







最近再向着超分辨率重建的方向学习,并通过Convnext对SRGAN网络进行了一些结构上的升级,效果还不错。
代码
带训练权重带少量数据集(414mb):
链接:https://pan.baidu.com/s/1KYyHyE5BpCTjKNuwBh52Wg?pwd=dnmd
提取码:dnmd
纯代码(5.8mb):
链接:https://pan.baidu.com/s/18kqXsh6NnKKMNg3WHdhRUA?pwd=89ay
提取码:89ay
视频
SRGAN完整代码,并用Convnext进行优化_哔哩哔哩_bilibili
如下是我的使用Convnext的SRGANext与SRGAN的比较。
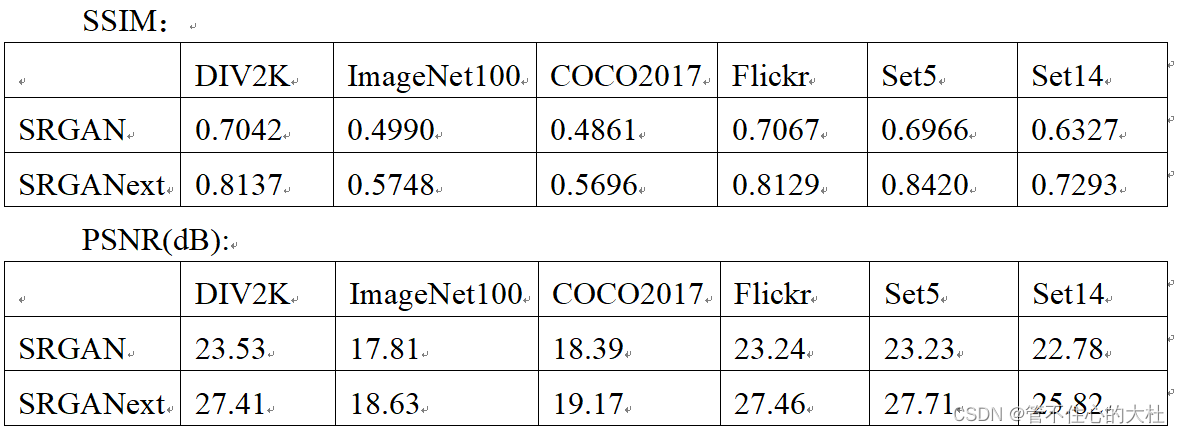
如下是SRGAN在第100轮训练的低分辨率图像,由低分辨率图像生成的高分辨率图像,和高分辨率图像



如下是SRGANext在第100轮训练的低分辨率图像,由低分辨率图像生成的高分辨率图像,和高分辨率图像



这是SRGAN的结构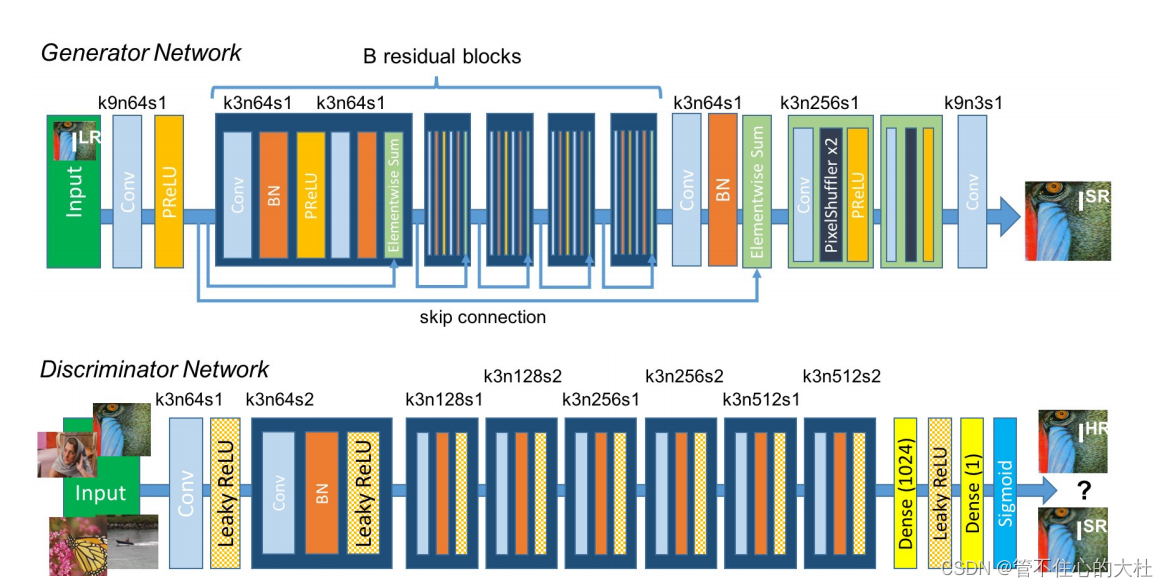
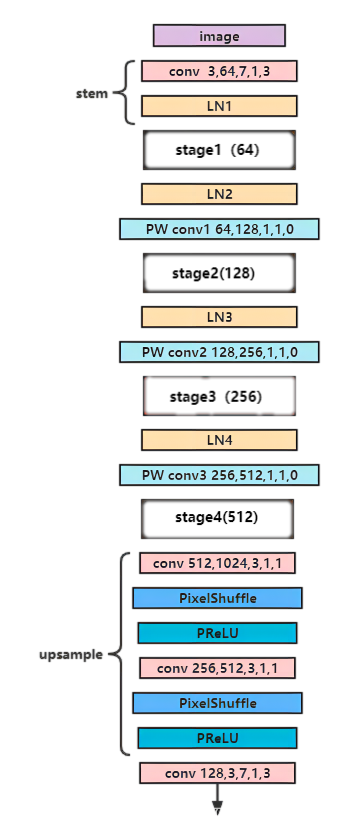
这是我的SRGANext的生成器结构
这是我的SRGANext的辨别器结构
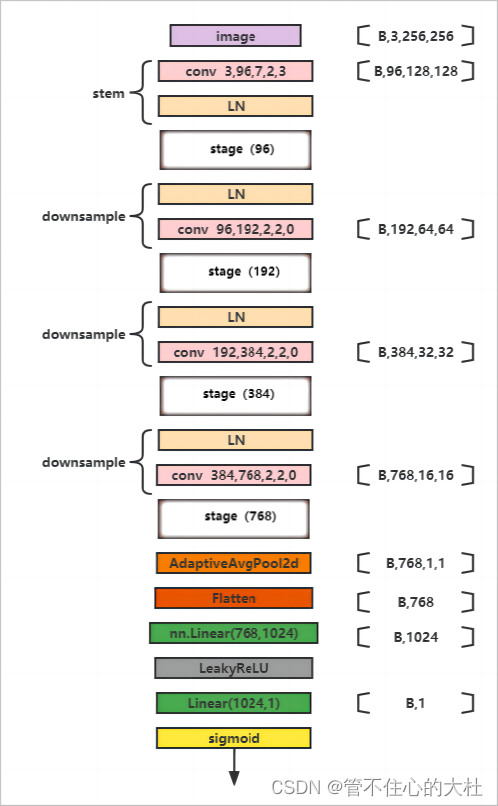
生成器和辨别器都采用的block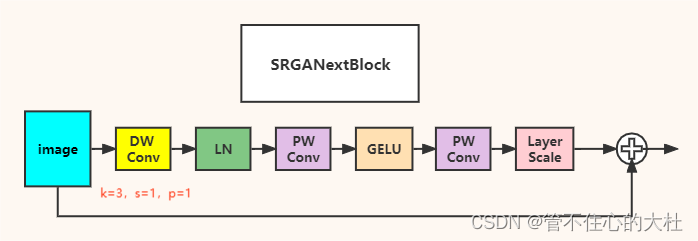
附上SRGAN代码
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
'''两个卷积,不改变大小;也不该变维度,因此残差也不需要1*1卷积核调整维度'''
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
nn.PReLU(),
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
)
def forward(self, x):
return x + self.conv_block(x)
class Generator(nn.Module):
def __init__(self, scale_factor=2, num_residual_blocks=16):
super(Generator, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, stride=1, padding=4,padding_mode='reflect', bias=True)
self.prelu = nn.PReLU()
self.residual_blocks = nn.Sequential(*[ResidualBlock(64) for _ in range(num_residual_blocks)])
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=True)
self.bn2 = nn.BatchNorm2d(64)
self.upsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=3, stride=1, padding=1,padding_mode='reflect', bias=True),
nn.PixelShuffle(scale_factor),
nn.PReLU(),
nn.Conv2d(64, 256, kernel_size=3, stride=1, padding=1,padding_mode='reflect', bias=True),
nn.PixelShuffle(scale_factor),
nn.PReLU(),
nn.Conv2d(64, 3, kernel_size=9, stride=1, padding=4, bias=True)
)
def forward(self, x):
out = self.conv1(x)
out = self.prelu(out)
residual = out
