






本文大多数是对这篇综述的翻译,为了便于查读,并且做重点的标注与记录,加深对当前3DGS相关各个领域的印象,论文的arxiv网址:
https://arxiv.org/abs/2407.17418![]() https://arxiv.org/abs/2407.17418Abstract
https://arxiv.org/abs/2407.17418Abstract
三维高斯溅射(3DGS)已经成为一个突出的技术,有可能成为一个主流的三维表示方法。它可以有效地将多视点图像通过有效的训练转换为显式的3D高斯表示,并实现实时绘制新的视图。本调查旨在从多个交叉角度分析现有的3DGS相关工作,包括相关任务,技术,挑战和机遇。主要目标是为新来者提供对该领域的快速了解,并协助研究人员有条不紊地组织现有技术和挑战。具体来说,我们深入研究了3DGS的优化、应用和扩展,并根据它们的重点或动机对其进行了分类。此外,我们总结和分类九种类型的技术模块和相应的改进,在现有的工作。基于这些分析,我们进一步研究了各种任务中的共同挑战和技术,并提出了潜在的研究机会。
1.INTRODUCTION
神经辐射场(NeRF)的出现点燃了对追求照片级真实感3D内容的相当大的兴趣。尽管最近的重大进展显着增强了NeRF的实际应用潜力,但其固有的效率挑战仍未得到解决。3D高斯溅射(3DGS)的引入决定性地解决了这一瓶颈,实现了1080p分辨率下的高质量实时(≥30 fps)新颖视图合成。这一快速发展迅速引起了研究人员的极大关注,并导致相关作品的激增。
由于3DGS的效率和可控的显式表示,其应用扩展到各个领域。这些包括增强虚拟现实(VR)和增强现实(AR)的沉浸式环境,改善机器人和自主系统的空间感知,电影和动画的先进视觉效果,以及城市规划和建筑等。
我们提供了一个全面的调查3DGS及其下游任务。这项调查系统地汇编了有关该主题的最重要和最新文献,对其重点和动机进行了详细分类和讨论。然而,我们发现,在不同的任务中,不可避免地会提到相当数量的类似技术。因此,我们进一步总结和分类3DGS的各种技术模块,如初始化,属性设置,正则化等。我们的目标是帮助读者阐明不同技术之间的联系,并增强3DGS的各种组件,以满足他们的定制任务。此外,我们还研究了3DGS中各种下游任务和技术之间的相互关系,系统地描述了四个主要挑战,以促进这一领域的未来研究。最后,我们强调了现有研究的局限性,并提出了解决核心挑战和推进这一快速发展的领域的有前途的途径。

我们的目标是系统地讨论和细粒度地分类3DGS的相关任务和技术,并分析它们之间的共性和挑战,如图1所示。这篇综述的贡献如下:
(1)讨论了3DGS及其衍生任务,包括3DGS的优化、应用和扩展。提供了基于焦点或动机的更详细的分类,使读者能够更全面地了解任务并建立研究方向。
(2)全面分析了现有文献中提出的3DGS中各种技术的增强,提供了详细的分类和深入的讨论。使读者能够辨别各种改进技术之间的共性,从而帮助他们应用到定制的任务。
(3)在分析现有工作和技术的基础上,我们确定了3DGS相关任务之间的共性和关联,并总结了核心挑战。
(4)在应对共同挑战方面,本调查阐明了潜在的机遇,并提供了富有洞察力的分析。
(5)GitHub发布https://github.com/qqqqqqy0227/awesome-3DGS.
如图2所示,本综述的结构组织如下:第2节描述了3DGS的背景和细节,强调了其相对于神经隐式场和基于点的渲染的优势。第3节重点介绍了如何优化3DGS以解决重建过程中遇到的挑战。第4节总结了3DGS的应用,并讨论了其在下游任务中的实现。第5节概述了3DGS的扩展,探讨了增强其原始功能的方法。第6节整合了用于改进3DGS模块的各种技术。第7节回顾了不同任务和技术之间的相互关系,并总结了核心挑战。最后,第8节概述了未来研究、解决现有挑战和技术优化的前景广阔的途径,第9节总结了本调查。在文章的前半部分,我们主要描述了现有的作品如何解决3DGS的下游任务,而后半部分则侧重于技术。虽然提到了一些重复的作品,但重点和内容不同。

2.PRELIMINARIES
2.1 Neural Implicit Field
神经隐式场表示在最近的研究中引起了人们的广泛关注[5],[6]。 这些方法将要重构的 2D 或 3D 信号概念化为相应欧几里得空间内的场,利用离散样本来训练近似这些场的神经网络。 这种方法有利于原始离散样本的重建、插值和外推,从而实现 2D 图像的超分辨率和 3D 场景的新颖视图合成等应用。 在 3D 重建和新颖视图合成的特定背景下,神经辐射场 (NeRF) [7] 利用神经网络将 3D 场景的几何形状和外观建模为密度场和辐射场。 NeRF 采用体积渲染来建立从 3D 场到 2D 图像的映射,从而能够从多个 2D 图像重建 3D 信号并促进新颖的视图渲染。 在该领域当前最先进的方法中,Mip-NeRF 360 [8] 因实现卓越的渲染质量而脱颖而出,而 Instant-NGP [9] 以其卓越的训练效率而闻名。
然而,神经隐式场方法很大程度上依赖于体积绘制过程来获得绘制的像素。这一过程需要沿着每条射线对数十到数百个点进行采样,并将它们输入神经网络,以产生最终的成像结果。因此,渲染单个1080p图像需要大约108次神经网络向前传递,这通常需要几秒钟的时间。尽管一些作品使用显式的、离散化的结构来存储连续的3D场,从而最小化了对神经网络的依赖并加速了对场表示[9]、[10]、[11]的查询过程,然而巨大的采样点的数量仍然会带来极高的渲染成本。 此类基于体积渲染的方法无法实现实时渲染,从而限制了它们在下游任务中的适用性。
2.2 Point-based Rendering
由于连续 3D 场不区分场景内的占用空间和未占用空间,因此体积渲染过程中的大量采样点位于未占用空间中。 这些采样点对最终渲染结果的贡献很小,导致渲染效率较低。 相比之下,离散点云表示仅记录 3D 场景中真正占据的部分,提供更高效、更精确的方式来表示场景。 基于点云的渲染依赖于光栅化而不是随机采样,允许使用现代 GPU 进行实时渲染。然而,现有的基于点云的高质量可微绘制方法通常依赖于预先构建的点云或需要密集的点云重建。这些方法在训练过程中没有进一步优化点云结构[12]、[13]、[14],导致渲染质量高度依赖于初始点云质量,并使最终图像容易出现伪影或外观不正确。
2.3 3D Gaussian Splatting
3D Gaussian Splatting[15]结合了神经隐式场和基于点的渲染方法的优点,实现了前者的高保真渲染质量,同时保持了后者的实时渲染能力,如图3所示。 ,3DGS 将点云中的点定义为具有体积密度的 3D 高斯基元。

3DGS使用的重新参数化方法有助于对高斯基元施加几何约束(例如,约束尺度向量以使高斯基元具有平坦的特征)。除了几何属性,每个高斯基元还存储一个不透明度α和一组可学习的球面调和(SH)参数,以表示依赖于视点的外观。因此,所有primitives原语的集合可以被视为只存储神经场的非空部分的离散化表示。
在渲染过程中,3DGS使用EWA Splting方法[16]将3D高斯基元投影到2D成像平面上,并使用α混合来计算最终的像素颜色。对于每个像素,这种渲染过程类似于神经领域中使用的离散形式的体积渲染,使3DGS能够构建复杂的场景外观并实现高质量的渲染。还实现了高帧速率、高分辨率的可区分渲染,使用了基于平铺的光栅化器。
在训练开始时,初始高斯基元要么从SFM提供的稀疏点云初始化,要么随机初始化。 高斯基元的初始数量可能不足以进行高质量的场景重建; 因此,3DGS 提供了一种自适应控制高斯基元的方法。 该方法通过观察视图空间中每个高斯图元位置属性的梯度来评估图元是否“重建不足”或“过度重建”。 基于此评估,该方法通过克隆或分割图元来增加高斯图元的数量,以增强场景表示能力。 此外,所有高斯基元的不透明度会定期重置为零,以减轻优化过程中伪影的出现。 这种自适应过程允许 3DGS 使用较小的初始高斯集开始优化,从而减轻以前基于点的可微分渲染方法所需的对密集点云的依赖。
3.OPTIMIZATION OF 3D GAUSSIAN SPLATTING
3.1 Efficiency-效率
效率是评估3D重建的核心指标之一。 本节我们从存储、训练、渲染效率三个角度进行描述。
3.1.1 Storage Efficiency-存储
3DGS需要数百万个不同的高斯基元来适应场景中的几何和外观,这导致了很高的存储开销:一个典型的室外场景重建通常需要几百兆到几千兆字节的显式存储空间,由于不同高斯基元的几何和外观属性可能高度相似,单独地存储每个图元的属性可能导致潜在的冗余。
因此,工作[17]、[18]、[19]主要集中在应用矢量量化[20](VQ)技术来压缩大量高斯基元。
Compact3D[18]应用VQ将不同属性压缩成四个相应的码本,并将每个高斯的索引存储在这些码本中以减少存储开销。 建立码本后,将训练梯度通过码本复制并反向传播到原始非量化高斯参数,更新量化参数和非量化参数,并在训练完成时丢弃非量化参数。 此外,Compact3D采用游程编码来进一步压缩排序后的索引值,从而提高存储效率。 同样,Niedermayr 等人的工作 [19]提出了一种敏感度感知向量量化技术来构建基于敏感度感知k均值[21]的码本,并利用DEFLATE压缩算法[22]进一步压缩训练后的码本。 训练后,它提出了一种量化感知微调策略来恢复由于 VQ 丢失的信息。
此外,一些工作[23],[24],[25]旨在制定修剪策略或压缩SH参数。
这些工作[23]、[24]同时考虑了这两个问题。LightGaus[24]提出了一种基于全局重要性分数的高斯剪枝策略和一种高次球谐参数的提取策略。同样,Lee等人的工作也是如此。[23]引入了一个可学习的掩模来减少原始高斯白噪声的数量,并引入了一个统一的基于散列网格的外观字段[9]来压缩颜色参数。
与上述工作不同,自组织高斯[25]不使用传统的非拓扑VQ码本来压缩大量高斯。 相反,它采用自组织映射的概念将高斯属性映射到相应的二维网格中。 二维网格中的拓扑关系反映了原始属性空间中的拓扑关系,允许将拓扑结构的二维数据的压缩算法应用于无序高斯基元。
此外,还有一些工作[26]、[27]专注于改进有效的高斯表示。
Scaffold-GS[26]为有效的表示设计了锚和附加属性,它们具有转换为3DGS的能力。基于这种表示,Scaffold-GS提出了一套在多分辨率体素网格上生长和剪枝锚点的策略。GES [27]引入了广义指数(GEF)混合来代替高斯表示,它能够有效地拟合任意信号,通过设计一个快速的可微光栅化和调频图像损耗loss,GES能够在保持性能的同时利用较少数量的全环基金原语。
3.1.2 Training Efficiency-训练加速
提高训练效率对于 3DGS 也很重要。 DISTWAR [28] 引入了一种先进技术,旨在加速基于光栅的可微分渲染应用程序中的原子操作, 这种纯软件实现采用现有的扭曲级原语来最大限度地减少针对 L2 的原子操作数量,从而显着提高吞吐量。
