






目录
一、爬取前期准备工作
二、爬取目标
三、爬取过程(重点)
四、生成可视化图表
五、全部代码
一、爬取前期准备工作
1.安装selenium模块及其相关驱动
安装selenium模块(以PyCharm为例)
方法一:打开PyCharm,依次点击 “文件”--->“设置”--->“python解释器”--->选择适合的环境(环境可以自己新建,也可以使用基础环境,不过建议新建一个)--->“加号”进入如下页面,
输入“selenium”,选择版本为“3.141.0”(这里一定要使用这个版本或者附近的版本,不要用最新的版本,最新的版本有些老的指令被废掉了,使用起来不方便,用这个版本就行了)
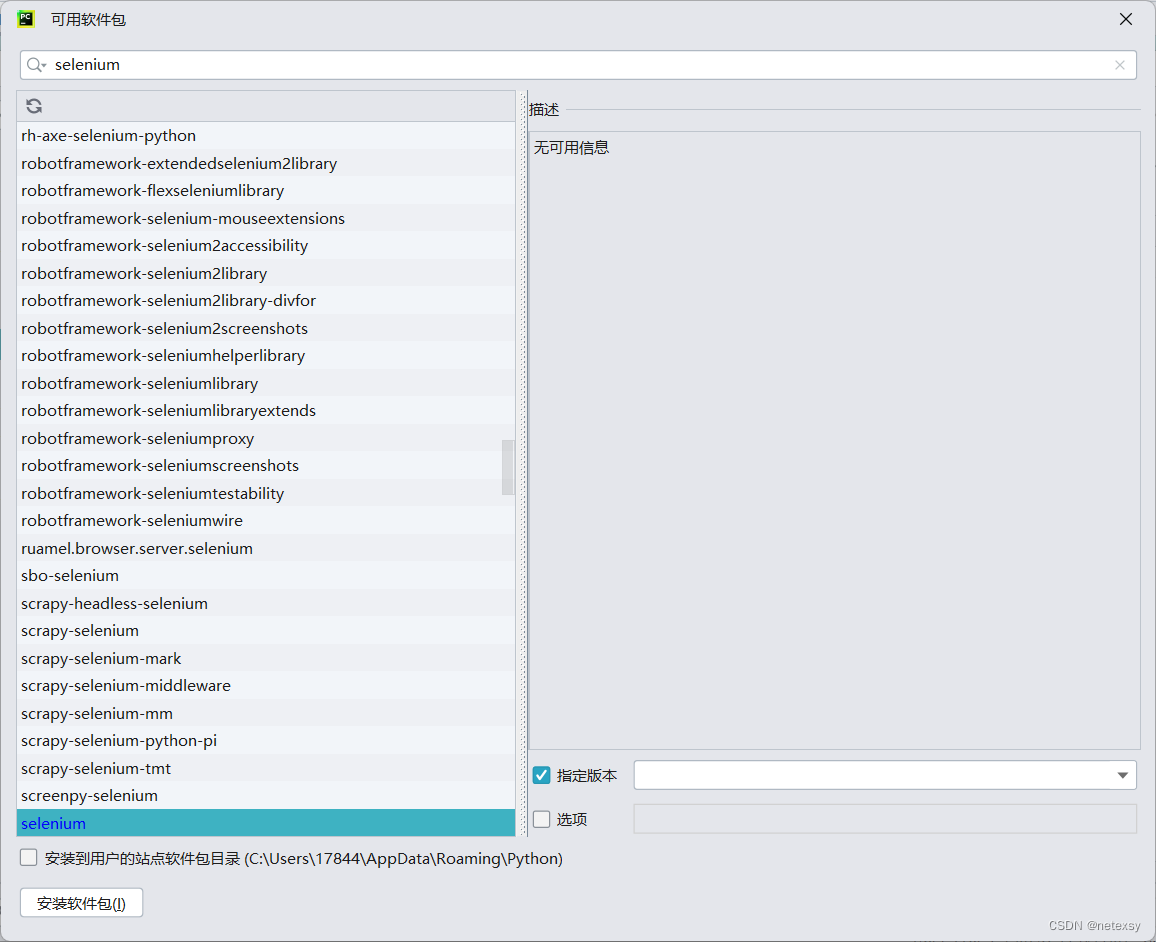
方法二:打开命令行,进入自己指定的环境或者基础环境,输入“pip install selenium==3.141.0”,一样也可以下载selenium模块。
2.安装chrome以及chromedriver(以chrome为例,firefox等等参考其他教程吧,这里我只用了chrome)
chrome可以随便百度搜索安装一下,但是要注意版本问题,最好使用114版本一下的,因为chromedriver的目前版本114以上的不好用,很少,chromedriver版本要和chrome版本对应,不然运行的时候会报错。
我使用的是109版本的chrome

下载链接:Chromev109.0.5414.120下载-Chrome2023最新版下载_3DM软件
安装完成后大多数人会遇到一个问题------chrome会自动升级,它会自动升级到116版本甚至116版本以上,这个时候就需要我们手动设置来阻止chrome自动升级。
如何阻止chrome自动升级呢:
在下载完chrome后,先别急着打开chrome。一般下载完chrome后桌面会自动创建快捷方式,右键点击快捷方式,然后点击“打开文件所在位置”,进入程序所在根目录
之后,按照操作,选择>>>Google目录

选择>>>Update
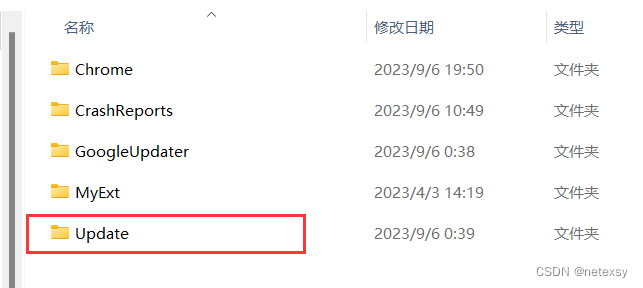
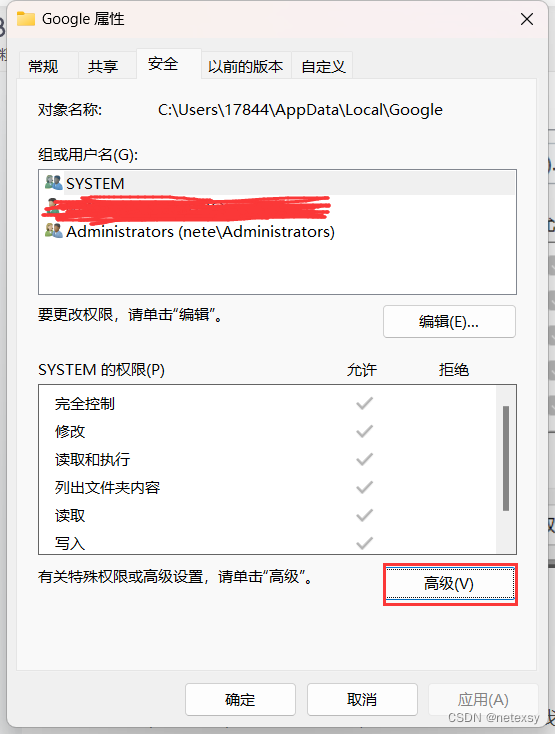
右键>>>属性

