






基础解释:
python汉译为'蟒蛇',python的拥有者是PSF非盈利组织,旨在保护python语言的开放,开源,发展。python语言是通用、脚本、跨平台、多模型语言。python具有两种模式的编程方式,分别是交互式,和文件式。
开发环境配置:
自动配置环境:
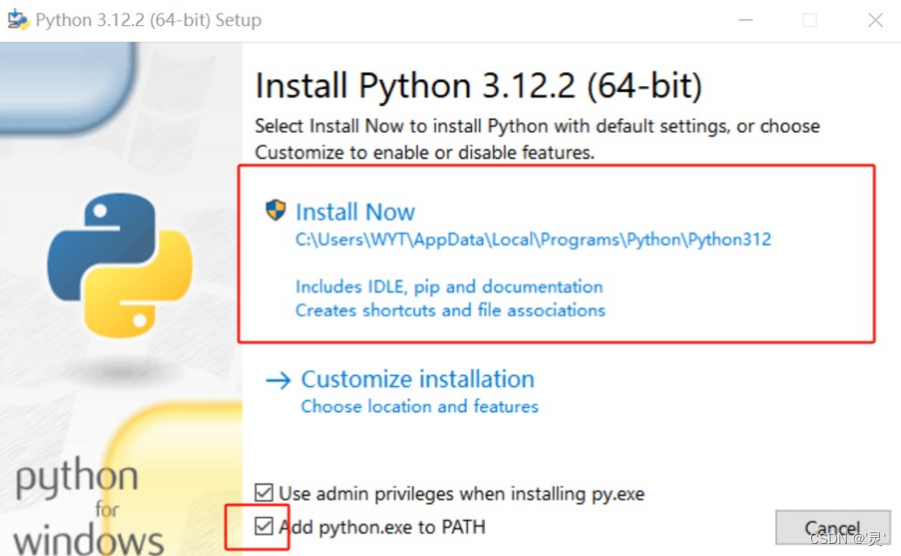
python的运行方式:

python的基础语法:
python语言允许采用字母大、小写,数字,下划线(_),汉字等字符的组合来为变量命名,给变量命名时首字符不能为数字,中间不能有空格,长度不限(但一般不建议取太长),还有命名的变量名不能与保留字相同。
python的常用保留字如下:
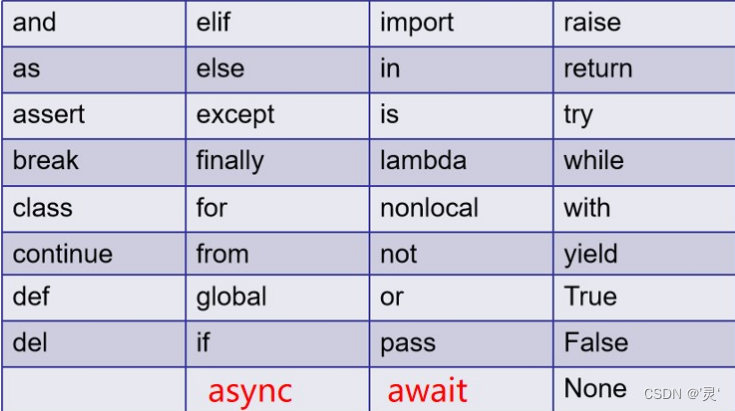
介绍几个有意思的保留字:
assert:用于进行断言测试。当你使用assert语句时,你是在告诉Python解释器,如果某个条件不为真,即条件评估结果为False,那么就触发一个AssertionError异常。
x=10
assert x<0 #x小于零
# 这个 assert 语句会触发 AssertionError,因为 y > 0 是假的。
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
assert x<0
AssertionError
raise:用于抛出一个异常(用于处理异常)。当你遇到一个错误或某些不可能的情况时,你可以使用raise来立即停止程序的执行并抛出一个异常。
x = 0
if x == 0:
raise ValueError("x 不能为 0")
# 这个 raise 语句会抛出一个 ValueError 异常,并附带信息 "x 不能为 0"。
nonlocal:用于在嵌套函数中声明一个变量,表明该变量不是局部变量,也不是全局变量,而是属于更高的嵌套级别的外围作用域。这在外围函数中定义了一个变量,并在内部函数中修改它时非常有用,而不是修改全局变量或创建一个局部副本。
def outer_function(value):
def inner_function():
nonlocal value # 声明变量 value 是非局部的
value += 1
print(value)
inner_function()
outer_function(1) # 输出:2
outer_function(3) # 输出:4
async:用于声明一个异步函数。异步函数是一种特殊类型的函数,允许你编写非阻塞的代码,这意味着函数在等待某些操作完成(例如,I/O操作)时,可以返回一个Task对象,而不是阻塞程序的执行。这样可以提高程序的效率,特别是在处理I/O密集型任务或者需要与多个服务并发交互的情况下。
await:用于在异步函数中挂起(暂停)当前任务的执行,直到另一个协程(coroutine)完成执行。使用await关键字可以让你在异步代码中执行阻塞操作(如I/O等待)而不阻塞整个事件循环。
import asyncio
import time
async def say_after(delay, what):
# 挂起执行指定的延迟时间
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
# 创建两个 say_after 任务的实例,并等待它们完成
task1 = asyncio.create_task(say_after(1, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
# 等待所有任务完成
await task1
await task2
print(f"finished at {time.strftime('%X')}")
# 运行异步主函数
asyncio.run(main())
yield:用于在生成器函数中创建一个迭代器。生成器函数是一个特殊类型的函数,它允许你在每次迭代时按需生成值,而不是一次性生成所有值。这种行为使得生成器函数非常适合处理大数据集或者需要节省内存的情况。
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# 使用生成器
f = fibonacci()
for i in range(10):
print(next(f))
lambda:用于定义匿名函数。匿名函数是一种没有名字的函数,它允许你快速定义一个简短的、一次性使用的函数。匿名函数主要适用于需要一个函数对象但操作简单的场合,如数据排序或过滤。
asd =lambda i=3:i*i
print(asd())
数据类型介绍:
字符串:由一对单引号(' '),或一对双引号(" ")括起来的单个或多个字符。字符串有正反两种序号体系
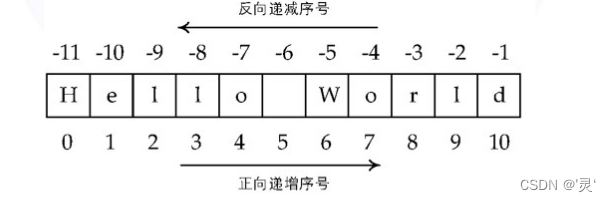
用三对单引号来标识多行注释(''' '''),或用#字符来表示单行注释
python的输入输出语句:input(),input()默认输入的是字符串,输出语句是print()可以输出各种类型的值
字符串常用函数:



温度转换的例子:
#python语言中没用语句分块的括号,只有缩进(一个tab键,相当于四个空格)
t=input() #输入带符号的的温度值
if t[-1] in ['c','C']: #判断是那种类型的温度值
f=1.8*eval(t[0:-1])+32 #eval()函数会在执行时去掉最外层的引号,执行剩下的语句
print("{:.2f}F".format(f)) #保留两位小数输出
elif t[-1] in ['F','f']:
c=(eval(t[0:-1])-32)/1.8
print("{:.2f}C".format(c))
else:
print("错误")
python包括三种数字类型:整数,浮点数,复数类型

程序分支语句:
单分支:单分支结构使用if保留字对条件进行判断,
格式:if <条件>: 语句块
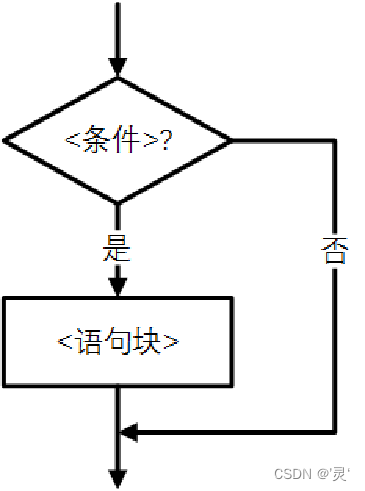

