







前言
https://www.bilibili.com/video/BV1Rc411b7ns/?spm_id_from=333.999.0.0&vd_source=6f44871de67edad92e13557be517746b
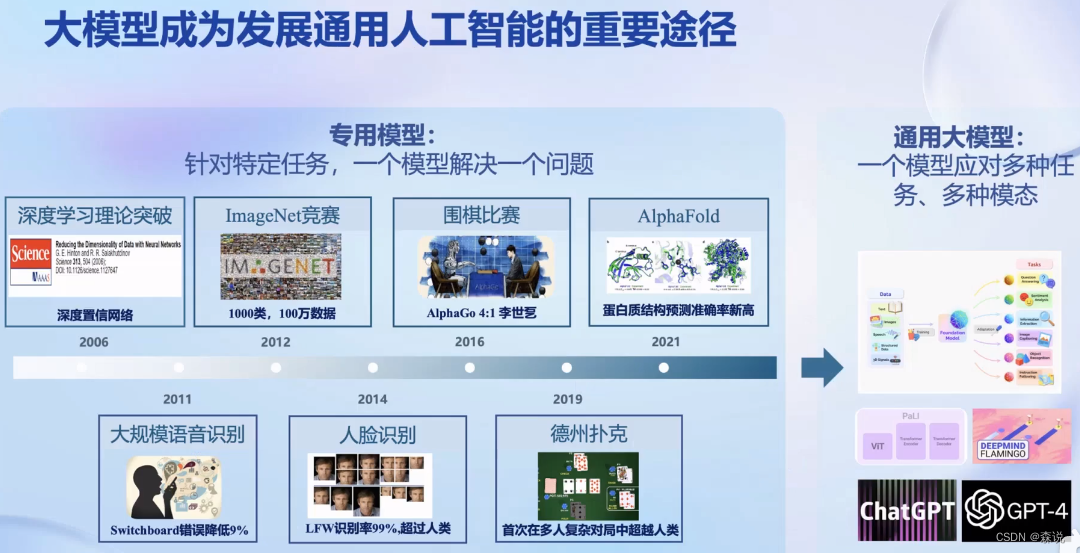
随着chatgpt的出现,大模型就成为现在的热点,论文数也是直线上升,那为什么大模型这么受关注呢?