安全>>>SYSTEM>>>编辑

全部勾选拒绝

继续选择>>>高级
最重要的一步:
首先点击禁用继承

然后将所有类型为允许的条目删除
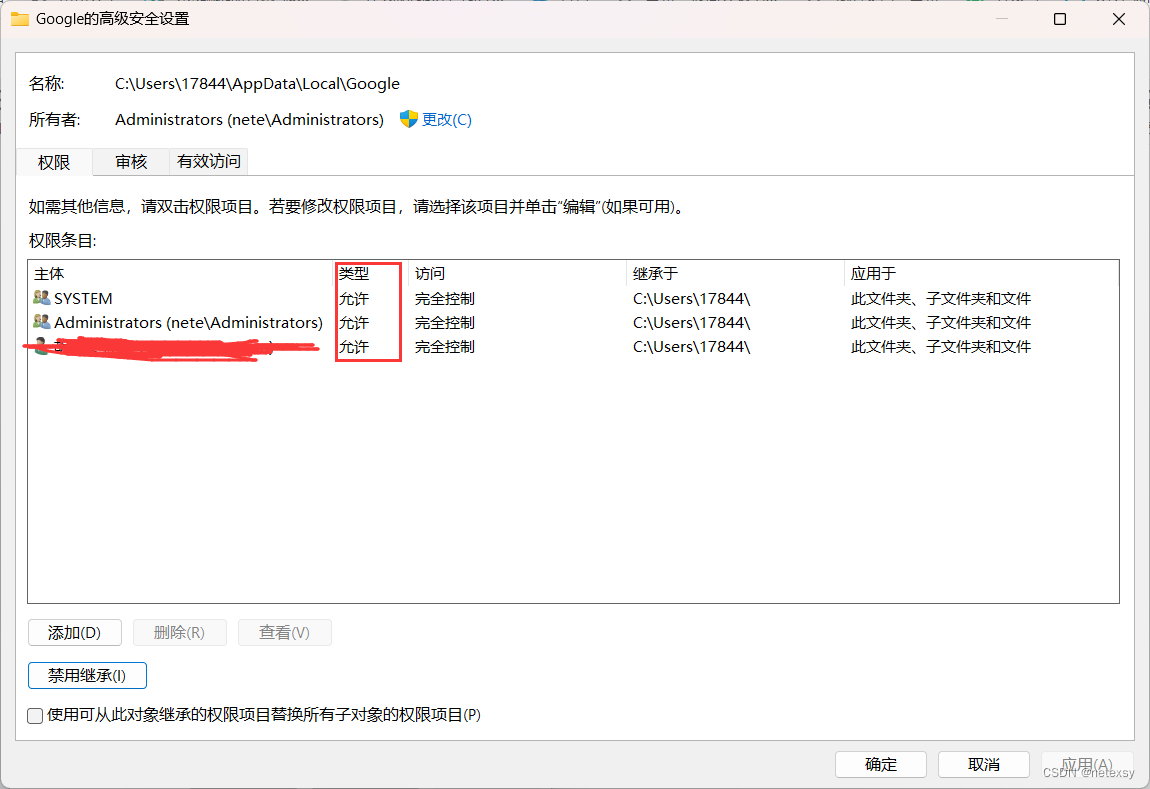
最后检查一下是否成功,点击Update文件夹,发现无权访问,那么就差不多成功了!
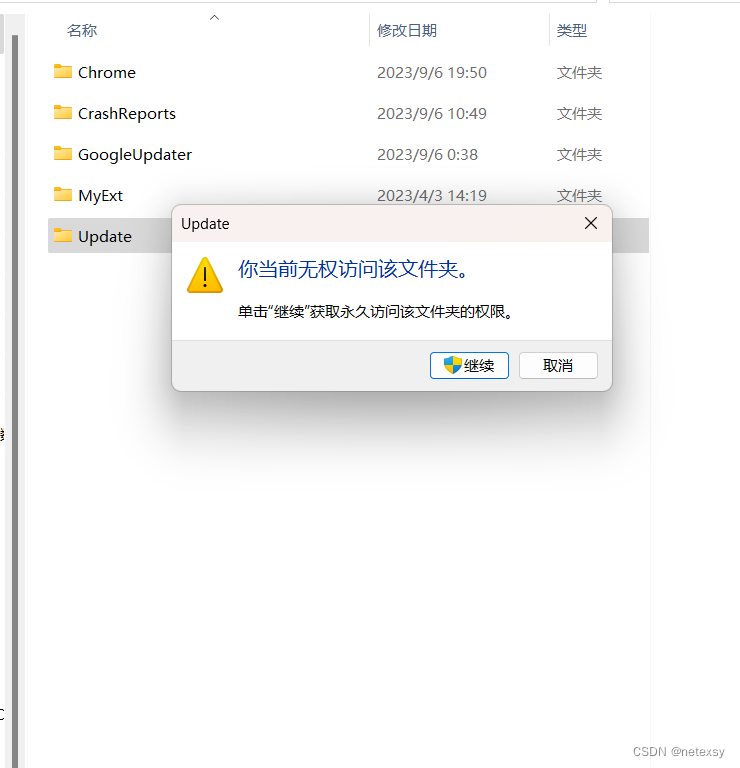
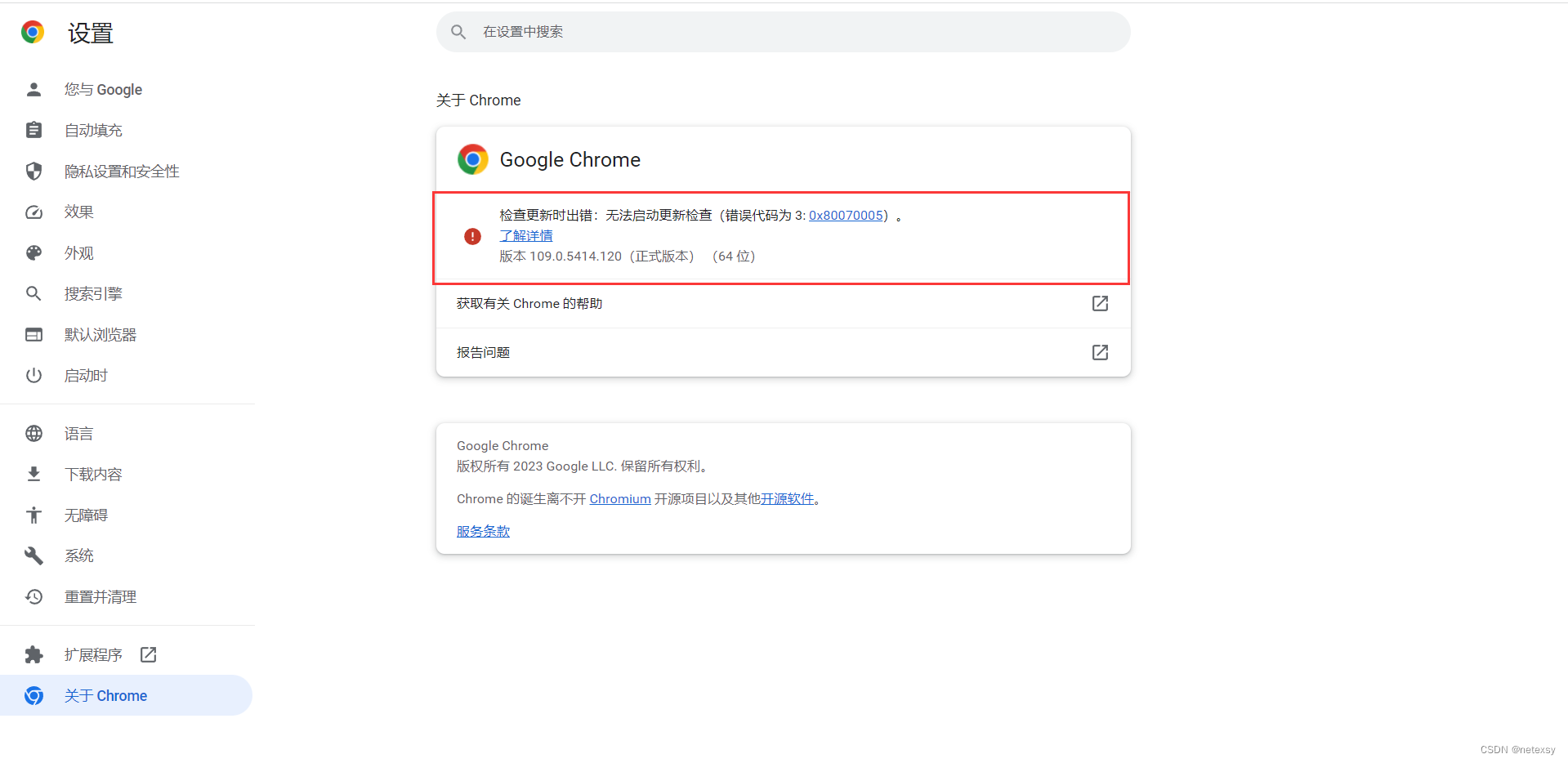
打开Chrome,点击右上角的设置>>>帮助>>>关于Google Chrome,发现检查更新报错,那么就成功了。
接下来我们安装chromedriver,这个东西可以帮助我们运行爬虫代码,实时测试网页。
安装地址:
ChromeDriver - WebDriver for Chrome - Downloads
Download older versions of Google Chrome for Windows, Linux and Mac
注意:你的chrome浏览器是什么版本的,那你下载的这个chromedriver也要对应
我下载的chrome是109.0.5414.120

