









ControlNet 为什么在 SD 中很重要呢,因为 ControlNet 真正让 SD 做到了让图像生成进入了可控时代,至于什么叫做可控,小伙伴们继续看下去就知道啦!
首先我们先来介绍一下 ControlNet 的安装吧,还是插件的安装方式,在扩展中搜索「sd-webui-controlnet」,然后点击安装,重启 SD 。
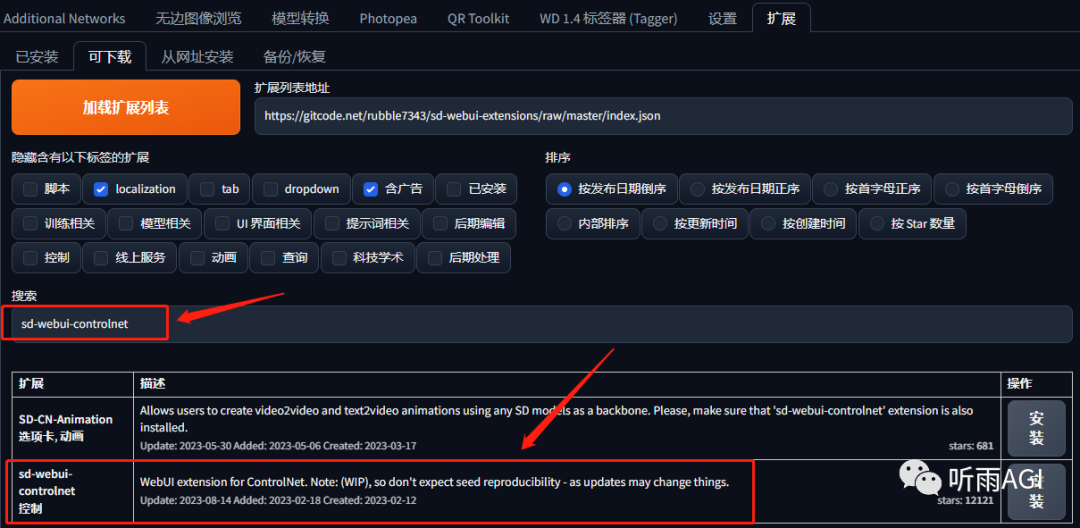
在 SD 的文生图或者图生图模式下,页面往下翻可以看到有一个 ControlNet 的选项,就说明安装成功了。
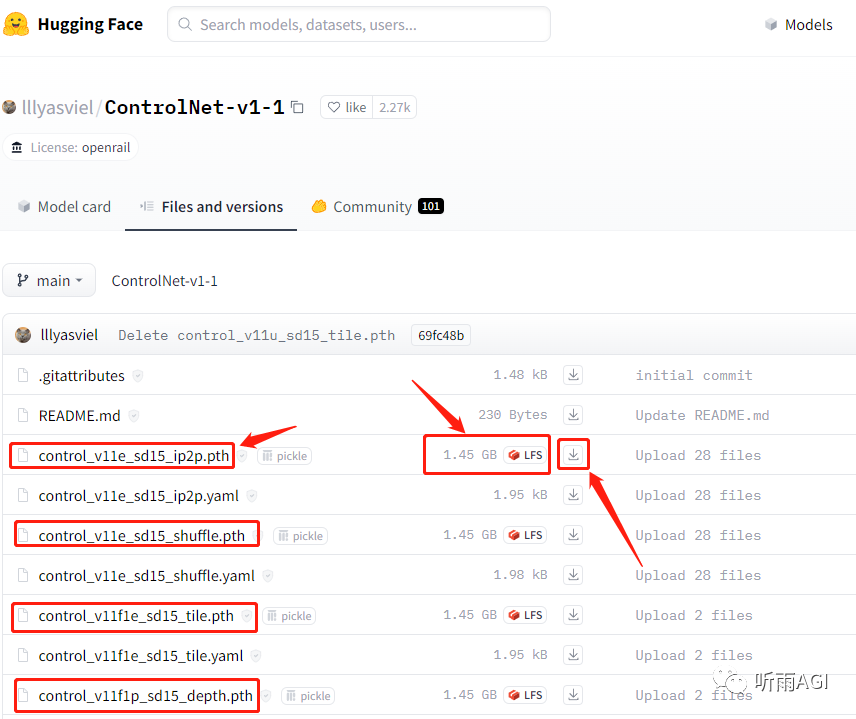
ControlNet 插件安装好以后还需要安装 ControlNet 模型,模型下载地址:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
总共有 14 个基础模型,依次下载模型名为「.pth」的文件,小伙伴们不要下载错了哈,认准那个「1.45 GB」的。
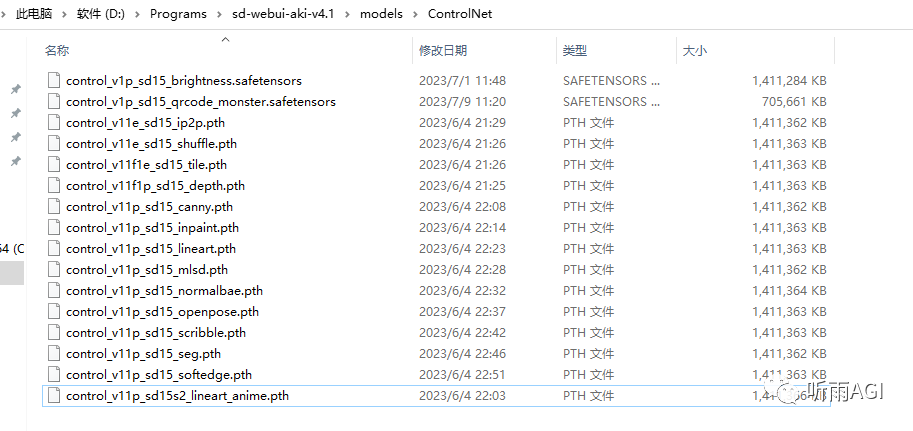
下载完成以后放入 SD 的 ControlNet 目录下。
