






微调大型语言模型(ChatGLM)是一个复杂而精细的过程,其中选择和调整超参数(如学习率、批量大小、训练轮次等)至关重要。这些参数直接影响模型的性能、收敛速度以及最终的输出质量。幸好我们使用的是LLaMA-Factory,不仅调参这个操作被简化成直观的图形界面,还贴心的提供了不同参数的分类,方便我们进行研究尝试。在这篇博客中,我们将深入探讨微调过程中常用超参数的设置与优化策略,分享我的实践经验与实验数据。
超参数是指在模型训练前需要手动设置的参数,影响模型训练过程和最终性能。不同于模型的参数(如权重和偏置),超参数不通过训练过程来学习,通常需要通过实验来选择最佳值。常见的超参数包括:
- 学习率(Learning Rate):控制模型权重更新的步长。
- 批量大小(Batch Size):每次迭代中处理的数据样本数量。
- 训练轮次(Epochs):整个数据集被用来训练模型的次数。
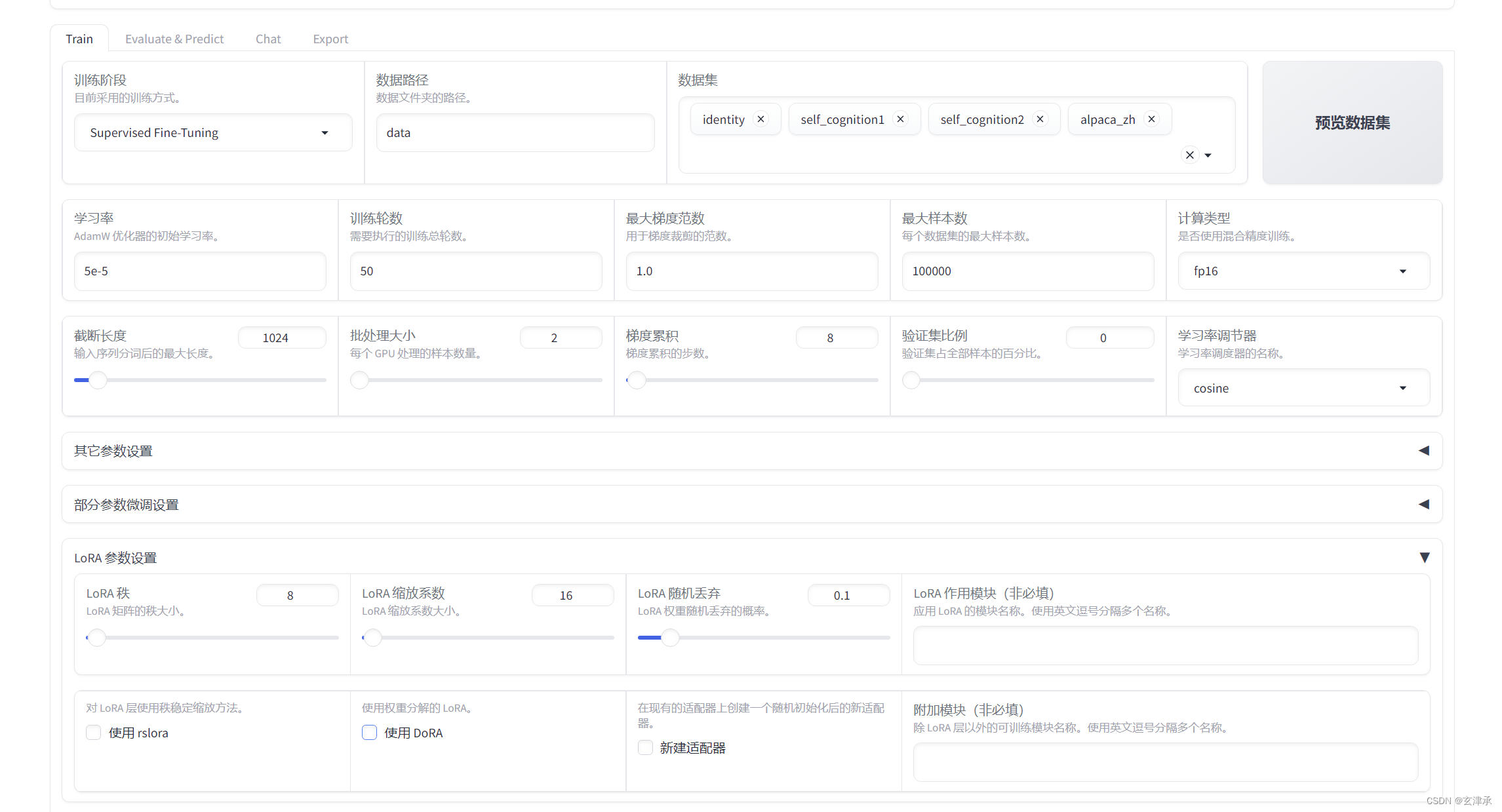
微调 ChatGLM 的超参数设置
1. 学习率(Learning Rate)
学习率是影响模型收敛速度和稳定性的关键超参数。在 LoRA 微调中,适当的学习率能确保模型权重的调整在合适的范围内,不至于过快或过慢。一般经验如下:
- 初始值设定: 可以从
1e-4到1e-5开始,根据模型的复杂度和数据集大小来调整。 - 调整策略: 在训练过程中,通常使用学习率调度器(如线性衰减或余弦退火)来动态调整学习率。
实验总结: 在微调 ChatGLM 的过程中,我从 1e-4 开始设置初始学习率,并在验证集上进行监控,发现 1e-4 有时会导致模型收敛过快而不稳定,调整到 5e-5 后效果显著改善。
2. 批量大小(Batch Size)
批量大小决定了每次迭代中使用的数据量,影响了模型训练的内存占用和计算效率。适当的批量大小能平衡训练速度和模型稳定性。
- 初始设定: 一般从
16到64之间选择。较大的批量大小能加速训练,但需要更多的内存。 - 调整依据: 根据硬件资源和显存容量调整,确保在可用内存范围内最大化批量大小。
实验总结: 我们使用的服务器机器不是很好,batchSize太大了会爆显存,最后使用了2 的批量大小,发现模型在内存占用和训练速度之间取得了较好的平衡。较小的批量大小虽然稳定性好,但训练时间狠狠增加了。
3. 训练轮次(Epochs)
训练轮次决定了整个数据集用于训练模型的次数。足够多的轮次能够让模型充分学习数据特征,但也要避免过拟合。
- 初始设定: 一般从
3到10轮次,根据数据集大小和复杂度来调整。 - 过拟合检测: 通过验证集性能监控过拟合的出现,适时终止训练。
实验总结: 在微调 ChatGLM 时,我使用了 50 个训练轮次。因为要是轮次太少模型记不住我们的数据集。超过50后继续增加轮次,验证集上的性能提升不明显且过拟合风险增加,最终选择 50 个轮次作为最佳配置。
4. 截断长度(Sequence Length)
截断长度决定模型处理的输入序列的最大长度,影响训练效率和内存使用。
