







PCA/LDA/2DPCA 核心知识点大纲总结(期末复习提纲)
1. PCA(主成分分析)
特征:
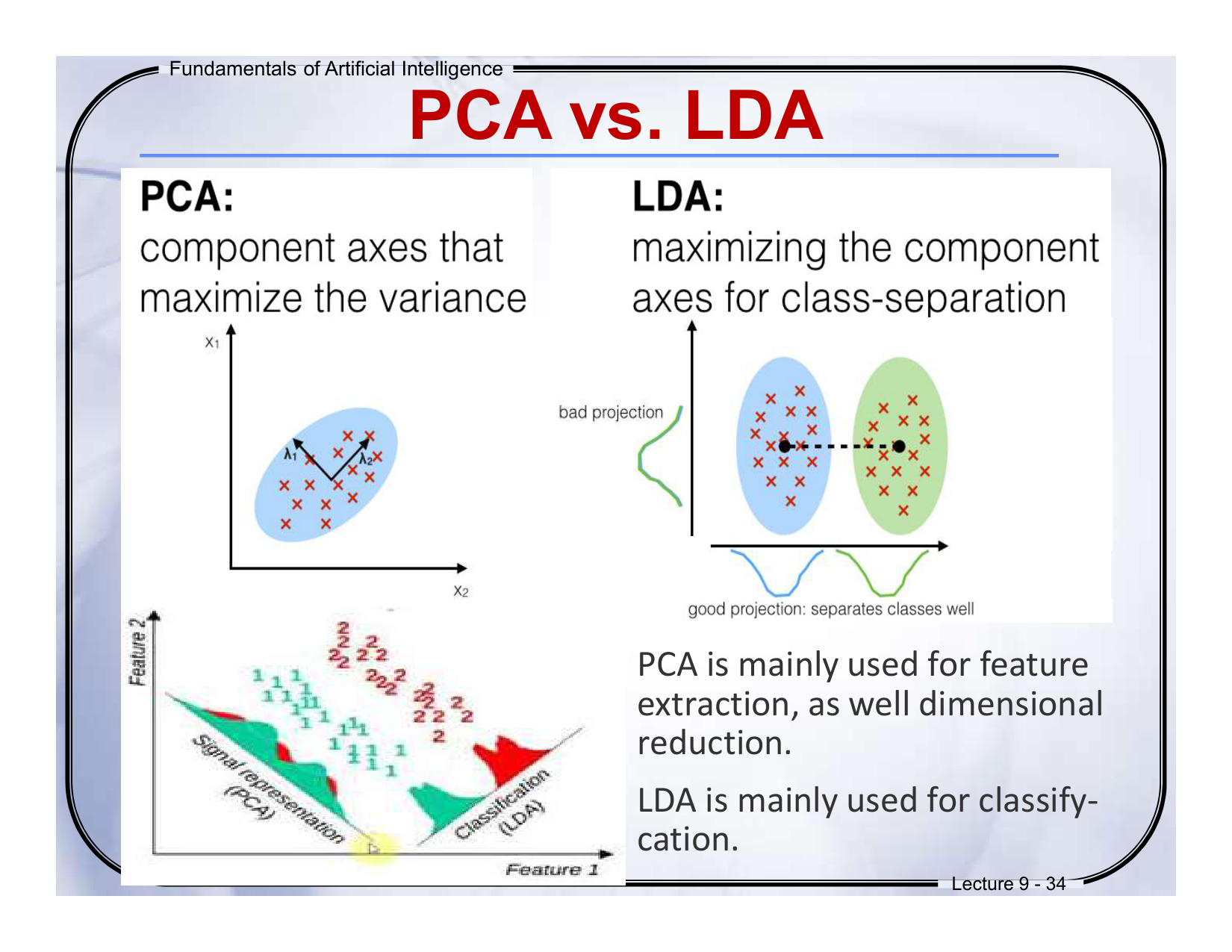
• 核心目标:最大化数据方差,找到数据主方向。
• 数据形式:展平为向量(MN×1)。
• 协方差矩阵:维度MN×MN,计算复杂度高。
• 应用场景:通用降维、去噪、信号压缩。
一句话说明:
PCA通过协方差矩阵的特征分解,保留最大方差方向,但丢失图像空间结构。
对比:
| 维度 | PCA |
|---|---|
| 数据形式 | 展平为向量(高维) |
| 优点 | 计算简单、适用性广 |
| 缺点 | 丢失结构、协方差矩阵过大 |
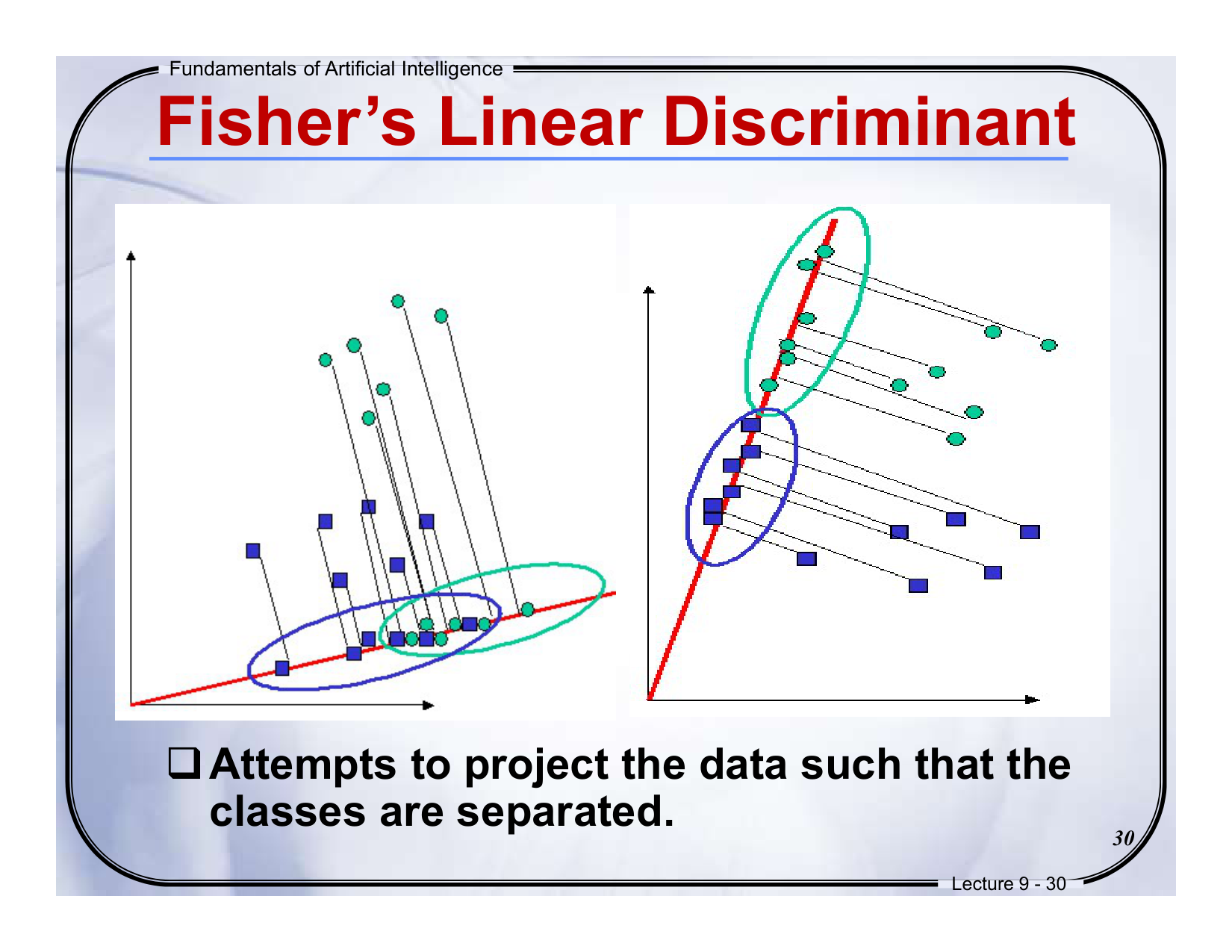
2. LDA(线性判别分析)
特征:
• 核心目标:最大化类间分离,最小化类内差异。
• 监督学习:需类别标签。
• 投影方向:类间散度与类内散度比值优化。
• 应用场景:分类任务(如人脸识别)。
一句话说明:
LDA通过类间差异最大化,投影后同类数据聚集,异类分离,适合小样本分类。
对比:
| 维度 | LDA |
|---|---|
| 监督性 | 有监督(需标签) |
| 目标 | 类间分离 |
| 缺点 | 需足够样本,计算复杂 |
3. 2DPCA(二维主成分分析)
特征:
• 核心目标:保留图像二维结构,直接操作矩阵。
• 数据形式:原始矩阵(M×N),无需展平。
• 协方差矩阵:维度N×N,计算更高效。
• 应用场景:小样本、实时任务(如人脸识别)。
一句话说明:
2DPCA通过酉矩阵投影,保留图像空间结构,避免高维协方差矩阵问题。
对比:
| 维度 | 2DPCA |
|---|---|
| 数据形式 | 保留矩阵结构(M×N) |
| 优点 | 结构保留、计算快、适合小样本 |
| 缺点 | 特征维度可能高于PCA |
综合对比表
| 指标 | PCA | LDA | 2DPCA |
|---|---|---|---|
| 数据形式 | 展平为向量(MN×1) | 展平为向量(MN×1) | 原始矩阵(M×N) |
| 监督性 | 无监督 | 有监督 | 无监督 |
| 核心目标 | 最大化方差 | 最大化类间分离 | 保留二维结构 |
| 计算效率 | 低(高维矩阵) | 中(依赖样本量) | 高(低维协方差矩阵) |
| 适用场景 | 通用降维 | 分类任务 | 小样本、实时任务 |
考试口诀
• PCA:展平→大矩阵→省空间但易乱。
• LDA:标签指导→类间分离→分类强。
• 2DPCA:留结构→小矩阵→快且准。
一句话记忆:
• PCA是“传统降维工具”,LDA是“分类加速器”,2DPCA是“结构保留专家”。
PCA/LDA/2DPCA 中英双语填空题(完整版)
PCA(主成分分析)
-
中文:PCA的核心目标是最大化数据的______。
英文:The core goal of PCA is to maximize the ______ of data.
答案:方差(variance)
解析:PCA通过协方差矩阵特征分解,保留数据方差最大的方向。 -
中文:PCA需要将图像展平为______维向量。
英文:PCA requires flattening images into ______-dimensional vectors.
答案:MN(如28×23=644)
解析:传统PCA将图像从2D矩阵展平为1D向量,导致结构丢失。 -
中文:PCA的协方差矩阵维度为______×______。
英文:The covariance matrix of PCA has dimensions ×.
答案:MN×MN(如644×644)
解析:协方差矩阵大小由展平后的向量维度决定,计算复杂度高。 -
中文:PCA的缺点是丢失______信息。
英文:A drawback of PCA is losing ______ information.
答案:空间结构(spatial structure)
解析:展平操作破坏像素间的空间关系(如眼睛与鼻子的相对位置)。 -
中文:PCA的投影方向由______矩阵的特征向量决定。
英文:The projection directions in PCA are determined by the eigenvectors of the ______ matrix.
答案:协方差(covariance)
解析:协方差矩阵的特征向量指向数据方差最大的方向。 -
中文:PCA适用于______任务(如信号压缩)。
英文:PCA is suitable for ______ tasks (e.g., signal compression).
答案:无监督降维(unsupervised dimensionality reduction)
解析:PCA无需标签数据,直接通过数据分布进行降维。 -
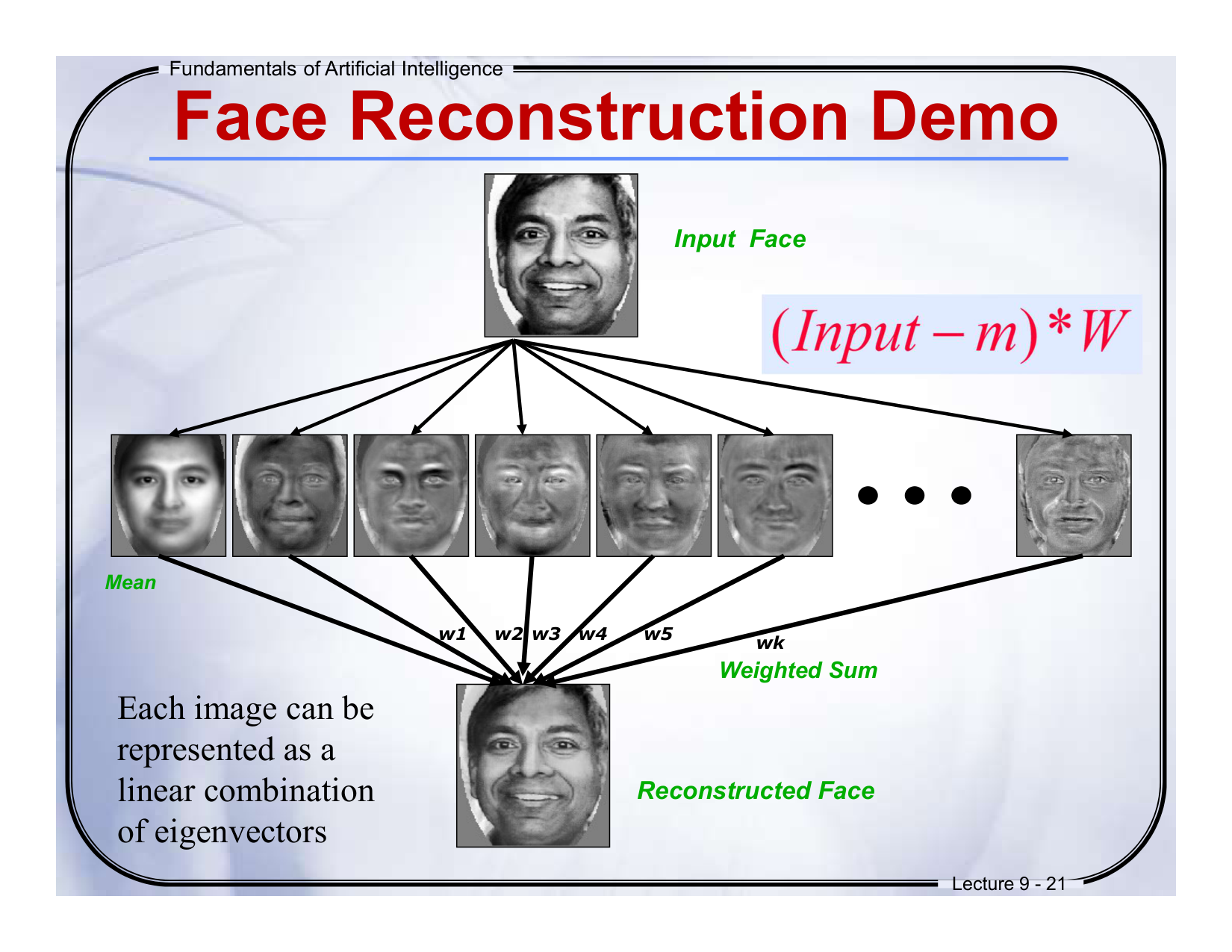
中文:PCA的重建公式为______。
英文:The reconstruction formula in PCA is ______.
