







IDE: CLion STM32CubeMX
MCU: STM32F407VET6
CubeAI:10.0.0
Build System: CMake
一、简介
以求知为导向,从问题到寻求问题解决的方法,以兴趣驱动学习。虽从0,但不到1,剩下的那一小步将由你迈出。
本篇主要目的是体验一次完整的简单AI模型部署流程,从数据采集到模型创建与训练,再到部署单片机上。所谓部署其实就是把模型转换为C语言代码,添加到我们的程序中。
选定的训练方向也非常简单,既不是手势、语音识别这些有一定难度的模型,也不是使用一些第三方的预训练模型,而是简简单单地从“调包”开始,搭建一个判断输入数字大小的小模型。比如判断输入数据是否小于24。最终生成的C代码其内存、存储占用均为10KB,也可缩减至不到1KB
既然是“从零开始”,那么就不需要介绍太多复杂的术语解释,但一些基本的概念还是需要了解的。该篇最主要的目的就是体验,不需要知道太多为什么,真正上手实践后,再自行学习。
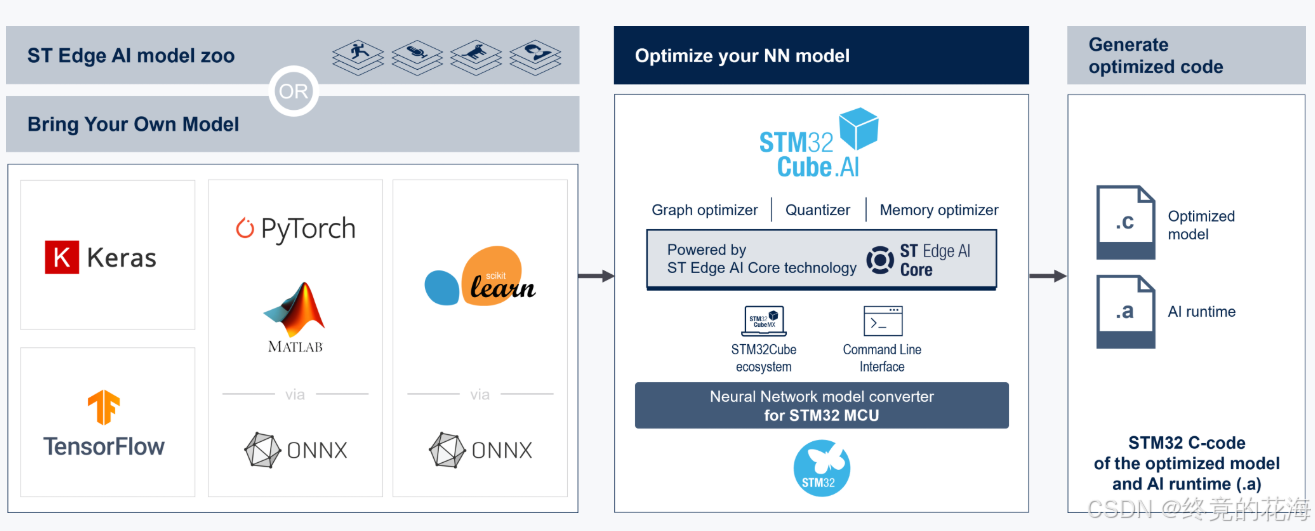
二、流程
1,STM32CubeMX的AI插件
想要触碰一个未曾熟知的领域,最重要的是要搜集信息,了解要做什么、怎么做,然后简单体验一番。那么第一步来了,我们的问题很简单,stm32单片机上怎么跑AI。带着这个问题我们使用搜索引擎可以得到一些博客,什么模型搭建、部署什么的可能也听不大懂。
但从这些博客里我们可以找到一个共同点,那就是都使用到了STM32CubeMX,虽然AI模型相关的不太懂,但这个工具软件可太熟了。
① X-CUBE-AI工具
从这里我们可以获取另一个关键点——就目前所获取的信息来看,stm32单片机上跑AI应是依赖STM32CubeMX的AI插件的。
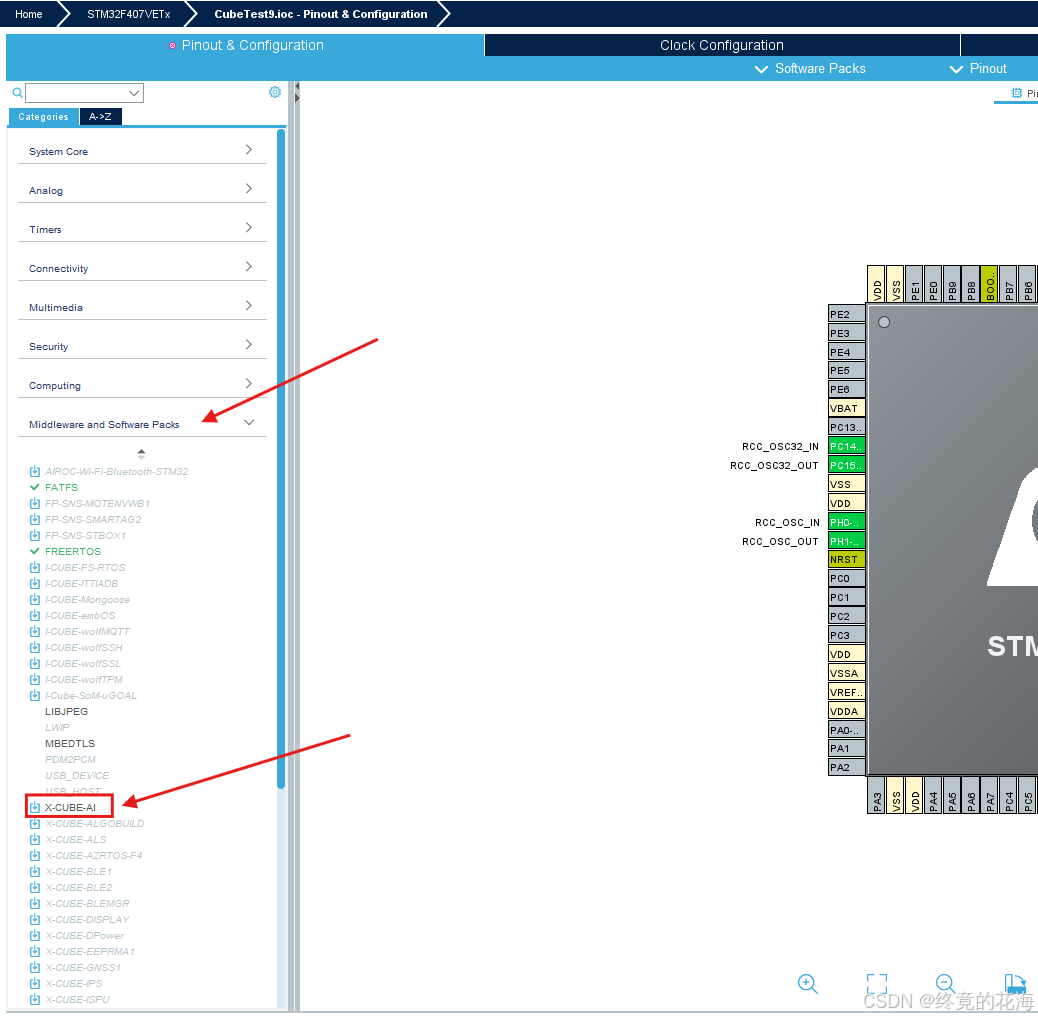
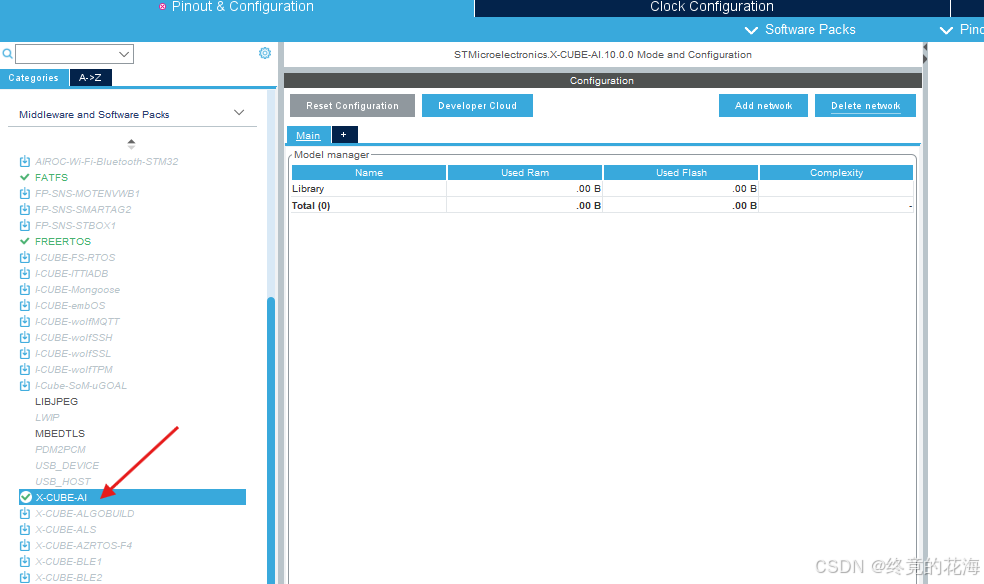
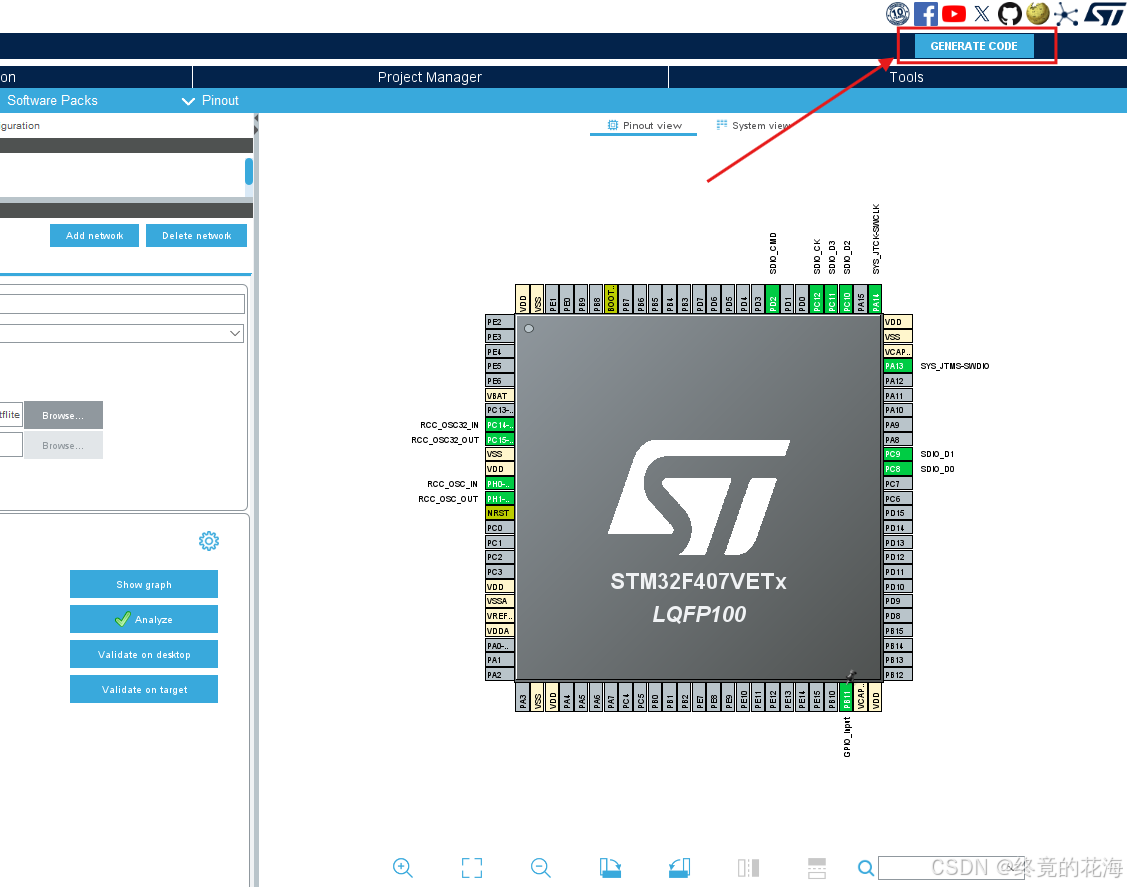
新建一个STM32Cube的工程,我们可以看到,在中间件和软件包这里有一个X-Cube-AI的工具(插件)
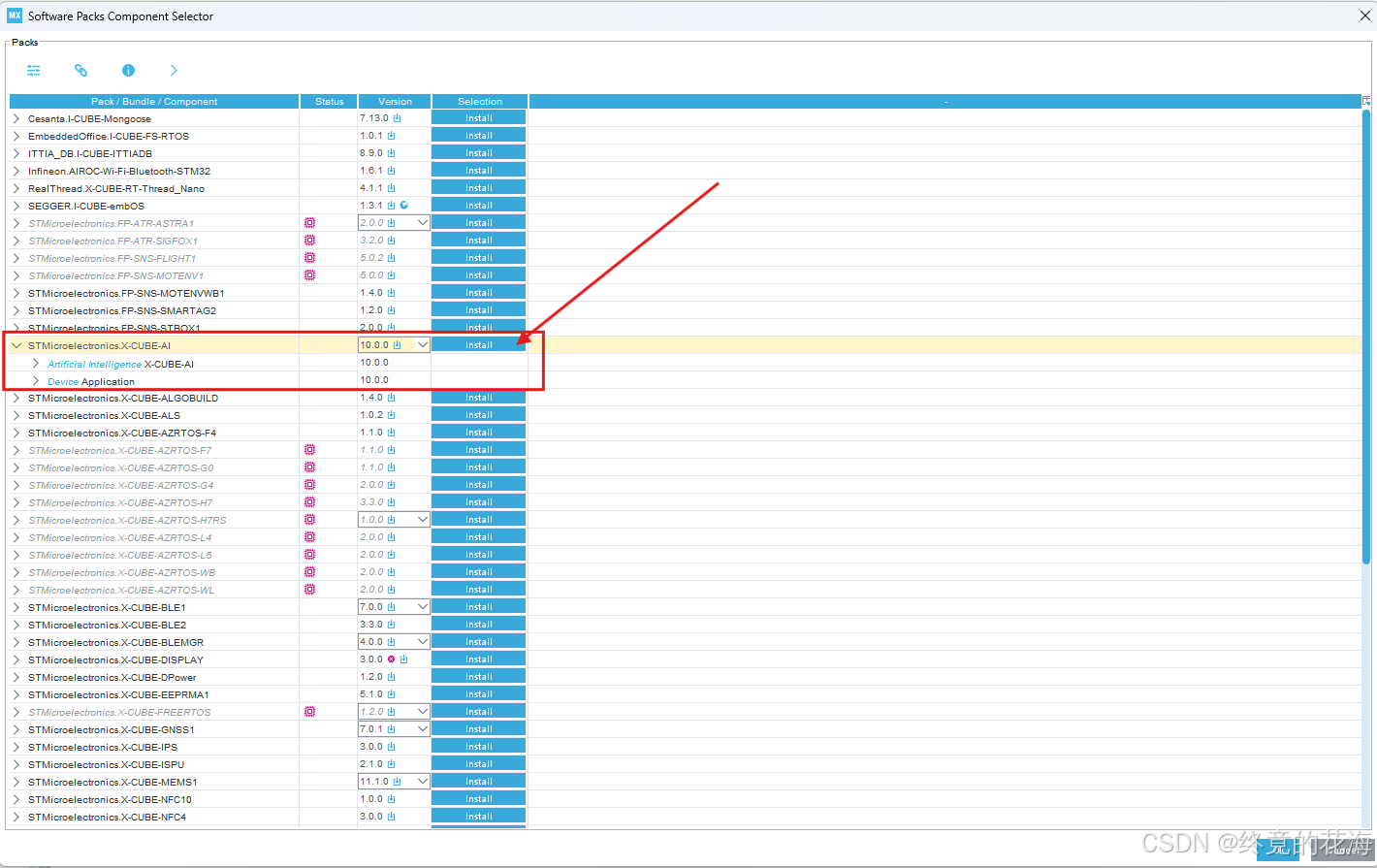
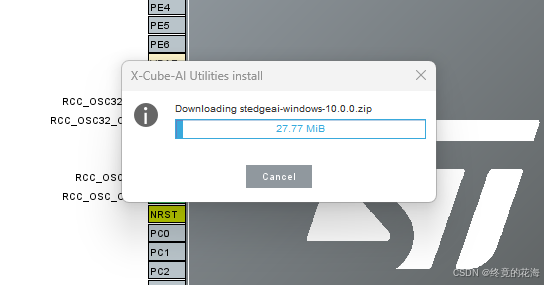
点击后,会弹出这样的界面,可以看到目前最新版是10.0.0,点击Install进行安装
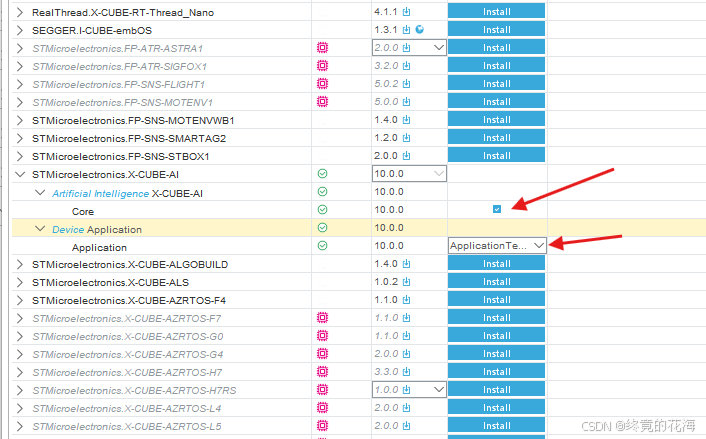
然后展开,勾选Core,并选择Application Template(应用模板),最后点击Ok
等待它下载扩展包,不过速度方面很是着急,大概几百KB/s
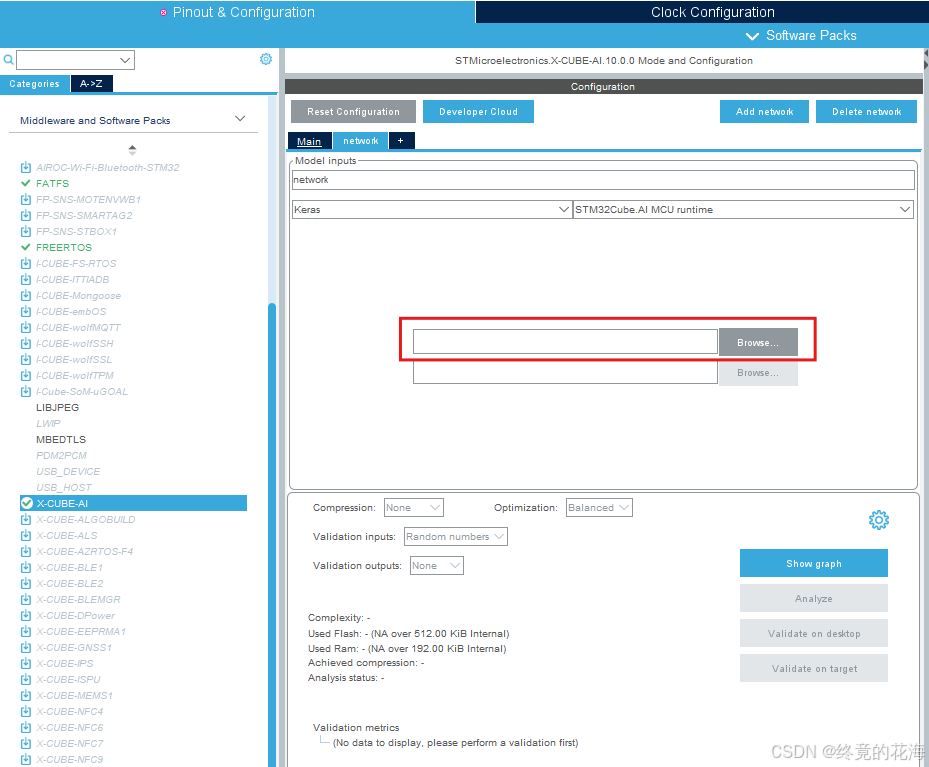
下载完成后,再点击X-CUBE_AI就可以进入配置项了
可以点击右上角的Add network来添加神经网络了
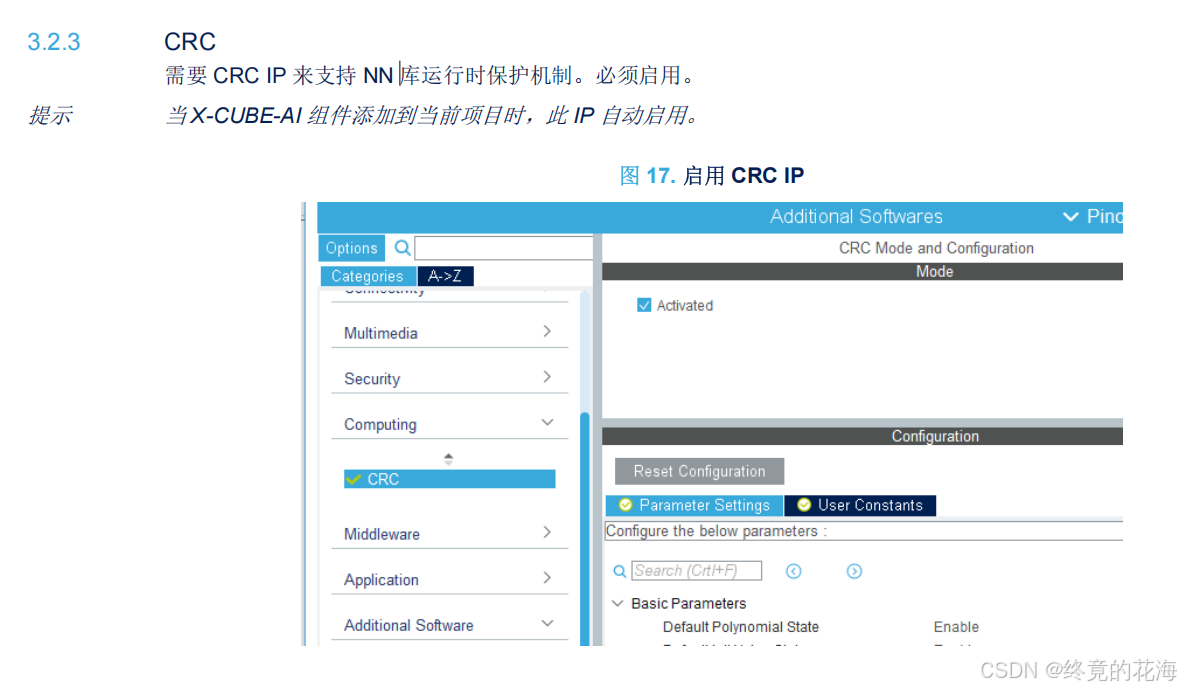
②开启CRC
此外,如果想要部署的AI能正常运行,那么必须要开启CRC
③文档(重要)
搜索手册文档,如图第一个就是我们要下载的文档
手册可以说是非常详细,且是友好的中文❤️,省去了大量的时间。如果你看完了本篇博客,知道了大概的开发流程,那么想要再深入一步,就可以反复翻阅最新的指导手册,种种不解之处或许就迎刃而解了
这个指南有个奇怪之处,目录是放在最后几页的


2,AI模型
①何为AI模型
当你兴冲冲地使用CubeMX上的AI插件时,你可能会发现,缺少一件东西——AI模型
回想前面回答,DS说过要准备模型
虽然网上相关博客有不少,什么手势识别模型、神经网络算法等等,但几乎没有几个是直接给你一个AI模型用的或者教你搭建一个模型,要么介绍各种算法充斥种种专业术语什么的,要么是到官网的github或者云盘上找。总之对于初学者而言,是有一些麻烦的
这属于“会了不难,难了不会”,也就是有一定门槛。那么我们接下来就继续发挥“不会就问”的精神
……
从这个问答,我们知道神经网络模型是有多种格式的,这一点在CubeAI插件里可以找到
同时,DS也指明了一条道路,让我们自己训练一个轻量级模型。不过呢,它举的这些例子更偏向实际应用,我们还是以“判断一个数字是否小于24”为我们训练AI模型的目的,模型格式选择Keras/TensorFlow Lite(后面你会理解为什么这样选择)




②如何训练一个模型
继续向DS提问
从回答中可以看出,确定问题后,我们只需要收集数据和训练模型即可。无论是收集数据(初印象自然是Excel),还是训练模型(使用python编程),都是非常清晰的过程。对于我们本次的目的,需要把数归类为小于24和不小于24,那么可定义为二分类问题(顾名思义,分成两个类别),毕竟有“小于24”和“不小于24”这两个类别。
③数据采集
当你对回答中的一些概念含混不清的时候,你可以把自己的理解、猜测主动反问给DS。无论你的想法是否正确,你都将被引向一条正确的道路
回答里,DS提供了一个很好的想法,那就是生成模拟数据,对于我们的此次目的来说,这无疑是很方便的
既然确定了步骤,不妨问问更细节的一些东西,比如
……
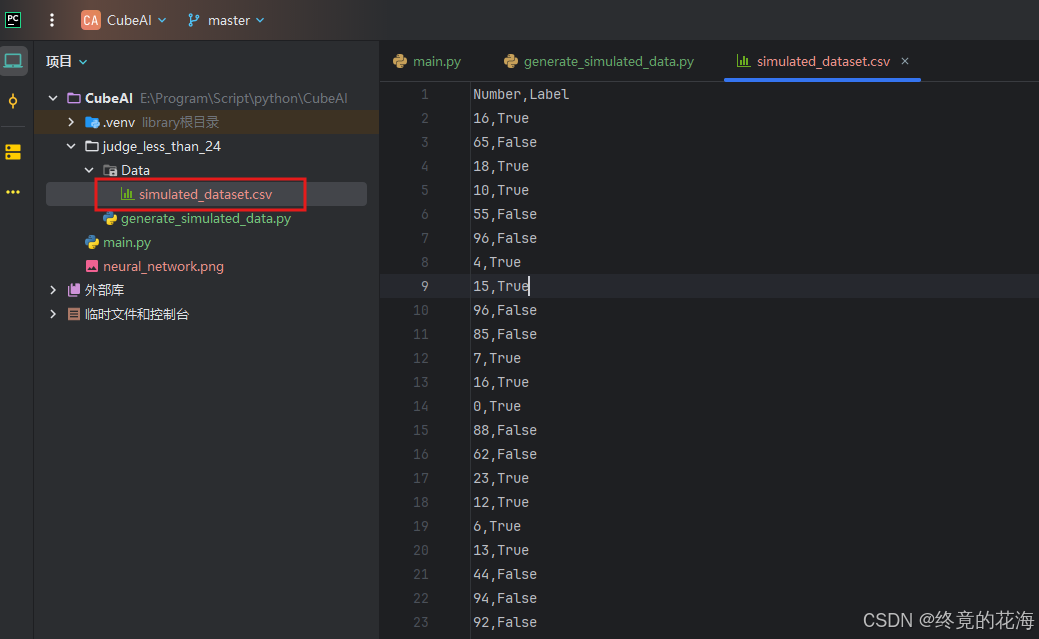
以我们当前要解决的问题,自然是选择CSV文件。打开CSV文件后你会发现这跟Excel里常见表格大差不差,第一行是标签,通过英文逗号隔开,每个标签下都是一列数据。
下图中可以看出,左边的就是我们要输入的值(布尔值),右边就是我们需要给数据进行“人工标注”的类别,1表示小于24,0表示不小于24
训练AI模型时,会用你收集到的这个数据集训练。以图中这个数据为例(二分类问题),所谓训练过程就是给它左边的输入数据,让AI模型输出,然后与数据集中的右边的输出对比,来判断AI预测的结果,之后AI再不断调整权重、参数什么的,让下次预测更加精准。
知道了这些信息后,你可以自行收集数据。比如一些波形数据,图像相关的什么矩阵、像素、灰度之类的等等
④训练模型
此处的“训练模型”是训练一个模型中的一个步骤,与“采集数据”同级。此外,我们需要清楚,STM32上跑的这个AI模型其实是神经网络模型,它们之间的包含关系是这样的:
AI(人工智能)> 机器学习 > 深度学习 > 神经网络模型(非传统神经网络)
而在神经网络中,我们常常能见到下面这种形式的结构图,也就是神经网络的“层”。它一共分为输入层、隐藏层和输出层。输入层很好理解,就是输入数据的层,输出层自然就是输出结果的层。隐藏层就是对数据进行某种不可描述的事情的层,也就是我们常常说神经网络模型是个“黑盒子”,即输入可知,输出也可知,但你不知道隐藏层究竟对数据做了多少次不可描述的操作。
那么自然,隐藏层可以包含很多层,比如CNN(卷积层)、RNN等,你也许经常听到它们的名称。没听过也没关系,遇到这些陌生术语,一带而过即可,用几遍就熟悉了。这些所谓的“层”,其实就是对数据的一次操作。