3.1.3 Rendering Efficiency-渲染效率
实时渲染是基于高斯的方法的核心优势之一。一些提高存储效率的作品可以同时提高渲染性能,例如,减少高斯基元的数量。在这里,我们讨论有助于这些进步的其他工作。
训练 3DGS 后,[29] 的工作涉及根据空间邻近性和对最终渲染 2D 图像的潜在影响。 此外,这项工作引入了专门的硬件架构来支持该技术,与 GPU 相比,实现了 10.7 倍的加速。
GSCore [30]提出了一种硬件加速单元,用于优化辐射场渲染中 3DGS 的渲染管线。在 GSCore 中实施这些技术可使移动 GPU 平均加速 15.86 倍。
3.2 Photorealism-精细化与稠密化
Photorealism也是一个值得关注的话题[31]。3DGS有望在各种场景下实现逼真的渲染。有些[32]、[33]专注于在其原始设置中进行优化。
为了减轻对 SfM 初始化的依赖,GaussianPro [32] 引入了联合 2D-3D 训练的创新范例。基于 3D 平面定义和patch匹配方法,它提出了一种渐进的高斯传播策略,该策略利用3D视图和投影关系的一致性来优化渲染的2D深度和法线贴图。在几何过滤和选择过程之后,优化后的深度图和法线图被用于稠密化和监督,最终实现精确的几何表示。
FreGS [33] 将监督过程转换到频域,并利用 2D 离散傅里叶变换的幅度和相位属性来减轻 3DGS 中的过度重建。 基于这个想法,FreGS 引入了频域引导的粗到精退火技术来消除不需要的伪影。
多尺度渲染性能的急剧下降也是一个值得关注的话题
这项工作muti-scale gs[34]首先分析了低分辨率和远距离绘制中频域混叠的原因,利用多尺度高斯来解决这个问题。然后,定义像素覆盖以反映与当前像素大小相比的高斯大小。基于这一概念,它识别小高斯,并将其聚合成较大的高斯,用于多尺度训练和选择性渲染。
MIP-Splting[35]同样从采样率的角度解决了这个问题,它引入了基于奈奎斯特定理的高斯低通滤波器,以根据所有观测样本的最大采样率来约束3D高斯频率。为了解决混叠和膨胀伪影,MIP-Splting用2D MIP滤镜取代了传统的2D膨胀滤镜。与训练阶段的修改不同,SA-GS[36]在测试期间仅通过2D比例自适应滤波器操作,使其适用于任何预先训练的3DG。
其他工作试图重建具有挑战性的场景,如反光表面[37]、[38]、[39]和重光照[40]。
GaussianShader [37] 通过采用混合颜色表示并集成镜面 GGX [41] 和法线估计模块来重建反射表面,其中包含漫反射颜色、直接镜面反射以及解释散射和间接光等现象的残余颜色分量。 此外,GaussianShader 在训练过程中引入了 3DGS 中的着色属性和法线几何一致性约束。
Mirror-3DGS [38]添加了可学习的镜像属性来确定镜像的位置,并引入了虚拟镜像视点来帮助基于原始 3DGS 重建镜像场景。 并且,SpecGaussian [39] 用各向异性球面高斯替换了原始 3DGS,以构建具有镜面和各向异性分量的场景,并引入基于锚点的表示 [26] 以提高效率。
可重新照明 3D 高斯 (R3DG) [40] 表示使用可重新照明点的 3D 场景,每个点都以法线方向、BRDF 参数和入射照明为特征,其中入射光被分解为具有与视图相关的可见性的全局和局部分量。 然后,在 R3DG 中设计了一种基于包围体层次结构的新颖的基于点的光线追踪技术,以实现高效的可见性烘焙和具有精确阴影效果的实时渲染。
DeblurGS [42] 解决了由严重模糊引起的相机姿势不准确的挑战, 通过估计每个模糊观察的 6 自由度 (6-DoF) 相机运动并合成相应的模糊渲染来优化清晰的 3D 场景。 它还引入了高斯致密退火策略以确保训练稳定性。
3.3 Generalization and Sparse Views-泛化性与稀疏视角
长期以来,稀疏视图设置下的泛化和重建挑战一直引起学术界的广泛关注。隐式表示(如NeRF)和显式表示(如3DGS)在实际应用中都面临巨大的障碍,因为需要对每个场景进行重新训练,并且对密集样本输入的需求很高。
3.3.1 Generalizable 3D Gaussian Splatting-可泛化3DGS
现有的通用 3D 重建或新颖的视图合成任务的目标是利用广泛的辅助数据集来学习与场景无关的表示。 在 NeRF [43]、[44]、[45] 的研究中,这个过程通常涉及输入少量(1-10)张具有相邻姿态的参考图像来推断目标图像。 辐射场充当媒介,有效地消除了显式场景重建的需要,并将任务转化为与场景无关的新颖视图合成问题。
相比之下,3DGS的显式表示导致了大量的工作,这些工作专注于使用参考图像直接推断出每个像素的相应高斯基元,随后这些基元被用于从目标视图渲染图像。为了实现这一目标,Splatter Image [46]等早期作品提出了一种将图像转换为高斯属性图像的新颖范式,从而预测与每个像素对应的高斯基元。 然后将该范例扩展到多个参考图像,以获得更好的渲染性能。
然而,与NeRF中的泛化工作不同,可泛化3DGS的训练难度显着增加。不可微分致密化等操作可能会对泛化训练过程产生负面影响。为了应对这些挑战,pixelSplat[47]旨在预测使用多视几何的极线变换[44]提取的特征深度的概率分布,并对该分布进行采样以替换不可微分量。
此外,基于多视图立体(MVS)的方法在场景重建和新颖视图合成方面始终取得了显着的成功,特别是通过引入成本量,增强了网络的空间理解。 与 MVSNeRF [48] 中的方法类似,MVSplat [49] 提出使用 3D 空间中的平面扫描来表示成本量,并预测稀疏参考输入中的深度,从而精确定位高斯基元的中心。 这种方法为新颖的视图合成提供了有价值的几何线索。
此外,一些研究[50]、[51]侧重于引入三平面来实现泛化能力。
工作[50]介绍了基于参考特征的点云表示解码器和三平面表示解码器。 通过并行解码,该工作建立了一种将显式点云与隐式三平面场相结合的混合表示,使高斯解码器能够在位置查询后直接预测高斯属性。 基于相似的表示,AGG [51]引入了基于伪标签的初始化方法和多阶段训练策略。 该策略包括粗略高斯生成,然后使用参考图像特征进行超分辨率,从而产生详细的输出。
3.3.2 Sparse Views Setting-利用深度信息
从稀疏输入中重建提出了重大挑战,其中3DGS的方法与NeRF的方法基本相似,旨在开发新的正则化策略并整合补充信息,如深度数据。
Chung et al. [52]建议采用单目深度估计模型来预测深度图,随后使用 SfM [53] 对其进行细化以获得精确的深度范围。 此外,他们的工作还结合了深度平滑度损失和两种针对样本有限的场景量身定制的修改技术。 在深度监督的基础上,FSGS [54]引入了一种邻近引导的高斯上采样方法来增加数量,并通过 2D 先验模型集成新的伪视图,以进一步减轻过度拟合。
随后,Touch-GS [55] 在机器人感知应用中通过触觉传感扩展了这一范式。 与单目深度信息对齐后,触觉传感数据基于隐式表面表示有效预测相应的深度和不确定性图,用于增强初始化和优化过程。
此外,DNGaussian [56]从正则化的角度探讨了该问题,提出了两种不同的正则化:硬深度和软深度,以解决场景几何的退化问题。 然后,DNGaussian 引入了全局和局部深度归一化方法,以增强对细微局部深度变化的敏感性。
一些研究主要集中在初始化和训练策略上。GaussianObject[57]介绍了一种基于Visual Hull的初始化策略,以及一种利用距离统计数据消除漂浮物的优化方法。此外,GaussianObject设计了一个高斯修复模块,该模块包括数据采集、训练和推理范式,从而利用预训练模型来解决稀疏视点条件下的遮挡和信息丢失问题。
4 APPLICATIONS OF 3D GAUSSIAN SPLATTING
3DGS因其效率和逼真的渲染而在各种应用领域表现出色,其中包括数字人体重建,人工智能生成内容(AIGC)和自动驾驶等。基于先前的探索,3DGS可以直接作为核心技术应用于不同的研究领域,有效地取代传统的3D表示。
4.1 Human Reconstruction-数字人
3DGS在数字人类相关任务中的应用,包括人类重建,动画和人类生成,已经在研究界引起了广泛的关注。最近的作品可以根据重建的部分进行分类。
4.1.1 Body Reconstruction-人体
人体重建主要是从多视角或单目视频中重建可变形的人体化身,并提供实时渲染。我们在表1中列出了近期作品的比较。大多数工作[58],[60],[61],[62],[63]更喜欢使用预先构建好的人类模型,如SMPL [66]或SMPLX [67]作为强先验知识。然而,SMPL仅限于引入关于人体本身的先验知识,因此对服装和头发等外部特征的重建和变形提出了挑战。

对于外观的重建,HUGS [60]仅在初始阶段使用SMPL和LBS,允许高斯基元偏离初始网格以准确地表示服装和头发。Animatable Gaussians [65]使用可以拟合外观的模板作为指导,并利用StyleGAN来学习姿势相关的高斯映射,增强了对详细动态外观建模的能力。GaussianAvatar [61]采用了一种捕获粗略全局外观的功能,该功能与姿势功能集成在一起。这些组合的特征然后被输入到解码器中以预测高斯基元的参数。3DGS-Avatar [63]引入了一个非刚性变换模块,该模块利用多级散列网格编码器对3D位置进行编码,并将其与潜在的姿势连接起来,以形成浅层MLP网络的输入,该网络预测高斯位置的偏移,比例和某些姿势下的旋转。
一些研究将问题空间从3D投影到2D,从而降低了复杂性,并能够利用完善的2D网络进行参数学习。
ASH [64]提出通过变形网络生成运动相关的模板网格,并从该网格预测运动相关的纹理图。然后,2D网络通过生成的纹理图预测高斯参数。类似地,Animatable Gaussians [65]将模板网格人体模型从规范空间投影到两个2D平面(正面和背面)上,学习这些空间中的高斯属性。
GPS-Gaussian [59]通过引入高斯参数映射来解决可推广的人类新视图合成,该高斯参数映射可以直接回归而无需每个受试者优化。这种方法由深度估计模块补充,该模块将2D参数图提升到3D空间。
4.1.2 Head Reconstruction-头部
在人类头部重建领域,与大多数使用SMPL作为强先验的管道一样,GaussianAvatars [68]的工作集成了FLAME [69]网格,为3DGS提供先验知识,以实现上级渲染质量。这种方法可以补偿FLAME网格无法准确描述或跟踪的细节和元素。然而,Gaussian Head Avatar [70]批评了使用FLAME网格和线性混合蒙皮(LBS)进行面部变形,指出这些相对简单的线性操作难以捕捉复杂面部表情的细微差别。相反,它建议采用MLP来直接预测高斯从中性到目标表达式的转换。这种方法有助于渲染高分辨率头部图像,实现高达2K的分辨率。
4.1.3 Others