答案:X=m+∑wiφi
解析:通过均值向量m和权重wi重构原始数据。 -
中文:PCA中权重wi表示每个主成分的______。
英文:In PCA, the weights wi represent the ______ of each principal component.
答案:贡献比例(contribution ratio)
解析:权重越大,对应主成分对重构的贡献越高。 -
中文:PCA的协方差矩阵计算公式为______。
英文:The covariance matrix formula in PCA is ______.
答案:S=n1XTX
解析:协方差矩阵反映数据各维度的方差和协方差。 -
中文:PCA在______场景下计算效率较低。
英文:PCA is computationally inefficient in ______ scenarios.
答案:高维数据(high-dimensional data)
解析:协方差矩阵维度随数据维度平方增长,计算复杂度高。 -
中文:PCA的降维结果称为______空间。
英文:The reduced dimension space in PCA is called the ______ space.
答案:主成分(principal component)
解析:降维后的数据投影到主成分方向,保留最大方差。 -
中文:PCA的缺点包括______和______。
英文:Drawbacks of PCA include ______ and ______.
答案:信息丢失(information loss)、计算复杂度高(high computational cost)
解析:展平操作丢失结构信息,高维协方差矩阵计算耗时。 -
中文:PCA的数学基础是______分解。
英文:The mathematical foundation of PCA is ______ decomposition.
答案:特征值(eigenvalue)
解析:通过协方差矩阵的特征值分解确定主成分方向。 -
中文:PCA的权重向量w需满足______条件。
英文:The weight vector w in PCA must satisfy ______ conditions.
答案:单位正交(unit orthogonal)
解析:主成分之间正交,避免信息冗余。 -
中文:PCA适用于图像______任务。
英文:PCA is applicable to image ______ tasks.
答案:去噪(denoising)
解析:通过保留主要成分去除噪声。 -
中文:PCA的协方差矩阵特征值越大,说明该方向______。
英文:A larger eigenvalue in PCA's covariance matrix indicates that the direction ______.
答案:方差越大(has higher variance)
解析:特征值反映对应主成分的信息量。 -
中文:PCA的降维过程也称为______变换。
英文:The dimensionality reduction process in PCA is also called ______ transform.
答案:Karhunen-Loève
解析:Karhunen-Loève变换是PCA的数学别名。 -
中文:PCA的缺点是______和______。
英文:PCA's drawbacks include ______ and ______.
答案:结构丢失(structure loss)、噪声敏感(noise sensitivity)
解析:展平操作破坏结构,且主成分可能包含噪声。 -
中文:PCA的权重计算通过______优化。
英文:The weights in PCA are optimized through ______.
答案:协方差矩阵特征分解(covariance matrix eigen-decomposition)
解析:权重由协方差矩阵的特征向量确定。 -
中文:PCA的降维结果保留了数据的______方向。
英文:PCA's reduced dimensions retain the data's ______ directions.
答案:最大方差(maximum variance)
解析:主成分方向对应数据方差最大的方向。
LDA(线性判别分析)
-
中文:LDA的全称是______。
英文:The full name of LDA is ______.
答案:线性判别分析(Linear Discriminant Analysis)
解析:LDA是一种有监督的降维方法,用于分类任务。 -
中文:LDA的目标是最大化______。
英文:The goal of LDA is to maximize ______.
答案:类间散度与类内散度的比值(ratio of between-class to within-class scatter)
解析:通过优化投影方向,使同类数据聚集,异类分离。 -
中文:LDA需要______作为输入。
英文:LDA requires ______ as input.
答案:带标签的数据(labeled data)
解析:LDA是有监督方法,依赖类别标签计算类间差异。 -
中文:LDA的投影方向由______矩阵优化。
英文:The projection direction in LDA is optimized by the ______ matrix.
答案:类间散度矩阵(between-class scatter matrix)
解析:通过类间散度矩阵SB和类内散度矩阵SW的比值确定方向。 -
中文:LDA的类间散度矩阵SB公式为______。
英文:The formula for the between-class scatter matrix SB is ______.
答案:SB=∑i=1cNi(μi−μ)(μi−μ)T
解析:Ni为第i类样本数,μi为类均值,μ为总均值。 -
中文:LDA的类内散度矩阵SW公式为______。
英文:The formula for the within-class scatter matrix SW is ______.
答案:SW=∑i=1c∑x∈ci(x−μi)(x−μi)T
解析:反映同类样本内部的方差分布。 -
中文:LDA的优化目标是最大化______。
英文:The optimization goal of LDA is to maximize ______.
答案:J(w)=wTSWwwTSBw
解析:通过拉格朗日乘子法求解最优投影方向。 -
中文:LDA的投影维度受限于______。
英文:The projection dimensionality of LDA is limited by ______.
答案:类别数减一(number of classes minus one)
解析:最大可投影维度为c−1,其中c为类别数。 -
中文:LDA适用于______任务。
英文:LDA is suitable for ______ tasks.
答案:分类(classification)
解析:通过最大化类间差异提升分类性能。 -
中文:LDA的缺点是______。
英文:A drawback of LDA is ______.
答案:需要足够样本量(requires sufficient sample size)
解析:类内散度矩阵需足够样本才能准确估计。 -
中文:LDA的投影公式为______。
英文:The projection formula in LDA is ______.
答案:y=wTx
解析:将原始数据投影到低维空间,权重w由类间散度优化。 -
中文:LDA的类间散度矩阵SB反映______差异。
英文:The between-class scatter matrix SB captures ______ differences.
答案:类别间(between-class)
解析:衡量不同类别中心之间的距离。 -
中文:LDA的类内散度矩阵SW反映______差异。
英文:The within-class scatter matrix SW captures ______ differences.
答案:类别内(within-class)
解析:衡量同类样本内部的方差分布。 -
中文:LDA的权重向量w需满足______条件。
英文:The weight vector w in LDA must satisfy ______ conditions.
答案:与类内散度矩阵正交(orthogonal to the null space of SW)
解析:投影方向需在类内散度矩阵的零空间外。 -
中文:LDA适用于小样本场景,因为______。
英文:LDA is suitable for small sample scenarios because ______.
答案:依赖类内散度矩阵的准确性(depends on accurate estimation of SW)
解析:样本不足时,类内散度矩阵估计误差较大。 -
中文:LDA的降维结果称为______空间。
英文:The reduced dimension space in LDA is called the ______ space.
答案:判别式(discriminant)
解析:投影后的维度用于区分不同类别。 -
中文:LDA的缺点包括______和______。
英文:Drawbacks of LDA include ______ and ______.
答案:需要标签数据(requires labeled data)、维度限制(dimensionality limitation)
解析:有监督方法依赖标签,且最大投影维度受类别数限制。 -
中文:LDA的数学基础是______优化。
英文:The mathematical foundation of LDA is ______ optimization.
答案:广义特征值(generalized eigenvalue)
解析:通过最大化类间散度与类内散度的比值求解。 -
中文:LDA的投影方向与______垂直。
英文:The projection direction in LDA is orthogonal to ______.
答案:类内散度矩阵的零空间(null space of SW)
解析:投影方向需在类内差异最小的方向上。 -
中文:LDA在______场景下表现最佳。
英文:LDA performs best in ______ scenarios.
答案:类别可分性强(strong class separability)
解析:当类别间差异明显时,LDA的分类效果最优。
2DPCA(二维主成分分析)
-
中文:2DPCA直接处理______而非展平向量。
英文:2DPCA directly processes ______ instead of flattened vectors.
答案:图像矩阵(image matrix)
解析:保留原始矩阵结构,避免展平导致信息丢失。 -
中文:2DPCA的协方差矩阵维度为______×______。
英文:The covariance matrix of 2DPCA has dimensions ×.
答案:N×N(如23×23)
解析:直接操作图像矩阵,协方差矩阵维度远小于PCA。 -
中文:2DPCA的酉矩阵V满足______。
英文:The unitary matrix V in 2DPCA satisfies ______.
答案:VTV=I
解析:酉矩阵保证投影方向正交,避免信息冗余。 -
中文:2DPCA的重建公式为______。
英文:The reconstruction formula in 2DPCA is ______.
答案:X=M+X′VT
解析:通过均值矩阵M和投影系数X′还原图像。 -
中文:2DPCA的投影变换W由______组成。
英文:The projection transform W in 2DPCA consists of ______.
答案:特征向量(eigenvectors)
解析:特征向量定义投影方向,保留最大方差。 -
中文:2DPCA的均值矩阵M是______矩阵。
英文:The mean matrix M in 2DPCA is a ______ matrix.
答案:M×N(如28×23)
解析:直接计算原始图像矩阵的均值,保留空间结构。 -
中文:2DPCA的协方差矩阵公式为______。
英文:The covariance matrix formula in 2DPCA is ______.
答案:St=n1(X−M)T(X−M)
解析:基于原始矩阵计算协方差,避免展平操作。 -
中文:2DPCA的缺点是______。
英文:A drawback of 2DPCA is ______.
答案:特征维度可能高于PCA(higher feature dimensionality than PCA)
解析:当投影维度d接近原始列数时,特征维度可能更高。 -
中文:2DPCA的投影方向优化目标是______。
英文:The projection direction optimization goal in 2DPCA is ______.
答案:最大化矩阵迹(maximize matrix trace)
解析:通过最大化Tr(WTStW)保留最大方差。 -
中文:2DPCA适用于______任务。
英文:2DPCA is suitable for ______ tasks.
答案:小样本实时任务(small-sample real-time tasks)
解析:计算效率高,适合处理实时数据流。 -
中文:2DPCA的重建误差公式为______。
英文:The reconstruction error formula in 2DPCA is ______.
答案:∥X−X^∥F2
解析:Frobenius范数衡量重建图像与原图的差异。 -
中文:2DPCA的酉矩阵V的列向量称为______。
英文:The column vectors of matrix V in 2DPCA are called ______.
答案:特征脸(eigenfaces)
解析:特征向量对应图像的主成分方向。 -
中文:2DPCA的投影维度d通常不超过______。
英文:The projection dimensionality d in 2DPCA usually does not exceed ______.
答案:原始列数(original column number)
解析:例如,23列的图像最多投影到23维。 -
中文:2DPCA的协方差矩阵计算复杂度为______。
英文:The computational complexity of 2DPCA's covariance matrix is ______.
答案:O(MN²)
解析:直接操作矩阵,复杂度显著低于PCA的O(M²N²)。 -
中文:2DPCA的权重矩阵W的维度为______×______。
英文:The dimensionality of the weight matrix W in 2DPCA is ×.
答案:N×d(如23×8)
解析:投影矩阵将原始矩阵压缩到d维。 -
中文:2DPCA的重建过程类似于______。
英文:The reconstruction process in 2DPCA is similar to ______.
答案:乐高拼图(Lego assembly)
解析:通过基矩阵(特征脸)和权重系数还原图像。 -
中文:2DPCA的缺点包括______和______。
英文:Drawbacks of 2DPCA include ______ and ______.
答案:计算资源需求高(high computational resources)、特征维度可能较高(higher feature dimensions)
解析:虽然协方差矩阵维度低,但投影矩阵可能较大。 -
中文:2DPCA的数学基础是______分解。
英文:The mathematical foundation of 2DPCA is ______ decomposition.
答案:奇异值(singular value)
解析:通过奇异值分解确定主成分方向。 -
中文:2DPCA的投影方向与______相关。
英文:The projection directions in 2DPCA are related to ______.
答案:图像局部结构(local image structure)
解析:保留像素列方向的结构信息(如五官排列)。 -
中文:2DPCA在______场景下优于PCA。
英文:2DPCA outperforms PCA in ______ scenarios.
答案:光照变化大或小样本(large illumination variations or small samples)
解析:保留结构信息,减少噪声影响。
综合对比表
| 指标 | PCA | LDA | 2DPCA |
|---|---|---|---|
| 数据形式 | 展平为向量(MN×1) | 展平为向量(MN×1) | 原始矩阵(M×N) |
| 监督性 | 无监督 | 有监督 | 无监督 |
| 核心目标 | 最大化方差 | 最大化类间分离 | 保留二维结构 |
| 协方差矩阵维度 | MN×MN | MN×MN | M×N |
| 计算复杂度 | 高 | 中 | 低 |
| 适用场景 | 通用降维 | 分类任务 | 小样本、实时任务 |
考试口诀
• PCA:展平→大矩阵→省空间但易乱。
• LDA:标签指导→类间分离→分类强。
• 2DPCA:留结构→小矩阵→快且准。
一句话记忆:
• PCA是“传统降维工具”,LDA是“分类加速器”,2DPCA是“结构保留专家”。

📘 Slide 9-3: "Why Do Dimensionality Reduction?"
🔹中英翻译:
Why Do Dimensionality Reduction?
为什么要进行降维?
 📘 Slide 9-4
📘 Slide 9-4
🔹中英翻译:
-
Many dimensions are related to each other.
许多维度之间是相互关联的。 -
These two values have the same meaning. If we jointly take these two into account, the difficulty of data analysis would be increased.
这两个值(62英里每小时 和 100公里每小时)意义是一样的。如果我们把两个都考虑进去,会加大数据分析的难度。
🔍解释:
有时候数据中不同的维度其实代表的是同一个意思,比如两个单位不同的速度。在分析数据时重复的信息会导致“维度灾难”,让模型变复杂,效率变低。
🧠通俗总结:
就像你说“今天气温是25°C”又说“今天气温是77°F”,其实只需要一个信息就够了。重复说只会让人更难分析。
📌英文填空题(Fill in the blank):
Redundant features can ______ the difficulty of data analysis.
A. reduce
B. increase
C. have no effect
D. eliminate
✅Answer: B
🧾中文解析: 重复维度会使分析变得更复杂。
📌英文选择题(Multiple choice):
Which of the following is a reason to reduce dimensionality?