\sd-webui-aki-v4.1\models\ControlNet
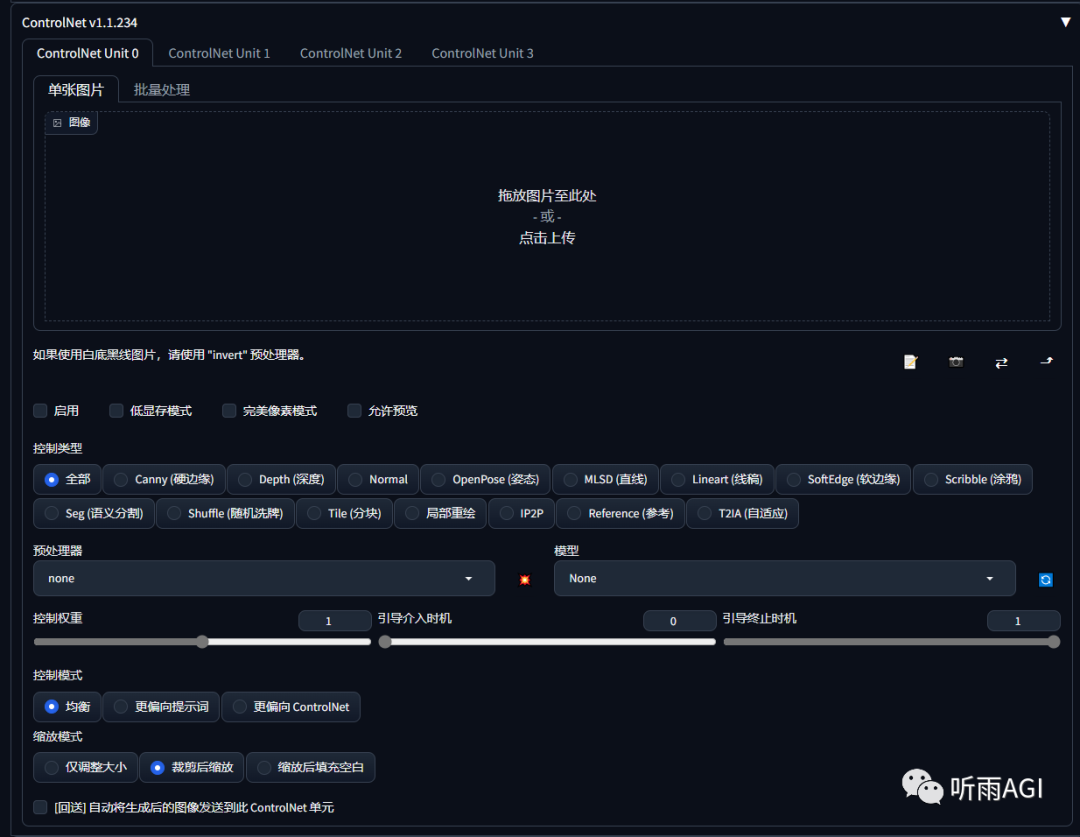
接下来我们继续来分享 ControlNet 的页面功能,我们接下来一个一个介绍哈。
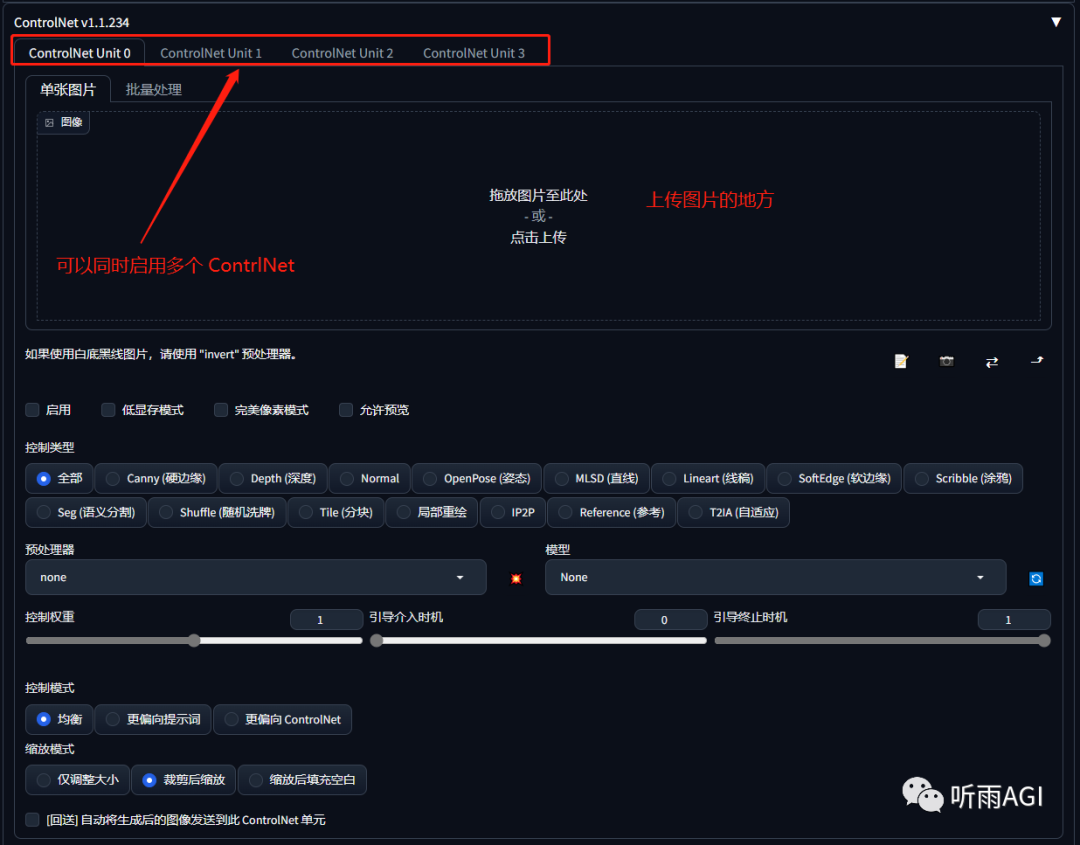
启用: 是否启用当前 ControNet 功能,如果你要启用多个 ControlNet ,你就多个 ControNet 都勾选启用。
低显存模式: 如果你的显卡低于 6G ,建议勾选该选项,原因你懂的。
完美像素模式: 让 ControlNet 自适应预处理器分辨率,勾选以后,「Preprocessor Resolution」选项会消失。
允许预览: 预览预处理处理的效果。
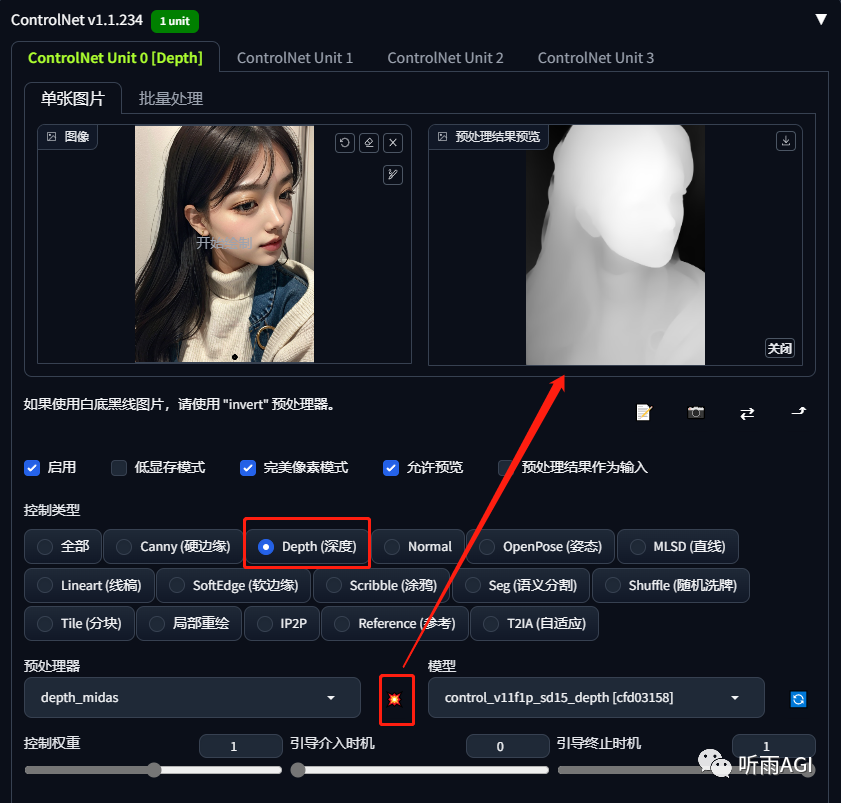
控制类型: 相当于选择预处理器和模型的快捷目录,点击需要的控制类型,会自动加载对应的预处理器和模型。
预处理: 预处理器下拉菜单,和模型搭配使用。
模型: 模型下拉菜单,也就是我们下载的各种模型,每个模型都有不同的功能。**
控制权重: ControlNet 输出的权重大小,权重越大,影响越大。**
