




在大模型技术席卷各行业的今天,通用大模型在专业领域往往面临知识局限(缺乏实时 / 私域数据)、幻觉风险(虚构错误信息)、数据安全(私域数据上传隐患)三大核心痛点。而检索增强生成(RAG)技术通过 "检索 + 生成" 的组合模式,成为解决这些问题的最优方案之一。本文结合 LlamaIndex 框架与 Chainlit 前端工具,带大家从零实现一个私域知识问答系统,完整覆盖前端搭建、RAG 核心流程与原理解析。
一、前端界面选型与实现:对话交互的入口搭建
前端是用户与 RAG 系统交互的直接载体,选择合适的前端框架能极大提升开发效率。目前主流的 Python 前端工具各有侧重,我们先通过对比明确选型逻辑。
1. 三大前端框架对比
不同场景对前端的需求差异显著,下表清晰梳理了三者的核心区别:
| 对比维度 | Chainlit | Streamlit | Gradio |
|---|---|---|---|
| 主要定位 | 面向 LLM 的对话式前端框架 | 通用型数据应用 / 仪表盘开发框架 | 机器学习模型演示与交互框架 |
| 核心特点 | 原生支持聊天流、工具调用可视化,与 LlamaIndex 深度集成 | 丰富数据可视化组件,脚本式开发 | 多模态输入输出,一键分享 Demo |
| 使用门槛 | 中等(需了解 LLM 应用逻辑) | 低(纯 Python 脚本) | 低(几行代码跑通 Demo) |
| 典型场景 | AI 助手、LLM 工具调用演示 | 数据可视化、商业智能 BI | Hugging Face 模型快速分享 |
对于 RAG 智能问答系统而言,Chainlit 的对话交互优化与 LLM 生态集成能力是核心优势,因此本文选择 Chainlit 作为前端框架。
2. Chainlit 实战:安装与问题解决
2.1 基础安装步骤
通过 pip 即可完成 Chainlit 的安装,核心命令如下:
# 安装Chainlit
pip install chainlit
# 验证安装是否成功
chainlit hello
安装好了之后浏览器就会自动跳转到这个页面,而且项目结构中会出现一个chainlit的文件夹。
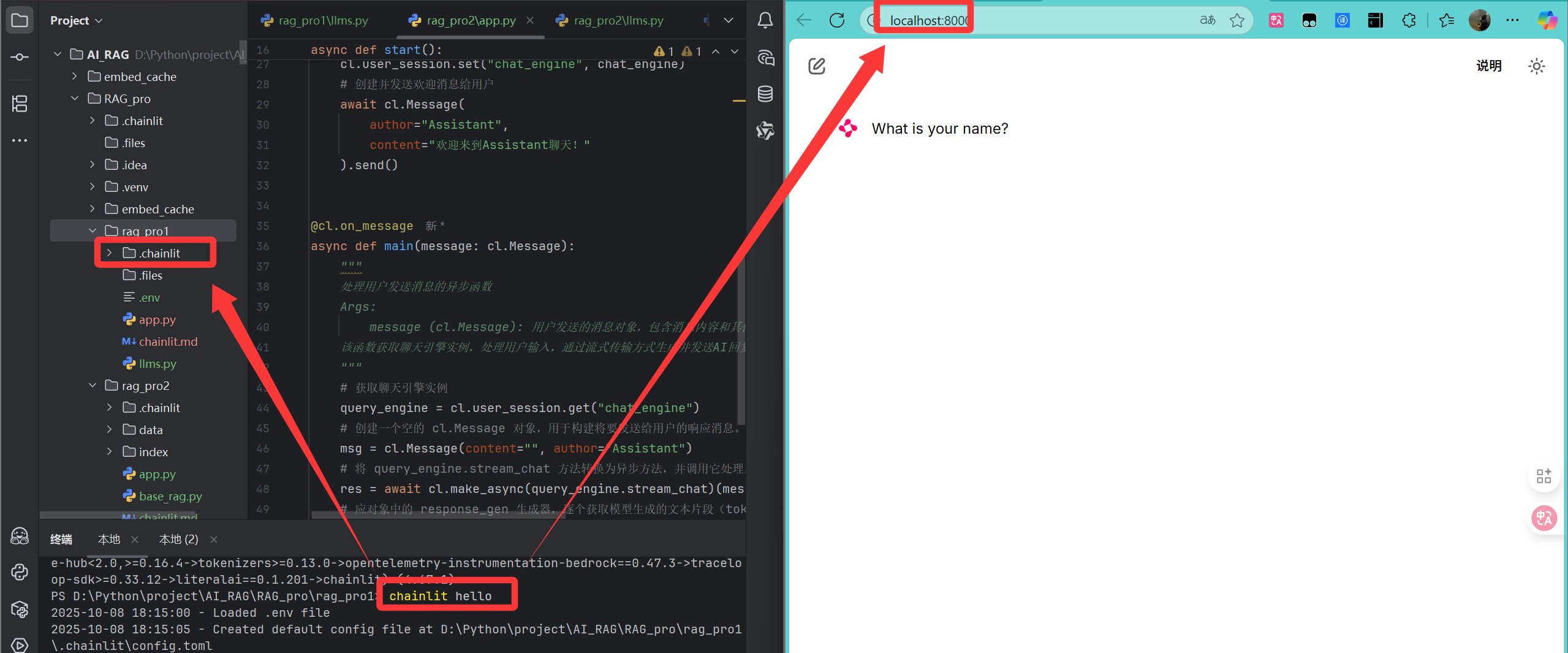
2.2 常见报错与解决方案
执行chainlit hello时,常因pydantic 版本不兼容出现如下错误:
pydantic.errors.PydanticUserError:
CodeSettingsis not fully defined; you should defineAction, then callpydantic.dataclasses.rebuild_dataclass(CodeSettings)
这是因为 Chainlit 对 pydantic 版本有明确要求,解决方案为指定安装 2.9.2 版本:
# 卸载冲突版本
pip uninstall pydantic
# 安装兼容版本
pip install pydantic==2.9.2
# 重新验证,成功后会提示访问localhost:8000
chainlit hello
3. 界面核心代码实现
Chainlit 通过装饰器机制简化对话流程开发,核心包含初始化逻辑与消息处理逻辑两部分。以下是结合 LlamaIndex 的完整实现代码:
# 导入chainlit库,用于构建和部署AI应用
import chainlit as cl
# 导⼊核⼼设置模块,⽤于配置全局的LLM(⼤语⾔模型)和其他设置
from llama_index.core import Settings
# 导⼊简单的聊天引擎模块,⽤于创建和管理聊天会话
from llama_index.core.chat_engine import SimpleChatEngine
