






Spring的理解
spring指的时spring framework , 他有两大核心
- IOC和DI spring的核心是一个打的工厂容器, 用于维护和管理对象创建和依赖的关系
- AOP spring提供了面向切面编程, 允许我们将日志和业务的代码分离开进行管理使用
bean创建过程
spring创建一个bean对象首先需要获取一个实例对象, 这种对象一般使用无参构造的方法创建实例对象,这种对象并不是我们想象中的bean对象, 普通对象和bean对象之间还差一个依赖注入的过程
//普通对象
Student stu = new Student();
//bean对象
ApplicationContext ac = new ClassPathXmlApplicationContext("xx.xml");
Student stu = ac.getBean("stu");通过无参构造获取一个实例对象, 再根据@Autowired的注解来判断属性注入
for(Field field: stu.getClass().getDeclaredFields()){
if(field.isAnnotationPresent(Autowired.class)){
field.set(stu, ??); //对stu这个对象的field字段赋值
}
}spring创建的对象并不是简单的利用反射创建一个对象, 创建的对象如果有依赖于其他对象, 通过依赖注入之后的普通对象就成为了bean对象
Student ==> 无参构造 ==> 对象 ==> 依赖注入 ==> bean对象
单例bean
spring创建的容器默认使用创建的bean是单例bean ,也就是说使用同一个名字,在ioc容器中获得的都是同一个对象,这些单例bean通常都放在单例池中(使用map实现), 需要使用的时候再从单例池中获取.
初始化
spring为了可扩展性强, 在bean完成创建之前, 引入了初始化前、初始化和初始化后这样的方法
Student ==> 无参构造 ==> 对象 ==> 依赖注入 ==> 初始化前 ==> 初始化 ==> 初始化后 ==> 存入单例池 ==> bean对象
@Componet
public class UserService{
@Autowired
private OrderService orderService;
//@Autowired admin在这边不能使用autowired注解自动注入
private User admin;
public void a(){
//mysql ==> user对象 ==>this.admin
}
}在这段代码中, admin这个对象需要查询数据库,对admin属性赋值,这些数据库为admin赋值spring无法完成, 需要手动写出一些代码逻辑对admin赋值
初始化前
通过对a方法的调用, 可以完成对admin的赋值,spring需要自动调用这个方法, 在方法上面加上@PostConstruct让spring自动调用
@PostConstruct
public void a(){
//mysql ==> user对象 ==>this.admin
}初始化
spring也提供了一个接口, 用于初始化这个阶段, InitializingBean,我们可以通过实现这个接口, 进而完成对admin的赋值
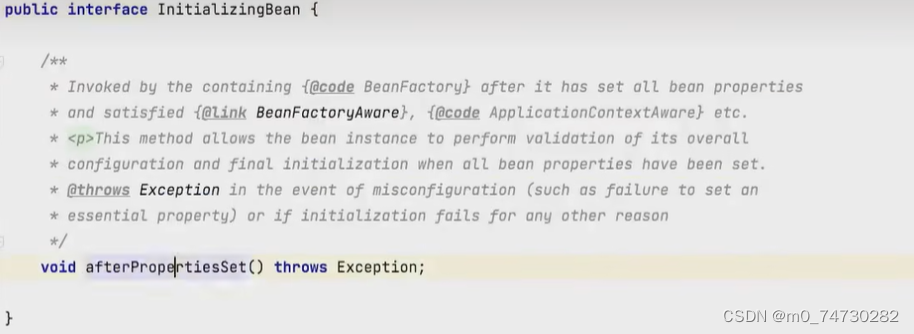
@Componet
public class UserService implements InitializingBean{
@Autowired
private OrderService orderService;
//@Autowired admin在这边不能使用autowired注解自动注入
private User admin;
@Override
public void afterPropertiesSet() throws Exception{
//mysql ==> user对象 ==>this.admin
}
}在spring源码中, 在doCreatBean这个方法中有个invokeInitMethods这个初始化方法, 在这个方法中,会对bean做 bean instanceof InitializingBean这个判断
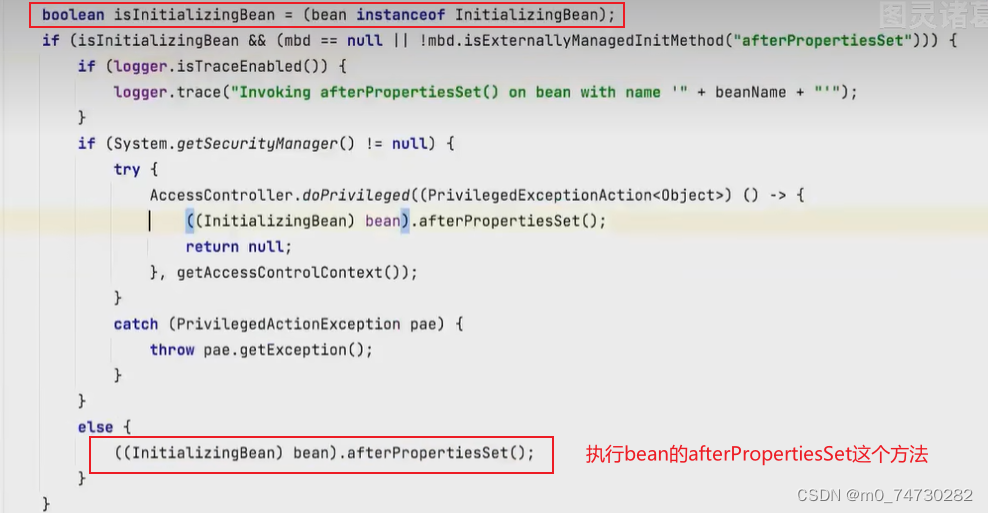
初始化后
初始化后是在属性赋值完成之后, spring会做一些aop操作, 经过aop代理后, 最后是将代理对象放入单例池中, 通过名字取出来的就是代理对象,如果不需要代理, 那么放入单例池的就是普通对象
流程总结
Student ==> 无参构造 ==> 对象 ==> 依赖注入 ==> 初始化前(PostConstruct) ==> 初始化(afterPropertiesSet) ==> 初始化后(aop) ==> 代理对象 ==> 存入单例池 ==> bean对象
后置处理器
这些初始化前中后操作和依赖注入的底层都是通过spring的后置处理器来实现的
有参构造
如果spring的类中, 有两个构造方法, 那么spring应该用哪个构造方法呢 ?