out = self.residual_blocks(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.upsample(out)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=True),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(512, 1024),
nn.Dropout(),
nn.LeakyReLU(0.2),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
out = self.layer(x)
return out
附上SRGANext代码
注意其中layernorm的通道维度在最后。
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
'''
[b,c,h,w] --> permute [b,h,w,c] --> LN --> permute [b,c,h,w]
'''
def __init__(self,dim):
super(LayerNorm, self).__init__()
self.norm = nn.LayerNorm(dim)
def forward(self,x):
x = x.permute(0,2,3,1)
x = self.norm(x)
x = x.permute(0,3,1,2)
return x
class SRGANextBlock(nn.Module):
def __init__(self,dim, layer_scale_init_value=1e-6):
super(SRGANextBlock, self).__init__()
self.dconv1 = nn.Conv2d(in_channels=dim,out_channels=dim,kernel_size=7,stride=1,padding=3,groups=dim)
self.norm1 = LayerNorm(dim)
self.pconv1 = nn.Conv2d(dim,4*dim,kernel_size=1,stride=1)
self.act = nn.GELU()
self.pconv2 = nn.Conv2d(4*dim,dim,kernel_size=1,stride=1)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)),
requires_grad=True) if layer_scale_init_value > 0 else None
def forward(self,x):
shortcut = x
x = self.dconv1(x)
x = self.norm1(x)
x = self.pconv1(x)
x = self.act(x)
x = self.pconv2(x)
x = x.permute(0, 2, 3, 1) # [N, C, H, W] -> [N, H, W, C]
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # [N, H, W, C] -> [N, C, H, W]
x = shortcut + x
return x
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.stem = nn.Conv2d(3,64,kernel_size=7,stride=1,padding=3)
self.norm1 = LayerNorm(64)
self.block1 = nn.Sequential(*[SRGANextBlock(64) for _ in range(3)])
self.norm2 = LayerNorm(64)
self.pconv1 = nn.Conv2d(64,128,kernel_size=1,stride=1)
self.block2 = nn.Sequential(*[SRGANextBlock(128) for _ in range(3)])
self.norm3 = LayerNorm(128)
self.pconv2 = nn.Conv2d(128,256,kernel_size=1,stride=1)
self.block3 = nn.Sequential(*[SRGANextBlock(256) for _ in range(9)])
