






一、理论知识
1.1概念定义
支持向量机(Support Vector Machine,简称SVM)是一种强大的监督学习算法,广泛用于分类和回归问题。
支持向量机是一种二分类算法,其目标是找到一个最优的超平面,将不同类别的数据点分隔开。这个超平面被称为决策边界,支持向量机的任务是找到使决策边界最佳的超平面。
1.2 svw的特点
- 适用于线性和非线性分类问题。
- 在高维空间中表现出色,适用于处理具有大量特征的数据。
- 通过选择支持向量(距离决策边界最近的数据点)来提高模型的鲁棒性。
1.3 svw的工作原理
svw的几个重要概念:
间隔(Margin):间隔是指决策边界(超平面)与离它最近的数据点之间的距离。SVM的目标是最大化这个间隔,以提高模型的泛化性能。
支持向量(Support Vectors):支持向量是距离决策边界最近的数据点。这些支持向量决定了决策边界的位置和方向。
核函数(Kernel Function):核函数是一种将数据从原始空间映射到更高维空间的技术。这种映射使得原本线性不可分的数据在新的空间中变得线性可分。
正则化参数(Regularization Parameter):正则化参数C是SVM的一个重要超参数。它控制了模型的复杂性和间隔之间的权衡。较小的C值会导致较大的间隔但可能会容忍一些分类错误,而较大的C值会导致更严格的分类但可能会导致过拟合。
1.4 svm实现的步骤
(1)数据准备:首先,需要准备用于训练和测试的数据集。数据要求每个数据点都应该属于一个特定的类别。
(2)定义SVM模型:在PyTorch中,您可以使用线性SVM模型,该模型尝试找到一个线性超平面来分隔不同的类别。模型的定义包括损失函数和正则化参数C的设置。
(3)模型训练:使用训练数据集对SVM模型进行训练。训练过程将自动寻找最佳的超平面。
(4)模型评估:使用测试数据集来评估SVM模型的性能,通常使用准确度等指标来衡量分类性能。
二、实例(乳腺癌检测)
通过svm预测肿瘤是恶心还是良性
2.1实现过程
(1)首先我们先创建一个线性的支持向量机分类器
代码如下:
import numpy as np
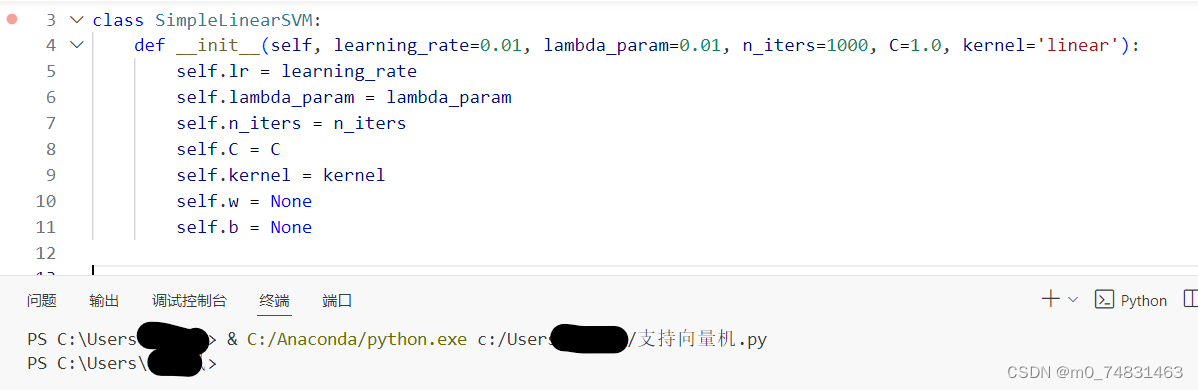
class SimpleLinearSVM:
def __init__(self, learning_rate=0.01, lambda_param=0.01, n_iters=1000, C=1.0, kernel='linear'):
self.lr = learning_rate
self.lambda_param = lambda_param
self.n_iters = n_iters
self.C = C
self.kernel = kernel
self.w = None
self.b = None在SimpleLinearSVM中,我们定义了必要的参数:学习率(learning_rate),用于梯度下降算法中更新权重和偏置的步长;正则化参数(lambda_param),用于防止过拟合; 迭代次数(n_iters); 软间隔参数(c)以及 核函数(kernel)。