此外,3DGS还在其他与人类相关的领域推出了创新解决方案。GaussianHair [71]专注于人类头发的重建,使用链接的圆柱形高斯建模。同时,它专门引入了GaussianHair散射模型,进一步增强了对结构的捕捉,让重建的链在不同光照条件下都能高保真渲染。
在Gaussian Shadow Casting for Neural Characters[72]中提出的研究重点是各种视角和运动下的阴影计算,首先使用NeRF从输入的人体姿势和训练图像中重建密度,法线和阴影值的体积。随后,它将NeRF输出密度图与各向异性高斯的集合拟合。高斯表示支持更高效的光线跟踪和延迟渲染技术,取代了传统的采样过程,从而加快了阴影的计算。
此外,一些研究[73],[74]已经探索了3DGS与生成模型的集成,这将在4.2节中讨论。
4.2 Artificial Intelligence-Generated Content (AIGC)
人工智能生成的内容(AIGC)利用人工智能技术自主生成内容。近来,用于基于3DGS生成3D表示的方法激增。在本章中,我们将根据提示的类型和它们生成的对象对当代算法进行系统分类。这些类别包括图像到3D对象生成、文本到3D对象生成、多对象和场景生成以及4D生成(XYZ − T),如图4所示。下面,我们将对这些类别中的每一个类别的相关工作进行概述。

4.2.1 Text to 3D Objects
目前,大量的研究致力于SDS[79],它在这一背景下起着至关重要的作用,旨在使用蒸馏范例直接生成具有多视图一致性的3D表示。为了进一步阐明DSD,我们将3D表示表示为θ,将可微渲染过程表示为g(·),从而将渲染图像表示为g(θ)。DREAMFUSION[79]确保来自每个摄像机视点的渲染图像与来自预训练扩散模型φ的可信样本保持一致。在实践中,他们利用现有扩散模型的分数估计函数ϵϕ(xt,t,y),其中ϵϕ基于噪声图像xt和文本条件y预测采样噪声。因此,θ的分数蒸馏损失的梯度为:

后来的工作广泛采用了这一点,或其改进的变体,作为对发电的主要监督。
一些工作[75]、[80]、[81]致力于改进将分数蒸馏损失应用于3DGS的框架。
DreamGaussian [75] 是一项将扩散模型与 3DGS 集成的早期工作,采用两阶段训练范例。 该方法以分数蒸馏采样 (SDS) 为基础,通过从 3DGS 中提取显式网格表示来确保生成模型的几何一致性,并细化 UV 空间中的纹理以提高渲染质量。 陈等人的工作。 同时进行的[80]引入了Point-E [82](或其他文本到点云模型)以及3D分数蒸馏损失,以指导第一阶段的3D几何生成。 在第二阶段,采用基于密度的致密化来进一步细化发电质量。 类似地,GaussianDreamer [81]采用了相同的基本概念; 然而,它的独特之处在于采用噪声点增长和颜色扰动等策略来解决初始化期间点云密度不足的问题。
然而,寻找模式的分数精馏范式经常导致生成结果的过饱和、过度平滑和缺乏细节,这在关于神经网络的相关工作中已经得到了广泛的讨论
高斯扩散[84]引入了变分高斯来缓解2D扩散模型的不稳定性,并引入了结构化噪声来增强3D一致性。
还有一些工作专注于改进 SDS。
LucidDreamer[85]解决了传统SD固有的过度平滑和采样步骤不足的挑战。通过引入确定性扩散轨迹(ddim[86])和基于区间的分数匹配机制(等式9),它实现了卓越的质量和效率。随后,Hyper-3DG[87]通过引入hypergraph[88]在LucidDreamer[85]的基础上构建,以探索拼接的高斯基元之间的关系。
同样,LODS[89]分析了训练和测试过程之间的内在不一致性,以及大的无分类器引导(CFG)在SDS中引起的过度平滑效应。为了应对这些挑战,LODS提出了一组额外的可学习的无条件嵌入和LoRA用于对齐分布。
在AIGC中,分数蒸馏损失也可以被替代:
IM-3D[91]确定了与分数蒸馏损失相关的优化困难。因此,它试图微调现有的图像到视频生成模型,以支持生成多视点空间一致的图像(视频)。这些生成的多视点图像然后被用作3DGS生成的监督。类似地,LGM[92]提出了一种从文本或单个图像生成3DG的新范例。它利用已有的网络生成目标的多视角图像,并使用基于非对称U-Net的具有cross-view self-attentions的体系结构重建不同输入下的3D模型。
作品[93],[94]的目的是只使用前馈网络来生成,而不需要特定于场景的培训。
BrightDreamer[93]的目标是将3.3.1中描述的概括性表示合并到文本到3D的生成中,从而能够直接创建3D模型,而不需要在特定场景中重新训练。BrightDreamer在固定初始化后预测位置偏移,并为提取的文本特征引入文本制导三平面生成器来预测3DGS的其他属性,从而实现任意文本到3D模型的转换。GVGEN[94]专注于一种没有三平面的前馈设置,提出了GaussianVolumes作为一种结构化的轻量级表示,用于泛化生成。基于这种表示,GVGEN通过训练好的扩散模型生成一个高斯距离场,并利用它来指导相应属性的预测。
一些工作[73]、[74]也试图将这种生成范式应用于数字人类生成等领域。
HumanGaus[74]结合了RGB和深度渲染来改进SDS,从而共同监督优化人体外观和几何形状的结构知觉,此外,它还引入了退火负提示指导和基于缩放的修剪策略来解决过饱和和浮动伪影。 除了大量依赖扩散模型的工作之外,Abdal 等人的工作。 [73] 提出了一种将 3DGS 与 Shell Maps [95] 和 3D 生成对抗网络 (GAN) 框架相结合的新颖范式。 通过利用高斯 Shell Maps,这种方法可以快速表示人体及其相应的变形。
4.2.2 Image to 3D Object
与 NeRF 的工作类似,最近的研究 [77]、[96] 也专注于从单个图像生成整个 3DGS。
按照与DreamGaussian[75]类似的过程,Repaint123[77]将这个过程分为粗略优化阶段和精细优化阶段。在粗略阶段,它使用预先训练好的Zero-123[97]作为监督,并使用SDS对粗略的3DGS进行优化。在细化阶段,Repaint123从第一阶段提取网格表示,并提出结合深度和参考图像来指导新视图图像的去噪过程,以确保不同视图之间的一致性。对于视图之间的重叠和遮挡区域,Repaint123使用可见性感知的自适应重绘方法来提高这些区域的重绘质量,然后用于微调3DGS。
FDGaussian [96]提出了一种更直接的方法,将整个生成过程分为多视图图像生成和 3DGS 重建。 在生成阶段,FDGaussian通过解耦正交平面从图像中提取3D特征,优化基于Zero-123[97]。 在重建阶段,通过基于高斯间距离的控制优化和基于高斯距离的融合策略,提高了3DGS的效率和性能。
4.2.3 Multi-Object and Scene Generation
除了单对象生成,多对象和场景生成在大多数应用场景中更为关键。
多对象生成:几项研究[78],[98]探索了多个复合对象的生成,旨在研究多个对象之间的相互作用。
CG3D [98]分别讨论了这两个方面。对于单个对象的重建,CG 3D在Alpha hull[99]上引入了K个最近邻损失,以确保预测的高斯基元均匀分布并集中在对象表面上。为了预测多个对象之间的交互,CG3D利用从文本中提取的SDS和概率图模型来预测对象之间的相对关系。最后,通过结合物体之间的重力和接触关系等先验知识,CG3D实现了具有真实物理交互的模型。
为了简化这样的问题,GALA3D[78]使用大型语言模型(LLM)生成的布局来指导多个对象重建。通过探索位置分布和根据布局优化高斯基元的形状,GALA3D生成符合指定布局的场景。此外,通过通过SDS监督单个对象和整个场景的生成,并引入布局优化模块,GALA3D获得了更逼真和文本一致的生成结果。
场景生成:与以对象为中心的生成不同,场景生成通常需要结合额外的辅助信息,例如预训练的单目深度估计模型,以实现高精度初始化。
为了实现这一目标,LucidDreamer2 [100]设计了一个两阶段生成范式。 在第一阶段,LucidDreamer2利用预先训练的文本到图像模型和单目深度估计模型来初始化点云,并引入稳定扩散修复模型[101]来完成多视图一致的场景点云。 在第二阶段,生成的点云用于初始化3DGS,并使用扩展的监督图像来确保训练过程更加顺利。 基于类似的范式,Text2Immersion [102]引入了姿势渐进生成策略以实现更稳定的训练过程,并结合放大的视点和预训练的超分辨率模型来优化生成的场景。
4.2.4 4D Generation
除了静态场景之外,一些研究[76]、[103]、[104]也开始深入研究动态3D场景。 与使用文本到图像 SDS 生成静态场景类似,很自然地认为文本到视频 SDS 可能会生成动态场景。
Align Your Gaussians (AYG) [103]明确地将问题分为两个阶段:静态3DGS重建和4DGS(动态3DGS)重建。 在静态重建阶段,AYG结合了预训练的文本引导多视图扩散模型MVDream [105]和文本到图像模型来共同监督3DGS训练。 在动态重建阶段,AYG建议使用预训练的文本到图像和文本到视频模型来监督动态3DGS训练。 此外,AYG引入了简化的分数蒸馏损失以减少训练不确定性。
在DreamGaussian[75]的基础上,DreamGaussian4D[76]将单个参考图像作为输入,并利用预先训练的图像到视频模型以及用于监督训练的多视点生成模型。
GaussianFlow[104]的目标是使用视频中的光流信息作为辅助监督来辅助4DGS的创建。类似于动态高斯工作Motion4D[106],本研究首先分析了高斯基元在3D空间中的运动与2D像素空间中的像素运动(光流)之间的关系。通过将3D高斯线的运动与光流对齐,GaussianFlow可以实现文本到4DG和图像到4DG的生成。
然而,视频生成模型的不稳定性影响了基于SDS范式的视频生成性能。
4DGen[107]通过为给定视频的每一帧引入多视图生成模型来创建伪标签,取代视频生成模型来解决这一问题。为了确保时间一致性,4DGen使用来自HexPlane[108]的多尺度中间表示来约束高斯基元随时间的平滑,从而进一步提高4DGS的生成质量。类似地,在相同的上下文和实验设置中,Fast4D[109]使用这些伪标签形成图像矩阵,并考虑时间和空间维度(即,行和列)的连续性。利用图像矩阵作为监督,Fast4D提出了一种新的时间相关的3DGS表示[110],以实现高效和高质量的生成。
此外,一些研究 [111] 重点关注现有静态 3DGS 的动画。
为了根据输入视频对现有 3DGS 进行动画处理,BAGS [111] 引入了神经骨骼和蒙皮权重来描述基于规范空间的空间变形。 使用扩散模型先验和刚体约束,可以手动操作 BAGS 以实现新颖的姿势渲染。
4.3 Autonomous Driving
在自动驾驶领域,3DGS主要应用于大规模驾驶场景的动态重建以及组合SLAM应用。
