






OpenCV-Python 是计算机视觉领域最流行的开源库之一,它结合了 OpenCV (Open Source Computer Vision Library) 的 C++ 高性能实现和 Python 的简洁易用特性,为开发者提供了强大的图像和视频处理能力。具有以下优势:
典型应用领域:
-
图像/视频处理与分析
-
物体检测与识别
-
人脸识别与生物特征识别
-
增强现实(AR)
-
自动驾驶视觉系统
-
医学影像分析
-
工业质检
丰富的算法库:
- 图像处理:滤波、几何变换、色彩空间转换
- 特征提取:SIFT、SURF、ORB 等
- 机器学习:SVM、KNN、决策树等
- 深度学习:支持 TensorFlow、PyTorch 模型
丰富的算法库,比如:
-
人脸识别系统:
-
使用 Haar 级联或 DNN 进行人脸检测
-
LBPH 或 FaceNet 进行识别
-
-
车牌识别:
-
边缘检测定位车牌
-
OCR 识别字符
-
-
实时滤镜应用:
-
美颜滤镜
-
风格化转换
-
-
运动追踪:
-
光流法追踪
-
背景减除
-
一、 Gui Features in OpenCV
1.1加载图片:cv2.imread()
cv2.imread() 是 OpenCV 中用于从文件加载图像的核心函数,它将图像文件读取为 NumPy 数组,便于后续处理和分析。所以,在opencv-python中,图片的实际上是一个np数组。
image = cv2.imread(filename, flags=cv2.IMREAD_COLOR)
参数说明
filename (字符串):图像文件的路径(支持格式:JPEG、PNG、BMP、TIFF等)
flags (可选):读取模式标志,常用有以下几种:
cv2.IMREAD_COLOR (默认):加载3通道BGR彩色图像(忽略透明度)
cv2.IMREAD_GRAYSCALE:加载为单通道灰度图像
cv2.IMREAD_UNCHANGED:按原样加载,包括alpha通道(4通道BGRA)
cv2.IMREAD_ANYDEPTH:保留原始位深度
cv2.IMREAD_REDUCED_COLOR_2/4/8:按比例缩小尺寸加载
返回值
成功时返回 numpy.ndarray 多维数组
失败时返回 None(文件不存在/格式不支持等)demo
从路径中加载一张图片,并且从窗口中打开,最后保存到其他地方
import cv2
import sys
img = cv2.imread('/media/lee/软件/colmap_exp/instant/result/zj/images/VID_20250325_150846/0.0.png')
print(type(img),img)
if img is None:
sys.exit("Error: Could not read the image.")
cv2.imshow("display window",img)
cv2.waitKey(0)
# cv2.waitKey(0) 中的 0 表示无限等待,即程序会一直暂停,直到用户按下任意键。
# 如果传入一个正整数(例如 cv2.waitKey(1000)),则表示等待指定的毫秒数(1000 毫秒 = 1 秒),之后程序会继续执行,无论用户是否按下键。
cv2.destroyWindow("display window")
cv2.imwrite('open-cv/read_image_output.png', img)
exit()
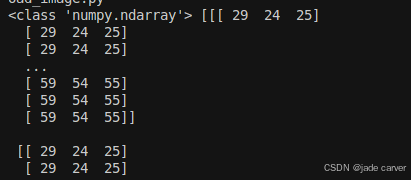