引导介入时机: 我们都知道 SD 有迭代步数,这里就是从哪一步开始介入图像的处理,设置为 0 ,则代表从一开始就介入,设置为 0.5 ,则代表从中间步数的时候介入处理。**
引导终止时机: 和以上相反,从哪一步退出对图像的处理。**
控制模式: 主要有三种模式:均衡、更偏向提示词、更偏向 ControlNet ,就是字面意思,听雨就不多解释了。**
缩放模式: 也分为三种:仅调整大小、裁剪后缩放、缩放后填充空白
仅调整大小:直接拉伸,比例不对会出现变形。裁剪后缩放:会丢失原图部分内容。缩放后填充空白:会在原图上产生新的内容。
回送: 字面意思,把生成以后的图像送回 ControlNet 。
模型介绍
接下来我们就来简单介绍一下各个模型的功能特点:
Canny: 硬边缘,可以很好的识别出图像的中各个对象的边缘轮廓,比较适合给线稿图上色。
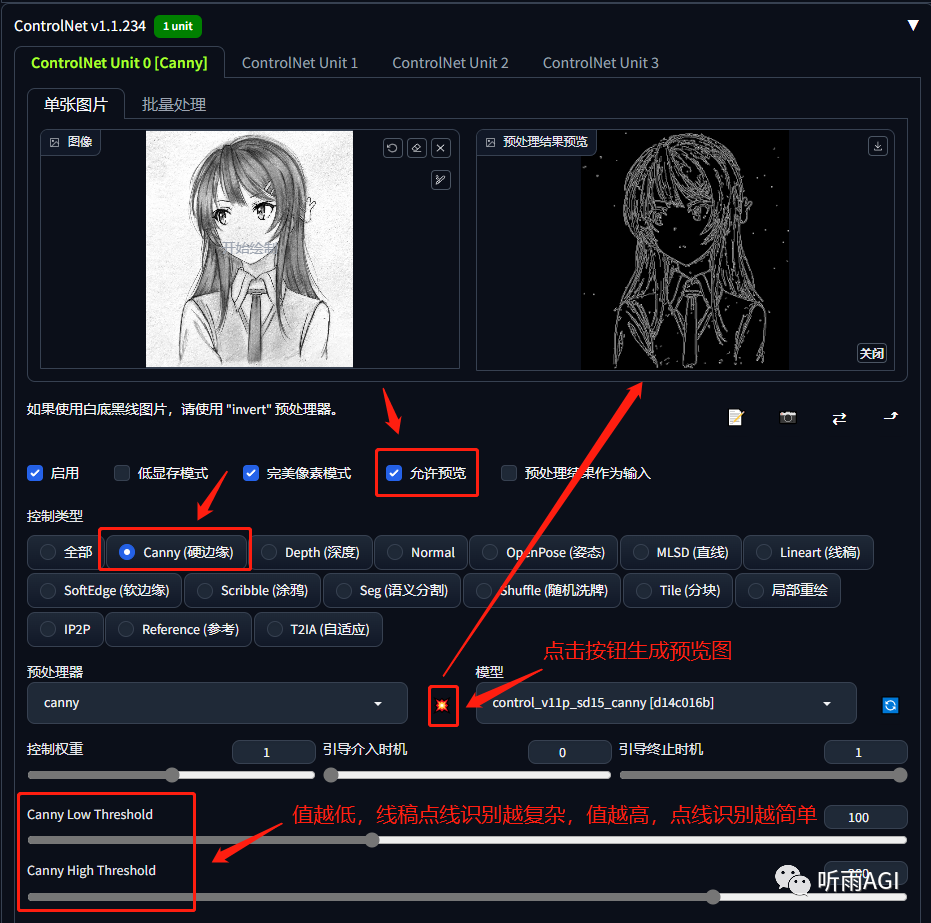
可以看到「low threshold」和「high threshold」的值越低,检测到的点线就越多。
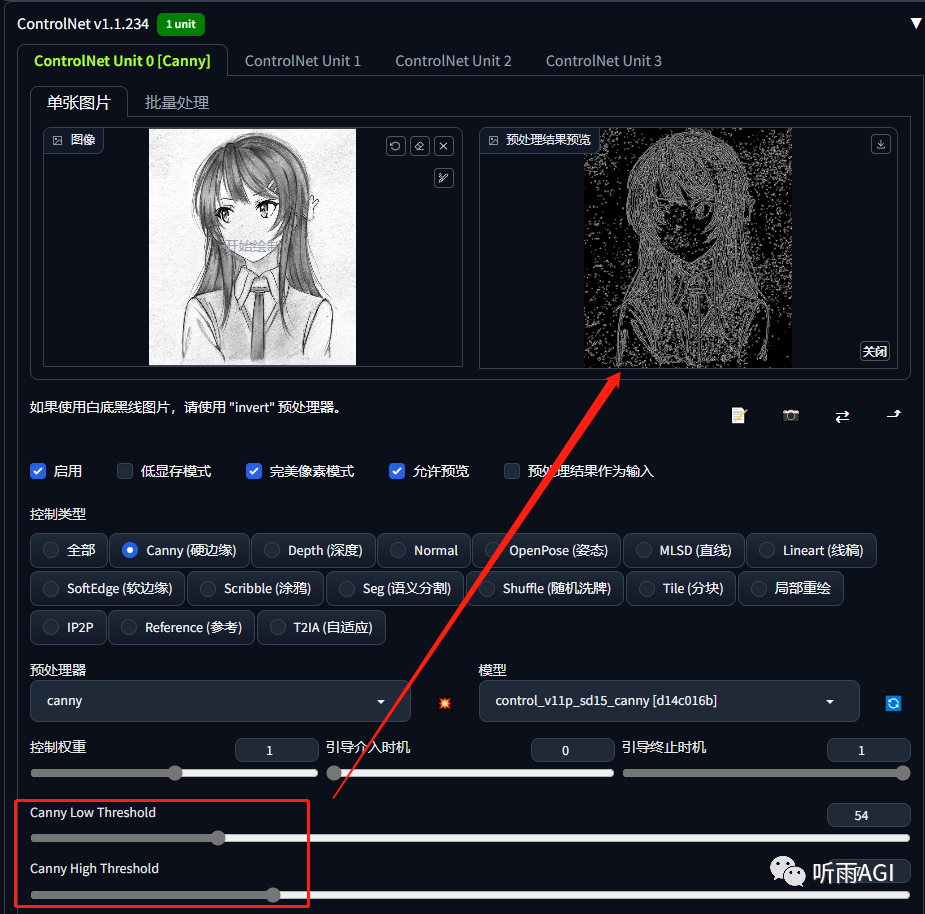
启用 ControlNet 插件,输入一个简单的提示词「1girl」,然后点击生成,可以看到以上的线稿图就已经完成上色啦,一键线稿上色有么有。