# 从⾃定义模块中导⼊DeepSeek LLM实例,⽤于处理语⾔模型相关的任务
from llms import moonshot_llm
@cl.on_chat_start
async def start():
"""
当聊天会话开始时执行的异步函数
该函数负责初始化聊天环境,包括配置语言模型、创建聊天引擎和发送欢迎消息
"""
# 配置大模型:聊天模型是实际执行文本生成和理解任务的核心AI模型。
Settings.llm = moonshot_llm()
# 创建聊天引擎:
# 聊天引擎负责:
# 1.管理对话历史记录
# 2.组织和格式化输入消息
# 3.调用底层的聊天模型进行响应生成
# 4.处理流式响应等高级功能
chat_engine = SimpleChatEngine.from_defaults()
# 启动聊天
cl.user_session.set("chat_engine", chat_engine)
# 创建并发送欢迎消息给用户
await cl.Message(
author="Assistant",
content="欢迎来到Assistant聊天!"
).send()
@cl.on_message
async def main(message: cl.Message):
"""
处理用户发送消息的异步函数
Args:
message (cl.Message): 用户发送的消息对象,包含消息内容和其他元数据
该函数获取聊天引擎实例,处理用户输入,通过流式传输方式生成并发送AI回复
"""
# 获取聊天引擎实例
query_engine = cl.user_session.get("chat_engine")
# 初始化聊天响应消息
msg = cl.Message(content="", author="Assistant")
# 把用户输入的内容转化为异步响应,存储于到res中,实现流式输出
res = await cl.make_async(query_engine.stream_chat)(message.content)
# 逐个处理模型生成的文本片段(token),并逐个发送给用户
for token in res.response_gen:
await msg.stream_token(token)
await msg.send()
核心逻辑解析
- 索引管理:首次运行时从
./data目录读取文档构建向量索引,后续直接加载持久化的索引,大幅节省时间; - 会话初始化:配置 LLM 与嵌入模型参数,创建支持流式输出的查询引擎,并存储到用户会话中;
- 流式回复:通过
stream_token实现逐词输出,提升用户交互体验。
以下是模型配置相关代码,为后续模型切换奠定基础,直接复制这两个代码,然后去申请秘钥并配置,即可实现基于chainlit和lammaIndex的最简单的聊天助手:
# 导入 Dict 类型,用于类型提示
from typing import Dict
# 导入操作系统接口模块,用于访问环境变量等操作系统功能
import os
# 从 llama_index 核心模块导入 LLM 基类,用于定义大语言模型接口
from llama_index.core.llms import LLM
# 从 llama_index 的 OpenAI 模块导入 OpenAI 类,用于与 OpenAI API 交互
from llama_index.llms.openai import OpenAI
# 从 OpenAI 工具模块导入模型列表常量
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS
# 定义Moonshot模型的上下⽂⻓度映射表
# key: 模型名称, value: 上下⽂⻓度(token数)
MOONSHOT_MODELS:Dict[str,int]={