OK,那么我们回归主题,前面回答中出现过Keras 和TensorFlow Lite,除了是神经网络的格式外,它们也分别对应一种神经网络框架(你也可以理解为库或包)。我们此时使用的是Keras框架,为什么呢?因为Keras可以让你快速搭建自己的模型结构,没有复杂的操作,只需一味地向括号里添加你所希望的层。
之前,STM32CubeMX.AI对Keras格式的支持其实并不算好,一些高级层CubeAI暂时无法将其转换为C代码,转换时就会表现为一些奇怪的提示错误。即使是它支持的层,比如CNN,直接输出为.keras格式,那么转换时仍可能会出现不支持的情况。
具体支持的层有哪些,需要对照手册
好在模型格式之间可以相互转换,例如将 Keras 模型(
.h5或SavedModel)转换为 TensorFlow Lite(.tflite)格式,而 CubeAI 对这种服务于嵌入式的框架的支持是很好的。⑤推理
推理,也就是预测,就是输入数据让AI模型输出预测的结果。说白了就是使用训练好的AI模型





三、采集数据
这里不说怎么安装Pycharm什么的,因为这是最基本的能力
正如前面所言,我们的训练目的是判断输入数据是否小于24。现在我们把训练目的具体化:在0-100内,判断出这个数据是否小于24。那么我们就需要生成这样的标注数据,为了保真,还得让数据随机起来,且小于24的和大于24的概率还不同,以增加些许难度。
这个数据可以使用python生成,那么怎么写python脚本呢?从变量命名、标识符开始学一遍python?那大可不必,我们不需要从头开始学习python(因为你至少已掌握了C语言),只需要知道怎么让DS生成正确的代码即可。
代码和它的注释见多了,并且尝试修改代码,需要什么操作就查什么,慢慢就会熟悉的
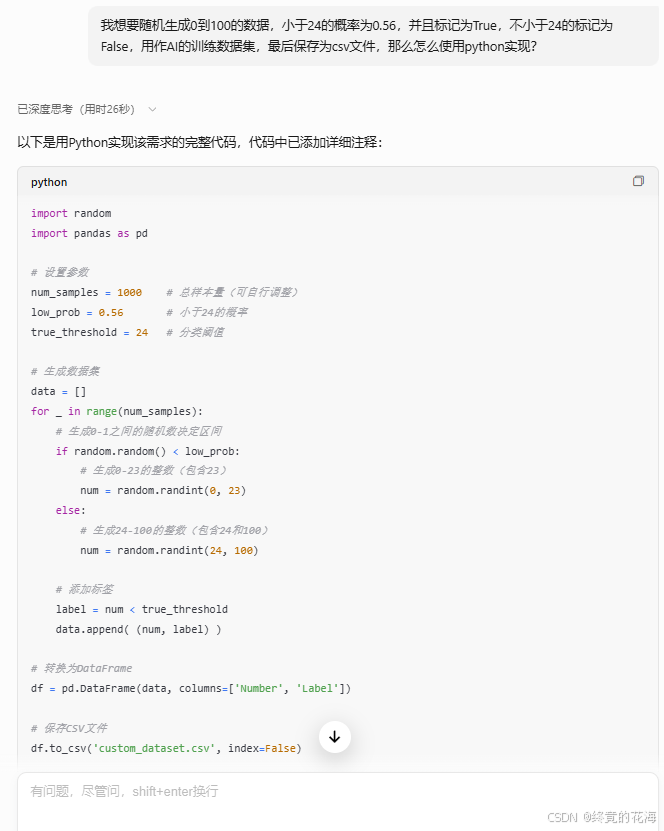
我想要随机生成0到100的数据,小于24的概率为0.56,并且标记为True,不小于24的标记为False,用作AI的训练数据集,最后保存为csv文件,那么怎么使用python实现?
DS生成的代码大多数情况下可用,如果出错,那么就把报错信息或者调试信息给它,提供给它需求,让它不断修改代码直至生成可用的代码,这里不展开细节了。下面就是可用的python代码,如果你是新安装的pycharm,那么可能会提示安装一些库,光标放在报错的地方就会提示安装对应的包,点击即可
如果安装软件包的过程可能会有些漫长,换源即可。可用的python代码如下,其中小于24的概率不建议调得太高或者太低,不然就成了“非平衡二分类问题”。举个例子,如果小于24的概率调到了0.05,那么意味不管输入什么数据全部蒙“不小于24”的概率都可以达到0.95,那么AI模型就根本不想进步了。需要用一些方法,比如调整权重、欠采样等来解决
import random import pandas as pd # 设置参数 num_samples = 1000 # 总样本量(可自行调整) low_prob = 0.56 # 小于24的概率 true_threshold = 24 # 分类阈值 file_name = 'Data/simulated_dataset.csv' # 生成数据集 data = [] for _ in range(num_samples): # 生成0-1之间的随机数决定区间 if random.random() < low_prob: # 生成0-23的整数(包含23) num = random.randint(0, 23) else: # 生成24-100的整数(包含24和100) num = random.randint(24, 100) # 添加标签 label = num < true_threshold data.append((num, label)) # 转换为DataFrame df = pd.DataFrame(data, columns=['Number', 'Label']) # 保存CSV文件 df.to_csv(file_name, index=False) # 验证分布比例 true_count = df['Label'].sum() false_count = len(df) - true_count print(f"True比例: {true_count / len(df):.2%} ({true_count}条)") print(f"False比例: {false_count / len(df):.2%} ({false_count}条)")正确执行完后,指定目录下就会有一个simulated_data.csv文件。
运行时要注意,运行的是不是当前文件
四、训练模型
1,训练模型代码
听着虽然有些不明觉厉,其实这里我们只用非常简单且有限的步骤,因为Keras框架已经帮我们做好了绝大部分工作了。
问询你可以描述得更加具体。不得不说DS太体贴了,前面提问时说过“我是初学者”,它生成代码时也没忘记,注释可谓是非常详细
……
既如此,让它改进代码
……
总之,多次让AI改进后,可以得到了一份可以训练刚才数据的代码
# -*- coding: utf-8 -*- import matplotlib import pandas as pd import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from keras.src.layers import Dense matplotlib.use('TkAgg') # 或者 'Qt5Agg' 设置matplotlib后端为TkAgg,不然pycharm绘图会报错 # 设置随机种子确保可重复性 np.random.seed(42) tf.random.set_seed(42) # --------------------------- # 1. 加载数据与预处理 # --------------------------- # 从CSV文件加载数据 df = pd.read_csv('./Data/simulated_dataset.csv') # 替换为你的CSV文件路径 X = df[['Number']].values # 输入特征 y = df['Label'].values # 标签(0或1) # 数据标准化 scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # 分割数据集 X_train, X_test, y_train, y_test = train_test_split( X_scaled, y, test_size=0.2, random_state=42 ) # --------------------------- # 2. 构建Keras模型 # --------------------------- model = tf.keras.Sequential([ Dense(8, activation='relu', input_shape=(1,)), Dense(1, activation='sigmoid') ]) model.compile( optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'] ) # --------------------------- # 3. 