那么下载的chromedriver也要对应,不一定要完全一样,选最接近的版本就行了。

下载好之后将我们的chromedriver放到和我们python安装路径相同的目录下

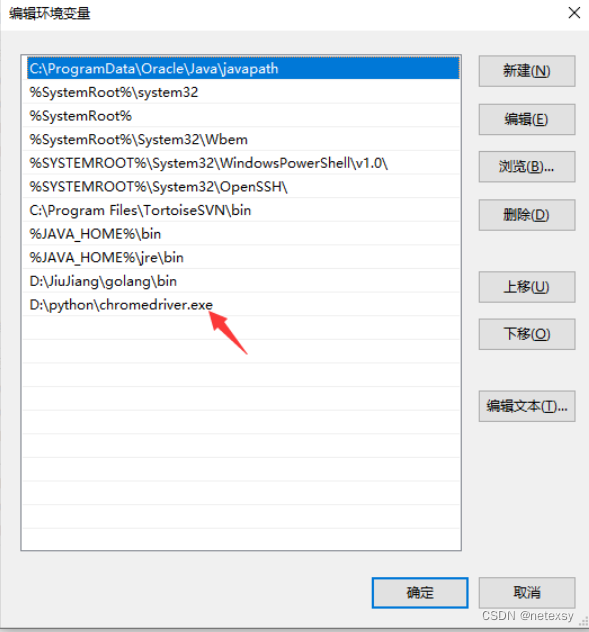
其实这个时候差不多已经可以正常运行了,但有些人可能运行不了,可能是对应的环境变量没有添加(如果你把python安装目录已经添加到环境变量里面就应该没问题,有问题可能是没有完全添加进去,导致这个chromedriver系统识别不到)
打开我们的查看高级系统设置,点击环境变量,打开系统变量里面的path环境。添加我们的驱动路径进去。
完成之后我们可以打开PyCharm运行一段代码:
from selenium import webdriver
if __name__ == '__main__':
url = "https://www.bilibili.com/"
driver = webdriver.Chrome()
driver.get(url)如果成功跳出chrome浏览器并显示已经到b站主页,那么安装就算完成了!