"kimi-k2-0711-preview": 128000, # 模型的最大上下文长度
}
DEEPSEEK_MODELS:Dict[str,int]={
"deepseek-chat": 128000, # 模型的最大上下文长度
}
QIANWEN_MODELS:Dict[str,int]={
"qwen-plus": 128000,
}
# 将Moonshot模型添加到所有可⽤模型集合中
ALL_AVAILABLE_MODELS.update(
MOONSHOT_MODELS | DEEPSEEK_MODELS | QIANWEN_MODELS
)
# 将Moonshot模型添加到聊天模型集合中
CHAT_MODELS.update(
MOONSHOT_MODELS | DEEPSEEK_MODELS | QIANWEN_MODELS
)
def moonshot_llm(**kwargs) ->LLM:
llm = OpenAI(
api_key=os.getenv("MOONSHOT_API_KEY"),
model="kimi-k2-0711-preview",
api_base="https://api.moonshot.cn/v1",
temperature=0.2,
context_window=32768,
**kwargs
)
return llm
def deepseek_llm(**kwargs):
llm = OpenAI(
api_key= os.getenv("DEEPSEEK_API_KEY"),
model="deepseek-chat",
api_base="https://api.deepseek.com",
temperature=1.3,
**kwargs
)
return llm
def qianwen_llm(**kwargs):
llm = OpenAI(
api_key= os.getenv("QIANWEN_API_KEY"),
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=1.3,
**kwargs
)
return llm
代码解析很多人小伙伴可能对一下代码有所疑问,其实主要是lammaIndex是国外的框架,默认的可用模型和聊天模型的字典中没有设置自定义的模型,所以要将自己配置的模型追加到聊天模型和可用模型中:
# key: 模型名称, value: 上下⽂⻓度(token数)
MOONSHOT_MODELS:Dict[str,int]={
"kimi-k2-0711-preview": 128000, # 模型的最大上下文长度
}
DEEPSEEK_MODELS:Dict[str,int]={
"deepseek-chat": 128000, # 模型的最大上下文长度
}
QIANWEN_MODELS:Dict[str,int]={
"qwen-plus": 128000,
}
# 将Moonshot模型添加到所有可⽤模型集合中
ALL_AVAILABLE_MODELS.update(
MOONSHOT_MODELS | DEEPSEEK_MODELS | QIANWEN_MODELS
)
# 将Moonshot模型添加到聊天模型集合中
CHAT_MODELS.update(
MOONSHOT_MODELS | DEEPSEEK_MODELS | QIANWEN_MODELS
)
4.运行和测试
4.1 运行
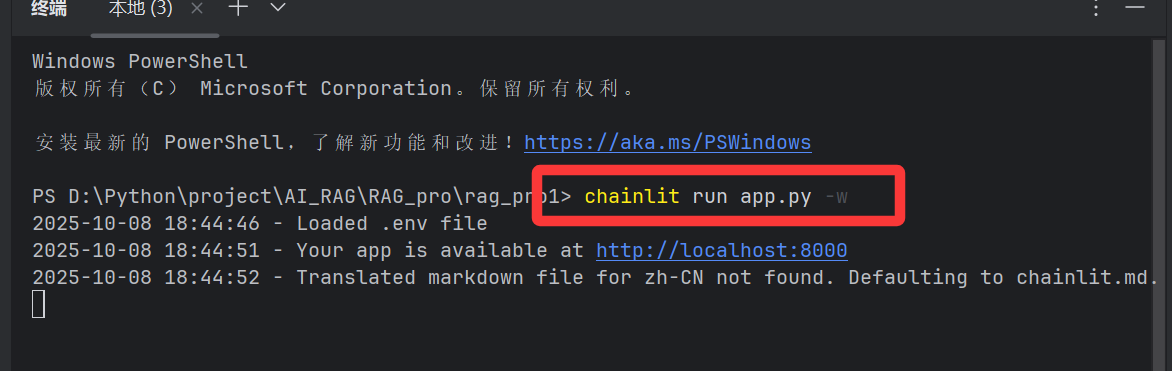
方式一:
运行命令:
chainlit run app.py -w
方式二:
配置运行配置,减少每次使用指令运行(更加方便)
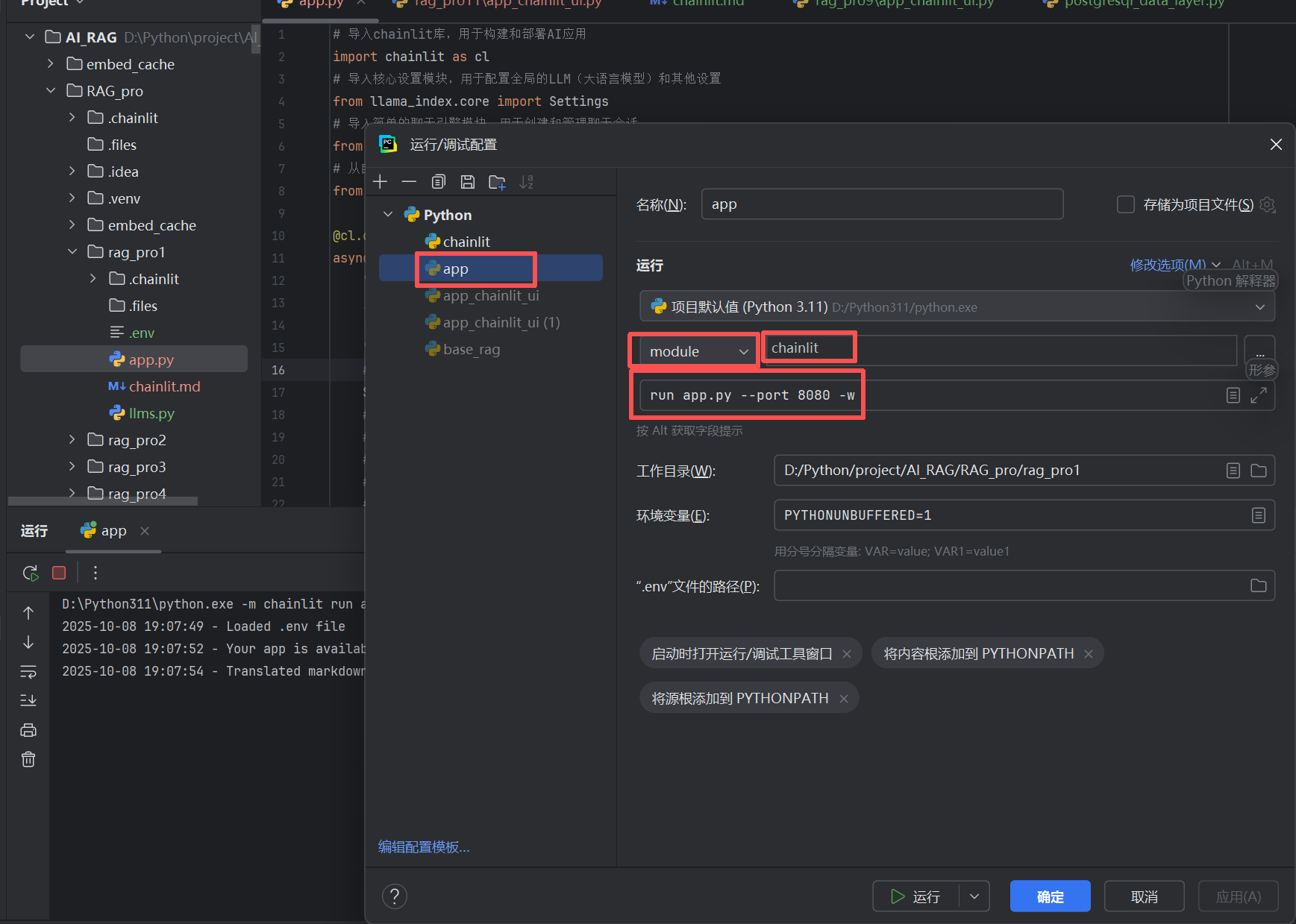
