






论文链接:https://arxiv.org/abs/2010.11929
论文代码链接:https://github.com/google-research/vision_transformer
GitHub上star比较多的代码(pytorch架构):https://github.com/lucidrains/vit-pytorch
一、ViT网络结构讲解
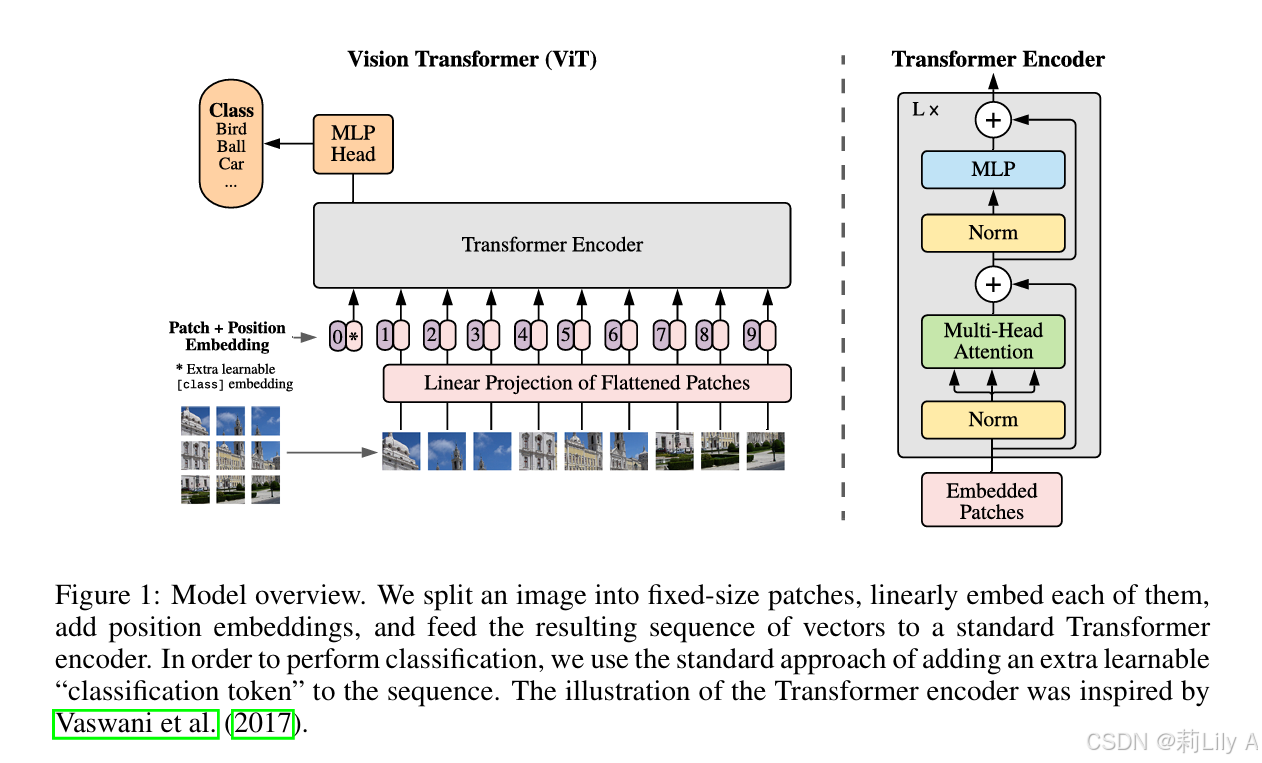
1.Patch embedding
将图形转化为序列化数据
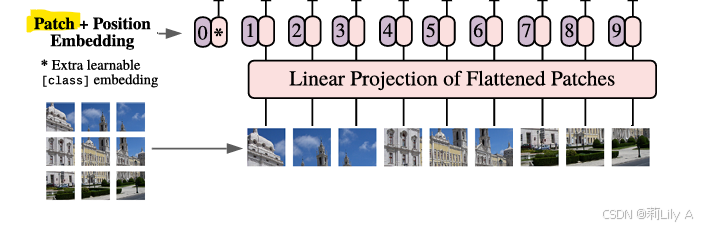
例如输入图片大小为 9 × 9 ,将图片分为固定大小的patch,patch大小为3 × 3 ,则每张图像会生成 9 × 9 / 3 × 3 = 9个patch,即输入序列长度为9,将每个patch重组成一个向量,得到所谓的flattened patch
如果图片是H×W×C维的,就用P×P大小的patch去分割图片可以得到N个patch,那么每个patch的大小就是P×P×C,即一共有N个token,每个token的维度是P×P×C,将N个patch 重组后的向量concat在一起就得到了一个N×P×P×C的二维矩阵,相当于NLP中输入Transformer的词向量。已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
