






安装版本:hadoop-2.10.1、zookeeper-3.4.12、hbase-2.3.1
一、zookeeper集群搭建与配置
1.下载zookeeper安装包
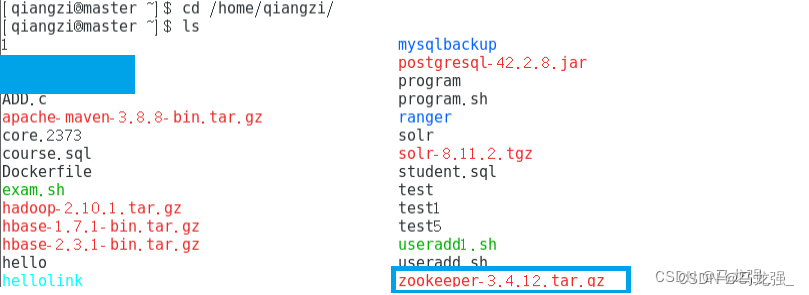
2.解压移动zookeeper
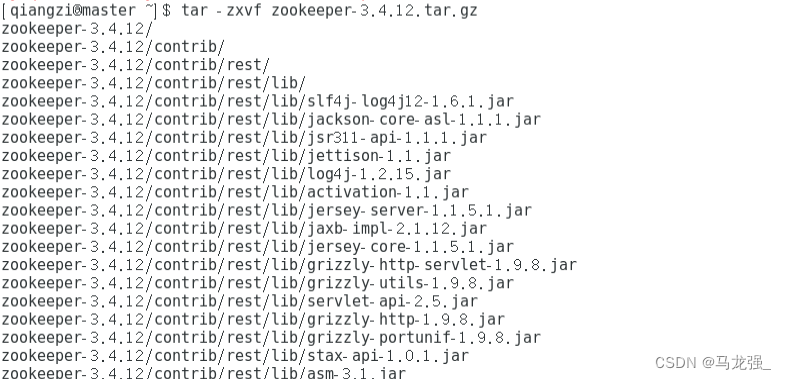
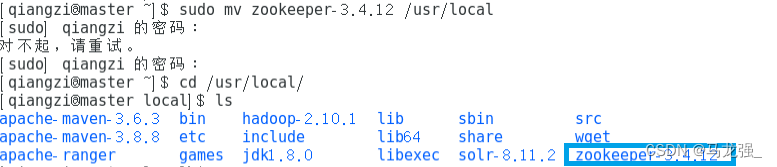
3.修改配置文件(创建文件夹)

4.进入conf/

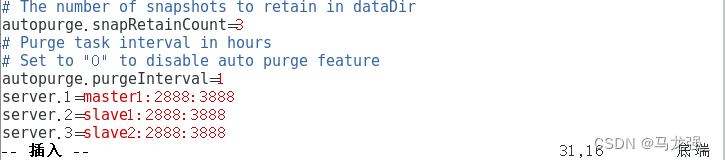
5.修改zoo.cfg文件

6.进入/usr/local/zookeeper-3.4.12/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1


7. 拷贝到两个节点上
复制到slave1

复制到slave2

查看是否复制到节点
slave1 slave2
slave2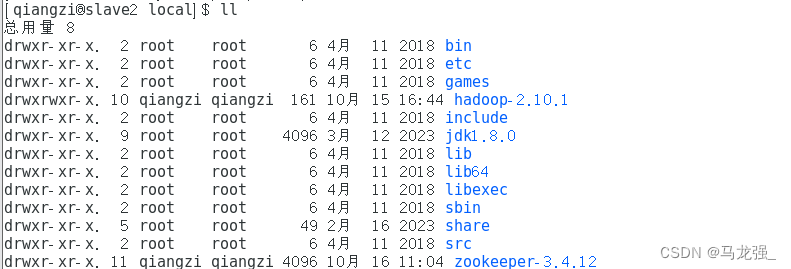
8.在节点上执行命令
Slave1 Slave2
Slave2
9.配置环境变量(三个节点都配置)