A. To introduce more redundancy
B. To increase model complexity
C. To simplify data analysis
D. To make data inconsistent
✅Answer: C
🧾中文解析: 降维的主要目的是减少重复,简化分析。
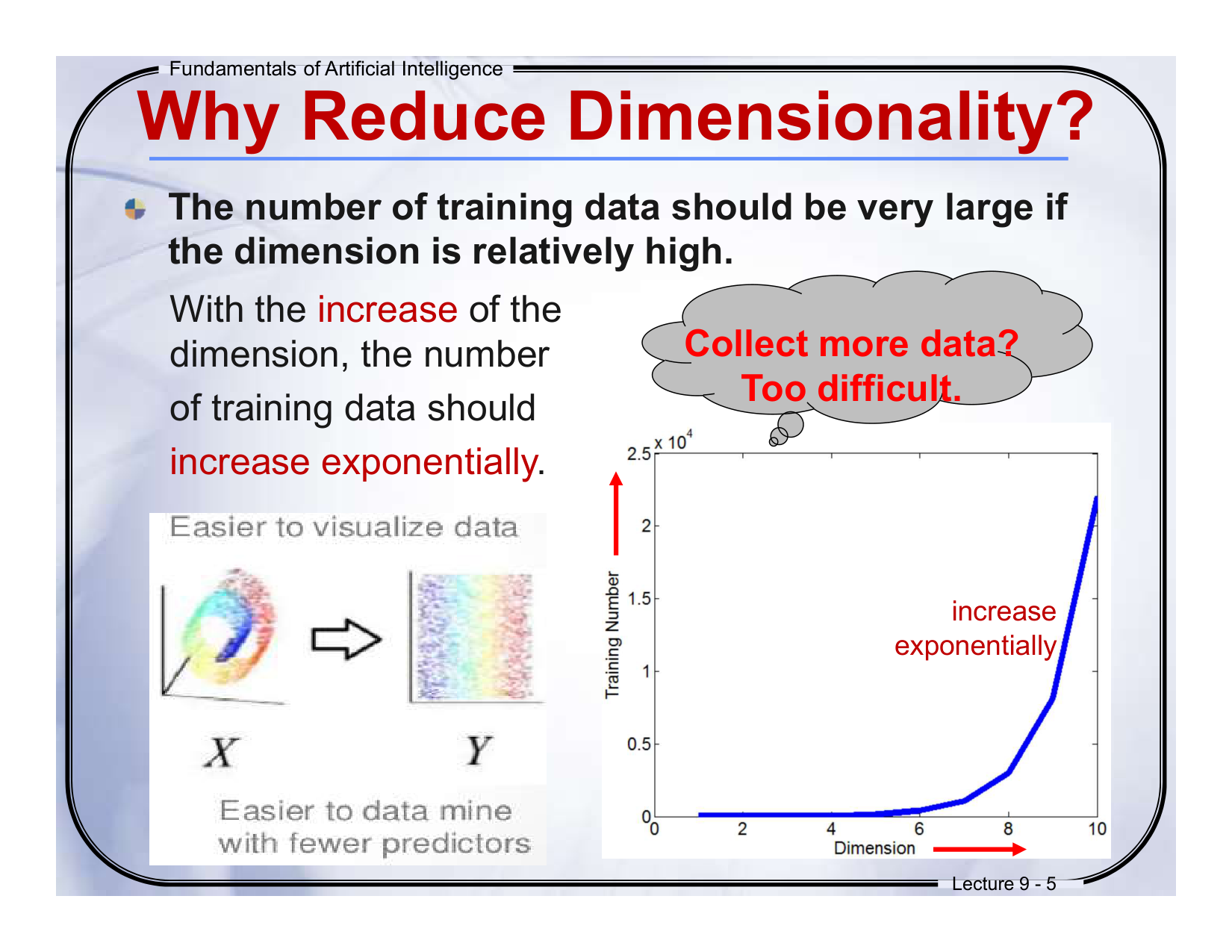 📘 Slide 9-5
📘 Slide 9-5
🔹中英翻译:
-
The number of training data should be very large if the dimension is relatively high.
如果维度较高,训练数据数量必须非常大。 -
With the increase of the dimension, the number of training data should increase exponentially.
随着维度的增加,训练数据的数量需要呈指数增长。 -
Collect more data? Too difficult.
收集更多数据?太难了。
🔍解释:
这是维度灾难的另一个表现:维度越多,我们就需要越多样本来覆盖每种可能性。否则模型学不到东西。
🧠通俗总结:
就像你要测试所有颜色组合,颜色多了,你得买无数颜料才够用!
📌英文填空题:
As dimensionality increases, the number of training samples needed ______.
A. decreases linearly
B. stays the same
C. increases exponentially
D. increases linearly
✅Answer: C
📌英文选择题:
Why is high dimensionality problematic in machine learning?
A. It makes the results easier to interpret
B. It reduces the need for data
C. It causes underfitting
D. It requires exponentially more data
✅Answer: D
🧾中文解析: 高维空间需要更多样本来填满可能性空间,否则模型学不到东西。
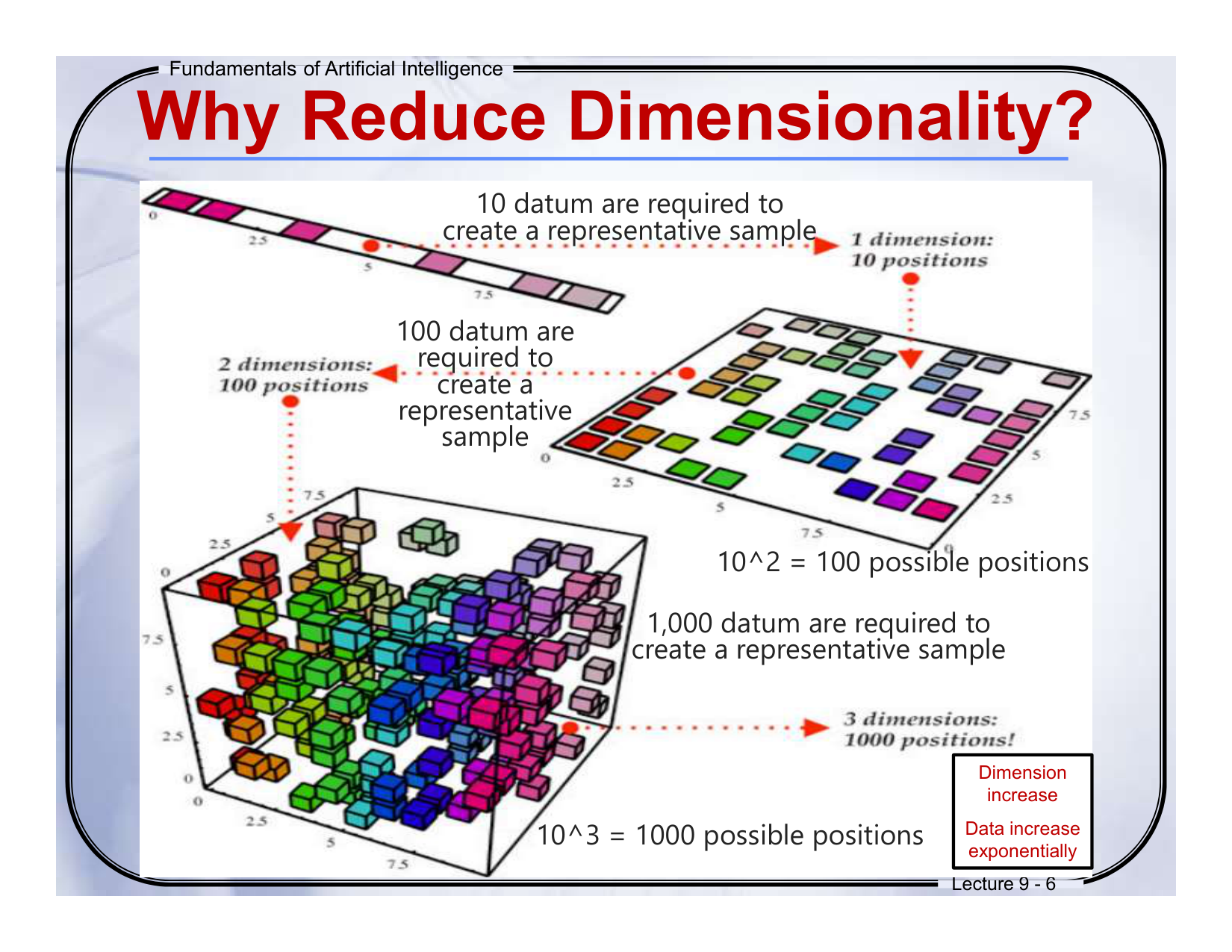
🧩 Slide 9-6:Why Reduce Dimensionality?
🔹中英对照翻译:
-
10 datum are required to create a representative sample
要创建一个有代表性的一维样本,需10个数据点 -
100 datum are required to create a representative sample
对二维来说,需要100个点 -
1000 datum are required to create a representative sample
三维则需要1000个点 -
10¹ = 10 positions, 10² = 100, 10³ = 1000
维度越高,可能的位置数呈指数增长
🔍讲解说明:
这是典型的“维度灾难”(curse of dimensionality):
每增加一个维度,你为了“填满”空间、获得代表性样本所需的数据数量就会 指数级增加。
🧠通俗理解:
想象你要在房间地板上撒糖果来覆盖每一个角落:
-
一条直线(1维)你只需放10个糖果
-
一个平面(2维)你需要放100个糖果
-
一个立方体(3维)你要放1000个糖果!
📌英文填空题(Fill in the blank)
As the number of dimensions increases, the amount of data needed to properly sample the space increases ______.
A. linearly
B. exponentially
C. randomly
D. negligibly
✅ Answer: B
🧾 解析: 样本数随维度指数级增加。
📌英文选择题(Multiple choice)
Which of the following best describes the curse of dimensionality?
A. Higher dimensions reduce the need for computation
B. More dimensions increase sample size requirements
C. Lower dimensions make analysis harder
D. Dimensions and sample size are unrelated
✅ Answer: B
🧾 解析: 高维空间下,覆盖空间需要更多样本,训练难度急剧增加。
🧩 Slide 9-7:Why Reduce Dimensionality?
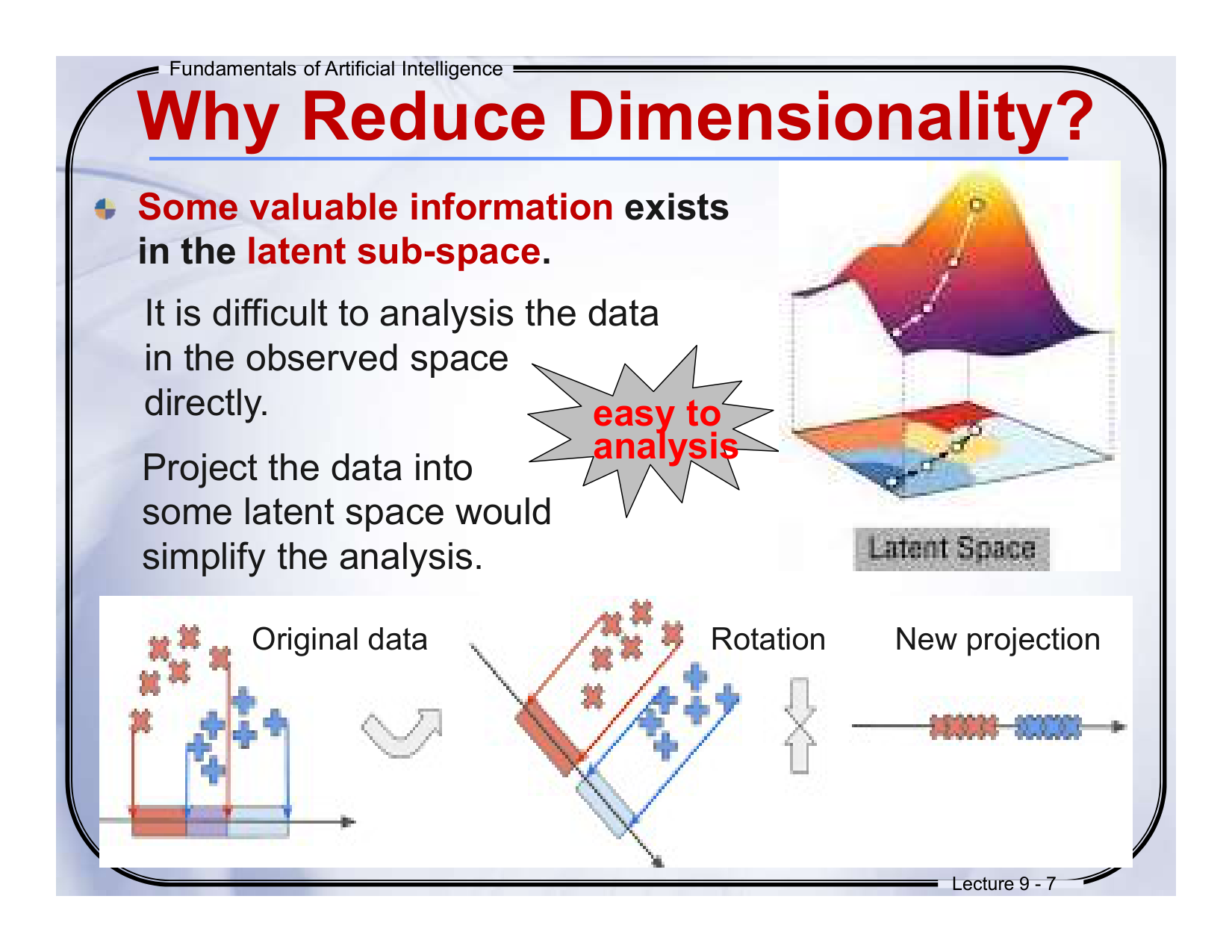 🔹中英对照翻译:
🔹中英对照翻译:
-
Some valuable information exists in the latent sub-space.
一些有价值的信息存在于“潜在子空间”中 -
It is difficult to analysis the data in the observed space directly.
在原始观测空间中分析数据是困难的 -
Project the data into some latent space would simplify the analysis.
将数据投影到一个潜在空间中可以简化分析过程
🔍讲解说明:
我们实际看到的数据可能很杂乱(图中左边的交叉样本),但通过线性变换或旋转,我们可以把它变换到一个 新空间,让数据变得更好分离、更易理解。
这就是“找出潜在变量”的核心思想,比如 PCA 主成分分析。
🧠通俗理解:
想象你用侧面看两个重叠的物体,看不清楚。但你换个角度,从上往下看,就能看到清晰的分界线了。
📌英文填空题(Fill in the blank)
Projecting data into a latent space can make analysis ______.
A. harder
B. meaningless
C. simpler
D. noisier
✅ Answer: C
📌英文选择题(Multiple choice)
Which of the following is an advantage of projecting data into a latent subspace?
A. It increases data complexity
B. It improves interpretability and separation
C. It removes valuable features
D. It adds more dimensions
✅ Answer: B
🧾 解析: 将数据映射到合适的空间可以提升可分性,简化建模。
🧩 Slide 9-8:Dimensionality Reduction
🔹中英对照翻译:
-
Dimensionality can be reduced by: combining features using a linear transformation
降维可以通过线性变换来合并特征 -
Linear combinations are particularly attractive because they are simple to compute and analytically tractable.
