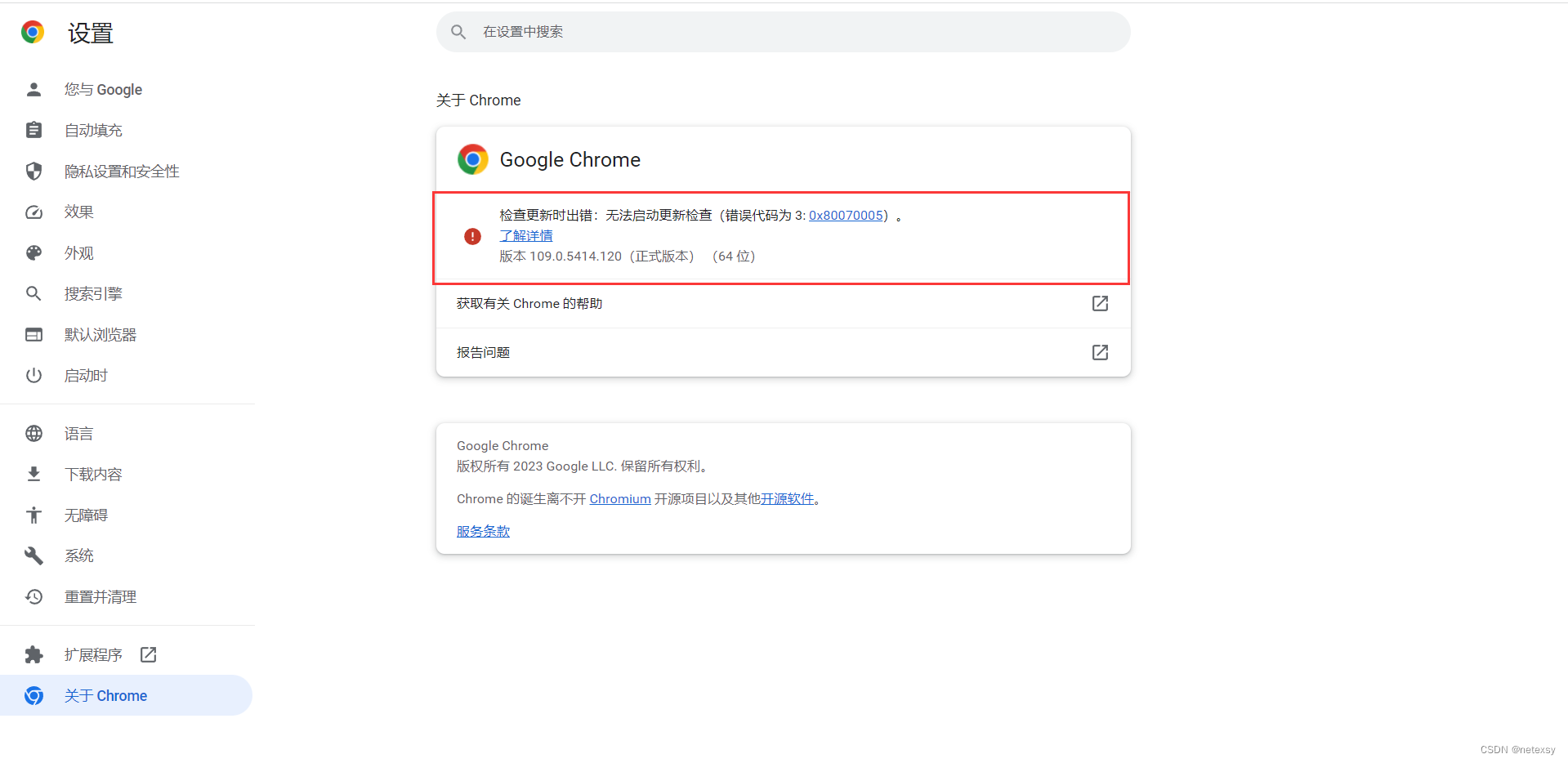
打开Chrome,点击右上角的设置>>>帮助>>>关于Google Chrome,发现检查更新报错,那么就成功了。
接下来我们安装chromedriver,这个东西可以帮助我们运行爬虫代码,实时测试网页。
安装地址:
ChromeDriver - WebDriver for Chrome - Downloads
Download older versions of Google Chrome for Windows, Linux and Mac
注意:你的chrome浏览器是什么版本的,那你下载的这个chromedriver也要对应
我下载的chrome是114.0.5735.199