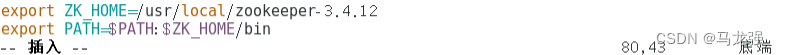
10. 让新添环境变量生效(三个节点都在hadoop用户下执行)


11.启动zookeeper服务
三台机器启动zookeeper服务;这个命令三台机器都要执行
Master Slave1
Slave1 Slave2
Slave2
12.查看状态
Master Slave1
Slave1 Slave2
Slave2
二、HBase分布式环境搭建与配置
1.下载安装包

2.解压HBase压缩包并移动到/usr/local/路径下(此处用的hbase-1.7.1版本作为演示)

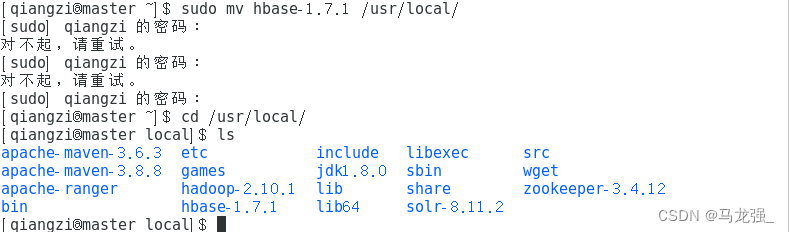
3.配置环境变量


4.进入HBase的conf文件夹下更改文件配置

5.更改hbase-env.sh文件



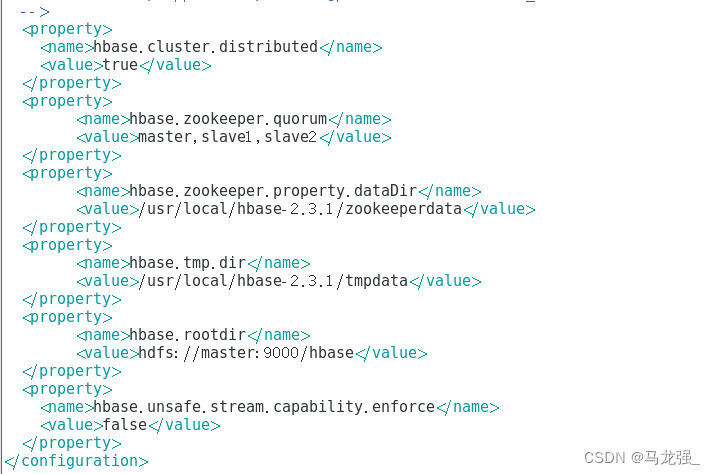
6.更改hbase-site.xml文件
7.在regionservers中添加hostname


8.将配置好的hbase拷贝到slave1、slave2节点上


9.配置节点环境变量(三个节点都进行,版本是2.3.1不要按照下方版本写)

 10.让环境变量生效(三个都进行)
10.让环境变量生效(三个都进行)

11.启动Hbase(只在Master启动,启动前一定要启动zookeeper服务和hadoop)
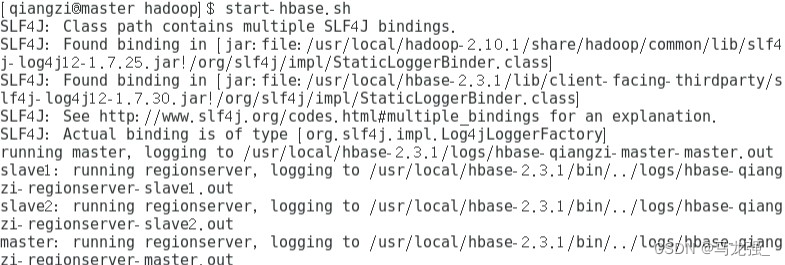
12.jps查看进程
Master Slave1
Slave1 Slave2
Slave2
13.进入hbase shell
Master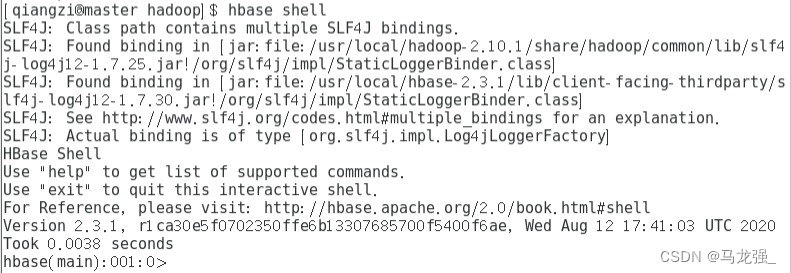 Slave1
Slave1 Slave2
Slave2
14.创建表”student”

