









数据挖掘与机器学习
实验:分类算法
一、实验名称
实验:分类算法
二、实验目的
1.了解分类算法理论基础
2.平台实现算法
3.编程实现分类算法
三、实验原理
分类(Categorization or Classification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类。
四、实验步骤
1、adult.data.txt数据集,该数据集由多组个人信息构成,其中信息包含年龄、工作、婚姻等属性,以及类别收入,根据这些已有数据建立模型,推测出未知收入群体的收入情况。

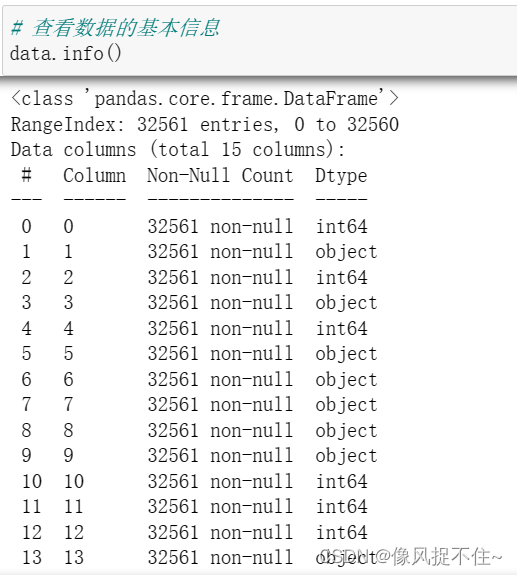
2、加载数据并查看数据,需注意数据的分隔符为', '即',空格',并且没有表头。
# 引包
import numpy as np
import pandas as pd
# 读取数据
# 分隔符为', '即',空格' , header=None表示在读取数据时不将第一行作为列名
data = pd.read_csv('D:/数据挖掘/实验/adult.data.txt', sep=', ', header=None)
data
# 查看数据的基本信息
data.info()

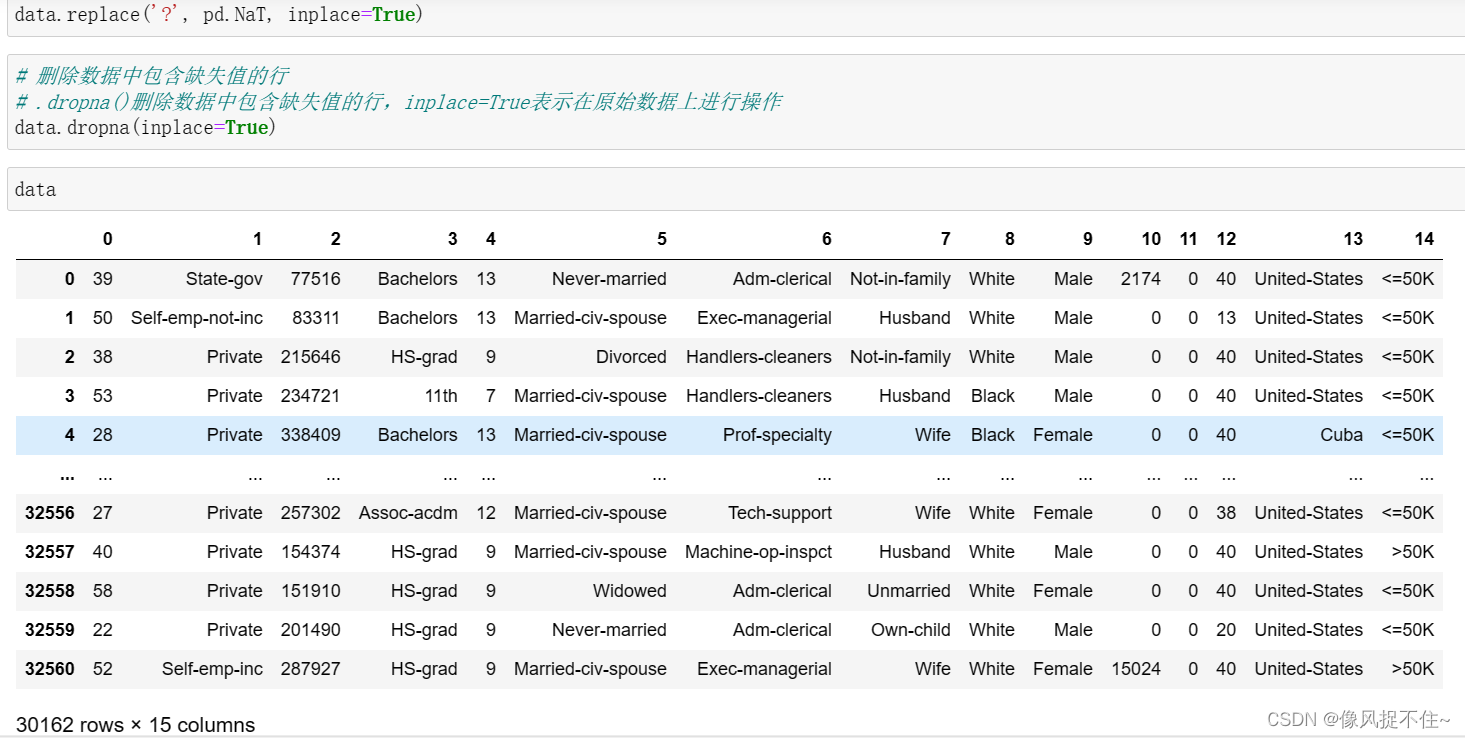
3、由于数据中含有异常值,需将异常值替换成缺失值pd.NaT,再将数据中包含缺失值的行删除掉。
# 将异常值替换成缺失值pd.NaT
# .replace()函数将数据中的'?'替换成pd.NaT
# inplace=True表示在原始数据上进行替换操作,而不是创建一个新的
data.replace('?', pd.NaT, inplace=True)
# 删除数据中包含缺失值的行
# .dropna()删除数据中包含缺失值的行,inplace=True表示在原始数据上进行操作
data.dropna(inplace=True)
data
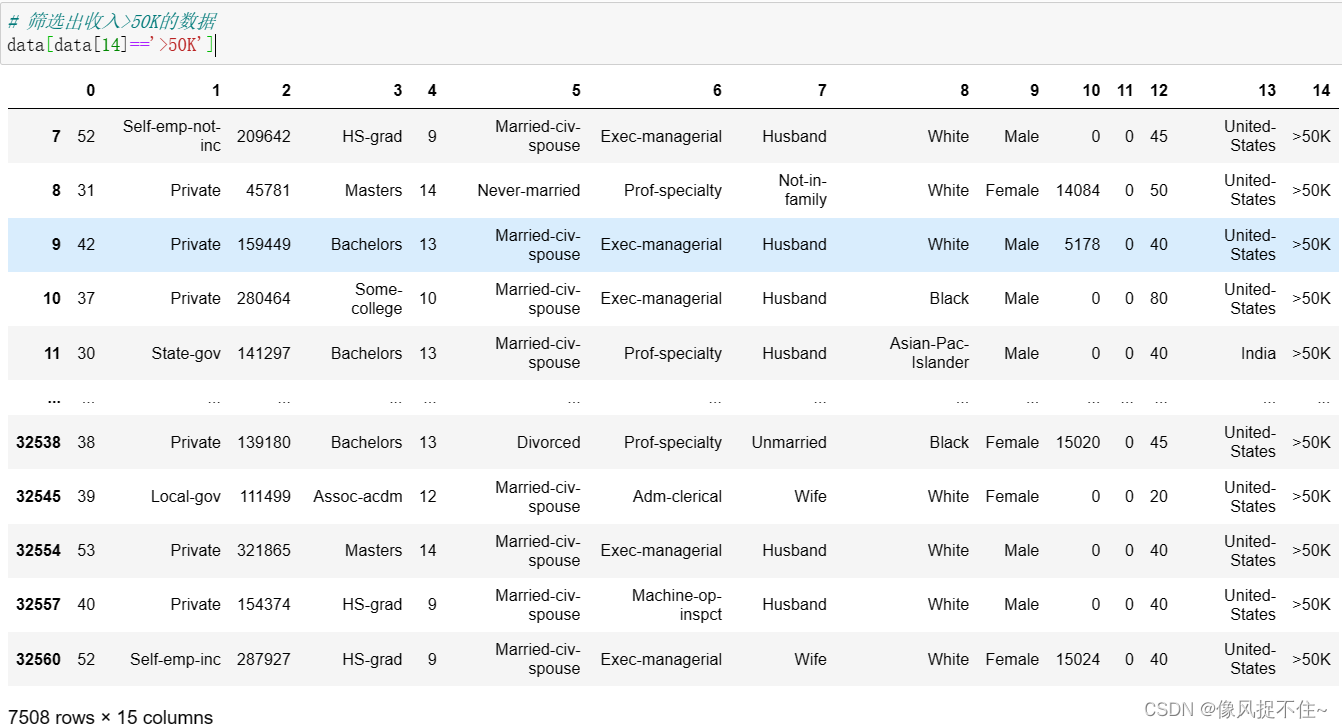
4、筛选收入<=50K和>50K的数据,发现收入<=50K的数据有22654条,而收入>50K的数据只有7508条,由于不同的类别的数据体量相差很大会造成分类器向大数据体量一方倾斜,因此我们需依据不同的类别收入加载相同数量的数据。