@Component
public class UserService{
private OrderService orderService;
public UserService(){
System.out.println(0);
}
public UserService(OrderService orderService){
this.orderService = orderService;
System.out.println(1);
}
}默认情况下, 如果是多个构造 ,而且有无参构造, 使用的是无参构造
如果类中只有一个有参构造, spring直接使用这个构造进行处理
@Component
public class UserService{
private OrderService orderService;
public UserService(OrderService orderService){
this.orderService = orderService;
System.out.println(1);
}
}如果类中有两个构造, 而且没有无参, 这种情况spring无法决定使用什么构造, 通过异常抛出处理
@Component
public class UserService{
private OrderService orderService;
public UserService(OrderService orderService){
this.orderService = orderService;
System.out.println(1);
}
public UserService(OrderService orderService,OrderService orderService1){
this.orderService = orderService;
System.out.println(2);
}
}
如果确实存在多个构造, 也没有无参构造, 通常使用@Autowired注解为spring做出标记, 使用当前被autowired标记的构造方法
@Component
public class UserService{
private OrderService orderService;
public UserService(OrderService orderService){
this.orderService = orderService;
System.out.println(1);
}
@Autowired
public UserService(OrderService orderService,OrderService orderService1){
this.orderService = orderService;
System.out.println(2);
}
}有参构造的参数细节
对于有参构造来说, 如果构造函数中的参数在spring容器中没有相应的bean, 就会无法创建该对象, 会抛出异常,而不是传入null
@Component
public class UserService{
private OrderService orderService;
public UserService(OrderService orderService){
this.orderService = orderService;
System.out.println(1);
}
}//没有加@Component
public class OrderService {
}
有参匹配规制
spring的有参构造究竟是以类型匹配还是按照名字匹配
@Component
public class UserService{
private OrderService orderService;
public UserService(OrderService memberService){ //Map<'orderService', OrderService;'memeberService', MemberServie>
this.orderService = orderService;
System.out.println(1);
}
}在探讨匹配问题前, 这边描述一个细节, 单例bean不是指的是该类只有一个实例对象,而是对应名字只能有一个对象,他们是三个单独的对象
@Component
public class OrderService{
}@Configuration
public class Config{
@Bean
public OrderService orderservice1(){
return new OrderService();
}
@Bean
public OrderService orderservice2(){
return new OrderService();
}
}所以构造函数匹配首先是按照类型匹配, 如果有多个, 再按照名字选出唯一的一个,先byType 再byName,像这种需要进一步推断才能确定属性值的叫做推断构造方法
参数匹配规制
参数匹配规制和构造函数匹配规制相同, 都是通过先byType再byName
