







今天给大家分享多目标樽海鞘算法,主要从算法原理和代码实战展开。需要了解智能算法、机器学习、深度学习和信号处理相关理论的可以后台私信哦,下一期分享的内容就是你想了解的内容。
一、算法原理
上一篇分享的SSA算法能够驱动salps向食物来源靠近,并在迭代过程中对其进行更新。但是,该算法不能解决多目标问题,主要有以下两个原因:
1、SSA只保存一个解决方案作为最佳解决方案,因此它不能存储多个解决方案作为一个多目标问题的最佳解决方案。
2、SSA在每次迭代中都用迄今为止得到的最优解更新食物源,但对于多目标问题没有单一的最优解。
多目标樽海鞘算法(Multi-objective Salp Swarm Algorithm, SSA)是针对多目标问题,在SSA算法的基础上提出的。

关于SSA算法的原理,可以参考上一期文章:樽海鞘群算法MATLAB实战
关于多目标问题的一些相关解释可以参考我之前的文章:多目标粒子群算法MATLAB实战
通过给SSA算法配备一个食物来源库来解决第一个问题。该存储库维护了到目前为止优化过程中获得的最优解,非常类似于多目标粒子群优化(MOPSO)中的存档[78]。存储库有一个最大大小来存储数量有限的最优解决方案。在优化过程中,使用Pareto优势操作符将每个樽海鞘与所有存储库原方案进行比较。如果一个樽海鞘在存储库中占优,则必须交换它们(把樽海鞘放入存储库,原方案拿出)。如果一个樽海鞘在存储库中优于一组解决方案,那么应该将这一组解决方案全部从存储库中删除,并把该樽海鞘应该添加到存储库中。如果至少有一个存储库中的原方案比该樽海鞘更优,那么该樽海鞘应被丢弃,不加入存储库。
如果与所有存储库居民相比,该樽海鞘与之互不占优,那么该樽海鞘即是最优解,则必须将其添加到存储库中。
这些规则可以保证存储库得到的始终都是目前为止算法所获得的最优解决方案。但是,有一种特殊情况,即存储库已满,与存储库原方案相比,该樽海鞘也不占优,此时本应该将该樽海鞘加入存储库,但是存储库满了。当然,最简单的方法是随机删除归档中的一个解决方案,并将其替换为这个樽海鞘。
更明智的方法是在存储库中删除一个类似的非主导解决方案:从存档中删除的最佳候选方案是在一个种群稠密的区域。这种方法改进了在迭代过程中存储库中方案的分布。
为求邻域有人口的非支配解,需要计算邻域有一定最大距离的解的个数。这个距离的定义是:
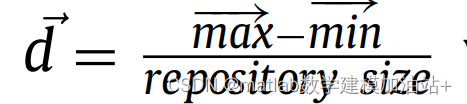
Max和min分别是存储每个目标函数的最大值和最小值的两个向量。每个段中有一个解决方案的存储库是最好的情况。在根据相邻解决方案的数量为每个存储库驻留分配级别之后,将使用轮盘赌来选择其中一个删除。一个解决方案的相邻解决方案的数量越多(级别数越大),从存储库中删除它的可能性就越大。图1展示了该存储库更新机制的示例。注意邻域应该为所有的解定义,但是在这个图中只研究了4个非支配解。
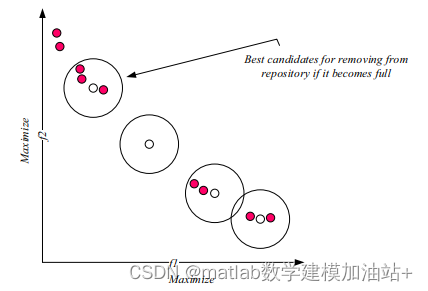
图1 存储库满时的更新机制
如图所述,介绍了存储库的更新机制后,使用SSA解决多目标问题的第二个问题是食物来源的选择,因为在多目标搜索空间中有不止一个最佳解。同样,可以从存储库中随机选择食物来源。然而,更合适的方法是从一组最优解决方案中选择最不拥挤的区域。这可以使用存储库维护操作符中使用的相同的排序过程和轮盘赌轮选择来完成。主要的区别是选择最优解决方案的概率。在存储库维护删除中,等级越高(邻里拥挤)的解决方案越容易被选择。相比之下,对于存储库中的最优解决方案而言,人口越少(较低的等级数),被选为食物来源的可能性就越大。(这样就能更多地开发未探索的区域,加强全局搜索能力,如果一直检索密集区域容易陷入局部最优,选择稀疏的区域作为食物能够减少陷入局部最优的可能性。)如图2中,中间没有相邻方案的最优解被选择为食物来源的概率最大。