训练模型并可视化 # --------------------------- history = model.fit( X_train, y_train, epochs=300, batch_size=32, validation_split=0.1, verbose=1 ) # 绘制训练过程曲线 plt.figure(figsize=(12, 4)) # 准确率曲线 plt.subplot(1, 2, 1) plt.plot(history.history['accuracy'], label='Training Accuracy') plt.plot(history.history['val_accuracy'], label='Validation Accuracy') plt.title('Model Accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() # 损失曲线 plt.subplot(1, 2, 2) plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.title('Model Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.tight_layout() plt.show() # --------------------------- # 4. 评估与保存模型 # --------------------------- # 保存模型为TensorFlow Lite格式(修正部分) converter = tf.lite.TFLiteConverter.from_keras_model(model) tflite_model = converter.convert() # 先转换模型 # 将模型写入文件(注意扩展名应为.tflite) model.save('model/number_classifier.h5') with open('model/number_classifier.tflite', 'wb') as f: # 使用相对路径 f.write(tflite_model) print("\n模型已保存为 number_classifier.tflite") # 测试集评估 test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0) print(f"\n测试集准确率: {test_acc:.2%}") print(f"测试集损失: {test_loss:.4f}")2,简单分析代码
这个代码,有时候即便你安装了所有软件包可能还会冒红线,可以先不用管它
码,由于有注释的帮助,这些步骤非常清晰明了。下面代码在个别地方可能与上面不同
①加载数据
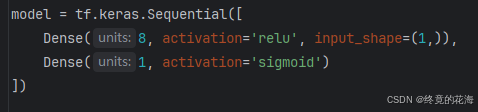
②创建模型
这里面可以看到两个函数,也就是两层神经网络,你想要增加,就再添加一个函数即可。事实上它表示了三层神经网络,输入层在input_shape那里,只不过由于只需输入一个数,因此输入层只有一个节点。
隐藏层只有一个Dense(全通层),里面有8个节点,激活函数是relu(这个现在应该可以自行查询哦)。
输出层只有一个节点,虽然是二分类问题,但事实上,一个节点激活和不激活就已经表示两种状态了。因此,只需要一个节点即可,而sigmoid这个激活函数常见用于二分类问题的输出层。
常用的隐藏层比如CNN和Dense,层越多,理论上训练效果更好,但容易过拟合并且占用算力资源也会增加。
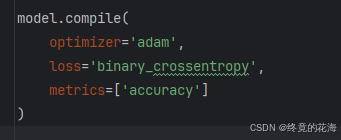
③编译模型
④训练模型
这里只要注意这两个参数即可,一个是epochs,另一个是batch_size。前者是训练轮数,后者是每批次训练的数据量
⑤评估模型
这里其实就是图形化显示训练的结果,什么准确率、损失什么的。准确率分为训练准确率和验证准确率,因为在训练过程中并不是拿出所有数据来训练,不然那就相当于拿着答案做题,正确率自然是百分百。因此,需要拿一部分题来训练,另一部分题来检验,一般这个比例为0.7:0.3
这就自然而言牵扯出一个概念,那就是过拟合——训练准确率很高,但是验证准确率很低,这就相当于做自己熟悉的题千百次,准确率相当高,但是遇到陌生题型时却难以变通,准确率很低。
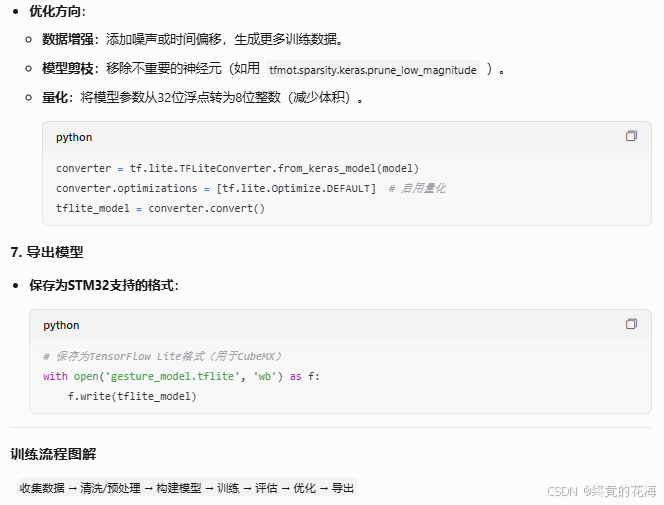
⑥保存模型
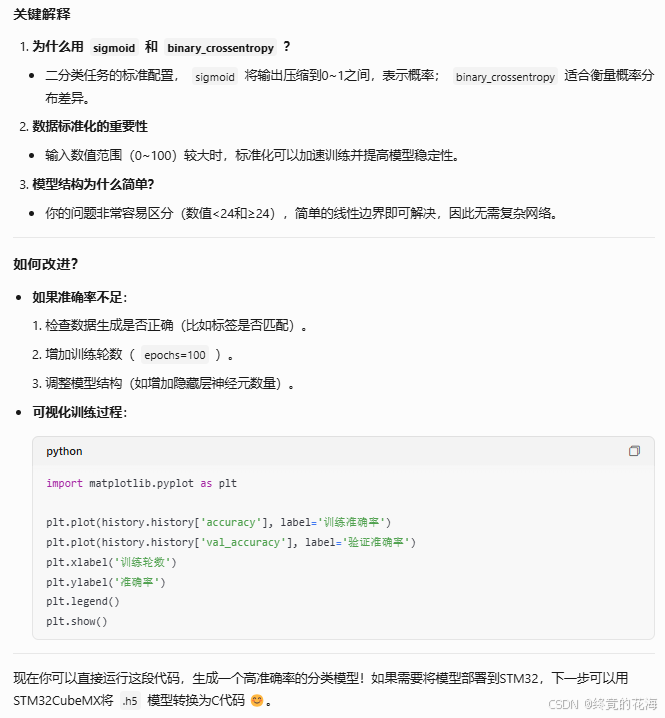



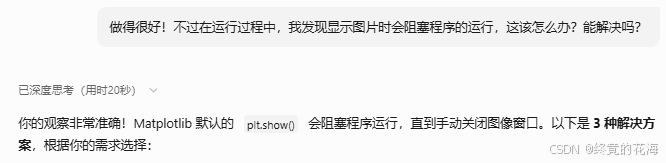


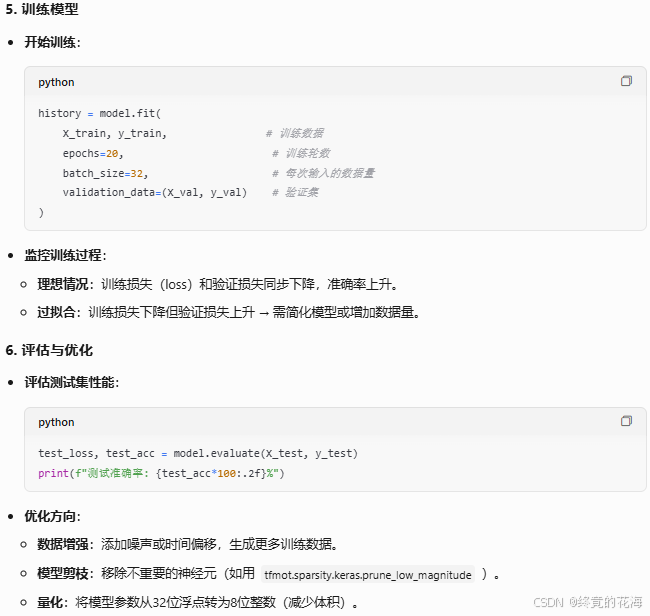
3,开始训练
①训练效果
既然这样,我们看看运行之后是什么样子的
如果这是你的第一个AI模型,成就感满满是不是
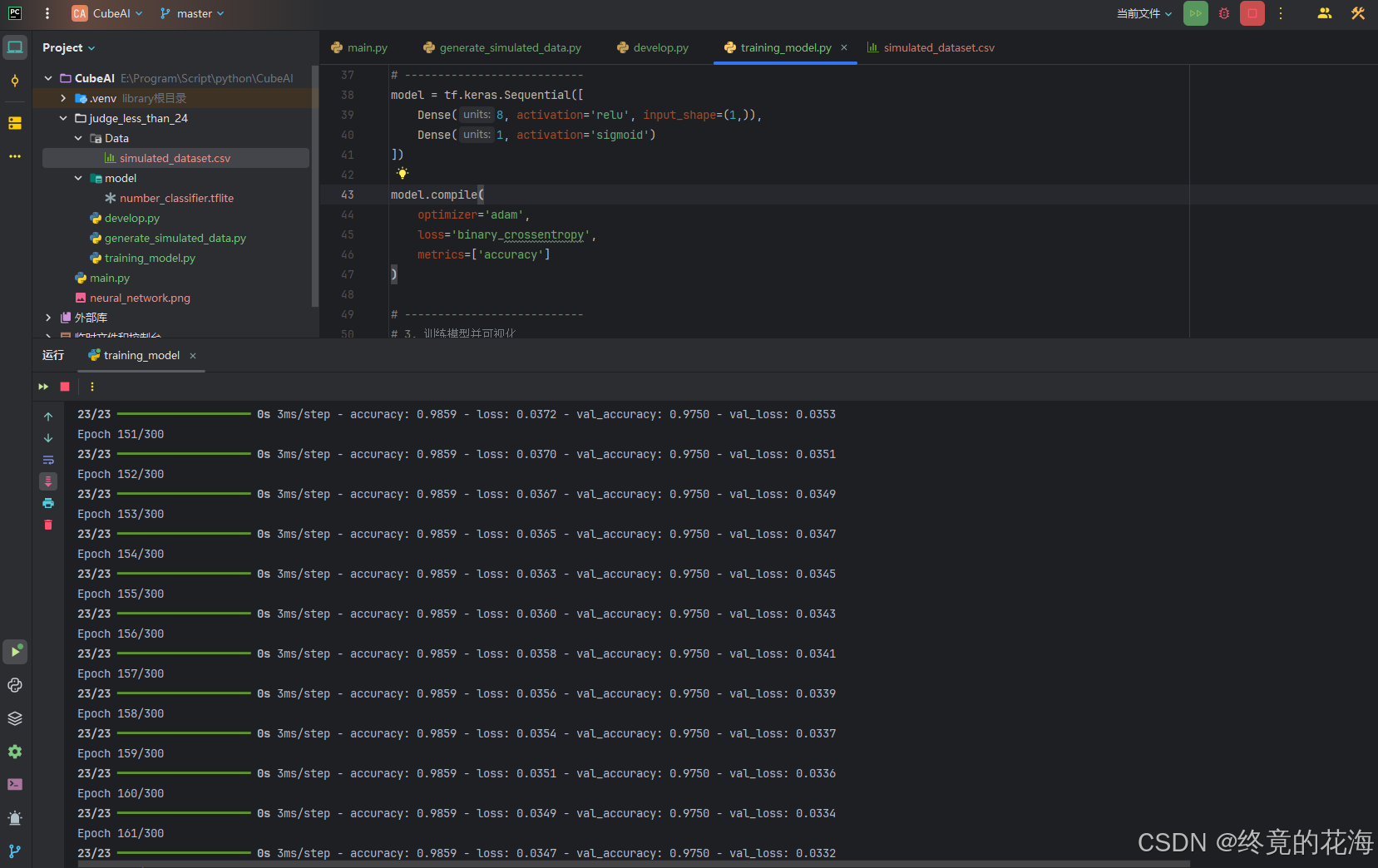
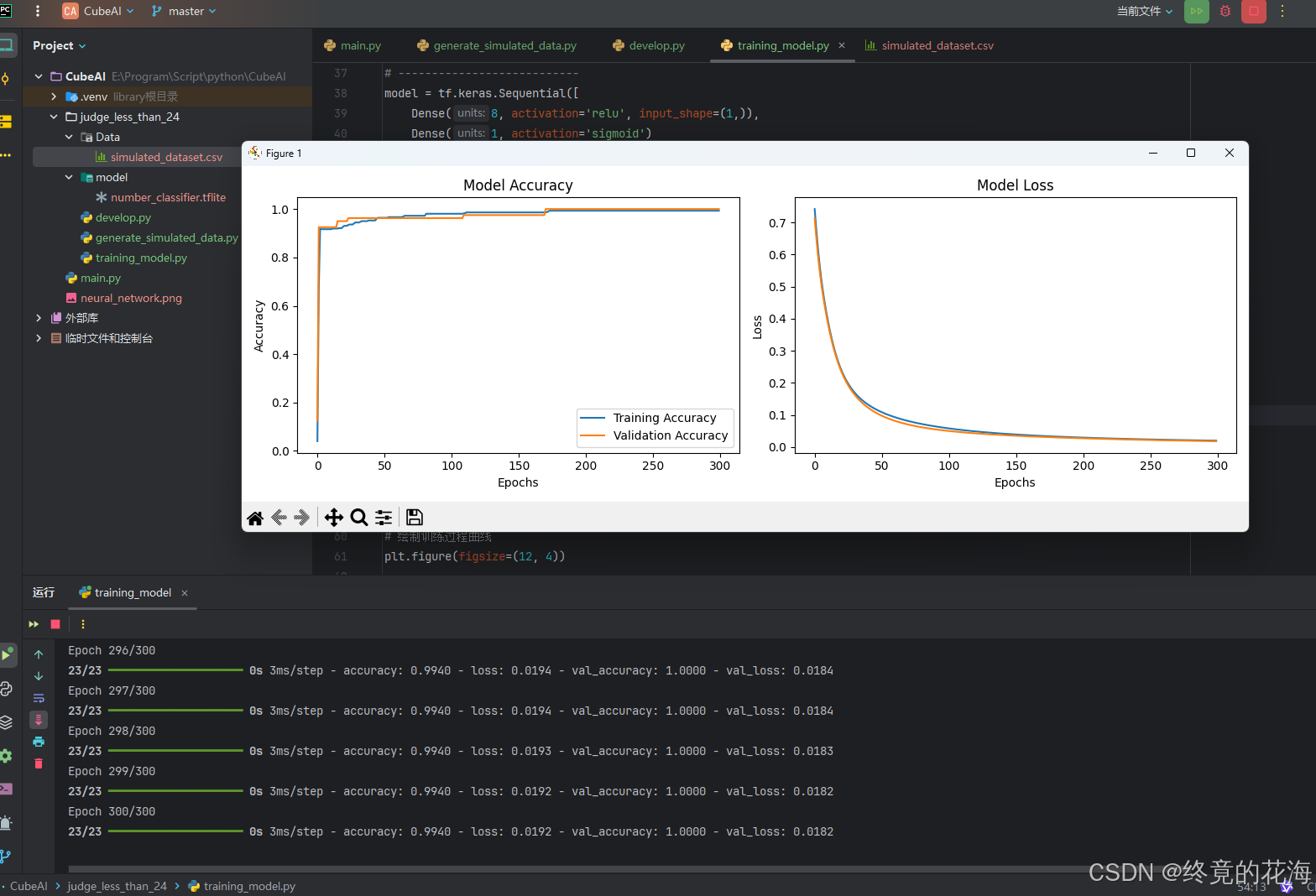
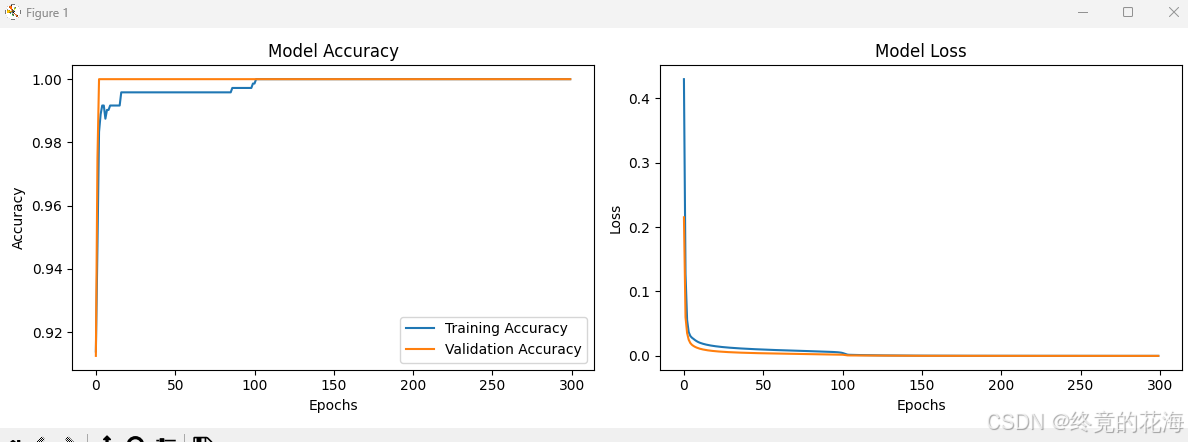
从图中可以看到随着训练轮次增加,准确率也逐渐增加,最后逐渐收敛
我们单看某一次的,可以发现正确率已经达到0.9940了,因为问题比较简单嘛
②改进模型
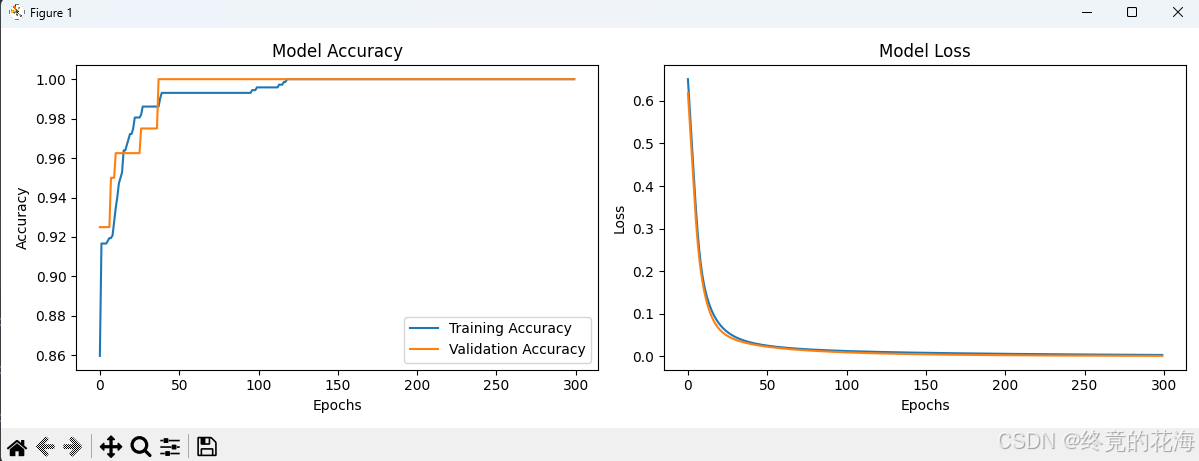
从训练结果来看,训练批次长,需要达到一百余次才渐渐稳定到令人满意地收敛。此外,准确率收敛在0.994(99.4%),仍有0.6%的优化空间。我们可以有以下优化方法:
调整模型结构
添加更多的节点、更多的层,更换激活函数以增强非线性能力
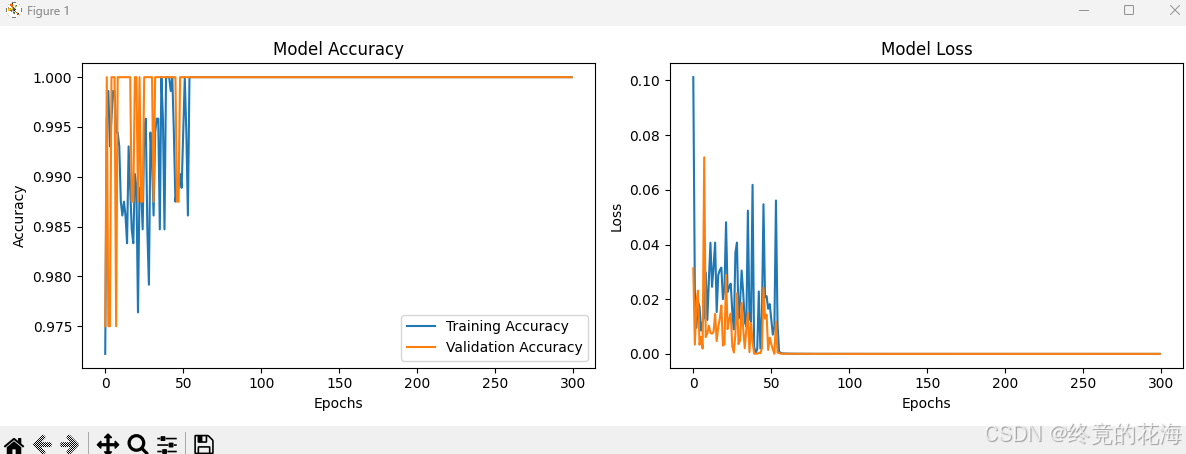
model = tf.keras.Sequential([ Dense(16, activation='swish', input_shape=(1,)), # 增强非线性能力 Dense(8, activation='swish'), Dense(1, activation='sigmoid') ])可以看出,训练到120次左右,无论是训练还是验证准确率都达到了1.00,效果十分的夸张
优化训练策略
比如调整权重、更换损失函数、早停法、显示设置学习率等等。设置学习率与调整模型结构一样,不能太高或者太低。太高容易错过最优解,步子跨太大了。太低呢容易陷入局部最优解,也就是沉浸于短期利益中,跳不出来,看不到远方。
一般可以10倍10倍的升或者降
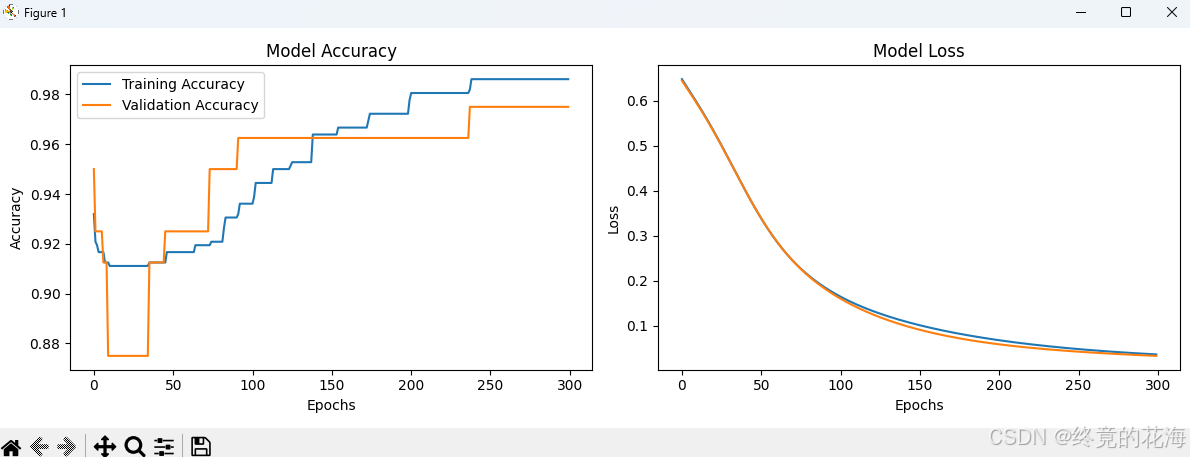
model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), # 显式设置学习率 loss='binary_crossentropy', metrics=['accuracy'] )调低的情况下(0.00001),收敛轮次变长