放大以后,可以看到各个像素的RGB数值:


print图片:
1.2加载视频:cv2.VideoCapture()
cv2.VideoCapture() 是 OpenCV(开源计算机视觉库)中用于从 摄像头、视频文件 或 网络流 捕获视频的函数。它是视频处理和计算机视觉应用的基础工具。
cv2.VideoCapture(source, [apiPreference])
source(输入源):
摄像头:0(默认摄像头)、1(第二个摄像头)等。
视频文件:文件路径(如 "video.mp4")。
网络/IP 摄像头:RTSP/HTTP 流地址(如 "rtsp://192.168.1.1/live")。
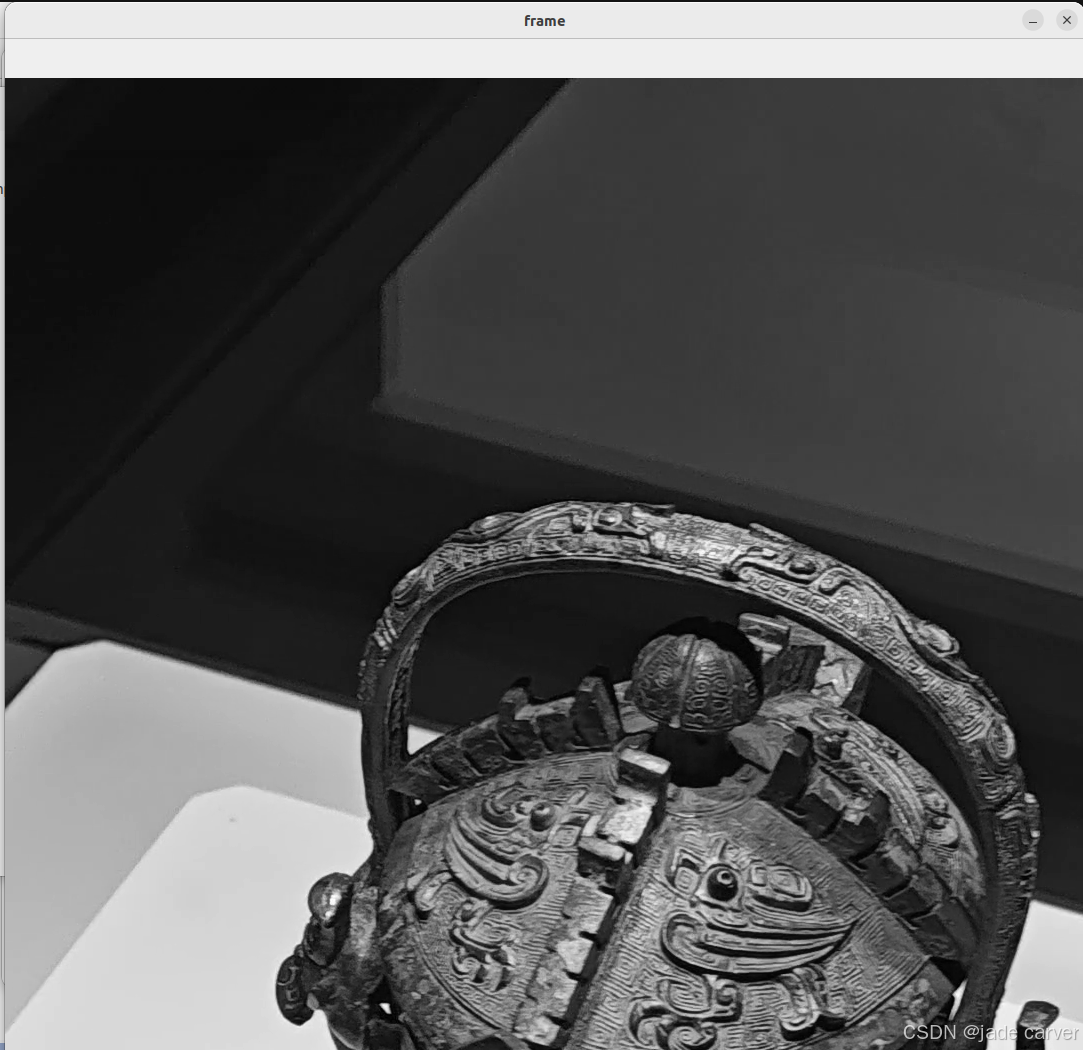
apiPreference(可选):指定视频捕获的后端(如 cv2.CAP_DSHOW 用于 Windows 摄像头)。demo1:加载本地视频,转为灰度图
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('/media/lee/软件/colmap_exp/instant/result/zj/video/VID_20250325_151144.mp4')
while cap.isOpened():
ret,frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
gray = cv.cvtColor(frame,cv.COLOR_BGR2GRAY)
cv.imshow('frame',gray)
if cv.waitKey(1) == ord('q'):
break
cap.release()#Closes video file or capturing device.
cv.destroyAllWindows()#Closes all OpenCV windows.
demo2:摄像头录像,保存
import cv2
cap = cv2.VideoCapture(0)
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 编码格式
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640, 480)) # 输出文件
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
out.write(frame) # 写入帧
cv2.imshow("录制中...", frame)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
out.release() # 释放写入器
cv2.destroyAllWindows()1.3draw different geometric shapes
包括多种形状
demo:使用直线,矩形,圆,椭圆,折线在纯黑图片上画出形状
import numpy as np
import cv2 as cv
# create a black image
img = np.zeros((512,512,3),np.int8)
# cv.imwrite('open-cv/gui_features/draw_image.png',img)
# draw a diagonal blue line with thickness of 5 px
cv.line(img,(0,0),(511,511),(255,0,0),5)