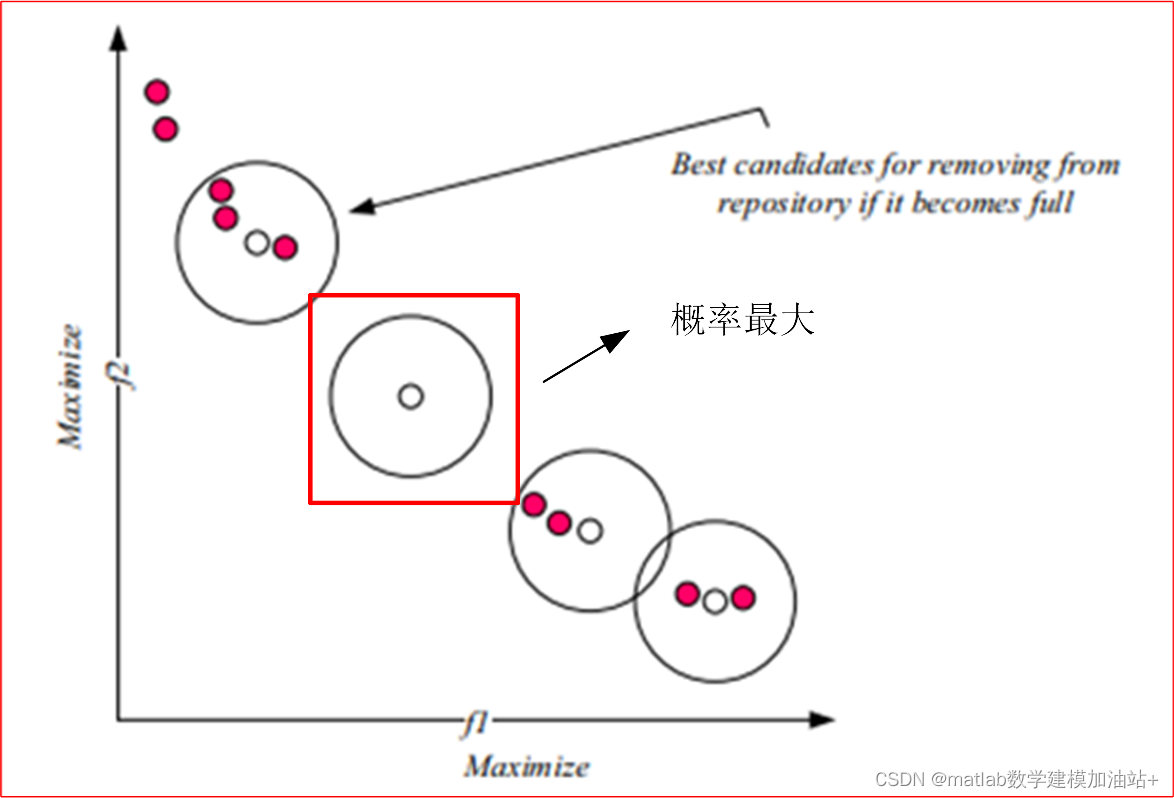
图2 红色方框的白点被选为食物源的概率最大
MSSA算法的伪代码如图3所示。

图3 MSSA算法的伪代码
二、代码实战
以ZDT1作为测试函数,进行仿真实验
clc;
clear;
close all;
% Change these details with respect to your problem%%%%%%%%%%%%%%
ObjectiveFunction=@ZDT1;
dim=5;
lb=0;
ub=1;
obj_no=2;
if size(ub,2)==1
ub=ones(1,dim)*ub;
lb=ones(1,dim)*lb;
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
max_iter=100;
N=200;
ArchiveMaxSize=100;
Archive_X=zeros(100,dim);
Archive_F=ones(100,obj_no)*inf;
Archive_member_no=0;
r=(ub-lb)/2;
V_max=(ub(1)-lb(1))/10;
Food_fitness=inf*ones(1,obj_no);
Food_position=zeros(dim,1);
Salps_X=initialization(N,dim,ub,lb);
fitness=zeros(N,2);
V=initialization(N,dim,ub,lb);
iter=0;
position_history=zeros(N,max_iter,dim);
for iter=1:max_iter
c1 = 2*exp(-(4*iter/max_iter)^2); % Eq. (3.2) in the paper
for i=1:N %Calculate all the objective values first
Salps_fitness(i,:)=ObjectiveFunction(Salps_X(:,i)');
if dominates(Salps_fitness(i,:),Food_fitness)
Food_fitness=Salps_fitness(i,:);
Food_position=Salps_X(:,i);
end
end
[Archive_X, Archive_F, Archive_member_no]=UpdateArchive(Archive_X, Archive_F, Salps_X, Salps_fitness, Archive_member_no);
if Archive_member_no>ArchiveMaxSize
Archive_mem_ranks=RankingProcess(Archive_F, ArchiveMaxSize, obj_no);
[Archive_X, Archive_F, Archive_mem_ranks, Archive_member_no]=HandleFullArchive(Archive_X, Archive_F, Archive_member_no, Archive_mem_ranks, ArchiveMaxSize);
