






一、个人任务
本周我的任务主要有以下两个
- 对比微调VisualGLM输出结果
- 初步进行前端的设计
二、任务1——深入了解VisualGLM模型
2.1 VisualGLM模型:融合图像识别能力的双语语言模型
在当今人工智能迅猛发展的时代背景下,自然语言处理(NLP)和计算机视觉(CV)两大领域不断交叉融合,催生出一系列创新的技术和应用。VisualGLM正是这一融合趋势下的杰出代表,它以ChatGLM-6B为基础,通过引入视觉识别能力,构建了一个强大的中英双语多模态语言模型。
1、VisualGLM的概述
VisualGLM不仅继承了ChatGLM-6B的62亿参数中英双语语言模型的优势,还通过结合计算机视觉技术,赋予了模型图像识别的能力。这使得VisualGLM能够处理包含图像和文本的多模态数据,为人工智能在跨媒体交互、智能问答、图像描述生成等领域的应用提供了强大的支持。
2、VisualGLM的模型架构
VisualGLM的模型架构由VIT(Visual Transformer)、QFormer和ChatGLM-6B三部分组成。其中,VIT负责处理图像数据,提取图像特征;QFormer则作为视觉和语言模型之间的桥梁,将图像特征与文本特征进行融合;ChatGLM-6B则负责处理文本数据,进行语言理解和生成。