# cv2.line(img, pt1, pt2, color, thickness=1, lineType=cv2.LINE_8, shift=0)
cv.rectangle(img,(394,0),(300,129),(0,255,0),3)
# cv2.rectangle(img, pt1, pt2, color, thickness=1, lineType=cv2.LINE_8, shift=0)
cv.circle(img,(347,363),(80),(0,0,255),-1)
# cv2.circle(img, center, radius, color, thickness=1, lineType=cv2.LINE_8, shift=0)
cv.ellipse(img,(256,256),(100,50),0,0,360,(255,0,0),-1)
# cv2.ellipse(img, center, axes, angle, startAngle, endAngle, color, thickness=1, lineType=cv2.LINE_8, shift=0)
pts = np.array([[10,5],[20,30],[70,20],[50,10]],np.int32)
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
# cv2.polylines(img, pts, isClosed, color[, thickness[, lineType[, shift]]])
# isClosed:布尔值,指示多边形是否闭合
cv.imshow("Line", img)
cv.waitKey(0)
cv.destroyAllWindows()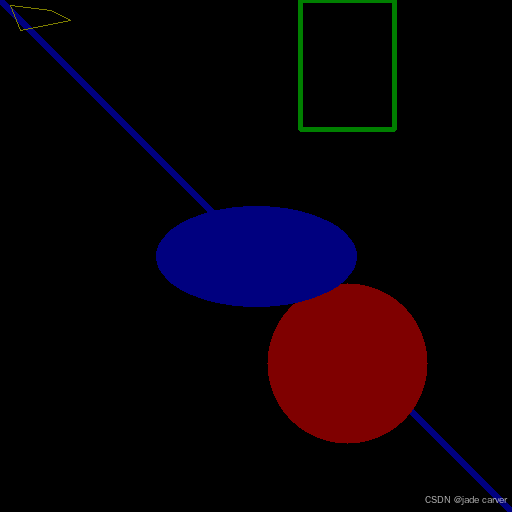
二、basic operation
2.1修改像素
图片在opencv中是一个array,所以修改图片等同于修改这个array
demo:修改像素
import cv2 as cv
import numpy as np
img = cv.imread('open-cv/core_operation/load_image_output.png')
assert img is not None, "file could not be read, check with os.path.exists()"
px = img[100,100]
print(px)
blue = img[100,100,0]
print(blue)
# modify the pixel values
modify_pixel = np.ones((800,800,3))
img[:800,:800:] = modify_pixel
# images property
print(f"image shape is {img.shape}, image size is {img.size}, and image type is {img.dtype}")
cv.imshow("modify the pixel values",img)
cv.waitKey(0)
cv.destroyWindow("modify the pixel values")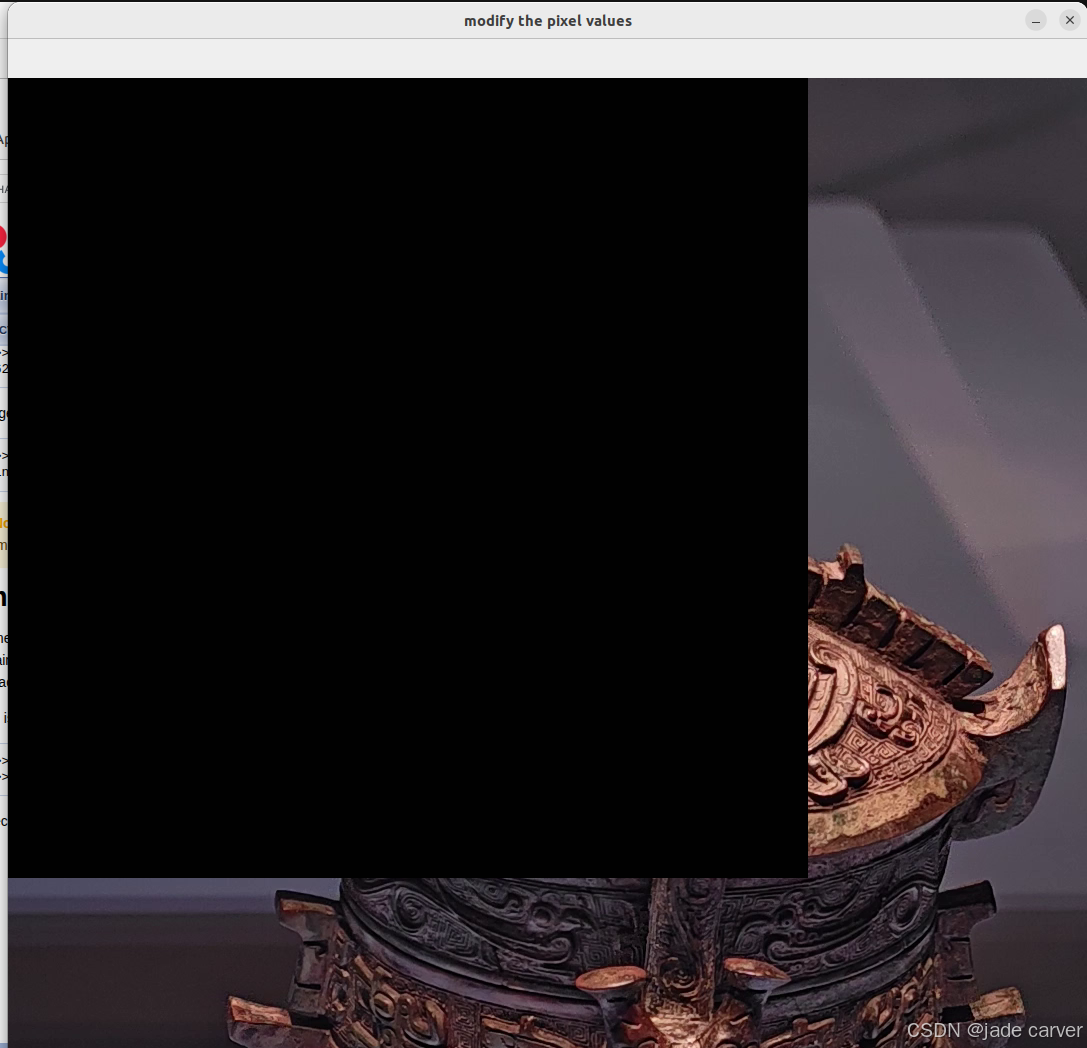
2.2ROI
ROI 技术就是只处理图像中关键的局部区域,而非整张图像,可以高效地实现局部图像处理,是计算机视觉中的基础技能!