4.3.1 Autonomous Driving Scene Reconstruction-重建自动驾驶场景
重建驾驶场景是一项具有挑战性的任务,涉及大规模场景重建、动态物体重建、静态物体重建、高斯混合重建等多个技术领域。
大量的工作[112]、[113]、[114]将重建过程分为静态背景重建和动态目标重建。 DrivingGaussian[112]旨在利用多传感器数据重建自动驾驶中的大规模动态场景。 在静态背景下,DrivingGaussian 引入了不同深度箱下的增量静态 3D 高斯,以减轻远处街道场景造成的尺度混乱。对于动态对象,DrivingGaussian引入动态高斯图来构建在多个目标(其属性包括位置、局部到世界坐标变换矩阵、方向等)之间的关系,与静态背景共同重建整个自动驾驶场景。 StreetGaussians[113]采用了类似的方法,主要区别在于在背景和前景重建过程中引入了语义属性。 此外,StreetGaussians 使用傅里叶变换来有效地表示动态 3DGS 的 SH 时间变化。 基于之前的工作,HUGS [114] 结合了 Unicycle 模型以及前向速度和角速度的建模,以协助物理约束下的动态重建。 与之前的动态 3DGS 工作[106]、[115]类似,HUGS 也采用光流监督,结合渲染 RGB 损失、语义损失和 Unicycle 模型损失,从而提高动态重建精度。
此外,3DGS已被应用于多通道时空定标任务
通过利用LiDAR点云作为高斯位置的参考,3DGS-CALIB[116]构建了连续的场景表示,并在所有传感器上执行几何和光度一致性,与基于NERF的方法相比,实现了准确和健壮的校准,显著减少了训练时间。
4.3.2 Simultaneous Localization and Mapping (SLAM)
SLAM 是机器人和计算机视觉中的一个基本问题,其中设备构建未知环境的地图,同时确定自己在该环境中的位置。 SLAM的技术方法大致可以分为传统方法、涉及NeRF的技术以及与3DGS相关的方法。 其中,3DGS 方法因其提供连续表面建模、减少内存需求、改进噪声和异常值处理、增强孔洞填充和场景修复以及 3D 网格重建中灵活的分辨率的能力而脱颖而出 [117]。
一些研究[118]、[119]、[120]、[121]、[122]保留了传统的SLAM输入,并从两个角度来解决这个问题:在线跟踪和增量建图。
在早期的工作中,GS-SLAM [118]利用3DGS作为SLAM的场景表示,并引入了自适应扩展策略。 该策略涉及在训练阶段动态添加新的高斯基元,并根据捕获的深度和渲染的不透明度去除噪声基元,从而促进运动期间的连续场景重建。 对于相机跟踪,GS-SLAM 提出了一种先进的从粗到精的优化策略。 最初,渲染一组稀疏像素以优化跟踪损失并获得相机姿势的初始粗略估计。 随后,基于这些粗略的相机位姿和深度观测,在3D空间中选择可靠的高斯基元来指导GS-SLAM在具有明确定义的几何结构的重新渲染区域中,从而进一步细化粗略的相机位姿。 使用重新渲染损失来监督整个过程。
Photo-SLAM [119] 引入了一种新颖的 SLAM 框架,其特点是超基元地图,它结合了 ORB 特征 [123] 和高斯属性。 基于这种表示,该框架利用 LevenbergMarquardt (LM) 算法 [124] 来优化投影关系的定位和几何图。 基于这些结果,Photo-SLAM 提出了基于几何的致密化策略和基于高斯金字塔的学习机制来构建照片级真实感映射。 最后,该框架集成了闭环[123]以进一步纠正相机姿势并提高映射质量。
Gaussian-SLAM [121]通过将地图划分为多个子图,每个子图单独重建来解决映射挑战,从而减轻灾难性遗忘。 对于相机跟踪,作者观察到跟踪精度受到 3DGS 的外推能力的限制,并建议结合 DROID-SLAM [125] 的轨迹辅助来增强重建。
工作Gaussian splatting slam[126]分析推导了有关相机位姿的雅可比矩阵,提出了一种有效的相机位姿优化策略。 在映射阶段,作者估计帧到帧的共同可见性,并设计一种关键帧选择和管理机制,优先考虑具有低共同可见性的帧作为关键帧。 这保证了同一区域内非冗余关键帧的有效利用,从而提高映射效率。
基于之前的工作,RGBD GS-ICP SLAM [127]将广义迭代最近点(G-ICP)[128]算法集成到建图和跟踪中。 通过共享 G-ICP 和 3DGS 之间的协方差以及采用尺度对齐技术,这项工作最大限度地减少了冗余计算并促进快速收敛。
同样,Sun 等人的工作。 [129]还提出了一种由孔洞和渲染误差引导的致密化策略,以绘制未观察区域并细化重新观察区域。 此外,作者设计了一个新的正则化项来缓解灾难性遗忘的问题。
语义很重要,因为它们不仅提供场景理解,而且稳定训练过程。
SGS-SLAM[122]采用多通道几何、外观和语义特征进行渲染和优化,并提出基于几何和语义约束的关键帧选择策略,以提高性能和效率。 此外,由于语义表示的构建,SGS-SLAM能够编辑3DGS,其对应于语义一致的区域。 基于此,SEMGAUSS-SLAM [130]设计了特征级的鲁棒性监督,并引入了基于特征的捆绑调整来减轻跟踪过程中的累积漂移。 后续工作 NEDS-SLAM [131] 也采用了这一概念,引入语义特征辅助 SLAM 优化,并结合 DepthAnything [132] 来学习具有 3D 空间感知的丰富语义特征。 此外,NEDS-SLAM 提出了一种基于虚拟多视图一致性检查的新颖剪枝方法,以识别和消除异常值。
此外,还有一些工作集中在相关问题上,如本地化[133]和导航[134]。
3DGS-ReLoc[133]引入了激光雷达数据初始化,以协助3DGS映射。在此基础上,提出将3DGS子图划分为二维体素图,并利用KD-树进行高效的空间查询,从而减轻了过多的GPU内存消耗。最后,3DGS-ReLoc使用基于特征的匹配和透视n点(PNP)方法迭代地细化查询图像的姿势,实现在全局地图中的精确定位。
在室内导航的背景下,GaussNav [134] 专注于实例图像导航(IIN)任务。 基于重建的 3DGS 地图,GaussNav 提出了一种图像目标导航算法,通过分类、匹配和路径规划取得了令人印象深刻的性能。
5. EXTENSIONS OF 3D GAUSSIAN SPLATTING
作为3D表示的基本技术,3DGS可以进一步扩展以获得更多功能,包括动态3DGS[图5(A)]、来自3DGS的表面表示[图5(C)]、可编辑的3DGS[图5(B)]、具有语义理解的3DGS[图5(D)]以及基于3DGS的物理模拟[图5(E)]。

5.1 Dynamic 3D Gaussian Splatting
动态3DGS的研究近年来引起了研究者的极大关注。动态场景重建突破了静态场景重建的局限,可有效应用于人体运动捕捉、自动驾驶模拟等领域。与静态3DGS不同,动态3DGS不仅必须考虑空间维度的一致性,还必须考虑时间维度的一致性,以确保随时间的连续性和平稳性。这里,我们根据重建输入的不同将其分为多视点视频和单目视频。
5.1.1 Multi-viewVideos-多视视频
一些作品[135]、[140]尝试直接逐帧构建动态3DGS。
早期的工作 [135] 通过允许高斯随时间移动和旋转,同时保持颜色、不透明度和大小等持久属性,将 3DGS 从静态场景扩展到动态场景。 重建是在时间上在线执行的,其中每个时间步长都使用前一个时间步长的表示进行初始化。 第一个时间步长充当优化所有属性的初始化,然后将其固定用于后续时间步长(定义运动的属性除外)。 物理先验,包括局部刚性、局部旋转相似性和长期局部等距,规范了高斯的运动和旋转,如公式 5-7 所示。 作者还讨论了相似背景信息和多视点相机差异等因素对重建性能的影响。

类似地,3DGStream [140]设计了一个用于变换预测的两阶段训练过程。 在第一阶段,它引入神经变换缓存和I-NGP [9]来重建动态3DGS。 在第二阶段,3DGStream提出了自适应致密化策略,通过计算梯度来初始化新的高斯位置。
其他工作[141]、[142]旨在通过预测变形来实现这种性能。
SWAGS [141]引入了基于窗口的4DGS,将视频采样到多个窗口中以实现长期场景重建。 为了保证每个窗口内的变形程度尽可能相似,引入了基于平均流的自适应窗口划分方法。 然后使用动态 MLP 来指导优化以关注动态区域。 基于多个采样窗口的预测,SWAGS 提出利用相邻窗口重叠帧的一致性来设计一种自监督损失,对整个场景进行微调,从而消除窗口划分带来的时间不连续性。
5.1.2 Monocular Video-单目视频
5.2 Surface Representation-表面重建
尽管3DGS可以实现高度真实的渲染,但提取表面表示仍然具有挑战性。在优化过程之后,所得到的表示通常缺乏有序结构,并且与实际表面不对应。但是,基于mesh的表示仍然是许多工作流的首选,因为它们允许使用强大的工具进行编辑、雕刻、动画和重新照明。
在曲面重构中,符号距离函数(SDF)是一个不可或缺的主题。
NeuSG [153]尝试联合优化NeuS [154]和3DGS,并引入多个正则化项,包括尺度正则化、正态正则化和Eikonal正则化[155],以确保3DGS尽可能平坦并沿着目标表面分布。SuGaR [156]利用3DGS表面特性设计理想化SDF。这个理想化的表示然后用于约束实际预测的SDF及其法线,从而鼓励优化的高斯更紧密地与对象的表面对齐。然后,使用泊松重建,SuGaR从对齐的3DGS中提取网格,这比Marching Cubes算法更快,更具可扩展性[157]。此外,可选的细化步骤将新的高斯模型绑定到网格并联合优化它们,从而实现高质量的渲染和表面。
然后,3DGSR [158]旨在通过设计可微SDF到不透明度转换函数将神经隐式SDF与3DGS集成,从而优化3DGS以更新SDF。为了解决优化连续SDF与离散3DGS的挑战,3DGSR建议强制执行的深度(法线)之间的一致性从体积渲染和推断从3DGS。GSDF [159]类似地引入了一致性约束,并采用了基于Scaffold-GS [26]和NeuS [154]的结合3DGS和神经隐式SDF的双流网络。为了提高SDF的采样效率,GSDF利用3DGS分支的深度图来指导光线采样过程,并改善高斯基元在曲面上的分布,设计了一种基于SDF分支的3DGS几何感知高斯密度控制。
其他研究[137],[160],[161]旨在通过增强3DGS的内在属性来解决这个问题。
这项工作High-quality surface reconstruction using gaussian surfels[160]介绍了一种称为高斯曲面的新表示,它具有增强的曲面重建能力。在此基础上,提出了一种深度法线一致性损失来解决梯度消失问题,并提出了一种体积切割策略来修剪深度误差和不连续区域中不必要的体素。最后,本文应用筛选泊松重建技术生成曲面网格。
高斯不透明度场(GOF)[161]是基于3DGS开发的,其中3DGS沿射线沿着归一化以形成用于体绘制的1DGS。GOF还包括深度失真和法向一致性损失,便于从四面体网格中提取表面网格。