# 筛选出收入<=50K的数据
data[data[14]=='<=50K']
# 筛选出收入>50K的数据
data[data[14]=='>50K']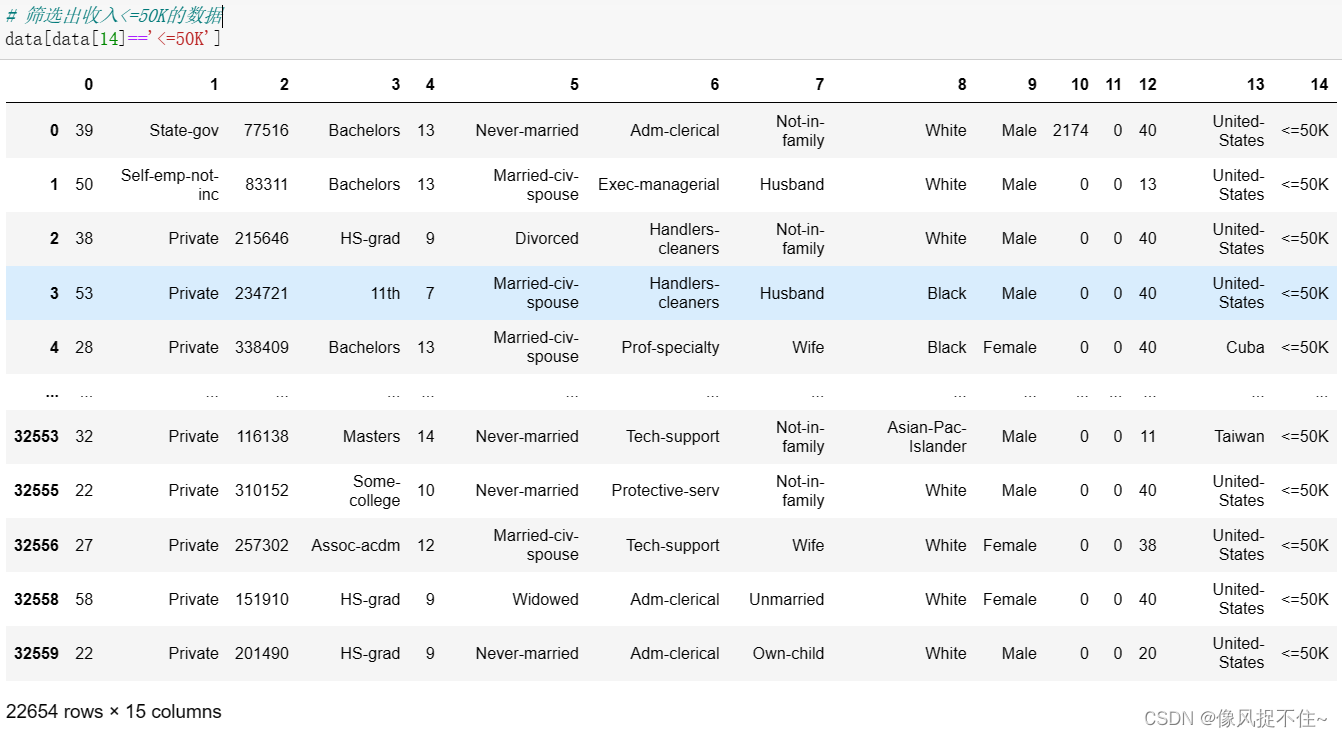
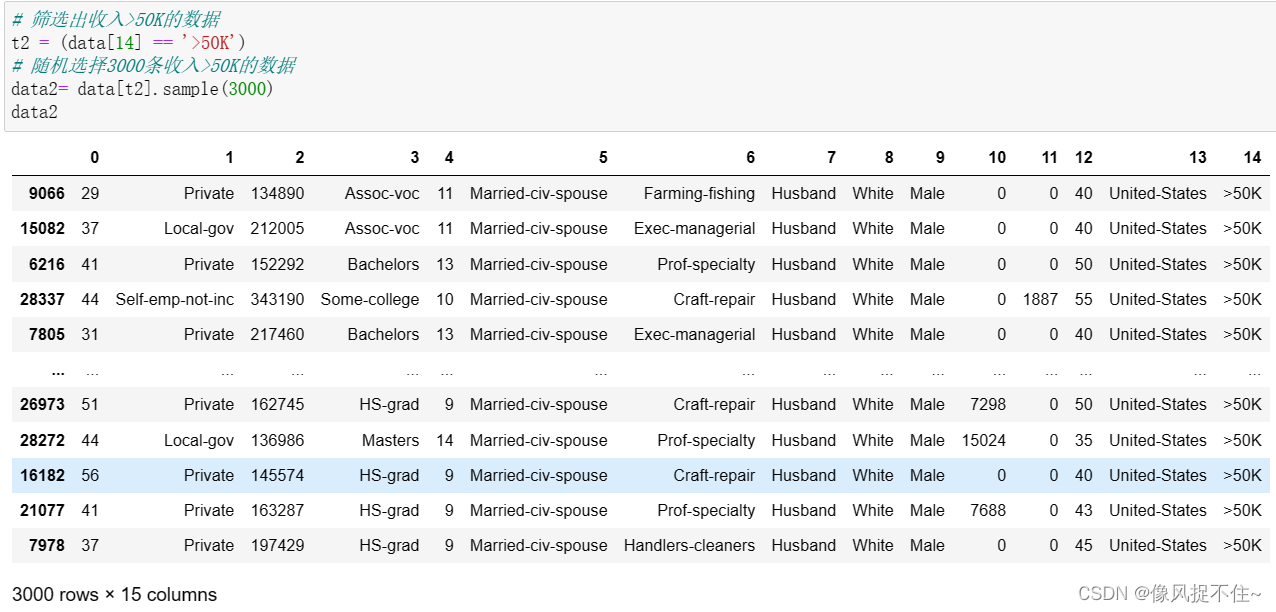
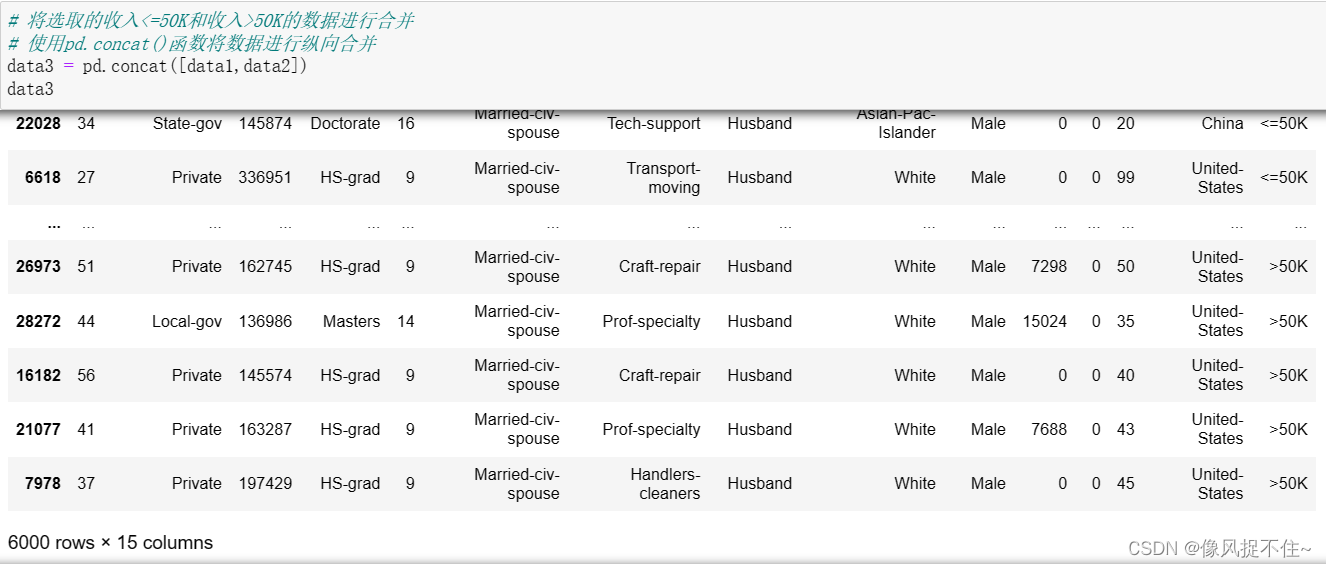
5、随机选取收入<=50K和收入>50K的数据各3000条,并将选取出的收入<=50K和收入>50K的数据进行合并。
# 选取收入50K上下的同等数据量进行数据分析
# 筛选出收入<=50K的数据,结果返回一个由布尔值组成的Series对象,其中每个元素的值为True或False
t1 = (data[14] == '<=50K')
# data1
# 随机选择3000条收入<=50K的数据
data1 = data[t1].sample(3000)
data1
# 筛选出收入>50K的数据
t2 = (data[14] == '>50K')
# 随机选择3000条收入>50K的数据
data2= data[t2].sample(3000)
data2
# 将选取的收入<=50K和收入>50K的数据进行合并
# 使用pd.concat()函数将数据进行纵向合并
data3 = pd.concat([data1,data2])
data3
6、转换数据的属性编码,由于原数据中的属性是包含英文字符的,无法进行数学运算,需将其转换为数值型数据。由于对新的数据集进行编码转换时,需要使用相同的编码方式,即使用相同的 LabelEncoder() 对象,所以需要将所有的 LabelEncoder() 对象保存下来,以便在对新数据集进行编码时使用。
# 转换数据的属性编码
# 原数据中含有英文字符,使用preprocessing.LabelEncoder()函数将英文转换成数值型
from sklearn.preprocessing import LabelEncoder
# 对新的数据集进行编码转换时,需要使用相同的编码方式,即使用相同的 LabelEncoder() 对象。
# 因此需要将所有的 LabelEncoder() 对象保存下来,以便在对新数据集进行编码时使用。
# 创建一个空列表 le1 用于存储所有的 LabelEncoder() 对象
le1 = []