(2)接下来我们要实现对数据的归一化
def feature_normalization(self, X):
# 特征归一化
mean = np.mean(X, axis=0)
std = np.std(X, axis=0)
X_normalized = (X - mean) / std
return X_normalized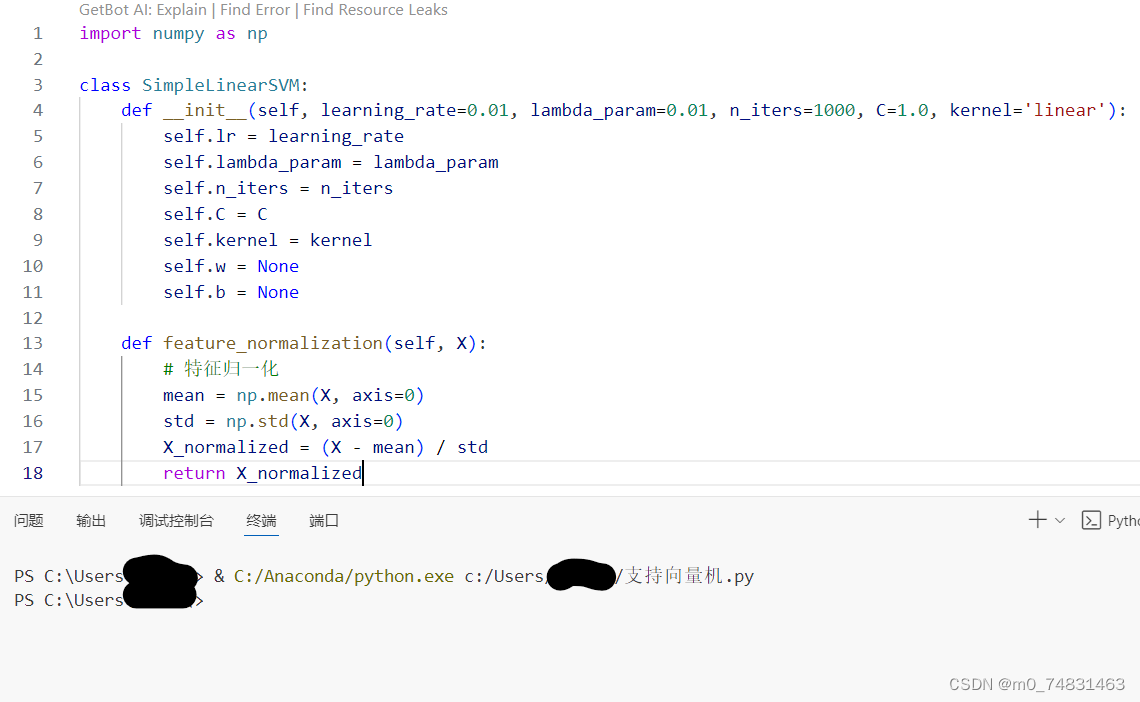
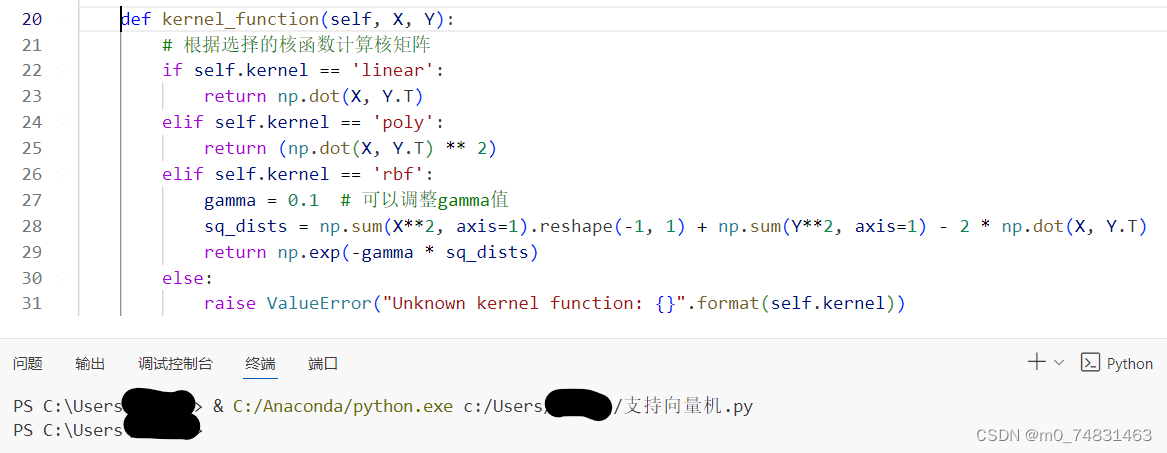
(3)核函数
def kernel_function(self, X, Y):
# 根据选择的核函数计算核矩阵
if self.kernel == 'linear':
return np.dot(X, Y.T)
elif self.kernel == 'poly':
return (np.dot(X, Y.T) ** 2)
elif self.kernel == 'rbf':
gamma = 0.1 # 可以调整gamma值
sq_dists = np.sum(X**2, axis=1).reshape(-1, 1) + np.sum(Y**2, axis=1) - 2 * np.dot(X, Y.T)
return np.exp(-gamma * sq_dists)
else:
raise ValueError("Unknown kernel function: {}".format(self.kernel))核函数用于计算两个矩阵 X 和 Y 之间的核矩阵,核函数在支持向量机中用于将原始特征空间映射到更高维的特征空间,以便能够更好地分离数据。
 (4) 然后我们用fit方法来达成训练线性支持向量机模型,用predict来实现线性输出计算。
(4) 然后我们用fit方法来达成训练线性支持向量机模型,用predict来实现线性输出计算。
def fit(self, X, y):
X_normalized = self.feature_normalization(X)
n_samples, n_features = X_normalized.shape
# 初始化权重和偏置
self.w = np.zeros(n_features)
self.b = 0
# 梯度下降法
for _ in range(self.n_iters):
for idx, x_i in enumerate(X_normalized):
condition = y[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= self.lr * (2 * self.lambda_param * self.w)
else:
self.w -= self.lr * (2 * self.lambda_param * self.w - np.dot(x_i, y[idx]))