15.查看Hadoop状态(在浏览器网址栏输入你的ip+:50070,示例192.168.1.1:50070)
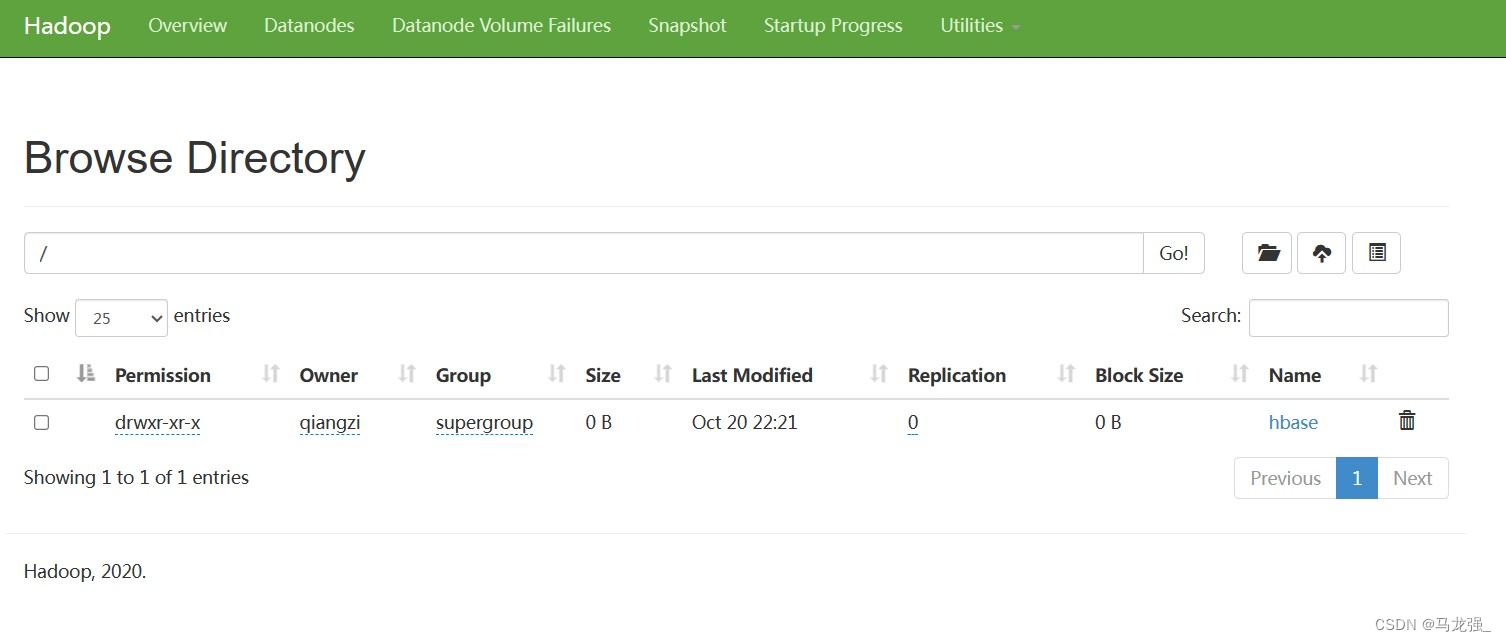