二、爬取目标
我们要爬取什么数据,并且该利用这些数据制作什么图表。这应该是我们要最先明确的,有了目标才能事半功倍。
我们小组在进行爬取信息决策时,想出了以下5条爬取目标:
1.bilibili热门榜top100视频相关数据的爬取
需要爬取内容: 当前榜单top100视频的标题,up主,观看量,弹幕数, 点赞数,投币数,收藏数,转发数。
分析点: 比较观看量,弹幕数, 点赞数,投币数,收藏数,转发数的差异。
2.bilibili热歌排行榜数据爬取
需要爬取内容: 各个种类歌曲排行榜,MV排行榜。
分析点: 统计各个种类歌曲的播放量,得出b站用户最爱哪种类型的歌曲。
3.bilibili美食区视频标签的数据爬取
需要爬取内容: 视频标题,各个视频的相关标签。
分析点: 分析标签词条出现频次,分析当前最热标签词条。
4.单一视频的评论数据爬取
需要爬取内容: 选择一个内容新颖的视频,爬取其评论信息
分析点: 分析各个评论传达出的情感态度,进行情感态度词条的统计,分析出该视频内容的好坏。
5.单一视频一周内各个参数数据的爬取
需要爬取内容: 该视频一周内的观看量, 弹幕数, 点赞数, 投币数, 收藏数, 转发数。
分析点: 分析该视频一周内各个数据的变化,推断出该视频的热度以及受欢迎度。
有了目标后,我们就可以开始干活了!
三、爬取过程
1.bilibili热门榜top100视频相关数据的爬取
由于这个top100榜单肯定是实时变化的,所以我们的这个榜单肯定不一样,但是爬取的过程是一样的,只是爬取下来的数据不一样。

这是我写这篇文章时的榜单
接下来是爬取过程:
先说一下我的爬取过程思考:
第一步:先将这个总页面中的100个视频的url(链接)都爬取下来,写入一个文件url.csv里面
第二部:循环读取url.csv文件里面的100个url(链接),进入每个视频的页面,然后将每个视频的具体信息爬取下来,写入一个文件top100.csv里面。
这样视频的相关信息就被我顺利爬取下来了(其实也可以直接在读取到每个视频url时就进入每个视频页面直接爬取信息,这就省略了第一步。但是当时我没有考虑这个,坚持一步一步来,所以这里就分享这个稍微麻烦一点的方法)
1.直接给出代码,下面这个是爬取top100所有视频链接的代码。
import csv # csv模块在生成、写入文件时用到
from selenium import webdriver # selenium模块下的webdriver是爬虫要用的
if __name__ == '__main__': # 入口
url = 'https://www.bilibili.com/v/popular/rank/all' # top100总页面链接
driver = webdriver.Chrome() # 启动chromediver进行调试
driver.get(url) # 传入url
csv_file = "data/top100_url.csv" # 新建一个名为top100_url的csv类型的文件放在data文件夹下(data文件夹可以自己新建,代码运行后也会自动生成)
with open(csv_file, 'a',newline='', encoding='utf-8') as f: # 打开刚刚定义的文件,'a'是追加模式,也可以换成'w','w'为重写模式,encoding为编码,设置为'utf-8'
writer = csv.writer(f) # 自定义一个名为writer的变量,这句就直接抄,不解释
writer.writerow(['b站实时排行榜前一百视频url','up主昵称']) # 写入列标题
i = 1 # i的初始值设置为1
print()
while(i < 101): # 循环爬取100个视频的url
all_datas = driver.find_elements_by_xpath(f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/a') # 这里是通过xpath来定位视频的链接,all_datas返回的值为当前视频所在小模块的所有信息,当然也包括了url
all_up_name = driver.find_elements_by_xpath(f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/div/a/span') # 这里通过xpath爬取up的名字,all_up_name返回值为一个list
href_values = [element.get_attribute("href") for element in all_datas] # 从all_datas中提取每个视频的url(链接)
up_name = all_up_name[0].text # 从all_ip_data中提取up主名字
writer.writerow([href_values[0], up_name]) # 将每个视频的url与对应up主名字写入文件
print(f'第{i}个视频已经爬取完成') # 显示进度
i += 1 要注意的是:在爬取的过程中,需要我们实时加载页面,因为页面如果不加载,数据就无法被系统检测到,会导致程序卡死,这个时候我们大概率只能重新来过,如果你看懂了代码,稍微修改一下就能够实现在对应的地方继续爬虫或者重复爬虫。
爬取下来的数据差不多是这样的(这里只展示了前一部分,一共应该有100行)----第一列是url,第二列是up主名字,其实只需要第一列,第二列没啥用。

欧克!现在我们第一步就算完成了
2.直接给出代码,这里是根据上面我们爬下来的url(链接)循环爬取每个视频的相关信息
# 导入模块
import csv
from selenium import webdriver
import pandas as pd
# 提取上一步爬取下来的文件中的url
all_urls = pd.read_csv('./data/top100_url.csv') # 利用pandas模块读取csv文件
all_video_urls = all_urls['b站实时排行榜前一百视频url'] # 利用类标题获取url所在列的信息,all_video_urls返回值类型为(pandas.core.series.Series),这个理解为一个表格就行了
all_video_up = all_urls['up主昵称'] # 同上这里获取up名字
driver = webdriver.Chrome() # 启动chromedriver
csv_file = "data/top100_details.csv" # 新建一个文件,存储所有视频的相关信息
with open(csv_file, 'a', newline='', encoding='utf-8') as f: # 打开文件,循环写入信息
writer = csv.writer(f)
writer.writerow(['视频标题', 'up主', '观看量', '弹幕数', '点赞数', '投币数', '收藏数', '转发数']) # 我们要爬取的视频信息包括(1.视频标题 2.up主 3.观看量 4.弹幕数 5.点赞数 6.投币数 7.收藏数 8.转发数)
i = 0
for url in all_video_urls: # 循环遍历all_video_urls中的每一个url(链接)
driver.get(url) # 打开每一个链接
###############################################################################
data_title = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / h1')
title = data_title[0].text ###### 视频标题
###############################################################################
up = all_video_up[i] ###### up主
###############################################################################
data_watch_dm = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / div / div / span') # data_watch_dm包含了播放量和弹幕数的相关数据
######################################################################
####因为爬取出来的数据都是数字加上汉字“万” ###
####所以我处理了一下,将“万”全部都变成×10000,使得所有数据都为数字形式###
#####################################################################
watch = data_watch_dm[0].text ###### 播放量
# 处理汉字‘万’
if watch[-1] in '万':
num = float(watch[0:-1])
num *= 10000
watch = str(num)
###############################################################################
dm = data_watch_dm[1].text ###### 弹幕数
# 处理汉字‘万’
if dm[-1] in '万':
num = float(dm[0:-1])
num *= 10000
dm = str(num)
###############################################################################
data_dz_tb_sc_fx = driver.find_elements_by_xpath('// *[ @ id = "arc_toolbar_report"] / div[1] / div') # data_dz_tb_sc_fx包含了带你赞数,投币数,收藏数,分享数的相关数据
######################################################################
####因为爬取出来的数据都是数字加上汉字“万” ###
####所以我处理了一下,将“万”全部都变成×10000,使得所有数据都为数字形式###
#####################################################################
video_like_info = data_dz_tb_sc_fx[0].text ###### 点赞数
# 处理汉字‘万’
if video_like_info[-1] in '万':
num = float(video_like_info[0:-1])
num *= 10000
video_like_info = str(num)
###############################################################################
video_coin_info = data_dz_tb_sc_fx[1].text ###### 投币数
# 处理汉字‘万’
if video_coin_info[-1] in '万':
num = float(video_coin_info[0:-1])
num *= 10000
video_coin_info = str(num)
###############################################################################
video_fav_info = data_dz_tb_sc_fx[2].text ###### 收藏数
# 处理汉字‘万’
if video_fav_info[-1] in '万':
num = float(video_fav_info[0:-1])
num *= 10000
video_fav_info = str(num)
###############################################################################
video_share_info = data_dz_tb_sc_fx[3].text ###### 分享数
# 处理汉字‘万’
if video_share_info[-1] in '万':
num = float(video_share_info[0:-1])
num *= 10000
video_share_info = str(num)
###############################################################################
row = [title, up, watch, dm, video_like_info, video_coin_info,
video_fav_info, video_share_info] # 将数据打包为一个list(列表)
writer.writerow(row) # 写入文件
print(f'第{i + 1}个视频已经爬取成功!') # 提示进度
i += 1到这里所有得视频信息就都被我们爬取下来了,可以检查一下爬取的数据集,下面是我爬取的部分数据。

