







 本文详细分析了JavaHashSet的底层实现原理,包括基于HashMap的数据结构、去重机制、扩容策略以及重写equals和hashCode的最佳实践。通过实例展示了添加元素的过程,以及如何确保元素唯一性与保持一致性。
本文详细分析了JavaHashSet的底层实现原理,包括基于HashMap的数据结构、去重机制、扩容策略以及重写equals和hashCode的最佳实践。通过实例展示了添加元素的过程,以及如何确保元素唯一性与保持一致性。
目录
5. 重写equals和hashCode(HashSet最佳实践)
1. 基本介绍
(1)HashSet实现了Set接口,是Set接口的实现子类。
(2)HashSet实际上是HashMap,看源码:
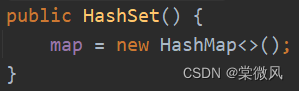
(3)不能有重复的元素或对象。可以存放null值,但只能有一个null。
(4)HashSet不保证元素是有序的,取决于调用hash()方法后,再确定索引的结果。
2. HashSet 底层机制分析
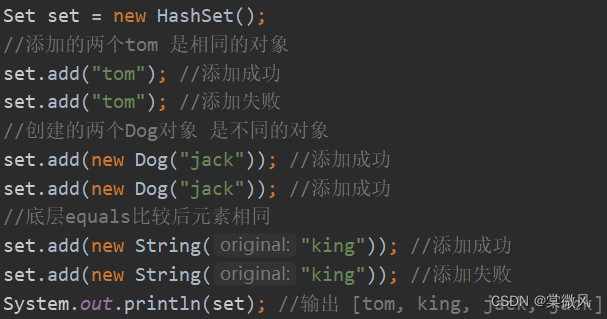
(1)HashSet底层就是HashMap,HashMap底层是 数组+链表+红黑树。
(2)HashSet的去重机制是:hashCode() + equals()。
(3)添加一个元素时,先得到hash值,会转成一个索引值。
(4)找到存储数据表table,看这个索引位置是否已经存放元素。
(5)如果没有存放,直接加入tabla数组。如果有存放,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到链表的最后。(equals具体比较什么,可以自己重写定制,不能简单的认为就是比较内容。)
(6)在JDK 8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD(默认是8),并且table的大小 大于等于 MIN_TREEIFY_CAPACITY(默认64)就会进行树化(红黑树)。
3. HashSet 底层机制 源代码分析
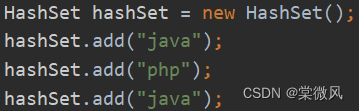
(1)执行new HashSet()后,调用了HashSet()的无参构造器 创建对象。
[第一次添加:add("java")]
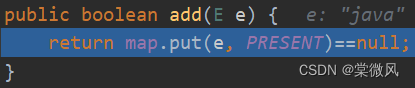