4.2 测试
随便发送一个问题,如果能够回答,那么我们这个最简单的基于chainlit和lammaIndex的最简单的聊天助手。

到这里我们已经实现了基本聊天,但是还是没有实现基于RAG知识库的聊天,接下来我会先向大家介绍什么是RAG,然后实现基于RAG的基本聊天。
二、RAG 核心流程实现:从私域数据到智能回答
RAG 的本质是 "用检索到的精准知识增强大模型的生成能力",完整流程分为数据准备(离线)与应用交互(在线)两大阶段。我们结合实战案例,拆解每个环节的实现细节。
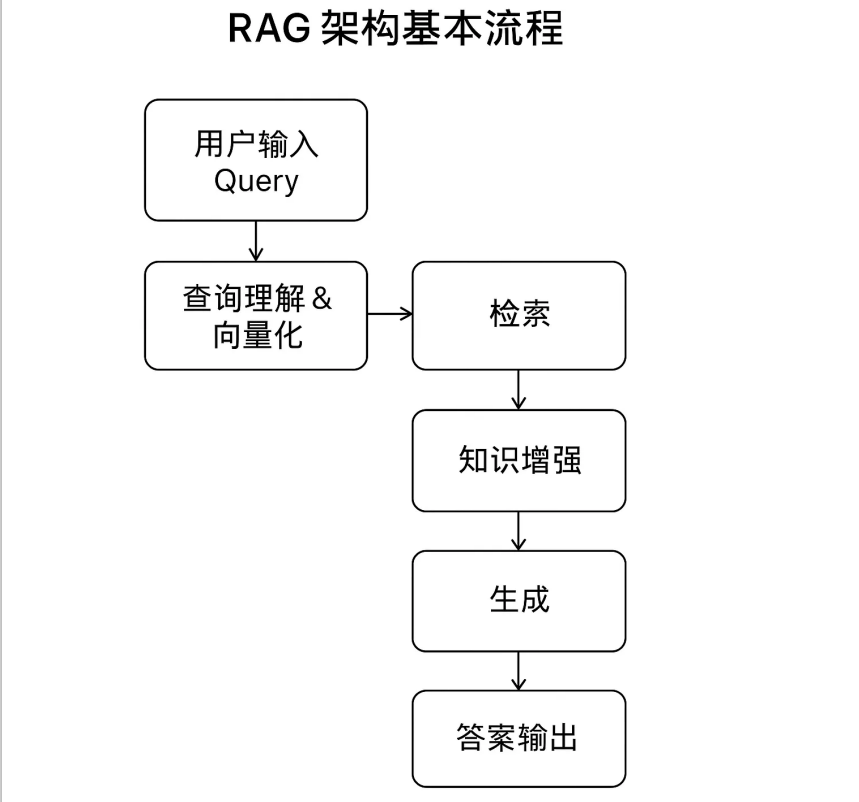
1. 什么是 RAG?解决大模型三大痛点
检索增强生成(RAG)通过将 "外部知识检索" 与 "大模型生成" 结合,精准解决通用大模型的核心缺陷:
- 知识局限:无需微调,直接接入私域 / 实时数据;
- 幻觉问题:基于检索到的真实数据生成回答,可追溯来源;
- 数据安全:私域数据仅做向量化存储,无需上传至第三方平台。
2. RAG 架构与核心流程
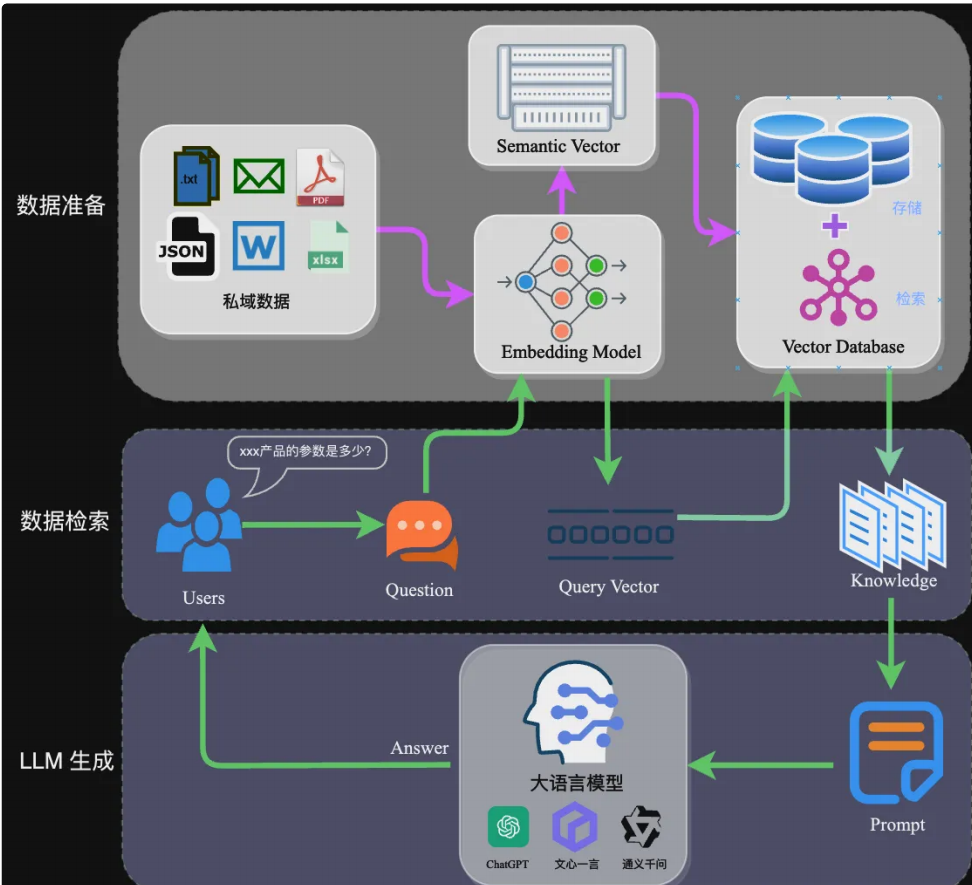
RAG 架构可拆解为 "数据准备" 和 "应用交互" 两个核心阶段,每个阶段包含多个关键环节:、
2.1 数据准备阶段(离线):构建私域知识索引
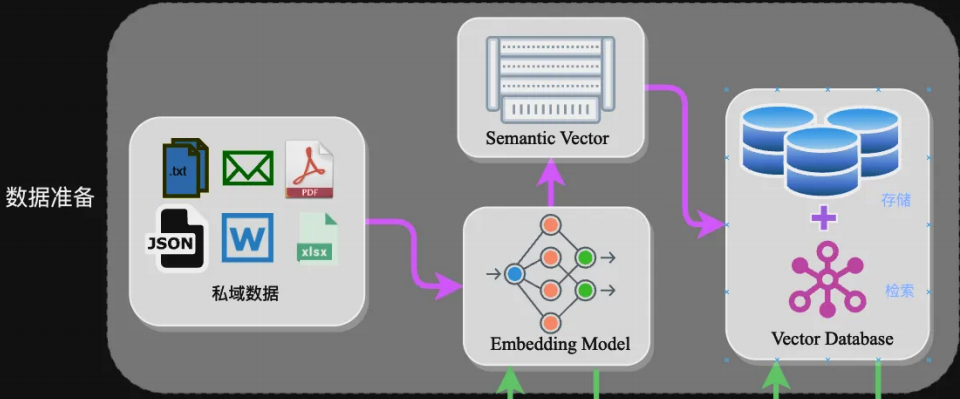
该阶段的目标是将非结构化的私域数据(如 PDF、Word、JSON 等)转换为可高效检索的向量索引,核心步骤如下:
- 数据提取:通过
SimpleDirectoryReader等工具加载多格式数据,提取文本内容并保留元数据(文件名、时间等); - 文本分割:平衡 "语义完整性" 与 "模型 Token 限制",常见方式包括:
- 句分割:按句号、换行符切分,保留完整语义;
- 固定长度分割:按 256/512Token 切分,通过冗余缓解语义丢失;
- 向量化(Embedding):将文本块转换为捕捉语义信息的高维向量,常用模型如下:
模型名称 特点 适用场景 ChatGPT-Embedding OpenAI 提供,接口调用 通用场景,无需本地部署 M3E 开源可微调,多尺寸版本 中文场景,需本地化部署 BGE 智源发布,支持中英双语 跨语言场景,可微调优化 - 数据入库:将向量索引存储到向量数据库,主流选择有 FAISS(轻量本地)、Chromadb(开源易用)、Milvus(大规模分布式)。
2.2 应用交互阶段(在线):响应用户查询
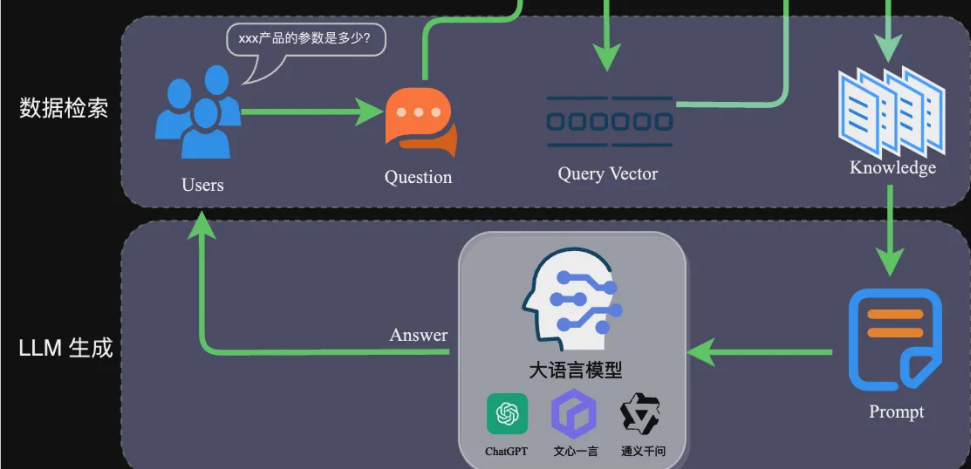
该阶段是用户可见的交互流程,核心是 "精准检索 + Prompt 增强 + 生成回答":
- 查询向量化:将用户提问转换为查询向量;
- 数据检索:在向量数据库中匹配 Top-K 相似的文本块;
- Prompt 构建:将检索到的知识作为 "背景信息" 注入 Prompt,示例如下:
- LLM 生成:大模型结合 Prompt 生成精准回答并返回给用户。
三、实践案例——私域知识问答应⽤案例
可能前面讲的太专业化,太难理解了,其实本质上要实现RAG知识库聊天:
- 首先是不是要上传文件到知识库,所以我们要提前知识库的文件。
- 然后如果知识库中的文件很多那么查询起来就很慢,导致浪费资源,这个时候我们就要把文件向量化(本地文件存储、向量数据库存储等),构建向量数据库。
- 其次聊天要基于向量知识库聊天,那么就要在向量数据库中快速检索想要的内容,然后把检索的内容添加到大模型内容中。
- 最后再根据内容生成准确的答案。
那么知道了这个基本原理,而且要记住这个原理,那么就让我来带大家实现一个最简单RAG的聊天助手。
该案例包含 3 个核心文件,实现从数据处理到前端交互的全流程闭环。