首先我们之前在AI模型的研究上是有针对性的,但这与我们人是不同的,而大模型就是可以做到通用,可以实现多个任务和多种模态。
书生-浦语
模型介绍
书生-浦语从年初开始研发,到现在为止已经有了三种级别的模型。
模型到应用
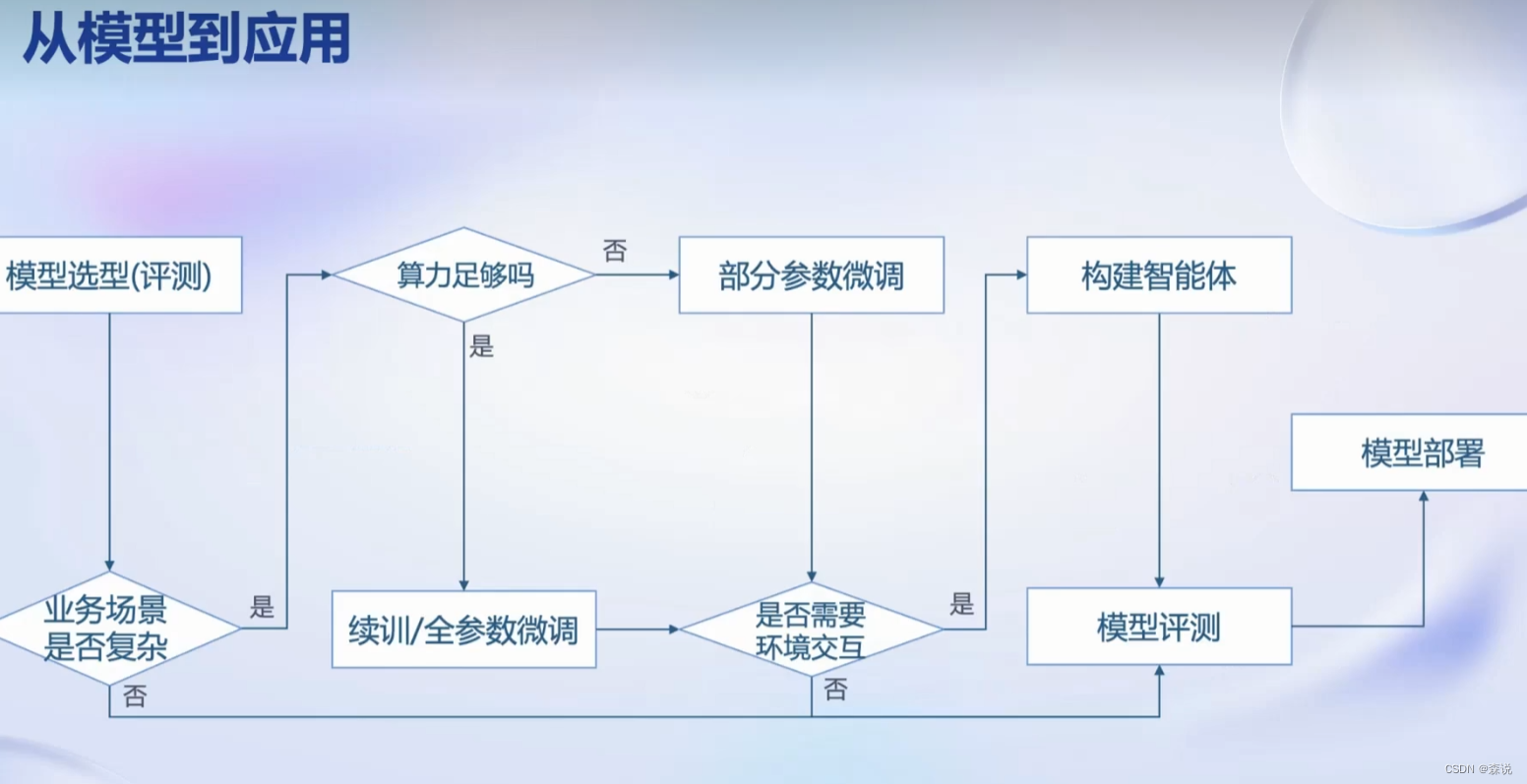
我们在社区选择我们要使用的模型后,在将其上线之间还是要经过很多的过程。
首先我们要和业务相结合,这样的话就要进行微调,而微调根据我们的算力来判断是否进行全参数的微调,而微调的时候,