demo:把感兴趣的区域复制到其他地方
ball = img[280:340, 330:390]
img[273:333, 100:160] = ball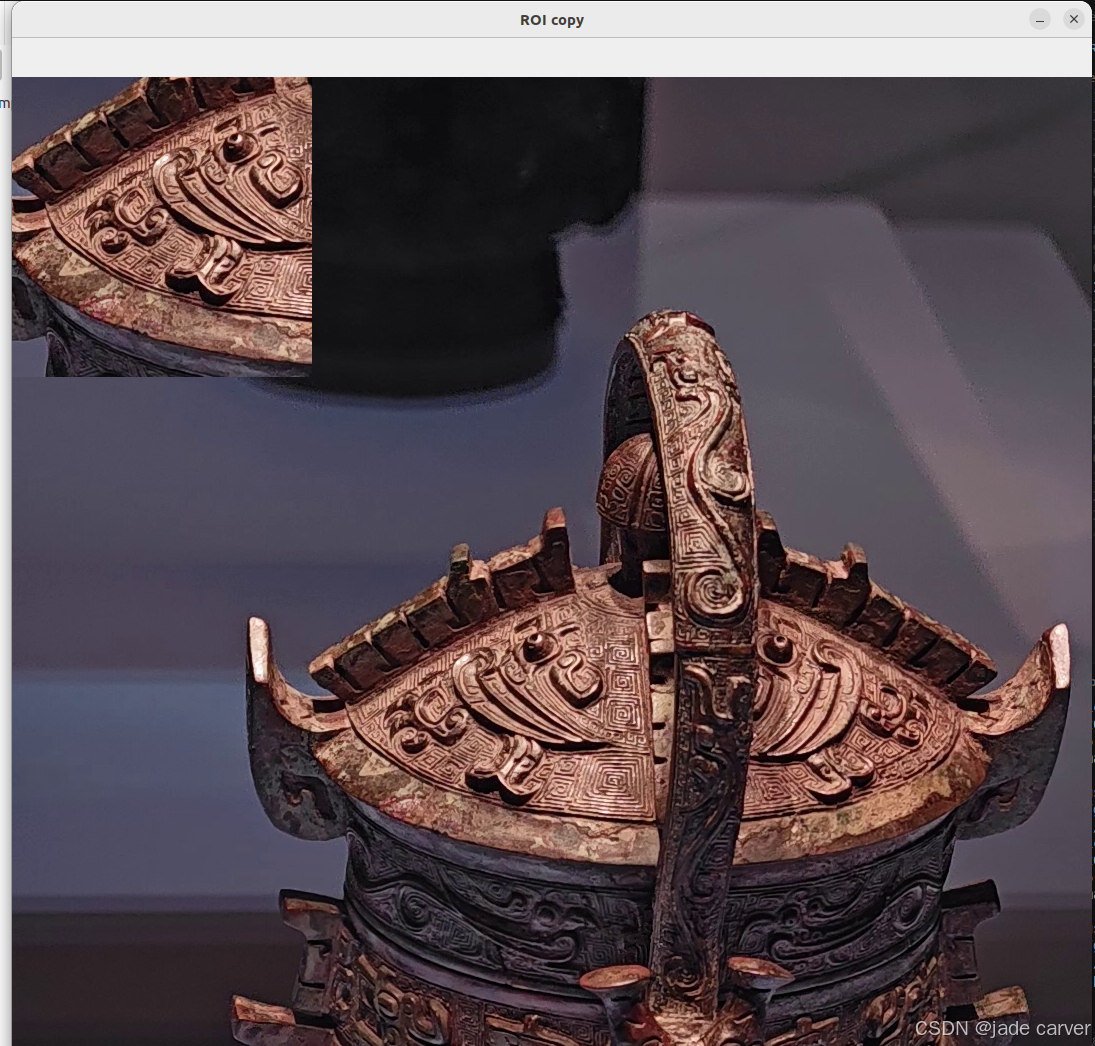
2.3分离以及合并通道:cv.split、cv.merge
有时需要分别处理图像的 B、G、R 通道。在这种情况下,要将 BGR 图像拆分为多个单独的通道。在其他情况下,可能需要合并这些单独的通道以创建 BGR 图像
demo:将图像的b通道数值减半,然后重新合成
import cv2 as cv
import numpy as np
img = cv.imread('open-cv/core_operation/load_image_output.png')
assert img is not None, "file could not be read, check with os.path.exists()"
# breakpoint()
# 使用自带的方法
b,g,r = cv.split(img)
img = cv.merge((b,g,r))
# or使用numpy,第三维是通道
b = img[:,:,0]
b = b // 2
img = cv.merge((b,g,r))
# img[:,:,2] = 0
cv.imshow("modify the channel",img)
cv.waitKey(0)
cv.destroyWindow("modify the channel")
结果:
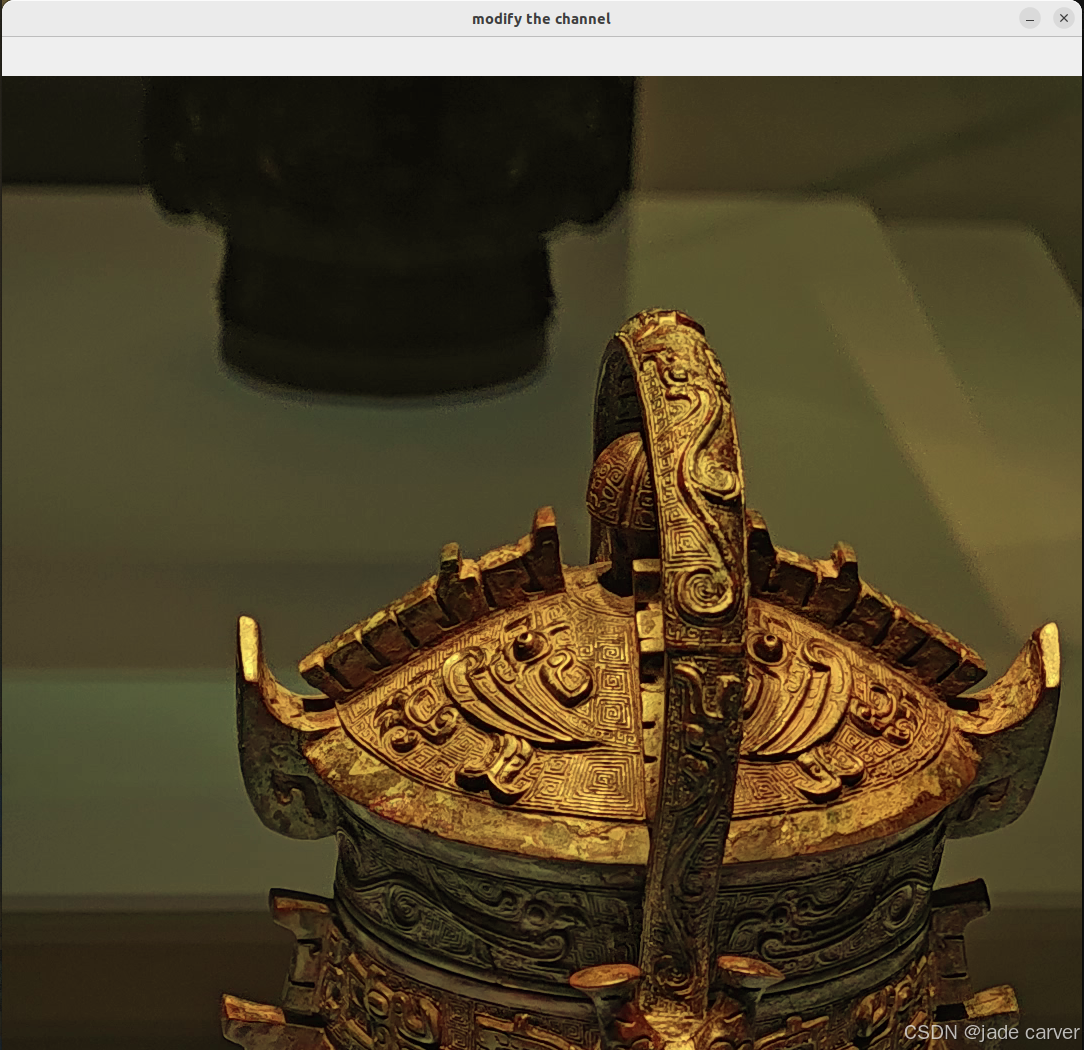
2.4扩展边界:cv2.copyMakeBorder()
cv2.copyMakeBorder() 是 OpenCV 中用于给图像添加边框(填充)的函数,常用于图像处理中的边缘扩展、卷积操作前的边界处理等场景。这个功能在做图像卷积时非常有用:
cv2.copyMakeBorder(src, top, bottom, left, right, borderType[, dst[, value]])
参数 说明
src 输入图像
top 顶部边框宽度(像素数)
bottom 底部边框宽度
left 左侧边框宽度
right 右侧边框宽度
borderType 边框类型(见下方说明)
dst 输出图像(可选)
value 当 borderType 为 BORDER_CONSTANT 时的边框颜色值
边框类型(borderType)
类型 说明
cv2.BORDER_CONSTANT 添加固定颜色的边框(需指定 value)
cv2.BORDER_REPLICATE 复制最边缘像素值:aaaaaa abcdefgh hhhhhhh
cv2.BORDER_REFLECT 镜像反射:fedcba abcdefgh hgfedcb
cv2.BORDER_REFLECT_101 镜像反射(不含边缘):gfedcb abcdefgh gfedcba