- 初始值: 根据任务要求和数据特点,一般设置为
512或1024。 - 调整策略: 确保截断长度足够覆盖重要信息,同时避免过多无关信息。
实验总结: 设置截断长度1024能有效覆盖输入序列的主要信息,同时控制内存使用。根据任务需求可适当调整,但应避免太长的序列导致不必要的计算开销。
5. 梯度累积(Gradient Accumulation)
梯度累积允许将多个小批量的梯度累积在一起,以模拟更大的批量大小,有助于在显存有限的情况下实现稳定训练。
- 初始值: 从
1到8之间选择。 - 调整策略: 根据实际显存和批量大小进行调整,以便在资源受限情况下稳定训练。
实验总结: 梯度累积值设置为 8,在显存有限的情况下能模拟更大的批量大小,有助于稳定训练过程。
6. 学习率调节器(Learning Rate Scheduler)
学习率调节器动态调整学习率,以适应模型不同训练阶段的需求。
- 余弦退火: 学习率从初始值逐渐减小到最低值。
- 线性衰减: 学习率逐渐线性减小。
- ReduceLROnPlateau: 根据验证损失变化自动减少学习率。
实验总结: 使用余弦退火结合初始学习率 5e-5,能有效控制学习率变化,平滑模型收敛过程。
7. LoRA 秩(LoRA Rank)
LoRA 秩决定了低秩矩阵在适配过程中表示的自由度,影响模型的适配能力和存储效率。
- 初始值: 通常设置在
4到16之间。 - 调整策略: 根据模型的复杂度和数据集大小调整,确保足够的适配能力。
实验总结: LoRA 秩设置为 8,能够提供足够的自由度进行模型适配,同时保持计算和存储效率。
8. LoRA 缩放系数(LoRA Scaling Factor)
LoRA 缩放系数控制了低秩矩阵在模型中的贡献度,影响适配效果和模型稳定性。
- 初始值: 从
8到32之间选择。 - 调整策略: 观察验证集上的表现,调整缩放系数以平衡稳定性和适配效果。
实验总结: LoRA 缩放系数设置为 16,在验证集上表现稳定,适配效果良好。
微调过程中的挑战与解决方案
- 学习率过高导致不稳定: 通过学习率调度器动态调整学习率,解决了初始学习率过高导致模型不稳定的问题。
- 内存不足问题: 通过调节批量大小和梯度累积技巧,解决了显存占用过高的问题。
- 过拟合现象: 通过早停法和权重衰减,避免了模型在验证集上的性能下降。
微调大型语言模型需要谨慎选择和调整超参数。这不仅影响模型的收敛速度和性能,还决定了最终模型的泛化能力。微调大模型就是需要系统化的实验和调整、不断积累经验才能得到稳定和高效的微调策略。
这一次基于参数的微调是为了进一步让大模型学习计算机行业专业知识,更好的应对用户的比较专业的面试问题。
训练前:

训练后:

可以观察到经过调参加专业数据集训练之后,大模型对于涉及到专业词汇的叙述的评价更正常了。















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