self.b -= self.lr * y[idx]
def predict(self, X):
X_normalized = self.feature_normalization(X)
linear_output = np.dot(X_normalized, self.w) - self.b
return np.sign(linear_output)fit方法中,我用到的是梯度下降法循环。这个循环会执行self.n_iters次,每次迭代都会遍历特征矩阵X_normalized中的每个样本 。使得模型学习到能够将不同类别的数据点正确分类的权重和偏置。
(5) 最后我们载入数据,并且创建svm实例,训练svm,预测并输出结果
# 示例数据
X = np.array([[1, 2],
[2, 3],
[3, 4],
[4, 5],
[5, 6],
[6, 7]])
y = np.array([1, 1, 1, -1, -1, -1])
# 创建SVM实例
svm = SimpleLinearSVM(learning_rate=0.001, lambda_param=0.01, n_iters=1000, C=1.0, kernel='rbf')
# 训练SVM
svm.fit(X, y)
# 进行预测
predictions = svm.predict(X)
# 输出预测结果
print(predictions)输出结果:
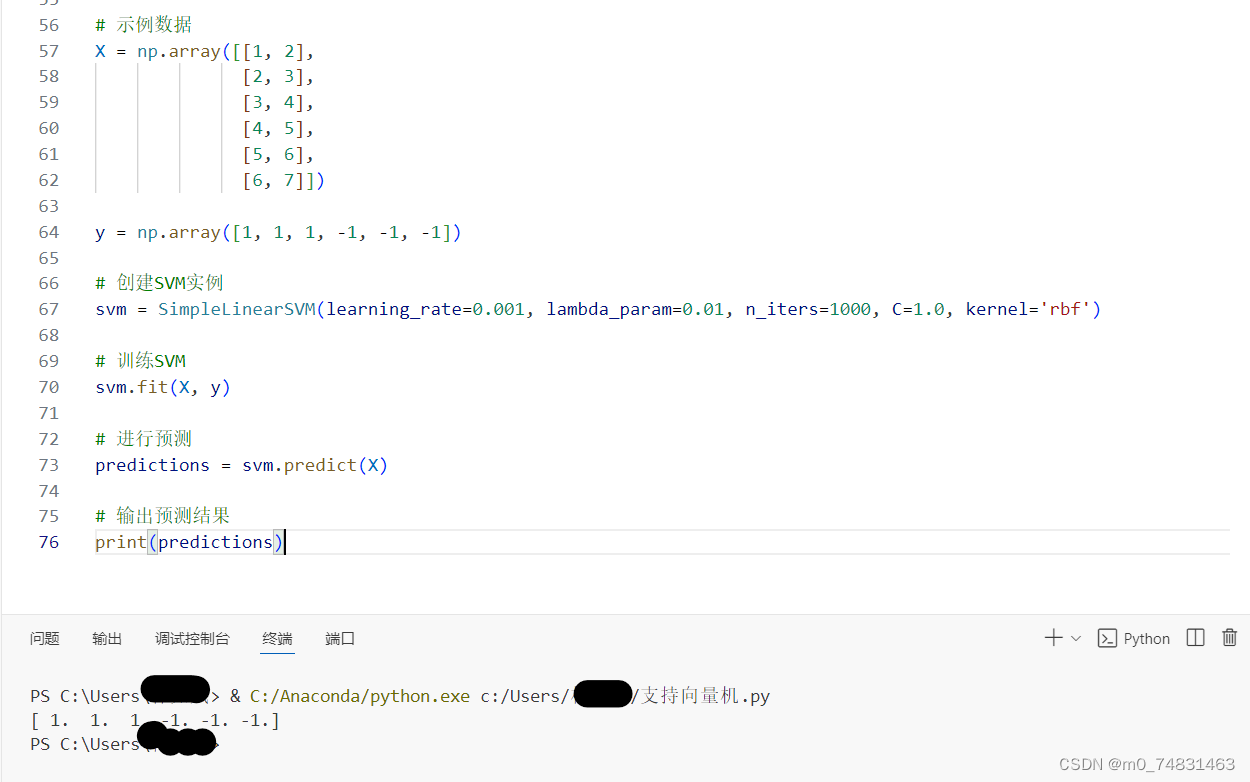
在输出的预测结果中显示,在六个数据样本中,前三个样本是1代表是良性肿瘤,后三个样本是-1代表是恶性肿瘤。
2.2完整代码
import numpy as np
class SimpleLinearSVM:
def __init__(self, learning_rate=0.01, lambda_param=0.01, n_iters=1000, C=1.0, kernel='linear'):
self.lr = learning_rate
self.lambda_param = lambda_param
self.n_iters = n_iters
self.C = C
self.kernel = kernel
self.w = None
self.b = None
def feature_normalization(self, X):
# 特征归一化
mean = np.mean(X, axis=0)
std = np.std(X, axis=0)
X_normalized = (X - mean) / std
return X_normalized
def kernel_function(self, X, Y):
# 根据选择的核函数计算核矩阵
if self.kernel == 'linear':
return np.dot(X, Y.T)