线性组合计算简单、易于解析,非常有吸引力 -
Given x ∈ Rⁿ, the goal is to find a matrix U such that y = Uᵀx ∈ Rᵏ, where k ≪ n.
目标是通过矩阵 U 把高维 x 映射为低维 y,其中 k 远小于 n。
🔍讲解说明:
这页讲的是降维的“数学操作”:我们通过矩阵乘法,把高维向量 x 转换成低维向量 y。核心是找出变换矩阵 U,它告诉我们:
"哪些方向保留信息最多,我们就保留那些方向。"
这就是 PCA、LDA 背后的基本思想!
🧠通俗理解:
就像把 10 张照片压缩成一张最能代表整体风格的照片。我们用数学找出“最重要的那几张”。
📌英文填空题(Fill in the blank)
Dimensionality reduction seeks a transformation from a high-dimensional space to a ______-dimensional space.
A. random
B. higher
C. lower
D. noisier
✅ Answer: C
📌英文选择题(Multiple choice)
Why are linear transformations used for dimensionality reduction?
A. They increase data redundancy
B. They are computationally simple and analytically useful
C. They always yield better models
D. They ignore data structure
✅ Answer: B
🧾 解析: 线性变换容易计算、便于理解,是实际降维的首选方法。
📘第9页:Principal Component Analysis (PCA)

 这一页是章节标题,介绍我们将讲解PCA——主成分分析,是最常用的降维方法之一。
这一页是章节标题,介绍我们将讲解PCA——主成分分析,是最常用的降维方法之一。
📘第10页:Introduction to PCA
🔁 中英对照翻译: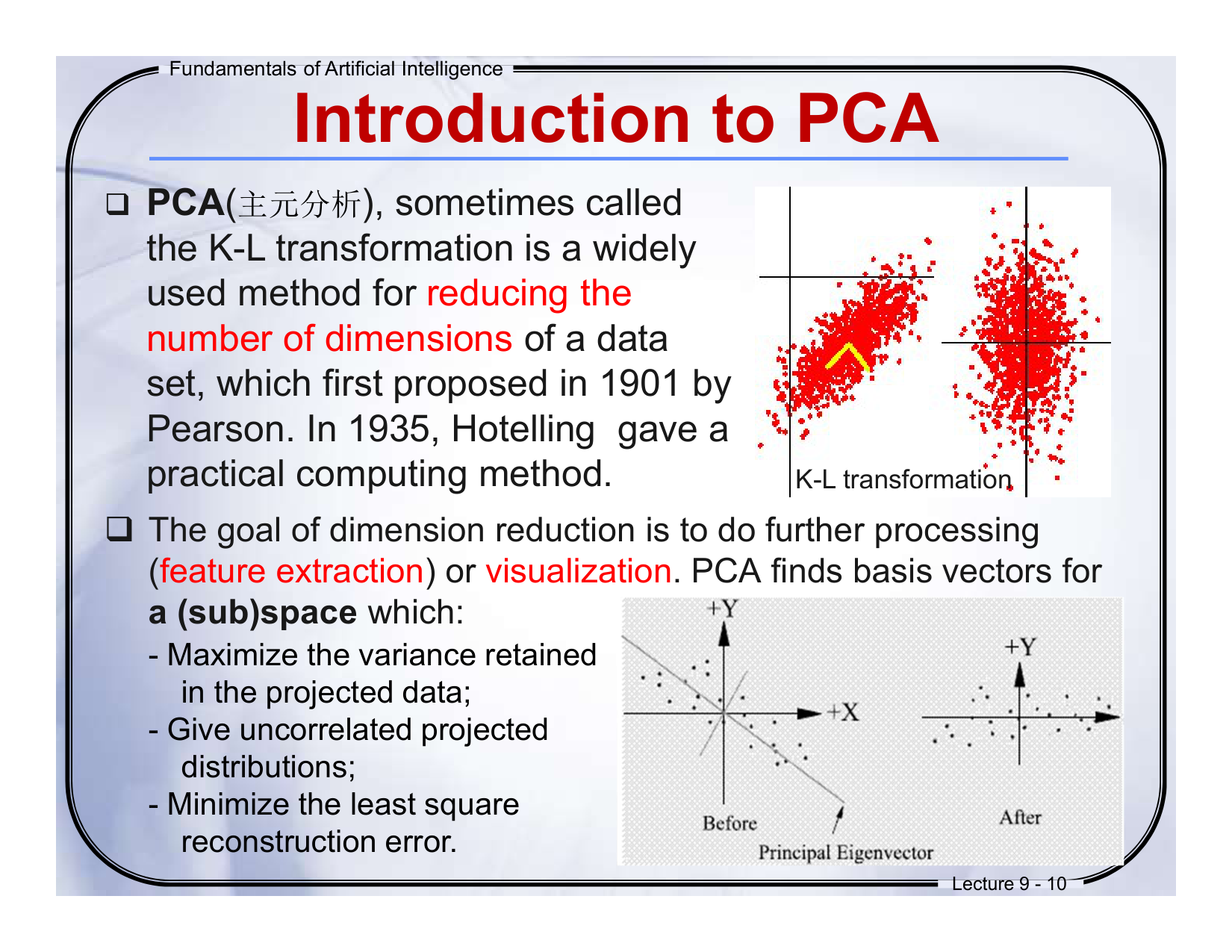
-
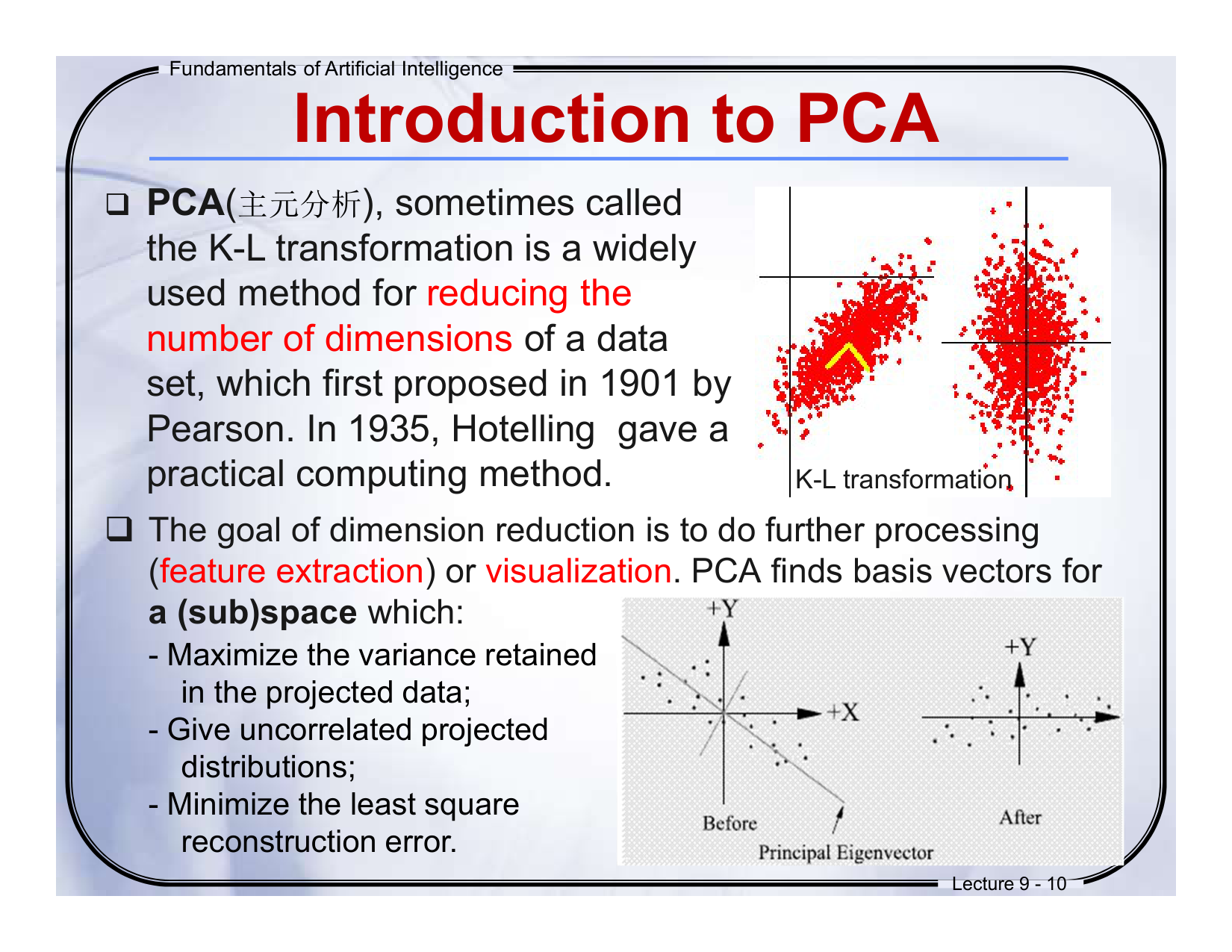
PCA(主元分析),有时被称为 K-L 变换,是一种广泛使用的数据降维方法。最早由 Pearson 在1901年提出,1935年 Hotelling 提供了一个实用的计算方法。
-
降维的目的是为了便于后续的处理(如特征提取)或可视化。PCA 会为某个 (子)空间 找到一组基向量,这些向量能:
-
最大程度保留投影后的方差;
-
使投影后的分布不相关;
-
最小化重建误差(最小二乘)。
-
🔍 通俗解释:
PCA 就像找出“最重要的方向”来看数据,把高维复杂的数据“压缩”到低维但仍保留大部分信息。比如从三维世界投影到二维纸上,但尽可能保留原始数据的结构。
📘第11页:Introduction to PCA(继续)
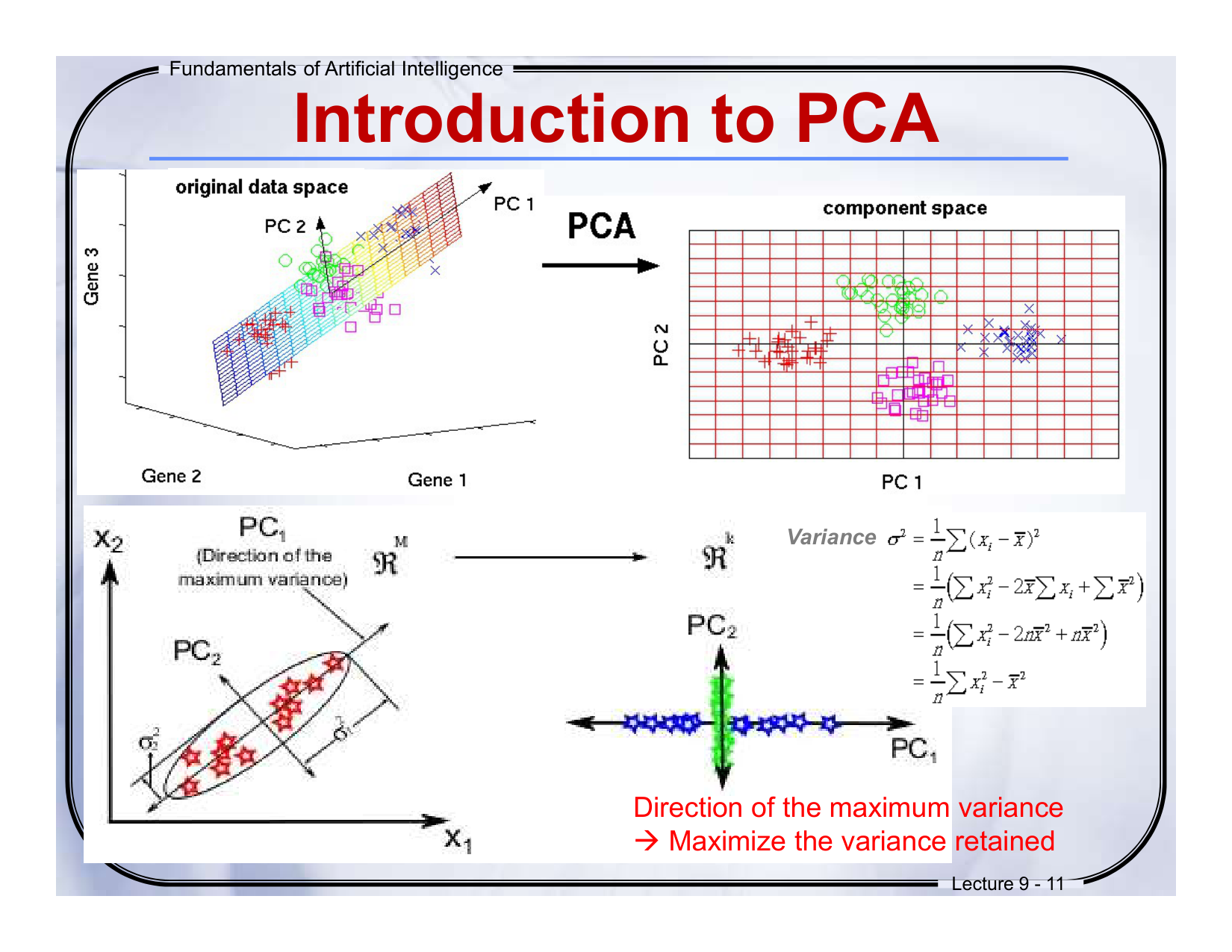
🔁 中英对照翻译: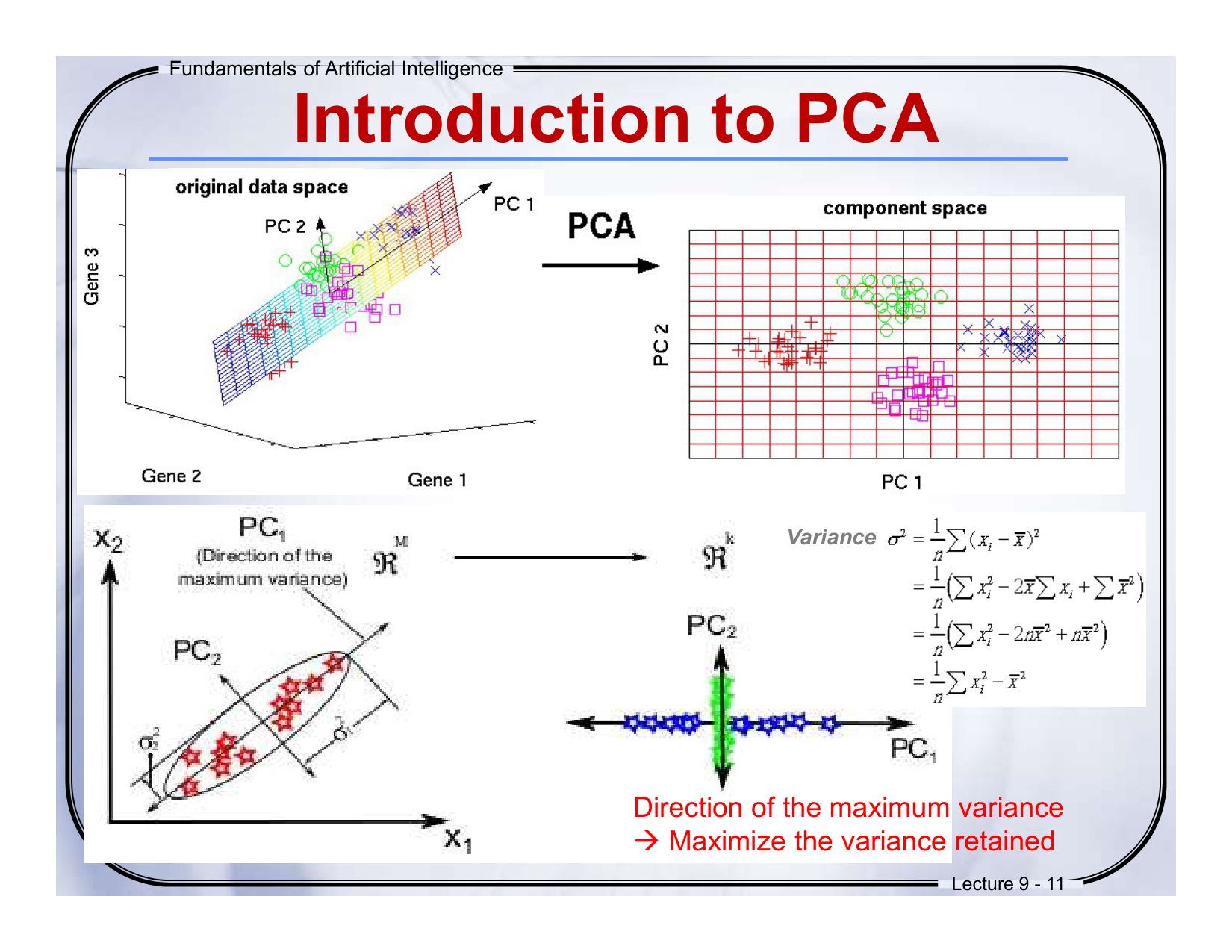
-
图左:原始数据空间中,找到方差最大的方向,定义为主成分(PC1, PC2)。
-
图右:将数据从原始空间变换到“成分空间”(component space)后,不同类别的数据被更清晰地区分开了。
🔍 通俗解释:
PCA的魔法在于:我们旋转坐标轴,让它们对准“信息最多”的方向(最大方差方向),这样我们就能用更少的坐标轴看清数据。
📘第12页:PCA in Image Space
 🔁 中英对照翻译:
🔁 中英对照翻译:
-
把下图中1x2像素的图像转换为向量表示。例如图像a₁变成
[120, 100]^T。 -
在图像空间中:
-
每张图像占据一个不同的点;
-
相似图像靠得很近;
-
不同图像则相距较远。
-
🔍 通俗解释:
就像把每张图像看作一个点,越相似的图像点就越近,这样我们可以在空间中“聚类”和“比较”图像。
✅ 出题环节(英文填空题 + 选择题)
Fill in the Blank:
PCA is a dimensionality reduction technique that finds the directions (called ____________) where the variance of the data is maximized.
