






xilinx的FAE: 尽量用最新的偶数版本,奇数版本是增加了新特性,偶数版本是修bug
“实测得到,在一个Block RAM资源占用率超过60%的项目中,Synthesis的速度和实体机相差不大,但是Implementation速度在实体机跑了85分钟,而在虚拟机跑了52分钟。”
论坛有大神解释称是windows的Vivado的GUI日志打印的效率低,因此大量时间都浪费在IO中。从CPU占用率可以看到,在Windows下CPU利用率是很低的,而内存占用非常大,猜测一部分原因是优化问题导致大量cache miss,另外一部分原因是IO中浪费很多时间。论坛中也有大神说运行Implementation的tcl而不在Vivado直接Impelmentation,这样也会快很多。
论坛采集的稳定版本如下:
| vivado2018 | vivado2019.2 | vivado2020.2 | vivado2022.2 | vivado2023.2 |
| 提供了更多针对 UltraScale+ 和 Versal 架构的优化和增强功能。 | 引入了对 Versal ACAP 架构的支持,并改进了时序分析和布局布线工具。 | 增加了对 Vitis AI 的集成支持,并提供了更多的 IP 核和开发板支持。 |
|
Vitis 分析调试工具
HLS 内核模块更新
Vitis Model Composer和Vitis工具的整合
其它功能增强
|
| PS(HLS-sdk) | VITIS(包含bit和硬件platform的.XSA) | VITIS(包含bit和硬件platform的.XSA) | ||
| PL | PL IO planning GUI界面,无论给外部引脚选择什么的电平标准,都是红色的提示 | PL vitis HLS 有更严格的格式检查 参考:ug1391; ug1399
|

