






1、音频信号处理
声音的记录,主要采集声音的振幅强度以及方向。采集某一个点的强度以及方向,因为声音是连续性的信号,以一个什么样的频率去采集十分重要———采样定理
采样率(16000个点/秒) * 语音时长 = 语音采样点数
1.1采样定理
对于连续信号x(t)进行抽样时,抽样信号的最小频率p(t)的频率要大于x(t)的最大频率的2倍,采样得出的信号x[n]才能还原出原始信号x(t)。
-
如果采样率正好等于原始频率,那每次采样的都会是同一个周期点

-
如果当采样频率小于2f时,得到的信号会发生失真,产生出新的混叠信号。

- 如果当采样频率大于2f时,一个信号周期内至少能采集到三个点,一定能够计算出正弦信号的表达式。(大多数信号都能展开成若干正弦信号叠加,如果我的采样间隔能够完美采样周期最短的那个正弦信号,那当然能完美采样这个由若干正弦叠加出来的信号。)
1.2基频,共振峰
基音,共振音: 能量通过声带使其振动产生一股基声音,这个基声音再通过声道,与声道发生相互作用产生共振声音,基声音与共振声音一起传播出去。
基音频率(通常由声带振动产生)和共振峰(由声道共振决定的频率增强区域)是语音信号的自然物理特征,反映了发音器官的运动和形状。通过傅里叶变换分析频率成分,我们可以提取出这些特征。
1.3短时傅里叶变换
语音信号处理常常要达到的一个目标,就是弄清楚语音中各个频率成分的分布,提取特征。
傅里叶变换能够将信号分解为多个不同频率的周期性成分,因此,它是分析语音信号频谱的重要工具。语音信号由声带振动产生的基音和由声道共振决定的共振峰共同构成。通过傅里叶变换,我们可以有效地分析语音信号中的基音频率和共振峰特征,进而了解语音的声学结构。
a) 傅里叶级数
看不懂点这里
傅里叶男爵(1768 -1830)猜测任意周期函数都可以写成三角函数之和
- 据周期函数的定义,常数函数是周期函数,周期为任意实数。所以,分解里面得有一个常数项。
- 任意函数可以分解和奇偶函数之和,所以同时需要sin(x),cos(x)
- 保证组合出来的函数周期依然为T。sin(2派n/T * x) cos(2派n/T * x)

b) 快速傅里叶变换(FFT)
傅里叶级数适用于周期性函数,而傅里叶变换用于非周期性信号。虽然语音信号有些局部周期性成分(如基音),但整体上是不周期的,不能用傅里叶级数直接分析。傅里叶变换通过将信号在整个时间范围内展开,可以揭示信号的频率成分。因此,它非常适合分析非周期信号的频率分布。
c) 短时傅里叶变换(STFT)

三个时域上有巨大差异的信号,频谱(幅值谱)却非常一致。我们从频谱上无法区分它们,因为它们包含的四个频率的信号的成分确实是一样的,只是出现的先后顺序不同。
傅里叶变换有一个重要限制:它分析的是整个信号的频率成分,没有时间局部化的信息。这对于分析语音信号(一个典型的非平稳信号)来说是一个问题,因为我们需要知道频率成分在时间上是如何变化的。
语音信号的频率特性在讲话过程中不断变化,属于非平稳信号。为了处理这种非平稳信号,我们使用短时傅里叶变换(STFT)。STFT通过将信号在小的时间窗口内进行傅里叶变换,从而在每个短时间段内得到频率成分的分布,提供了时间-频率的联合表示。这样我们就能追踪频率成分随时间的变化,适合分析语音信号。
“把整个时域过程分解成无数个等长的小过程,每个小过程近似平稳,再傅里叶变换,就知道在哪个时间点上出现了什么频率了。”这就是短时傅里叶变换。