Depth: 通过提取原始图片中的深度信息,生成具有同样深度结构的深度图,以一张照片为例,越白代表点线离镜头越近,越黑代表点线离镜头越远。
可以看到图像的还原度还是很可以的,可以给我们的原图生成不同的出片风格。
depth 还可以运用在家装设计上,你可以使用该功能生成不同的家装设计风格。同样的布局,可以尝试更多的风格有么有。

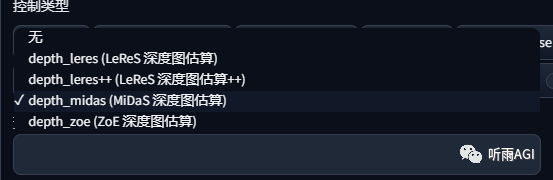
我们还可以看到 depth 有四种算法选择,四种算法各有千秋,Zoe 和Midas 的 3D 景深效果还原更好,Zoe 比 Midas 还原细节上更好。Leres 可以考虑环境比较简单的平面图,Leres++是 Leres 的升级版。
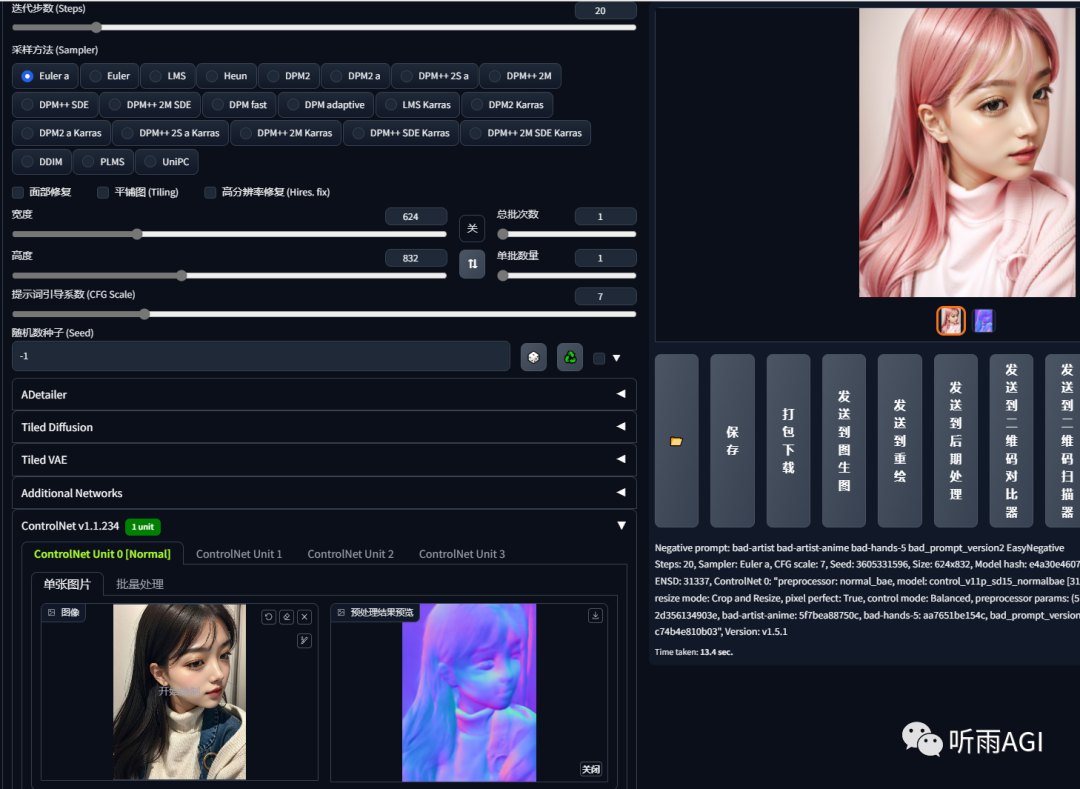
Normal: 法线贴图,用来改善表面细节和真实感,相比 depth 模型保留了更多的细节。法线贴图在游戏的制作领域运用的比较多。
OpenPose: 姿势检测模型,如果小伙伴们使用过 ControlNet 呢,对这个模型一定不陌生吧,它主要用于我们全方位的控制人物姿势。
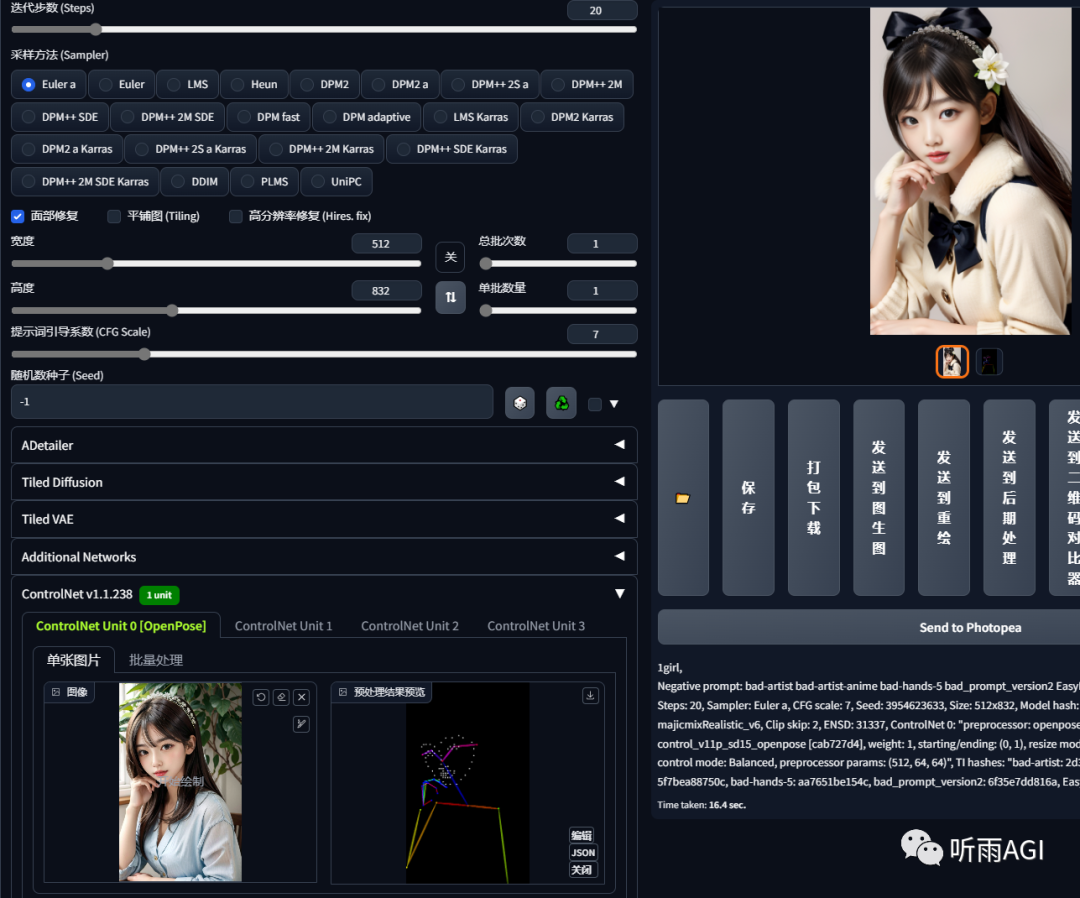