同一份源码,HLS编译资源对比:
| vivado2018.2 | vivado2020.2 | vivado2022.2 | vivado2023.2 |
|
|
|
|
时钟布线更优化 |
|
| 时序检查更为严格,且布线更优化
|
|
兼容旧编译器,新编译器需安装 |
|
|
|
|
资源消耗 |
| 可根据function正常选择函数顶层 | 但函数只能一个文件存放一个,否则找不到对应的函数作为顶层 | IP时序违例报告 可根据function正常选择函数顶层 | IP时序违例报告 可根据function正常选择函数顶层 自定义编译优化策略 |
|
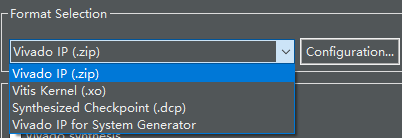
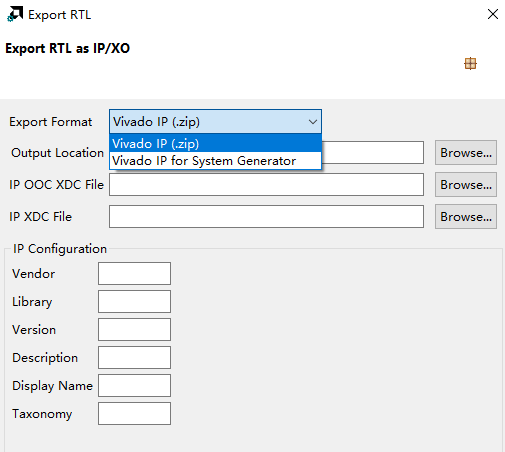
可将源码封装成IP或网表 | 源码封装成IP,可自定义IP内部 的走线
| 源码封装成IP,可自定义IP内部 的走线
| |
| 存在导出IP需要改时间的BUG | 仍然存在时间BUG,综合时偶发报时间错误 | 导出IP不需要改时间 | 导出IP不需要改时间,较快 |
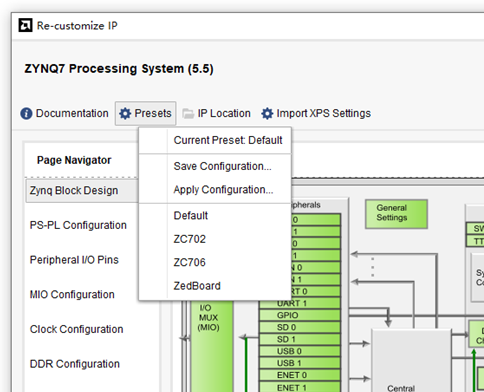
| 支持软核配置一键导入导出 | 支持软核配置一键导入导出 | 支持软核配置一键导入导出,且可显示当前配置 | 支持软核配置一键导入导出,且可显示当前配置
|
| 适配低版本VITIS开发的IP | 适配低版本VITIS开发的IP | ||
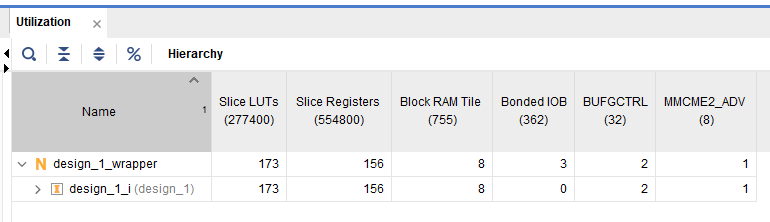
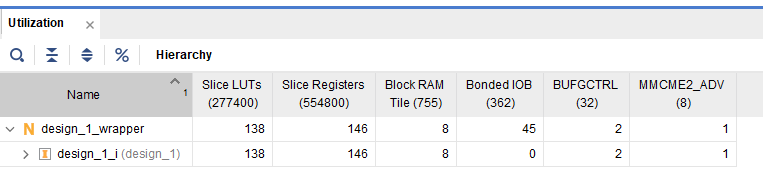
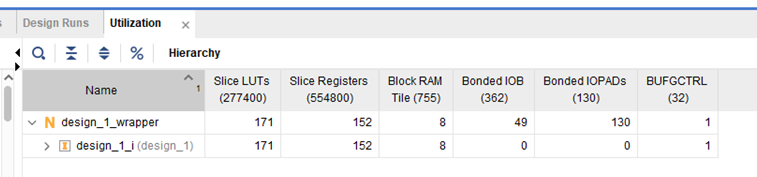
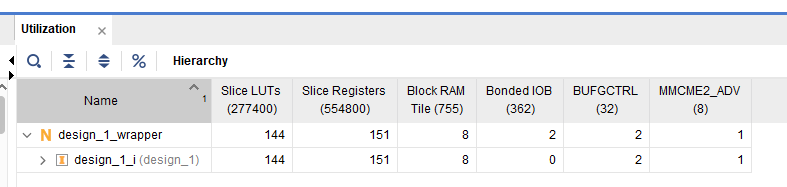
| vivado实际资源占用
| vivado实际资源占用
| vivado实际资源占用
| vivado实际资源占用
|
| LUT占用较前一版本多 | LUT占用减少,IOB资源大大节省 | ||
| 小demo, 时间一般 | 小demo, 时间一般 | 小demo, 时间快 | 小demo, 时间快 |
| 选择Vivado 2022.2的理由: | 选择Vivado 2023.2的理由: |
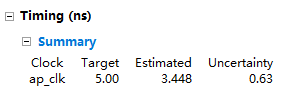
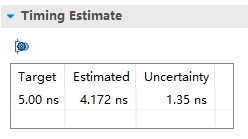
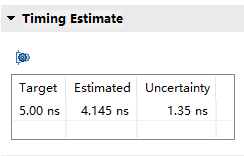
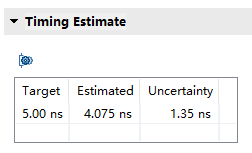
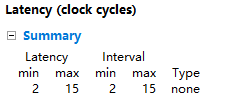
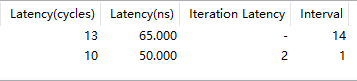
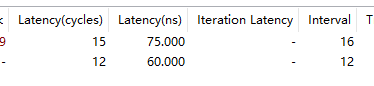
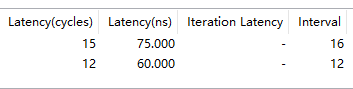
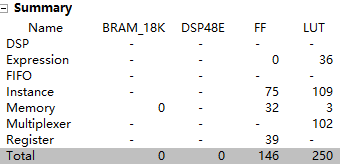
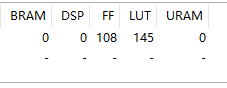
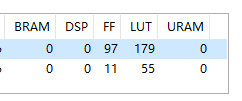

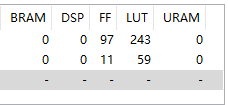


linux中vivado编译要比win中编译速度快上不少,可以使用Linux版本的vivado提升编译速度。


















 5278
5278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