比较合适的情况下(0.01)
调高的情况下(0.1),有可能不收敛(前面乱糟糟的,如果没挺过去,后面也会乱糟糟的)
增强数据质量
在阈值24附近生成更多样本,相当于增大生存压力。或者清洗数据,剔除一些错误或者噪声数据。
……
优化的代码
# -*- coding: utf-8 -*- import matplotlib import pandas as pd import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from keras.src.layers import Dense matplotlib.use('TkAgg') # 或者 'Qt5Agg' 设置matplotlib后端为TkAgg,不然pycharm绘图会报错 # 设置 matplotlib 使用的字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 设置随机种子确保可重复性 np.random.seed(42) tf.random.set_seed(42) # --------------------------- # 1. 加载数据与预处理 # --------------------------- # 从CSV文件加载数据 df = pd.read_csv('./Data/simulated_dataset.csv') # 替换为你的CSV文件路径 X = df[['Number']].values # 输入特征 y = df['Label'].values # 标签(0或1) # 数据标准化 scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # 分割数据集 X_train, X_test, y_train, y_test = train_test_split( X_scaled, y, test_size=0.2, random_state=42 ) # --------------------------- # 2. 构建Keras模型 # --------------------------- model = tf.keras.Sequential([ Dense(16, activation='swish', input_shape=(1,)), # 增强非线性能力 Dense(8, activation='swish'), Dense(1, activation='sigmoid') ]) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), # 显式设置学习率 loss='binary_crossentropy', metrics=['accuracy'] ) # --------------------------- # 3. 训练模型并可视化 # --------------------------- history = model.fit( X_train, y_train, epochs=150, batch_size=32, validation_split=0.1, verbose=1 ) # 绘制训练过程曲线 plt.figure(figsize=(12, 4)) # 准确率曲线 plt.subplot(1, 2, 1) plt.plot(history.history['accuracy'], label='训练准确率') plt.plot(history.history['val_accuracy'], label='验证准确率') plt.title('模型准确率') plt.xlabel('训练轮次') plt.ylabel('准确率') plt.legend() # 损失曲线 plt.subplot(1, 2, 2) plt.plot(history.history['loss'], label='训练损失') plt.plot(history.history['val_loss'], label='验证损失') plt.title('模型损失') plt.xlabel('训练轮次') plt.ylabel('损失') plt.tight_layout() plt.show() # --------------------------- # 4. 评估与保存模型 # --------------------------- # 保存模型为TensorFlow Lite格式(修正部分) converter = tf.lite.TFLiteConverter.from_keras_model(model) tflite_model = converter.convert() # 先转换模型 # 将模型写入文件(注意扩展名应为.tflite) model.save('model/number_classifier.keras') with open('model/number_classifier.tflite', 'wb') as f: # 使用相对路径 f.write(tflite_model) print("\n模型已保存为 number_classifier.tflite") # 测试集评估 test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0) print(f"\n测试集准确率: {test_acc:.2%}") print(f"测试集损失: {test_loss:.4f}")③注意事项
此外,TensorFlow的新版只能用CPU进行训练,想要使用GPU训练,那么就需要在Conda环境里下载旧版的TensorFlow。只不过以当前训练而言,使用CPU足矣。
运行过程中图片会阻塞程序

五、部署推理
1,生成模拟数据
既然模型已经训练完毕,接下来我们就可以在本地部署,然后进行推理看看效果怎么样。(加载训练好的模型,然后输入数据,看看AI的输出是什么样的)
不过在此之前我们还要生成100个模拟数据,当做实际中的数据,用于验证模型的推理效果。生成这100个数据,我可以通过原先的模拟数据生成代码微调一些参数,来生成实际模拟数据。
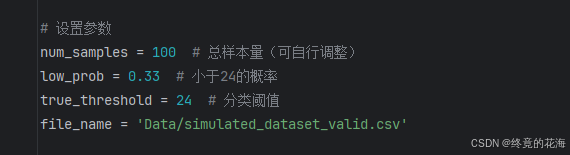
2,推理预测
然后就是推理(预测)了
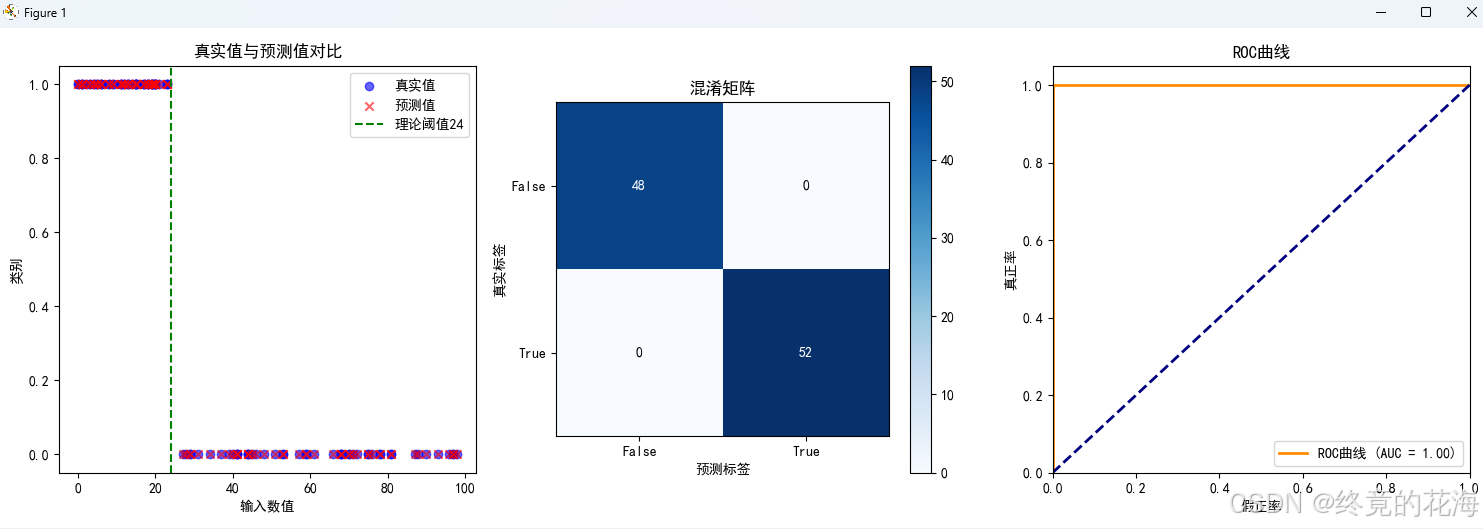