类似地,2D高斯溅射[137](2DGS)用平面圆盘代替3DGS来表示表面,这些表面在局部切平面内定义。在渲染过程中,2DGS放弃了直接仿射变换,并使用三个非平行平面来定义光线-splat交叉点,然后在应用低通滤波器后进行光栅化。
5.3 Editable 3D Gaussian Splatting-编辑
3DGS以其实时绘制、复杂场景表示和显式表示的优势,自然引起了3DGS编辑研究者的极大关注。不幸的是,当前可编辑的3DGS作品往往缺乏精确的监督,这对编辑来说是一个很大的挑战。在本节中,我们根据不同的任务对现有的作品进行分类。
5.3.1 Manipulation byText-文本操作
为了应对这一挑战,现有的工程可以分为两个不同的类别。第一种类型引入了蒸馏损失分数,如公式3所示。与AIGC 4.2不同,这些方法需要编辑提示作为指导编辑过程的附加条件。
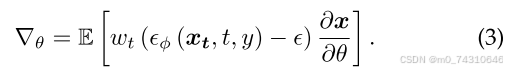
基于SDS,GaussianEditor [162]将语义控制引入3DGS编辑,实现基于语义的跟踪和编辑区域的自动掩蔽。更重要的是,这项工作提出了一个层次化的3DGS和多代锚丢失,这稳定了编辑过程,减轻了SDS的随机性的影响。此外,GaussianEditor引入了2D修复技术,为对象删除和合并的任务提供指导。继Dreamgaussian [75]之后,GSEdit [163]使用预训练的Instruct-Pix 2 Pix [164]模型而不是图像生成模型来计算3DGS编辑的分数蒸馏损失。
第二种类型侧重于在重建 3DGS 之前顺序编辑多视图 2D 图像。
GaussianEditor2 [165]利用多模态模型、大型语言模型和分割模型来根据给定的文本描述预测可编辑区域。 然后,它根据 2D 编辑模型编辑的图像优化目标区域内的相关高斯基元。
然而,这样的范式引入了一个直观的问题:
如何确保多视图编辑的一致性。 GaussCtrl [166]引入了一种深度引导的图像编辑网络ControlNet [167],利用其感知几何形状并在编辑网络中保持多视图一致性的能力。 它还在注意力层中引入了潜在代码对齐策略,确保编辑后的多视图图像与参考图像保持一致。
工作View-consistent 3d editing with gaussian splatting[136]旨在引入逆向渲染和3D潜在空间渲染以保持注意力图的一致性。 此外,还引入了编辑一致性模块和迭代优化策略,进一步增强了多视图一致性和编辑能力。
与 3DGS 的编辑方法不同,最近的讨论越来越集中在 4DGS 的编辑上。
最近的工作 Control4D [168] 通过引入 4D GaussianPlanes 深入研究了该领域,它在结构上分解 4D 空间,以确保与 Tensor4d 一样在空间和时间维度上的一致性。 基于GaussianPlanes,它设计了一个使用超分辨率生成对抗网络的4D生成器[169],它从扩散模型生成的编辑图像中学习GaussianPlanes上的生成空间,并采用多阶段渐进引导机制来增强局部 -全球品质。
5.3.2 Manipulation by Other Conditions-其他条件控制
除了文本控制编辑外,现有作品还探索了各种条件下的3DGS编辑方法。TIP-Editor[170]需要提供编辑文本、参考图像和编辑位置以精细地控制3DGS。核心技术包括用于分别学习现有场景和新内容的渐进式2D个性化策略,以及用于精确外观的粗略-精细编辑策略。该方法允许用户执行各种编辑任务,例如对象插入和样式化。
Point‘n Move[171]要求用户为要编辑的对象提供注释点。它通过两个阶段的分割、修复和重组步骤来实现对象的受控编辑(包括修复移除区域)。
5.3.3 Stylization-风格
在 3DGS 风格迁移领域,Gaussian splatting in style[172] 已经进行了早期探索。 与传统的风格迁移作品Stylizednerf[173]类似,该作品在渲染图像上设计了一个 2D 风格化模块,在 3DGS 上设计了一个 3D 颜色模块。 通过对齐两个模块的风格化 2D 结果,该方法在不改变几何形状的情况下实现了多视图一致的 3DGS 风格化。
5.3.4 Animation-动画
如5.1中所述,某些动态3DGS作品(如SCGS[150])可以通过设置稀疏控制点的动画来实现动画效果。与AIGC相关的作品,如BAG[111],旨在利用视频输入和生成模型来使现有的3DG具有动画效果。在人类重建的背景下也提到了类似的研究。此外,Cogs[174]还讨论了如何控制该动画。基于动态表示[135]、[143],它使用小的MLP来提取相关的控制信号并对齐每个高斯基元的变形。然后,COGS为要编辑的区域生成3D掩码,以减少不必要的伪影。
5.4 Semantic Understanding-语义理解
赋予3DGS语义理解能力,可以将2D语义模型扩展到3D空间,从而增强模型在3D环境中的理解能力。这可以应用于各种任务,例如3D检测、分割和编辑。
许多工作试图利用预先训练的2D语义感知模型来对语义属性进行额外的监督。
早期的工作,Feature 3DGS [175],提炼了预先训练的 2D 基础模型来联合构建 3DGS 和特征字段。 通过引入并行特征光栅化策略和正则化,它赋予 3DGS 空间理解的能力,并为下游任务设计即时显式场景表示。
随后,Gaussian Grouping[176]引入了高斯群的概念,并扩展了身份编码属性来实现它。 这项工作提出将多视图数据视为具有逐渐变化的视图的视频序列,并利用预训练的对象跟踪模型[177]来确保从SAM(Segment Anything)[178]获得的分割标签的多视图一致性。 此外,高斯群在 2D 和 3D 空间中受到监督,并直接应用于编辑。 类似地,工作2d-guided 3d gaussian segmentation[179]通过引入 KNN 聚类和高斯滤波来解决语义不准确问题,这可以约束附近的高斯并消除远处的高斯。
CoSSegGaussians [180]利用预训练的点云分割模型与双流特征融合模块。该模块将来自2D编码器的未投影2D特征与来自3D编码器的3D特征进行整合,遵循高斯位置的预测[15]。通过使用解码器和语义监督,CoSSegGaussians有效地为高斯基元注入语义信息。
其他人[138],[181],[182]专注于将文本视觉对齐功能用于开放世界的理解。
一个重要的挑战是CLIP特征的高维性,与原始高斯属性相比,这使得直接训练和存储变得困难。工作Language embedded 3d gaussians for open-vocabulary scene understanding[138]通过从CLIP [183]和DINO [184]中提取和离散化密集特征,将相应的连续语义向量引入到3DGS中,这些特征用于通过VQ-VAE [185]中的MLP预测离散特征空间中的语义索引m。它还提出了一个不确定性属性来描述高斯基元的不稳定性和频繁变化,并设计了一个自适应的空间平滑损失,故意降低嵌入的紧凑语义特征的空间频率。
LangSplat [181]使用经过训练的自动编码器压缩场景特定的CLIP特征,以减少训练内存需求。为了实现这一目标,LangSplat引入了分层语义-使用SAM构建的子部分,部分和整体[178],它解决了多个语义级别的点歧义,并促进了响应任意文本查询的场景理解。随后,FMGS [182]通过引入多分辨率哈希编码器[9]来缓解大CLIP特征尺寸的问题。
5.5 Physics Simulation-物理模拟
最近的努力旨在将3DGS扩展到模拟任务。基于“所见即所模拟”的理念,PhysGaussian [139]将静态3DGS重建为待模拟场景的离散化,然后将连续介质力学理论沿着材料点方法(MPM)[186]求解器结合起来,赋予3DGS物理属性。为了稳定基于旋转的变化外观并将粒子填充到空隙内部区域中,PhysGaussian提出了一种渐进的方向和内部填充策略。
6 TECHNICAL CLASSIFICATION
3DGS通常可以分为以下阶段,如图3所示:初始化,属性优化,溅射,正则化,训练策略,自适应控制和后处理。此外,一些并行工程旨在纳入补充信息和表示,从而提高3DGS的能力。这些技术改进不仅增强了原始3DGS的渲染性能,还解决了衍生作品中的特定任务。因此,本节深入研究了3DGS的技术进步,旨在为相关领域的研究人员提供有价值的见解。

6.1 Initialization-GS的初始化
正确的初始化已被证明是至关重要的,因为它直接影响优化过程[187]。3DGS的初始化通常使用从运动恢复结构(SfM)或通过随机生成导出的稀疏点来执行。然而,这些方法往往不可靠,尤其是在弱监督信号下,如稀疏视图设置和生成性任务。
组合预先训练的模型是一种可选的方法。
在有限数量的3D样本上预训练3D模型并将其用作初始化先验是一种可行的策略Agg[51]。该方法可以在一定程度上提高初始化的性能,尽管其有效性取决于所使用的数据。为了解决该限制,还引入了预训练的3D生成模型Text-to-3d using gaussian splatting[80]、Gaussiandreamer[81]、Hyper-3dg[87]或单目深度估计模型Luciddreamer[100]、Text2immersion[102]用于初始化目的。此外,一些工作[80]提出引入新的扰动点,以实现更全面的几何表示。
改进初始化策略也很重要。
基于对SfM在捕获频谱内的低频信号中的作用的分析,Relaxing accurate initialization constraint for 3d gaussian splatting[187]设计了稀疏大方差(SLV)初始化,以有效地集中在由SfM识别的低频分布上。
利用其它表示法也可以增强初始化能力。
通过从粗略参数点模型确定局部体积,在每个体积内初始化少量高斯,从而避免关于目标的过度假设[188]。随后,提出了一种基于视觉锥体的初始化策略,能够从四个图像中获取结构先验[57]。
讨论:精确初始化有可能通过提高性能和确保稳定的训练过程来使 3DGS 的各种衍生工作受益。
6.2 Attribute Expansion-GS属性的扩展
3DGS 的原始属性包括位置、比例、旋转、球谐 (SH) 系数和不透明度值。 一些作品扩展了这些属性,使它们更适合下游任务。 它可以分为现有属性的改进或新属性的引入,如图6所示。
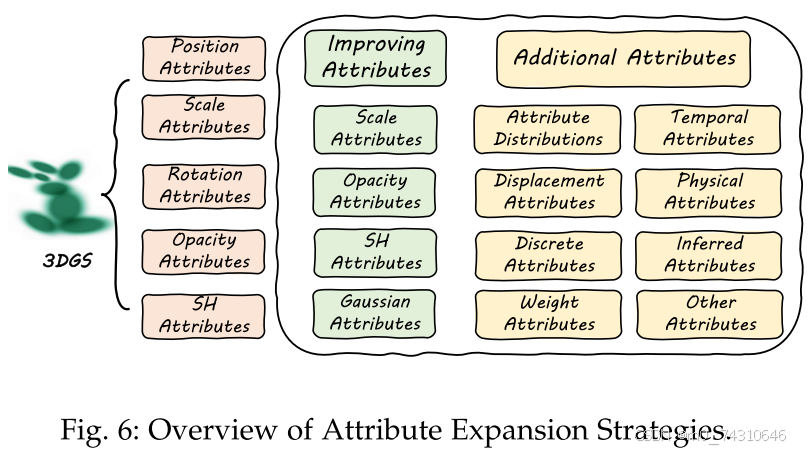
6.2.1 Improving Attributes-优化提升GS属性
高斯的某些属性可以定制,从而使3DGS适用于更广泛的任务。