AOP
cglib代理
这里使用target.test()而不是supper.test(); 如果使用的是supper, 这里执行的只是父类的代码, 而且父类属性是对象属性,不是类属性,属性上值为null, 使用创建出来的普通对象target的属性中有值
class UserServiceProxy extends UserService{
UserServie target;
@Override
public void test(){
//@Before 切面逻辑
//userService的test方法 这里不是使用super.test();
target.test();
}
}通过代理的普通对象并不存在于单例池中, 而是在jvm中,代理对象在单例池中
@Aspect
@Component
public class MAspect{
@Before("execution(public void com.service.UserService.test()))
public void before(JoinPoint joinPoint){//joinPoint.getTarget() == 需要代理的普通对象
System.out.println("before");
}
}spring事务
事务的配置
@ComponentScan("com")
@EnableTransactionManagement
public class AppConfig{
@Bean
public JDBCTemplate jdbcTemplate(){
return new JDBCTemplate(datasource());
}
@Bean
public PlatformTransactionManager transactionManager(){
DatasourceTransactionManager transactionManager = new DatasourceTransactionManager();
transactionManager.setDataSource(datasource());
}
@Bean
public DataSource datasource(){
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/db");
dataSource.setUsername("root");
dataSource.setPassword("123456");
return dataSource;
}
}这里的 sql语句会成功, 因为上面的bean配置都没有成功, AppConfig没有配置@Configuration注解
@Component
public class UserService{
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional
public void test()
jdbcTemplate.execute("insert into t value(1,1,1)");
throw new NullPointException();
}
}如果加上@Configuration, 事务会回滚
spring事务的代理对象
class UserServiceProxy extends UserService{
UserService target;
public void test{
//判断有无@Transal注解
// 利用事务管理器建立数据库连接conn,修改conn.autocommit = false;
target.test();//sql执行
//conn.rollback, conn.commit();
}
}@Configuration代理对象
JdbcTemplate需要一个datasource , transactionManager需要一个datasource, 在没有加入configuration注解之前, 在java层面,他就是两次方法调用, 那么两次都会创建一个datasource对象, 也就是说jdbcTemplate和transactionManager中的连接是两个不同的连接,如果是两个不同的连接, jdbc执行完成之后(jdbc已经提交了), 再抛出异常也没有什么用处.
public void test(){
//@Transactional
//事务管理器创建连接conn , ThreadLocal<Map<DataSource,conn>> 一个数据源对应一个连接, 支持多数据源
//conn.autocommit = false;
//jdbcTemplate获取连接 conn 执行sql, 这个conn是事务管理器创建的连接,
//jdbc用自己的datasource去从ThreadLocal获取对应datasource的conn, 如果有,直接使用,没有再创建一个
}使用configuration不仅可以实例化对象, 而且被@configuration标记的类是个代理类,通过方法调用也能获取到一样的datasource,而不是全新的datasource.