Answer: principal components
**中文解析:**PCA的本质是找出方差最大的方向,这些方向就是“主成分”。
Multiple Choice:
Which of the following is NOT a goal of PCA?
A. Maximize variance in projected data
B. Make projected features uncorrelated
C. Increase reconstruction error
D. Enable better visualization
Answer: C
中文解析:PCA的目标是尽量最小化重建误差,而不是增大它。A、B、D都是PCA追求的目标。
✅ 简化版总结一句话:
PCA 就像一个聪明的压缩师傅,它会压缩你手里的数据:
保留最重要的信息,
去掉重复的东西,
还能让你以后有可能把原来的信息大致恢复回来。
🎯 一、什么是“方差”?它和“原始信息”有什么关系?
✅ 方差 = 数据的“变化程度”
方差(variance)衡量的是数据的发散程度。在一组数中,如果数值变化大,说明它们差异大、信息量也大;如果都差不多,那信息就比较“平”。
📌 为啥方差越大,说明信息越多?
你可以这样理解:
-
数据如果很分散(方差大),说明它在这个方向上“有东西”,有差异、有结构、有模式。
-
如果数据都挤成一团(方差小),那说明这个方向没啥用,数据都差不多,不携带有用信息。
🧠 直觉比喻:
-
你拍了十张照片,如果大家脸的位置变化很大(方差大),你可以分析出谁笑了、谁转头了。
-
如果十张照片几乎一模一样(方差小),你根本分析不出啥。
✌️ 二、为什么 PCA 会保留最大方差方向?
📌 PCA 的核心任务就是:
找出一组“方向”(也就是新坐标轴)——这些方向上的数据变化最大(也就是方差最大)。
👉 所以 PCA 做的第一件事就是:
找到数据变化最剧烈的方向,然后把原始数据投影上去,这样保留的信息最多。
这就是所谓的 最大方差投影原则。
🔄 三、为啥 PCA 会让投影后的分布不相关?
📌 不相关(Uncorrelated)= 每个方向都独立、不会重复说信息
PCA 的另一个目标是把原来的维度重新组合成一组“正交”(互相垂直)的新方向,也就是说:
每个主成分(主轴)携带的都是全新的、不重复的信息。
这个就像你做报告时,不希望每个人重复发言:PCA 找的方向互相之间没有“废话”。
🔄 四、为啥 PCA 会最小化重建误差(最小二乘)?
这个是个数学结果:
PCA 找到的前 k 个主成分方向,构成的子空间,是在所有可能的 k 维子空间中:
对于原始数据来说,投影误差(也就是从原始点到子空间的距离平方和)最小的。
这就是所谓的 最小平方重建误差。
🧠 比喻:
-
你想在一张图里画尽量像的“简笔画版人脸”。
-
PCA 就是帮你找出最适合画的几笔,能把人脸画得最像(误差最小)。
✅ 总结一下关系链:
| 概念 | 直觉解释 | 与 PCA 的关系 |
|---|---|---|
| 方差大 | 说明有变化、有信息 | PCA专挑这种方向来保留信息 |
| 不相关 | 不重复,独立的内容 | PCA找出的主轴彼此独立,信息无重复 |
| 最小重建误差 | 压缩后还原尽可能接近原图 | PCA提供误差最小的子空间 |


第1张图核心内容解析
中文核心观点
- PCA定义:主成分分析用于计算最能代表图像空间小区域的向量,这些向量是训练集协方差矩阵的特征向量。
- 子空间构建:特征向量定义图像的子空间(称为图像空间),降维过程称为Karhunen-Loève变换或PCA。
- 可视化示例:通过PCA将二维数据降维到一维(图中蓝色和橙色点沿绿色主线分布)。
English Core Idea
- PCA Definition: PCA calculates vectors representing small regions of image space, which are eigenvectors of the training set's covariance matrix.
- Subspace Construction: Eigenvectors define an image subspace (image space), and the dimensionality reduction process is called Karhunen-Loève transform or PCA.
- Visualization: Example shows 2D data reduced to 1D via PCA (blue/orange points aligned along a green line).
第1张图详细讲解
-
技术逻辑
• 协方差矩阵:反映图像像素间的相关性,PCA通过计算其特征向量找到数据主方向。• 特征向量:代表数据最大方差方向,降维后保留主要信息,剔除噪声或冗余。
• Karhunen-Loève变换:数学上等价于PCA,强调线性变换的无损压缩特性。
-
应用意义
• 降维:减少数据存储和计算成本(如从2D到1D)。• 去噪:去除次要特征(如图中橙色点偏离主方向的部分)。
题目设计
填空题
- PCA降维过程也被称为______变换。
答案:Karhunen-Loève
解析:PPT明确提到Karhunen-Loève变换是PCA的数学名称。
选择题
2. PCA的核心目标是?
A. 增加数据维度
B. 保留数据最大方差方向
C. 提高图像分辨率
D. 压缩文件格式
答案:B
解析:PCA通过特征向量保留数据最大方差方向,实现降维。
口语化总结
PCA就像给数据“瘦身”——比如你有一堆乱糟糟的照片,PCA会找到它们共同的特征方向(比如脸的方向、光线),把高维数据压成低维,同时保留最重要的信息。比如二维变一维,就像把平面上的点按一条线排列,只看这条线上的位置,忽略其他方向的变化。
第2张图核心内容解析
中文核心观点
- 生物识别问题:高维图像(如256×256像素)占据极大空间,同类图像聚集在小区域,不同类分布在不同区域。
- PCA应用:通过降维找到“最近邻”向量,实现人脸识别(流程:输入图像→检测→特征提取→分类)。
English Core Idea
- Biometric Challenge: A 256x256 pixel image is a point in 65,536D space; same types cluster in small regions, different types in distinct areas.
- PCA Application: Reduce dimensionality to find the nearest "known" vector for identification (pipeline: input → detection → feature extraction → classification).
第2张图详细讲解
-
技术逻辑
• 高维数据问题:直接处理65,536维图像计算量巨大,PCA将其压缩到低维可管理的空间。• 最近邻分类:降维后,同类图像在低维空间中距离更近,通过计算距离(如欧氏距离)识别身份。
-
流程细节
• 人脸检测/跟踪:定位图像中的人脸区域。• 特征提取:用PCA提取关键特征(如眼睛间距、下巴形状)。
• 分类:比对已知人脸特征库,匹配最近邻。
题目设计
填空题
- 在PCA生物识别中,分类的关键是找到图像空间中的______向量。
答案:最近邻(nearest 'known')
解析:PPT强调通过降维后计算与“已知”向量的距离进行识别。
选择题
2. 为什么PCA适用于高维图像识别?
A. 提高图像分辨率
B. 降低计算复杂度并保留关键特征
C. 增加数据维度
D. 压缩文件大小
答案:B
解析:PCA通过降维减少计算量,同时保留区分不同类别的关键特征(如人脸结构)。
口语化总结
想象一下,你要在一堆高分辨率照片里找某个人,直接比对所有像素点会累死电脑。PCA就像给照片“打标签”——把脸型、五官比例等关键信息抽出来,压缩成简记。比如把一张脸从6万多个数据点压成几十个特征值,然后只要比较这些简化的标签,就能快速认出是谁。流程就像先框出人脸,再提取特征,最后比对新旧标签。
第1张图核心内容解析
中文核心观点
- 数据集划分:20张28×23灰度人脸图像分为2类(c1/c2),每类10张。训练集X取每类前5张,测试集Y为剩余10张。
- 数据维度:每张图像展平为644维向量(28×23=644)。
- 教学阶段:标记为“Lecture 9-15”,属于PCA应用的第一步——数据准备。
English Core Idea
- Dataset Split: 20 images (2 classes, 10 per class) split into training set X (first 5 per class) and test set Y (remaining 5 per class).
- Image Vectorization: Each 28×23 image is flattened into a 644-dimensional vector.
- Phase: Step 1 of PCA ("Lecture 9-15"), focusing on data preparation.
第1张图详细讲解
-
技术逻辑
• 数据划分原则:训练集与测试集按类别均分(每类前5训练,后5测试),确保类别平衡。• 图像向量化:将2D图像转为1D向量,便于后续数学运算(如计算均值、协方差矩阵)。
-
关键细节
• 样本量:训练集共10张(每类5张),测试集10张(每类5张)。• 维度统一:所有图像统一为644维,保证计算一致性。
题目设计
填空题
- 每张28×23的图像被展平为______维向量。
答案:644
解析:28×23=644,图像数据需向量化以进行PCA计算。
选择题
2. 训练集X的构建方法是?
A. 随机选取10张图像
B. 每类随机选5张
C. 每类取前5张作为训练
D. 全部图像用于训练
答案:C
解析:PPT明确说明训练集X由每类前5张组成,其余为测试集Y。
口语化总结
这一步就像准备考试题——把20张人脸图片分成“练习题”(训练集)和“考试题”(测试集)。每类题目(比如猫和狗)各出5道练手,剩下5道留着考试。所有图片都被“压平”成一串数字(644位),方便计算机处理。
第2张图核心内容解析
中文核心观点
- 均值计算:定义总均值m、类均值m1/m2的数学公式,用于中心化数据。
- 符号说明:E为数学期望,样本索引i=1,2;f=1,…,5。
English Core Idea
- Mean Calculation: Formulas for total mean (m) and class means (m1, m2) to center data.
- Notation: E denotes expectation, with sample indices i=1,2 (classes) and f=1,…,5 (samples per class).
- Phase: Step 2 of PCA ("Lecture 9-16"), focusing on data normalization.
第2张图详细讲解
-
技术逻辑
• 中心化:通过减去均值(m/m1/m2)消除数据偏差,使PCA关注方向性变化而非绝对位置。• 公式细节:m1为c1类5个样本的均值,m2为c2类5个样本的均值,m为整体均值。
-
应用意义
• 数据标准化:确保不同类别的数据分布可比。• 降维基础:后续散射矩阵计算依赖中心化后的数据。

题目设计
填空题
- 在PCA中,数据标准化需减去______(总均值/类均值)。
答案:总均值
解析:总均值m是全局平均值,用于将数据中心化。
选择题
2. 公式中的E(·)代表什么?