scale:通过将 z 方向折叠为0并在深度、法线或壳图上加入额外的监督,作品 Gaussianpro[32]、Gaussian shell maps for efficient 3d human generation[73]、2d gaussian splatting[137]、Sugar[156]、High-quality surface reconstruction using gaussian surfels[160] 旨在提高 高斯基元,使它们更平坦,更适合表面重建,从而减少高斯几何重建中的不准确性。z 方向可以近似为法线方向。类似地,尺度约束限制了长轴长度与短轴长度之比3dgscalib [116],Gaussian splatting slam [126],Physgaussian [139],可确保高斯基元保持球形,以缓解由过于紧的内核引起的意外毛绒伪影问题。
SH:通过结合哈希网格和MLP,对相应的颜色属性进行编码,有效解决了SH参数过多导致的存储问题Compact 3d gaussian representation for radiance field[23]。
opacity:通过将透明度限制在接近 0 或 1,从而最大限度地减少半透明高斯基元的数量,作品 Gaussianshader[37]、Sugar[156] 实现了更清晰的高斯表面,有效地缓解了伪影。
Gaussian:通过引入形状参数,试图用广义指数(GEF)混合替换原始高斯Ges: Generalized exponential splatting for efficient radiance field rendering[27]。传统的3DGS可以看作是广义指数族(GEF)混合(β = 2)的特例,增强了高斯的表示效率,
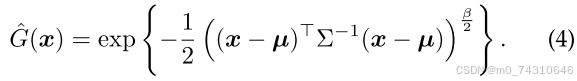
6.2.2 Additional Attributes-其他的属性
通过添加新的属性和监督,可以增强 3DGS 的原始表示功能。
语义属性:通过引入语义属性和相应的监督,赋予Street gaussians for modeling dynamic urban scenes[113]、Hugs: Holistic urban 3d scene understanding via gaussian splatting[114]、Sgs-slam: Semantic gaussian splatting for neural dense slam[122]、Semgaussslam: Dense semantic gaussian splatting slam[130]、Neds-slam: A novel neural explicit dense semantic slam framework using 3d gaussian splatting[131]、Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields[175]等作品增强的空间语义感知能力,这对于SLAM和编辑等任务至关重要。在用于语义属性的展开过程之后,使用2D语义分割图对3DGS的语义属性进行监督。此外,改进语义信息提取方法Point’n move: Interactive scene object manipulation on gaussian splatting radiance fields[171]和引入高维语义文本特征,如CLIP和DINO特征Language embedded 3d gaussians for open-vocabulary scene understanding[138]、Langsplat: 3d language gaussian splatting[181]、Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding[182],已被用于处理更广泛的下游任务。与语义属性类似,身份编码属性可以将属于同一实例或同一事物的3DGS分组,这对于多目标场景更有效Gaussian grouping[176]。
属性的分布:Gaussiandiffusion[84]使用重新参数化技术而不是固定值来学习分布式属性是防止3DGS中的局部极小并减少其对3DGS自适应控制的依赖的有效方法pixelsplat[47]。除了这些专注于位置属性分布预测的工作外,尺度属性的分布也被纳入Gaussiandiffusion[84]。通过对预测的属性分布进行采样,可以得到用于溅射的高斯基元。
时间属性:用时态属性替换原始静态属性是设置3DGS动画的关键Fast dynamic 3d object generation from a single-view video[109]、Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting[110]、Street gaussians for modeling dynamic urban scenes[113]、4d gaussian splatting: Towards efficient novel view synthesis for dynamic scenes[152]。对于包括旋转、比例和位置的4D属性,现有作品通过在特定时间点获取时间切片[152]或者将t维与4D属性[109]、[110]分离来在时间步长t上呈现3DGS。此外,4D SH的引入对于时变的颜色属性至关重要。为此,在现有的工作中,通常使用傅里叶级数作为所采用的基函数,以赋予SH时间能力[110],[113]。注意,由于涉及不同的时间步长,此类属性通常需要基于视频的训练。
位移属性:位移属性是必不可少的,因为它们描述了高斯基元的最终位置和初始位置之间的关系。这些属性可以根据它们对时间的依赖性进行分类。与时间无关的置换属性通常用于校正粗略位置属性,该属性可以与其他属性相同的方式直接优化Splatter image: Ultra-fast single-view 3d reconstruction[46]、3dgsavatar: Animatable avatars via deformable 3d gaussian splatting[63]。时变位移属性可以描述静态3DGS的位置变化,从而实现动态表示。该方法通常包括引入小的MLP以基于时间步长t,Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction[143]、Gaufre[144]、4d gaussian splatting for real-time dynamic scene rendering[145]和其他控制信号Cogs: Controllable gaussian splatting[174]来预测位移。
物理属性:物理属性包含广泛的潜在属性,这些属性描述了控制高斯基元的客观物理定律,从而赋予 3DGS 更真实的表示。 例如,与着色相关的属性(例如漫反射颜色、直接镜面反射、残余颜色和各向异性球面高斯)可用于镜面重建Gaussianshader[37]、Mirror-3dgs[38]、Spec-gaussian[39]。 此外,引入阴影标量来表达阴影Md-splatting[146],并采用速度来表示高斯基元的瞬态信息,这对于描述动态属性至关重要Motion-aware 3d gaussian splatting for efficient dynamic scene reconstruction[106]。 这些属性通常通过考虑特定渲染位置处物理属性的影响[37]、[39]、[146]或通过合并补充监督信息(例如流量图[106])来更新。
离散属性:使用离散属性代替连续属性是压缩高维表示或表示复杂运动的有效方法。这通常通过存储VQ码本Eagles[17]、Compact3d[18]、Compressed 3d gaussian splatting for accelerated novel view synthesis[19]、Compact 3d gaussian representation for radiance field[23]的索引值或用于运动基础[147]的运动系数作为高斯基元的离散属性来实现。然而,离散属性可能会导致性能下降;将它们与压缩的连续属性相结合可能是一个潜在的解决方案[138]。
Inferred Attributes:此类属性不需要优化; 它们是从其他属性推断出来的并用于下游任务。 参数敏感度属性反映了参数变化对重建性能的影响。 它由参数的梯度表示,用于指导压缩聚类Compressed 3d[19]。 Pixel-Coverage 属性确定当前分辨率下高斯图元的相对大小。 它与高斯基元的水平或垂直尺寸有关,用于指导高斯尺度以满足多尺度渲染的采样要求Multi-scale 3d gaussian splatting for anti-aliased rendering[34]。
权重属性:权重属性依赖于结构化表示,例如Local Volume[188]、GaussianKernel RBF[150]和SMPL[189],这些表示通过计算相关点的权重来确定查询点的属性。
其他属性:不确定性属性可通过减少高不确定性领域的减重来帮助保持训练稳定性Touch-gs[55],Language embedded 3d gaussians for open-vocabulary scene understanding[138]。并且,从图像帧Orb: An efficient alternative to sift or surf[123]中提取的ORBFeature属性在建立2D-2D和2D-3D对应关系[119]中起着至关重要的作用。
讨论:修改高斯属性有助于执行更广泛的下游任务,提供一种有效的方法,因为它不需要额外的结构元素。 此外,新的高斯属性与补充信息约束的集成也有可能显着增强原始 3DGS 的表示功效。 例如,在某些情况下,语义属性可以产生更精确的对象边界。
6.3 Splatting-溅射过程
Splatting的作用是高效地将3D高斯数据转换为高质量的2D图像,保证平滑、连续的投影,显着提高渲染效率。 作为传统计算机图形学的核心技术,也有人致力于从效率和性能的角度对其进行改进2DGS[137]。
TRIPS [191] 在 3DGS 中引入 ADOP [12] 进行实时渲染,利用屏幕空间图像金字塔进行点光栅化,并采用三线性写入来渲染大点。 这种方法与前后 Alpha 混合和用于细节重建的轻量级神经网络相结合,可确保图像清晰、完整且无锯齿。
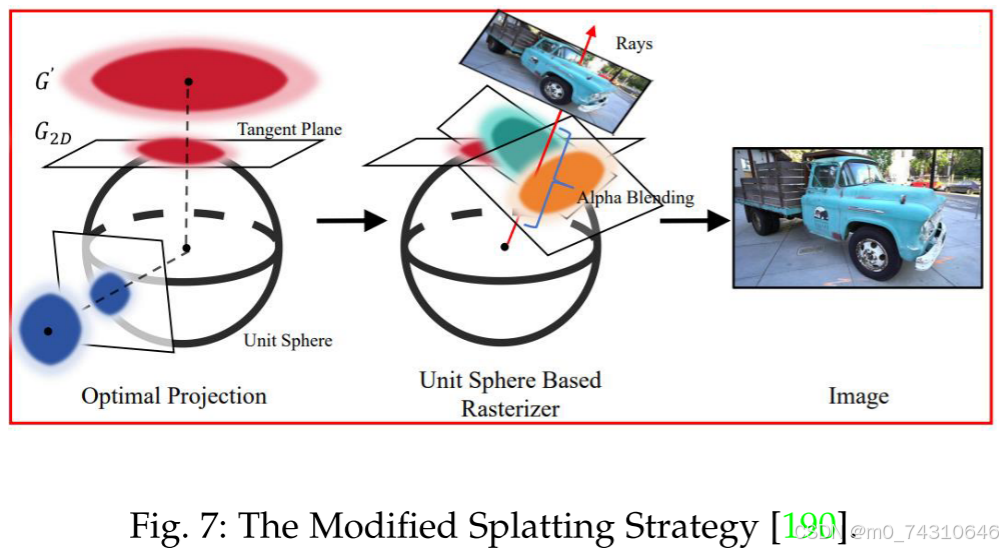
这项工作Gs++: Error analyzing and optimal gaussian splatting [190] 指出了现有方法 3DGS[15] 的局限性,这些方法在投影过程中使用局部仿射近似,从而导致不利于渲染质量的错误。 通过分析一阶泰勒展开的残余误差,他们建立了这些误差与高斯平均位置之间的相关性。 基于此分析,将统一投影平面替换为切平面,通过基于单位球体的光栅化器减轻原始3DGS中的投影误差,如图7所示。2D-GS中也提到了类似的问题[137] ,这是在第5.2节中介绍的。