以下是 OpenPose 支持的预处理器,以及每个预处理器对应的功能,这里重点讲一下 dw_openpose_full 预处理器,这个是最近刚更新的 OpenPose 预处理器,是 openpose_full 的升级版本,识别姿势方面比 openpose_full 更精确。
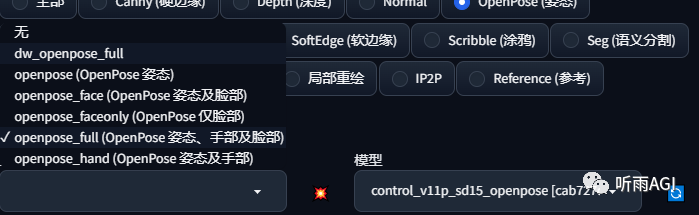
如果小伙伴们选择 dw_openpose_full 预处理器点击预览的时候报错,那可能是预处理器下载失败,小伙伴们可以手动下载。
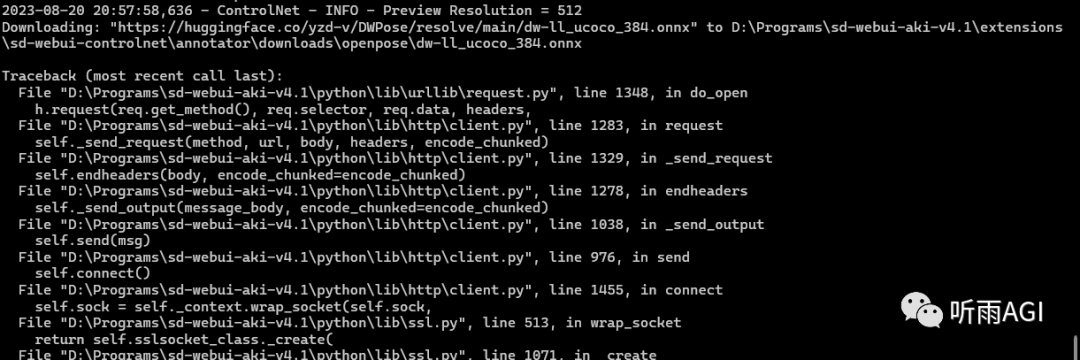
下载地址:
https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx
下载完成以后复制到 SD 以下文件夹目录下就可以了。
\sd-webui-aki-v4.1\extensions\sd-webui-controlnet\annotator\downloads\openpose
**MLSD:**适用于直接线条结构多的比如建筑设计和室内设计,只要简单的线稿图配上提示词,就可以得到让你惊喜的设计。
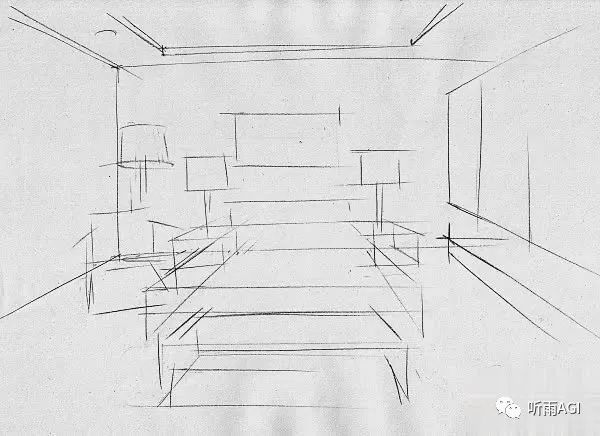