那么下载的chromedriver也要对应,不一定要完全一样,选最接近的版本就行了。

下载好之后将我们的chromedriver放到和我们python安装路径相同的目录下

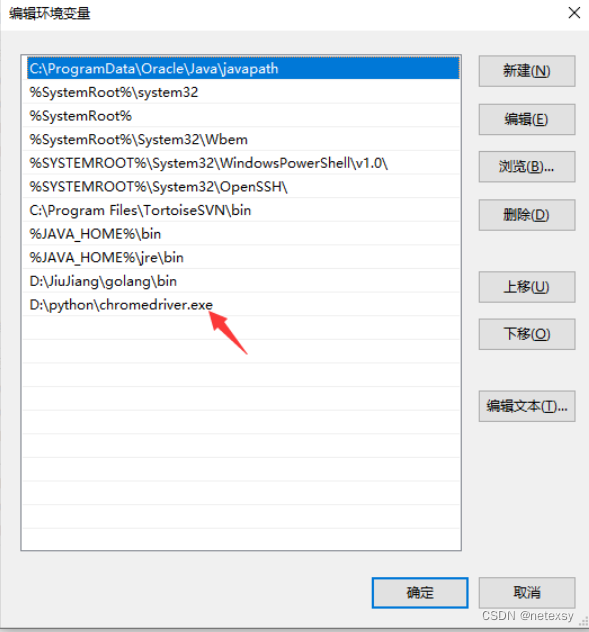
其实这个时候差不多已经可以正常运行了,但有些人可能运行不了,可能是对应的环境变量没有添加(如果你把python安装目录已经添加到环境变量里面就应该没问题,有问题可能是没有完全添加进去,导致这个chromedriver系统识别不到)
打开我们的查看高级系统设置,点击环境变量,打开系统变量里面的path环境。添加我们的驱动路径进去。
完成之后我们可以打开PyCharm运行一段代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)如果成功跳出chrome浏览器并显示了如下图的网页,那么安装就算完成了!

3.2 模拟点击相关标签、按钮的实现
在安装好selenium模块以及Chrome浏览器和chromedriver驱动后,我们开始爬虫!

我们先观察一下这个网页,当我们开始运行代码后,跳出来的第一个页面就是上图,我们总结一下其中需要我们关注的标签及按钮。

对上图的解释:
3.2.1 时间标签:
点击一下该标签,弹出三个选择项,分别是“最近5年” “最近10年” “最近20年” 和 一个输入框,我们可以通过输入“last21”来显示从2003年到2022年的所有数据。

3.2.2 大类指标标签:
你自己操作一下就知道了,点击不同的大类指标标签,右边就会显示不同小类指标
3.2.3 选择小类指标标签
点击该标签后会出现对应的小类指标标签
当点击不同的大类指标标签,再第一次点击选择小类指标标签时,会出现如下情况

这时候我们需要点击“序列”,然后会出现小类指标的第一项所有数据,即“地区生产总值”的所有数据。

这个时候我们再点击选择小类指标标签,就会出现所有的小类指标标签,这个时候再点击不同的小类指标标签,比点击如第三行的“第一产业增加值”,就会切换到“第一产业增加值”的所有数据。

其他的小类标签同上都可以被获取!
3.2.4 小类指标标签:
就是点击选择小类指标标签后出现的所有小类指标


其实本次项目涉及到的标签元素很少,就一个小类指标标签和一个大类指标标签还有一个时间标签,输入框元素就只有在输入那个“last21”的时候输入一下,大部分都是数据元素的定位。
举个例子,一次性讲明白
比如我现在要爬取国民经济核算大类指标下的第一产业增加值

(重点):
开始运行程序的时候,出现的界面是

这个时候我们点击一下“国民经济核算”这个大类指标标签

然后点击一下选择小类指标标签

然后再点击一下“序列”,这个时候跳到了“地区生产总值”这一项上

然后再点击一下选择小类指标标签

最后点击一下小类指标标签中的“第一产业增加值”,就成功找到了我们想要的元素
总结一下整个过程
点击大类标签——>点击选择小类指标标签——>点击序列——>点击选择小类指标标签——>点击小类指标标签。
3.3 标签元素、输入框元素、数据元素等元素的定位
我们可以借助开发者工具来实现对于元素的定位(XPath)
进入页面,按下F12 或者 右键选择“检查”(有些浏览器可能是“开发者工具”字样)
反正不管怎样,右边弹出来一个类似下图的界面就行。

我们先点击上图红框框区域最左上角的![]() (这个按钮必须要被选中)
(这个按钮必须要被选中)
随后我们移动鼠标到左边的网页,发现每个元素都能被选中,我们选择“国民经济核算”这个大类指标标签,点击它。
随后右边的开发者工具中会显示该标签所在的html语句

