







供自己复习使用,写的非常随便。。。
前言
纯Transformer的问题:
1、参数多,复杂度高
2、缺少空间归纳偏置
3、迁移到其他任务比较繁琐
4、模型训练困难
解决方法:将CNN与Transformer混合使用。由于CNN有空间归纳偏置,所以不再需要位置编码。并且可以加速网络收敛。
结构


MV2来自于MobileNet V2
第一个淡黄色的Conv是膨胀卷积。
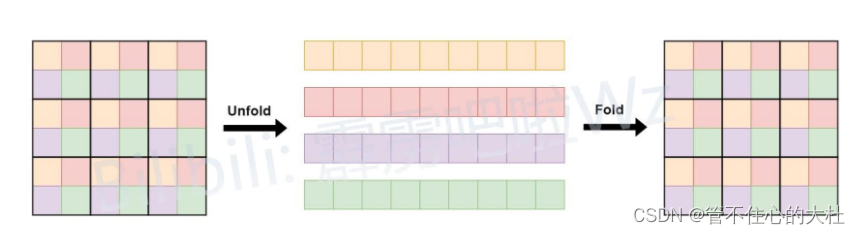
全局表征(global representations) :打成patch,对每个patch中相同位置的做自注意力。因为图像数据中相邻部分存在很多的冗余数据。而且在MobileVit Block的全局表征前已经做过局部表征,所以不需要过于细致。

unfold和fold就是实现全局表征,将unfold的直接放入Transformer中。















 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