# -*- coding: utf-8 -*- import matplotlib import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.metrics import accuracy_score, confusion_matrix, roc_curve, auc from sklearn.preprocessing import StandardScaler import tensorflow as tf matplotlib.use('TkAgg') # 或者 'Qt5Agg' 设置matplotlib后端为TkAgg,不然pycharm绘图会报错 # 设置 matplotlib 使用的字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # --------------------------- # 1. 加载数据与预处理 # --------------------------- # 加载测试数据集 df = pd.read_csv('./Data/simulated_dataset_valid.csv') X = df[['Number']].values y_true = df['Label'].values # 必须使用训练时的scaler对象!假设已保存训练时的scaler # 如果未保存,需要重新拟合(但会引入数据泄漏,不推荐) scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # 实际部署时应加载训练时的scaler参数 # --------------------------- # 2. 加载TFLite模型 # --------------------------- interpreter = tf.lite.Interpreter(model_path='model/number_classifier.tflite') interpreter.allocate_tensors() # 获取输入输出张量信息 input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() # --------------------------- # 3. 批量推理并评估 # --------------------------- def batch_predict(X): y_pred = [] for sample in X: # 预处理输入 sample = sample.reshape(1, -1).astype(np.float32) # 设置输入 interpreter.set_tensor(input_details[0]['index'], sample) # 运行推理 interpreter.invoke() # 获取输出 pred = interpreter.get_tensor(output_details[0]['index'])[0][0] y_pred.append(pred) return np.array(y_pred) y_prob = batch_predict(X_scaled) y_pred = (y_prob > 0.5).astype(int) # 将概率转换为0/1预测 # --------------------------- # 4. 可视化评估结果 # --------------------------- plt.figure(figsize=(15, 5)) # 子图1:真实值与预测值对比散点图 plt.subplot(1, 3, 1) plt.scatter(X, y_true, c='blue', label='真实值', alpha=0.6) plt.scatter(X, y_pred, c='red', marker='x', label='预测值', alpha=0.6) plt.axvline(x=24, color='green', linestyle='--', label='理论阈值24') plt.xlabel('输入数值') plt.ylabel('类别') plt.title('真实值与预测值对比') plt.legend() # 子图2:混淆矩阵 plt.subplot(1, 3, 2) cm = confusion_matrix(y_true, y_pred) plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues) plt.title('混淆矩阵') plt.colorbar() tick_marks = [0, 1] plt.xticks(tick_marks, ['False', 'True']) plt.yticks(tick_marks, ['False', 'True']) plt.xlabel('预测标签') plt.ylabel('真实标签') for i in range(2): for j in range(2): plt.text(j, i, cm[i][j], ha='center', va='center', color='white' if cm[i][j] > cm.max()/2 else 'black') # 子图3:ROC曲线 plt.subplot(1, 3, 3) fpr, tpr, _ = roc_curve(y_true, y_prob) roc_auc = auc(fpr, tpr) plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.2f})') plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('假正率') plt.ylabel('真正率') plt.title('ROC曲线') plt.legend(loc='lower right') plt.tight_layout() plt.show() # --------------------------- # 5. 打印评估指标 # --------------------------- test_accuracy = accuracy_score(y_true, y_pred) print(f"\n测试集准确率: {test_accuracy:.2%}") print(f"混淆矩阵:\n{cm}") # --------------------------- # 6. 单样本推理演示 # --------------------------- def predict_single_number(num): # 数据预处理 scaled_num = scaler.transform([[num]]) # 推理 interpreter.set_tensor(input_details[0]['index'], scaled_num.astype(np.float32)) interpreter.invoke() prob = interpreter.get_tensor(output_details[0]['index'])[0][0] prediction = prob > 0.5 actual_label = num < 24 # 可视化结果 plt.figure(figsize=(6, 4)) plt.bar(['预测概率'], [prob], color='skyblue') plt.axhline(y=0.5, color='red', linestyle='--', label='决策阈值') plt.ylim(0, 1) plt.title(f'输入值: {num}\n预测结果: {prediction} (正确性: {prediction == actual_label})') plt.legend() plt.show() return prob # 示例:手动输入数值测试 while True: try: user_input = input("\n输入测试数值(输入 'q' 退出): ") if user_input.lower() == 'q': break num = float(user_input) predict_single_number(num) except: print("请输入有效数字!")我们可以看到推理后的结果是非常哇塞的,这根本就难不倒它嘛
关闭图像后,下面的终端还开着,可以输入数字来测试一下,按输入q或者直接按停止运行键即可退出