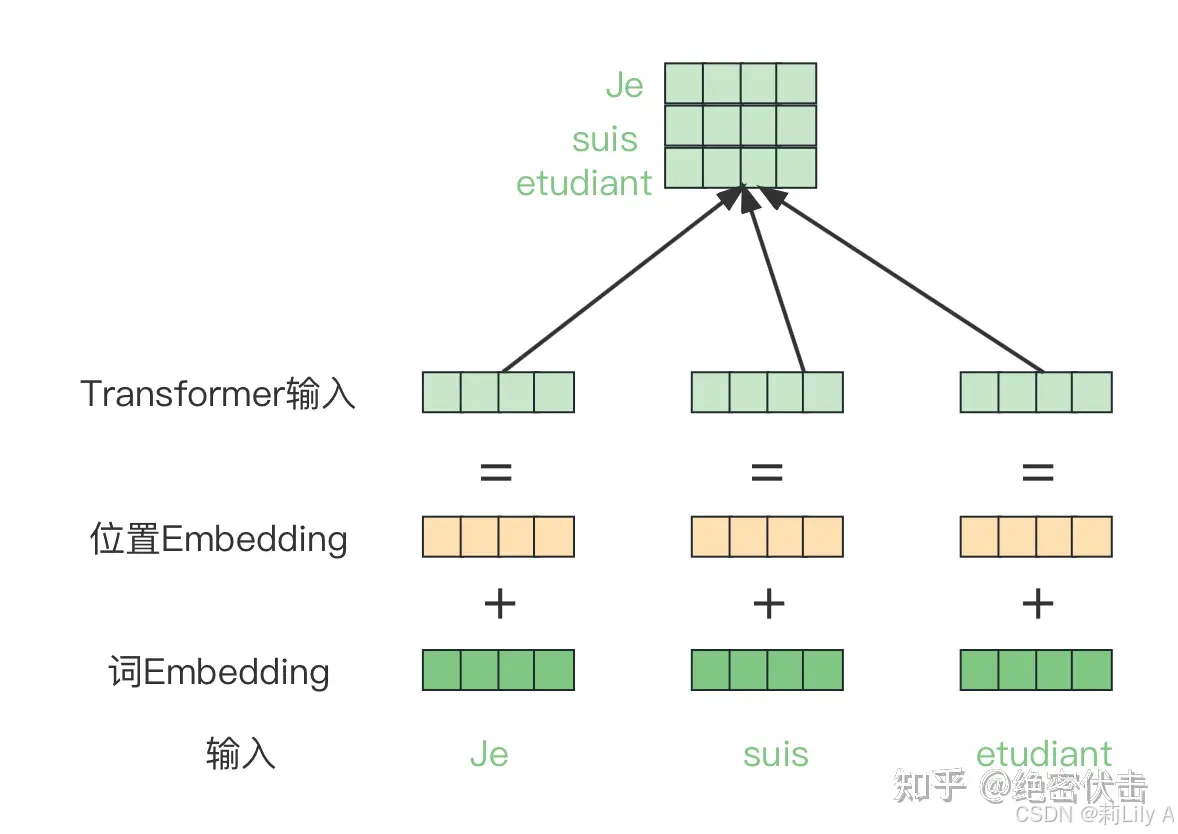
2. Positional encoding
由于Transformer模型本身是没有位置信息的,所以我们需要用position embedding将位置信息加到模型中去。位置编码可以理解为一张表,表一共有N 行,N 的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(P×P×C)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是N×P×P×C
论文中采用将position embedding(即图中紫色框)和patch embedding(即图中粉色框)相加的方式结合position信息。
一文了解Transformer全貌(图解Transformer)可以看下面这个图理解一下
3.Learnable embedding

将 patch 输入一个 Linear Projection of Flattened Patches 这个 Embedding 层,就会得到一个个向量,通常就称作 tokens。tokens包含position信息以及图像信息。
紧接着在一系列 token 的前面加上加上一个新的 token,叫做class token,也就是上图带星号的粉色框(即0号紫色框右边的那个),注意这个不是通过某个patch产生的。