







一、概念
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
具体来说就是在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
SVM使用准则:n为特征数,m为训练样本数。
如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
如果n较小,而且m大小中等,例如n在 1-1000 之间,而m在10-10000之间,使用高斯核函数的支持向量机。
如果n较小,而m较大,例如n在1-1000之间,而𝑚大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
二、支持向量机
1、超平面
在维度为1时,我们可以找到一个点来分开两类的样本。在维度为2时,我们可以找到一条直线来分开两类样本。在维度为3时,我们也可以找到一个平面来分开两类样本。即维度为n时,我们可以找到一个维度为n-1的超平面来对样本进行分类。总之,将数据集分隔开的直线或者平面叫做超平面。下图为超平面示意图及超平面公式:
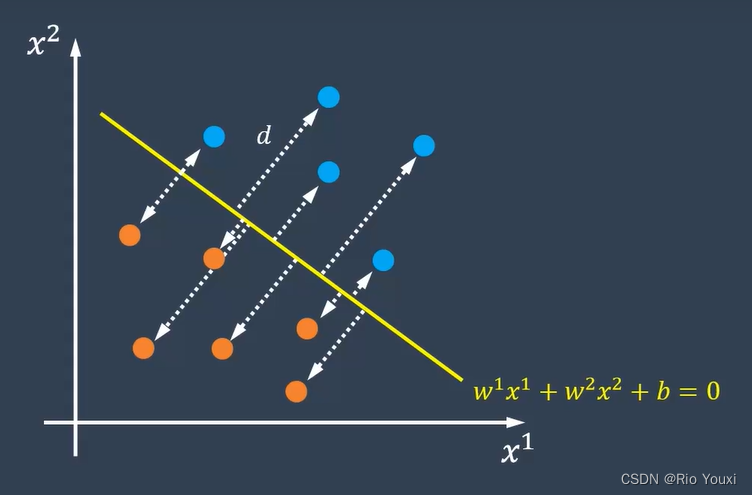
2、间隔
间隔指的是数据点到超平面的距离
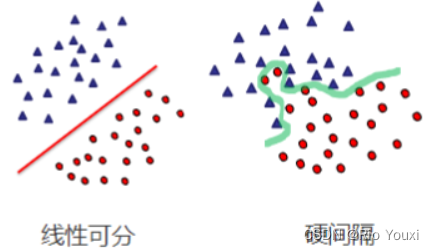
线性可分
硬间隔
假如数据是完全线性可分的,即数据的分类完全正确,不存在错误分类的情况下,即称我们学习出来的模型叫做硬间隔支持向量机
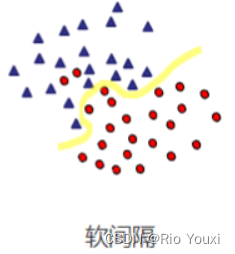
软间隔
允许数据的分类存在一定量的错误,即称我们学习到的模型成为软间隔支持向量机。但相应的需要增加一个惩罚项。
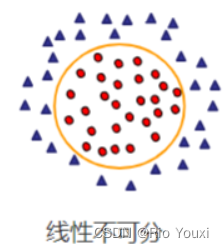
线性不可分
倘若两类数据无法进行线性分类,则称这种情况为线性不可分。
3、支持向量
在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量
4、核函数
支持向量机算法分类和回归方法的中都支持线性性和非线性类型的数据类型。非线性类型通常是二维平面不可分,为了使数据可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易可分,这样就达到数据分类或回归的目的,而实现这一目标的函数称为核函数。
工作原理:当低维空间内线性不可分时,可以通过高位空间实现线性可分。但如果在高维空间内直接进行分类或回归时,则存在确定非线性映射函数的形式和参数问题,而最大的障碍就是高维空间的运算困难且结果不理想。通过核函数的方法,可以将高维空间内的点积运算,巧妙转化为低维输入空间内核函数的运算,从而有效解决这一问题。
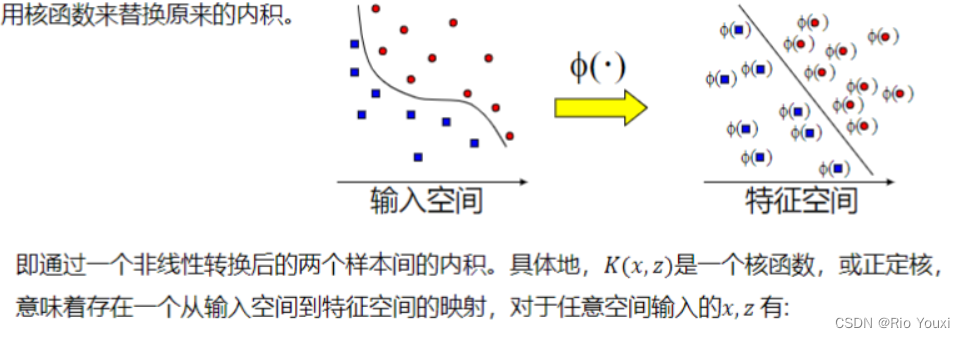
常用的核函数有:线性核函数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