六、加载模型
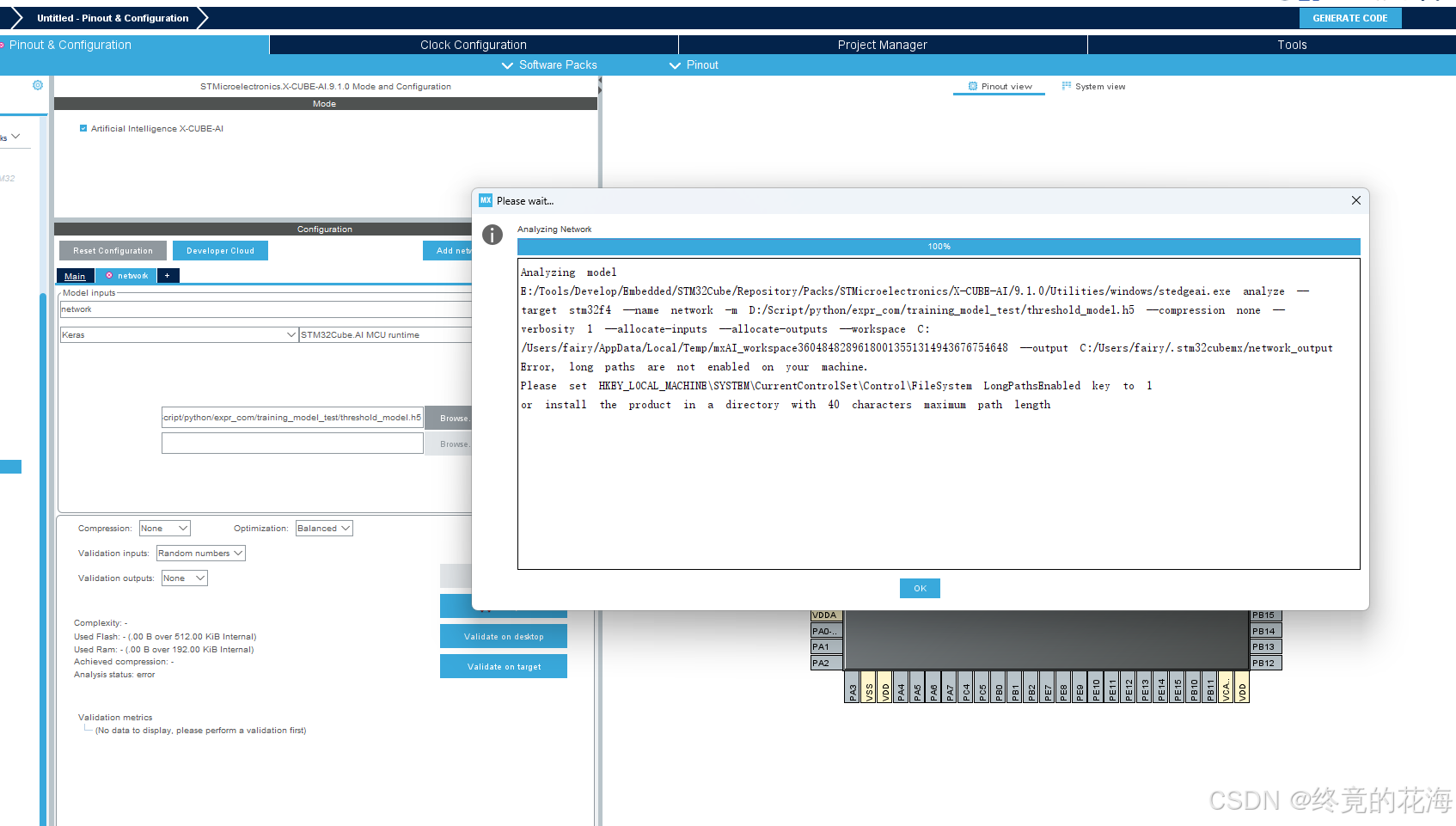
既然前面已经把模型训练了出来,接下来就可以把模型部署到单片机上了。不过部署模型时可能会遇到下面问题,即长路径错误,建议配置一下。
- 在注册表编辑器中,找到路径
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem。修改或添加
LongPathsEnabled值:
- 在
FileSystem文件夹中查找名为LongPathsEnabled的DWORD (32-bit) 值。- 如果存在,双击它并将其值设置为
1。- 如果不存在,右键点击
FileSystem文件夹,选择新建->DWORD (32-bit) 值,命名为LongPathsEnabled,然后将其值设置为1。- 然后重启
1,生成C代码
①添加模型
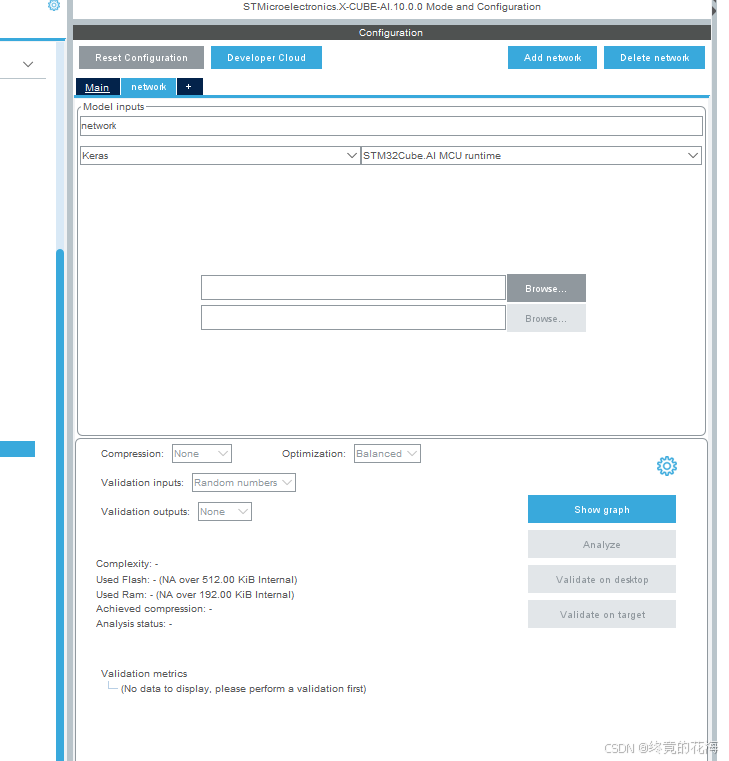
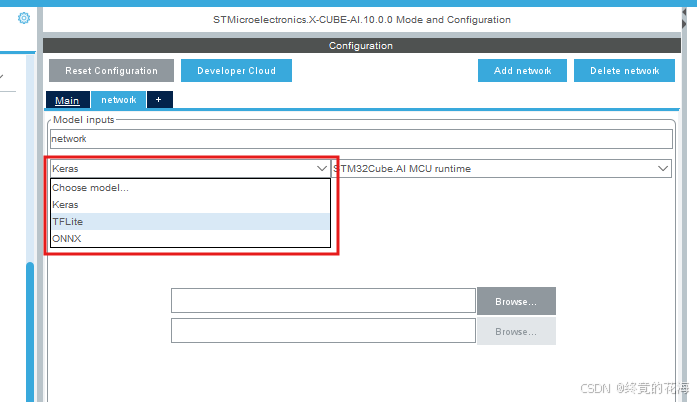
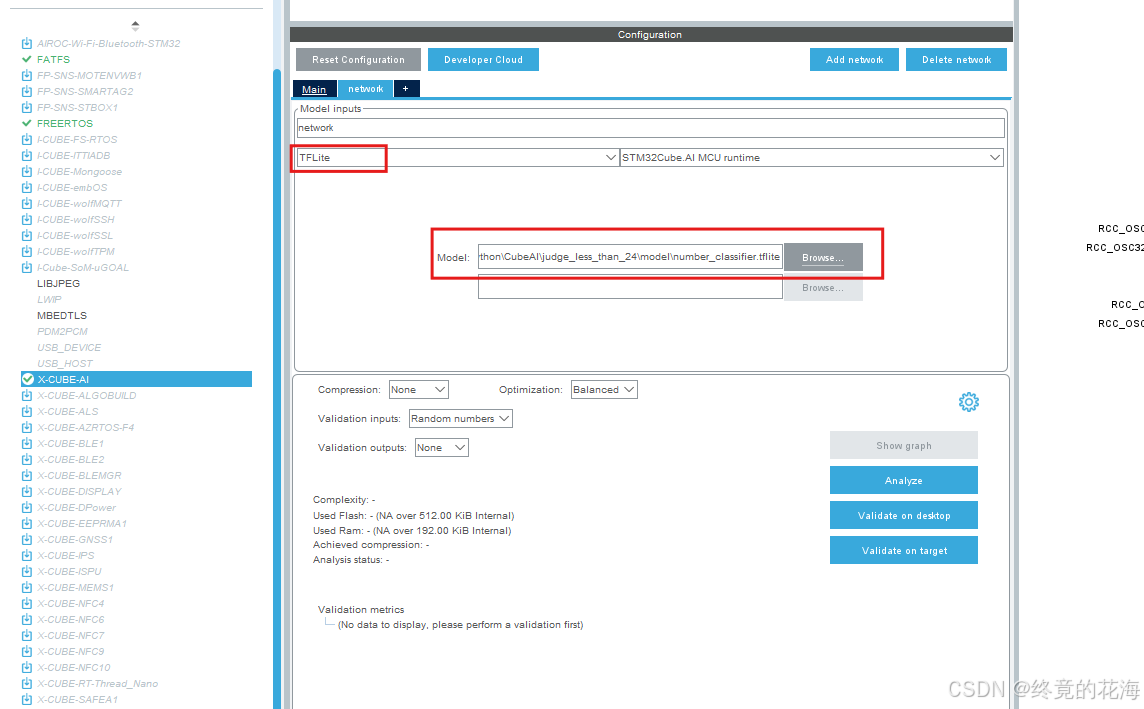
在STM32Cube的X-CUBE-AI插件里,选择TFLite格式,并选择前面我们保存的模型
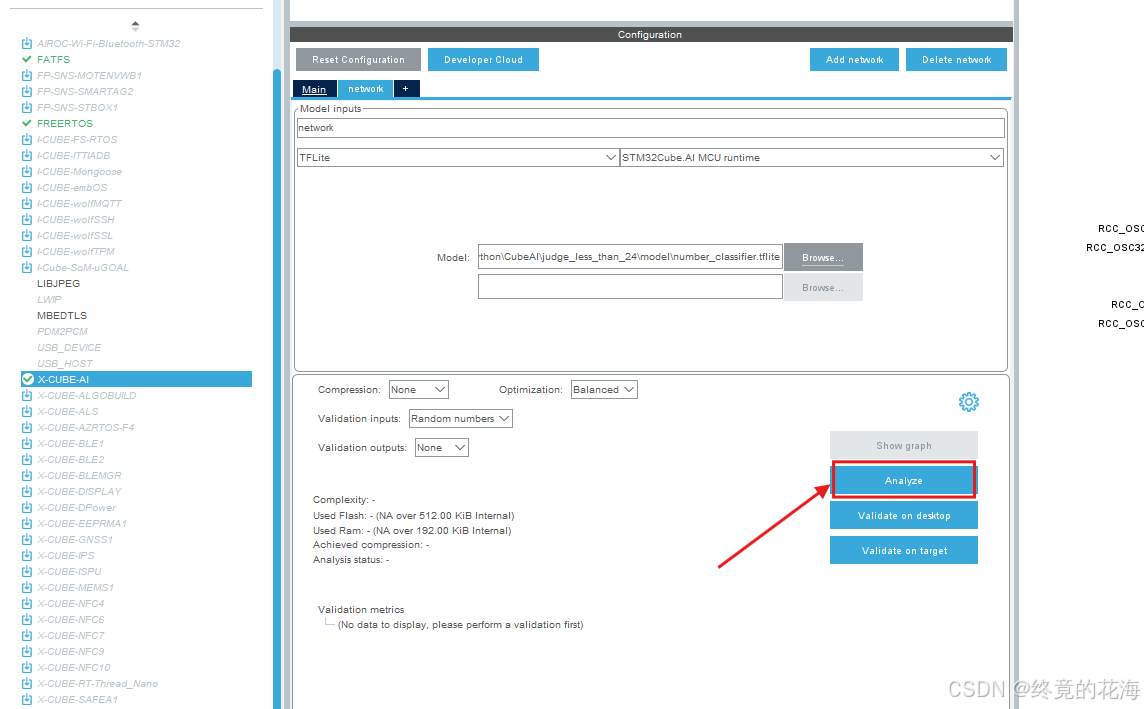
②分析模型
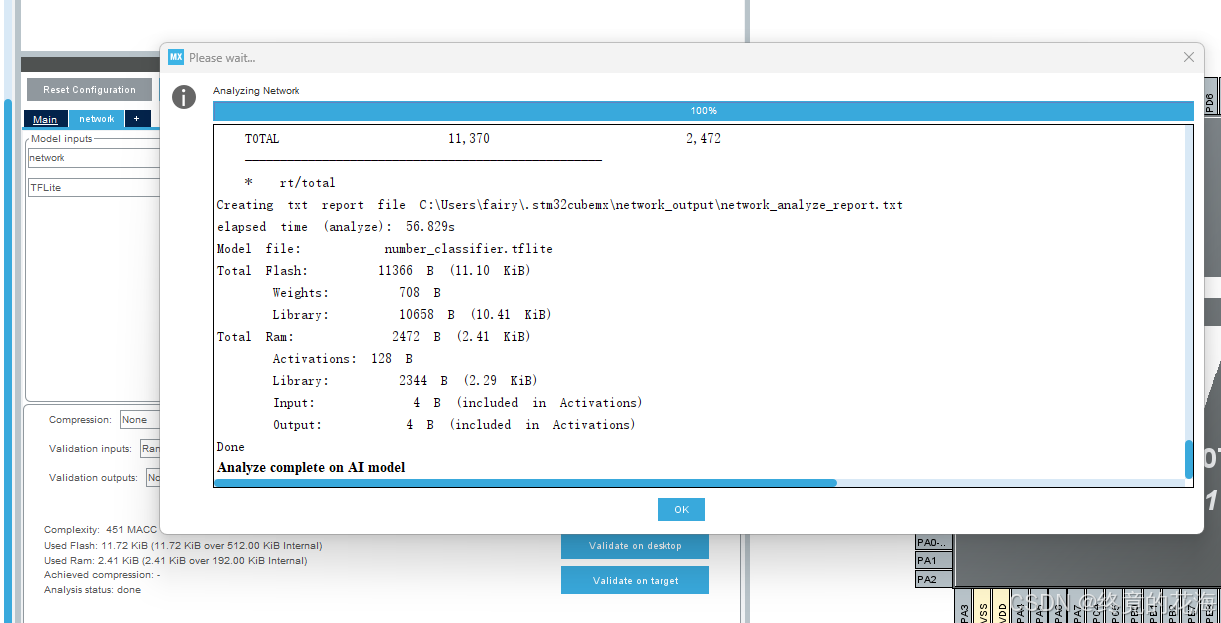
选择后,点击分析即可
分析成功后应如下,能显示分析后的Flash和Ram
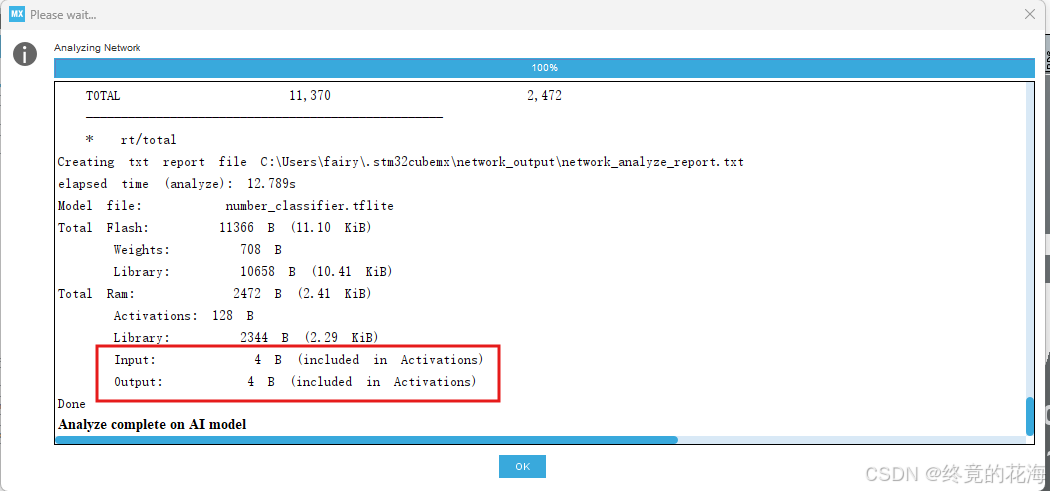
我们可以看到最后一句,输入和输出都是4字节
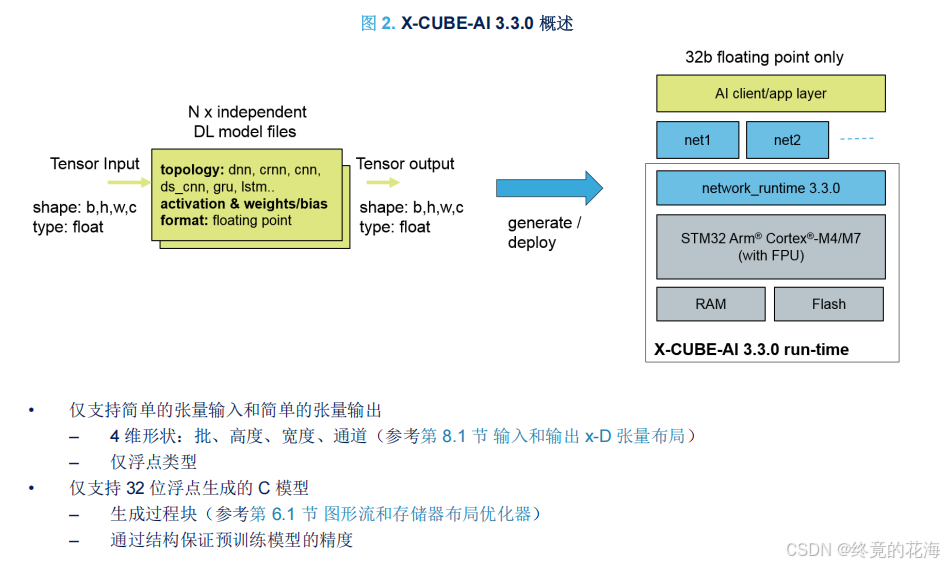
根据手册,生成的C模型或者说C代码,其实只有float32_t类型,并且仅支持简单的张量输入和输出
③张量
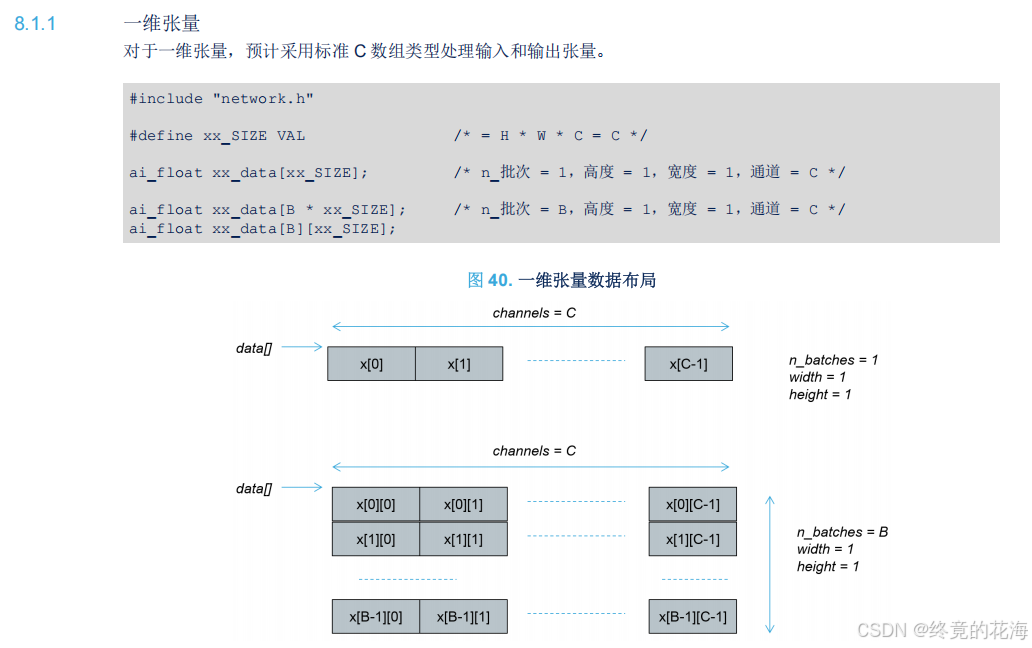
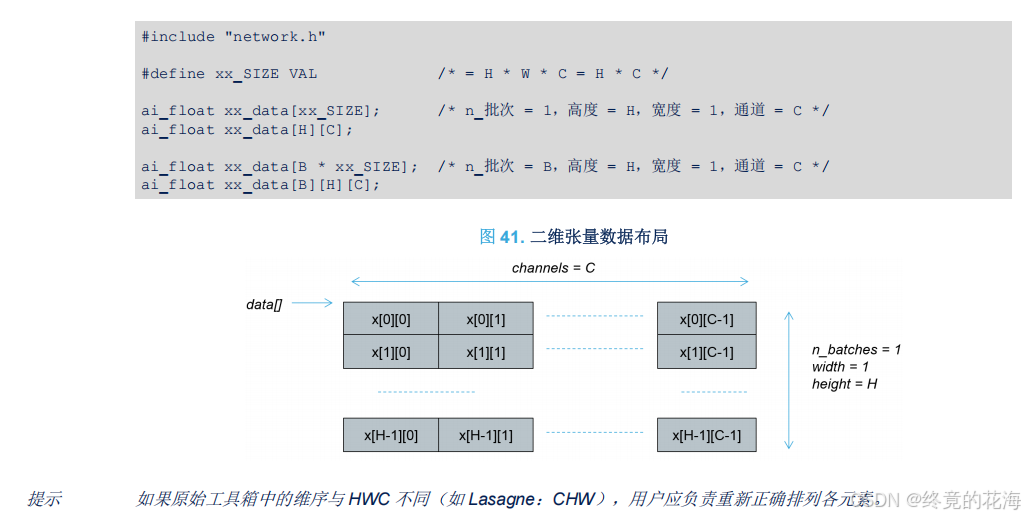
张量是里面的术语,这里强调的是数据的布局,毕竟无论是图像处理还是别的什么,数据输入与输出总得有东西存储起来。在C语言里,那么就是多维数组。
对于我们此次实验,用到的自然是一维张量,由于只用一个批次,那么自然是一维数组
④生成的文件
回到正题,既然模型经X-CUBE-AI分析成功了,那么就生成代码,此处使用的是STM32CubeIDE
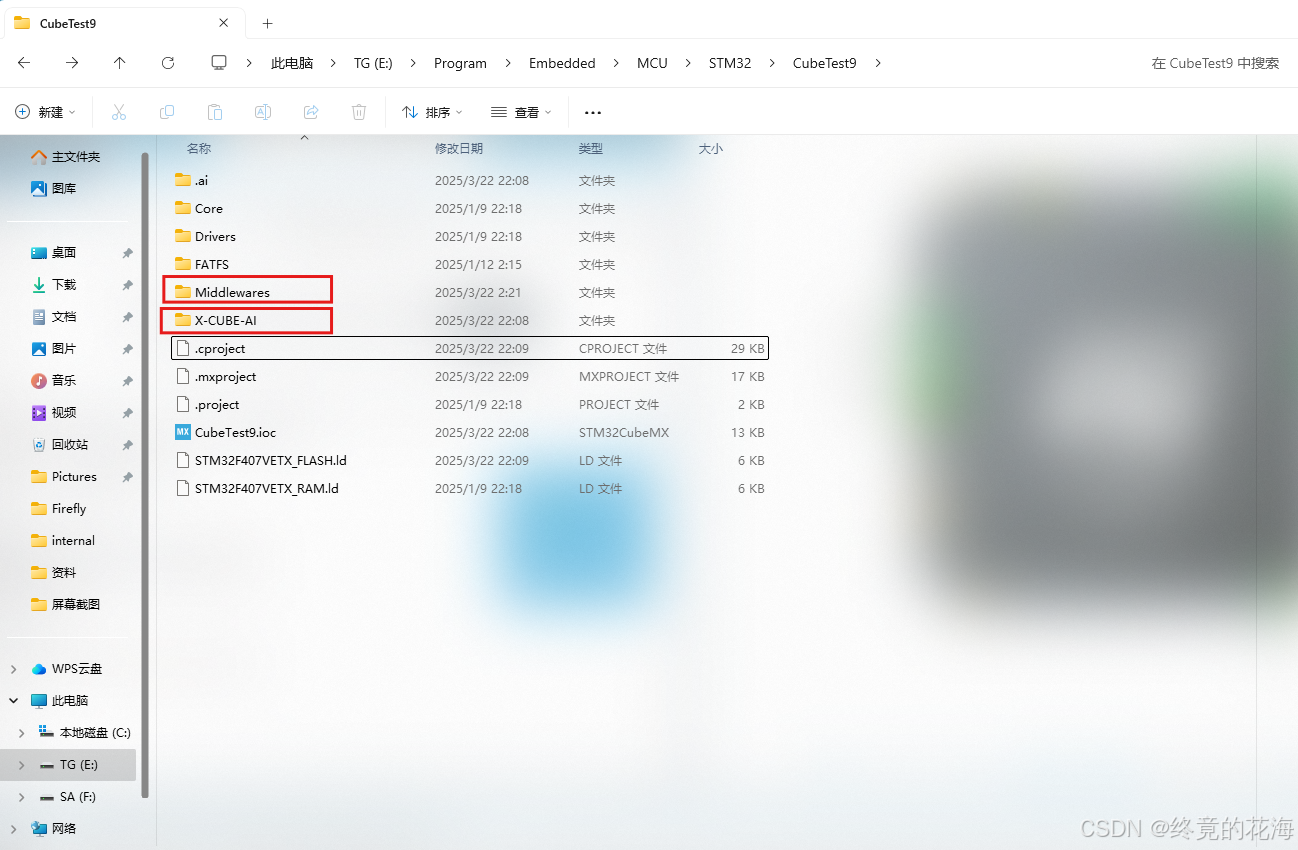
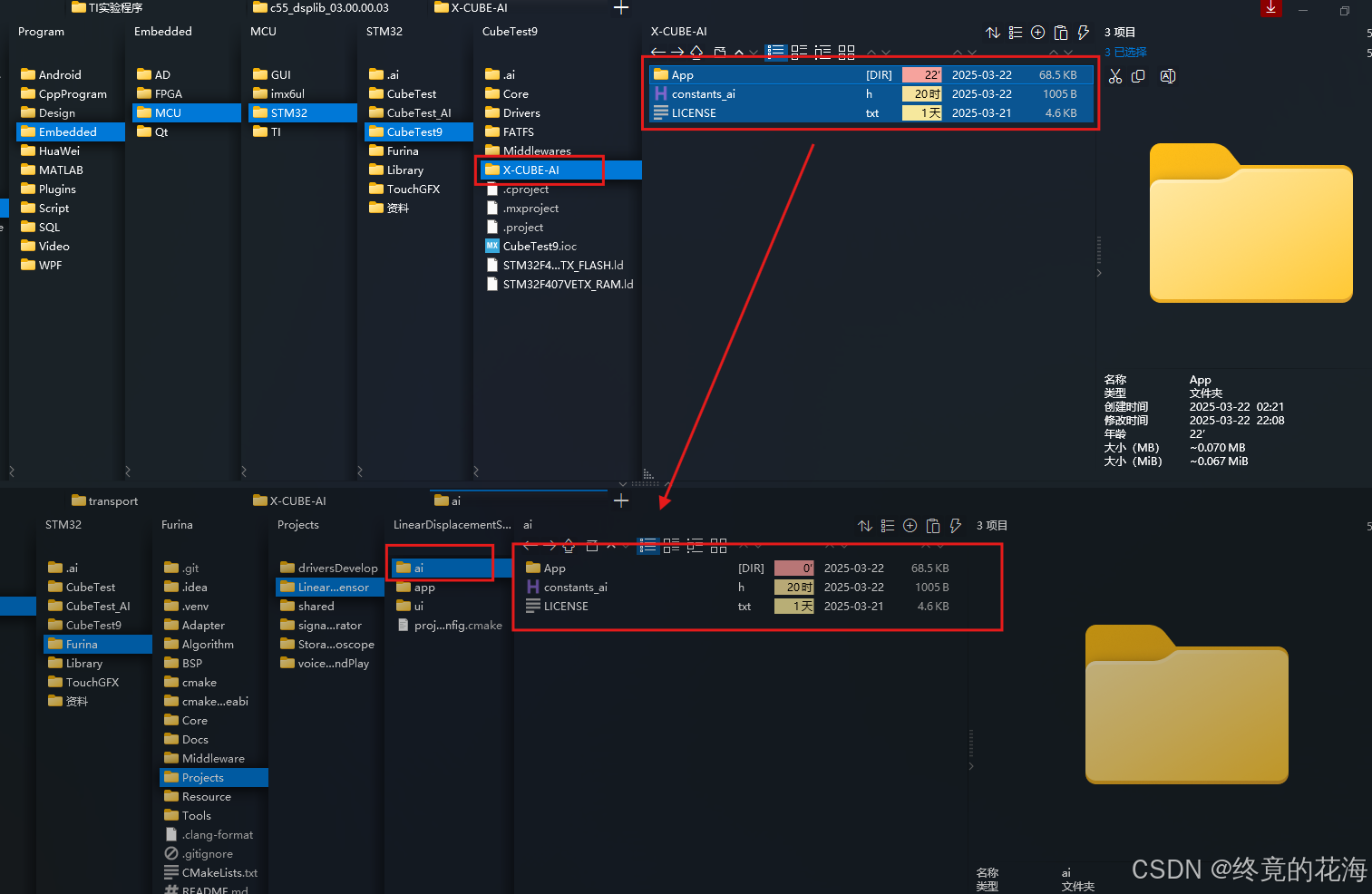
生成的代码工程中,我们需要重点关注下面这两个目录
Middlewares目录下有我们需要的AI静态库,X-CUBE-AI目录里是应用级模板。前者相当于是封装好的HAL库,后者相当于是我们自己要编写的BSP或者应用。前者自然是不能改,也改不了,后者我们可以自由更改。


2,移植库
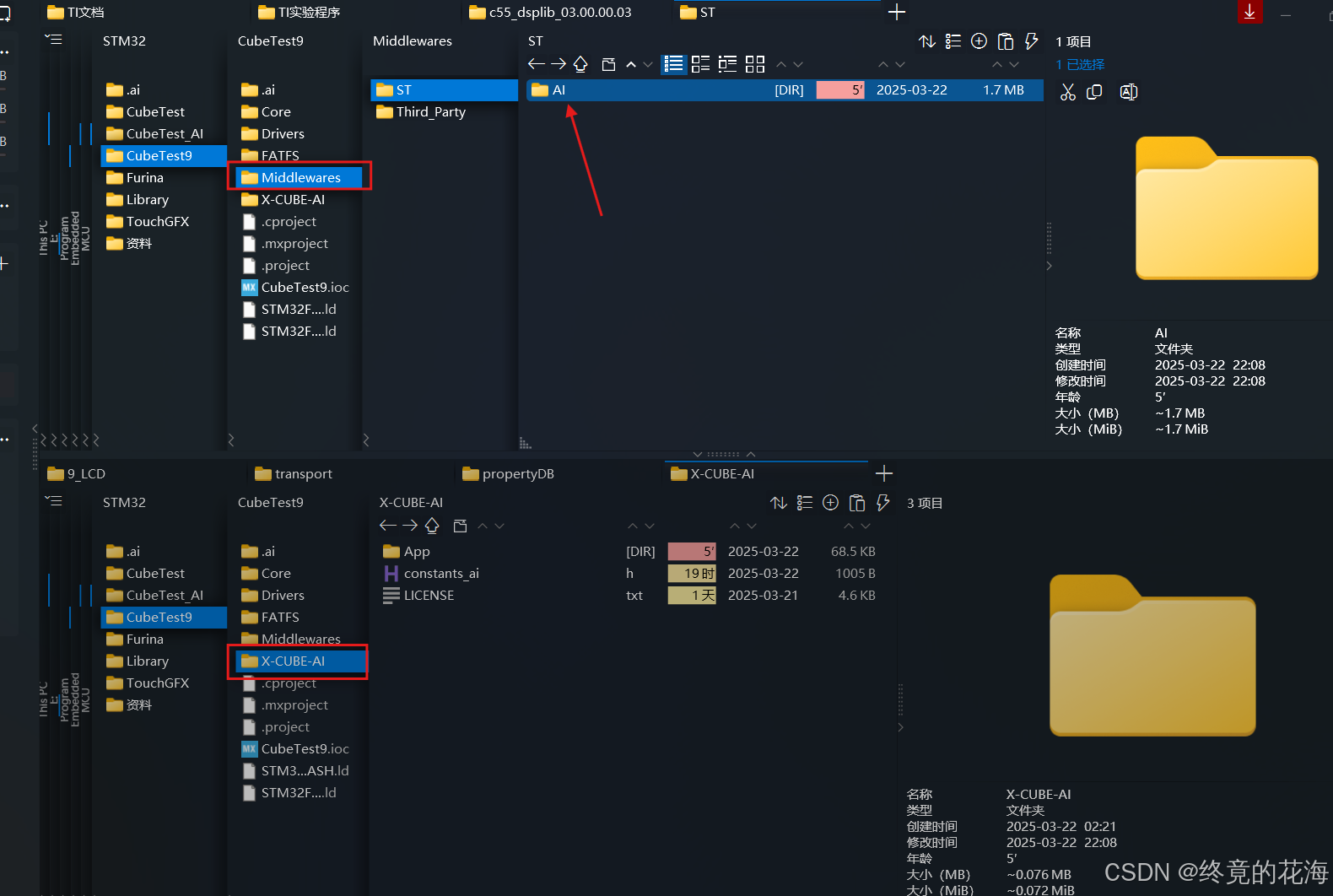
如果你移植很熟练的话,这一步也没什么难度。这里要做的事只有一件,就是把生成的代码文件移动到我们的工程里。不过要说明的是,我的工程是cmake工程,移动文件后,只需要修改CMakelists就行了。如果是Keil或者IAR的话,需要手动图形化添加这些文件。
①内核运行时库
内核运行时库指的就是下面这个后缀名为.a的静态库
移植时,需要把这个AI目录移动到自己工程里,这里建议保持跟Cube工程类似的组织结构,方便后续添加其他扩展
如果是CMake工程,那么在CMakelists里需要添加下面语句来链接静态库(疑惑的话可以多问问DS)
target_link_libraries(libai INTERFACE :NetworkRuntime910_CM4_GCC.a) target_link_libraries(libai PRIVATE libdrivers)如果是IAR或者Keil,库的头文件目录ST/AI/Inc不要忘记包含了(或者说头文件),头文件比较多,可以按Ctrl + A全部选中
②应用级模板
X-CUBE-AI这个移植就随意一点了,把里面文件放在你认为合适的目录里即可,比如你可以放在与Middleware同级的新建目录AI里
与前面一致,源文件和头文件不要忘了添加
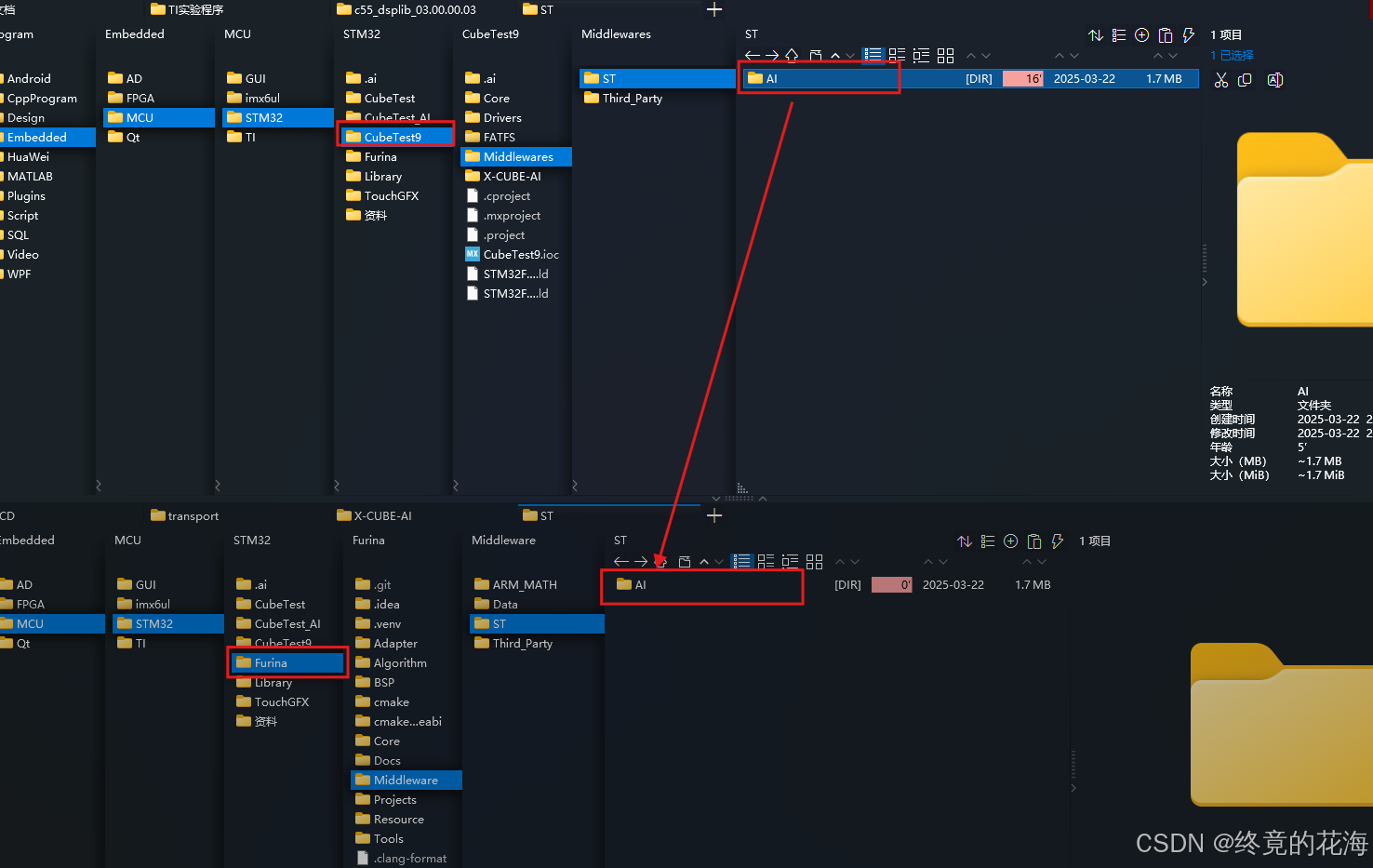
③CRC
把生成的CRC源文件和头文件都复制到自己的工程里

3,使用
最初选择软件包时,由于勾选了应用模板,生成的自然是前面看到的应用级模板,也就是给你一个使用的模板供参考
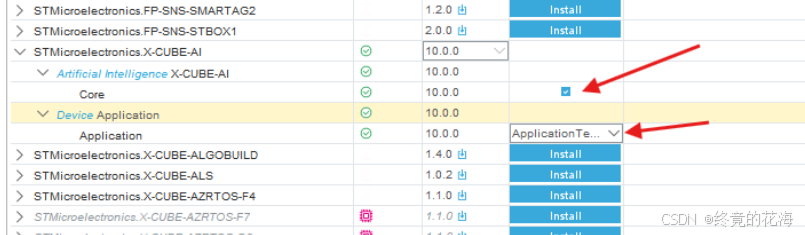
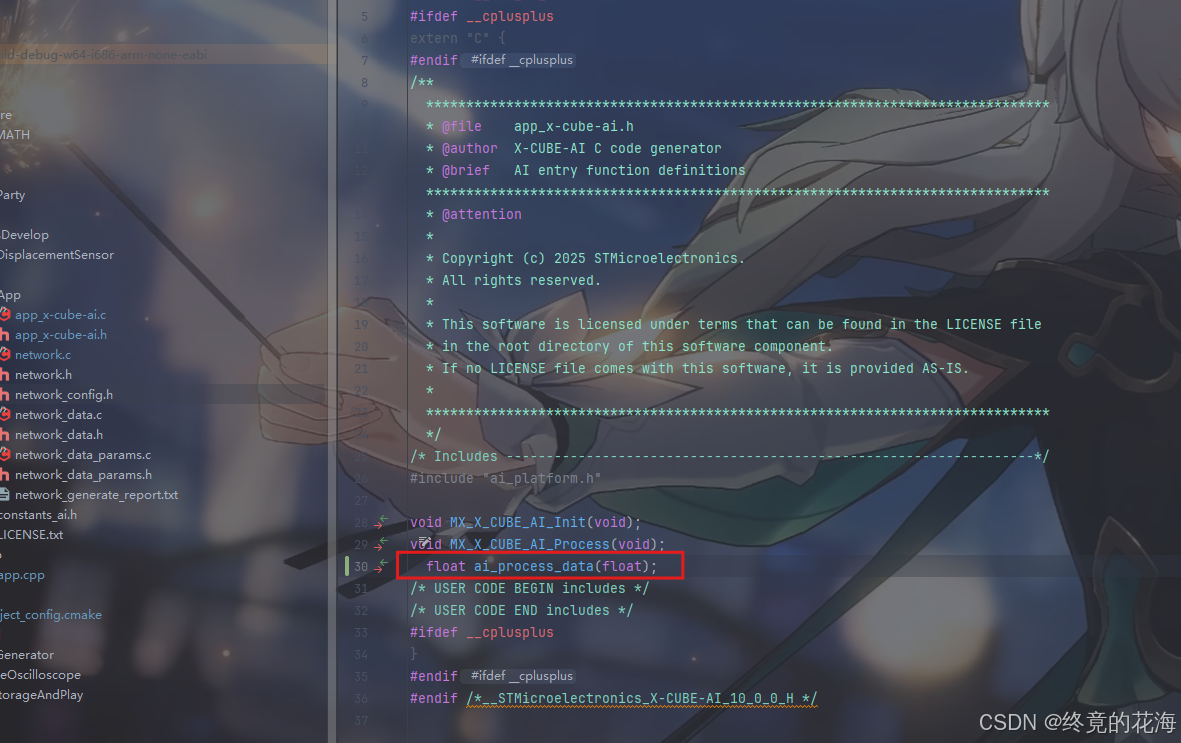
①初印象
这些文件中,我们只要考虑这两个即可。从下面的图中,可以看到app_x-cube-ai.c中有个头文件包含错误,也就是找不到main.h。这个根据自己需要改即可,由于本工程没有main.h,那么这个头文件包含去掉即可
那么在这么多函数里我们要找哪个呢?使用STM32CubeMX的经验告诉我们,应该重点关注带有MX_前缀的函数。从这两个函数的名称可以看出,一个是初始化的示范,另一个是使用AI推理的示范
②简单分析
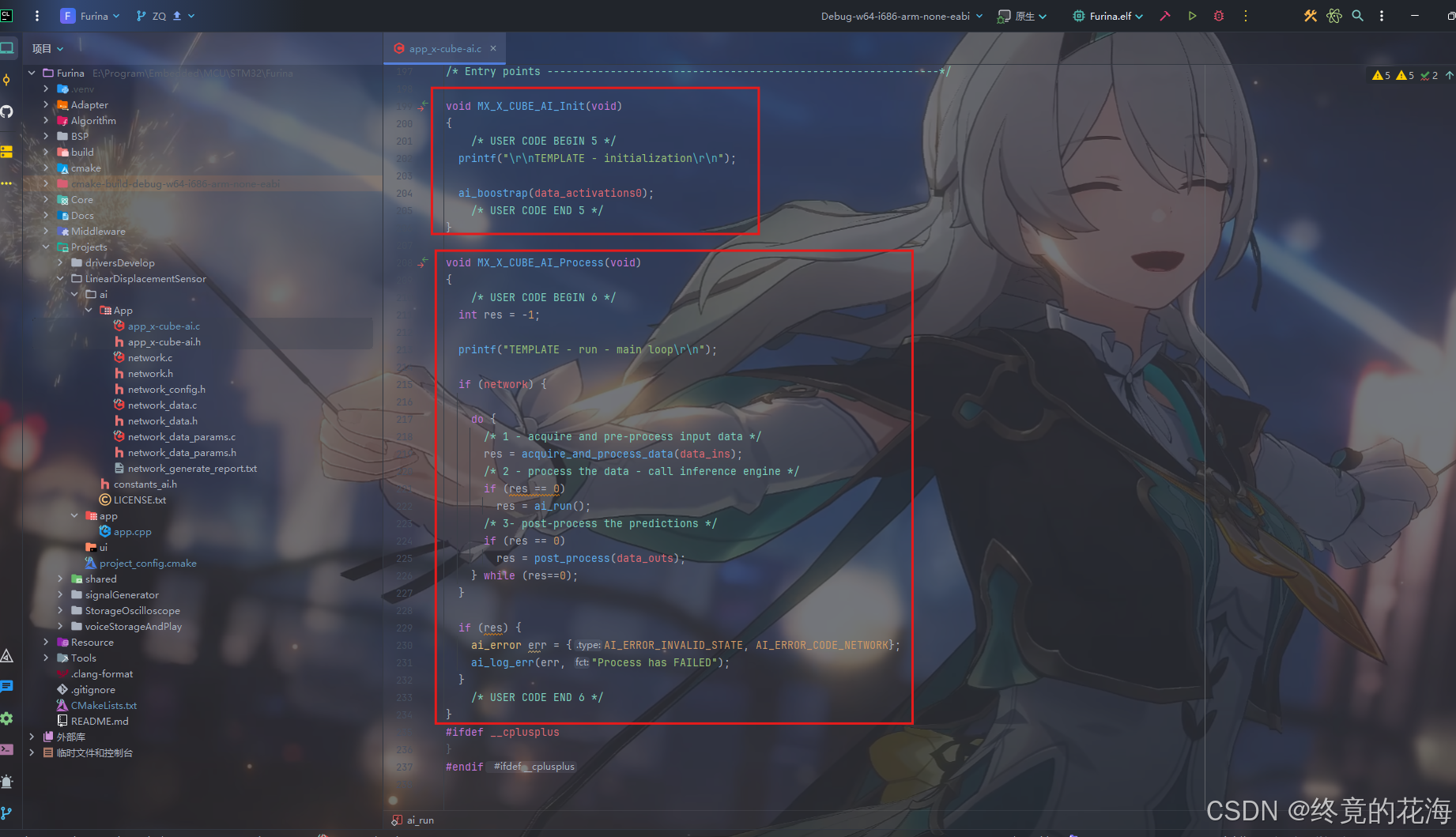
MX_X_CUBE_AI_Init
我们先观察初始化函数,可以看到这个函数的初始化过程其实就两步,使用printf打印提示信息和调用ai_boostrap这个函数
那么进入这个函数,会发现它是一个静态函数,也就是说这个函数只在这个模板文件里存在,那么自然就可以随便修改。
其内部充斥着大量条件预编译指令,但细看就可以拆解为下面几个部分:
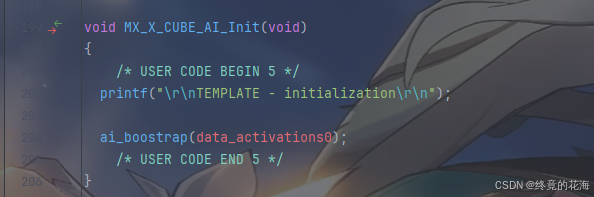
ai网络初始化、获取ai网络的输入和输出缓冲区指针、拷贝那两个缓冲区
怎么拷贝呢?以输入缓冲区为例,从形式上来看,好像是把ai_input赋值给外部的缓冲区data_ins,嗯?这是不是反了呢?