配合提示词「room」,最终出图效果,是不是很 nice ,你还可以调整不同的提示词来得到你想要的效果,设置自己想要的风格,比如你可以在提示词中加入中式风格,欧式风格,简约风格等等。

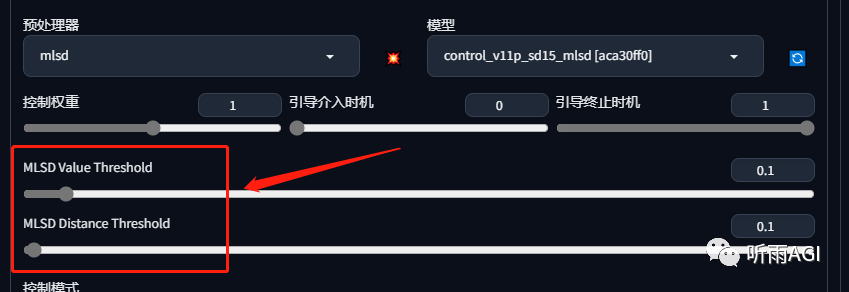
简单介绍一下MLSD模型两个参数,小伙伴们通过调整「MLSD Value Threshold」可以发现,值越小,预览图中的直线线条越多,值越大,直线线条越少。
通过调整「MLSD Distance Threshold」的值大小,值越越大,预览图中一些边角的线条会消失,使得整体的轮廓更加清晰。
Lineart: 主要用来提取图像的线稿,在线稿的基础上生成图像。主要有以下几种效果提取预处理器。小伙伴们可以根据自己的需求选择不同的线稿提取方式。
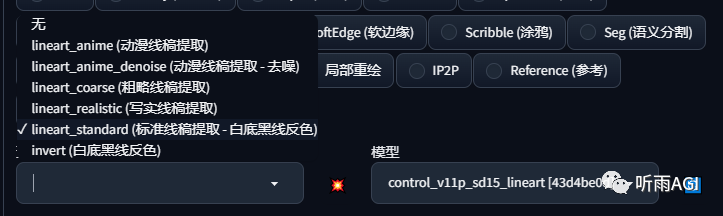
感觉功能是不是和Canny差不多,是差不多,应用场景的话可以重新给动漫人物上色。

SoftEdge: 软边缘和 Canny 的硬边缘相反,其实它们的功能都差不多。
SoftEdge相比 Canny ,只能识别图像的大概轮廓,线条比较柔和,可以给 SD 更多的想象空间。
Scribble: 涂鸦,字面意思就是可以把我们随手涂鸦的东东,变成一幅画。辅助提示词可以让 SD 更加明白我们的的意思。