3.1 文件结构
RAG_PROJECT/
├── data/ # 私域数据目录(如PDF、Word)
├── index/ # 持久化的向量索引
├── basic_rag.py # 向量索引构建与聊天引擎创建
├── embeddings.py # 嵌入模型定义
├── app.py # 前端交互入口(Chainlit)
└── llms.py # LLM模型配置(如DeepSeek)
3.2 核心文件实现
(1)embeddings.py:本地 / 在线嵌入模型库
支持本地开源模型与在线模型切换,满足不同部署需求:
# 本地嵌入模型的创建函数,用于将文本转换为向量表示。
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 创建本地/在线嵌⼊模型库:
# 文本向量化:将文本转换为数值向量表示,便于机器学习模型处理和计算
# 语义理解:通过向量空间中的距离关系,捕捉文本之间的语义相似性
def embed_model_local_bge_small(**kwargs):
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5", # 专门针对中文优化的嵌入模型
cache_folder = r"../embed_cache",
**kwargs
)
return embed_model
# pip install llama-index-embeddings-huggingface
或者
# pip install llama-index-embeddings-ollama
或者
# pip install llama-index-embeddings-instructor
(2)base_rag.py:构建向量索引与聊天引擎
# 提供操作系统相关功能,如文件路径操作
import os
# 从llama_index库导入,用于定义聊天模式类型
from llama_index.core.chat_engine.types import ChatMode
# 从llama_index库导入,用于管理聊天对话内存缓冲区
from llama_index.core.memory import ChatMemoryBuffer
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
# 基础RAG模型
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
Settings,
StorageContext,
load_index_from_storage
)
# 导入本地的嵌入模型
from embeddings import embed_model_local_bge_small
# 设置嵌入模型
Settings.embed_model = embed_model_local_bge_small()
# 1、创建索引的方法
def create_index():
"""构建向量数据索引 """
# SimpleDirectoryReader--- 读取目录下的文件
# input_dir="data"---- 输入目录
# recursive=True ---- 递归搜索
# load_data --- 读取数据
data = SimpleDirectoryReader(input_dir="data", recursive=True).load_data() # 读取数据
# VectorStoreIndex---- 创建向量数据索引
# from_documents ------ 从文档创建索引
index = VectorStoreIndex.from_documents(data) # 创建索引