6.4 Regularization
正则化是三维重建的关键。然而,由于缺乏对3D数据的直接监督,原始3DGS通过将渲染图像与真实图像进行比较来监督其训练。这种形式的监督可能会导致训练不稳定,特别是在确定不足的情况下,例如具有稀疏视图设置的情况。在这一部分中,我们将正则化项分为2D正则化项和3D正则化项,如图8所示。3D正则化项主要直接为3DGS提供约束,而2D正则化项对渲染的图像施加约束,从而影响属性的优化。
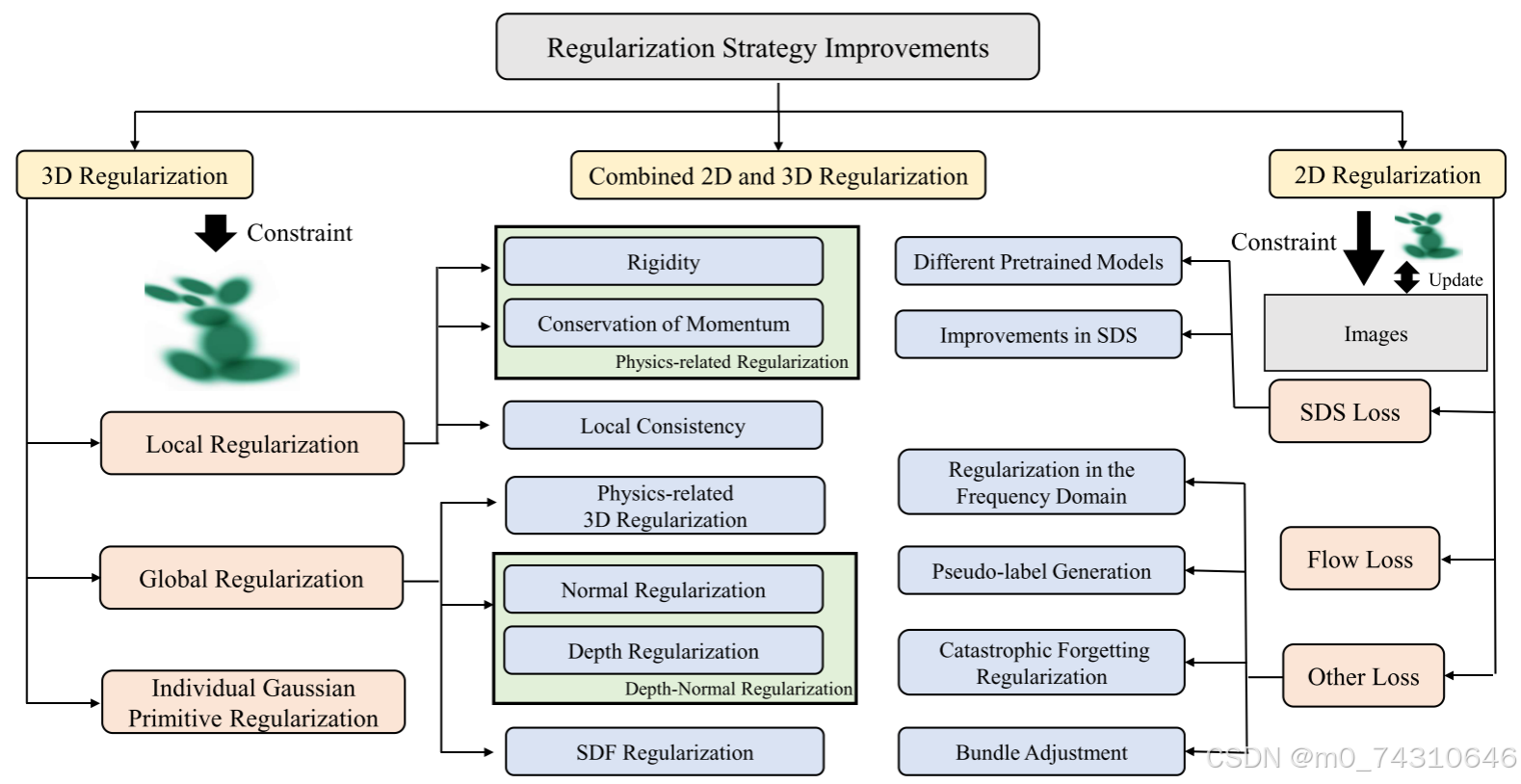
6.4.1 3D Regularization
3D 正则化由于其直观的约束能力而引起了广泛的关注。 这些工作可以根据其目标分为个体高斯原始正则化、局部正则化和全局正则化。
个体高斯原语正则化:这种正则化主要旨在改善高斯原语的某些属性Gaussianpro[32],Gala3d[78],Gaussian splatting slam[126],Physgaussian[139],如第 6.2 节中所述。
局部正则化:由于 3DGS 的显式表示,对局部区域内的高斯基元施加约束是有意义的。 这样的约束可以保证高斯原语在局部空间中的连续性。 与物理相关的正则化通常用于保证可变形目标的局部刚度,包括短期局部刚度损失、局部旋转相似性损失和长期局部等距损失。 短期局部刚性意味着附近的高斯应该在时间步长之间遵循刚体变换移动,
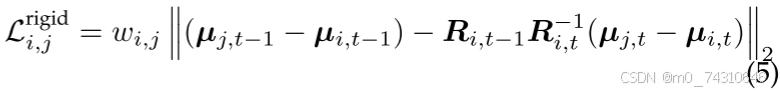
其中,µ是高斯平均位置,i和j是邻近点的索引,t是时间步长,R表示旋转;局部旋转相似性强制相邻的高斯基元在时间步长上具有相同的旋转,
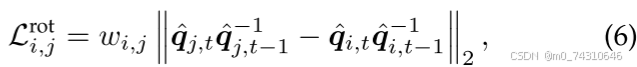
其中是每个高斯的旋转的归一化四元数表示;长期的局部等距损失防止场景的元素漂移,
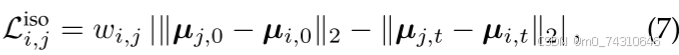
Align your gaussians[103]、Gaussianflow[104]、Dynamic 3d gaussians[135]、Md-splatting[146]、Dynmf[147]、Sc-gs[150]、Cogs[174]、Neural parametric gaussians for monocular non-rigid object reconstruction[188]。随后,一些工作也采用了类似的范式来约束局部刚性Bags[111],Gaussian-flow[149]。
除了刚性损失外,动量守恒正则化也可以作为动态场景重建的约束。它鼓励速度恒定的矢量,并对3D轨迹应用低通滤波效果,从而平滑具有突然变化的轨迹Md-splatting[146]。此外,还有一些局部一致性正则化术语也旨在约束局部区域内的高斯基元以保持相似的属性,例如语义属性Language embedded 3d gaussians for open-vocabulary scene understanding[138]、Gaussian grouping[176]、2dguided 3d gaussian segmentation[179]、位置Cg3d[98]、4dgen[107]、时间Gaussian-flow[149]、帧Swags[141]、法线Geogaussian[192]和深度Depth-regularized optimization for 3d gaussian splatting in few-shot images[52]。
全局正则化:与相邻区域内的局部正则化不同,全局正则化旨在约束整体 3DGS。 与物理相关的正则化引入了现实世界的物理特征来约束 3DGS 的状态,包括重力损失和接触损失等。 重力损失用于约束物体和地板之间的关系,而接触损失则针对多个物体之间的关系Cg3d[98]。
受益于 3DGS 的显式表示,可以直接获得深度和法线方向属性,这可以作为训练期间的约束,特别是对于表面重建任务。 深度法线正则化通过将深度值计算的法线与预测法线进行比较来实现深度法线一致性Gaussianshader[37]、3dgsr[158]、High-quality surface reconstruction using gaussian surfels[160]、Gaussian opacity fields[161]。 该方法有效地同时对法线和深度施加约束。 另外,直接约束法线或深度也是可行的。法线正则化由于缺乏直接监督信号,往往采用自监督范式,可以通过从梯度Neusg[153]、最短轴方向设计伪标签来实现 高斯原语Gaussianshader[37]或SDF[158],Gsdf: 3dgs meets sdf for improved rendering and reconstruction[159]。 同样,Depth Regularization也采用了类似的做法; 然而,它不仅旨在获得准确的深度值,还力求确保 3DGS 中的清晰表面。 深度畸变损失Mip-nerf 360 [8] 沿光线聚合高斯基元。
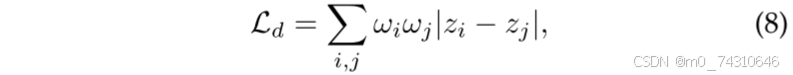
其中z是高斯2DGS[137]、Gaussian opacity fields[161]的相交深度。除了自监督方法,结合额外的预训练模型来估计法线High-quality surface reconstruction using gaussian surfels[160]和深度Mirror-3dgs[38]、FSGS[54]、DNGaussian[56]、Sparsegs[193]已被证明在法线正则化和深度正则化方面更有效。在此基础上,导出的工作引入了硬深度和软深度正则化,以解决几何退化问题,并获得更完整的曲面[56]。类似的正则化项是SDF正则化,它也是曲面重建的一种约束策略。它通过将对应于3DGS的SDF约束到理想分布NeuSG[153]、Sugar[156]、3dgsr[158]、Gsdf[159]、Gaussian shadow casting for neural characters[194]来获得所需的表面。
6.4.2 2D Regularization
与 3D 正则化的直观约束不同,2D 正则化通常用于解决仅原始损失函数不足以解决约束不足的情况。
SDS损失:一个重要的例子是SDS损失,如公式3所示,它利用预先训练的2D扩散模型通过蒸馏范例来监督3DGS训练Dreamgaussian [75],GaussianEditor[162]。 这种方法还可以扩展到提取预训练的 3D 扩散模型Point-E [82]、多视图扩散模型Syncdreamer [195]、图像编辑模型 Instruct-Pix 2 Pix[164] 和视频扩散模型。 其中,引入3D扩散模型Text-to-3d using gaussian splatting[80]、Controllable text-to-3d generation via surface-aligned gaussian splatting[196]和多视图扩散模型DreamGaussian4D[76]、Repaint123[77]、Gala3d[78]、Align your gaussians[103]、Gaussianflow[104]、4DGen[107]可以优化重建 显式几何和多视图一致性。 图像编辑模型GSEdit[163]可以实现可控编辑,而视频扩散模型[103]可用于通过视频SDS生成动态时间场景。 基于这种范式,其他模态图像的蒸馏也具有潜力,因为它可以从相应的预训练扩散模型中提供更多约束,例如RGB-Depth [74],设计者需要讨论如何构建扩散模型。
一些改进专门针对 SDS中的固有问题LucidDreamer [85]、LODS[89] 。 提出间隔分数匹配是为了解决随机性和单步采样的问题,
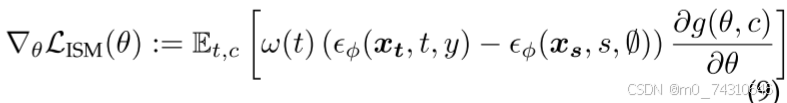
![]()
引入否定提示Introducing Negative Prompts[197]也是一种通过用否定提示项![]() 取代随机噪声ϵ来减轻随机噪声ϵ的影响并增强稳定性的方法RGB-Depth[74]、LucidDreamer[85]、Controllable text-to-3d generation via surface-aligned gaussian splatting[196]。随后,LODS引入LORA[90]项
取代随机噪声ϵ来减轻随机噪声ϵ的影响并增强稳定性的方法RGB-Depth[74]、LucidDreamer[85]、Controllable text-to-3d generation via surface-aligned gaussian splatting[196]。随后,LODS引入LORA[90]项![]() 来取代传统的随机噪声ϵ,从而减轻了分布外的影响[89]。
来取代传统的随机噪声ϵ,从而减轻了分布外的影响[89]。
Flow loss:流动损失是动态3DGS中常用的正则化术语。使用预先训练的2D光流估计模型的输出作为地面真实,它可以通过计算单位时间内高斯基元的位移并将这些3D位移溅射到2D平面[104]、[114]、[115]来呈现预测的流。然而,这种方法有一个很大的差距,主要是因为光流是2D平面属性,容易受到噪声的影响。选择在空间中具有正确深度的高斯基元并通过KL发散引入不确定性来约束光流是一种潜在的可行方法[106]。
other loss:还有一些 2D 正则化术语值得讨论。 例如,在频域中限制渲染图像和GT之间的幅度和相位差异可以作为损失函数来帮助训练,从而减轻过度拟合问题Fregs: 3d gaussian splatting with progressive frequency regularization[33]。 通过噪声扰动为假设视点引入伪标签可以帮助稀疏视图设置中的训练Fsgs: Real-time few-shot view synthesis using gaussian splatting[54]。 在大规模场景映射中,限制优化前后属性的变化可以防止 3DGS 上的灾难性遗忘High-fidelity slam using gaussian splatting with rendering-guided densification and regularized optimization[129]。 此外,束调整BA通常是位姿估计问题中的一个重要约束Gs-slam: Dense visual slam with 3d gaussian splatting[118]、Photo-slam[119]、Semgauss-slam[130]。