# 创建一个副本保留原始数据
data4 = data3.copy()
# 使用循环对每一列的数据进行属性编码
for column in data3.columns:
# 判断每列的数据类型是否为object(即非数值型数据)
if data3[column].dtype == 'object':
# 创建一个LabelEncoder对象
le = LabelEncoder()
# 如果是非数值型数据,就使用LabelEncoder对象le对该列进行编码
data4[column] = le.fit_transform(data3[column])
# 保存LabelEncoder对象,将le对象添加到le1列表中
le1.append(le)
# print(le1)
data4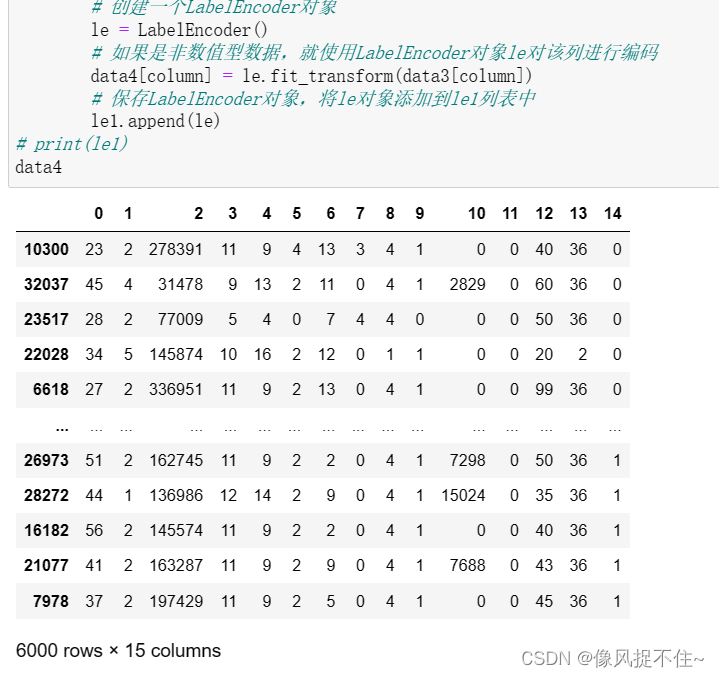
7、获取数据的属性和标签,先对数据集进行划分,模型选择朴素贝叶斯算法,再依次进行模型的训练、预测、测评,测评使用交叉验证,交叉验证是将数据分成n等份,每次取其中1份作为测试集,其余作为训练集进行评测,重复n次,取n次的平均值作为结果。将结果转换成百分比的形式,并保留两位小数。
# 获取数据属性
X = data4.iloc[:, :-1].values
# 获取数据标签
y = data4.iloc[:, -1].values
X
y
from sklearn.model_selection import train_test_split
# 划分数据集
# test_size:测试集大小,random_state:随机种子
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=5)
# 模型的选择,朴素贝叶斯算法
from sklearn.naive_bayes import GaussianNB
classifier_gaussiannb = GaussianNB()
# 模型的训练
classifier_gaussiannb.fit(X_train, y_train)
# 模型的预测
y_test_pred = classifier_gaussiannb.predict(X_test)