# storage_context ---- 存储上下文
# persist ---- 保存索引
# persist_dir="index" --- 保存目录
index.storage_context.persist(persist_dir="index") # 保存索引
# 2、创建聊天模型
async def create_chat_model():
"""
创建聊天模型
"""
# 读取索引数据
# StorageContext---存储上下文
# from_defaults ---- 创建存储上下文
# persist_dir="index" ---- 索引目录
storage_context = StorageContext.from_defaults(persist_dir="index")
# 加载索引数据
# load_index_from_storage ---- 创建索引
index = load_index_from_storage(storage_context)
print("索引数据加载成功:",index)
# 构建储存,存储聊天记录,限制token的数量为1024
# ChatMemoryBuffer --- 内存缓存数据
# token_limit ---- 限制token数量
memory = ChatMemoryBuffer.from_defaults(token_limit=1024)
# 创建聊天引擎,设置聊天模式为上下⽂模式,并指定记忆和系统提示
# chat_mode: 设置聊天模式为上下⽂模式,这意味着AI的回答将基于⽤户提供的上下⽂内容
# memory: ⽤于存储聊天历史记录,以便AI在回答时能考虑到之前的对话内容
# system_prompt: 系统提示,定义了AI的⾏为准则,即AI助⼿应基于⽤户提供的上下⽂内 容来回答问题,不允许随意编造回答
chat_engine = index.as_chat_engine(
chat_mode=ChatMode.CONTEXT,
memory=memory,
system_prompt="你是⼀个AI助⼿,可以基于⽤户提供的上下⽂内容,回答⽤户的问题。不能肆意编造回答。"
)
return chat_engine
if __name__ == "__main__":
create_index()
代码解析:
create_index函数1. 加载数据:从指定⽬录 "data" 中读取⽂档数据。2. 构建索引:使⽤加载的⽂档数据构建向量存储索引,并显示进度条。3. 持久化索引:将构建的索引保存到磁盘⽬录 "index" 下。说白了调用这个函数就能把data文件夹中的文件生成向量索引存储在index文件夹下面。create_chat_engine_rag 函数1. 初始化存储上下⽂:设置默认持久化⽬录为 "./index"。2. 加载索引:从存储路径中加载之前构建的索引。3. 构建聊天记忆缓冲区:创建⼀个⽤于存储聊天历史的内存缓冲区,限制 token 数量为 1024。4. 创建聊天引擎:基于加载的索引、聊天记忆和系统提示创建聊天引擎,并返回该引擎。说白了就是在读取index文件下面的向量数据和历史聊天记录,然后根据这些创建聊天引擎。
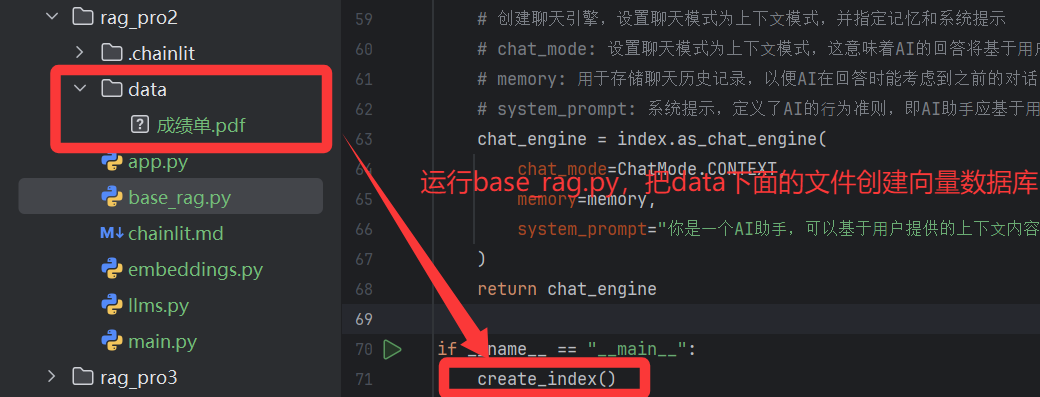
运行之后就会生成index文件就是用来存储向量数据,但是这种做法不推荐,后续会继续更新,教大家使用向量数据库milvus存储。
(3)app.py:前端交互入口
复用前文 Chainlit 核心逻辑,仅需修改聊天引擎的创建方式,现在创建的聊天引擎就是基于index向量数据库聊天:
# 导入chainlit库,用于构建和部署AI应用
import chainlit as cl