(2)执行add("java")操作后,调用add()方法。其中PRESENT是一个静态对象,不管执行多少次,始终都是同一个,起占位的作用。
![]()
(3)在add()方法中,是返回put()方法执行的结果。在put()方法中会执行hash(key)方法,经过一个算法(不需要深究),得到key对应的hash值,得到的hash值不是hashCode()。


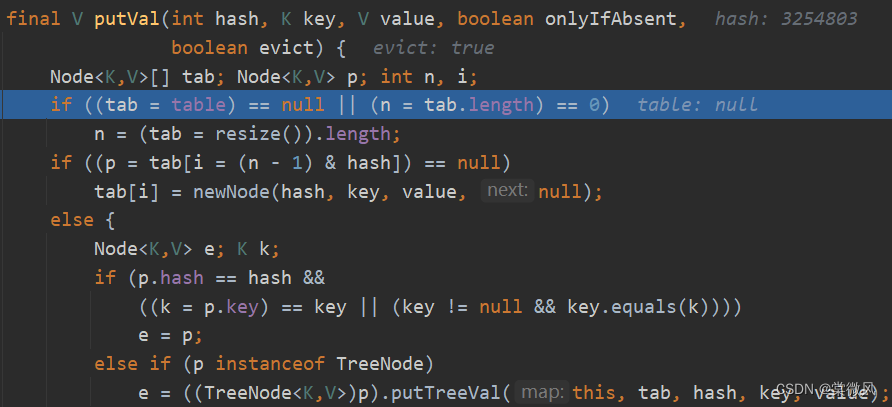
(4)执行完hash(key)方法后,返回结果,进入到putVal()方法。
//第三句:Node<K,V>[] tab; Node<K,V> p; int n, i; 是辅助变量
//第四句:table就是HashMap的一个数组,类型是Node[]。if语句表示 如果table是null 或 大小=0,就调用resize()方法进行第一次扩容到16个空间。
//第六句:先根据key得到hash,去计算该key应该存放到table表的哪个索引位置,并把这个位置的对象赋给p。再判断p是否为null,如果p为null,表示还没有存放元素,就创建一个Node (key, value),就放在第七句的tab[i]。
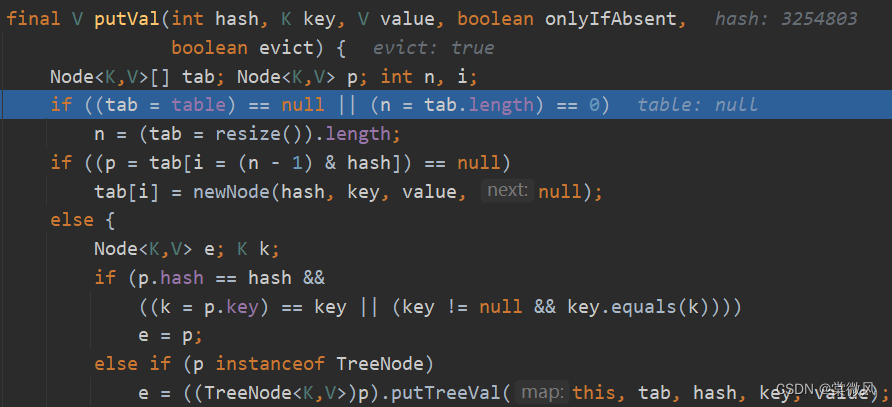
(在本次元素添加中不进入该else语句,具体内容就先进行省略……)
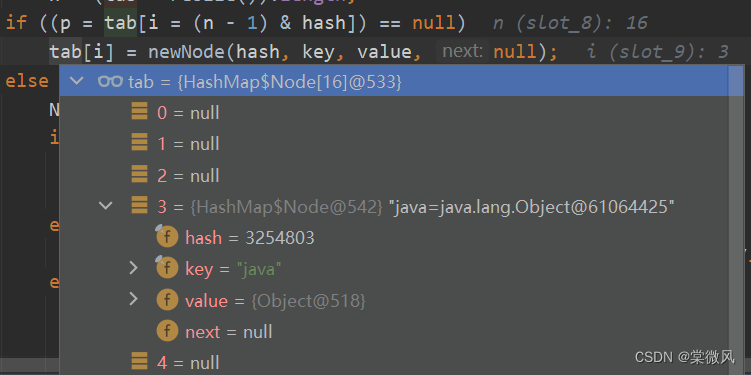
//在本次执行中执行完第四句和第六句的if语句后,将元素添加到了链表中索引为3的位置。同时不会进入下面的else语句,直接执行到了++modCount语句,此时tab数组的情况如下:
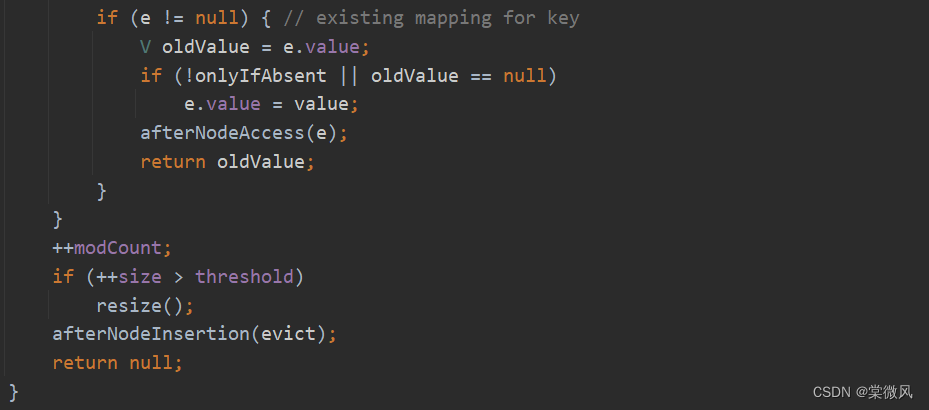
//执行++modCount语句后,修改次数加1。然后在下面的if语句判断数组的元素个数是否超过threshold(threshold是12)。
//if语句下面的afterNodeInsertion(evict)方法是HashMap留给它的子类去实现的方法,对于HashMap来说,这个方法是一个空方法,不用去管。
![]()
//在putVal()方法的最后返回一个null,代表元素添加成功了。然后就进行一步步的返回上层。
[第二次添加:add("php")]
(5)执行add("php")操作,进行第二个元素的添加。依然是先调用add()方法,然后调用put()方法,再执行hash(key)方法,最后进入putVal()方法。