实则不然,因为它们都是指针,这句代码实际上是把内部缓冲区指针给这个外部缓冲区指针。没错,data_ins是个指针数组,用来保存内部缓冲区的指针,我们可以通过data_ins指针数组里的指针来间接访问内部缓冲区,进而达到向内部缓冲区读取或写入数据的目的
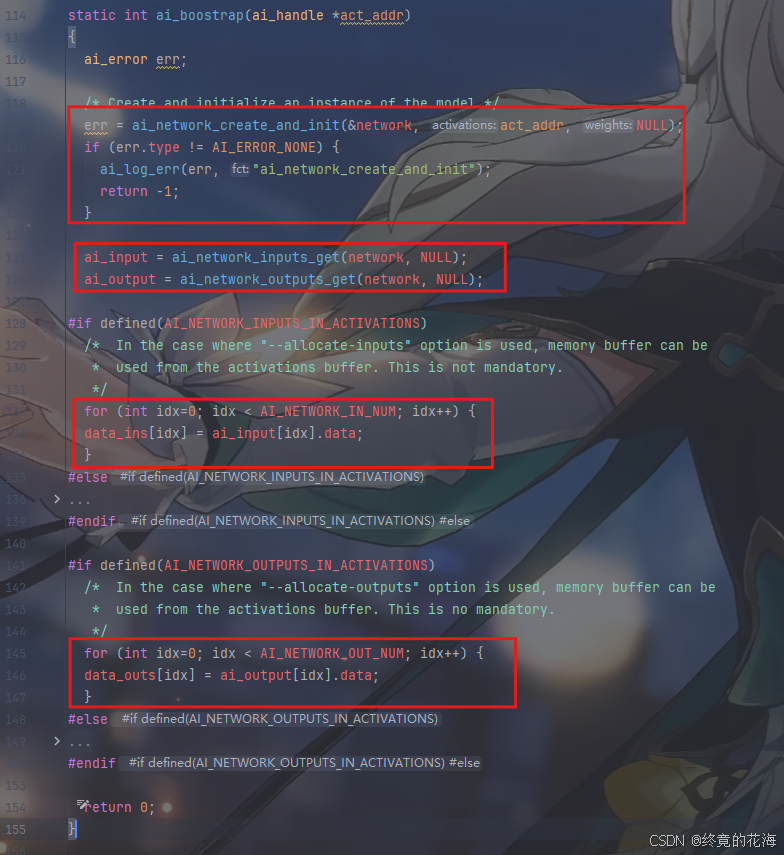
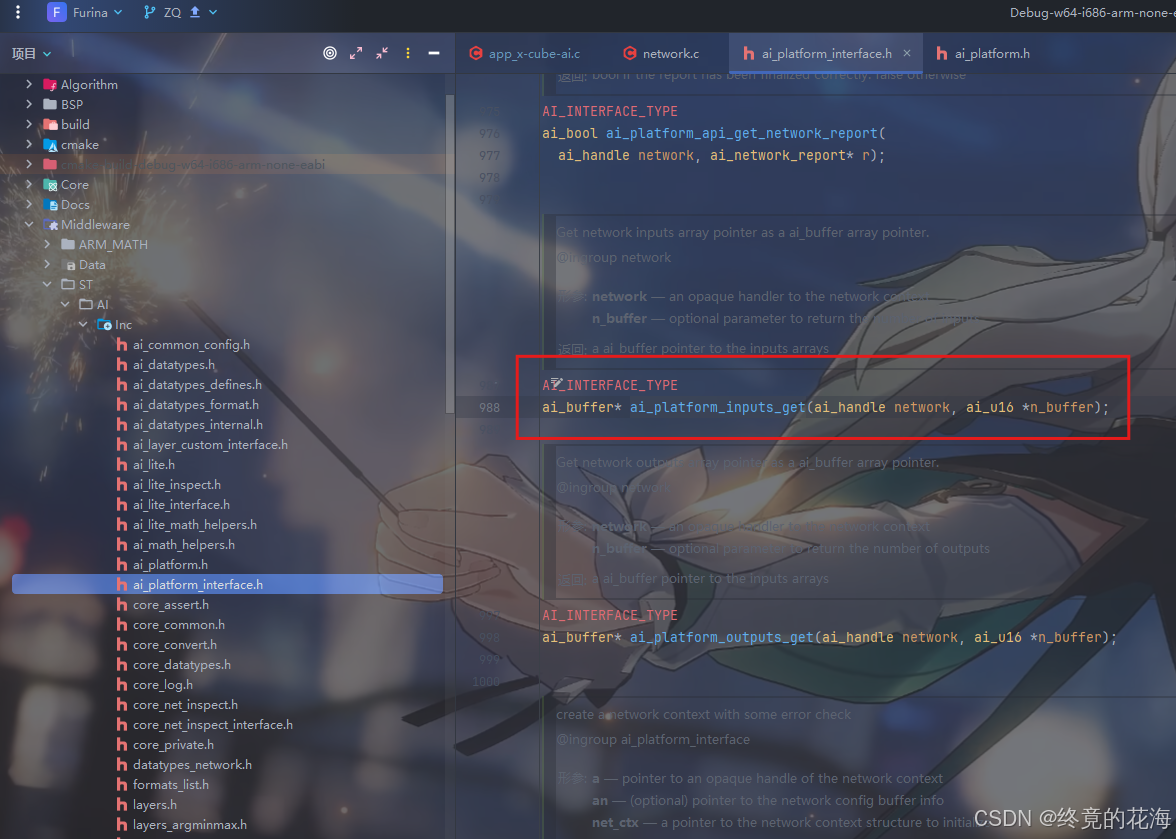
我们接着进入ai_network_inputs_get函数,先是检查ai网络句柄(其实就是个指针),然后再调用一个函数来返回输入缓冲区的指针
继续进入ai_platform_inputs_get函数里,发现进不去,而是进入了这个函数声明里。显然,这是之前移植的那个AI内核运行时库的API(应用程序编程接口),也就是ST提供给你的函数,与HAL没什么区别,直接调用即可。
从这可以看出,这个AI应用级模板的套路其实就是调用那个运行时库的API,做了一些检查机制并提供一层层的封装。需要注意的是,不同版本的X-CUBE-AI拓展包提供的API不一定相同
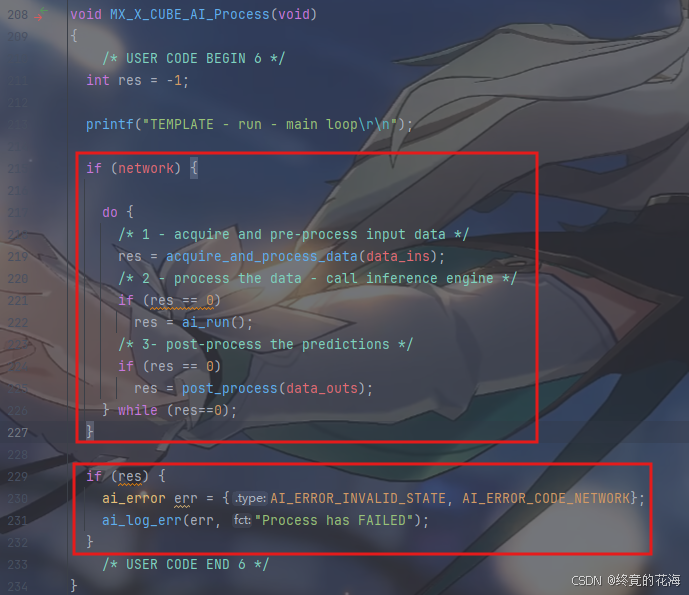
MX_X_CUBE_AI_Process
接着来看这个处理函数,这个处理过程非常地自然。上面这一块显然是进行AI推理的部分,下面这一块是判断AI推理结果的部分
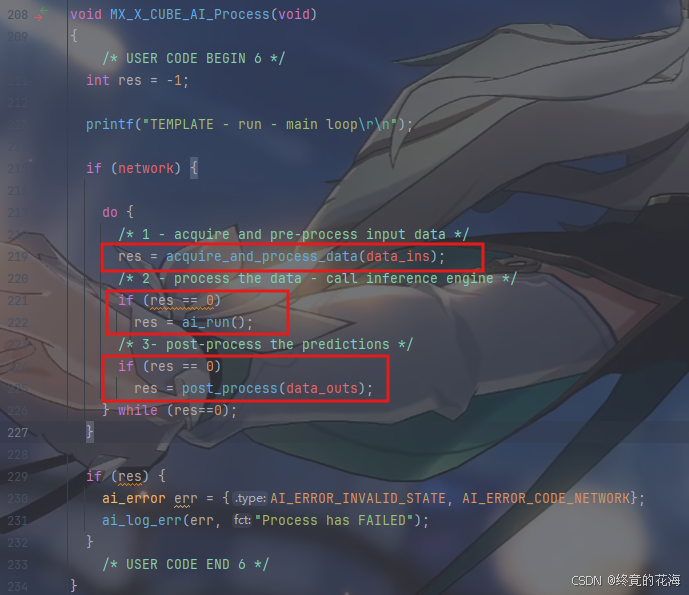
先看AI推理的部分,这里使用一个do while循环,显然是处理不同批次的数据。对于每一批次,我们可以从注释看到三步走的过程——先调用acquire_and_process_data
获取并处理输入数据,然后调用ai_run来推理,最后再调用post_process函数处理输出结果
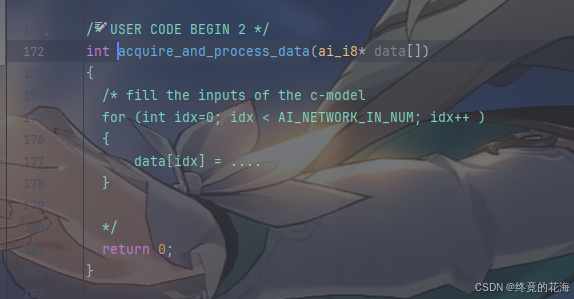
那么我们看看这三个函数在干嘛,先看acquire_and_process_data。你会发现它其实是空函数,不过注释里已经有了很明显的注释,它的意思是把数据放到data这个数组(缓冲区)里,比如传感器数据、从ADC里获取的数据等,只不过是以指针的形式
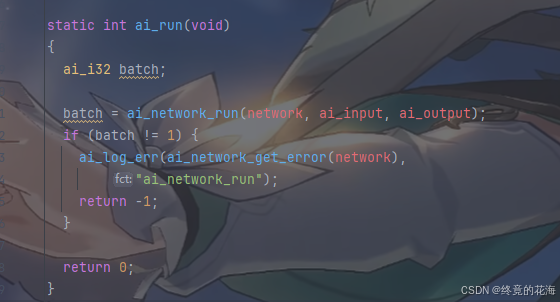
那么ai_run在干嘛呢,从图下可以看出,它根据ai网络句柄、输入输出缓冲区来进行推理
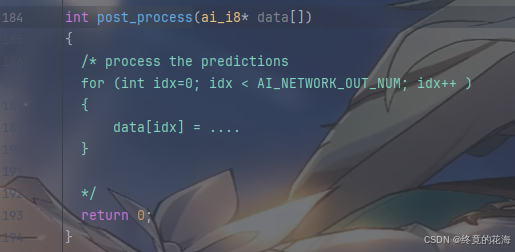
那么post_process呢,从名称上来看,它的作用是进行后处理,也就是下面注释提到的“处理推理结果”
③添加代码
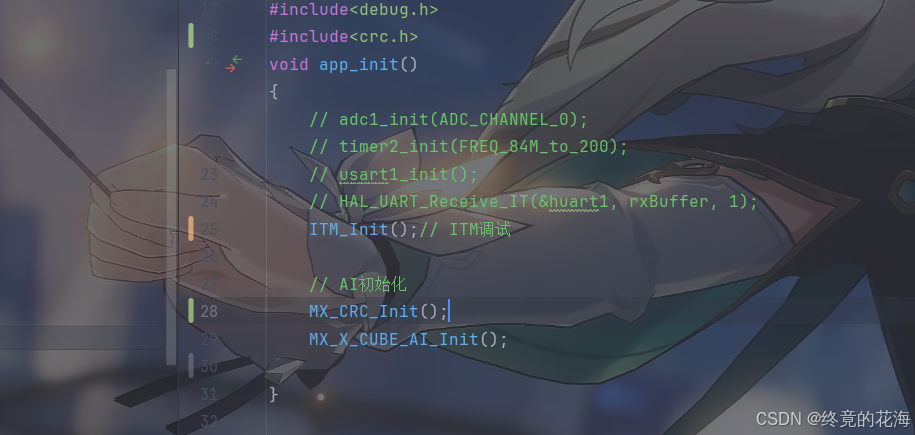
对代码进行简单分析后,那么我们想使用AI推理的步骤就很清晰了。首先是CRC初始化和AI初始化,既然MX_CRC_Init和MX_X_CUBE_AI_Init做得很完善了,那么直接调用它即可。
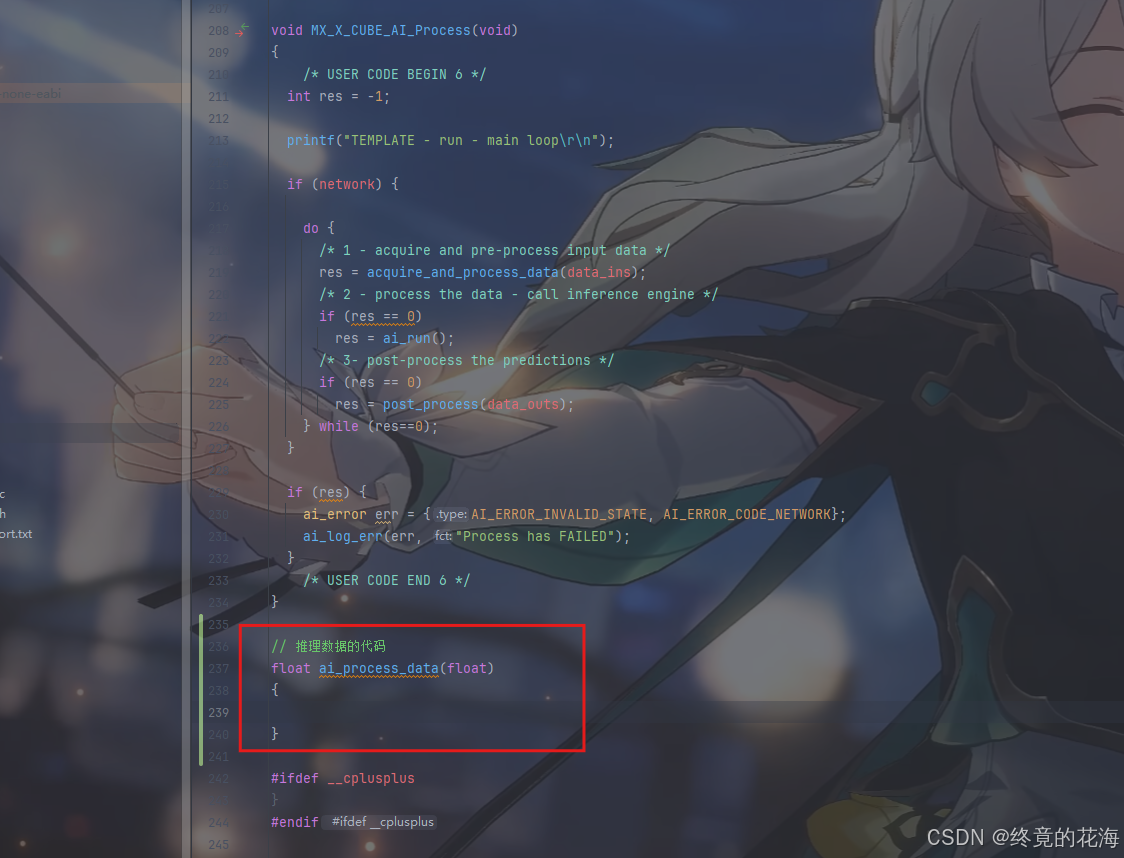
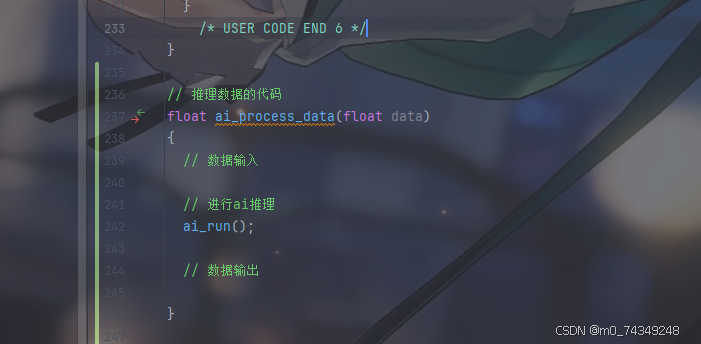
接着是对输入数据进行推理,由于MX_X_CUBE_AI_Process完全是个空模板,那么就要求我们对其进行一些修改。
出于测试(省事)的目的,我们不需要做那么多检查,也不用那么多层封装。因此只需要输入数据、处理数据、输出数据这三个简单步骤。为此,我们可以编写一个这样的函数供调用。
先搭建一个空函数,在它旁边即可
头文件里声明它
搭建一个基本的三步走
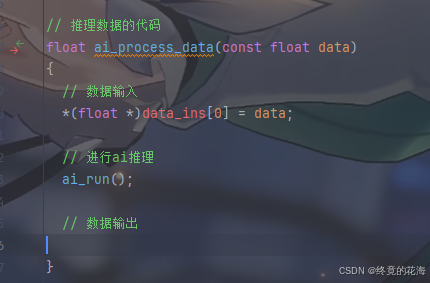
前面提到,数据输入只需要对外部缓冲区指针data_ins操作即可,同时手册里也提到,生成的C模型目前只支持float32_t类型,也就是说给我们看到的这个ai_i8类型(singed char)实际上与我们要输入的数据类型无关