# 导⼊核⼼设置模块,⽤于配置全局的LLM(⼤语⾔模型)和其他设置
from llama_index.core import Settings
# 导⼊简单的聊天引擎模块,⽤于创建和管理聊天会话
from llama_index.core.chat_engine import SimpleChatEngine
# 从⾃定义模块中导⼊DeepSeek LLM实例,⽤于处理语⾔模型相关的任务
from llms import moonshot_llm
# 导入本地的base_rag模块的create_chat_model函数
from base_rag import create_chat_model
@cl.on_chat_start
async def start():
"""
当聊天会话开始时执行的异步函数
该函数负责初始化聊天环境,包括配置语言模型、创建聊天引擎和发送欢迎消息
"""
# 配置大模型
Settings.llm = moonshot_llm()
# 创建聊天引擎
# chat_engine = SimpleChatEngine.from_defaults()
chat_engine = await create_chat_model() # 创建本地知识库的聊天引擎
# 启动聊天
cl.user_session.set("chat_engine", chat_engine)
# 创建并发送欢迎消息给用户
await cl.Message(
author="Assistant",
content="欢迎来到Assistant聊天!"
).send()
@cl.on_message
async def main(message: cl.Message):
"""
处理用户发送消息的异步函数
Args:
message (cl.Message): 用户发送的消息对象,包含消息内容和其他元数据
该函数获取聊天引擎实例,处理用户输入,通过流式传输方式生成并发送AI回复
"""
# 获取聊天引擎实例
query_engine = cl.user_session.get("chat_engine")
# 创建一个空的 cl.Message 对象,用于构建将要发送给用户的响应消息。初始内容为空,作者设置为 "Assistant"。
msg = cl.Message(content="", author="Assistant")
# 将 query_engine.stream_chat 方法转换为异步方法,并调用它处理用户的消息内容。
res = await cl.make_async(query_engine.stream_chat)(message.content)
# 应对象中的 response_gen 生成器,逐个获取模型生成的文本片段(token)。
for token in res.response_gen:
# 将每个生成的文本片段逐步添加到消息对象中,实现流式输出效果,使用户能够逐步看到回复内容。
await msg.stream_token(token)
# 在所有文本片段处理完毕后,将完整的响应消息发送给用户。
await msg.send()
运行测试:
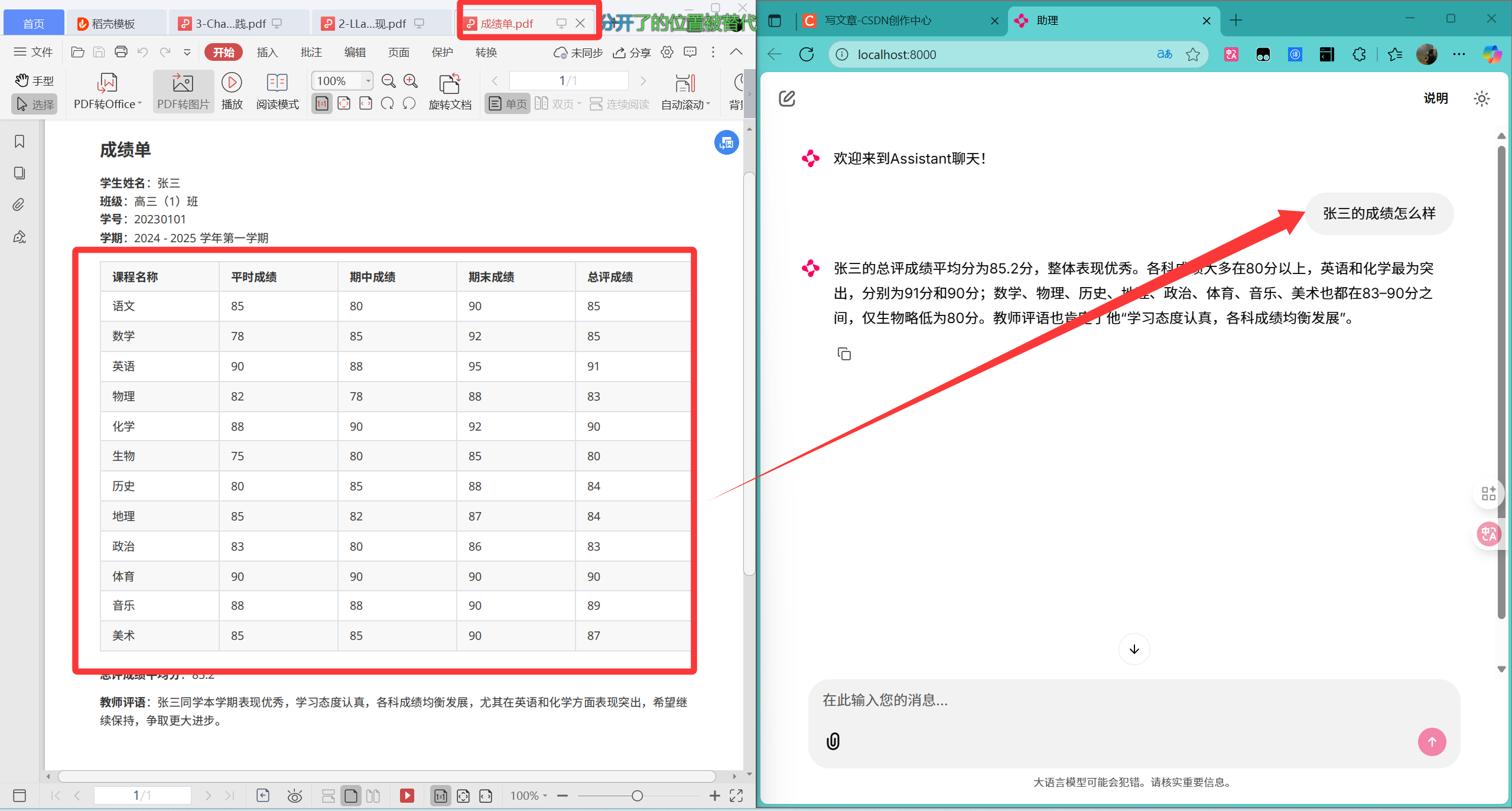
四、RAG 原理深度解析:从传统流程到多模态扩展
理解 RAG 的底层原理,能帮助我们在实际开发中针对性优化性能。本节从核心流程、关键概念、进阶扩展三个维度展开分析。
1. RAG 核心流程拆解(七步闭环)
RAG 的完整流程可概括为 "文档处理→查询匹配→生成回答" 的七步闭环,每一步都直接影响最终效果:
- 文档加载:通过连接器(Reader)加载本地文档(PDF/Word 等)为文本格式;
- 文本分割:将长文本切分为语义完整的文本块(Chunk);
- 向量化与存储:文本块通过嵌入模型转换为向量,存储到向量数据库;