else
Archive_mem_ranks=RankingProcess(Archive_F, ArchiveMaxSize, obj_no);
end
Archive_mem_ranks=RankingProcess(Archive_F, ArchiveMaxSize, obj_no);
% Archive_mem_ranks
% Chose the archive member in the least population area as food`
% to improve coverage
index=RouletteWheelSelection(1./Archive_mem_ranks);
if index==-1
index=1;
end
Food_fitness=Archive_F(index,:);
Food_position=Archive_X(index,:)';
for i=1:N
index=0;
neighbours_no=0;
if i<=N/2
for j=1:1:dim
c2=rand();
c3=rand();
%%%%%%%%%%%%% % Eq. (3.1) in the paper %%%%%%%%%%%%%%
if c3<0.5
Salps_X(j,i)=Food_position(j)+c1*((ub(j)-lb(j))*c2+lb(j));
else
Salps_X(j,i)=Food_position(j)-c1*((ub(j)-lb(j))*c2+lb(j));
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
end
elseif i>N/2 && i<N+1
point1=Salps_X(:,i-1);
point2=Salps_X(:,i);
Salps_X(:,i)=(point2+point1)/(2); % Eq. (3.4) in the paper
end
Flag4ub=Salps_X(:,i)>ub';
Flag4lb=Salps_X(:,i)<lb';
Salps_X(:,i)=(Salps_X(:,i).*(~(Flag4ub+Flag4lb)))+ub'.*Flag4ub+lb'.*Flag4lb;
end
display(['At the iteration ', num2str(iter), ' there are ', num2str(Archive_member_no), ' non-dominated solutions in the archive']);
end
figure
Draw_ZDT1();
hold on
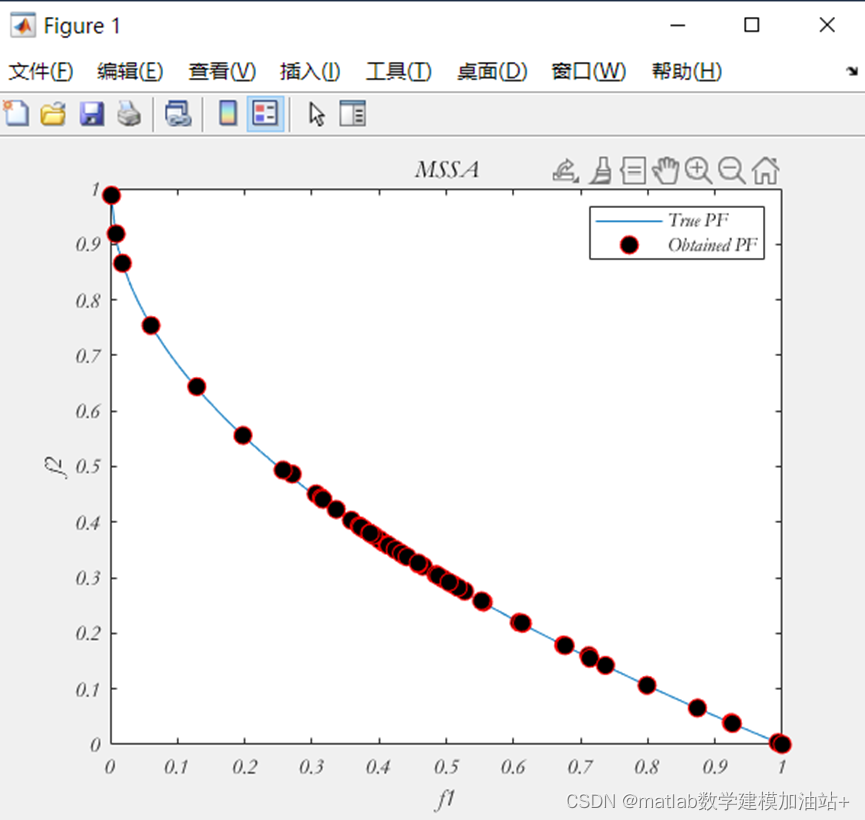
plot(Archive_F(:,1),Archive_F(:,2),'ro','MarkerSize',8,'markerfacecolor','k');
legend('True PF','Obtained PF');
title('MSSA');
set(gcf, 'pos', [403 466 230 200])
仿真结果:
部分知识来源于网络,如有侵权请联系作者删除~
完整代码(关注获取)
















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