self.norm4 = LayerNorm(256)
self.pconv3 = nn.Conv2d(256,512,kernel_size=1,stride=1)
self.block4 = nn.Sequential(*[SRGANextBlock(512) for _ in range(3)])
self.upsample = nn.Sequential(
nn.Conv2d(512,1024,kernel_size=3,stride=1,padding=1),
nn.PixelShuffle(2),
nn.PReLU(),
nn.Conv2d(256,512,kernel_size=3,stride=1,padding=1),
nn.PixelShuffle(2),
nn.PReLU()
)
self.conv1 = nn.Conv2d(128,3,kernel_size=7,stride=1,padding=3)
def forward(self,x):
x = self.stem(x)
x = self.norm1(x)
x = self.block1(x)
x = self.norm2(x)
x = self.pconv1(x)
x = self.block2(x)
x = self.norm3(x)
x = self.pconv2(x)
x = self.block3(x)
x = self.norm4(x)
x = self.pconv3(x)
x = self.block4(x)
x = self.upsample(x)
x = self.conv1(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.stem = nn.Sequential(
nn.Conv2d(3,96,kernel_size=7,stride=2,padding=3),
LayerNorm(96)
)
self.block1 = nn.Sequential(*[SRGANextBlock(96) for _ in range(3)])
self.downsample1 = nn.Sequential(
LayerNorm(96),
nn.Conv2d(96,192,kernel_size=2,stride=2)
)
self.block2 = nn.Sequential(*[SRGANextBlock(192) for _ in range(3)])
self.downsample2 = nn.Sequential(
LayerNorm(192),
nn.Conv2d(192, 384, kernel_size=2, stride=2)
)
self.block3 = nn.Sequential(*[SRGANextBlock(384) for _ in range(9)])
self.downsample3 = nn.Sequential(
LayerNorm(384),
nn.Conv2d(384, 768, kernel_size=2, stride=2)
)
self.block4 = nn.Sequential(*[SRGANextBlock(768) for _ in range(3)])
self.endLayer = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(768,1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self,x):
x = self.stem(x)
shortcut = x
x = shortcut+self.block1(x)
x = self.downsample1(x)
shortcut = x
x = shortcut+self.block2(x)
x = self.downsample2(x)
shortcut = x
x = shortcut+self.block3(x)
x = self.downsample3(x)
shortcut = x
x = shortcut+self.block4(x)
x = self.endLayer(x)
return x















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