我们也要考虑到环境的影响,这时候就要去构建智能体,最好进行评测和部署。
体系
从上面可以看到我们每一个环节也是都是需要很多的工具和技能的,下面是全链路的工具: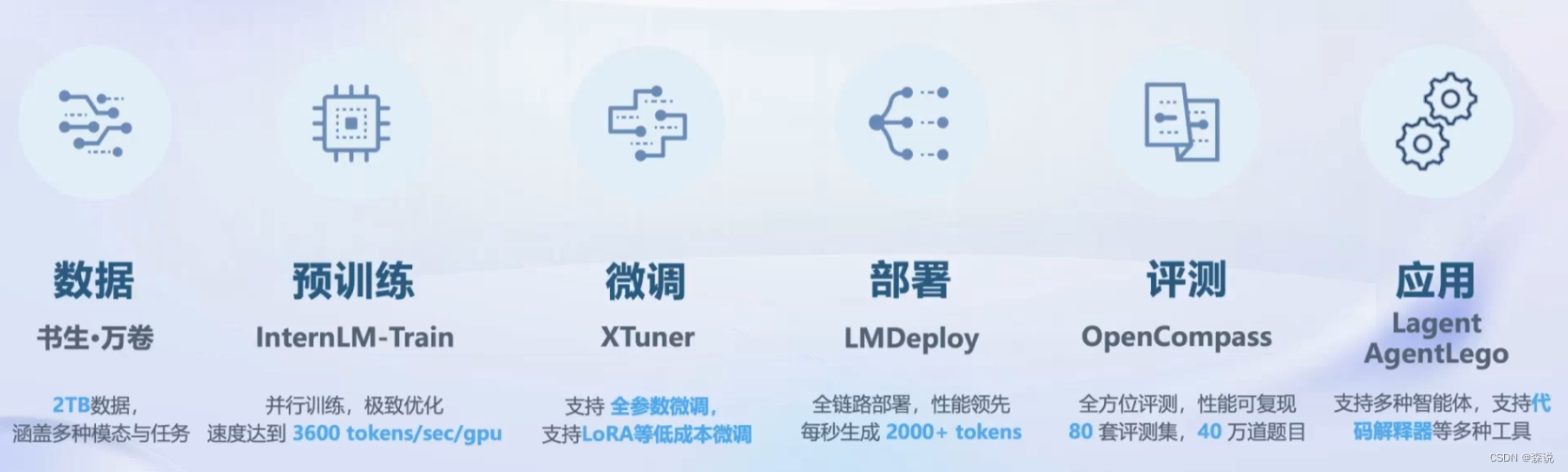
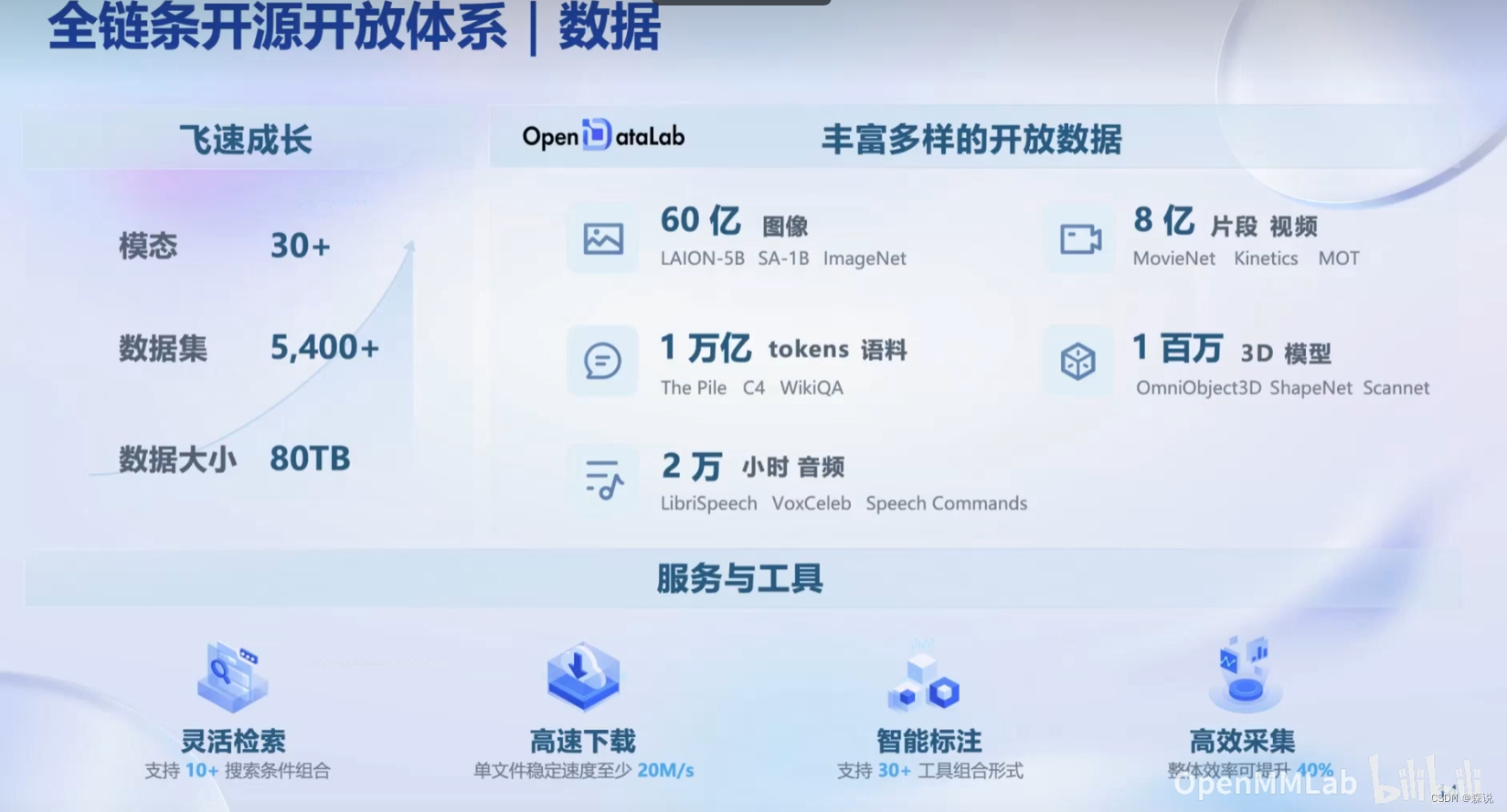
数据
多模态数据

数据集平台
预训练

微调
其实这个是我们使用者关心的,因为预训练那些我们根本就没资源,而微调的话确实可以的,并且