使用STFT存在一个问题,我们应该用多宽的窗?(分帧)
- 窗内的信号太短,会导致频率分析不够精准,频率分辨率差。

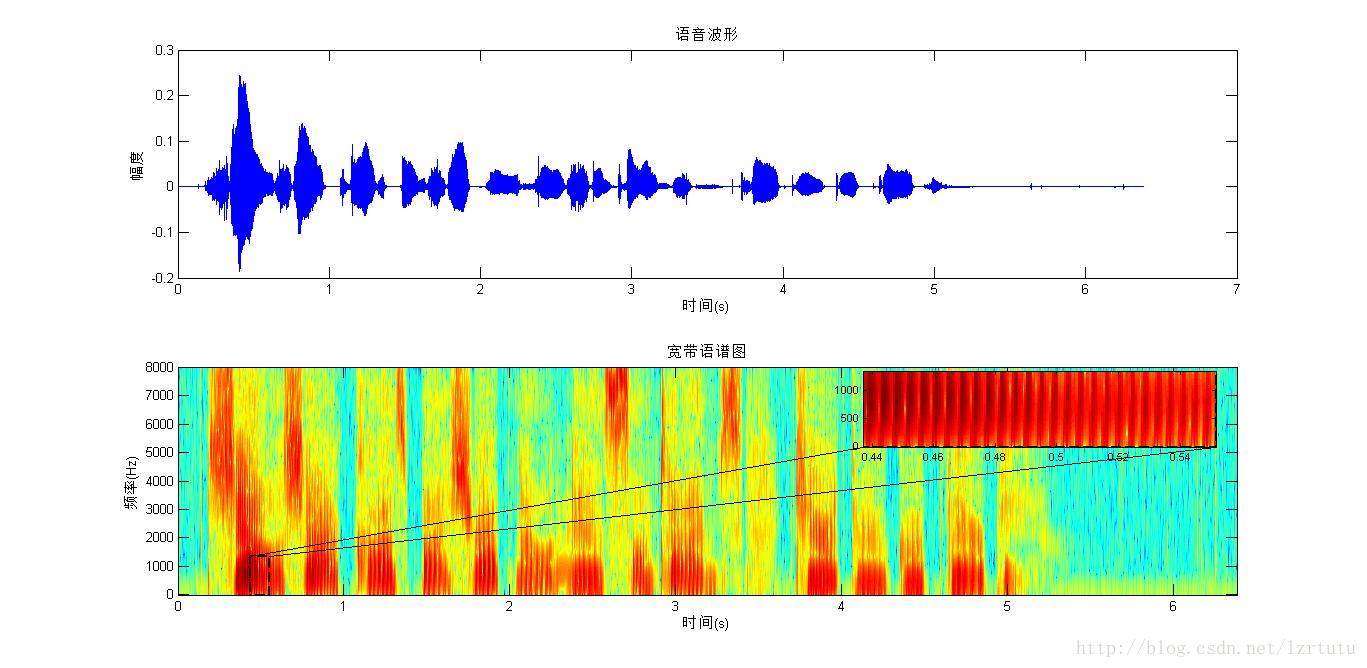
宽带语谱图的时宽窄,那么在时间上就“分得开”,即能将语音在时间上重复的部分“看得很清楚”,即表现为“竖线”。“竖”就体现出了时间分辨率高。时间分辨率越高,谱图上的竖线看得越清楚。
- 窗太宽,时域上不够精细,时间分辨率低。