# 模型的测评
# 交叉验证:将数据分成n等份,每次取其中1份作为测试集,其余作为训练集进行评测,重复n次,取n次的平均值作为结果
from sklearn.model_selection import cross_val_score
# cv每种情况训练的次数,scoring='f1_weighted' 表示使用加权的F1得分作为评价指标
scores = cross_val_score(classifier_gaussiannb,X,y,scoring='f1_weighted',cv=5)
# 得分取平均值,转换成百分比形式,保留两位小数
print("scores:" + str(round(100*scores.mean(),2)) + "%")
8、选取一个新的个体样本,采用相同的编码规则进行处理,并进行预测其收入类别,注意得到的结果是数值型的标签,需将数值型标签转换成非数值型的标签。
# 选取个例进行预测
# 创建一个新样本,使用训练好的模型对其进行预测,预测该样本的收入类别
input_data = ['39', 'State-gov', '77516', 'Bachelors', '13', 'Never-married', 'Adm-clerical', 'Not-in-family', 'White',
'Male', '2174', '0', '40', 'United-States']
# 创建一个与 input_data 长度相同的列表,并将初始值设置为 -1,将编码后的结果存储到对应的位置上
# 创建一个列表,用于存放新样本数据编码后的结果
input_data_encoder = [-1] * len(input_data)
# 对新样本的数据进行编码
# count表示新样本数据中非数字的列的顺序
# 在上面有一个训练好的编码器列表,通过count使用非数值的列对应的编码器对新样本数据进行编码
count = 0
# 使用 enumerate() 函数遍历输入数据,index 表示当前元素的索引,item 表示当前元素的值
for index, item in enumerate(input_data):
# 判断当前元素是否为数值型数据,如果是,则将其转换为整数并存储到 input_data_encoder 的相应位置上
if item.isdigit():
input_data_encoder[index] = int(item)
# 如果当前元素不是数值型数据,则需要进行编码转换
else:
# tranform()对数据进行编码,参数是一个 numpy 的 ndarray,所以需要使用 np.array() 构建一个ndarray
temp = le1[count].transform(np.array([item]))
# 将编码后的结果转换为整数,并存储到 input_data_encoder 的相应位置上
input_data_encoder[index] = int(temp)
count += 1
# 查看一下编码后的样本数据
print(input_data_encoder)
# 使用 np.array()函数将数据转换为 numpy 数组对象
out = np.array(input_data_encoder)
out
# 进行预测
# .reshape(1,-1):对数据进行转换,将其转换为一个只有一行的二维数组
result=classifier_gaussiannb.predict(out.reshape(1,-1))
result
# 将编码后的数值型标签转换成非数值型的标签
print(le.inverse_transform(result)[0])

五、完整代码
# 引包
import numpy as np
import pandas as pd
# 读取数据
# 分隔符为', '即',空格' , header=None表示在读取数据时不将第一行作为列名
data = pd.read_csv('D:/数据挖掘/实验/adult.data.txt', sep=', ', header=None)
data
# 查看数据的基本信息
data.info()
# 将异常值替换成缺失值pd.NaT
# .replace()函数将数据中的'?'替换成pd.NaT
# inplace=True表示在原始数据上进行替换操作,而不是创建一个新的
data.replace('?', pd.NaT, inplace=True)
# 删除数据中包含缺失值的行
# .dropna()删除数据中包含缺失值的行,inplace=True表示在原始数据上进行操作
data.dropna(inplace=True)
data
# 筛选出收入<=50K的数据
data[data[14]=='<=50K']
# 筛选出收入>50K的数据
data[data[14]=='>50K']