3.下面是完整代码,可以直接复制使用,爬取的是b站热门榜top100视频的相关链接与具体数据,代码会生成两个csv文件-------第一个是top100_url.csv,存储100个视频的链接;第二个是top100_details.csv,存储100个视频的具体参数及数据。(包括 1.视频标题 2.up主 3.观看量 4.弹幕数 5.点赞数 6.投币数 7.收藏数 8.转发数)(数据是粗数据,只能精确到万位,对于大作业来说应该到这里就差不多了)
import csv
from selenium import webdriver
import pandas as pd
if __name__ == '__main__':
url = 'https://www.bilibili.com/v/popular/rank/all'
driver = webdriver.Chrome()
driver.get(url)
csv_file = "data/top100_url.csv"
with open(csv_file, 'a',newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['b站实时排行榜前一百视频url','up主昵称'])
i = 1
print()
while(i < 101):
all_datas = driver.find_elements_by_xpath(f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/a')
all_up_name = driver.find_elements_by_xpath(f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/div/a/span')
href_values = [element.get_attribute("href") for element in all_datas]
up_name = all_up_name[0].text
writer.writerow([href_values[0], up_name])
print(f'第{i}个视频已经爬取完成')
i += 1
########################################################################################################################
# 提取上一步爬取下来的文件中的url
all_urls = pd.read_csv('./data/top100_url.csv')
all_video_urls = all_urls['b站实时排行榜前一百视频url']
all_video_up = all_urls['up主昵称']
driver = webdriver.Chrome()
csv_file = "data/top100_details.csv"
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['视频标题', 'up主', '观看量', '弹幕数', '点赞数', '投币数', '收藏数', '转发数'])
i = 0
for url in all_video_urls:
driver.get(url)
data_title = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / h1')
title = data_title[0].text ###### 视频标题
up = all_video_up[i] ###### up主
data_watch_dm = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / div / div / span')
watch = data_watch_dm[0].text ###### 播放量
if watch[-1] in '万':
num = float(watch[0:-1])
num *= 10000
watch = str(num)
dm = data_watch_dm[1].text ###### 弹幕数
if dm[-1] in '万':
num = float(dm[0:-1])
num *= 10000
dm = str(num)
data_dz_tb_sc_fx = driver.find_elements_by_xpath('// *[ @ id = "arc_toolbar_report"] / div[1] / div')
video_like_info = data_dz_tb_sc_fx[0].text ###### 点赞数
if video_like_info[-1] in '万':
num = float(video_like_info[0:-1])
num *= 10000
video_like_info = str(num)
video_coin_info = data_dz_tb_sc_fx[1].text ###### 投币数
if video_coin_info[-1] in '万':
num = float(video_coin_info[0:-1])
num *= 10000
video_coin_info = str(num)
video_fav_info = data_dz_tb_sc_fx[2].text ###### 收藏数
if video_fav_info[-1] in '万':
num = float(video_fav_info[0:-1])
num *= 10000
video_fav_info = str(num)
video_share_info = data_dz_tb_sc_fx[3].text ###### 分享数
if video_share_info[-1] in '万':
num = float(video_share_info[0:-1])
num *= 10000
video_share_info = str(num)
row = [title, up, watch, dm, video_like_info, video_coin_info,
video_fav_info, video_share_info]
writer.writerow(row)
print(f'第{i + 1}个视频已经爬取成功!')
i += 1欧克欧克!到这里所有的数据就爬取完成了,第一个目标就算完成了,看到这里,你应该差不多了解这个爬虫的具体过程(上面的注释详细看看)
如果你不了解的话,可以找我问问,看到了问题私信的话我会回的😊
接下来直接放代码
bilibili热歌排行榜数据爬取
import csv
from selenium import webdriver
if __name__ == '__main__':
url = "https://www.bilibili.com/v/musicplus/video"
driver = webdriver.Chrome()
driver.get(url)
csv_file = "data_analysis/music_hank.csv"
i = 50
music_type_list = []
while(i < 120):
data_type_elements = driver.find_elements_by_xpath(f'//*[@id="main"]/div/div[2]/ul[2]/li[{int(i/5)}]')
data_type = data_type_elements[0].text
i += 1
print(i)
# print(music_type_list)
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([data_type])
j = 1
while j:
data_bf_element = driver.find_elements_by_xpath(f'//*[@id="main"]/div/div[3]/div[{j}]/div/a/div[1]/div[1]/span[1]')
if not data_bf_element:
break
else:
data_bf = data_bf_element[0].text
if data_bf[-1] in '万':
num = float(data_bf[0:-1])
num *= 10000
data_bf = str(num)
writer.writerow([data_bf])
print(j)
j += 1注意:这个代码不要直接点运行,推荐使用“调试”,因为程序运行很快,我们来不及加载页面。
这个代码爬取的是音乐区---->最热 里面的“全部曲风”的每一个曲风的前5页的所有视频的播放量