elif self.kernel == 'poly':
return (np.dot(X, Y.T) ** 2)
elif self.kernel == 'rbf':
gamma = 0.1 # 可以调整gamma值
sq_dists = np.sum(X**2, axis=1).reshape(-1, 1) + np.sum(Y**2, axis=1) - 2 * np.dot(X, Y.T)
return np.exp(-gamma * sq_dists)
else:
raise ValueError("Unknown kernel function: {}".format(self.kernel))
def fit(self, X, y):
X_normalized = self.feature_normalization(X)
n_samples, n_features = X_normalized.shape
# 初始化权重和偏置
self.w = np.zeros(n_features)
self.b = 0
# 梯度下降法
for _ in range(self.n_iters):
for idx, x_i in enumerate(X_normalized):
condition = y[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= self.lr * (2 * self.lambda_param * self.w)
else:
self.w -= self.lr * (2 * self.lambda_param * self.w - np.dot(x_i, y[idx]))
self.b -= self.lr * y[idx]
def predict(self, X):
X_normalized = self.feature_normalization(X)
linear_output = np.dot(X_normalized, self.w) - self.b
return np.sign(linear_output)
# 示例数据
X = np.array([[1, 2],
[2, 3],
[3, 4],
[4, 5],
[5, 6],
[6, 7]])
y = np.array([1, 1, 1, -1, -1, -1])
# 创建SVM实例
svm = SimpleLinearSVM(learning_rate=0.001, lambda_param=0.01, n_iters=1000, C=1.0, kernel='rbf')
# 训练SVM
svm.fit(X, y)
# 进行预测
predictions = svm.predict(X)
# 输出预测结果
print(predictions)














 7392
7392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