# 选取收入50K上下的同等数据量进行数据分析
# 筛选出收入<=50K的数据,结果返回一个由布尔值组成的Series对象,其中每个元素的值为True或False
t1 = (data[14] == '<=50K')
# data1
# 随机选择3000条收入<=50K的数据
data1 = data[t1].sample(3000)
data1
# 筛选出收入>50K的数据
t2 = (data[14] == '>50K')
# 随机选择3000条收入>50K的数据
data2= data[t2].sample(3000)
data2
# 将选取的收入<=50K和收入>50K的数据进行合并
# 使用pd.concat()函数将数据进行纵向合并
data3 = pd.concat([data1,data2])
data3
# 转换数据的属性编码
# 原数据中含有英文字符,使用preprocessing.LabelEncoder()函数将英文转换成数值型
from sklearn.preprocessing import LabelEncoder
# 对新的数据集进行编码转换时,需要使用相同的编码方式,即使用相同的 LabelEncoder() 对象。
# 因此需要将所有的 LabelEncoder() 对象保存下来,以便在对新数据集进行编码时使用。
# 创建一个空列表 le1 用于存储所有的 LabelEncoder() 对象
le1 = []
# 创建一个副本保留原始数据
data4 = data3.copy()
# 使用循环对每一列的数据进行属性编码
for column in data3.columns:
# 判断每列的数据类型是否为object(即非数值型数据)
if data3[column].dtype == 'object':
# 创建一个LabelEncoder对象
le = LabelEncoder()
# 如果是非数值型数据,就使用LabelEncoder对象le对该列进行编码
data4[column] = le.fit_transform(data3[column])
# 保存LabelEncoder对象,将le对象添加到le1列表中
le1.append(le)
# print(le1)
data4
# 获取数据属性
X = data4.iloc[:, :-1].values