爬取下来又整理之后的数据集差不多是这样的(数据全部都是播放量)(部分)

那么,第二个爬取目标也就完成了
bilibili美食区视频标签的数据爬取
import csv
from selenium import webdriver
import pandas as pd
if __name__ == '__main__':
url = 'https://www.bilibili.com/v/food'
driver = webdriver.Chrome()
driver.get(url)
csv_file = "data/food_part_url.csv"
with open(csv_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['栏目', '链接'])
i = 3
while(i < 8):
all_part_name = (driver.find_elements_by_xpath(f'//*[@id="i_cecream"]/div/main/div/div[{i}]/div/div[1]/div[1]/a/span'))[0].text
all_part_url = driver.find_elements_by_xpath(f'//*[@id="i_cecream"]/div/main/div/div[{i}]/div/div[1]/div[2]/a')
href_values = [element.get_attribute("href") for element in all_part_url] # 栏目链接
writer.writerow([all_part_name, href_values[0]])
i += 1
######################################################################################################################################################
df = pd.read_csv("data/food_part_url.csv")
all_urls = df['链接']
name = df['栏目']
driver = webdriver.Chrome()
csv_file = "data/food_part_video_url.csv"
with open(csv_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['栏目', '视频标题', '视频链接'])
j = 0
for url in all_urls:
driver.get(url)
i = 1
while(i < 51):
video_name = (driver.find_elements_by_xpath(f'//*[@id="i_cecream"]/div/main/div/div[3]/div[2]/div[{i}]/div[2]/div/div/h3'))[0].text
video_element = driver.find_elements_by_xpath(f'//*[@id="i_cecream"]/div/main/div/div[3]/div[2]/div[{i}]/div[2]/div/div/h3/a')
href_values = [element.get_attribute("href") for element in video_element] # 视频链接
video_url = href_values[0]
writer.writerow([name[j], video_name, video_url])
i += 1
j += 1
#######################################################################################################################################################
df = pd.read_csv("data/food_part_video_url.csv")
all_urls = df['视频链接']
# print(all_urls)
driver = webdriver.Chrome()
csv_file = 'data/food_video_label.csv'
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['序号', '标签'])
xh = 1
for url in all_urls:
driver.get(url)
# //*[@id="v_tag"]/div
label_str = (driver.find_elements_by_xpath('//*[@id="v_tag"]/div'))[0].text.split('\n')
label_len = len(label_str)
i = 1
while(i < label_len):
label = label_str[i]
writer.writerow([xh, label])
i += 1
xh += 1
pass
这个代码爬取的是美食专区各栏目下视频的标签
这个代码也不能直接运行,需要调试,不会私信我,也可以自己试试看。
爬取的数据集(部分)

单一视频的评论数据爬取
from selenium import webdriver
import csv
from selenium.webdriver.common.action_chains import ActionChains
if __name__ == '__main__':
url = 'https://www.bilibili.com/video/BV1Dh4y1B7hL/?vd_source=aa7ea87c008d6da6708ad822cc3ba7e0'
driver = webdriver.Chrome()
driver.get(url)
count_comment = driver.find_elements_by_xpath('//*[@id="comment"]/div/div/div/div[1]/div/ul/li[1]/span[2]')
num = int(count_comment[0].text)
csv_file = "data/comment.csv"
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['序号', '评论者', '评论内容'])
i = 1
while(i < num):
comment_data = driver.find_elements_by_xpath(f'//*[@id="comment"]/div/div/div/div[2]/div[2]/div[{i}]/div[2]/div[2]/div[3]/span/span')
commenter_data = driver.find_elements_by_xpath(f'//*[@id="comment"]/div/div/div/div[2]/div[2]/div[{i}]/div[2]/div[2]/div[2]/div')
comment = comment_data[0].text
commenter = commenter_data[0].text
# print(comment)
# print(commenter)
xh = str(i)
row = [xh, commenter, comment]
writer.writerow(row)
print(f'成功爬取第{i}条评论')
print(commenter)
i += 1这个代码是爬取某个视频的相关评论(视频自己选),将url替换一下就可以了
在爬取时需要不断加载评论,不然代码就立刻停止了,卡在未刷新的地方。
爬取的数据集(部分)