需要注意的是,无论是使用 2D 还是 3D 正则化,由于 3DGS 中基元数量较多,整体优化有时不是最优的。 一些原语常常会对结果产生无法控制的影响。 因此,有必要利用可见性Splatam: Splat, track & map 3d gaussians for dense rgb-d slam[120]、Sgs-slam: Semantic gaussian splatting for neural dense slam[122]、Neds-slam: A novel neural explicit dense semantic slam framework using 3d gaussian splatting[131]、Gaussnav: Gaussian splatting for visual navigation[134]等方法选择重要的高斯原语来指导优化。
讨论:对于特定任务,常常可以引入各种约束,包括2D和3D正则化项,其中许多正则化项是即插即用的,可以直接增强性能。
6.5 Training Strategy
训练策略也是一个重要的话题。在本节中,我们将其分为多阶段训练策略和端到端训练策略,可以应用于不同的任务。
6.5.1 Multi-stage Training Strategy-多阶段训练
多阶段训练策略是一种常见的训练范式,通常涉及从粗到细的重建。 它广泛用于未确定的任务,例如 AIGC、动态 3DGS 构建和 SLAM。
在不同的训练阶段使用不同的3D表示是多阶段训练的典型范例之一。3DGS→网格(第一阶段训练3DGS,将表示转化为网格,然后在第二阶段优化网格)[75],[76],[77],[92],[163],[196]是保证生成的3D模型几何一致性的有效方法。另外,代替在3D表示之间转换,在第一阶段中生成多视点图像[91]、[96]、[109]、[136]、[165]、[166]、[196]来帮助第二阶段的改造还可以提高生成质量。
静态和动态重建的两阶段重建在动态 3DGS 中也很重要。 此类工作通常涉及在第一阶段训练与时间无关的静态 3DGS,然后在第二阶段训练与时间相关的变形场来表征动态高斯[115]、[143]、[144]、[145] ,[146],[168]。 此外,逐帧动态场景的增量重建也是一些工作的重点,通常依赖于先前重建的性能[135],[140]。
在多目标优化任务中,多阶段训练范式可以增强训练稳定性和性能。 例如,从粗到细的相机跟踪策略是一种常见的方法,首先通过一组稀疏像素获得粗略的相机位姿,然后根据优化的渲染结果进一步细化估计的相机位姿Gs-slam: Dense visual slam with 3d gaussian splatting[118],3dgs-reloc: 3d gaussian splatting for map representation and visual relocalization[133] ]。
此外,一些工作旨在完善第一阶段训练的 3DGS [51]、[57]、[80]、[87]、[170]、[179]、[188] 或赋予它们额外的能力,例如 语义[134]、[180]和风格化[172]。 这样的训练策略有很多,也是保持训练稳定性、避免局部最优的有效手段[24]。 此外,对最终结果进行迭代优化以提高性能也是可行的[136]。
6.5.2 End-to-EndTraining Strategy-端到端
端到端的训练策略通常更有效,并且可以应用于更广泛的下游任务。 一些典型的作品如图9所示。
渐进式优化策略:这是一种常用策略,可帮助3DGS在局部优化细节之前优先学习全局表示。在频域中,这一过程也可以看作是从低频分量到高频分量的渐进学习。它通常通过逐渐增加高频信号的比例FreGS[33]、Relaxing accurate initialization constraint for 3d gaussian splatting[187]或引入用于监督的逐渐较大的图像/特征尺寸Eagles[17]、SpecGaussian[39]、Photo-slam[119]来实现,这也可以提高效率3dgscalib[116]。在生成性任务中,循序渐进地选择相机姿势也是一种容易做到难的训练策略,从接近初始视点的位置逐渐优化到距离较远的位置Repaint123[77]、Text2immersion[102]。
块优化策略:该策略经常用于大规模场景重建,不仅可以提高效率,还可以缓解灾难性遗忘[121]、[133]、[134]的问题。同样,它可以通过将场景划分为静态背景和动态对象[112]、[113]、[114]、[144]来实现重建。此外,这样的方法也应用于AIGC和语义理解,其中精炼子地图的重建质量提高了整体性能[87],[181]
与按空间区域划分的子图不同,高斯基元可以根据其致密化过程被分类到不同的世代,从而允许对每一代应用不同的正则化策略,这是调节不同世代流动性的有效策略[162]。将初始点分为光滑曲面上的点和独立点也是一种可行的策略。通过为每个类别设计不同的初始化和增密策略,它可以获得更好的几何表示[192]。此外,一些工作旨在设计基于时态数据的帧间共可见性或几何重叠率的关键帧(或窗口)选择策略,并将其用于重建[118]、[120]、[122]、[126]、[129]、[141]。
鲁棒优化策略:在训练过程中引入噪声扰动是增强训练过程鲁棒性的常用方法[57]、[92]、[143]。 这种扰动可以针对相机姿势、时间步长和图像,并且可以被视为一种防止过度拟合的数据增强形式。 此外,一些训练策略旨在通过避免从单一观点进行连续训练来减轻过度拟合和灾难性遗忘[121],[127]。
基于蒸馏的策略:为了压缩模型参数,一些蒸馏策略使用原始 3DGS 作为教师模型,使用低维 SH 3DGS 作为学生模型。 通过引入更多的伪视图,他们的目标是提高低维 SH 的表示性能 [24]。
讨论:改进训练策略是优化 3DGS 训练过程的有效方法,可以提高许多任务的性能。 特别是端到端的培训策略可以在确保效率的同时提高绩效。
6.6 Adaptive Control
3DGS的自适应控制是调节高斯基元数量的一个重要过程,包括克隆、分裂和剪枝。在接下来的部分中,我们将从致密化(克隆和分裂)和修剪的角度总结现有的技术。
6.6.1 Densification-稠密化
致密化是至关重要的,尤其是对于细节重建。在这一部分,我们将从“在哪里增密”和“如何增密”两个角度进行分析。此外,我们还将讨论如何避免过度致密化。
何处致密化:致密化技术通常集中于识别需要致密化的位置,该过程由原始 3DGS 中的梯度控制,也可以扩展到动态场景中新目标的重建 [140]。 随后,具有低不透明度或轮廓和高深度渲染误差的区域,被视为不可靠区域,也被认为是指导致密化的重要因素[32],[118],[129],[134],[148],[ 160],通常用于填充孔洞或改善 3D 不一致的区域。 一些工作继续关注基于梯度的改进,其中不同视图中每个高斯覆盖的像素数量被视为权重来动态平均这些视图的梯度,从而改善点云生长的条件[198]。 此外,SDF 值和邻居距离也是重要的标准,位置越靠近表面且紧凑度越低,更容易致密化[80]、[156]、[159]。
如何稠密:许多工作已经改进了稠密方法。图结构被用来探索节点之间的关系并基于邻近度分数在边缘中心定义新的高斯图,从而减轻稀疏视点的影响[54]。为了防止高斯人数量的过度增长,候选者池策略旨在存储修剪后的高斯人以进行增密[94]。此外,Work[199]引入了三个守恒定律来确保视觉一致性,并使用积分张量方程来模拟致密化。
过度致密化也是不必要的,因为它直接影响3DGS的效率。 在两个高斯函数非常接近的情况下,限制它们的致密化是一个简单的想法,其中高斯函数之间的距离可以通过高斯发散显着性 [96] (GDS) 或 Kullback-Leibler 散度 [62] 来测量,其中 µ1, Σ1 , µ2, Σ2 属于两个相邻高斯。
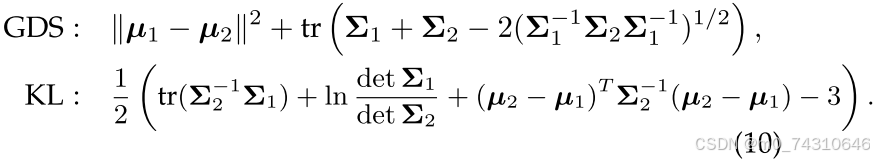
DeblurGS[42]结合了高斯致密化退火法策略,以防止在不精确的摄像机运动估计的早期训练阶段不准确的高斯值的致密化。此外,在一些下游任务中,有时会放弃加密,以防止3DGS过度适合每个图像,这可能会导致不正确的几何形状[116]、[118]、[120]、[126]。
6.6.2 Pruning-剪枝
去除不重要的高斯原语可以确保有效的表示。在最初的3DGS框架中,不透明度被用作确定高斯显著性的标准。随后的研究探索了将尺度作为剪枝的指导因素[74]。然而,这些方法主要关注单个高斯原语,缺乏对全局表示的全面考虑。因此,后续的衍生技术已经解决了这个问题。
重要性分数:训练视图上的体积和命中数可以与不透明度一起引入共同确定高斯原语[24]的全局显著性分数。
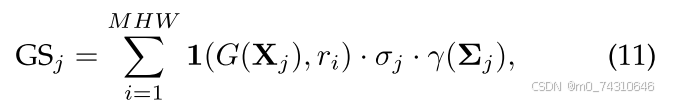
其中γ(Σ j)和1(G(Xj),ri)为体积和命中数,M为训练视图的个数。随后,根据高斯分布的全局显著性得分对其进行排序,并对得分最低的高斯分布进行修剪。其他著作[200]、[201]也改进了类似的重要性分数。
多视图一致性:多视图一致性是确定是否需要修剪高斯分布的关键标准。例如,工作[126]对新添加的高斯分布进行了剪枝,这些高斯分布在局部关键帧窗口内没有被三个关键帧观察到,而工作[131]对所有虚拟视图中不可见但在真实视图中可见的高斯分布进行了剪枝。
距离度量:一些表面感知方法通常引入到表面的距离[118]和SDF值[159],修剪远离表面的高斯原语。高斯分布之间的距离也是一个重要的度量。GauHuman[62]旨在“合并”具有小尺度和低KL散度的高斯分布,如Eq. 10所述。
可学习的控制参数:引入一个基于比例和不透明度的可学习掩模来确定是否要去除目标高斯基元也是防止3DGS变得过于密集[23]的有效方法。
6.7 Post-Processing
预训练高斯分布的后处理策略非常重要,因为它们可以提高3DGS的原始效率和性能。常见的后处理通常通过不同的优化策略来改进高斯表示。这类工作已经在第6.5节中讨论过。
表示转换:通过对采样的3D点[156],[160]引入泊松重构[202],可以将预训练好的3DGS直接转换为Mesh。类似地,高斯不透明度域(GOF)[161]引入3D边界框,将预训练的3DGS转换为四面体网格表示,然后使用水平集二分搜索从中提取三角形网格。此外,LGM[92]首先将预训练的3DGS转换为NeRF表示,然后使用NeRF2Mesh[203]将其转换为Mesh。
性能和效率:一些作品旨在通过后期处理,如多尺度渲染,来提高3DGS在某些任务中的性能。SA-GS[36]在预训练3DGS的基础上,引入了一种二维尺度自适应滤波器,可以根据测试频率动态调整尺度,增强缩小时的抗混叠性能。在效率方面,从预训练的3DGS[29]中去除冗余的高斯
原语或引入高斯缓存机制[204]可以有效提高渲染效率。

















 4186
4186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