# 获取数据标签
y = data4.iloc[:, -1].values
X
y
from sklearn.model_selection import train_test_split
# 划分数据集
# test_size:测试集大小,random_state:随机种子
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=5)
# 模型的选择,朴素贝叶斯算法
from sklearn.naive_bayes import GaussianNB
classifier_gaussiannb = GaussianNB()
# 模型的训练
classifier_gaussiannb.fit(X_train, y_train)
# 模型的预测
y_test_pred = classifier_gaussiannb.predict(X_test)
# 模型的测评
# 交叉验证:将数据分成n等份,每次取其中1份作为测试集,其余作为训练集进行评测,重复n次,取n次的平均值作为结果
from sklearn.model_selection import cross_val_score
# cv每种情况训练的次数,scoring='f1_weighted' 表示使用加权的F1得分作为评价指标
scores = cross_val_score(classifier_gaussiannb,X,y,scoring='f1_weighted',cv=5)
# 得分取平均值,转换成百分比形式,保留两位小数
print("scores:" + str(round(100*scores.mean(),2)) + "%")
# 选取个例进行预测
# 创建一个新样本,使用训练好的模型对其进行预测,预测该样本的收入类别
input_data = ['39', 'State-gov', '77516', 'Bachelors', '13', 'Never-married', 'Adm-clerical', 'Not-in-family', 'White',
'Male', '2174', '0', '40', 'United-States']
# 创建一个与 input_data 长度相同的列表,并将初始值设置为 -1,将编码后的结果存储到对应的位置上
# 创建一个列表,用于存放新样本数据编码后的结果
input_data_encoder = [-1] * len(input_data)