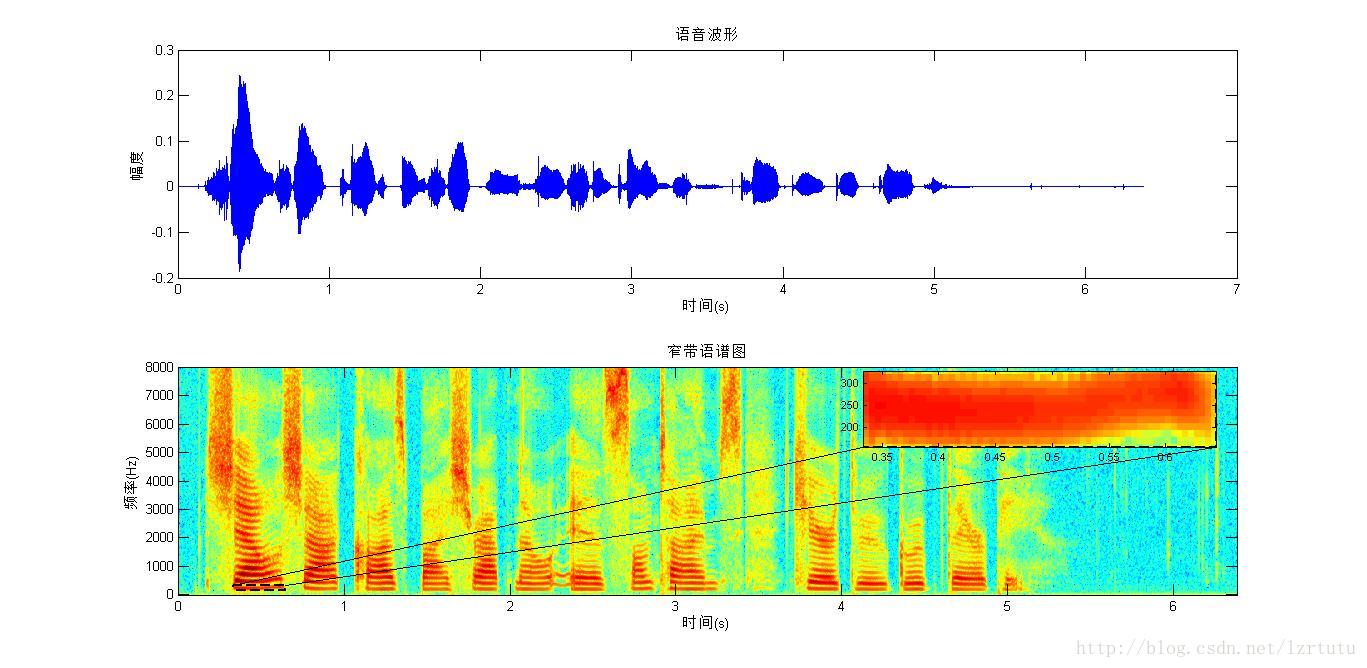
“窄带”,顾名思义,带宽小,则时宽大,则短时窗长,窄带语谱图就是长窗条件下画出的语谱图。“宽带”,正好相反。至于“横竖条纹”,窄带语谱图的带宽窄,那么在频率上就“分得开”,即能将语音各次谐波“看得很清楚”,即表现为“横线”。“横”就体现出了频率分辨率高。分辨率可以直观的看做“分开能力”。“频率分辨率”高就是在频率上将各次谐波分开的能力高,表现为能分辨出各次谐波的能力高,频率分辨率越高,越容易分辨各次谐波。
对于时变的非稳态信号,高频适合小窗口,低频适合大窗口。
d) 从窄带语谱图和宽带语谱图看基音频率和共振峰
基音周期表示声带的震动周期,每隔这么长时间(震动周期),有一个气流通过,“每隔”就体现了周期性,这就是基音周期,那么谱图上就应该有这个频率的信号分量,而且这个频率的幅度(能量)不应该很小,因为每隔一段时间“就有”一团能量通过声带。
所以基音频率所在的成分在窄带语谱图上应该是所有横条纹中频率范围最低的那条。在图2中,用虚线框框住的部分就表示基音频率成分,与其在同一水平线上的条纹都表示该时刻的基音频率成分,这条条纹对应的纵轴刻度值就表示基音频率。从图2小图可估计基音频率大约在250Hz左右,基音频率略有波动,0.5s处大约是240Hz。其他横条纹就是各次谐波,这些谐波中有些地方颜色比同时刻其附近其他横条纹颜色要深,这些颜色深的条纹表示共振峰。有些时刻,颜色较局部附近深的条纹不止一条,这些深色条纹组成了各次共振峰,如第一、第二、第三共振峰。
图1,宽带语谱图的基音频率和共振峰就不清晰了。但是其仍可以看出基音周期,图1小图具有明显的竖线,两条竖线之间的时间就表示基音周期。在0.44s到0.54s时间段内大约有25条竖线,即24个间隔,则基音周期可估计为(0.54-0.44)/24=4.17ms,则基音频率估计为240Hz。
在宽带语谱图中,短的时间窗口使得语谱图能够捕捉到声波信号的周期性特征。当语音信号是周期性的(例如发声时声带振动产生的周期波形),宽带语谱图中会出现竖线,这些竖线对应着每一次声带振动产生的周期信号。
这些竖线的间隔正好对应着信号中的基音周期。也就是说,每条竖线的出现代表一次声带的完整振动周期,因此两条竖线之间的时间间隔就是一个基音周期。
1.4小波变换
然而STFT的窗口是固定的,在一次STFT中宽度不会变化,所以STFT还是无法满足非稳态信号变化的频率的需求。
小波变换与傅里叶变换有一个根本的区别在于基函数的选择。在傅里叶变换中,基函数是无限长的正弦波,而在小波变换中,基函数是有限长的衰减小波。这使得小波变换在处理非平稳信号时具有显著优势。