QFormer的设计是VisualGLM的核心创新点之一。它通过一系列精心设计的注意力机制和变换操作,实现了图像特征和文本特征的有效融合。在预训练过程中,QFormer和VIT的参数会被同时训练,以确保它们能够协同工作,共同提取出图像和文本中的有用信息。
3、VisualGLM的训练过程
VisualGLM的训练过程分为预训练阶段和微调阶段。在预训练阶段,模型会使用中英双语图文大规模数据进行训练,以学习如何同时处理图像和文本数据。这一阶段的训练目标是让模型能够准确地识别图像中的物体、场景等信息,并理解文本中的语义含义。
在微调阶段,模型会使用高质量图文指令数据对进行训练。这些数据对通常包含一张图像和一个与之相关的文本指令,如“描述这张图片中的场景”或“找出图片中的红色物体”。通过微调训练,模型能够更好地理解图文之间的关联关系,并生成与图像内容相关的准确回答或描述。
4、VisualGLM的应用前景
VisualGLM的出现为人工智能在跨媒体交互、智能问答、图像描述生成等领域的应用带来了广阔的前景。例如,在智能客服领域,VisualGLM可以处理用户发送的包含图像的咨询信息,并生成准确的回答或建议;在图像搜索领域,VisualGLM可以根据用户输入的文本描述,从海量图像库中检索出符合要求的图片;在辅助创作领域,VisualGLM可以根据用户输入的文本内容,自动生成与之相关的图像素材或背景故事等。
5、VisualGLM局限性