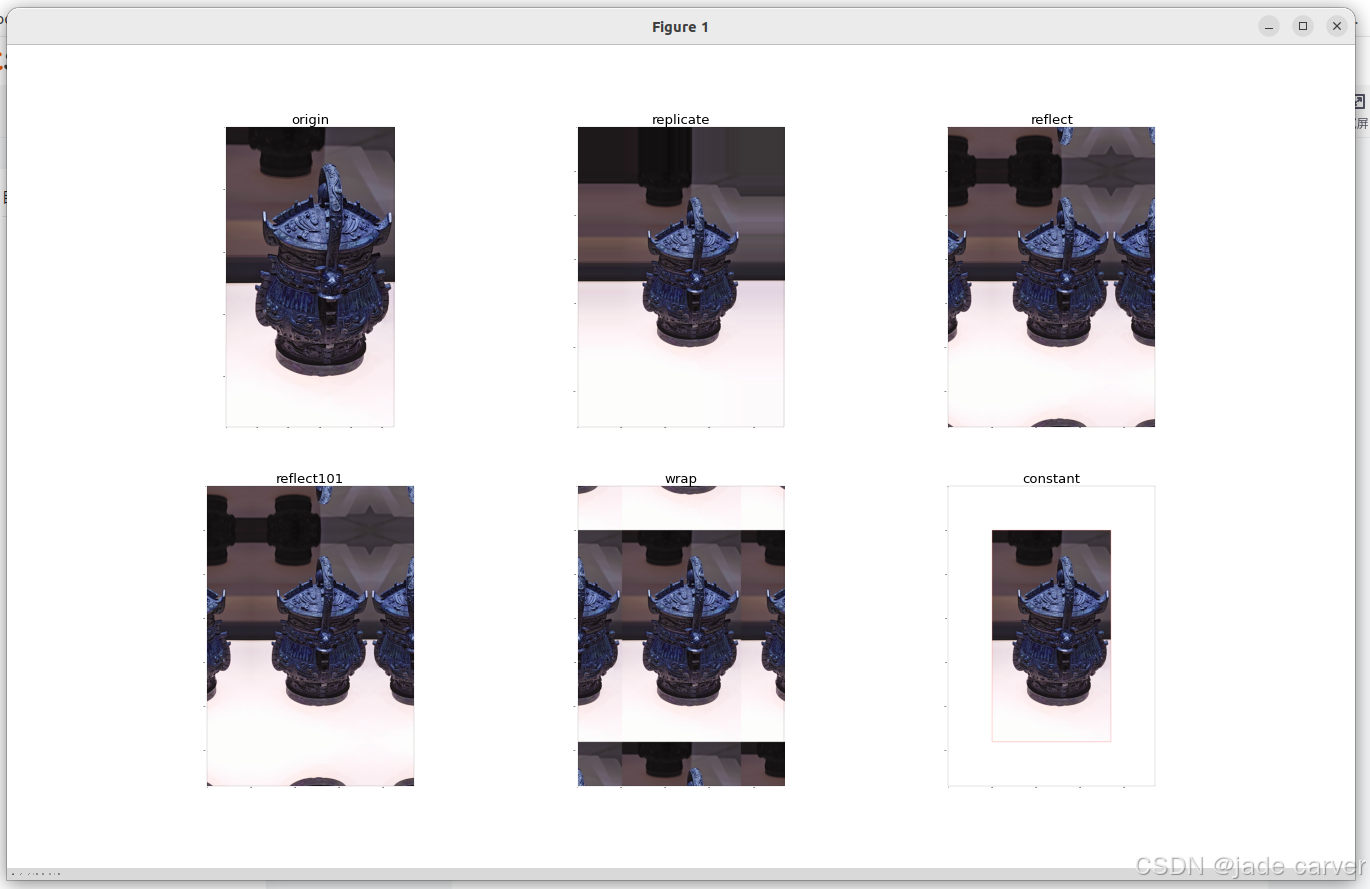
cv2.BORDER_WRAP 平铺重复:cdefgh abcdefgh abcdefgdemo:在图片中分别添加上述边缘
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('open-cv/core_operation/load_image_output.png')
assert img is not None, "file could not be read, check with os.path.exists()"
img = cv.resize(img,(540,960))
# cv.imshow("",img)
# cv.waitKey(0)
# cv.destroyWindow("")
cv.imwrite('open-cv/core_operation/image1.png',img)
img = cv.cvtColor(img,cv.COLOR_BGR2BGRA)
# 复制最边缘像素值
replicate = cv.copyMakeBorder(img,200,200,200,200,cv.BORDER_REPLICATE)
# 镜像反射
reflect = cv.copyMakeBorder(img,200,200,200,200,cv.BORDER_REFLECT)
# 镜像反射(不含边缘)
reflect101 = cv.copyMakeBorder(img,200,200,200,200,cv.BORDER_REFLECT_101)
# 平铺重复
wrap = cv.copyMakeBorder(img,200,200,200,200,cv.BORDER_WRAP)
# 添加固定颜色的边框
constant = cv.copyMakeBorder(img,200,200,200,200,cv.BORDER_CONSTANT,value=[255,0,0])
# 画图
plt.figure(figsize=(12,8))
plt.subplot(231),plt.imshow(img),plt.title('origin', fontsize=100)
plt.subplot(232),plt.imshow(replicate),plt.title('replicate', fontsize=100)
plt.subplot(233),plt.imshow(reflect),plt.title('reflect', fontsize=100)
plt.subplot(234),plt.imshow(reflect101),plt.title('reflect101', fontsize=100)
plt.subplot(235),plt.imshow(wrap),plt.title('wrap', fontsize=100)