事务传播行为
如果是直接在方法中调用另一个方法, 这是普通对象调用普通对象的方法, 事务不会发生传播行为
@Component
public class UserService{
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional
public void test()
jdbcTemplate.execute("insert into t value(1,1,1)");
a();
}
@Transactional(propagation = Propagation.NEVER)
public void a(){
jdbcTemplate.execute("insert into t value(1,1,1)");
}
}那如何解决事务无法传播呢? 因为事务是靠aop代理得来的, 调用方法的对象中一定有个已经接受事务代理的对象,如果执行成功, 那么就会抛出异常
@Component
public class UserService{
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private UserServiceBase userServiceBase;
@Transactional
public void test()
jdbcTemplate.execute("insert into t value(1,1,1)");
userServiceBase.a();
}
}@Component
public class UserServiceBase {
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional(propagation = Propagation.NEVER)
public void a(){
jdbcTemplate.exexute("insert into t values(1,1,1)");
}
}
但是这种方式还需要再写一个类, 比较麻烦, 可以自己注入自己
@Component
public class UserService{
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private UserService userService;
@Transactional
public void test()
jdbcTemplate.execute("insert into t value(1,1,1)");
userService.a();
}
@Transactional(propagation = Propagation.NEVER)
public void a(){
jdbcTemplate.exexute("insert into t values(1,1,1)");
}
}spring三级缓存
像这种情况属性之间互相依赖, 如果不做特殊处理, 就会出现一种死循环的情况
public static void main(String[] args){
AnnotationConfigApplicationContext application = new AnnotationConfigApplication(AppConfig.class);
AService aService = (AService)application.getBean("AService");// 这里的A是大写的, spring默认情况下,如果前两个字符都是大写的,那么名字第一个字母不会小写
aService.test();
}@Component
public class BService{
@Autowired
private AService aService;
public void test(){
System.out.println(aService);
}
}@Component
public class AService{
@Autowired
private BService bService;
public void test(){
System.out.println(bService);
}
}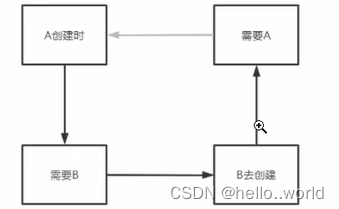
AService创建的生命周期
- 创建一个AService普通对象 ==> map 将普通对象和名字放入map中 map.put(AService,对象);
- 填充bService属性 ==> 去单例池中找BService对象 ==> map ==> 创建BService
- 其他属性
- 其他操作
- 初始化后
- 放入单例池
BService创建的生命周期
- 创建一个BService普通对象
- 填充aService属性 ==> 去单例池中找AService对象 ==> map(获取AService普通对象)
- 其他属性
- 其他操作
- 初始化后
- 放入单例池
像这样我们可以通过使用单例池和额外的一个map来解决循环依赖问题, 而且如果在没有aop的情况下, 似乎可以完美解决循环依赖问题
A a = new A();
a.b = ?
B b = new B();
b.a = a; //这里的b获取的A是普通对象
a.b = b; //通过a的引用将b赋值那为什么需要使用三级缓存呢? 在上面我也提醒了, 如果是没有aop的情况下, 因为aop之后, 存入单例池的对象不在是普通对象, 而是代理对象, 也就是说, autowired进入的值必须是代理对象,像这种情况使用二级缓存是无法完美解决问题的.
提前aop
如果我们可以提前将aop的对象放入map中, BService的aService属性获取的就是AService的代理对象, 就此思路我们可以提前对AService进行aop处理, 以下是对aop提前创建的抽象流程
AService
- creatingSet("AService") 表示当前AService正在创建过程
- 创建AService普通对象
- 填充bService属性 ==>去单例池中找BService ==>从createSet()找有无BService正在创建(无) ==> map ==> 创建BService
BService
- creatingSet("BService")
- 创建一个BService对象
- 填充aService属性 ==> 去单例池中找AService ==> creatingSet存在AService..表明出现了循环依赖问题 ==> 提前aop ==> AService代理对象
这样看起来是不是已经解决了循环依赖而且aop问题也得到了解决. 但这只是我们讨论两个类, 那如果是三个类呢.