A. 方差
B. 数学期望(均值)
C. 协方差矩阵
D. 特征值
答案:B
解析:E(·)是数学期望符号,此处计算样本均值。
口语化总结
这一步就像调整天平——把所有人脸图片的平均亮度、对比度统一。比如先算出所有猫脸的平均耳朵长度,再让每张图片减去这个平均值,消除整体偏差,只关注差异部分。
第3张图核心内容解析
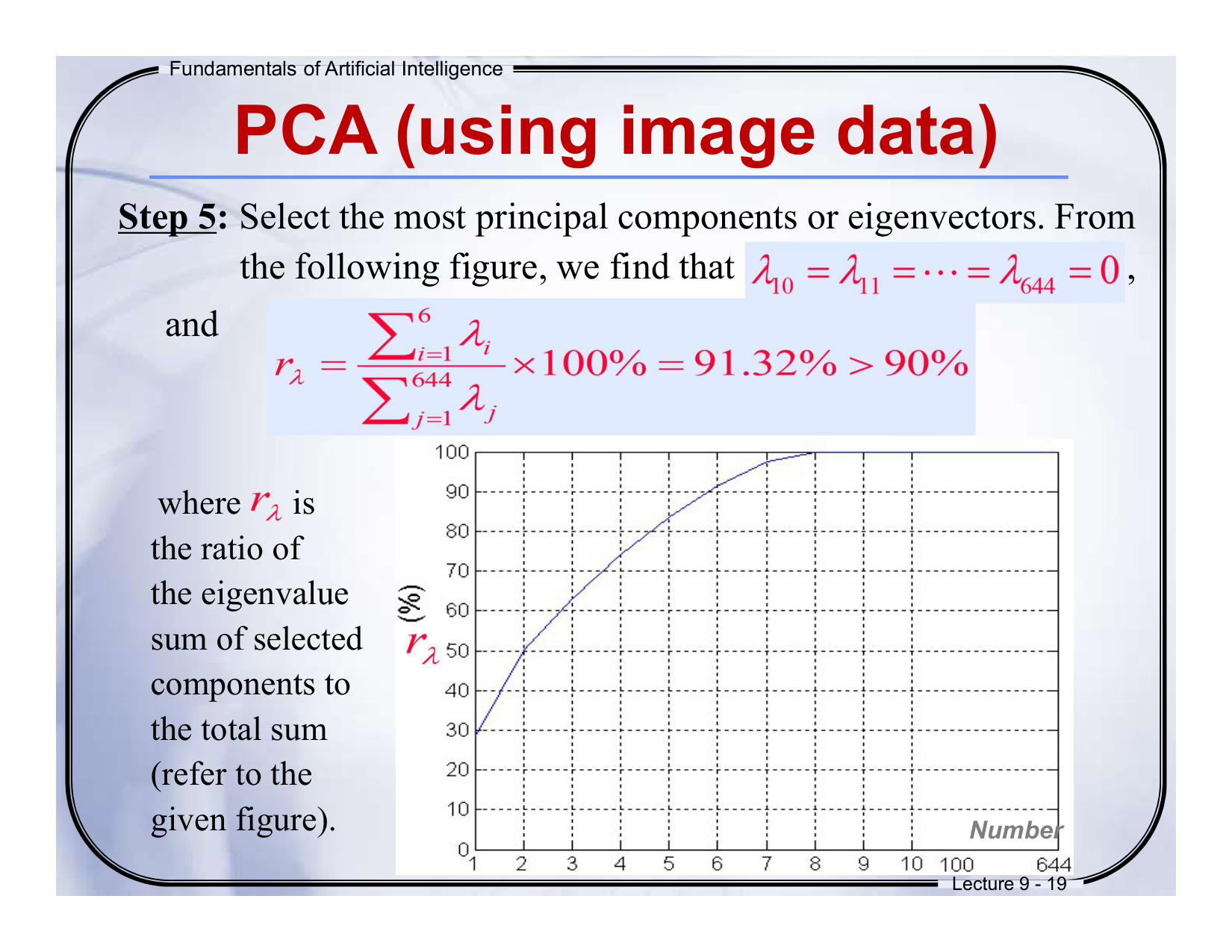
中文核心观点
- 总散射矩阵:计算St公式,其维度为644×644,反映数据方差分布。
- 降维示例:图示从2D到1D、3D到2D的PCA投影过程。
- 教学阶段:标记为“Lecture 9-17”,属于PCA第三步——协方差矩阵分析。
English Core Idea
- Total Scatter Matrix: St is a 644×644 matrix quantifying data variance.
- Dimensionality Reduction: Visual examples show projecting 2D→1D and 3D→2D.
- Phase: Step 3 of PCA ("Lecture 9-17").
第3张图详细讲解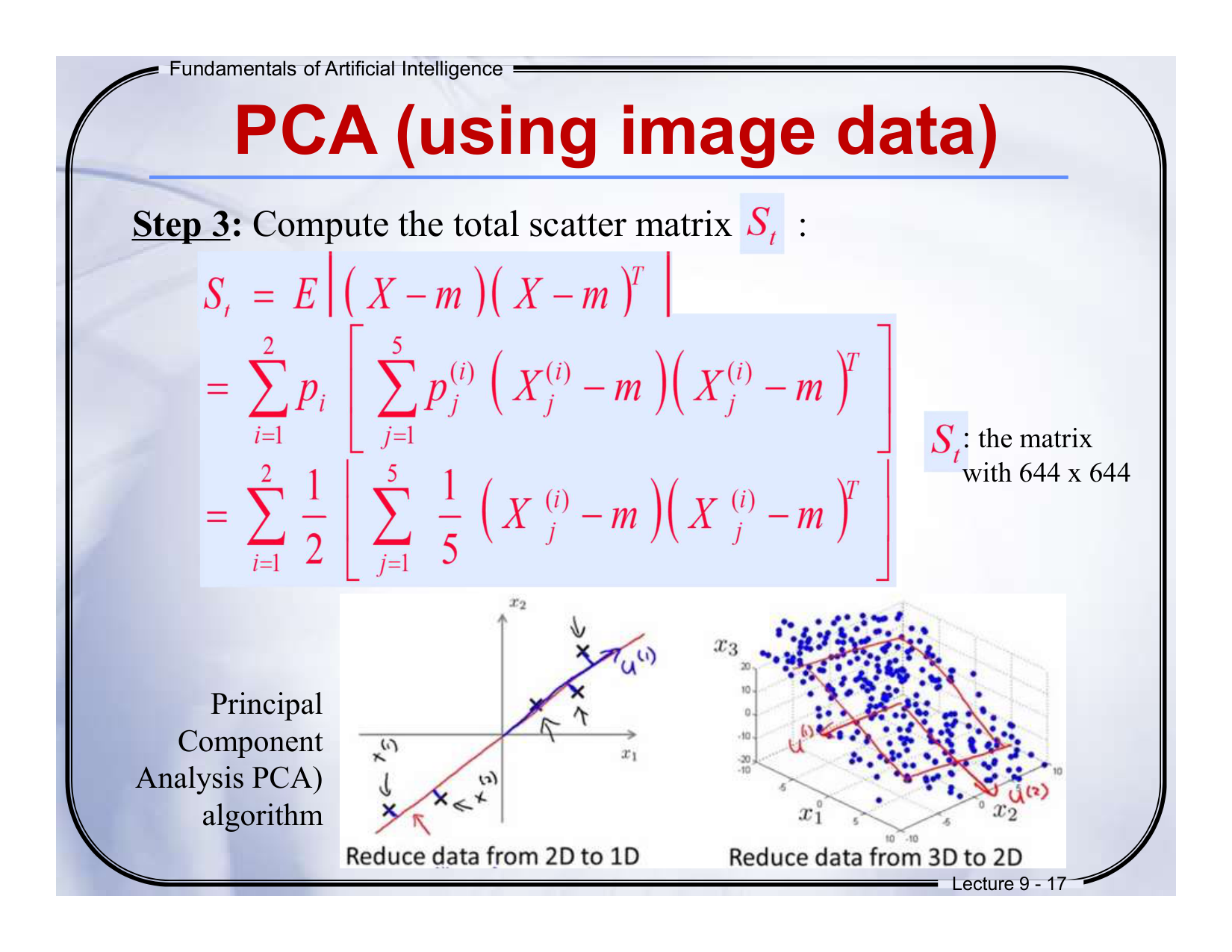

-
技术逻辑
• St的作用:通过计算数据与均值的偏离,确定数据主方向(方差最大方向)。• 降维本质:保留最大方差方向(如从2D保留x轴方向,丢弃y轴噪声)。
-
图示解读
• 左图:2D数据沿主成分(绿线)投影,保留主要信息。• 右图:3D数据降维到2D平面,舍弃次要维度。
题目设计
填空题
- 总散射矩阵St的维度是______×______。
答案:644, 644
解析:St是644维向量的协方差矩阵,故为方阵。
选择题
2. PCA降维的核心目标是?
A. 增加数据维度
B. 保留最大方差方向
C. 提高数据分辨率
D. 压缩文件大小
答案:B
解析:St的方差最大方向即主成分,决定降维后保留的信息量。
口语化总结
这一步就像用鱼竿钓鱼——总散射矩阵St帮你找到鱼群聚集的方向(方差最大的方向)。比如从2D人脸图中找到“脸型”主方向,把侧面的干扰信息(如头发)过滤掉,只保留正面特征。
第4张图核心内容解析
中文核心观点
- 特征分解:计算St的特征值(λ)和特征向量(φ),得到9个非零特征脸。
- 特征脸意义:高特征值的特征向量代表数据主要变化(如五官形状)。
English Core Idea
- Eigen Decomposition: Solve λφ = Stφ to get 9 non-zero eigenvectors (eigenfaces).
- Key Variation: Largest eigenvalues correspond to most significant facial variations.
- Phase: Step 4 of PCA ("Lecture 9-18").
第4张图详细讲解
-
技术逻辑
• 特征脸:特征向量可视化为图像,捕捉数据变化模式(如眼睛开合、嘴角变化)。• 特征值筛选:大特征值对应的特征脸保留核心信息,小特征值视为噪声。
-
实际应用
• 人脸识别:用特征脸构建分类器,通过投影距离判断身份。• 压缩表示:将原始644维图像压缩到少数特征脸(如9维)。
题目设计
填空题
- 特征脸是______的可视化结果。
答案:特征向量(或主成分)
解析:特征脸φ是St的特征向量,代表数据主方向。
选择题
2. 选择大特征值的原因是?
A. 减少计算量
B. 保留主要变化信息
C. 提高图像分辨率
D. 简化代码
答案:B
解析:大特征值对应的特征脸捕捉数据最大方差,即关键变化(如五官结构)。
口语化总结
这一步就像挑出最重要的表情——特征脸是数据变化的“主心骨”。比如9个特征脸分别代表脸型、眼睛位置、鼻子形状等核心特征,而其他细节(如眼镜反光)被过滤掉,只保留最能区分人脸的信息。


1. 特征脸示例(Examples of Eigenfaces)
- 把图像数据里的一些关键特征提取出来,这些特征用图像表示就像一张张脸,所以叫 “特征脸”。它们组合在一起,能表示很多不同的人脸图像,就像搭积木一样,这些特征脸是基本的积木块。
2. 特征向量(Eigenvectors)
- 选几个关键的特征(前M个特征向量),能简化数据(降维),但选太少,图像的很多细节就丢了,图像之间就难区分。比如本来每个人脸有不同的眉毛、眼睛形状,选太少特征,这些细节没了,看谁都差不多。
3. PCA 处理流程(PCA Processing Procedure)
- 先把图像 “拍扁” 成一串数字(转成向量),然后计算这些数字的分布特征(协方差矩阵的特征值和向量)。训练时,用一堆图像算出特征脸,再把每个图像用这些特征脸表示;测试时,把输入的图像也转成类似的表示,然后看和哪个已知图像最像(通过距离计算)。就像把人脸变成密码,训练时记密码,测试时看新密码和哪个旧密码最接近。
4. 特征脸的问题(Eigenfaces Problems)
- 如果输入图像的头大小和特征脸不匹配,识别效果就差。比如特征脸是大头,输入是小头,就难认对。而且在不同光照、角度、尺寸变化下,正确率不同,尺寸变化时正确率只有 64%。
5. PCA 总结(PCA Summary)
- 优点:
- 减少数据量,让图像数据更简洁。
- 让图像还原时误差最小(满足最小均方误差)。
- 去掉图像数据之间的一些关联(消除相关性),让数据更 “干净”。
- 缺点:
- 特征脸不区分人脸的形状和外观细节,比如分不清是脸圆还是脸长。
- 没用到图像的类别信息(比如没管这张脸是张三还是李四的类别标签)。
- 不能直接处理图像,得先把图像转成一串数字(向量),麻烦。








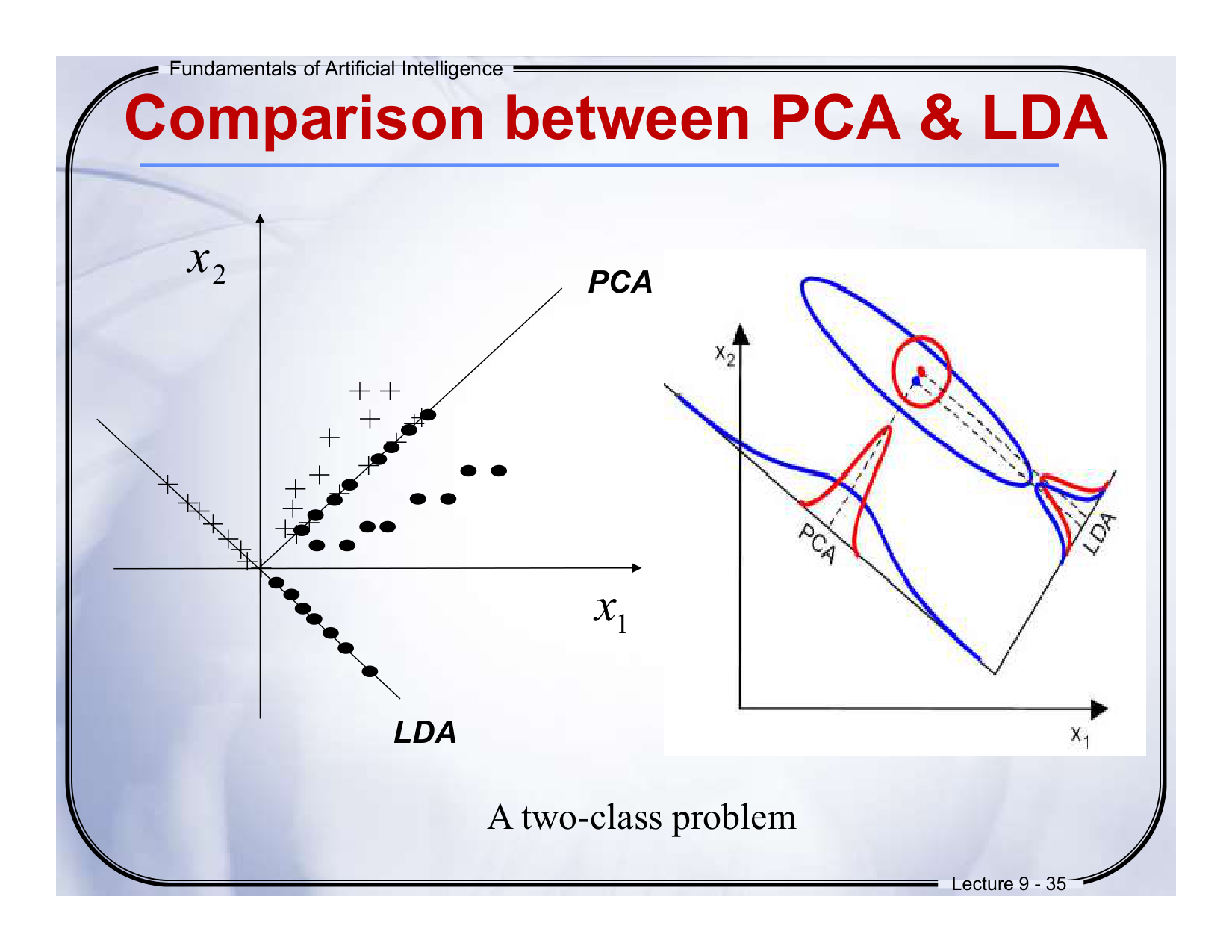

一、核心知识点总结(期末重点)
1. PCA vs LDA
| 技术 | 目标 | 核心方法 | 应用场景 | 通俗比喻 |
|---|---|---|---|---|
| PCA | 最大化数据方差(找主成分) | 协方差矩阵特征分解 | 降维、去噪、信号压缩 | 像整理书包,只塞最常用的书(省空间但可能乱) |
| LDA | 最大化类间分离(分类导向) | 类间散度/类内散度比值优化 | 分类任务(如人脸识别) | 像按科目分开放试卷,考试时秒找答案 |
考试重点:
• PCA是无监督方法(不需要标签),LDA是有监督(需类别标签)。
• PCA保留最大方差方向,LDA投影后类间距离最大。
2. Eigenface vs Fisherface
| 技术 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Eigenface | 全局特征(最大化人脸空间散布) | 简单、计算快 | 易受光照/背景干扰 | 光照稳定、数据量大 |
| Fisherface | 平衡类间差异与类内紧凑性 | 鲁棒性强(小样本更稳) | 计算复杂度高 | 光照变化大、样本少 |
考试重点:
• Eigenface是“整体长相”,Fisherface是“五官特征”。
• Fisherface通过拉近同类脸、推远异类脸,类似“人脸身份证”。
二、通俗解题技巧(期末提分)
选择题高频考点
-
PCA的核心目标?