plt.subplot(236),plt.imshow(constant),plt.title('constant', fontsize=100)
# 调整子图之间的间距
plt.subplots_adjust(
left=0.1, # 左边距
right=0.9, # 右边距
bottom=0.1, # 下边距
top=0.9, # 上边距
wspace=0.1, # 水平间距
hspace=0.2 # 垂直间距
)
plt.show()
结果:
2.5图像的blend-cv2.addWeighted()、cv.add()
cv2.add() 是 OpenCV 中用于执行图像或矩阵加法的基本函数,它可以将两幅图像或矩阵进行逐元素的加法运算。
cv2.add(src1, src2[, dst[, mask[, dtype]]])
参数 说明
src1 第一个输入数组(图像/矩阵)
src2 第二个输入数组(与src1大小和类型相同)
dst 输出数组(可选)
mask 可选的操作掩码,8位单通道数组
dtype 输出数组的可选深度cv2.addWeighted() 是 OpenCV 中用于执行图像加权融合(线性混合)的函数,它可以将两幅图像按照指定的权重进行组合,生成新的图像。这个函数在图像混合、透明度叠加、图像融合等场景中非常有用。
cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])
参数 说明
src1 第一个输入图像(矩阵)
alpha 第一个图像的权重(0-1之间的浮点数)
src2 第二个输入图像(必须与src1大小和类型相同)
beta 第二个图像的权重(0-1之间的浮点数)
gamma 标量值,添加到加权和中
dst 输出图像(可选)
dtype 输出数组的可选深度
函数执行的计算公式为:
dst = src1 × alpha + src2 × beta + gamma
gamma是一个亮度调整值,正数使图像变亮,负数使图像变暗
demo:把两张图片加起来
import cv2 as cv
import numpy as np
# img = cv.imread("open-cv/core_operation/19.58605149080521.png")
# img = cv.resize(img,(540,960))
# cv.imwrite('open-cv/core_operation/image2.png',img)
img1 = cv.imread("open-cv/core_operation/image1.png")
img2 = cv.imread("open-cv/core_operation/image2.png")
print(img1.shape,img2.shape)
x = np.uint8([255])
y = np.uint8([10])
print(cv.add(x,y),x+y)
blended_img = cv.addWeighted(img1,0.7,img2,0.3,0)