@Component
public class AService{
@Autowired
private BService bService;
public void test(){
System.out.println(bService);
}
}@Component
public class BService{
@Autowired
private AService aService;
}@Component
public class CService{
@Autowired
private AService aService;
}BService
- creatSet("BService")
- 创建BService 普通对象
- 填充aService属性 ==> 单例池 ==>creatingSet判断 ==> 出现循环依赖 ==> 二级缓存中查找AService==>AService提前Aop ==> 放入earlySingletonObjects<"AService",AService代理对象>
- 后面的逻辑
CService
- creatSet("CService")
- 创建CService 普通对象
- 填充aService属性 ==> 单例池 ==>creatingSet判断 ==> 出现循环依赖 ==> AService提前Aop ==> 放入earlySingletonObjects<"AService",AService代理对象>
- 后面的逻辑
三个map
- 单例池 singletonObjects bean(完成各种属性赋值操作,经过完整的生命周期,可以为外界所用)
- 二级缓存 earlySingletonObjects (没有经过完整生命周期的单例bean ,但是这些bean的地址将来一定是对应属性的地址值)
- 三级缓存 singletonFactories (存放lambda表达式(普通对象,beanDefinition, 名字) ) 如果要进行aop , 给二级返回代理对象, 如果不需要, 返回普通对象, 不执行lambda表达式
能够打破循环的只是三级缓存, 单例池和二级缓存是保证不重复创建对象
总结

spring拦截器和过滤器的区别
在正式讨论拦截器和过滤器之前, 我想声明一点, filter只作用在请求到达controller之前, 而拦击器后前置处理和后置处理,分别在controller之前和之后.
file和interceptor都是aop思想的一种体现, 用来解决莫一类问题的两种接口, 可以对代码做一些增强. 那他们的区别是什么呢 ?
| 过滤器 | 拦截器 | |
|---|---|---|
| 出身不同 | 来自servlet | 来自spring |
| 使用范围不同 | 过滤器实现了javax.servlet.Filter接口,依赖于tomcat, 只能用在web程序中 | org.spirngframework.web.servlet,由spirng管理,不依赖于tomcat |
| 实现原理不同 | 基于过滤链ApplicationFilterChain实现 | 基于java反射 |
| 使用场景不同 | 字符编码设置,响应数据压缩(偏向通用功能) | 登录判断, 权限判断,日志等(偏向业务) |
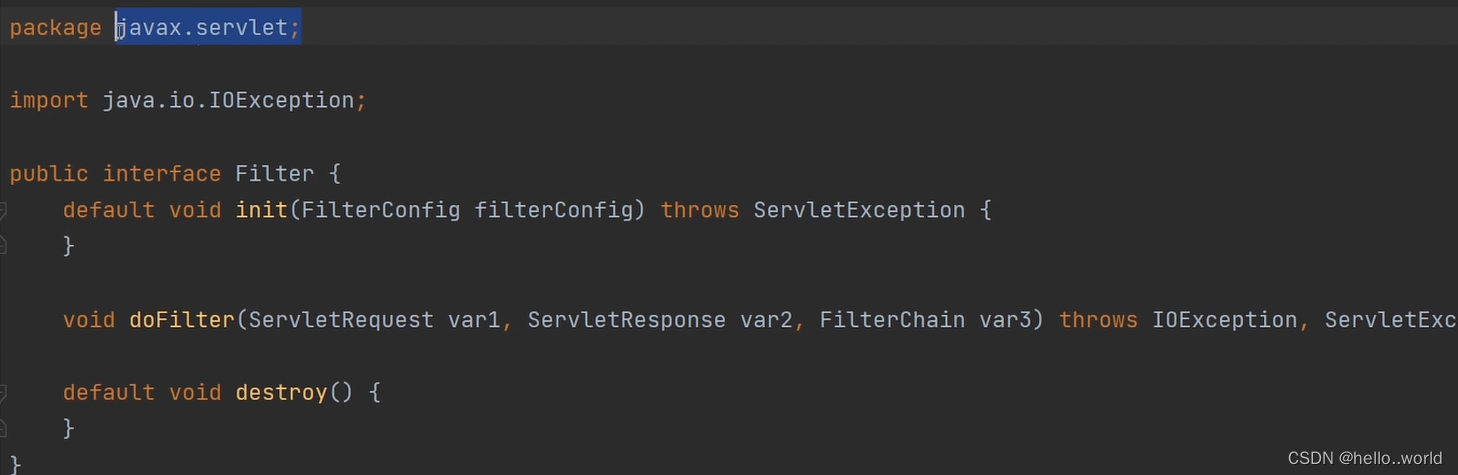
filter和interceptor都可以对request和response做一些增强操作

filter
首先我想明确的一点是, filter只能对web的request和response做处理 ,也就是说你可以对请求响应做一些参数更改处理
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1.获取request和response对象
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
//2.判断是否是登录