• ✅ 正确选项:保留最大方差方向• ❌ 干扰项:提高分辨率、增加维度
-
LDA为什么适合分类?
• ✅ 正确选项:投影后同类数据更聚集,异类更分开• ❌ 干扰项:压缩数据、去噪
-
Fisherface比Eigenface更擅长?
• ✅ 正确选项:处理光照变化或小样本数据• ❌ 干扰项:加快计算速度
填空题万能公式
-
PCA通过______矩阵计算主成分方向。
• 答案:协方差• 解析:协方差矩阵反映数据相关性,PCA分解其特征向量。
-
Fisherface的核心是平衡______散度和______散度。
• 答案:类间、类内• 解析:公式 J(w)=wTSWwwTSBw,分子最大化类间差异,分母最小化类内差异。
三、口语化记忆口诀
PCA vs LDA
• PCA:像吃自助餐,专挑自己爱吃的(高方差特征),但可能夹到不喜欢的菜(噪声)。
• LDA:像考试划重点,老师说“这部分必考!”(类间差异),直接背熟就能高分。
Eigenface vs Fisherface
• Eigenface:普通证件照,记录整体长相,但光线不好时可能看不清脸。
• Fisherface:专业艺术照,只拍鼻梁、眼睛等关键特征,灯光再暗也能认出你。
四、真题实战(附解析)
例题1(选择题)
以下哪种方法适合高光照变化的人脸识别?
A. PCA
B. LDA
C. Eigenface
D. Fisherface
答案:D
解析:Fisherface通过最小化类内散度(如光照差异),增强类间区分度,鲁棒性更强。
例题2(填空题)
PCA的降维过程也被称为______变换,其数学目标是______。
答案:Karhunen-Loève;最大化数据方差
解析:Karhunen-Loève变换是PCA的数学名称,核心是找到方差最大的主成分。
五、期末复习策略
- 概念对比:画表格区分PCA/LDA/Eigenface/Fisherface(目标、方法、应用)。
- 公式记忆:重点背LDA的类间散度公式 SB=∑i=1cNi(μi−μ)(μi−μ)T。
- 图像联想:看到PCA想“整理书包”,看到LDA想“按科目分试卷”。
一句话总结:
• PCA:无监督降维,省空间但可能乱。
• LDA:有监督分类,精准但需标签。
• Eigenface:整体特征,快但易受干扰。
• Fisherface:局部特征,稳但计算慢。
第1张图核心内容翻译(中英对照)

第1张图详细讲解
-
技术逻辑
• 课程定位:2DPCA是PCA的二维扩展,直接处理图像矩阵而非向量,避免高维数据计算复杂度。• 核心改进:保留图像二维结构,协方差矩阵维度更低(例如,MN×MN → M×N)。
题目设计
填空题
- 2DPCA直接处理______而非向量,避免协方差矩阵过大。
答案:图像矩阵
解析:传统PCA需将图像展平为向量,而2DPCA直接操作原始矩阵。
选择题
2. 2DPCA的主要优势是?
A. 计算更快
B. 保留图像二维结构
C. 无需训练数据
D. 适合小样本
答案:B
解析:2DPCA直接处理图像矩阵,保留二维结构,避免PCA的“结构丢失”问题。
口语化总结
2DPCA就像整理试卷时不撕掉页码——传统PCA把试卷撕成碎片(展平向量),容易丢信息;而2DPCA保留试卷的页码顺序(二维结构),更完整也更省空间。
第2张图核心内容翻译(中英对照)
中文核心观点
-
PCA的缺点:
• 图像二维结构丢失(展平为向量后失去空间关系)。• 协方差矩阵过大(MN×MN),小样本下难以准确估计。
-
公式示例:协方差矩阵St的构建过程。
English Core Idea
-
PCA Disadvantages:
• Loss of 2D image structure (flattened to vector).• Huge covariance matrix (MN×MN), hard to estimate with small samples.
-
Formula: St=n1XTX, where X is an MN×1 vector.
第2张图详细讲解
-
技术逻辑
• 结构丢失:将28×23的人脸图像展平为644维向量,丢失像素间空间关系(如眼睛与鼻子的相对位置)。• 协方差矩阵问题:644×644矩阵需大量样本才能准确估计,小样本时噪声占比高。
题目设计
填空题
- PCA需要将图像转换为______维向量,导致______结构丢失。
答案:MN(如644);二维
解析:展平操作破坏图像空间关系,如相邻像素的关联性被忽略。
选择题
2. 为什么PCA的协方差矩阵难以用小样本评估?
A. 矩阵维度太高
B. 计算速度慢
C. 需要标签数据
D. 仅适用于分类任务
答案:A
解析:协方差矩阵维度为MN×MN,样本不足时无法覆盖所有特征组合。
口语化总结
PCA就像用一张纸写完所有科目笔记——虽然省纸(降维),但数学公式(协方差矩阵)会变得超大,小样本时根本填不满关键信息,反而漏洞百出。
第3张图核心内容翻译(中英对照)
中文核心观点
-
2DPCA方法:
• 直接使用原始图像矩阵构建协方差矩阵(尺寸更小)。• 投影公式:y=Xw=∑wiXi(各列加权求和)。
-
核心问题:如何找到最优投影向量w?
English Core Idea
-
2DPCA Method:
• Use original image matrix to build covariance matrix (smaller size).• Projection formula: y=Xw=∑wiXi.
-
Key Question: How to find the optimal projection vector w?
第3张图详细讲解
-
技术逻辑
• 协方差矩阵优化:传统PCA的协方差矩阵是MN×MN,2DPCA通过保留图像列方向(如人脸五官排列),将矩阵降为M×N(如28×23)。• 投影意义:加权各列(如眼睛、鼻子区域的像素),提取主成分方向。
题目设计
填空题
- 2DPCA的协方差矩阵尺寸为______,比PCA的______更小。
答案:M×N;MN×MN
解析:例如,28×23的图像,2DPCA协方差矩阵为28×23,而PCA为644×644。
选择题
2. 2DPCA的投影公式中,w的作用是?
A. 调整图像亮度
B. 决定各列(如五官)的权重
C. 压缩数据维度
D. 去除噪声
答案:B
解析:w是投影向量,决定各列(如眼睛、鼻子区域)对最终特征的贡献比例。
口语化总结
2DPCA的投影就像给五官打分——权重w决定哪个部位更重要(比如鼻子占50%,眼睛占30%),最后综合评分(投影值y)反映人脸特征。
第4张图核心内容翻译(中英对照)
中文核心观点
-
数据划分:
• 两类人脸(c1/c2),每类10张样本(28×23像素)。• 训练集X:每类前5张;测试集Y:剩余5张。
-
图像示例:训练集和测试集的黑白人脸图像。
English Core Idea
-
Data Split:
• Two classes (c1/c2), 10 samples each (28×23).• Training set X: first 5 per class; Test set Y: remaining 5.
-
Images: Display of training and test images.
第4张图详细讲解
-
技术逻辑
• 类别平衡:确保训练和测试集中每类样本数量相同,避免偏差。• 低维表示:每张图像从644维降至2×23=46维(假设投影到2个主成分)。
题目设计
填空题
- 训练集X由每类前______张图像组成,测试集Y包含剩余______张。
答案:5;5
解析:按类别均分,保证模型泛化能力。
选择题
2. 数据划分的主要目的是?
A. 减少计算量
B. 防止过拟合
C. 提高分辨率
D. 压缩数据
答案:B
解析:训练集用于学习特征,测试集验证模型,避免用全部数据训练导致的过拟合。
口语化总结
这一步就像分试卷——训练集是平时练习题,测试集是期末考卷。每类题目(如选择题、填空题)各出5道练手,剩下5道留着考试,确保公平性。
第5张图核心内容翻译(中英对照)
中文核心观点
-
均值计算:
• 总均值M:所有样本的平均矩阵(M×N)。• 类均值M1/M2:每类样本的平均矩阵。
-
公式对比:
• PCA的均值m是MN×1向量,2DPCA的均值M是M×N矩阵。
English Core Idea
-
Mean Calculation:
• Total mean M: Average of all samples (M×N matrix).• Class means M1/M2: Average of each class.
-
Formula Contrast:
• PCA: m (MN×1 vector).• 2DPCA: M (M×N matrix).
第5张图详细讲解
-
技术逻辑
• 均值矩阵:2DPCA保留原始图像的空间结构,均值M反映整体“平均人脸”的五官分布。• 公式差异:传统PCA的均值是向量,2DPCA的均值是矩阵,直接对应图像各列(如像素列)的平均值。
题目设计
填空题
- 在2DPCA中,总均值M是______矩阵,而PCA的均值是______向量。
答案:M×N;MN×1
解析:例如,28×23的图像,2DPCA均值为28×23矩阵,PCA为644×1向量。
选择题
2. 为什么2DPCA的均值是矩阵而非向量?
A. 保留图像二维结构
B. 计算更简单
C. 无需训练数据
D. 适合分类任务
答案:A
解析:矩阵形式保留列方向(如五官排列),避免PCA展平导致的结构丢失。
口语化总结
2DPCA的均值就像班级平均分——传统PCA把每个学生的各科成绩拍成一张纸(向量),而2DPCA保留成绩单的表格结构(矩阵),方便看出哪科整体得分高。
综合总结(期末提分版)
核心对比表
| 技术 | 数据形式 | 协方差矩阵尺寸 | 优点 | 缺点 |
|---|---|---|---|---|
| PCA | 展平为向量(MN×1) | MN×MN | 计算简单 | 丢失结构、矩阵过大 |
| 2DPCA | 保留原始矩阵(M×N) | M×N | 保留结构、矩阵更小 | 需更多计算资源 |
考试口诀
• PCA:展平→大矩阵→省空间但易乱。
• 2DPCA:留结构→小矩阵→精准但费脑。
真题实战
-
填空题:2DPCA的协方差矩阵尺寸为______,相比PCA的______更小。
答案:M×N;MN×MN
解析:例如,28×23图像,2DPCA矩阵为28×23,PCA为644×644。 -
选择题:2DPCA如何保留图像结构?
A. 使用原始矩阵而非向量
B. 减少训练样本数量
C. 压缩数据维度
D. 提高图像分辨率
答案:A
解析:直接操作图像矩阵,避免展平导致空间关系丢失。
一句话记忆:
• PCA:撕碎试卷做总结(易丢信息)。
• 2DPCA:保留试卷页码再总结(结构清晰)。
第1张图核心内容翻译(中英对照)
中文核心观点
-
步骤2:用Xj(i)(i=1,2;j=1,⋯,5)表示图像样本,定义总均值M和类均值矩阵M1、M2。
-
公式对比:
• PCA的均值m是MN×1向量。• 2DPCA的均值M是M×N矩阵。
-
图像示例:展示M1、M2、M的灰度图像(如平均脸)。
English Core Idea
-
Step 2: Represent image samples as Xj(i) (i=1,2; j=1,⋯,5), define total mean M and class mean matrices M1, M2.
-
Formula Contrast:
• PCA: m is MN×1 vector.• 2DPCA: M is M×N matrix.
-
Images: Display average faces for M1, M2, M.
第1张图详细讲解
-
技术逻辑
• 数据表示:Xj(i)表示第i类(如人脸类别)的第j个样本,共5个样本。• 均值矩阵:M1和M2是类均值矩阵,反映每类人脸的“平均长相”;M是总均值矩阵,反映所有样本的全局平均。
• 维度差异:传统PCA的均值是向量(需展平图像),而2DPCA直接保留矩阵结构(如28×23的人脸图像)。
题目设计
填空题
- 在2DPCA中,类均值M1和M2是______矩阵,而PCA的均值是______向量。
答案:M×N(如28×23);MN×1(如644×1)
解析:2DPCA保留图像空间结构,均值矩阵维度与原始图像一致。
选择题
2. 为什么2DPCA的均值是矩阵而非向量?
A. 计算更简单
B. 保留图像二维结构
C. 无需训练数据
D. 适合分类任务
答案:B
解析:矩阵形式保留像素列方向的空间关系(如五官排列),避免PCA展平导致的结构丢失。
口语化总结
这一步就像计算班级平均分——传统PCA把每个学生的各科成绩拍成一张纸(向量),而2DPCA保留成绩单的表格结构(矩阵),方便看出哪科整体得分高。
第2张图核心内容翻译(中英对照)
中文核心观点
- 步骤3:计算总散射矩阵St,公式为St=∑i=1n(Xi−M)(Xi−M)T。
- 关键区别:在2DPCA中,X和M是M×N矩阵,St是N×N矩阵。
- 对比PCA:PCA的St是MN×MN矩阵,需更高计算成本。
English Core Idea
- Step 3: Compute total scatter matrix St=∑i=1n(Xi−M)(Xi−M)T.
- Key Difference: In 2DPCA, X and M are M×N matrices, making St an N×N matrix.
- Contrast with PCA: PCA's St is MN×MN, computationally heavier.
第2张图详细讲解
-
技术逻辑
• 散射矩阵作用:衡量数据方差分布,指导主成分选择。• 维度优化:2DPCA的St维度为N×N(如23×23),远小于PCA的644×644,降低计算复杂度。
题目设计
填空题
- 总散射矩阵St的维度是______×,而PCA的St是×______。
答案:N×N(如23×23);MN×MN(如644×644)
解析:2DPCA通过保留原始矩阵结构,大幅减少协方差矩阵维度。
选择题
2. 2DPCA的St为何更小?