cv.imshow("cv.add", cv.add(img1,img2))
cv.imshow("blend", blended_img)
cv.waitKey(0)
cv.destroyAllWindows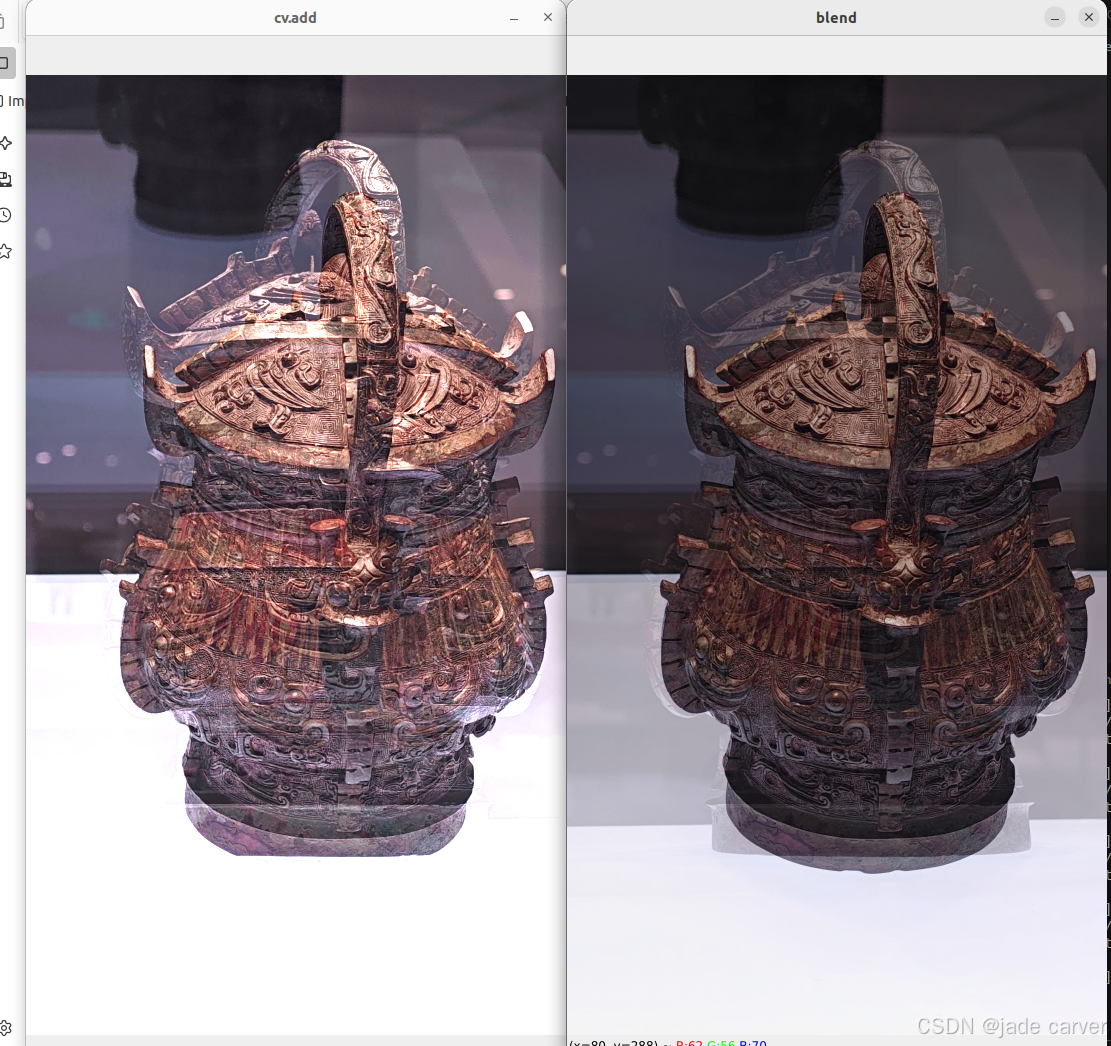
2.6mask的使用-cv.cvtCOLOR、cv.threshold、cv.bitwise
cv2.cvtColor() 是 OpenCV 中用于图像颜色空间转换的核心函数,它能够将图像从一种颜色空间转换为另一种颜色空间.
cv2.cvtColor(src, code[, dst[, dstCn]])
参数 说明
src 输入图像(8位无符号、16位无符号或单精度浮点型)
code 颜色空间转换代码(如 cv2.COLOR_BGR2GRAY)
dst 输出图像(可选)
dstCn 输出图像的通道数(0表示自动确定)cv2.threshold()是OpenCV中用于图像阈值处理的核心函数,它能将灰度图像转换为二值图像。
retval, dst = cv2.threshold(src, thresh, maxval, type)
src:输入图像(必须为8位或32位浮点型单通道图像)
thresh:阈值(0-255之间的值)
maxval:当像素值超过阈值时赋予的新值
type:阈值化类型,有以下几种:
cv2.THRESH_BINARY:二进制阈值化
cv2.THRESH_BINARY_INV:反二进制阈值化
cv2.THRESH_TRUNC:截断阈值化
cv2.THRESH_TOZERO:阈值化为0
cv2.THRESH_TOZERO_INV:反阈值化为0
cv2.THRESH_OTSU:大津算法(自动确定阈值)
cv2.THRESH_TRIANGLE:三角算法(自动确定阈值)cv2.bitwise_not() 是 OpenCV 中用于执行按位非运算的函数,它能够对图像或数组进行像素级的逻辑非操作。这个函数在图像处理中常用于二值图像的反转、掩码操作等场景。
cv2.bitwise_not(src[, dst[, mask]])
参数 说明
src 输入图像/数组(单通道或多通道)
dst 输出图像/数组(与src大小和类型相同)
mask 可选的操作掩码(8位单通道数组)cv2.bitwise_or 是 OpenCV 提供的按位或(Bitwise OR)运算函数,用于对两幅图像(或数组)进行逐像素的按位或运算。
dst = cv2.bitwise_or(src1, src2[, dst[, mask]])
参数说明
src1:第一个输入数组/图像
src2:第二个输入数组/图像
dst:输出数组/图像(可选)
mask:操作掩膜(可选),指定要处理的区域
典型应用场景
图像合并:将两幅图像的非重叠部分合并
掩膜组合:组合多个掩膜区域
