






1.1 概念
K近邻算法(K-Nearest Neighbors,KNN)是一种基本的机器学习算法,也是一种分类和回归方法。它的原理很简单,即根据特征相似度来进行分类或回归预测。 K近邻(K-Nearest Neighbor, KNN)是一种最经典和最简单的有监督学习方法之一。
在KNN算法中,首先需要给定一个训练集,其中包含了已知分类标签的样本数据。
然后,通过计算待预测样本与训练集中各个样本的特征距离,选择与待预测样本最相似的K个训练样本(即K个最近邻)
并根据这K个并据这K个最近邻样本的分类标签来对待预测样本进行分类或回归预测.
1.2 步骤
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类
1.3 三个基本要素
K值的选择
k较小→使用较小邻域中的训练实例预测→近似误差会减小、估计误差会增大→模型复杂,容易过拟合
k较大→使用较大邻域中的训练实例预测→近似误差会增大、估计误差会减小→模型简单
距离度量
欧氏距离:欧几里得距离是我们在平面几何中最常用的距离计算方法,即两点之间的直线距离。
曼哈顿距离:曼哈顿距离是计算两点在一个网格上的路径距离,与上述的直线距离不同,它只允许沿着网格的水平和垂直方向移动。
闵可夫斯基距离、切比雪夫距离
决策规则
分类:多数表决,即经验风险最小化实现
二、代码实现
设定训练集:
def createDataSet(): group = array([[90, 3], [109, 5], [98, 2], [6, 80], [8, 92], [4, 78],[78,7]]) labels = ['动作片', '动作片', '动作片', '爱情片', '爱情片', '爱情片','动作片'] return group, labels
实现KNN算法:
def classifyKNN(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
绘制图像
def data_show(in_data, train_data):
x = []
y = []
for i in range(train_data.shape[0]):
x.append(train_data[i][0])
y.append(train_data[i][1])
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(x, y, "*")
plt.xlabel("打斗镜头出现次数")
plt.ylabel("接吻镜头出现次数")
plt.plot(in_data[0], in_data[1], "r*")
plt.show()
主函数实现
if __name__ == '__main__':
group, labels = createDataSet()
# 测试集
test = [97, 4]
# kNN分类
test_class = classifyKNN(test, group, labels, 3)
# 打印分类结果
print('该电影类型为' + test_class)
data_show(test, group)
运行结果
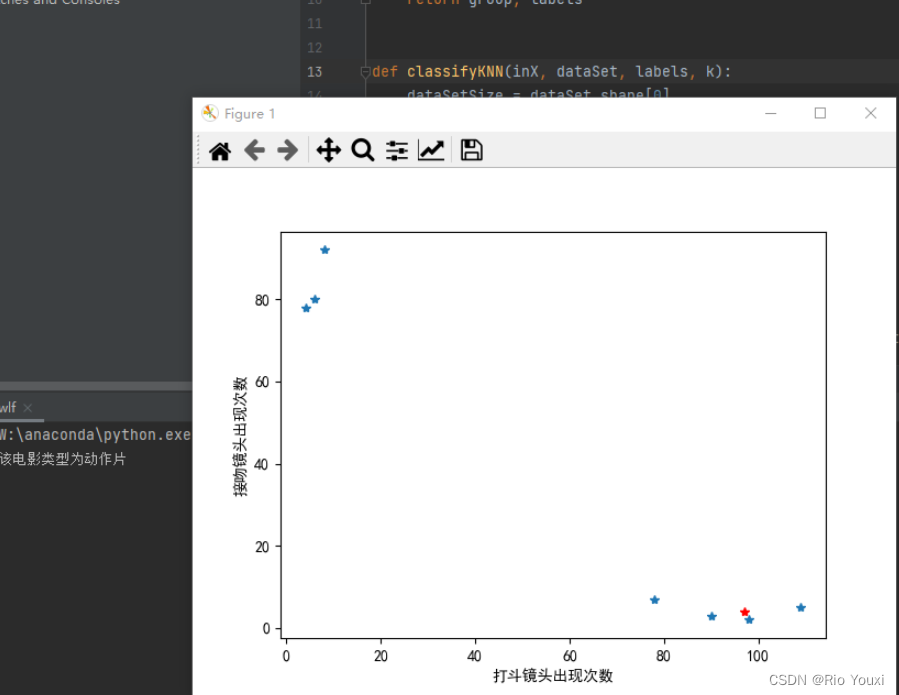
实验总结:
1.KNN算法是一种简单且有效的分类算法,特别适用于小规模数据集和简单的分类任务,一般而言,较小的K值会使模型更加复杂,容易过拟合;较大的K值会使模型更加简单,容易欠拟合。
2.通过实验可知一般k值选择较小的K值,选择奇数的K值在看情况而更改。















 4550
4550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