- 查询向量化:用户提问转换为查询向量;
- 相似性检索:在向量数据库中匹配 Top-K 相似文本块;
- Prompt 构建:将相似文本块与提问整合为 Prompt;
- LLM 生成:大模型基于 Prompt 生成精准回答。
这一流程的核心优势在于 **"知识外置"** —— 知识存储在向量数据库中,无需通过微调更新大模型,仅需更新索引即可扩展知识范围。
2. RAG 中的关键概念
2.1 加载阶段
- 文档与节点:文档是数据源容器(如一个 PDF),节点是数据的原子单位(PDF 中的一个文本块),包含元数据用于关联;
- 连接器:用于提取不同数据源的工具(如
SimpleDirectoryReader处理本地文件,APIRetriever处理 API 数据)。
2.2 索引阶段
- 索引:将文本块转换为可检索结构的过程,核心是向量嵌入;
- 嵌入(Embedding):将文本语义映射为高维向量的技术,向量相似度直接反映语义相关性。
2.3 查询阶段
- 检索器:定义检索策略的组件(如相似性检索、全文检索),决定检索效率与相关性;
- 节点后处理器:对检索到的节点进行过滤、重排序(如基于相关性得分);
- 响应合成器:将检索到的文本块与提问整合,生成供 LLM 使用的 Prompt。
3. 传统 RAG vs 多模态 RAG
随着需求升级,RAG 已从单一文本处理扩展到支持图像、图表的多模态场景,两者的核心差异如下:
3.1 传统 RAG(文本 - only)
流程:用户文本提问→文本向量化→检索文本块→文本回答核心局限:无法处理图像、图表等非文本数据,例如无法回答 "请解释这张产品结构图的核心部件"。
3.2 多模态 RAG
多模态 RAG 通过引入视觉语言模型(VLM) 实现跨模态理解,以 CoLPaLi 方法为例,流程如下:
- 离线处理:通过视觉编码器(Vision Encoder)与 LLM 联合编码图像 / 图表,生成多模态向量;
- 在线查询:用户提问(可含文本 / 图像)通过对应模型转换为查询向量;
- 跨模态检索:在向量数据库中匹配相似的多模态数据;
- 多模态生成:LLM 结合文本与视觉信息生成回答(如解释图表数据、描述图像内容)。
多模态 RAG 的优势显著:在医疗影像分析、产品设计文档解读等场景,其检索准确率(NDCG@5 可达 0.81)远超传统文本检索(0.66),且离线处理速度提升近 20 倍。
五、总结与进阶方向
本文通过 "前端搭建→核心流程→原理解析" 的三层结构,完整实现了基于 LlamaIndex 与 Chainlit 的 RAG 智能问答系统。核心要点可概括为:
- 前端选型:Chainlit 最适配 LLM 对话场景,需注意版本兼容问题;
- RAG 核心:数据准备阶段的 "文本分割 + 向量化" 与应用阶段的 "相似检索 + Prompt 增强" 是效果关键;
- 原理本质:通过 "知识外置" 解决大模型的知识滞后与幻觉问题。
进阶优化方向
- 文本分割优化:使用语义感知的分割器(如 LlamaIndex 的
SentenceSplitter),结合文档结构(标题、段落)提升分割质量; - 检索策略升级:融合相似性检索与全文检索,加入重排序模型(如 Cross-Encoder)提升相关性;
- 多模态扩展:集成 VLM 模型(如 NeVA、DePlot),支持图像、图表的解析与问答;
- 性能优化:使用分布式向量数据库(如 Milvus)支持大规模数据,通过缓存减少重复检索。
掌握 RAG 技术,能让我们在不具备大模型微调能力的情况下,快速构建精准、安全的行业级智能问答系统。希望本文的实践与解析,能为你的 RAG 开发之路提供清晰指引。

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