特征增强:增强图像中的特定特征cv2.bitwise_and() 是 OpenCV 中用于执行按位与操作的函数,它对两个数组(通常是图像)进行逐元素的位与运算,也就是取交集。这是图像处理中用于掩膜操作、提取感兴趣区域等的基础操作。
cv2.bitwise_and(src1, src2[, dst[, mask]])
参数说明
src1: 第一个输入数组(图像)
src2: 第二个输入数组(图像)
dst: 可选输出数组(必须与输入数组大小和类型相同)
mask: 可选操作掩膜(8位单通道数组),指定要更改的输出数组元素
返回值
返回一个包含输入数组按位与结果的数组(图像)。
主要用途
图像掩膜:通过与二进制掩膜进行AND操作提取感兴趣区域
图像合成:对两幅图像进行像素级组合
特征提取:分离特定颜色通道或特征
import cv2 as cv
import numpy as np
img1 = cv.imread("open-cv/core_operation/image1.png")
img2 = cv.imread("open-cv/core_operation/19.png")
assert img1 is not None
assert img2 is not None
# 划定感兴趣区域
row,col,channel = img1.shape
roi = img1[0:row, 0:col]
# 产生msk
img1 = cv.cvtColor(img1,cv.COLOR_BGR2GRAY)
ret,mask = cv.threshold(img1,80,255,cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
# bitwise_and中使用相同的src1和src2取交集还是原来的图,然后使用mask抠图
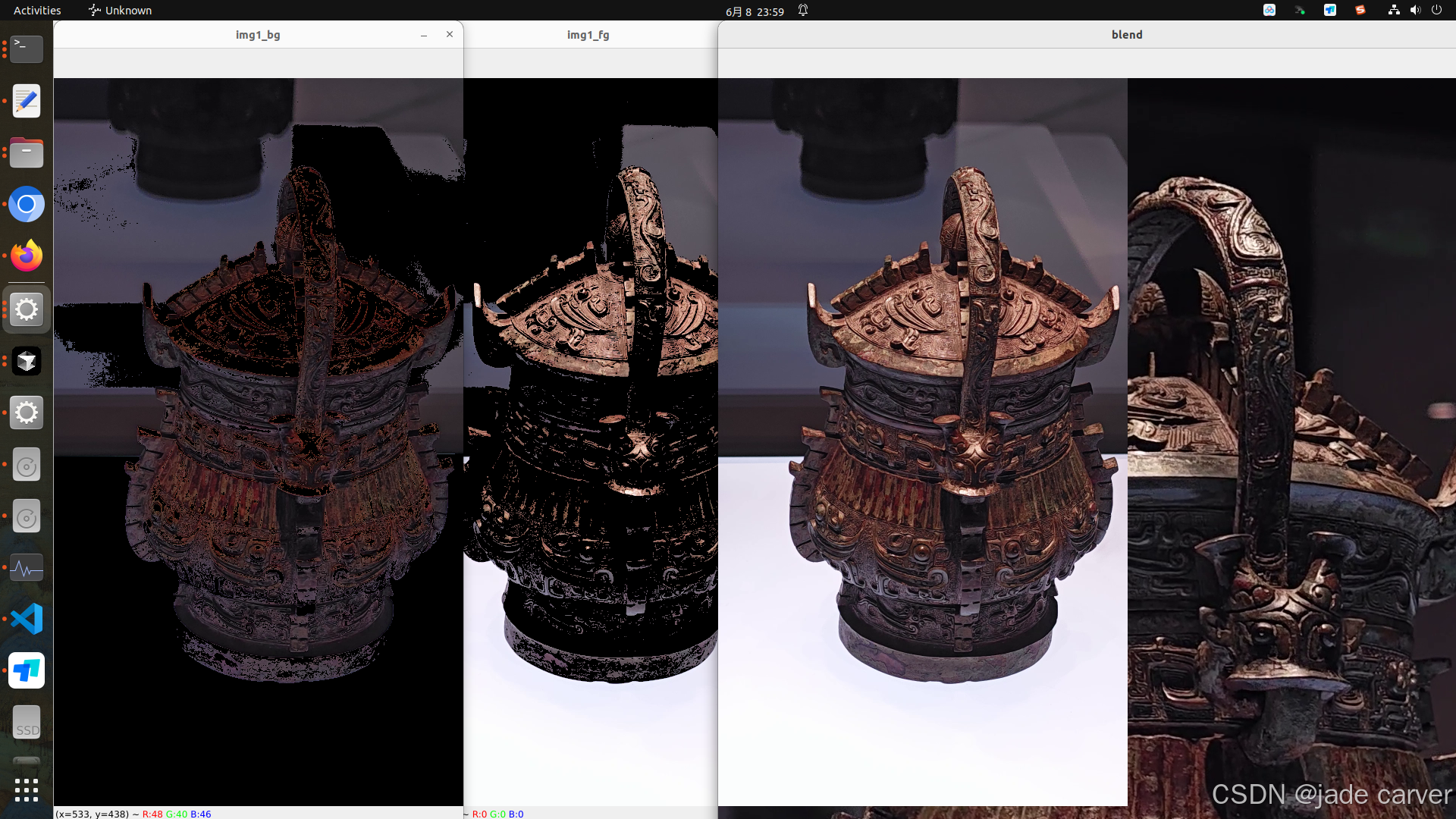
img1_bg = cv.bitwise_and(roi,roi,mask=mask_inv)
cv.imshow("img1_bg", img1_bg)
cv.waitKey(0)
cv.destroyAllWindows
img1_fg = cv.bitwise_and(roi,roi,mask=mask)
cv.imshow("img1_fg", img1_fg)
cv.waitKey(0)
cv.destroyAllWindows
dst = cv.add(img1_bg,img1_fg)
img2[0:row, 0:col] = dst
cv.imshow("blend", img2)
cv.waitKey(0)
cv.destroyAllWindows
结果分别是根据threshold得到的mask确定的img1(1k)的背景、前景,然后融合(还是img原图),加到img2(2k)里面


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