- 小波基函数:与傅里叶变换使用的无限长正弦函数不同,小波变换的基函数是一个局部化的、会随时间衰减的小波函数(例如 Morlet 小波、Daubechies 小波等)。这些小波基函数能在时间和频率上同时具有局部性。
- 多分辨率分析:小波变换可以根据信号的不同频率范围自动调整时间和频率分辨率。低频部分使用较长的小波基函数,获得良好的频率分辨率,而高频部分使用较短的小波基函数,获得良好的时间分辨率。
- 小波变换不仅能像傅里叶变换一样分析信号的频率成分,还可以在时间域上精确定位信号的特征。例如,对于瞬时信号突变或尖峰信号,小波可以准确告诉你这些特征发生的时刻,而傅里叶变换则难以做到这一点。
既能捕捉频率信息,又能精确定位时间信息
1.5语音处理流程
a) 预加重与去加重
受口唇辐射的影响,功率谱随频率的增加而减小,语音的能量主要集中在低频部分,高频部分信噪比较低,为了抵消这种不利影响,需要对语音信号进行预加重和去加重处理。
- 预加重一般使用一阶的FIR的高通滤波器来加重语音信号的高频分量,滤波器的传递函数H(z)=1-a z^{-1},a为预加重系数,通常为0.9 < a < 1.0。MATLAB中可以用y=filter([1, -0.98],1,x)指令来实现预加重,其结果如下图所示。

b) 分帧与加窗
那么一帧有多长呢?帧长要满足两个条件:
- 从宏观上看,它必须足够短来保证帧内信号是平稳的。口型的变化是导致信号不平稳的原因,所以在一帧的期间内口型不能有明显变化,即一帧的长度应当小于一个音素的长度。正常语速下,音素的持续时间大约是 50~200 毫秒,所以帧长一般取为小于 50 毫秒。
- 从微观上来看,它又必须包括足够多的振动周期,因为傅里叶变换是要分析频率的,只有重复足够多次才能分析频率。语音的基频,男声在 100 赫兹左右,女声在 200 赫兹左右,换算成周期就是 10 毫秒和 5 毫秒。既然一帧要包含多个周期,所以一般取至少 20 毫秒。
这样,我们就知道了帧长一般取为 20 ~ 50 毫秒,20、25、30、40、50 都是比较常用的数值
取出来的一帧信号,在做傅里叶变换之前,要先进行「加窗」的操作,即与一个「窗函数」相乘,如下图所示:

加窗的目的是让一帧信号的幅度在两端渐变到 0。渐变对傅里叶变换有好处,可以让频谱上的各个峰更细,不容易糊在一起(术语叫做减轻频谱泄漏)。
加窗的代价是一帧信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移,常见的取法是取为帧长的一半,或者固定取为 10 毫秒。

c) Mel滤波
频率的单位是HZ,人耳能听到的频率范围是20-20000HZ,但是人耳对HZ单位不是线性敏感,而是对低HZ敏感,对高HZ不敏感,将HZ频率转化为梅尔频率,则人耳对频率的感知度就变为线性。变换公式如下:


上图是HZ到Mel的映射关系图,由于二者为log关系,在频率较低时,Mel随HZ变化较快;当频率较高时,曲线斜率小,变化缓慢。
常见的语音特征参数
语音信号具有以下几个显著特点:
- 带宽:语音信号的带宽大约为 5 kHz,能量主要集中在较低的频率范围内。
- 非平稳性:语音信号属于非平稳时变信号,但在短时间内(10ms - 30ms)的窗口内,可以被认为是短时平稳的。
- 音质分类:
- 浊音:发声时声带振动,语音信号在时域上呈现周期性特征。
- 清音:发声时声带不振动,语音信号没有明显周期性。
- 区别:
- 浊音的短时能量大、短时平均幅度大、短时过零率低。
- 清音的短时能量小、短时平均幅度小、短时过零率高。
浊音的周期性表现为基音频率,而基音周期的估计也被称为基音检测。
由于语音信号复杂,直接将其输入到神经网络中进行处理效率低下,因此常需要提取以下特征参数:
1.短时过零率
即一帧语音信号波形穿过横轴的次数。一般,高频语音过零率较高,低频语音过零率较低,故短时过零率是区分清音(多数能量集中在高频)和浊音(多数能量集中在低频)的有效参数。

xn(m)表示短帧信号,N NN表示帧长,sgn [ ∙ ] 表示符号函数。
某两帧的过零率如下所示:

因此由上图可知,第834帧语音信号为浊音(过零率低),第828帧语音信号为清音(清音)。
2.短时平均幅度
短时平均幅度是用来表示语音信号在某个短时间段内的能量大小的特征。因为语音信号的能量会随着时间的变化而波动,短时平均幅度通过在每一帧内对信号的绝对值求和,来反映该帧的平均能量。
语音信号是动态的,信号强弱随时间波动。为了在不同时刻跟踪信号的能量变化,我们可以将信号切成短时的片段(即分帧),然后分别计算每个片段的平均能量。这样就可以有效捕捉到信号的动态变化。
包络指的是信号幅度随时间变化的趋势,短时平均幅度的曲线形状与原始语音信号的包络非常相似。短时平均幅度也能反映出这种趋势,因此二者的形状大体一致。
短时平均幅度可以帮助区分语音和噪音,尤其是在**语音活动检测(VAD)**中,判断某段信号是否包含语音。例如,当短时平均幅度大时,通常意味着信号中有语音,而当幅度较小时,则可能是静音或噪音。

3.基因周期
发浊音时,声带振动语音信号在时域上有明显的周期性,声带振动频率称作基音频率,相应的周期称为基因周期,这一参数广泛被用在语音识别、说话人确认、语音合成,男女生辨别等领域。
- 基于事件检测方法,主要是通过对声门闭合时刻进行定位来估计基音周期,主要有小波变换法和希尔伯特变换法。
- 非基于事件的检测法,主要利用语音的短时平稳性,将语音分为短时语音段,然后对每一段进行求解。主要方法有:自相关函数法、平均幅度差函数法和倒谱法。
补充: 男性的基音频率较低,其范围大概为70Hz-200Hz之间,说话人为女性的基音频率大概再200-450Hz之间。
4.共振峰频率
人体说话时声带振动,产生准周期脉冲激励,当激励进入声道时,受声道模型的影响,会引起共振,产生一组共振频率,称作共振峰频率。目前,共振峰的常用检测方法有倒谱法、线性预测法。
5.梅尔倒谱系数(MFFCC)
梅尔频谱是语音信号经过傅里叶变换后,按梅尔尺度重新分布频率成分而得到的频谱。它将频率变换为人耳听觉感知的频率尺度。
特点:
- 梅尔频谱强调人类更敏感的低频部分,降低了对高频部分的敏感度。
- 它通过梅尔滤波器组对普通频谱进行加权变换得到。
- 梅尔频谱作为频谱表示的一种,保留了频率成分,但已经适配了人耳的听觉特性。
用途:
- 可用于分析语音的频率成分,更符合人耳的感知。
见上文
梅尔倒谱系数MFCC 是语音特征提取的常用方法。它通过对梅尔频谱取对数并做离散余弦变换(DCT)得到倒谱系数,表示语音信号中的主要频率信息。
步骤:
- 对语音信号做短时傅里叶变换(STFT)得到频谱。
- 使用梅尔滤波器组将频谱转换为梅尔频谱。
- 对梅尔频谱取对数,压缩动态范围。
- 对对数梅尔频谱进行离散余弦变换(DCT),得到一系列倒谱系数。
特点:
- MFCC 是离散的频率表示,更适合用于机器学习模型。
- 它能有效表示语音信号的频谱特征,且维度较低,便于输入深度学习模型。
用途:
- 语音识别、说话人识别、情感识别等任务中广泛使用,是深度学习领域中最常用的语音特征提取方法之一。(更好地模拟了人耳对语音的感知方式,能够更有效地捕捉人类声音的频率信息,尤其是低频部分的细节。这对于语音识别、说话人识别和情感识别等任务至关重要,因为这些任务依赖于音高、声纹、情感语调等与频率相关的特征。)
import librosa
Mel_M = librosa.feature.mfcc(wav,sr=44100,n_mfcc=20)
# -- Mel spectrogram and MFCCs -- #
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, **kwargs):
if S is None:
S = logamplitude(melspectrogram(y=y, sr=sr, **kwargs))
return np.dot(filters.dct(n_mfcc, S.shape[0]), S)
2、神经网络(Neural Networks)
1. 神经网络(Neural Networks)
神经网络是模仿人脑神经元连接方式的一种机器学习模型。它由多个层级的节点(也叫做“神经元”或“单元”)构成,其中每个节点接受输入并通过非线性激活函数生成输出。神经网络的核心思想是通过层与层之间的加权连接实现输入与输出的复杂映射,并通过大量训练数据不断调整这些权重,从而使模型能够学习数据中的模式和规律。

基本结构:
- 输入层:接受外部数据输入。
- 隐藏层:在输入层和输出层之间,负责数据的特征提取和复杂处理。
- 输出层:生成最终预测结果。

正向传播:
正向传播是神经网络训练过程中计算输出的一种方式。它的过程如下:
-
输入层接收输入数据,将数据传递给第一层隐藏层。
-
每个神经元计算输入的加权和,并通过激活函数进行处理。