其作用类似于BERT中的[class] token。在BERT中,[class] token经过encoder后对应的结果作为整个句子的表示;class token也是其他所有token做全局平均池化,效果一样。[class] token和其他token拼接,维度变成(N+1)×P×P×C
4.Transformer encoder
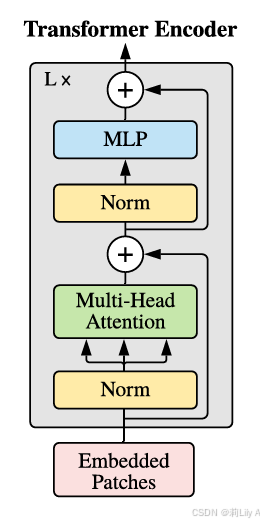
Transformer Encoder结构和NLP中Transformer结构基本上相同,class embedding 对应的输出经过 MLP Head 进行类别判断。
二、代码
https://github.com/lucidrains/vit-pytorch
ViT网络结构
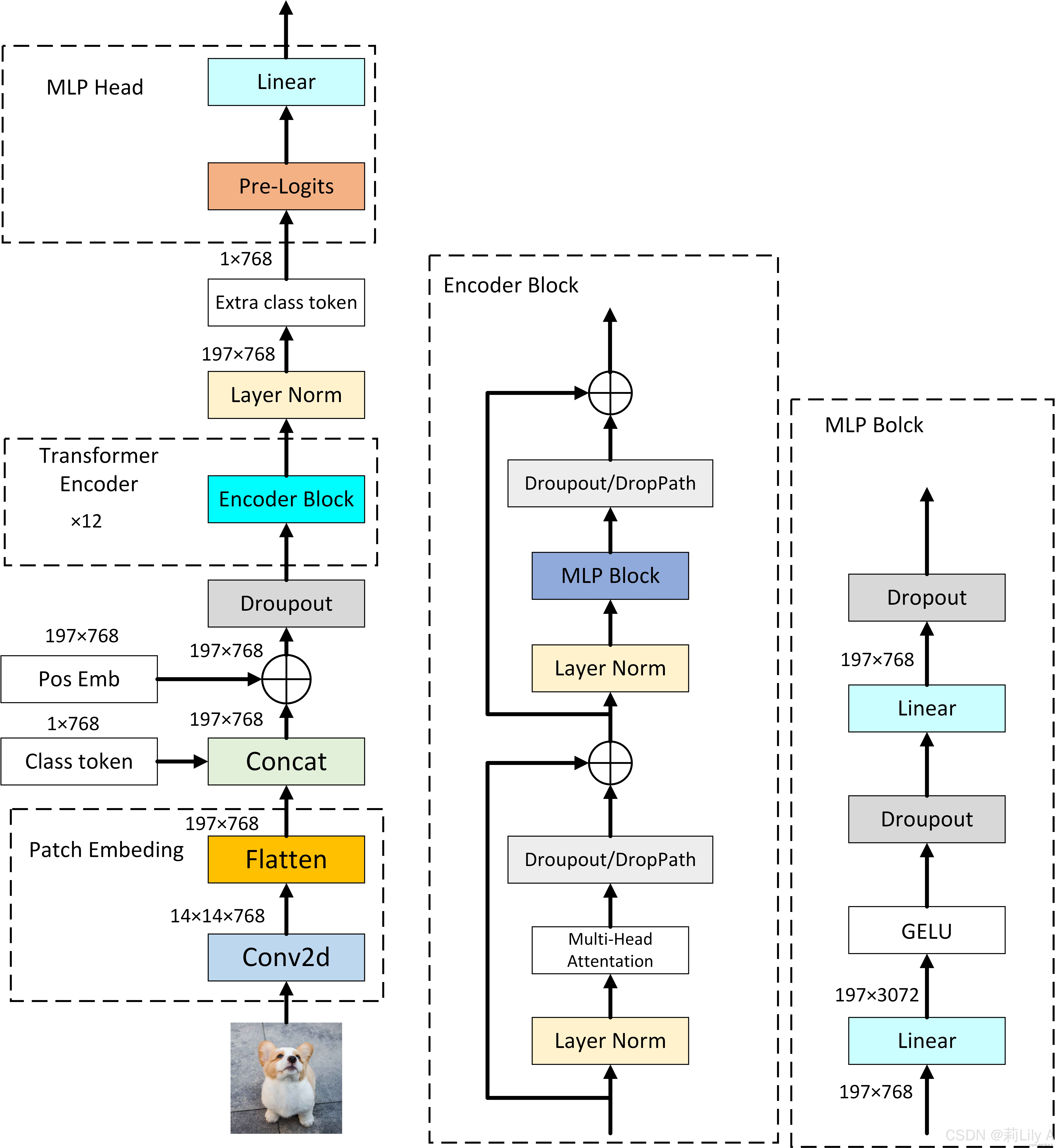
但我感觉这个图有个地方有点问题,flatten那里应该是196×768,cat之后才是197×768吧
求大佬解答!!
1.搭建虚拟环境(anaconda)并安装依赖项
【Anaconda 虚拟环境搭建----最适合新手的详细教程】_anaconda创建虚拟环境-CSDN博客
创建新环境
conda create -n vit_pytorch python=3.9
打开cmd界面,cd进入setup.py的文件夹内,进入环境vit_pytorch
conda activate vit_pytorch依次输入