//因为数组中已经有元素了,所以不会进入第四句的if语句
//进行第六句的if语句判断,能进入,执行完后,在链表中9的位置添加了元素,不进入else语句,直接到++modCount语句,此时tab数组的情况如下:
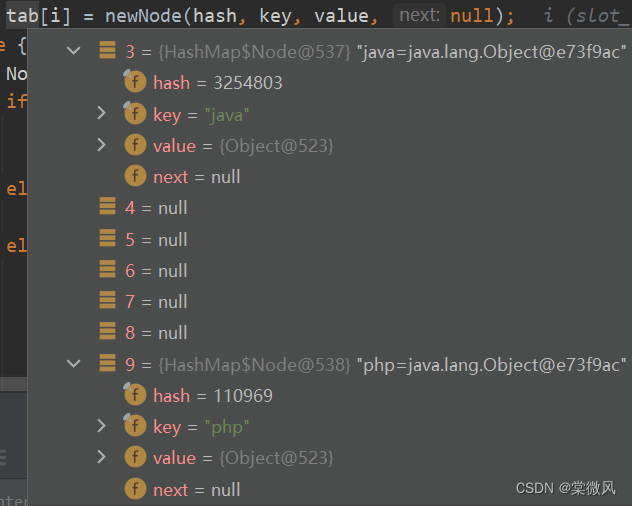
//最后执行++modCount语句,修改次数加1,依次向下执行,返回null,第二次元素添加执行完毕。
[第三次添加:add("java")]
(6)执行add("java")操作,进行第三个元素的添加。依然是先调用add()方法,然后调用put()方法,再执行hash(key)方法,最后进入putVal()方法。
//因为链表中已经有元素了,所以不会进入第四句的if语句
//第六句的if语句判断,因为在第一次添加java元素时,最后得到的索引为3,此时添加相同的元素,得到的索引也为3,不等于null,不会进入if语句,而进入下面的else语句。
//在else中的第二句的if语句进行判断:如果当前索引位置对应的链表的第一个元素 和 准备添加的key的hash值一样,并满足下面两个条件之一:①准备加入的key 和 p指向的Node节点的key是同一个对象;②p指向的Node节点的key的equals()和准备加入的key比较后相同。
//不满足if语句后,对else if语句进行判断:判断p是不是一颗红黑树。如果是一颗红黑树,就按照putTreeVal()方法来进行添加。
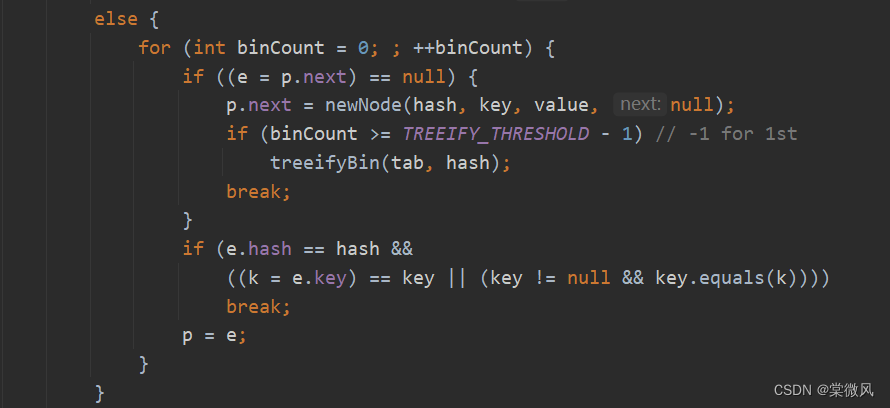
//不满足if和else if语句后,就进入else语句。如果tab数组对应的索引位置已经是一个链表,就使用for循环进行比较。for循环中有以下两种情况:
(在该for循环中,e指向的是下一个元素,执行p = e语句,是使p指向下一个元素)
①依次和该链表的每个元素比较后,都不相同,e指向了链表最后一个元素的后面null,即e = null。则执行第一个if语句,将元素加入到链表的最后,再break退出循环。
(在执行该if语句,将元素加入到链表后,还会进行一个if判断:该链表是否已经达到8个节点。如果达到了,就调用treeifyBin()方法,对当前链表进行树化,转成红黑树。同时在treeifyBin()方法的底层还会进行一个判断,看当前tab数组是否为空 或 大小 < 64,如果条件成立就不会直接树化,而是调用resize()方法进行扩容,只有条件不成立时,才转成红黑树。)