优化的还不错,那我这个4070ti也是可以跑了,但可惜的是放假回家就用不了了。

预训练是使用自监督的方法,那么这个增量续训也是如此但是会专业一点,最后进行有监督微调。
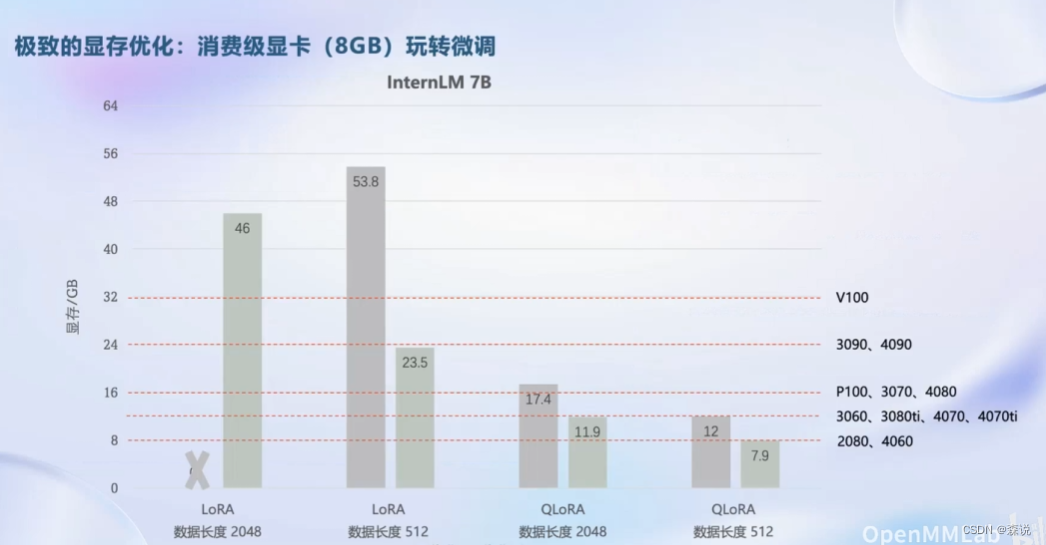
评测

部署
这里学到了不少东西,首先我们在部署的时候对于内存开销确实大,并且还要缓存,所以怎么在低存储设备上部署呢:模型并行,低比特量化。还有就是我们token是动态的,shape不一致,这样的话就得加速算子的计算,好在大语言模型相对而言结构简单。