python setup.py build
python setup.py install解释一下setup.py这个文件
之前跑过几个简单的小模型,都是跟着别人的视频运行的,配置环境安装依赖的时候都是用pip install -r requirements.txt,但这次这个没找到txt文件,点进setup.py一看,哟,好眼熟啊,需要哪些库都写得明明白白,但为什么这么做,我也不太明白。在知乎上看到一篇文章,大家可以参考一下。python安装带有setup.py的库包以及解决问题 - 知乎
setup.py大概长这样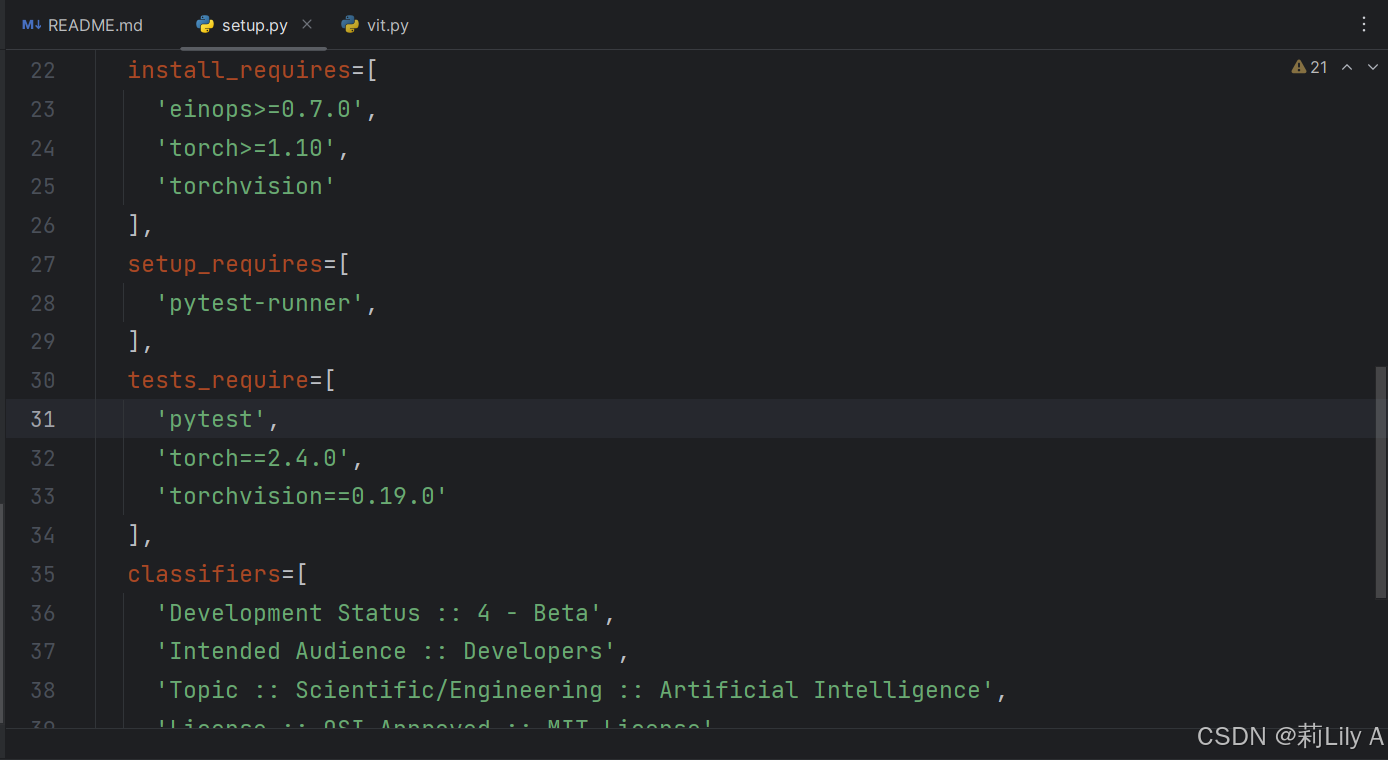
在安装依赖项的时候还看到一篇帖子VIT(vision in transformer)pytorch怎么使用 - 简书
它是这样安装库的:
pip install vit-pytorch -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install timm -i https://pypi.tuna.tsinghua.edu.cn/simple怎么在pycharm配置虚拟环境的Python解释器,防止有小白不会,这里放个帖子供参考PyCharm加载虚拟环境的Python解释器_pycharm新建conda解释器 一直在等待-CSDN博客
我就不细嗦了~
2.代码解释