# 对新样本的数据进行编码
# count表示新样本数据中非数字的列的顺序
# 在上面有一个训练好的编码器列表,通过count使用非数值的列对应的编码器对新样本数据进行编码
count = 0
# 使用 enumerate() 函数遍历输入数据,index 表示当前元素的索引,item 表示当前元素的值
for index, item in enumerate(input_data):
# 判断当前元素是否为数值型数据,如果是,则将其转换为整数并存储到 input_data_encoder 的相应位置上
if item.isdigit():
input_data_encoder[index] = int(item)
# 如果当前元素不是数值型数据,则需要进行编码转换
else:
# tranform()对数据进行编码,参数是一个 numpy 的 ndarray,所以需要使用 np.array() 构建一个ndarray
temp = le1[count].transform(np.array([item]))
# 将编码后的结果转换为整数,并存储到 input_data_encoder 的相应位置上
input_data_encoder[index] = int(temp)
count += 1
# 查看一下编码后的样本数据
print(input_data_encoder)
# 使用 np.array()函数将数据转换为 numpy 数组对象
out = np.array(input_data_encoder)
out
# 进行预测
# .reshape(1,-1):对数据进行转换,将其转换为一个只有一行的二维数组
result=classifier_gaussiannb.predict(out.reshape(1,-1))
result
# 将编码后的数值型标签转换成非数值型的标签
print(le.inverse_transform(result)[0])六、实验总结
本实验对分类算法的原理做了基本的了解,并通过Python代码的形式进行真实的算法实现,构建了一个分类器实现对未知收入群体的收入情况的预测。

















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