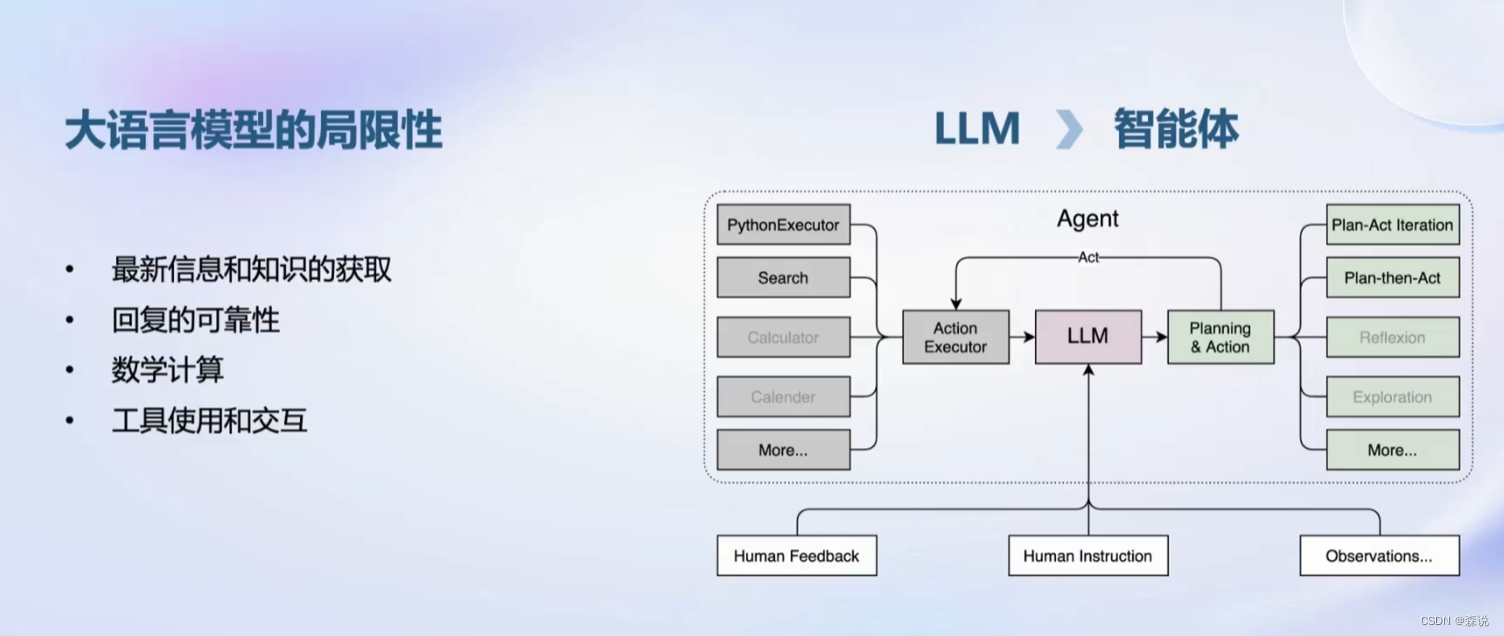
智能体
这个主要是对于智能体的构建
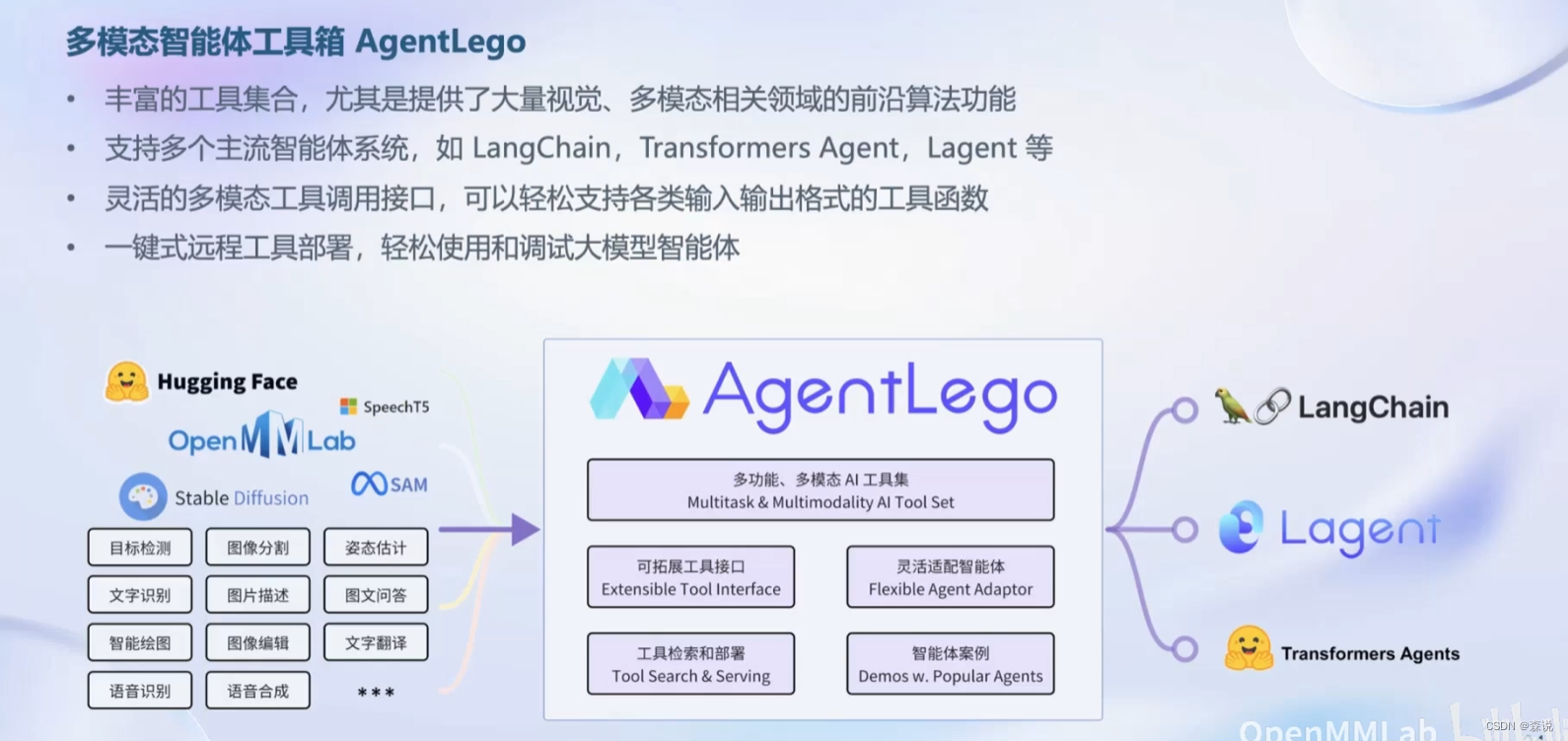
下面这个是可以让智能体进行多模态工具的使用















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