if(request.getURI().getPath().contains("/login")){
//放行
return chain.filter(exchange);
}
//6.放行
return chain.filter(exchange);
}
}interceptor
拦截器, 从方法的参数来看, 除了response和request, 它还可以对handler做处理
其次, 我在这个例子中加入了ThreadLocal, 对当前线程添加了一个变量, 线程结束后为了防止内存泄漏, 将变量删除, filter就无法做到这一点
public class WmTokenInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String userId = request.getHeader("userId");
if (userId != null) {
WmUser wmUser = new WmUser();
wmUser.setId(Integer.valueOf(userId));
WmThreadLocalUtil.setUser(wmUser);
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
WmThreadLocalUtil.clear();
}
}@Configuration
public class WebMvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new WmTokenInterceptor())
.addPathPatterns("/**");
}
}
Spring容器启动流程是怎么样的
- 首先进行扫描, 得到所有的BeanDefinition对象, 并存在一个map中, 这些BeanDefination存储着bean的类描述信息, bean是单例的还是多列的, 懒加载还是非懒加载,一个BeanDefination对应着一个Bean对象
- 然后筛选出非懒加载的单例BeanDefination进行创建Bean,对于多例bean并不需要在启动过程中去创建, 对于多例bean会在每次获取bean时,用BeanDefination去创建
- 在创建过程中间就包括bean的生命周期
- 当bean创建完成之后, spring发布容器启动事件
- spring启动结束
Spring中的单例bean是线程安全的吗
先说结论, bean不具备线程安全的特性. Spring的bean在上下文中只有一个, 在多线程情况下, 单例bean的状态是可被修改的, 可能存在线程安全问题.
那么为了保证bean线程的安全性, 这里有三种方法
- 使用无状态的bean, bean中不含任何实例变量, 只包含方法和局部变量, 因此就不会有线程安全问题, 那什么是无状态bean, 在多线程中, 只会对bean的成员变量进行查询操作而不会修改成员变量值的bean(比如: 常量), 就是无状态bean(并不是没有成员变量)
@Component
public class A{
public void print(String s){
System.out.println(s);
}
}- 多例bean(prototype), 在每次使用bean的时候, 都会创建一个bean, 这样就可以保证, 线程的安全问题,线程间不存在bean共享的问题
- 在类中定义ThreadLocal, 将可变的成员变量保存在ThreadLocal中,因为ThreadLocal本身具备线程隔离性, 因此可以使用ThreadLocal来存放可变的成员变量;
public class A{
ThreadLocal<Object> threadLocal = new ThreadLocal<>();
}














 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