那也就是说,我们需要让输入数据以float的形式进行存储,那么需要进行强制转换。索引是0也很好理解,因为我们只有一个批次一个输入数据
数据输出自然是返回data_outs里的数据,并且也要以float32_t的形式读取出来
那么最终的代码就是
// 推理数据的代码 float ai_process_data(const float data) { // 数据输入 *(float *)data_ins[0] = data; // 进行ai推理 ai_run(); // 数据输出 return *(float *)data_outs[0]; }标准化
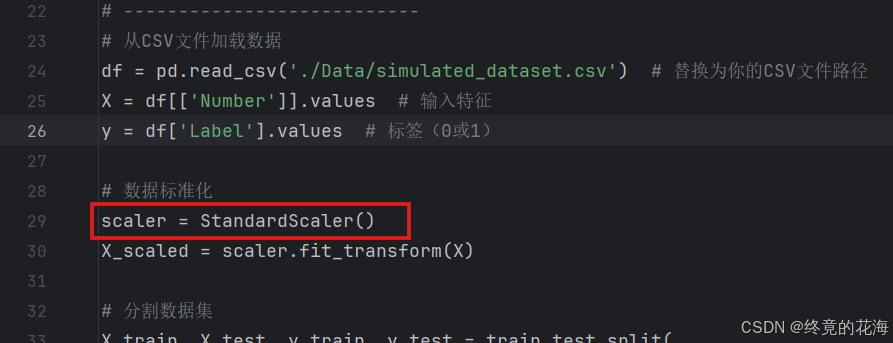
but!!有一个非常容易忽略的问题,如果训练模型时对输入数据进行了标准化(StandardScaler),那么部署在stm32上的输入数据也要标准化,不然输出数据可能完全不对。以本次为例,输入大于0的数,输出数据就会全部变成0.00
// 推理数据的代码 float ai_process_data(const float data) { // 数据输入 // *(float *)data_ins[0] = data; *(float *)data_ins[0] = (data - 24.5f) / 5.0f;// 复现标准化 // 进行ai推理 ai_run(); // 数据输出 return *(float *)data_outs[0]; }④测试
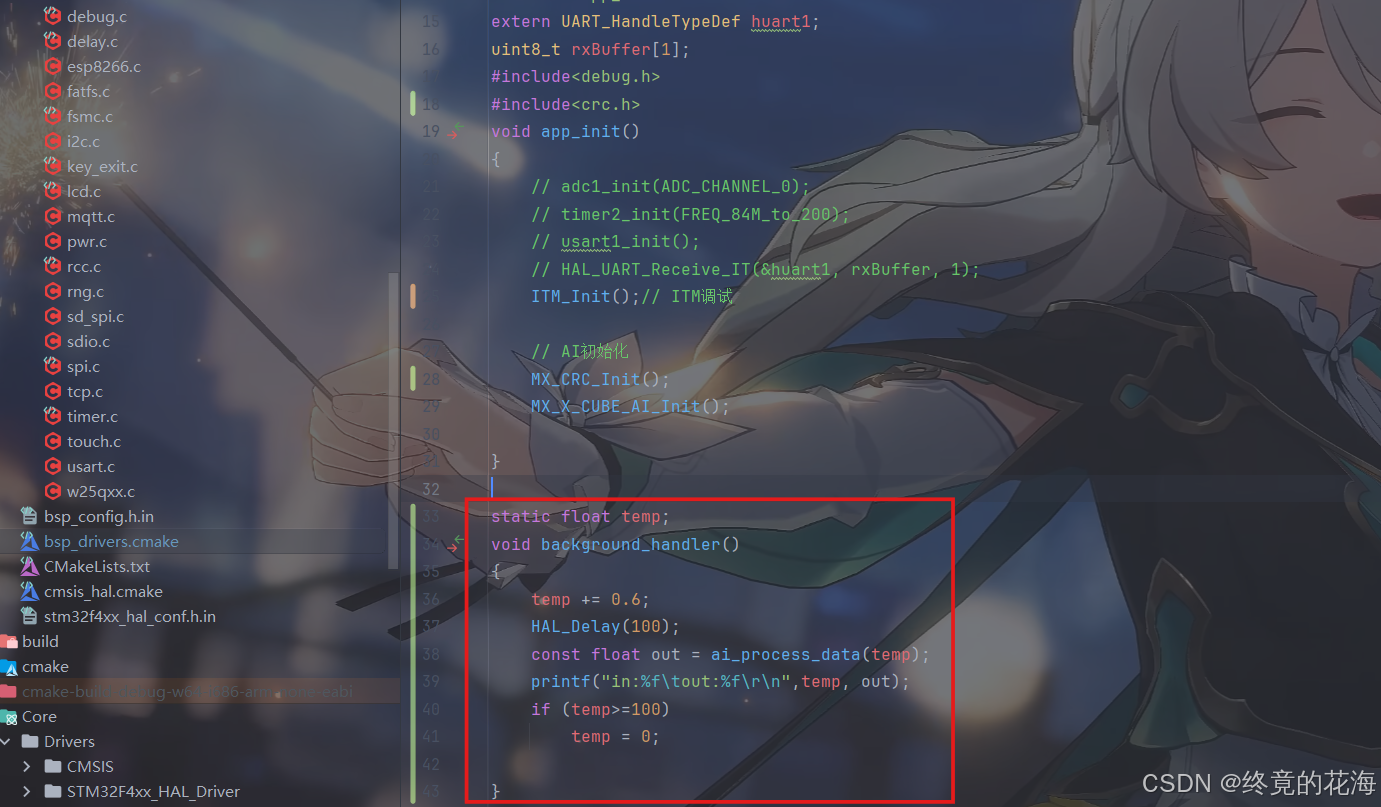
为了测试一下部署的AI模型能否工作,这里写了一个简单的测试代码。
app_init和background_handler都是封装过的函数,前者是初始化各种驱动的,后者是后台任务,也就是死循环
打印串口使用的是ITM,仅通过ST-Link仿真器即可打印信息到CLion上。当然,你也可以使用其他手段,比如直接从调试栏观察变量、使用USB转TTL等
参考博客:STM32使用ITM调试_通过仿真器实现串口打印_stm32 itm-CSDN博客
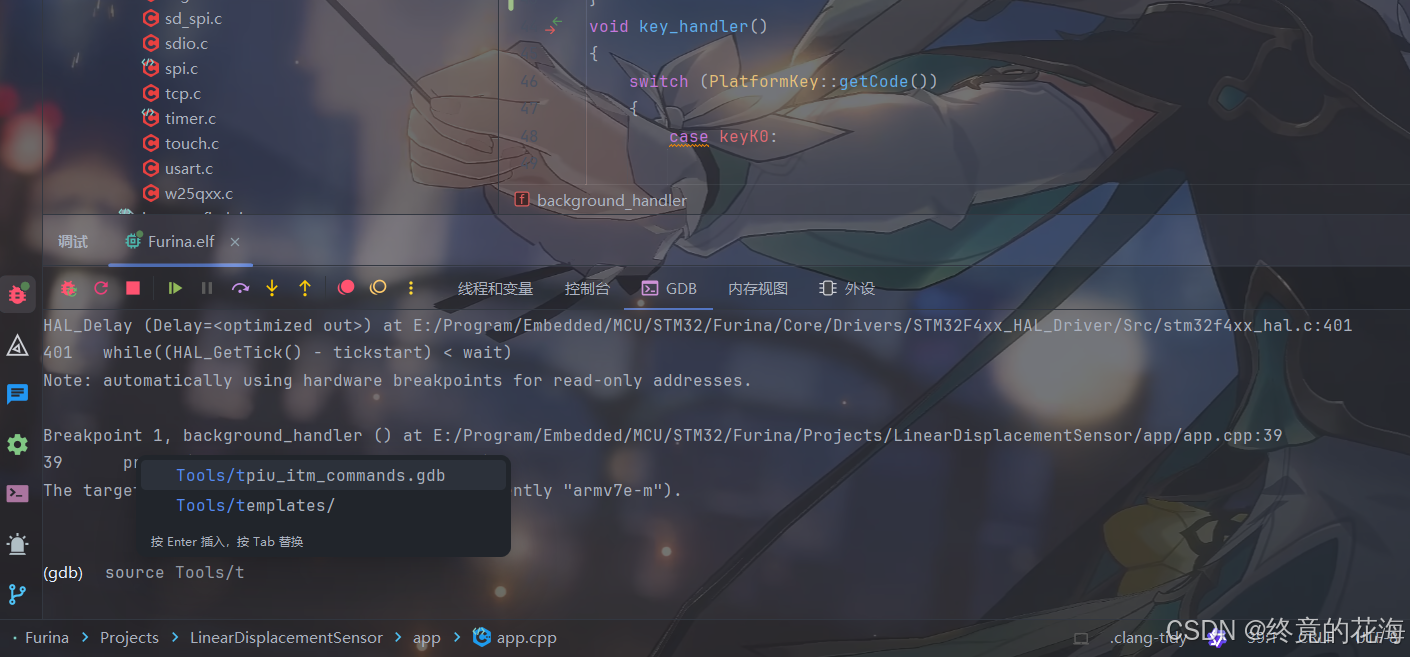
先在GDB窗口加载gdb脚本(脚本在上面博客里)
然后在终端输入TCP命令,连接端口(其实可以直接编写ps1脚本一步到位)
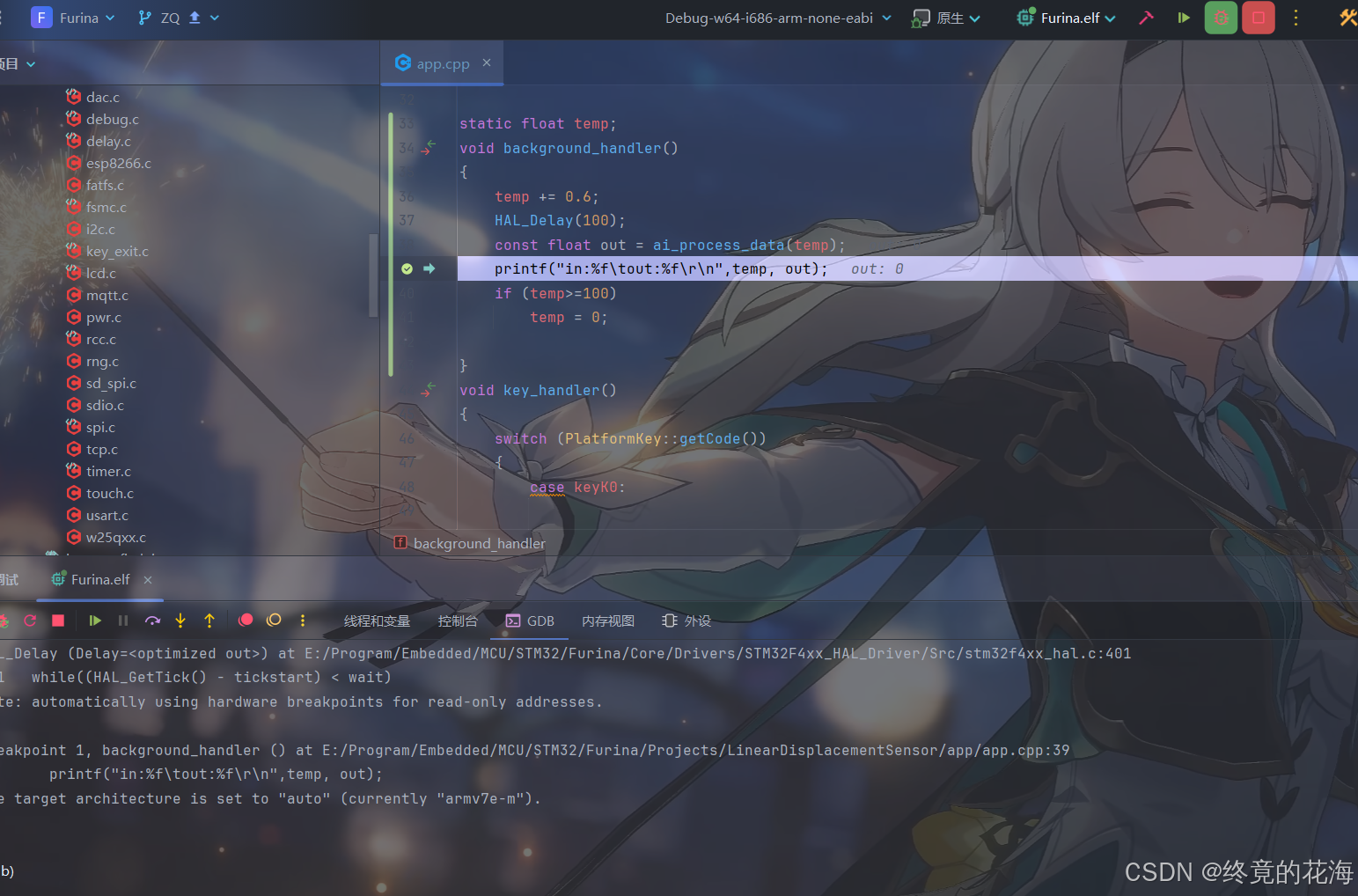
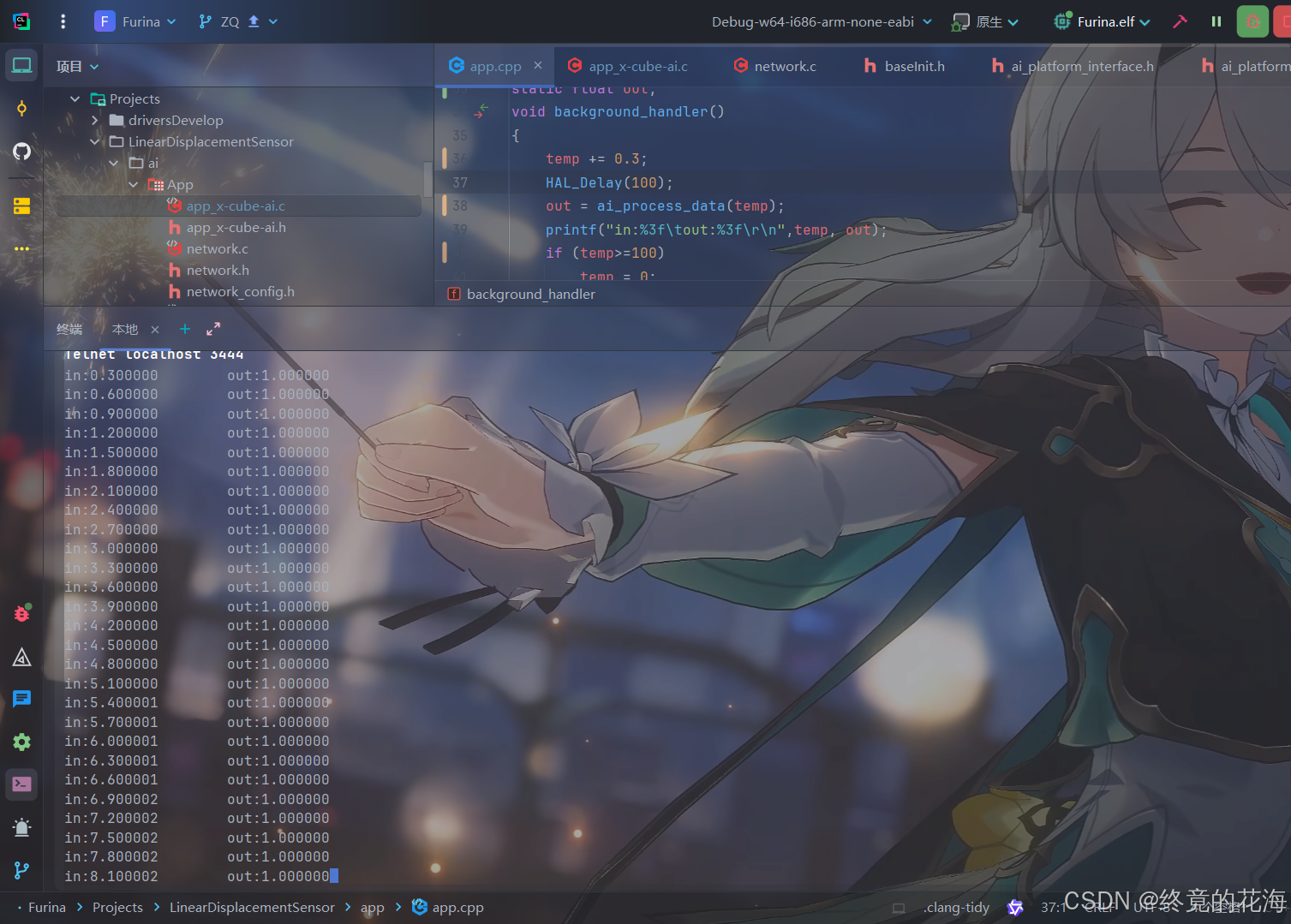
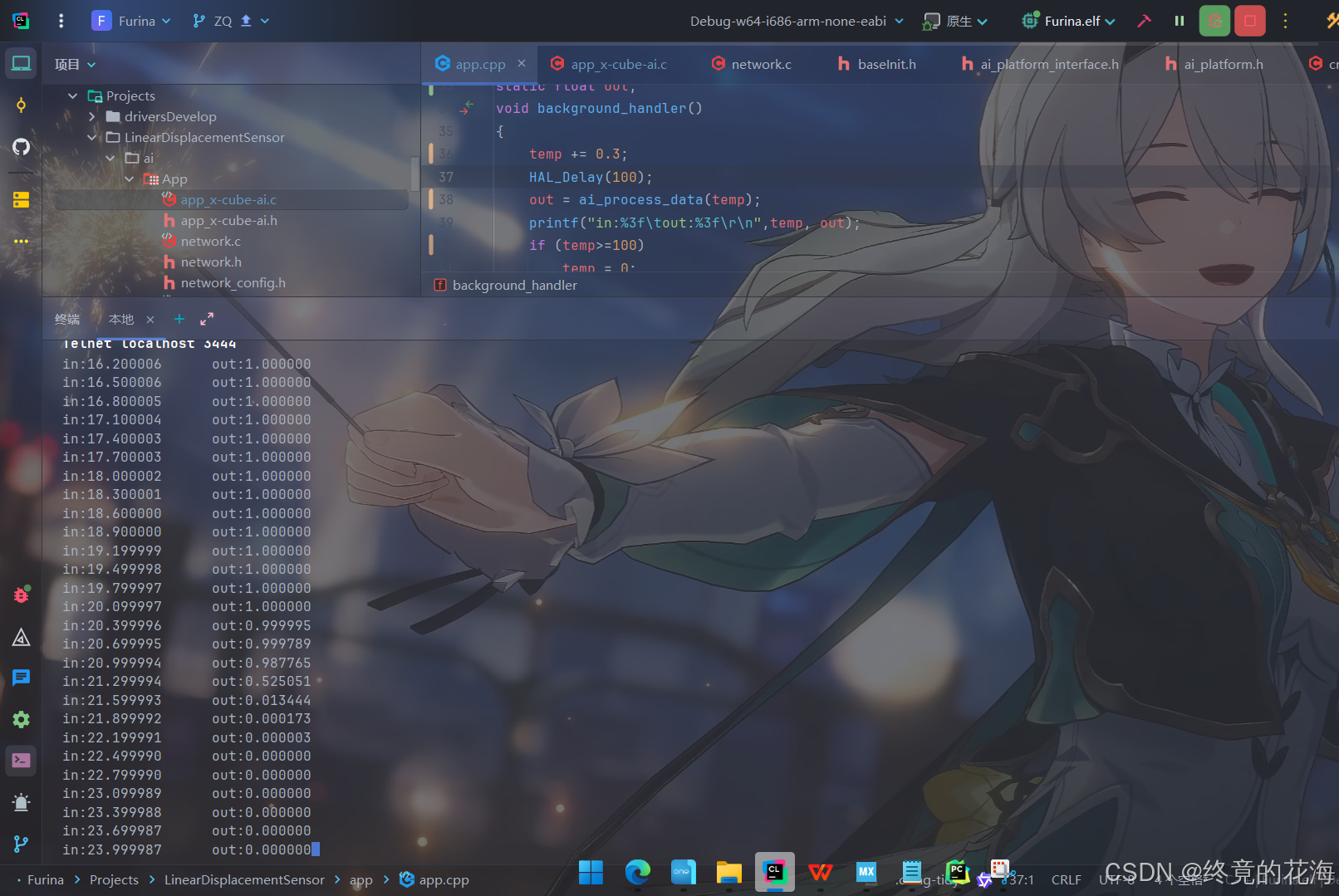
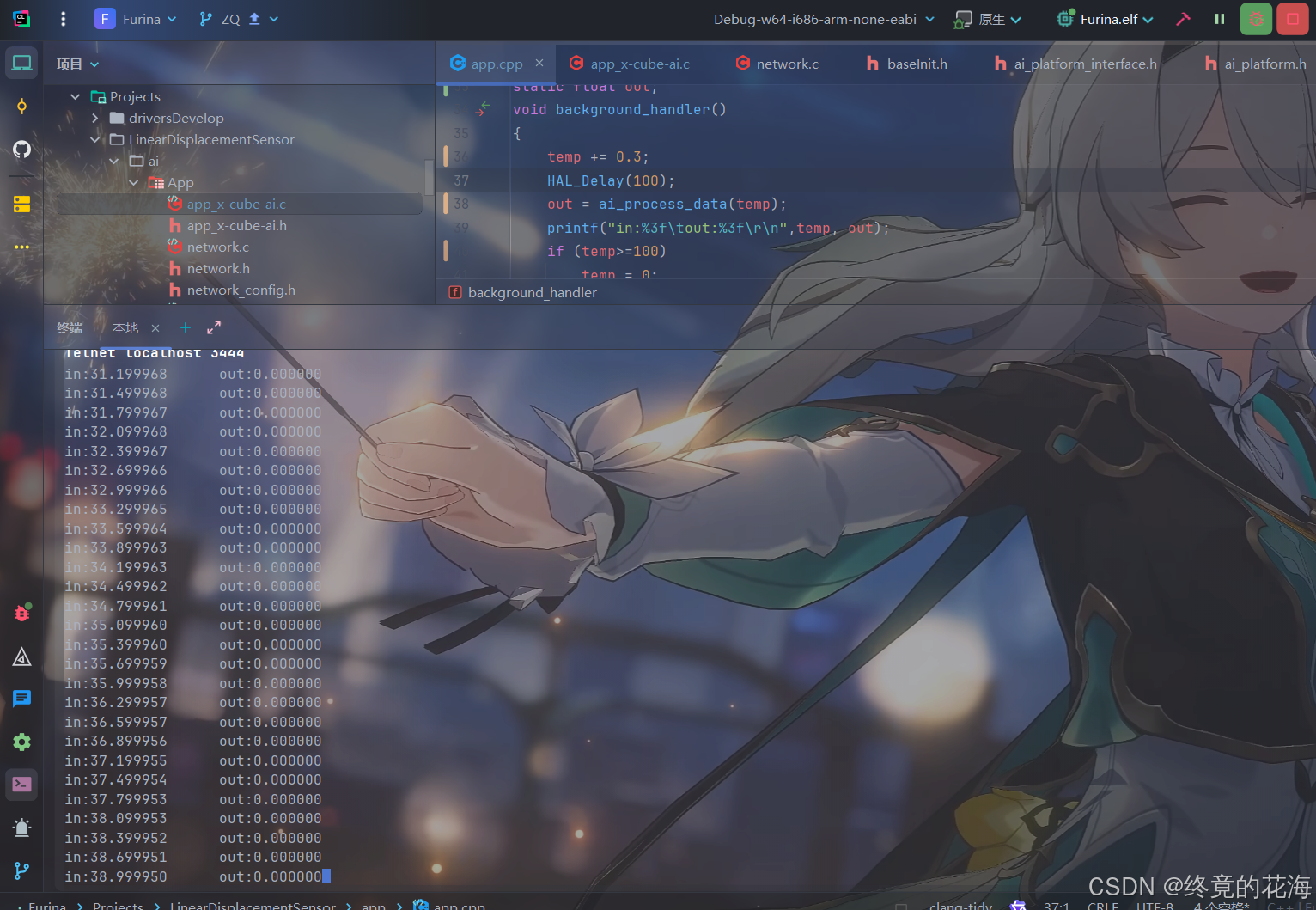
运行后可以看到,能进行正常的ai推理
由于训练时用的是整型数据,并且没有在24附近进行强化训练,所以模型在24附近没那么准
但其他地方很准,非常符合预期


七、跨越
AI模型转为C代码可以不使用CubeMX的这个插件,但那样占用可能会很高,性能无法有效利用。对于STM32平台,无论是操作的便捷性还是针对STM32的性能优化,使用官方的无疑是比较合适的。如果是其他单片机,那么直接使用由TensorFlow Lite训练的模型转换的C代码,占用也不会很夸张,因为它专门用于嵌入式平台。
至于神经网络、CNN、LVTM、图像识别什么的,从0.9到∞,就需要靠自己主动学习了。
八、日志
2025.3.21
感谢大家的支持,经一些同志的反馈,文章部分内容有些含糊,且版本有些落后(这是无可避免的)。为此,更新了一下部分内容,并添加了一些信息提示。当初写下本篇时,最好用的免费大语言模型还是通义2.5,现在有了DeepSeek,那么辅助学习就更加简单准确了。于是,把当初通义回答的图片替换为了DeepSeek,后文中DeepSeek就简称为DS。
今晚先更新训练代码的部分,明晚再更新部署过程

















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