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrangetorch: 这是主要的Pytorch库。它提供了构建、训练和评估神经网络的工具
torch.nn: torch下包含用于搭建神经网络的modules和可用于继承的类的一个子包
einops: 灵活和强大的张量操作,可读性强和可靠性好的代码。支持numpy、pytorch、tensorflow等。在Vision Transformer等需要频繁操作张量维度的代码实现里极其有用。
einops.layers.torch中的Rearrange: 用于搭建网络结构时对张量进行“隐式”的处理
主要的函数就是这些【ViT系列(2)】ViT(Vision Transformer)代码超详细解读(Pytorch)_vit代码-CSDN博客
这篇帖子每个函数具体在做什么都解释了,但不知道为什么我没有找到 PreNorm层
ViT操作的整体流程:
首先对输入进来的img(256*256大小),划分为32*32大小的patch,共有8*8个。并将patch转换成embedding。
生成cls_tokens
将cls_tokens沿dim=1维与x进行拼接
生成随机的position embedding,每个embedding都是1024维
对输入经过Transformer进行编码
如果是分类任务的话,截取第一个可学习的class embedding
最后过一个MLP Head用于分类。
3.测试代码
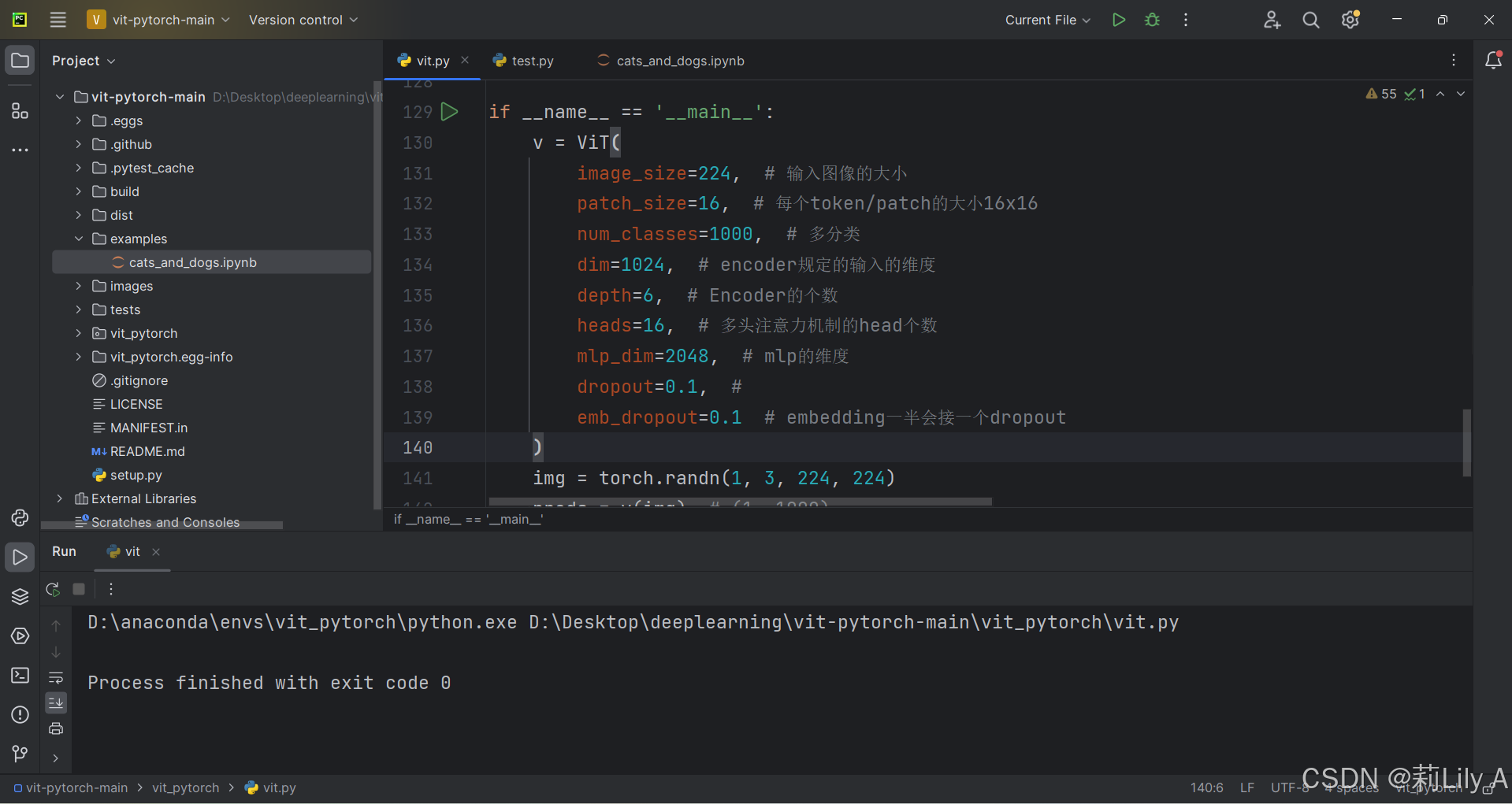
在vit.py最后写以下代码进行测试:
if __name__ == '__main__':
v = ViT(
image_size=224, # 输入图像的大小
patch_size=16, # 每个token/patch的大小16x16
num_classes=1000, # 多分类
dim=1024, # encoder规定的输入的维度
depth=6, # Encoder的个数
heads=16, # 多头注意力机制的head个数
mlp_dim=2048, # mlp的维度
dropout=0.1, #
emb_dropout=0.1 # embedding一半会接一个dropout
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)如果上述代码能够正常运行并输出预测结果,说明安装和配置成功。
可是我运行没有任何结果!!!啊可恶!!!
先写这么多,下次继续更新
参考
『论文精读』Vision Transformer(VIT)论文解读_vit论文-CSDN博客
【ViT系列(2)】ViT(Vision Transformer)代码超详细解读(Pytorch)_vit代码-CSDN博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