A. 忽略类别标签
B. 保留图像二维结构
C. 使用最近邻算法
D. 压缩数据
答案:B
解析:直接操作图像矩阵,避免展平导致维度爆炸(如644→23)。
口语化总结
这一步就像用一张班级成绩表(矩阵)计算方差,而不是把每个学生的成绩撕成碎片再统计。传统PCA的协方差矩阵像一堆积木(644维),而2DPCA的矩阵像一张表格(23×23),既省空间又清晰。
第3张图核心内容翻译(中英对照)
中文核心观点
- 步骤4:计算St的特征值λi和特征向量Φi,公式为λiΦi=StΦi。
- 示意图:展示矩阵运算关系(左:标量λi与向量Φi;右:矩阵St)。
English Core Idea
- Step 4: Solve λiΦi=StΦi to get eigenvalues and eigenvectors.
- Visualization: Matrix operation diagram (left: scalar-vector; right: matrix).
第3张图详细讲解
-
技术逻辑
• 特征分解:通过St的特征值分解,确定数据主方向(方差最大方向)。• 图像意义:特征向量Φi是投影方向,λi表示该方向的信息量占比。
题目设计
填空题
- 特征值分解的公式是______ = ______ × ______。
答案:λiΦi=StΦi
解析:特征值λi对应主成分的重要性,特征向量Φi是投影方向。
选择题
2. 特征值λi越大,说明投影方向______。
A. 信息量越少
B. 方差越大
C. 计算越简单
D. 维度越低
答案:B
解析:特征值反映该方向的数据方差,值越大代表该方向包含更多信息。
口语化总结
特征值分解就像挑西瓜——特征值是“甜度得分”,值越大说明这个方向(如脸型)越能区分不同人脸,而特征向量是“切瓜方向”,决定怎么看瓜。
第4张图核心内容翻译(中英对照)
中文核心观点
- 步骤5:选择累计方差贡献率rλ达92.16%的主成分(前8个特征值)。
- 图表:柱状图(特征值大小)和折线图(累计贡献率)。
English Core Idea
- Step 5: Select top eigenvectors where cumulative variance rλ=92.16%.
- Charts: Bar plot (eigenvalue magnitudes), line plot (cumulative rλ).
第4张图详细讲解
-
技术逻辑
• 方差筛选:前8个特征值贡献92.16%的信息,剩余17.84%视为噪声。• 降维意义:将23维数据压缩到8维,保留主要特征(如五官结构)。
题目设计
填空题
- 当累计方差贡献率rλ达到______%时,可停止选择主成分。
答案:92.16
解析:前8个特征值已覆盖92.16%的方差,足够用于后续分类。
选择题
2. 为什么选择累计方差贡献率高的主成分?
A. 减少计算量
B. 保留主要信息
C. 提高图像分辨率
D. 压缩文件大小
答案:B
解析:高贡献率的主成分包含数据主体信息,避免“噪声干扰”。
口语化总结
这一步就像挑重点——前8个主成分是“考试重点”(占92%的知识点),剩下的2%是“冷门知识点”,复习时优先背重点,考试大概率不亏。
第5张图核心内容翻译(中英对照)
中文核心观点
- 步骤6:投影变换W=(φ1,φ2,⋯,φd),将数据压缩到d维(如23×8)。
- 公式:X′=(X−M)W,输出M×d矩阵(如28×8=224维)。
- 应用:可用任何分类器(如最近邻)。
English Core Idea
- Step 6: Project data via W=(φ1,φ2,⋯,φd), reducing dimensionality to d.
- Formula: X′=(X−M)W, output M×d matrix.
- Application: Compatible with classifiers (e.g., nearest neighbor).
第5张图详细讲解
-
技术逻辑
• 投影意义:将原始图像(如28×23)压缩到低维(28×8),保留关键特征(如脸型、眼睛间距)。• 分类应用:低维数据计算更快,适合实时识别(如人脸解锁)。
题目设计
填空题
- 投影变换W的大小为______×,输出数据X′的维度为×______。
答案:N×d(23×8);M×d(28×8)
解析:例如,23个特征向量组成W,将28×23图像压缩为28×8。
选择题
2. 为什么2DPCA适合实时分类?
A. 无需训练数据
B. 降维后计算更快
C. 保留所有原始信息
D. 适合大样本
答案:B
解析:低维数据减少计算量,提升分类速度(如实时人脸识别)。
口语化总结
这一步就像把长篇小说缩写成摘要——原始数据是28×23的小说,投影后变成28×8的提纲,考试时快速翻阅就能抓住重点。
综合总结(期末提分版)
核心对比表
| 步骤 | PCA | 2DPCA |
|---|---|---|
| 数据形式 | 展平为向量(MN×1) | 保留矩阵(M×N) |
| 均值计算 | 向量(644×1) | 矩阵(28×23) |
| 协方差矩阵 | 644×644(大而耗时) | 23×23(小而高效) |
| 应用场景 | 通用降维 | 光照变化、小样本 |
考试口诀
• PCA:展平→大矩阵→省空间但易乱。
• 2DPCA:留结构→小矩阵→精准但费脑。
真题实战
-
填空题:2DPCA的投影变换W由______个特征向量组成,输出数据维度为______×______。
答案:8;28×8
解析:例中选前8个特征向量,输出28×8矩阵。 -
选择题:2DPCA相比PCA的核心优势是?
A. 计算更快
B. 保留图像结构
C. 无需标签数据
D. 适合大样本
答案:B
解析:直接操作图像矩阵,避免展平导致空间关系丢失。
一句话记忆:
• PCA:撕碎试卷做总结(易丢信息)。
• 2DPCA:保留试卷页码再总结(结构清晰)。
第1张图核心内容解析
中文核心观点
- 2DPCA重建公式:当d=N时,X′=(X−M)V,其中V是酉矩阵(VTV=I),重建公式为X=M+X′VT=M+∑xi′φiT。
- 变量解释:V=(φ1,φ2,…,φN),xi′是投影后的特征向量。
- 教学阶段:标记为“Lecture 9-46”,属于2DPCA人脸重建的理论基础。
English Core Idea
- Reconstruction Formula: When d=N, X′=(X−M)V, where V is a unitary matrix (VTV=I), and X=M+X′VT=M+∑xi′φiT.
- Variables: V=(φ1,φ2,…,φN), xi′ is the i-th column of X′.
- Phase: Lecture 9-46, foundational theory of 2DPCA face reconstruction.
第1张图详细讲解
-
技术逻辑
• 酉矩阵作用:保证投影方向正交,避免信息冗余。• 重建过程:通过均值矩阵M和投影系数xi′还原图像,保留最大方差方向。
题目设计
填空题
- 当d=N时,2DPCA的重建公式为X=M+∑i=1Nxi′φiT,其中φi是______矩阵V的第i个______。
答案:酉;特征向量
解析:V是酉矩阵,φi为其列向量(特征向量)。
选择题
2. 酉矩阵的性质是?
A. VTV=I
B. VTV=0
C. VTV=N
D. VTV=M
答案:A
解析:酉矩阵满足VTV=I,确保正交性。
口语化总结
这一步就像用乐高拼脸——V是“拼装说明书”,每个φi代表一块积木的位置。酉矩阵保证积木不重叠,最后拼出完整的脸(重建图像)。
第2张图核心内容解析
中文核心观点
- 重建效果:展示不同d值(0到23或92)下的重建图像,d=0为均值脸,d增大时细节逐渐恢复。
- 公式与维度:重建公式X~=M+∑i=1dxi′φiT,X′的维度为M×d。
- 教学阶段:标记为“Lecture 9-47”,属于2DPCA的实践应用。
English Core Idea
- Reconstruction Effect: Show reconstructed faces at different d values (0 to 23/92), with d=0 as mean face.
- Formula: X~=M+∑i=1dxi′φiT, X′ is M×d.
- Phase: Lecture 9-47, practical application of 2DPCA.
第2张图详细讲解
-
技术逻辑
• d值意义:d越大,保留的细节越多(如从模糊轮廓到清晰五官)。• 维度控制:X′的列数d决定重建精度,d=23对应原始图像列数。
题目设计
填空题
- 当d=23时,重建图像X~的维度为______×______。
答案:28(行);23(列)
解析:原图为28×23,d=23时保留全部列信息。
选择题
2. 为什么d=0时是均值脸?
A. 无投影系数
B. 仅保留均值矩阵
C. 特征向量全为0
D. 训练样本不足
答案:B
解析:d=0时仅使用均值矩阵M,无投影特征。
口语化总结
这一步就像调节照片清晰度——d=0是模糊的灰度图(均值脸),d越大细节越清晰(如眼睛、鼻子逐渐显现)。
第3张图核心内容解析
中文核心观点
- ORL数据库:40人,每人10张112×92图像,用于对比PCA和2DPCA性能。
- 教学阶段:标记为“Lecture 9-48”,属于实验数据准备。
English Core Idea
- ORL Dataset: 40 individuals, 10 images each (112×92).
- Phase: Lecture 9-48, data preparation for performance comparison.
第3张图详细讲解
-
技术逻辑
• 数据用途:验证2DPCA在小样本(每人10张)下的鲁棒性。• 身份标识:40个不同人脸身份,用于分类任务。
题目设计
填空题
- ORL数据库中,每人提供______张不同图像,图像尺寸为______。
答案:10;112×92
解析:数据集结构关键参数,用于后续实验对比。
选择题
2. ORL数据库的用途是?
A. 测试图像分辨率
B. 对比PCA与2DPCA性能
C. 训练自动驾驶模型
D. 压缩文件大小
答案:B
解析:明确数据集用于算法性能对比。
口语化总结
ORL数据库就像考试题库——40个学生(身份),每人10道题(图像),用来测试两种方法(PCA和2DPCA)谁更会“解题”。
第4张图核心内容解析
中文核心观点
-
准确率对比:
• PCA准确率:66.9%(d=1)→93.5%(d=5)。• 2DPCA准确率:76.7%(d=1)→96.0%(d=5)。
-
训练时间对比:
• PCA时间:44.45s(d=1)→304.61s(d=5)。• 2DPCA时间:10.76s(d=1)→14.03s(d=5)。
-
教学阶段:标记为“Lecture 9-49”,属于实验结果分析。
English Core Idea
- Accuracy: PCA (66.9%→93.5%) vs. 2DPCA (76.7%→96.0%).
- Training Time: PCA (44.45s→304.61s) vs. 2DPCA (10.76s→14.03s).
- Phase: Lecture 9-49, experimental results.
第4张图详细讲解
-
技术逻辑
• 准确率优势:2DPCA在更低维度下达到更高精度(如d=5时96% vs. PCA 93.5%)。• 效率优势:2DPCA训练时间始终低于PCA(14s vs. 304s)。
题目设计
填空题
- 当d=5时,2DPCA的识别准确率为______%,比PCA高______%。
答案:96;2.5
解析:数据对比直接反映2DPCA性能优势。
选择题
2. 为什么2DPCA训练更快?
A. 无需计算协方差矩阵
B. 数据维度更低
C. 使用更少样本
D. 无需特征分解
答案:B
解析:2DPCA直接操作图像矩阵,避免高维协方差矩阵计算。
口语化总结
这一步就像考试答题——2DPCA是“速记法”,用更短时间(14秒)答对更多题(96%),而PCA是“笨办法”,花10倍时间(304秒)还容易错。
第5张图核心内容解析
中文核心观点
- 2DPCA缺点:特征维度高于PCA(如d=5时112×5=560维)。
- 解决方案:2DPCA+PCA,先降维到M×d,再进一步压缩到d'×1。
- 效果:混合方法准确率仍优于纯PCA(0.95 vs. 0.9)。
- 教学阶段:标记为“Lecture 9-50”,属于优化策略。
English Core Idea
- Disadvantage: 2DPCA feature dimension is higher (e.g., 112×5=560).
- Solution: Combine 2DPCA+PCA (reduce to d'×1).
- Result: Hybrid method accuracy (0.95) > PCA (0.9).
- Phase: Lecture 9-50, optimization strategy.
第5张图详细讲解
-
技术逻辑
• 混合流程:2DPCA保留结构,PCA进一步压缩,平衡精度与效率。• 折线图意义:混合方法在维度增加时准确率更稳定。
题目设计
填空题
- 2DPCA+PCA的流程中,最终特征维度为______×1。
答案:d'
解析:第二次PCA将M×d降维到d'×1。
选择题
2. 混合方法的优势是?
A. 计算更快
B. 避免高维协方差矩阵
C. 保留更多特征
D. 无需训练
答案:B
解析:通过两次降维减少计算复杂度,同时保持精度。
口语化总结
这一步就像写作文先列大纲再精简——2DPCA是“大纲”,PCA是“缩写”,既省纸(降维)又保留重点(高精度)。
第6张图核心内容解析
中文核心观点
-
2DPCA优势:
• 基于图像矩阵,更简单。• 识别精度更高。
• 计算更快,适合小样本。
-
教学阶段:标记为“Lecture 9-51”,属于结论总结。
English Core Idea
-
Advantages:
• Simpler (based on image matrix).• Higher accuracy.
• Faster, suitable for small samples.
-
Phase: Lecture 9-51, summary of 2DPCA.
第6张图详细讲解
-
技术逻辑
• 适用场景:小样本、实时处理(如人脸解锁)。• 协方差矩阵:直接基于图像块计算,避免高维噪声。
题目设计
填空题
- 2DPCA特别适合______问题,因为其计算效率更高。
答案:小样本
解析:避免高维协方差矩阵对样本量的依赖。
选择题
2. 2DPCA的核心优势是?
A. 特征维度更低
B. 计算更快且精度更高
C. 无需标签数据
D. 适合大样本
答案:B
解析:综合速度与精度,平衡性能。
口语化总结
2DPCA就像速溶咖啡——冲泡快(计算快)、味道好(精度高),小杯子(小样本)也能喝出浓缩精华。
综合总结(期末提分版)
核心对比表
| 指标 | PCA | 2DPCA | 2DPCA+PCA |
|---|---|---|---|
| 特征维度 | 高(如560维) | 中(如112×5=560维) | 低(d'×1) |
| 计算速度 | 慢(304秒) | 快(14秒) | 更快(优化后) |
| 识别精度 | 93.5% | 96.0% | 95% |
| 适用场景 | 通用降维 | 小样本、实时任务 | 平衡速度与精度 |
考试口诀
• PCA:展平→大矩阵→慢但省空间。
• 2DPCA:留结构→小矩阵→快且精度高。
• 混合方法:先结构后压缩,鱼和熊掌兼得。
真题实战
-
填空题:2DPCA+PCA的最终特征维度为______×1,其准确率比纯PCA高______%。
答案:d';约1.5%
解析:混合方法在保留精度的同时降低维度。 -
选择题:2DPCA最适合解决什么问题?
A. 高分辨率图像分类
B. 小样本实时人脸识别
C. 视频压缩
D. 增强图像色彩
答案:B
解析:计算快、精度高,适合小样本实时任务。
一句话记忆:
• PCA:传统方法,简单但笨。
• 2DPCA:升级版,聪明又高效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









