






一、贝叶斯决策的原理和基本概念
1、贝叶斯决策的原理
在类条件概率密度和先验概率已知(或可以估计)的情况下,通过贝叶斯公式比较样本属于两类的后验概率,将类别决策为后验概率大的一类,这样做的目的是为了使总体错误率最小。贝叶斯决策理论也称作统计决策理论。
2、先验概率
理解:
以猜测硬币大小为例子,硬币为x,w1,w2分别表示一毛硬币和五毛硬币,则p(w1)和p(w2)分别表示事件w1和w2的先验概率。
其中:
如果 P(w1)>P(w2),则 x∈w1;反之,则 x∈w2
P(w1) + P(w2) = 1
如果x∈w1,则那么犯错误的概率就是 P(error)=1−P(w1)=P(w2),反之亦然。
3、后验概率
理解:
仍然以猜测硬币大小为例子,在不确定硬币面值的情况下根据硬币的重量下做决策。记硬币的重量为x,对两类硬币分别记做 P(ω1∣x)和 P(ω2∣x),这种概率处称为后验概率(a posterior probability)。
其中:
如果 P(w1∣x)>P(w2∣x),则 x∈w1;反之,则 x∈w2
P(w1∣x) + P(w2∣x) = 1
如果x∈w1,则那么犯错误的概率就是 P(error)=1−P(w1∣x)=P(w2∣x),反之亦然。
4、基于贝叶斯公式的后验概率
根据概率论中的贝叶斯公式(Bayes'formula 或 Bayesian Theorem),有
P(ωi∣x)=p(x,ωi)p(x)=p(x∣ωi)p(ωi)p(x),i=1,2
其中,P(ωi)是先验概率;P(x,ωi)是 x与 ωi的联合概率密度;p(x)是两类所有硬币重量的概率密度,称为总体密度;p(x∣ωi)是第 i类硬币重量的概率密度,称为类条件密度。
5.条件概率
假设有A,B两个事件,在B事件发生的条件下,A事件发生的概率。
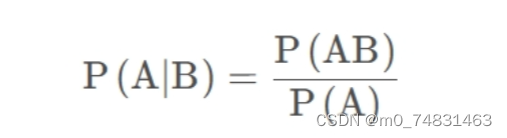
6.全概率公式
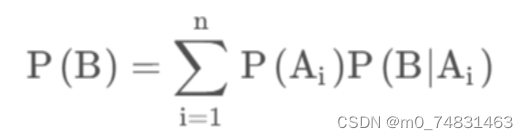
公式表示若事件A1,A2,…,An构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立。
7.贝叶斯公式
在事件A发生的条件下,考察每种情况出现的条件概率。其中样本空间由A和A’组成。
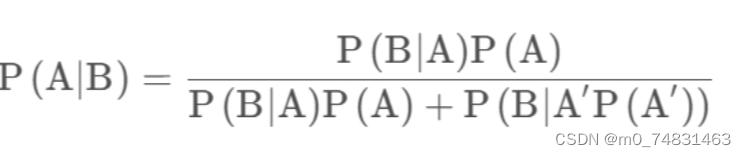
二、贝叶斯算法的实例
假设我们有一个西瓜数据集,其中包括以下特征:色泽、根蒂、敲声和好坏(1表示好瓜,0表示坏瓜)。
我们可以根据这些特征来训练一个朴素贝叶斯分类器,并使用它来预测新的西瓜的好坏。
以下是示例代码:
import numpy as np
# 训练数据集
data = [['青绿', '蜷缩', '浊响', 1],
['乌黑', '蜷缩', '沉闷', 1],
['乌黑', '蜷缩', '浊响', 1],
['青绿', '稍蜷', '浊响', 1],
['浅白', '稍蜷', '浊响', 1],
['浅白', '硬挺', '清脆', 0],
['乌黑', '稍蜷', '沉闷', 0],
['浅白', '稍蜷', '沉闷', 0],
['青绿', '硬挺', '清脆', 0],
['浅白', '蜷缩', '浊响', 0]]
# 特征名称
features_name = ['色泽', '根蒂', '敲声']
# 将特征值转化为数值
def convert_feature_to_num(feature_list):
feature_set = set(feature_list)
feature_dict = {}
for i, feature in enumerate(feature_set):
feature_dict[feature] = i
return [feature_dict[feature] for feature in feature_list]
# 将训练数据集转化为数组
data_array = np.array([convert_feature_to_num(d[:-1]) + [d[-1]] for d in data])
# 好瓜数量和坏瓜数量
good_count = np.sum(data_array[:, -1] == 1)
bad_count = np.sum(data_array[:, -1] == 0)
# 计算每个特征每个取值下好瓜的概率和坏瓜的概率
prob_good_given_feature_value = np.zeros((len(features_name), max([len(set(data_array[:, i])) for i in range(len(features_name))]), 2))
prob_bad_given_feature_value = np.zeros((len(features_name), max([len(set(data_array[:, i])) for i in range(len(features_name))]), 2))
for i, feature_name in enumerate(features_name):
feature_values = set(data_array[:, i])
for feature_value in feature_values:
good_given_feature_value = np.sum((data_array[:, i] == feature_value) & (data_array[:, -1] == 1))
bad_given_feature_value = np.sum((data_array[:, i] == feature_value) & (data_array[:, -1] == 0))
prob_good_given_feature_value[i, feature_value, :] = [(good_given_feature_value + 1) / (good_count + len(feature_values)), (bad_given_feature_value + 1) / (bad_count + len(feature_values))]
prob_bad_given_feature_value[i, feature_value, :] = [(bad_given_feature_value + 1) / (bad_count + len(feature_values)), (good_given_feature_value + 1) / (good_count + len(feature_values))]
# 测试数据集
test_data = ['青绿', '稍蜷', '浊响']
# 将测试数据集转化为数组
test_data_array = np.array(convert_feature_to_num(test_data))
# 计算好瓜概率和坏瓜概率
prob_good = good_count / len(data_array)
prob_bad = bad_count / len(data_array)
for i, feature_value in enumerate(test_data_array):
prob_good *= prob_good_given_feature_value[i, feature_value, 0]
prob_bad *= prob_bad_given_feature_value[i, feature_value, 0]
# 根据概率比较判断好瓜或坏瓜
if prob_good > prob_bad:
print('好瓜')
else:
print('坏瓜')
根据我们自定义的测试数据集

得到的运行结果为:

算法思想:
good_count和bad_count分别计算出训练数据中好瓜和坏瓜的数量。prob_good_given_feature_value和prob_bad_given_feature_value将分别存储每个特征值下好瓜和坏瓜的概率。- 对于测试数据
['青绿', '稍蜷', '浊响'],代码将计算它是好瓜和坏瓜的概率,并比较这两个概率。















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