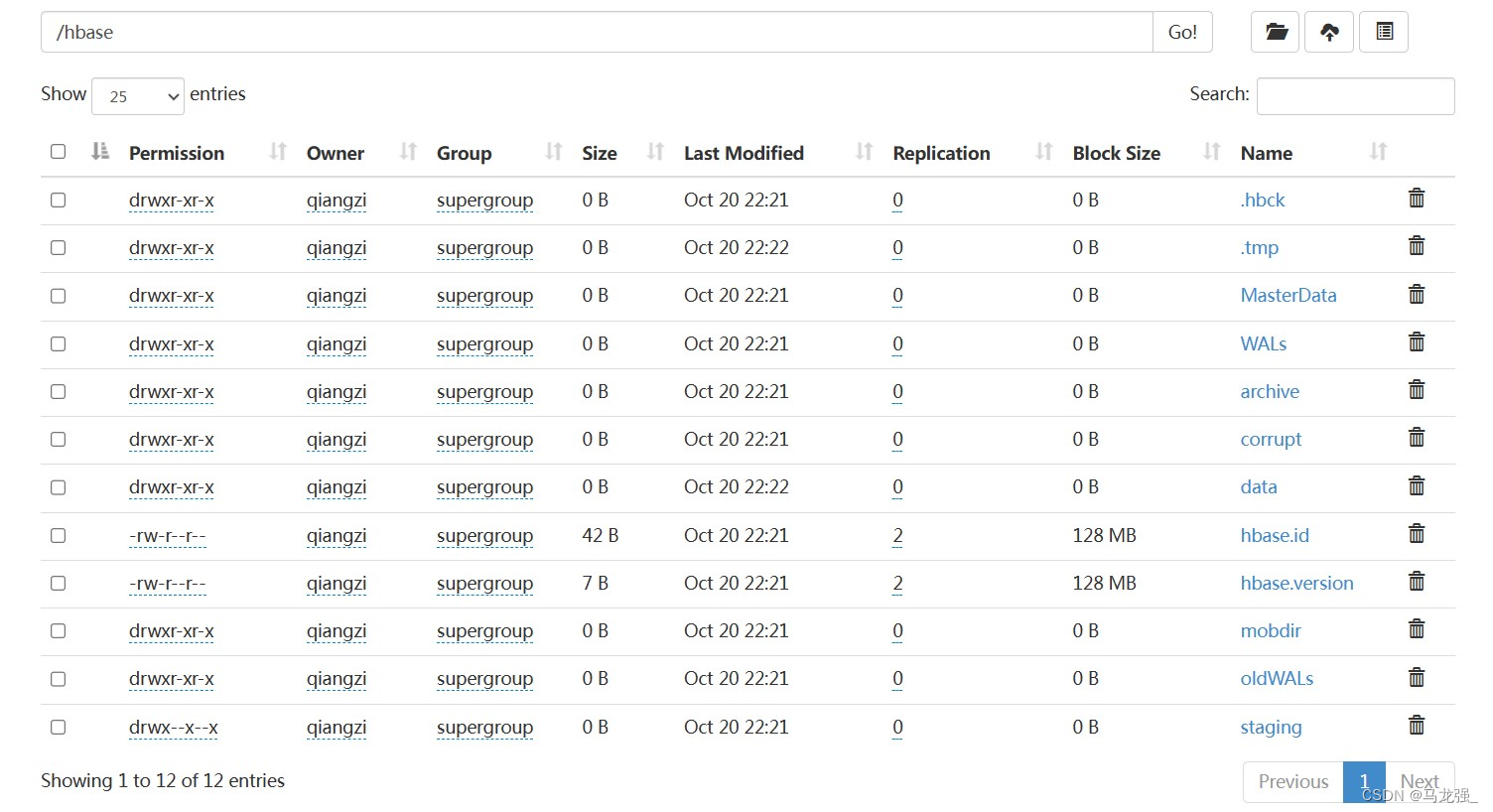
16.查看hbase下文件

















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