二分支:if-else语句用来形成二分支结构,语法格式如下:
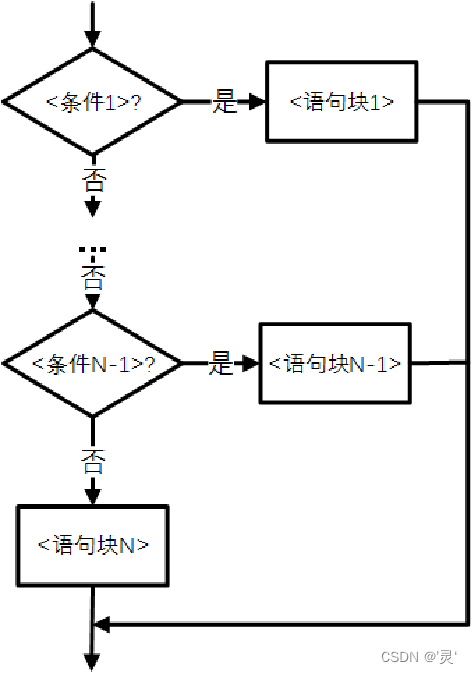
if <条件>:
<语句块1>
else:
<语句块2>
多分支语句:if-elif-else语句(多分支结构通常用于判断同一个条件或一类条件的多个执行路径)
循环语句
循环遍历:遍历循环可以理解为从遍历结构中逐一提取元素,放在循环变量中,对于每个所提取的元素执行一次语句块。for语句的循环执行次数是根据遍历结构中元素个数确定的。
for <循环变量> in <遍历结构>:
<语句块>
例1:输入一个数n,判断区间[2,n)的所有数是否为质数。
n=eval(input())
for i in range(2,n):
for j in range(2,i):
if i%j==0:
print(i,"不是质数")
break
else:
print(i,'是质数')
异常处理:
Python使用try…except…来进行异常处理,基本格式如下:
try :
<语句块1>
except <异常类型> :
<语句块2>
'''如果没有错误,控制跳转到try-except后面的语句 如果发生错误,Python解释器会寻找异常类型相同的except异常语句,然后执行except后面的代码,标注异常类型后,仅响应此类异常'''
简单例子:

函数及其参数处理
Python定义一个函数使用def保留字,语法形式如下:
def 函数名(参数列表):
函数体
return 返回值列表
函数名可以是任何有效的Python标识符 参数列表是调用该函数时传递给它的值,可以有零个、一个或多个,当传递多个参数时各参数由逗号分隔,当没有参数时也要保留圆括号。 函数体是函数每次被调用时执行的代码,由一行或多行语句组成。 return 结束函数,返回值给调用函数的地方。不带表达式的return相当于返回 None。
函数的参数传递 当函数的定义中存在多个参数时,其参数的传递形式主要有以下5种:
位置传递 :位置固定,参数传递按照形式参数定义的顺序提供实际参数。其优点是使用方便,缺点是当参数数目较多时,函数调用容易混淆。

关键字传递 :使用名称参数调用时,可以任意调换参数传参的位置。
还可以使用位置参数和名称参数混合传参的方式。但混合传参时关键字参数必须位于所有的位置参数之后。

在函数定义时,单独一个星号*之后的所有参数都只能以关键参数的形式进行传值,不接收其他任何形式的传值。

默认值传递 :函数的参数在定义时可以指定默认值,当函数被调用时,如果没有传入对应的参数值,则使用函数定义时的默认值替代,函数定义时的语法形式如下:
def <函数名>(<非可选参数列表>, <可选参数> = <默认值>):
<函数体>
return <返回值列表>


包裹传递(引用传递) :函数定义时可以设计可变数量参数,既不确定参数总数量,通过参数前增加星号(*)实现( *parameter ),对于可变类型(如列表、字典),则是按引用传递的。

解包裹传递 :函数定义时可以设计多个关键字参数,这些关键字参数在函数内部自动组装为一个dict( **paramater ),[字典,列表,元组等]
解包字典
def unpack_dict(dct):
# 将字典中的键值对解包并赋值给多个变量
a, b = dct['key1'], dct['key2']
print(a, b)
my_dict = {'key1': 10, 'key2': 20}
unpack_dict(my_dict) # 输出:10 20
解包多个变量
def unpack_multiple(*args, **kwargs):
# 解包位置参数
print(args)
# 解包关键字参数
print(kwargs)
unpack_multiple(1, 2, 3, key1='value1', key2='value2')
# 输出:
# (1, 2, 3)
# {'key1': 'value1', 'key2': 'value2'}
python的高阶函数:
map:map 是一个在 Python 里非常有用的高阶函数。它接受一个函数和一个序列(迭代器)作为输入,然后对序列(迭代器)的每一个值应用这个函数,返回一个序列(迭代器),其包含应用函数后的结果。
sorted:sorted()函数就可以对list进行排序, sorted()函数也是一个高阶函数,它可以接收一个key函数来实现自定义的排序
例子:将字符串'716598465982456',转为列表
s=input()
li=list(map(int,s)) #用map函数将字符串转为列表
li=sorted(li) #利用sorted()函数将li列表排序
print(li)
组合数据类型
组合数据类型:通过组合将多个同类型数据或不同数组类型组合在一起,是数据更加有序。
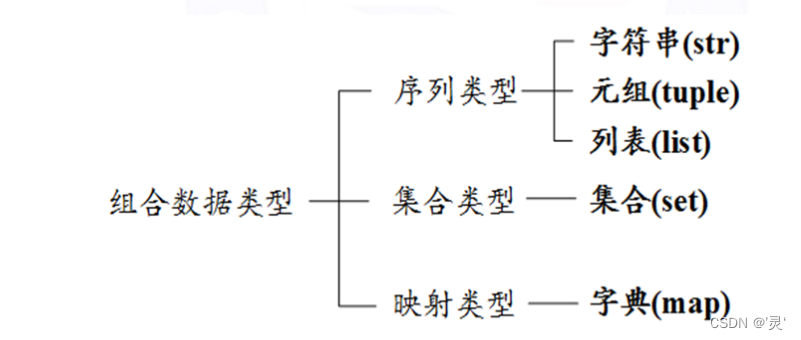
元组数据类型:元组中的数据类型可以是不同数据类型的,定义后不可修改,存在先后顺序,可以通过索引的方式访问元组中的元素,使用小括号()或tuple()创建,可以不使用小括号,元素之间用逗号分隔 元组可以是空的,t2=()
创建空元组
tup1 = ()
不为空的元组
t=(1,2,3,23,'af',23)
列表数据类型:列表中的数据类型可以是不同数据类型的,定义后可以修改,存在先后顺序,可以通过索引的方式访问元组中的元素,使用[]或list()来创建,无长度限制
创建空列表
l=[]
不空列表
l=[1,2,1,3]
列表的操作函数:

集合数据类型:集合是无序组合,用大括号({})表示,它没有索引和位置的概念,集合中元素可以动态增加或删除。集合中元素不可重复,元素类型只能是固定数据类型,例如:整数、浮点数、字符串、元组等。可变数据类型不能作为集合的元素出现。
集合的操作函数
字典类型:字典是实现键值对映射的数据结构; 字典是一个键值对的集合,该集合以键为索引,一个键信息只对应一个值信息; 字典类型使用{}和dict()创建,键值对之间用:分隔; d[key] 方式既可以索引,也可以赋值 字典长度是可变的。
字典中键值对的访问模式如下,采用中括号格式: <值> = <字典变量>[<键>]

字典的操作函数:


例子:
d={1:1.5,2:2.5,3:3.5} #字典
for key in d.keys(): #打印键值
print(key)
for value in d.values(): #打印值
print(value)
for item in d.items(): #以元组的形式打印键值对
print(item)
for key,value in d.items(): #分开打印键值与值
print(key,value)
文件操作:
文件操作步骤:打开-操作-关闭
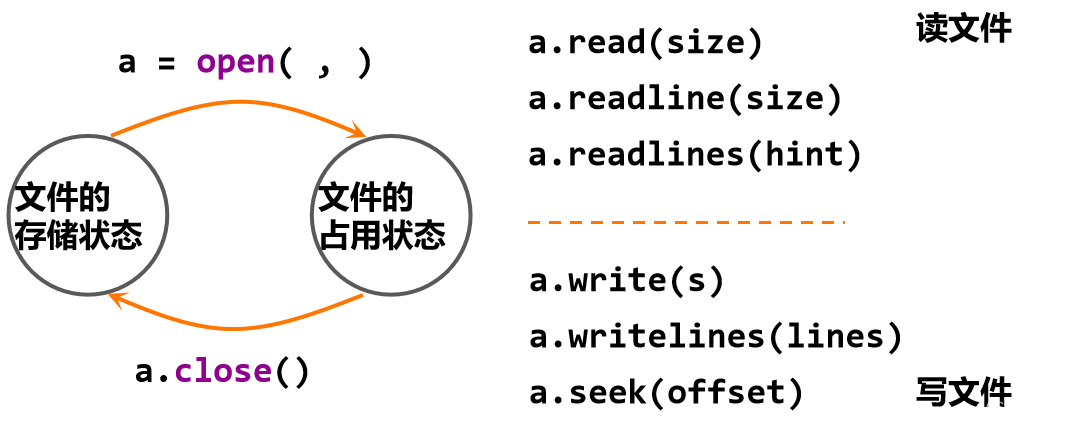
打开方式:
open():file = open(<文件路径+文件名>, <打开模式>)
文件读取:

<变量名>.readlines() 返回文件所有行,以每行为元素形成列表

<变量名>. readline(size = -1) 返回一行内容,如果给出参数,读入该行前size长度

文件路径和名称
绝对路径(由根目录到该文件目录):“D:/PY/f.txt"、"D:\\PYE\\f.txt"
相对路径(由当前目录查询):"./PYE/f.txt" 、"f.txt"
文件遍历-全文遍历:一次读入,全部处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read() #对全文txt进行处理
fo.close()
文件遍历-逐行遍历(分行读入,逐行处理)
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo:
print(line)
fo.close()
文件遍历-逐行遍历(一次读入,逐行处理)
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo.readlines():
print(line)
fo.close()
with open('文件路径','操作方式',)as f :在处理文件对象时,最好使用 with 关键字。优点是,子句体结束后,文件会正确关闭,即便触发异常也可以。 调用 f.write() 时,未使用 with 关键字,或未调用 f.close(),即使程序正常退出,也**可能** 导致 f.write() 的参数没有完全写入磁盘。