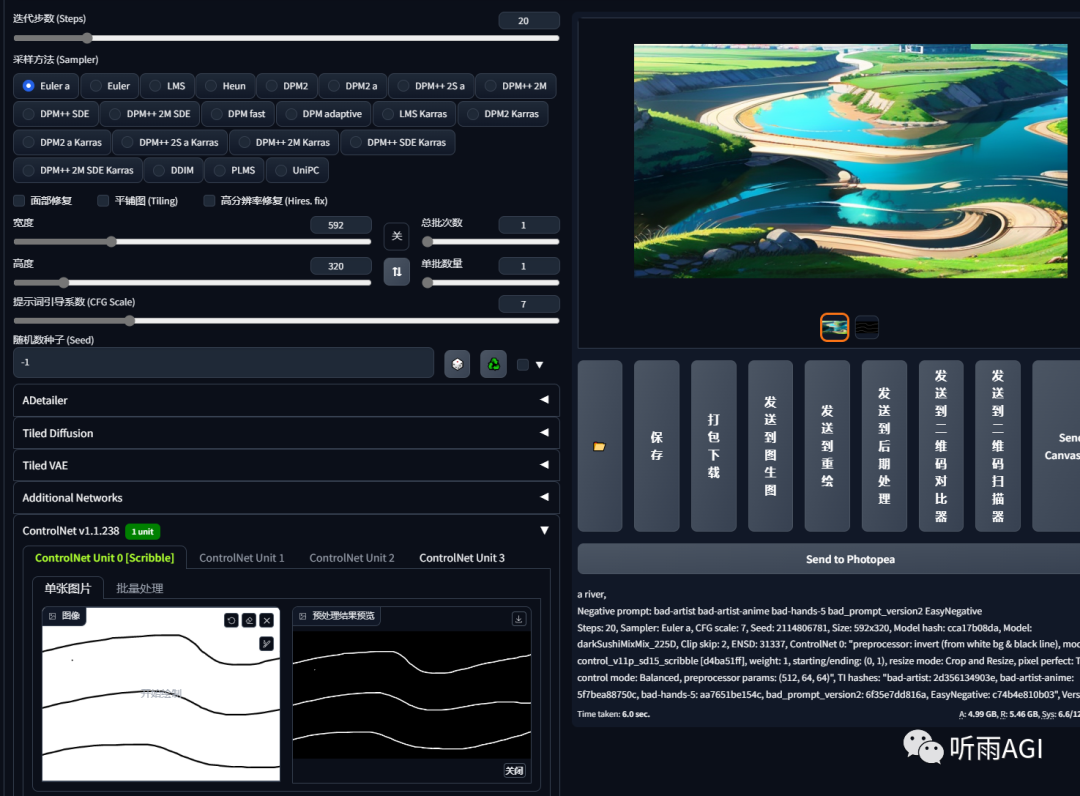
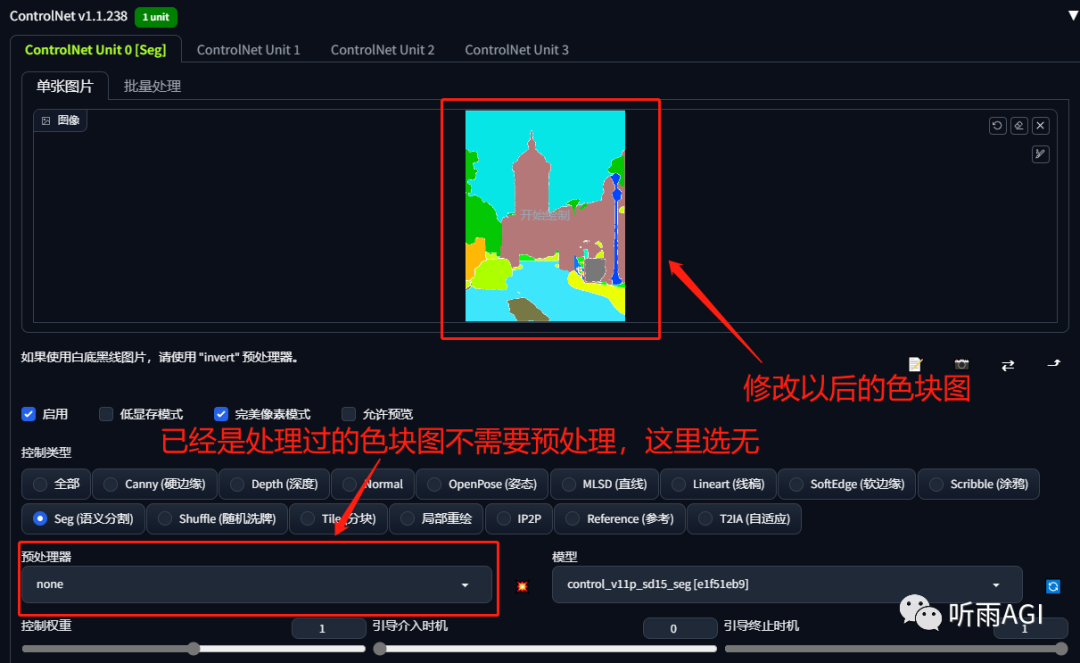
Seg: 语义分割,把图像根据不同的场景分割成不同的色块。
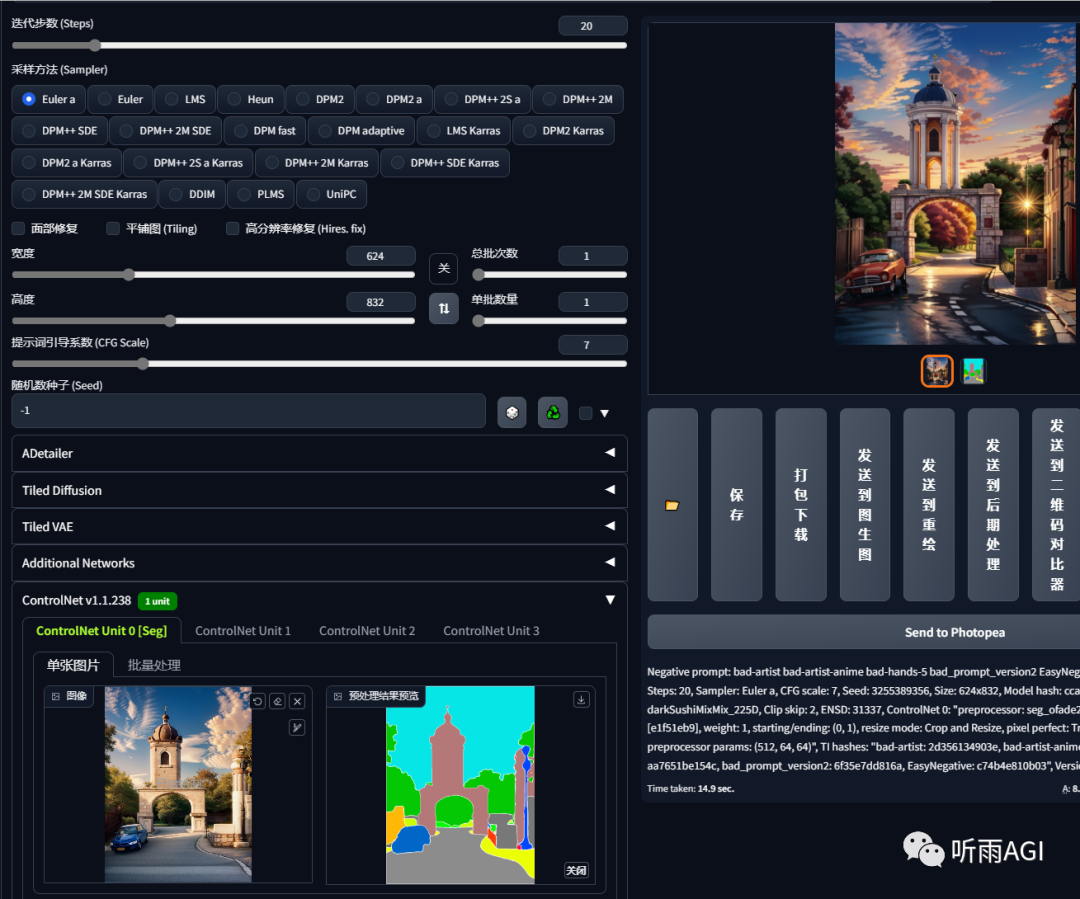
每个色块代表的含义都不一样。小伙伴们可以根据以下的色块通过 ps 等软件修改对应的色块来生成新的物体。

Shuffle: 随机洗牌,通过随机打散再扩散重组图像。可以看到预处理器中图像被拆散重组了,不过这可不是最终出图效果哦!其实 Shuffle 真正的功能是风格转移,就是可以把别的图像的风格转移到我们的图像上。
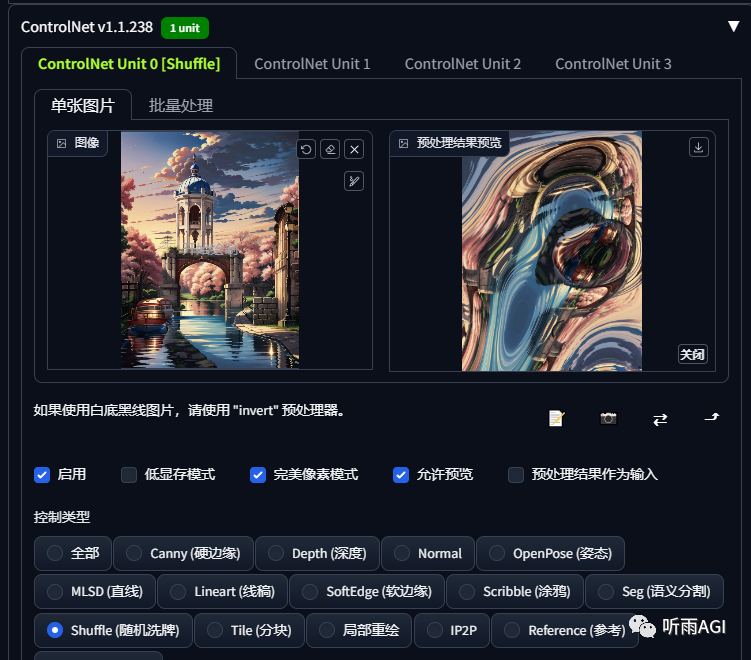
提示词「1girl」,最终出图风格会偏向于我们预处理的图片。
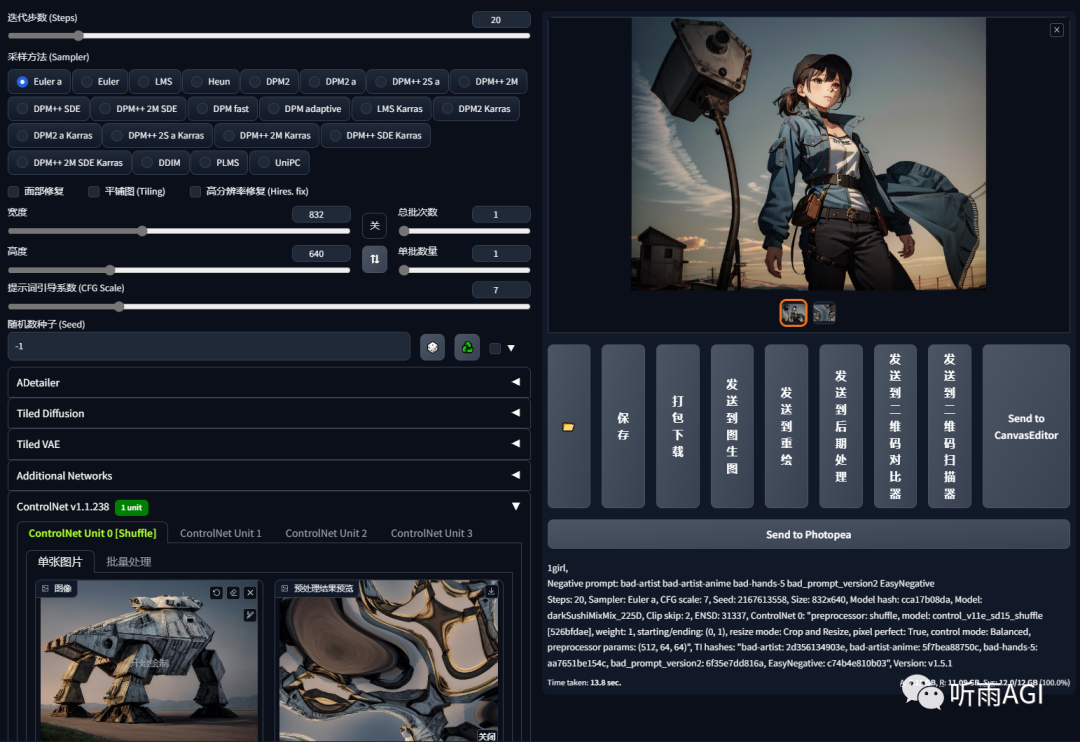
Tile: 分块,它的用法有很多种。可以用来恢复画质,真人变动漫,动漫变真人。
可以看到Tile模型新增了「Down Sampling Rate」向下采样率,这个参数主要是用来缩小参考图的分辨率,缩小分辨率的同时会丢失更多的细节,最终出图的时候,随机性就更大。所以这个参数值越大,出图的随机性就越大,和原图的关联性就越小。