VisualGLM-6B正处于V1版本视觉和语言模型的参数、计算量都较小,局限性包含以下几点:
(1)图像描述事实性/模型幻觉问题。在生成图像长描述的时候,距离图像较远时,语言模型的将占主导,有一定可能根据上下文生成并不存在于图像的内容。
(2)属性错配问题。在多物体的场景中,部分物体的某些属性,经常被错误安插到其他物体上。
(3)分辨率问题。本项目使用了224*224的分辨率,也是视觉模型中最为常用的尺寸;然而为了进行更细粒度的理解,更大的分辨率和计算量是必要的。
(4)由于数据等方面原因,模型暂不具有中文ocr的能力(英文ocr能力有一些)。
总之,VisualGLM作为一个融合图像识别能力的双语语言模型,不仅展示了人工智能技术的强大潜力,也为未来的跨媒体交互和智能应用提供了有力的支持。
三、任务2——训练记录
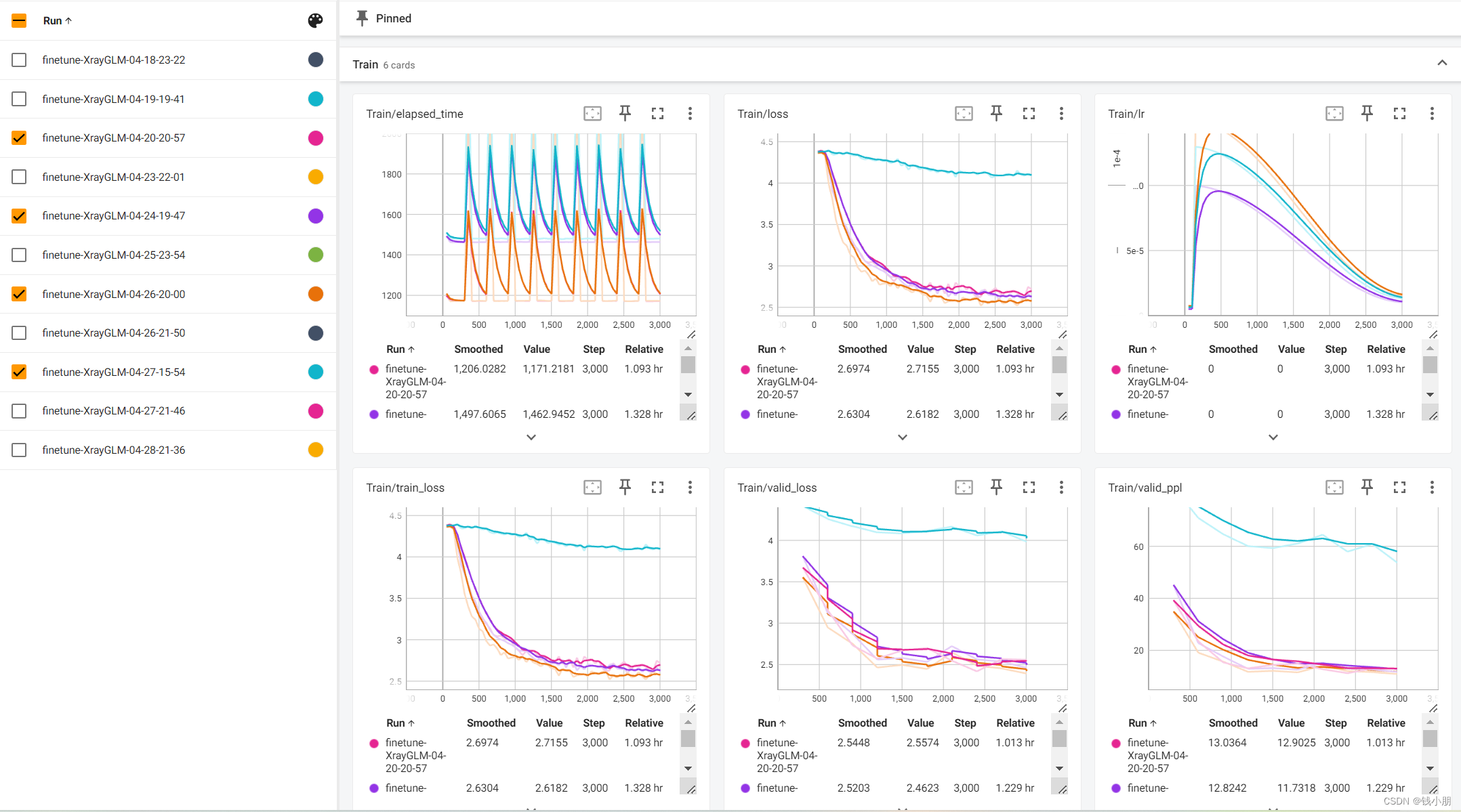
这部分工作由我和团队成员刘欣悦共同完成,具体的微调结果如下:
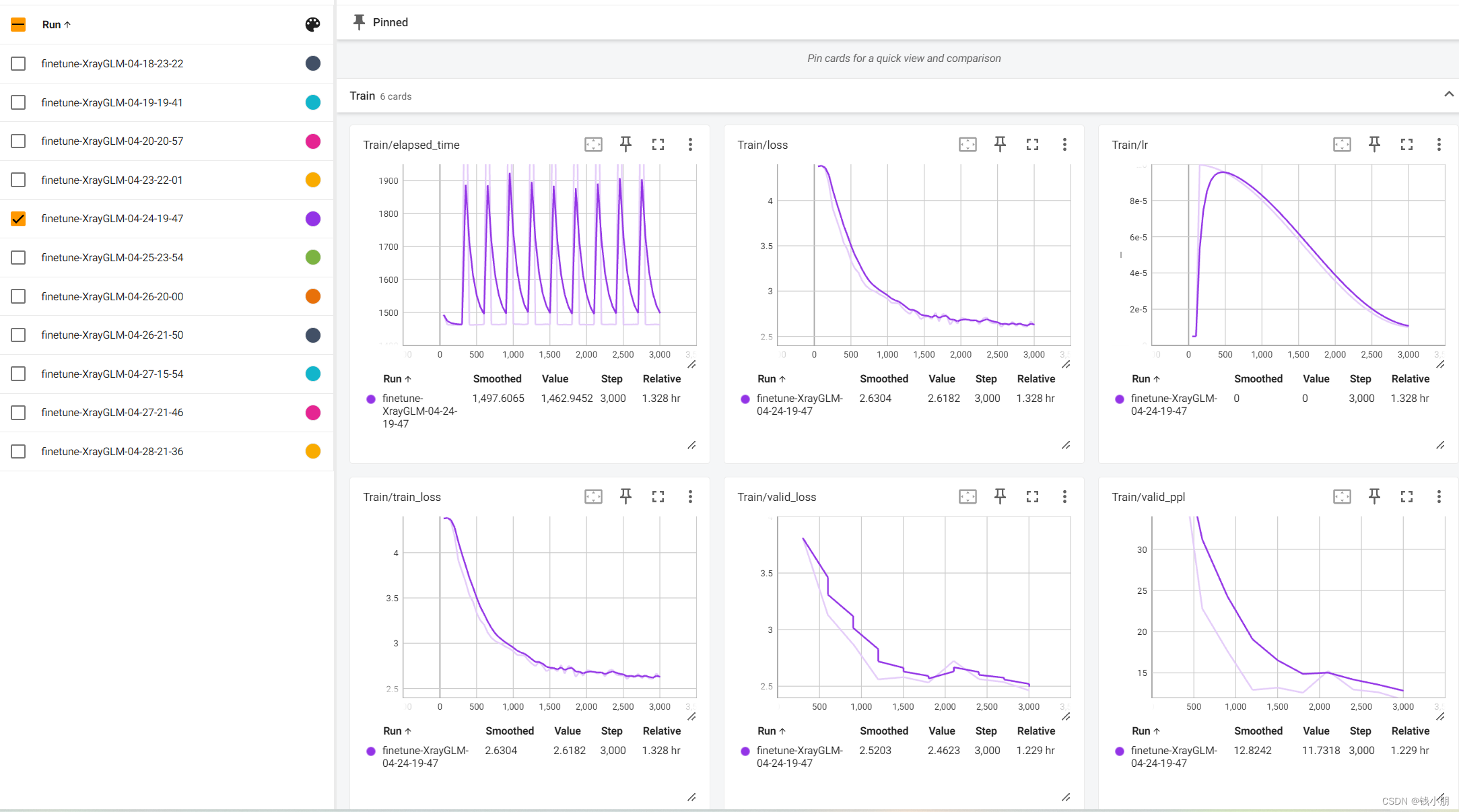
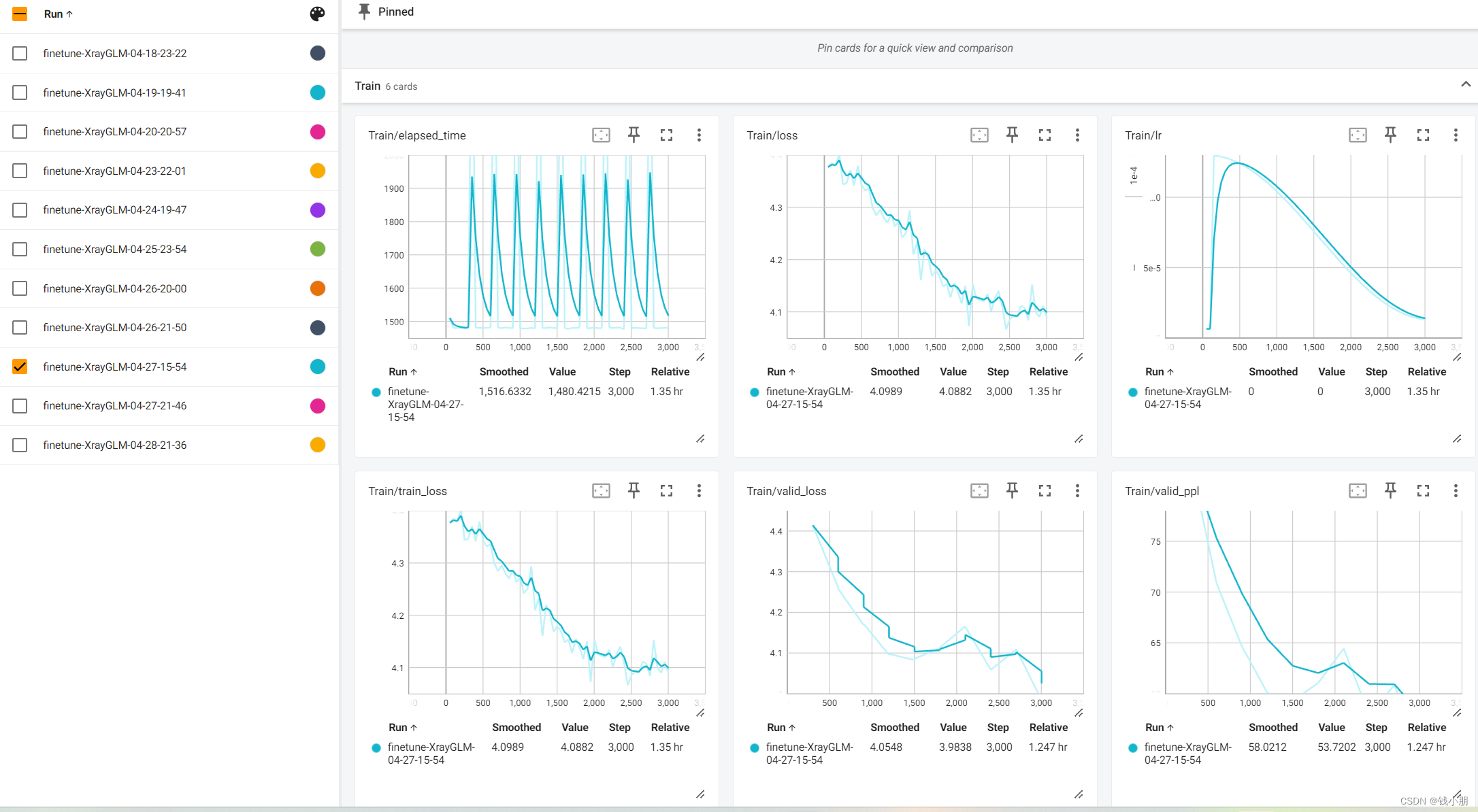
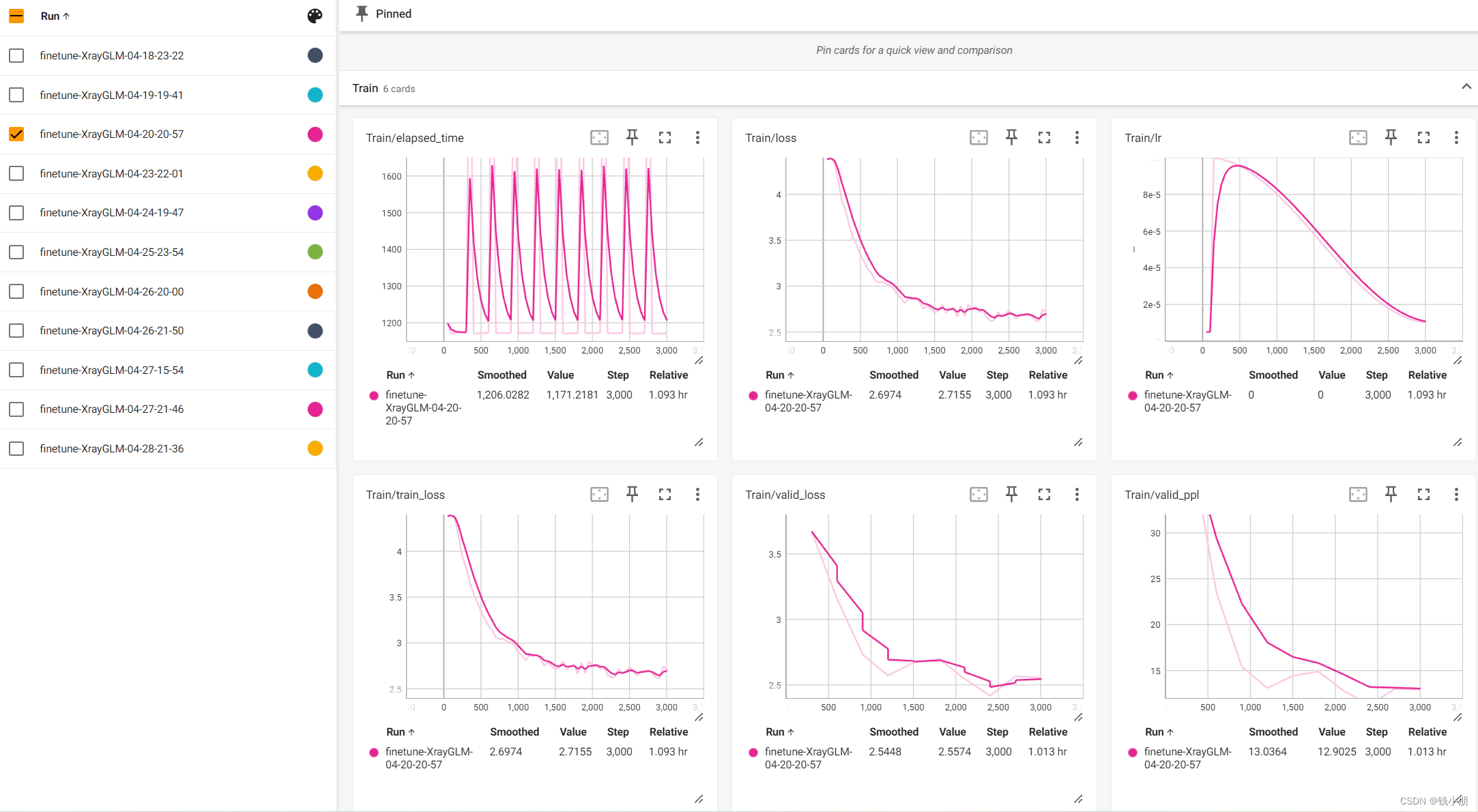

训练结果对比
四、总结
本周的首要任务是深入了解VisualGLM模型及其微调过程。VisualGLM是一个基于ChatGLM-6B的中英双语多模态语言模型,通过引入计算机视觉技术,使模型具备了图像识别的能力。在学习过程中,我主要关注了以下几个方面:
-
模型架构:VisualGLM的模型架构由VIT(Visual Transformer)、QFormer和ChatGLM-6B三部分组成。VIT负责处理图像数据,QFormer作为桥梁连接视觉和语言模型,ChatGLM-6B则负责处理文本数据。
-
预训练过程:在预训练阶段,VisualGLM使用中英双语图文大规模数据进行训练,学习如何同时处理图像和文本数据。这一阶段的训练目标是让模型能够准确地识别图像中的物体、场景等信息,并理解文本中的语义含义。
-
微调过程:微调阶段是关键步骤,它使用高质量图文指令数据对进行训练,以优化模型在特定任务上的表现。通过微调,模型能够更好地理解图文之间的关联关系,并生成与图像内容相关的准确回答或描述。
-
微调技术:在微调过程中,我学习了Lora(Low-Rank Adaptation)等参数微调技术。这些技术允许我们在不改变原始模型大部分参数的情况下,通过微调少量参数来适应新任务,从而保持模型的泛化能力。
在掌握了VisualGLM模型及微调相关知识后,我进行了实际的微调实验。我选择了一个与图像描述生成相关的任务作为实验对象,使用了包含图像和对应文本描述的数据集。
-
数据准备:首先,我对数据集进行了预处理,包括图像缩放、归一化等操作,以确保输入数据符合模型要求。同时,我还对数据集进行了划分,以便进行训练和验证。
-
模型加载:我加载了预训练的VisualGLM模型,并设置了适当的超参数,如学习率、批次大小等。
-
微调过程:在微调阶段,我使用训练数据集对模型进行了多轮迭代训练,并监控了验证集上的性能变化。通过不断调整超参数和优化器设置,我逐步提高了模型在验证集上的性能。
-
结果记录:我记录了每轮训练后的损失函数值和验证集上的性能指标(如准确率、BLEU分数等)。通过对比不同轮次的结果,我发现模型在微调过程中逐渐适应了新任务,并在验证集上取得了稳定的性能提升。
-
结果分析:最后,我对微调结果进行了深入分析。通过对比微调前后的模型性能,我发现微调后的模型在图像描述生成任务上取得了更好的效果。同时,我也分析了不同超参数设置对模型性能的影响,以便在未来的实验中进一步优化模型性能。
通过本周的学习和实践,我深入了解了VisualGLM模型及微调相关知识,并成功地将这些知识应用到了实际任务中。通过微调VisualGLM模型,我提高了模型在图像描述生成任务上的性能,并获得了有价值的实验结果。未来,我将继续探索多模态语言模型的应用场景和优化方法,以推动人工智能技术在跨媒体交互和智能问答等领域的发展。
















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









