









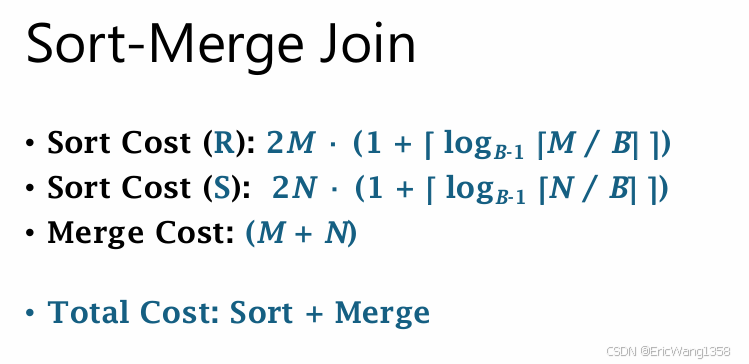
Sort-Merge Join(排序合并连接)详细解析
Sort-Merge Join 是一种高效的连接算法,通过先对两张表进行排序,然后合并排序后的结果找到匹配的记录。
算法核心
1. 两个阶段
- 阶段 1:排序(Sort Phase)
- 将两张表 RRR 和 SSS 按照连接键(Join Key)排序。
- 如果表很大,可以使用 外部排序(External Sort),具体步骤包括分块排序和归并。
- 阶段 2:合并(Merge Phase)
- 使用两个游标(Cursor),分别遍历两张排序后的表:
- 如果两条记录的连接键相等,输出匹配的记录。
- 如果不相等,移动游标以继续匹配。
- 使用两个游标(Cursor),分别遍历两张排序后的表:

俗解释与比喻
1. 排序阶段(Sort Phase)
比喻:整理商品货架
- 想象你在仓库整理商品(表中的记录):
- 按商品类别对两批货物分别排序(按连接键排序)。
- 排序后的商品从左到右排列整齐,方便后续查找。
2. 合并阶段(Merge Phase)
比喻:对比商品编号
- 现在,你要从两批已排序的货物中找到匹配的商品编号:
- 两个指针(Cursors): 分别指向两批货物的起始位置。
- 如果两个指针指向的商品编号相同,就输出这对匹配商品。
- 如果编号不匹配,调整指针:
- 较小的编号指针向右移动,直到找到匹配的编号。
详细步骤
算法伪代码
sort R, S on join keys
cursorR ← Rsorted, cursorS ← Ssorted
while cursorR and cursorS are valid:
if cursorR.key > cursorS.key:
increment cursorS # 内表游标前进
elif cursorR.key < cursorS.key:
increment cursorR # 外表游标前进
else:
emit matching tuple (cursorR, cursorS)
increment cursorS # 或 cursorR, 取决于 join 类型
案例分析
示例
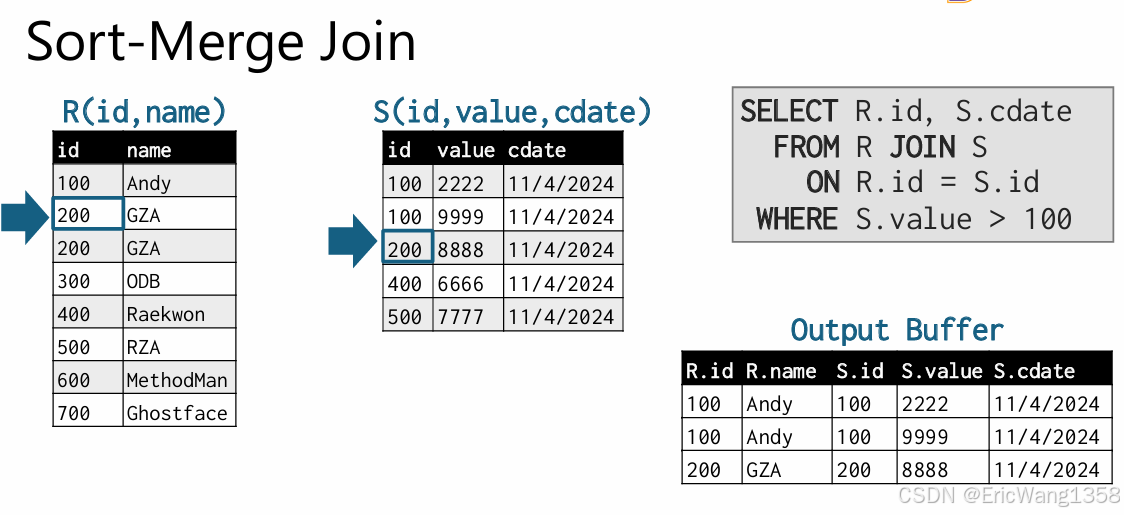
假设:
- 表 RR:包含记录
(id, name)。 - 表 SS:包含记录
(id, value, cdate)。
查询:
SELECT R.id, S.cdate
FROM R JOIN S
ON R.id = S.id
WHERE S.value > 100;
步骤
-
排序阶段(Sort Phase)
- 对 RR 和 SS 按
id进行排序:- 排序后 RR:
id name 100 Andy 200 GZA 200 GZA 300 ODB 400 Raekwon 500 RZA 600 MethodMan 700 Ghostface - 排序后 SS:
id value cdate 100 2222 11/4/2024 100 9999 11/4/2024 200 8888 11/4/2024 400 6666 11/4/2024 500 7777 11/4/2024
- 排序后 RR:
- 对 RR 和 SS 按
-
合并阶段(Merge Phase)
- 使用两个游标分别从排序后的 RR 和 SS 起始位置开始:
- 比较 R.id=100R.id = 100 和 S.id=100S.id = 100,匹配,输出结果。
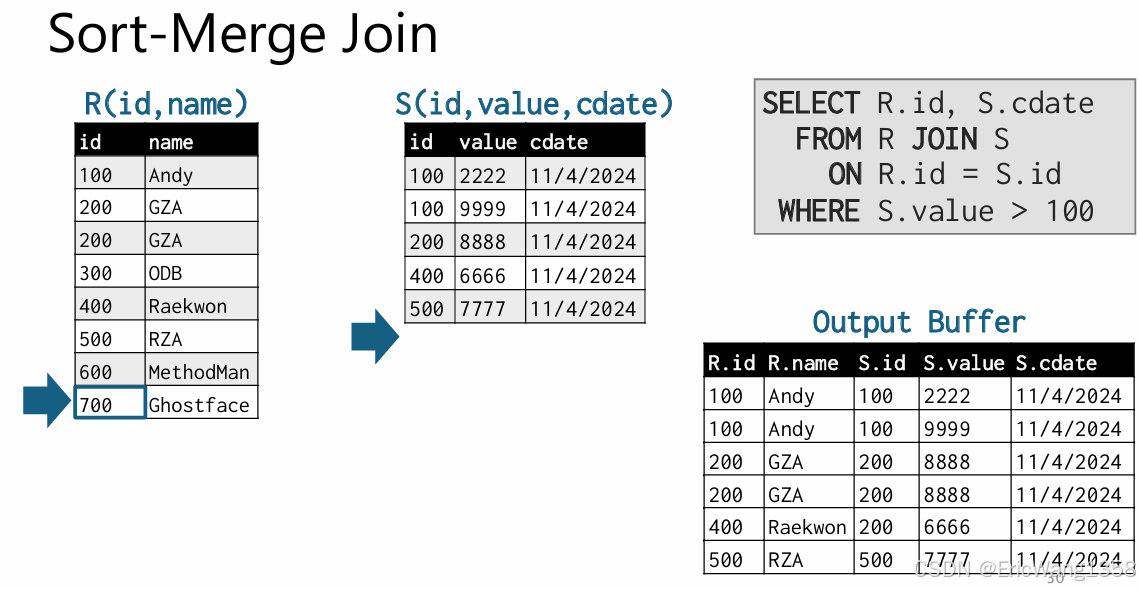
- 移动 SS 游标到下一个 id=100id=100,再次匹配。
- SS 游标继续移动到 id=200id=200,匹配 RR 中所有 id=200id=200 的记录。
- 按此规则进行,直到所有匹配完成。
- 使用两个游标分别从排序后的 RR 和 SS 起始位置开始:
优缺点分析
优点
- 适合排序表: 如果表已经按照连接键排序,排序阶段的成本为零。
- 顺序访问: 排序和合并阶段都使用顺序访问磁盘,效率较高。
- 无额外索引需求: 不需要表上已有索引。
缺点
- 排序开销大: 如果表未排序且数据量很大,排序阶段的成本较高。
- 内存依赖: 排序阶段需要足够的缓冲区,否则需要外部排序。
- 回退成本: 如果是非等值连接(如范围连接),可能需要回退游标,增加复杂性。
性能对比与适用场景
| 特点 | Sort-Merge Join | Nested Loop Join | Hash Join |
|---|---|---|---|
| 排序需求 | 必须对两张表排序 | 无排序需求 | 无排序需求 |
| 索引需求 | 无索引需求 | 内表需要索引 | 无索引需求 |
| I/O 模式 | 顺序 I/O | 随机 I/O | 随机 I/O(构建哈希表) |
| 适用场景 | 表大但排序后易于合并 | 内表小且有索引 | 表大且无索引 |
| 复杂度(排序后) | O(M+N)O(M + N) | O(M⋅N)O(M \cdot N) | O(M+N)O(M + N) |
总结
-
核心原理:
- Sort-Merge Join 通过排序和合并操作高效地完成连接。
- 排序阶段为后续合并奠定基础,合并阶段利用顺序访问提升性能。
-
通俗比喻:
- 排序阶段类似整理商品,合并阶段类似对比两个列表的商品编号,找到匹配的记录。
-
适用场景:
- 表数据量大但有规律,或者需要排序输出时,Sort-Merge Join 是优选算法。



















 9530
9530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