我们来看Tile模型的第一个功能,恢复画质,或者说增强细节。可以看到以下的低分辨的图片,通过tile变清晰了,细节也更多了。
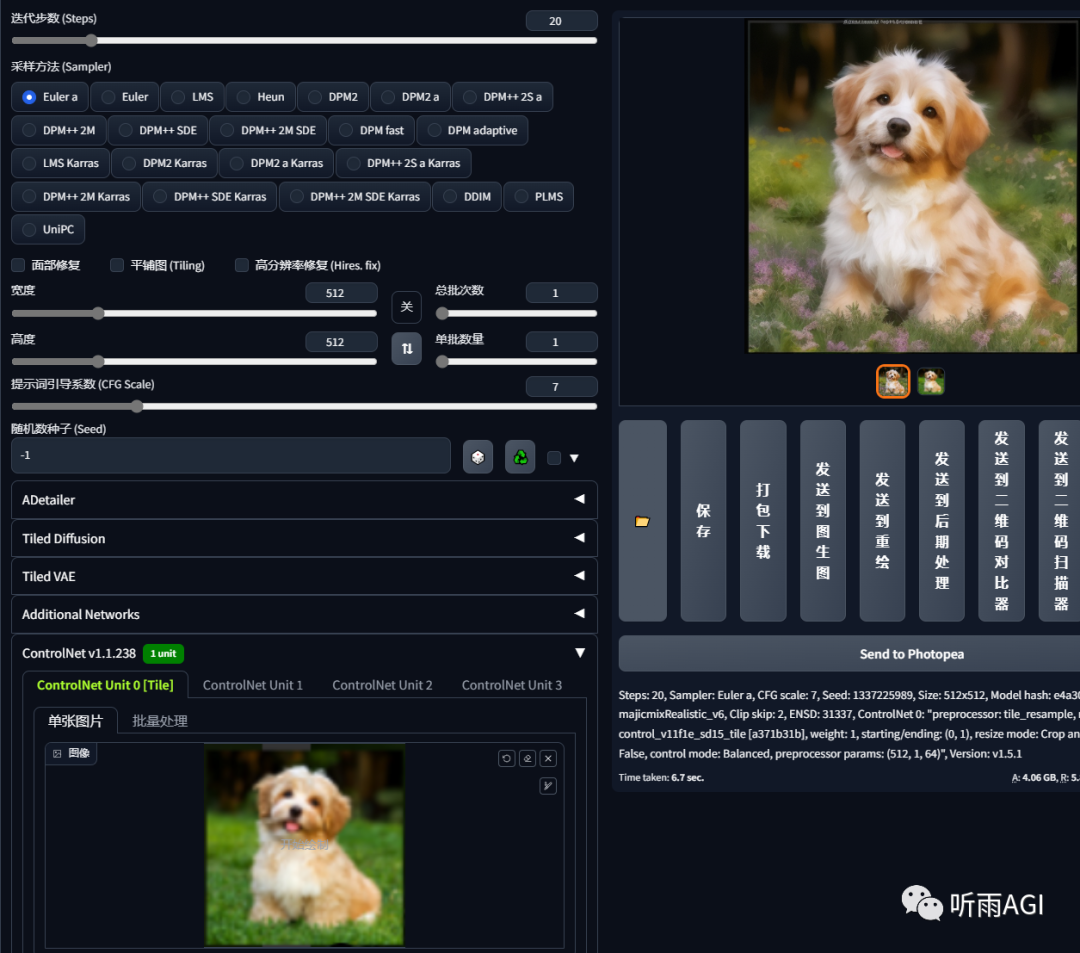
真人转动漫,准备一个动漫的大模型就可以了。

动漫转真人,准备一个真人大模型就可以了。

局部重绘: 和图生图的局部重绘差不多。
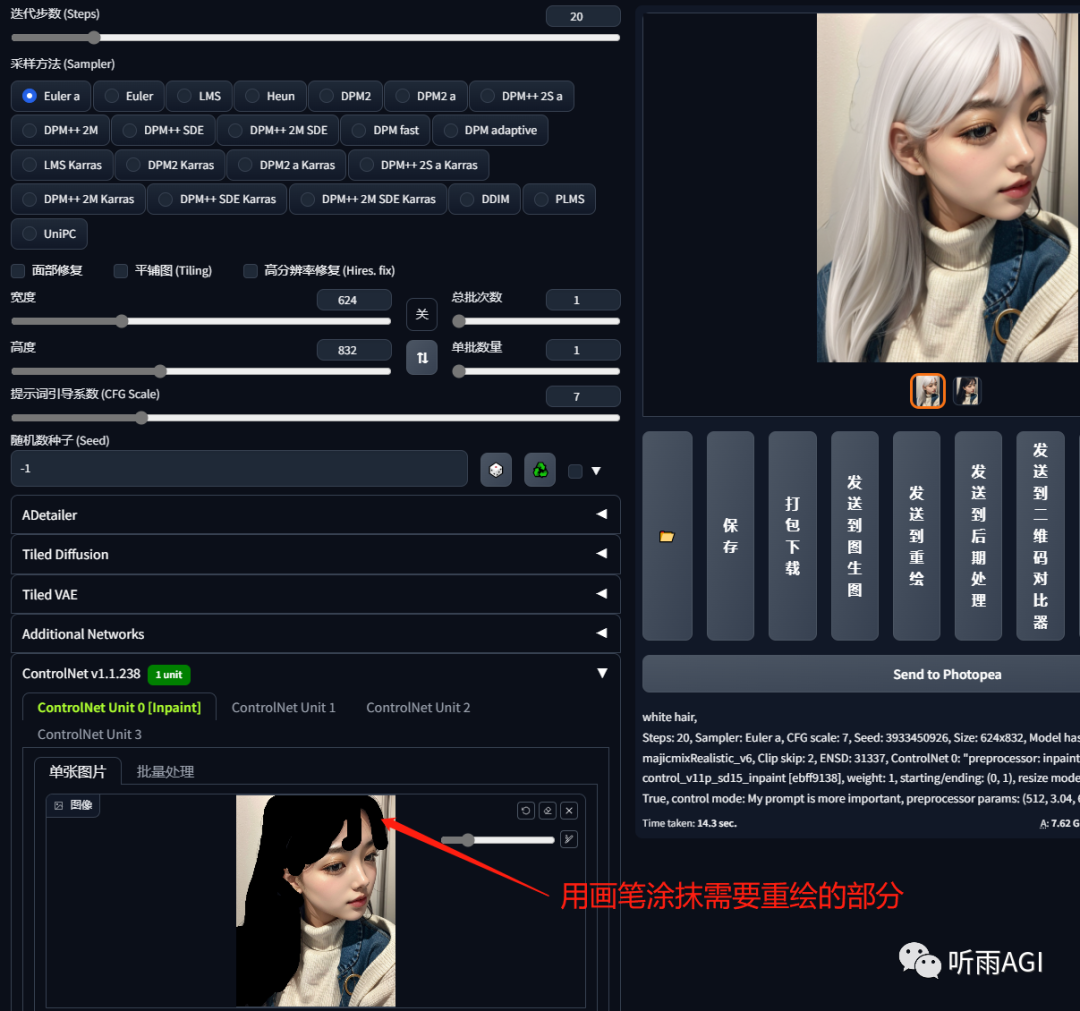
IP2P: 给图像加个特效,用法是「make it xxx」。
比如,以下的图片,在提示词中输入「make it winter」让它过冬。冬天的特效是不是就加上了。

Reference: 参考,可以保留原图的整体风格。有点类似 Lora 的感觉有么有。

T2IA: 主要是参考原图的颜色,将原图像素化以后重新生成新的图像。
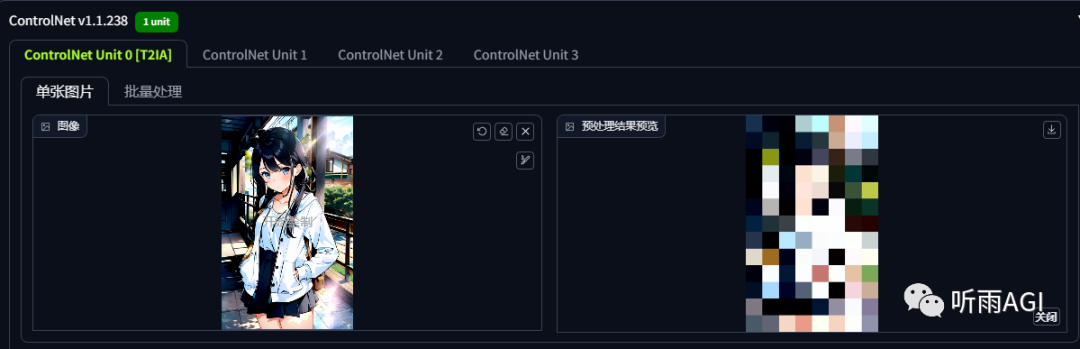
颜色风格是不是蛮一致的。

今天的分享到这里了哦,以上就是 ControlNet 的基本介绍啦,小伙伴们学会了嘛!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