单一视频一周内各个参数数据的爬取
from selenium import webdriver
import csv
import datetime
from time import strftime
if __name__ == '__main__':
url = "https://www.bilibili.com/video/BV1vw411r7yL/?spm_id_from=333.337.search-card.all.click&vd_source=5bfdd9c5aae2db8e974ef5d8db543de8"
driver = webdriver.Chrome()
driver.get(url)
csv_file = "data_analysis/jl_change.csv"
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['视频标题', '观看量', '弹幕数', '点赞数', '投币数', '收藏数', '转发数', ['时间']])
all_datas_part0 = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / h1')
data_title = all_datas_part0[0].text ###### 视频标题
all_datas_part2 = driver.find_elements_by_xpath('// *[ @ id = "viewbox_report"] / div / div / span')
data_watch = all_datas_part2[0].text ###### 播放量
if data_watch[-1] in '万':
num = float(data_watch[0:-1])
num *= 10000
data_watch = str(num)
data_dm = all_datas_part2[1].text ###### 弹幕数
if data_dm[-1] in '万':
num = float(data_dm[0:-1])
num *= 10000
data_dm = str(num)
all_datas_part3 = driver.find_elements_by_xpath('// *[ @ id = "arc_toolbar_report"] / div[1] / div')
data_video_like_info = all_datas_part3[0].text ###### 点赞数
if data_video_like_info[-1] in '万':
num = float(data_video_like_info[0:-1])
num *= 10000
data_video_like_info = str(num)
data_video_coin_info = all_datas_part3[1].text ###### 投币数
if data_video_coin_info[-1] in '万':
num = float(data_video_coin_info[0:-1])
num *= 10000
data_video_coin_info = str(num)
data_video_fav_info = all_datas_part3[2].text ###### 收藏数
if data_video_fav_info[-1] in '万':
num = float(data_video_fav_info[0:-1])
num *= 10000
data_video_fav_info = str(num)
data_video_share_info = all_datas_part3[3].text ###### 分享数
if data_video_share_info[-1] in '万':
num = float(data_video_share_info[0:-1])
num *= 10000
data_video_share_info = str(num)
data_time = datetime.datetime.now().strftime("%Y-%m-%d")
# print(data_time)
row = [data_title, data_watch, data_dm, data_video_like_info, data_video_coin_info,data_video_fav_info, data_video_share_info]
writer.writerow(row)这个和第一个差不多,直接爬取了一个指定的视频的所有视频,直接输入url。
但是后面这个要做数据可视化,我们在一周内的每一天都要运行一次这个代码,这样一周之后就会有七组数据。
到此为止,数据的爬取工作就基本完成了。
四、生成可视化图表
爬取完数据后,接下来最后一步就是根据数据生成可视化图表了
制作图表最常用的是pyecharts模块和matplotlib模块。这里我使用的是pyecharts模块,也没有做的很豪华,只是大概的生成图表。
回顾一下我们的目标:
1.bilibili热门榜top100视频相关数据的爬取
需要爬取内容: 当前榜单top100视频的标题,up主,观看量,弹幕数, 点赞数,投币数,收藏数,转发数。
分析点: 比较观看量,弹幕数, 点赞数,投币数,收藏数,转发数的差异。
2.bilibili热歌排行榜数据爬取
需要爬取内容: 各个种类歌曲排行榜,MV排行榜。
分析点: 统计各个种类歌曲的播放量,得出b站用户最爱哪种类型的歌曲。
3.bilibili美食区视频标签的数据爬取
需要爬取内容: 视频标题,各个视频的相关标签。
分析点: 分析标签词条出现频次,分析当前最热标签词条。
4.单一视频的评论数据爬取
需要爬取内容: 选择一个内容新颖的视频,爬取其评论信息
分析点: 分析各个评论传达出的情感态度,进行情感态度词条的统计,分析出该视频内容的好坏。
5.单一视频一周内各个参数数据的爬取
需要爬取内容: 该视频一周内的观看量, 弹幕数, 点赞数, 投币数, 收藏数, 转发数。
分析点: 分析该视频一周内各个数据的变化,推断出该视频的热度以及受欢迎度。
欧克!现在让我们开始制作图表!
1.bilibili热门榜top100视频相关数据(柱状图)
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
if __name__ == '__main__':
df = pd.read_csv("data/top100_details.csv") # 打开文件,使用参数df接收所有数据
df_title = df['视频标题'] # 提取视频标题
df_watch = df['观看量'] # 提取观看量
df_dm = df['弹幕数'] # 提取弹幕数
df_dz = df['点赞数'] # 提取点赞数
df_tb = df['投币数'] # 提取投币数
df_sc = df['收藏数'] # 提取收藏数
df_zf = df['转发数'] # 提取转发数
# 为所有参数各自新建一个空list
Title = []
Watch = []
Dm = []
Dz = []
Tb = []
Sc = []
Zf = []
# 将所有数据写入各自的list
for element in df_title:
Title.append(element)
for element in df_watch:
Watch.append(element)
for element in df_dm:
Dm.append(element)
for element in df_dz:
Dz.append(element)
for element in df_tb:
Tb.append(element)
for element in df_sc:
Sc.append(element)
for element in df_zf:
Zf.append(element)
# 自定义bar1为一个Bar类型,并设置 图表主题/宽度/高度
bar1 = Bar(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE, width="4500px", height="1200px"))
bar1.add_xaxis(Title) # x轴参数为各个视频的名称
# 设置图表标题
bar1.set_global_opts(
title_opts=opts.TitleOpts(title="b站热门榜top100数据统计柱状图", pos_left="50%", pos_top="5%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
# 设置y轴参数
# bar1.add_yaxis('播放量', Watch)
bar1.add_yaxis('弹幕数', Dm)
bar1.add_yaxis('点赞数', Dz)
bar1.add_yaxis('投币数', Tb)
bar1.add_yaxis('收藏数', Sc)
bar1.add_yaxis('转发数', Zf)
# 生成html文件
bar1.render('b站热门榜top100数据统计柱状图.html')
# 制作快照,这个代码会生成png图片,但是要安装其他模块(make_snaposhot模块/snapshot_selenium模块/snapshot模块)(其实截图就行了,可选)
make_snapshot(snapshot, "b站热门榜top100数据统计柱状图.html", "./picture/b站热门榜top100数据统计柱状图.png")
代码运行需要个7s~8s左右,主要是make_snapshot()运行时间长。
代码会生成一个html文件和一个png图片
图片参考如下:

接下来直接放代码
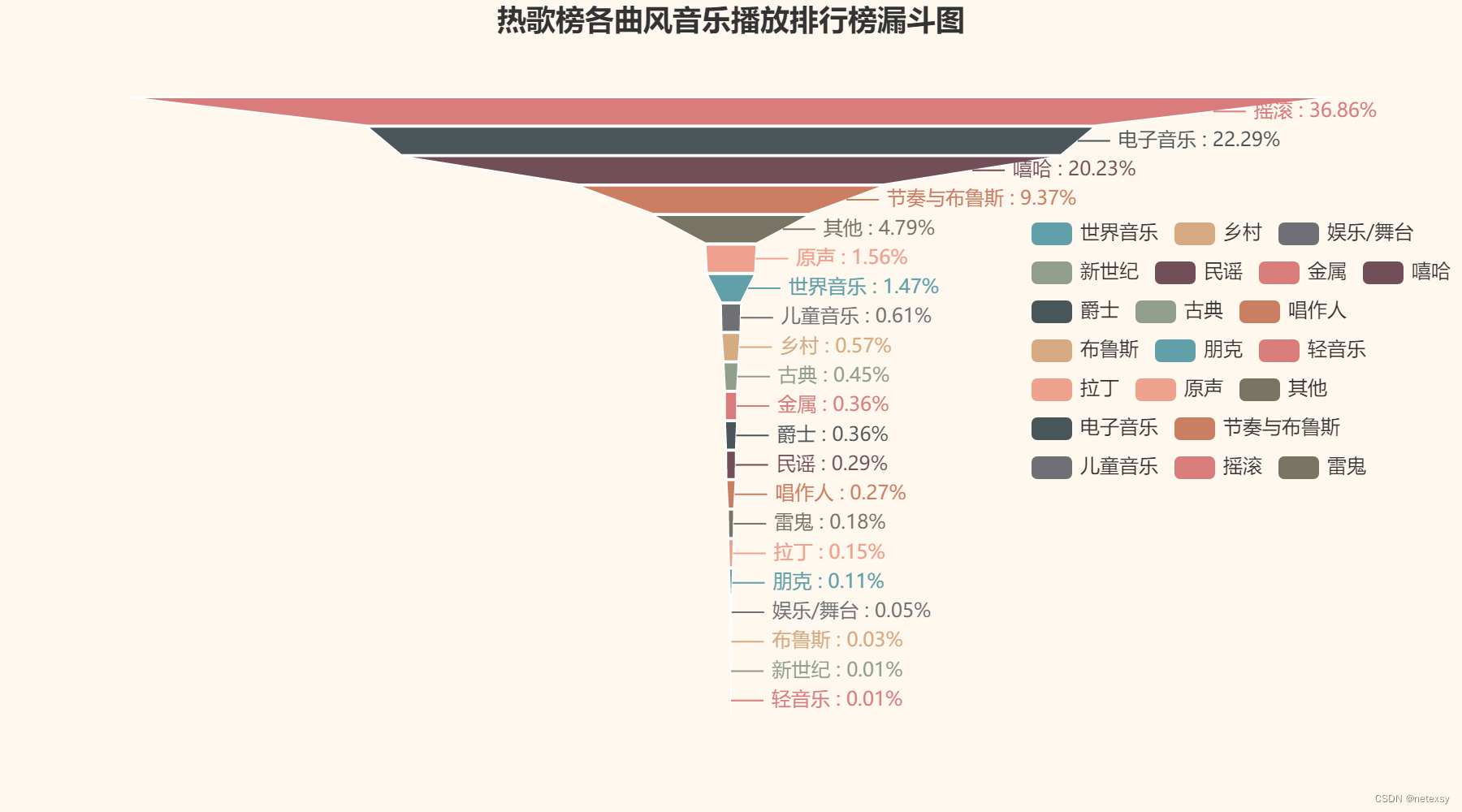
bilibili热歌排行榜数据 (漏斗图)
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
from pyecharts.globals import ThemeType
if __name__ == '__main__':
df = pd.read_csv('data_analysis/music_hank_new.csv', encoding='gbk')
type_sums = df.sum()
print(type_sums)
df_type_sum = list(zip(type_sums.index.to_list(),type_sums.to_list()))
sort_type_sum = sorted(df_type_sum, key=lambda x:x[1])
funnel = Funnel(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
funnel.add("", sort_type_sum,
gap=0.9,
label_opts=opts.LabelOpts(formatter="{b} : {d}%"),
)
funnel.set_global_opts(
title_opts=opts.TitleOpts(title="热歌榜各曲风音乐播放排行榜漏斗图", pos_left="center"),
legend_opts=opts.LegendOpts(pos_left='70%',pos_bottom='40%'), # 将图例放到右侧
)
funnel.render('热歌榜各曲风音乐播放排行榜漏斗图.html')
make_snapshot(snapshot, "热歌榜各曲风音乐播放排行榜漏斗图.html", "./picture/热歌榜各曲风音乐播放排行榜漏斗图.png")参考如下:
bilibili美食区视频标签的数据 (云图)
import pyecharts.options as opts
from pyecharts.charts import WordCloud
import pandas as pd
from pyecharts.globals import SymbolType
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
if __name__ == '__main__':
df = pd.read_csv("data_analysis/food_video_label.csv")
# print(df)
df_label = df.groupby('标签').size().sort_values(ascending=False)
# print(df_label)
datas = list(zip(df_label.index.to_list(),df_label.to_list()))
# print(datas)
cloud = WordCloud(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
cloud.add('', datas,shape='circle')
cloud.set_global_opts(
title_opts=opts.TitleOpts(title="b站美食热点标签统计分析云图", pos_left="37%", pos_top="3%")
)
cloud.render("b站美食热点标签统计分析云图.html")
make_snapshot(snapshot, "b站美食热点标签统计分析云图.html", "./picture/b站美食热点标签统计分析云图.png")
参考如下:

单一视频的评论数据爬取 (饼状图)
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
if __name__ == '__main__':
df = pd.read_csv('./data_analysis/comments_finish.csv', encoding='gbk')
df_mood = df.groupby('感情').size().sort_values(ascending=False)
datas = list(zip(df_mood.index.to_list(),df_mood.to_list()))
# print(datas)
title = "有关'AI越来越“变态”了,10大AI神器闻所未闻!'的相关评论的情感分析饼状图"
pie = Pie(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
pie.add("", datas)
pie.set_global_opts(
title_opts=opts.TitleOpts(title=title),
legend_opts=opts.LegendOpts(pos_right="right")
)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}: {d}%"))
pie.render('AI_视频情感态度分析统计饼状图.html')
make_snapshot(snapshot, "AI_视频情感态度分析统计饼状图.html", "./picture/AI_视频情感态度分析统计饼状图.png")参考如下:

单一视频一周内各个参数数据的爬取 (折线图)
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Line
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
if __name__ == '__main__':
df = pd.read_csv("data_analysis/jl_change.csv", encoding='gbk')
df_watch = df['观看量']
df_dm = df['弹幕数']
df_dz = df['点赞数']
df_tb = df['投币数']
df_sc = df['收藏数']
df_zf = df['转发数']
df_time = df['时间']
Watch = []
Dm = []
Dz = []
Tb = []
Sc = []
Zf = []
Sj = []
for element in df_watch:
Watch.append(element)
for element in df_dm:
Dm.append(element)
for element in df_dz:
Dz.append(element)
for element in df_tb:
Tb.append(element)
for element in df_sc:
Sc.append(element)
for element in df_zf:
Zf.append(element)
for element in df_time:
Sj.append(element)
line = Line(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
line.add_xaxis(Sj)
# line.add_yaxis('播放量', Watch)
line.add_yaxis('弹幕数', Dm)
line.add_yaxis('点赞数', Dz)
line.add_yaxis('投币数', Tb)
line.add_yaxis('收藏数', Sc)
line.add_yaxis('转发数', Zf)
line.set_global_opts(
title_opts=opts.TitleOpts(title='星穹铁道镜流角色pv剑出无回各指数变化趋势折线图',pos_left="25%", pos_top="6%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45), name="时间"),
yaxis_opts=opts.AxisOpts(name="参数")
)
line.render('星穹铁道镜流角色pv剑出无回各指数变化趋势折线图.html')
make_snapshot(snapshot, '星穹铁道镜流角色pv剑出无回各指数变化趋势折线图.html', 'picture/星穹铁道镜流角色pv剑出无回各指数变化趋势折线图.png')
参考如下:

到此位置,所有的数据都经过了可视化操作,生成了5张直观的图表,整个大作业到此也就结束了!
五、全部代码(github)
GitHub - nete1108/Bilibili-data-crawler-visual-charts: b站数据爬虫+可视化图表(selenium模块+pyecharts模块)















 4158
4158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