②依次和该链表的每个元素比较过程中,如果发现有元素相同,则执行第二个if语句,直接break退出循环。
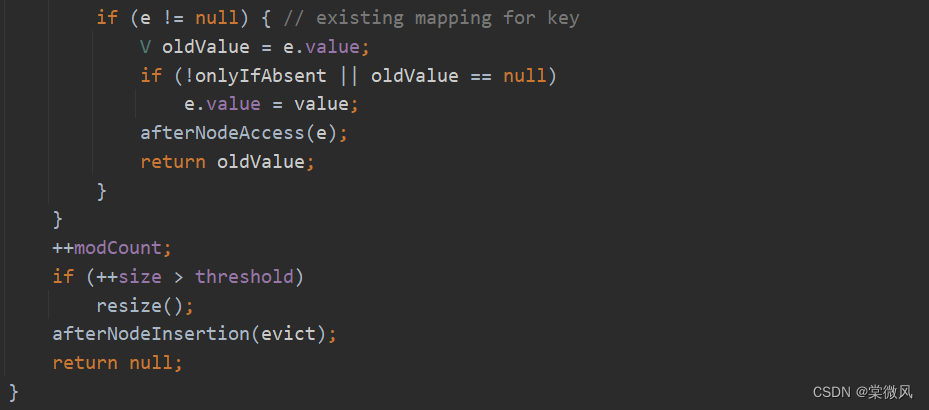
//在本次执行元素添加操作中,添加的元素java和第一次添加的元素相同,所以会进入到else语句的第一个if语句,执行了e = p后,因为e != null,就进入到该else语句最后的if语句,返回oldValue,最后就添加失败了。
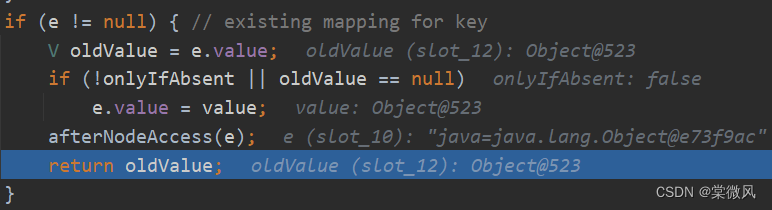
//最后就执行完了这三次元素添加,只有第一个java和php添加成功了。
4. HashSet 扩容和转成红黑树机制分析
(1)HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值threshold是:16*0.75(加载因子loadFactor)= 12。
(2)如果table数组使用到了临界值12(只要是添加了12个元素就算,不管是否是在table数组本身的位置,在同一个位置的链表上添加也算),数组就会扩容到16*2=32,新的临界值就是32*0.75=24,依次类推。
(3)在JDK 8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则 仍然采用上面第一第二点的数组扩容机制。
5. 重写equals和hashCode(HashSet最佳实践)
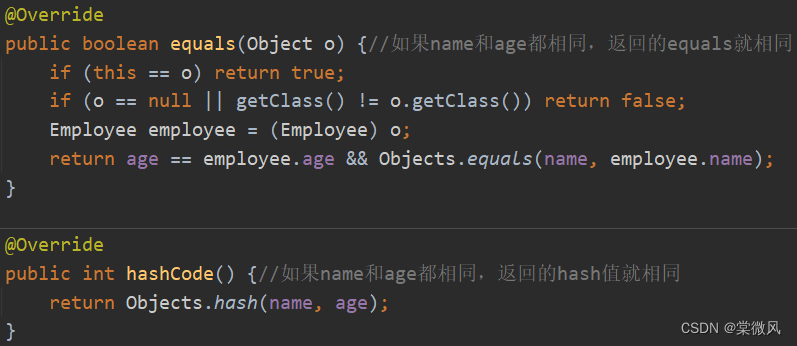
当使用HashSet来添加新的对象时,如果添加的新对象是使用new创建的对象,那么它们的计算出来的hash值肯定会不同。而如果想要对创建的对象的内容进行比较计算,不想让相同的对象进行添加,就需要在类中重写equals和hashCode方法,改变计算逻辑(只重写equals和hashCode中的一个,结果也是相同元素都加入了进去)。
例:
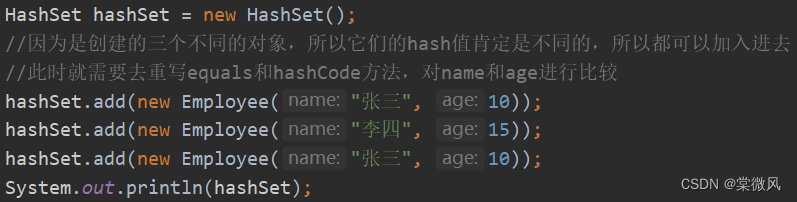
Employee类:(只是name和age中的一个相同,是可以添加进去的)
main方法:
运行结果:

(注:如果对添加元素的name或age重新赋值后,此时按照创建的对象使用remove去删除对象,就会按照当前的name和age进行hash值计算,就不再是原本对象在的那个位置,最后就会删除失败。)















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