-
将经过激活函数处理的输出传递到下一层,直到达到输出层。
在输出层,通常根据具体的任务选择相应的激活函数。例如,在二分类问题中,常使用 Sigmoid 函数来生成预测概率。
反向传播:
反向传播是训练神经网络的关键算法,它用于更新权重和偏置,以最小化预测误差。反向传播的步骤如下:
-
计算损失:通过损失函数计算网络输出与实际目标之间的误差。常用的损失函数有均方误差(MSE)和交叉熵损失等。
-
计算梯度:使用链式法则计算损失函数相对于每一层权重的梯度。梯度指示了损失函数对权重的变化率,帮助优化网络。
-
更新权重:根据计算出的梯度更新权重和偏置。常用的更新规则是梯度下降(或其变体,如 Adam 算法)。

-
重复:通过多次迭代(多个训练周期),反向传播不断优化网络权重,减少预测误差。
2. 深度神经网络(Deep Neural Networks, DNN)
深度神经网络是神经网络的扩展版本,其关键特征是多层隐藏层的存在。相比传统的浅层神经网络(仅包含1-2层隐藏层),DNN 具有多层结构(通常超过3层),因此它能够提取更加复杂的特征,并适应更复杂的任务。
DNN 是现代深度学习的核心模型之一,常用于图像识别、语音识别、自然语言处理等任务。DNN 通过**反向传播算法(Backpropagation)**来调整每一层之间的权重,逐步优化模型。
特点:
- 能处理非线性、复杂的数据模式。
- 深层次的结构使其能够自动学习数据的多级特征。
- 通常需要大量的数据和计算资源来进行有效训练。

3. 卷积神经网络(Convolutional Neural Networks, CNN)
卷积神经网络是一种专门用于处理图像数据的神经网络,它通过引入卷积层和池化层来提取数据中的局部空间特征。
CNN的主要结构组件:
- 卷积层(Convolutional Layer):通过卷积核(滤波器)在输入数据上滑动,提取局部特征,如图像中的边缘、角点等。
- 池化层(Pooling Layer):对特征图进行下采样,减少数据维度,减轻模型计算负担,同时保持重要特征。
- 全连接层(Fully Connected Layer):类似于传统神经网络的隐藏层,连接所有输入节点并进行特征的整合。
特点:
- CNN 擅长处理具有空间或局部关联的数据,尤其是图像和视频等。
- 它通过卷积操作减少参数数量,提升模型的计算效率。
- 常见的应用包括图像分类、目标检测、图像分割等。
4. 循环神经网络(Recurrent Neural Networks, RNN)
循环神经网络是一种擅长处理序列数据的神经网络,它的关键特性在于网络的记忆能力。RNN 的隐藏层不仅依赖当前输入,还依赖前一时刻的输出,因此可以捕捉到输入数据的时间依赖性。这使得 RNN 能够处理时间序列、语音、文本等顺序性很强的数据。
RNN的工作原理:
- 循环连接:RNN 中的隐藏层节点存在自反馈环,允许前一时刻的信息传递到下一时刻,从而保留历史信息。
- 时序依赖:RNN 能够对输入的序列进行逐步处理,并记住先前的数据状态,适合解决时间依赖或有顺序要求的任务。
问题与扩展:
- RNN 在处理长序列时,容易出现梯度消失或爆炸问题,这限制了其对长期依赖的学习能力。
- 为了解决这一问题,出现了改进版的网络结构,如 LSTM(长短期记忆网络) 和 GRU(门控循环单元),它们能够更好地捕捉长序列中的长期依赖信息。
应用场景:
- 自然语言处理(NLP):如机器翻译、情感分析、文本生成等。
- 语音识别:识别并处理语音中的时间依赖性。
- 时间序列预测:用于金融、气象等领域的时间数据预测。
总结
- 神经网络(Neural Networks) 是机器学习的基础模型,模拟人脑神经元的工作原理。
- DNN 是神经网络的深层次扩展,适合处理复杂、非线性的数据模式,广泛应用于图像识别、语音识别等任务。
- CNN 是处理图像等空间数据的神经网络,通过卷积和池化操作提取局部特征,减少参数,具有高效性。
- RNN 擅长处理序列数据,能够捕捉时间依赖性,常用于自然语言处理、语音识别和时间序列预测等任务。

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