这样这个标签的具体信息就得到了!
接下来,我们寻找大类指标标签、选择小类指标标签、小类指标标签和输入框的对应元素信息。
3.3.1 输入框及“确认”按钮

![]()
那么如何用代码来表示呢,代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
time.sleep(0.47)
element = driver.find_element_by_xpath("//div[@class='dtHead' and @node='{\"code\":\"LAST5\",\"name\":\"最近5年\",\"sort\":\"4\"}']")
element.click()
time.sleep(2.5)
if __name__ == "__main__":
start()使用一个element变量获取这个下拉框,然后使用click的方法实现点击

输入框:
![]()
“确定”按钮:
![]()
使用代码向输入框里面写入“last21”,并点击确认按钮
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
time.sleep(0.47)
element = driver.find_element_by_xpath("//div[@class='dtHead' and @node='{\"code\":\"LAST5\",\"name\":\"最近5年\",\"sort\":\"4\"}']")
element.click()
input_box = driver.find_element_by_class_name("dtText")
input_box.clear()
input_box.send_keys("last21")
confirm_button = driver.find_element_by_xpath("//div[@class='dtTextBtn']")
confirm_button.click()
time.sleep(2.5)
if __name__ == "__main__":
start()
3.3.2 大类指标标签

![]()
使用代码进行点击
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
# 点击大类指标标签
element = driver.find_element_by_id('treeZhiBiao_3_span')
element.click()
time.sleep(2.5)
if __name__ == "__main__":
start()
3.3.3 选择小类指标标签

![]()
注意:这里虽然是很长的一大串,但是我们可以使用class="dtHead"来进行定位
使用代码进行点击
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
# 点击选择小类指标标签
element = driver.find_element_by_class_name('dtHead')
element.click()
time.sleep(2.5)
if __name__ == "__main__":
start()
3.3.4 序列标签

代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
element = driver.find_element_by_class_name('dtHead')
element.click()
# 点击序列标签
element = driver.find_element_by_xpath("//li[@node='{\"code\":\"\",\"name\":\"序列\",\"sort\":\"4\"}']")
element.click()
time.sleep(2.5)
if __name__ == "__main__":
start()3.3.5 小类指标标签


我们只需要关注红框框中的就行了,代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
element = driver.find_element_by_id('treeZhiBiao_3_span')
element.click()
element = driver.find_element_by_class_name('dtHead')
element.click()
element = driver.find_element_by_xpath("//li[@node='{\"code\":\"\",\"name\":\"序列\",\"sort\":\"4\"}']")
element.click()
element = driver.find_element_by_class_name('dtHead')
element.click()
# 点击小类指标标签
element = driver.find_element_by_xpath("//li[@node='{\"code\":\"A0102\",\"name\":\"第一产业增加值(亿元)\",\"sort\":\"1\"}']")
element.click()
time.sleep(2.5)
if __name__ == "__main__":
start()3.3.6 数据元素
以2022年地区生产总值为例

首先我们定位到2022年北京的那一个数据,即41540.90

右键蓝色部分,然后复制——>复制XPath

该数据元素的Xpath是这样的
//*[@id="table_main"]/tbody/tr[1]/td[3]而该元素又是位于第一行第三列的,所以根据规律,我们可以获取所有数据元素的值
获取该元素的代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def start():
# 创建ChromeOptions对象
chrome_options = Options()
# 禁用SSL证书验证
chrome_options.add_argument('--ignore-ssl-errors=yes')
chrome_options.add_argument('--ignore-certificate-errors')
url = "https://data.stats.gov.cn/easyquery.htm?cn=E0105"
driver = webdriver.Chrome(options=chrome_options)
# driver.minimize_window()
driver.get(url)
element = driver.find_element_by_id('treeZhiBiao_3_span')
element.click()
element = driver.find_element_by_class_name('dtHead')
element.click()
element = driver.find_element_by_xpath("//li[@node='{\"code\":\"\",\"name\":\"序列\",\"sort\":\"4\"}']")
element.click()
data = driver.find_elements_by_xpath(f'//*[@id="table_main"]/tbody/tr[1]/td[3]')[0].text
print(data)
if __name__ == "__main__":
start()运行代码后,下面的输出栏会显示数据41540.90

到此为止,基本的概念与操作就解释完了!
三、代码展示
GitHub - nete1108/Annual-data-crawling-of-major-cities-in-China: Selenium爬虫项目-我国主要城市年度数据爬取相关代码
https://download.csdn.net/download/m0_74282695/89195107?spm=1001.2014.3001.5503














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