文件的写入:
文件写入 file.write(): 把含有文本数据或二进制数据块的字符串或字节流写入文件

file.writelines(): 针对列表操作,接受一个字符串列表作为参数,将它们写入文件

类的定义
类的定义 Python定义一个类使用class保留字,语法形式如下:
class 类名(要继承的类):
类名可以是任何有效的Python标识符 要继承的类是指被定义的类是从哪个类继承下来的,通常如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。

__init__方法 类有一个名为 __init__()的特殊初始化方法,该方法在类实例化时会自动调用,将对象创建为有初始状态,类的实例化操作会自动为新创建的类实例调用 __init__() 方法,只能有一个。

类的实例化:
在类的内部,使用 def 关键字来定义方法,除第一个参数外其他与普通函数是完全一样。 与一般函数定义不同,实例方法必须第一个参数为 self, 用于绑定调用此方法的实例对象,self 代表的是类的实例,实例方法只能被实例对象调用。
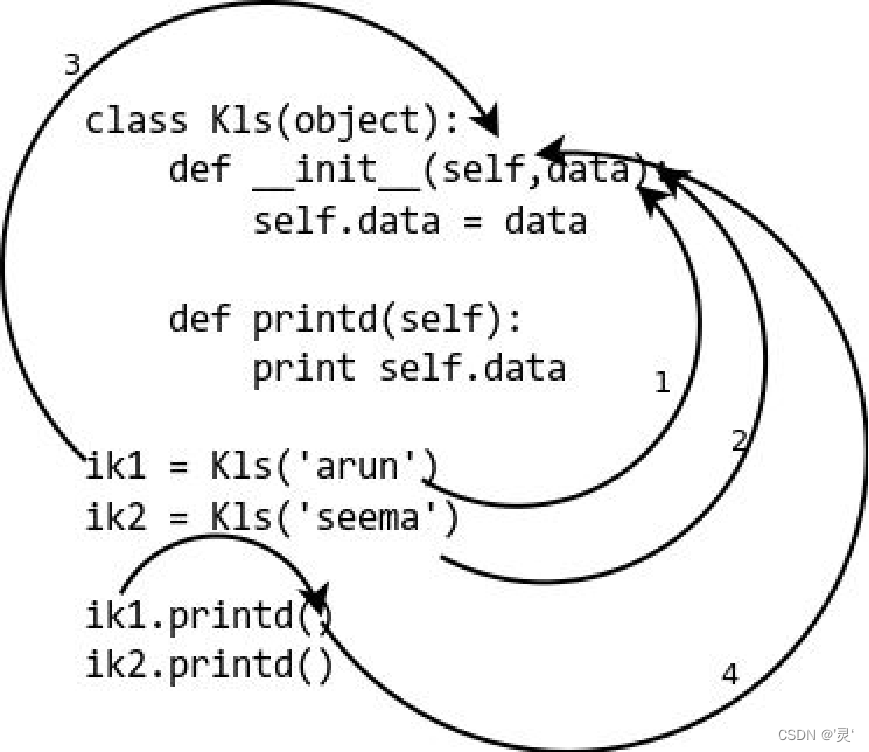
类的方法使用:
类方法 类方法是将类本身作为对象进行操作的方法,不用通过实例化类就能访问,由@classmethod装饰的方法,可以被类或类的实例对象调用。
第一个参数必须要默认传类,一般习惯用cls,Python 会自动将类本身绑定给 cls 参数(注意,绑定的不是类对象)。也就是说,我们在调用类方法时,无需显式为 cls 参数传参。 主要用于和类进行交互,如读取私有化类属性数据、定义多个构造函数等

@property装饰器
@property 装饰器,可以直接通过方法名来访问方法,不需要在方法名后添加一对“()”小括号。 @property 装饰器可以与所定义的属性配合使用,这样可以防止属性被修改。

自定义安装第三方库
安装一个库的命令格式如下
pip install <拟安装库名>
下载(download)
卸载(uninstall)
列表(list)
查看(list)
查找(search)等一系列安装和维护子命令。
eg:pip install jieba
库的使用(以jieba库为例)


















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









