







目录
PEFT分类
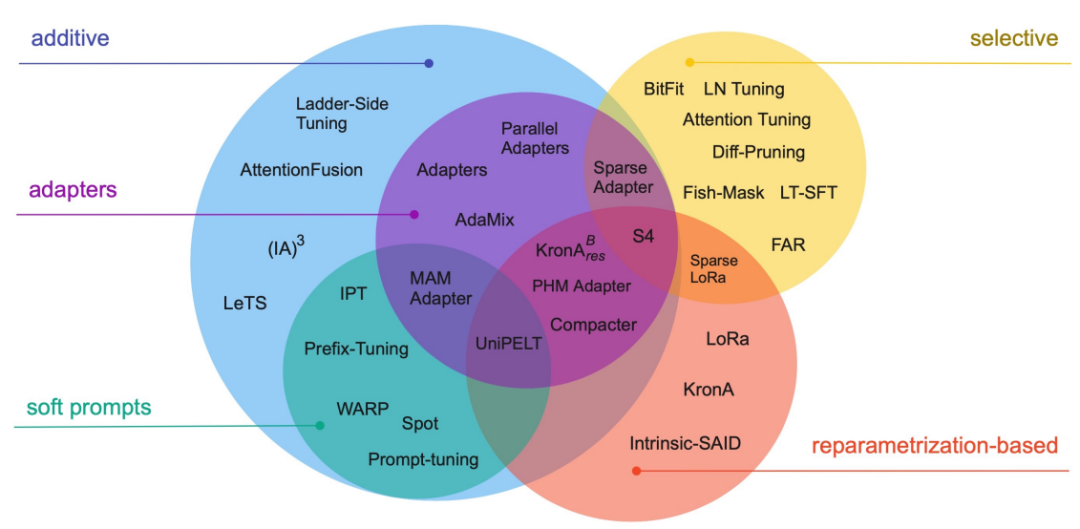
图1. PEFT分类
如上图1,按是否增加了额外参数,PEFT主要分为:
-
Additive类:在预训练模型基础上增加额外的参数或者网络层,微调训练的时候只训练这些新增的参数或层,包含两个子类:
1)Adapter--在Transformer子层后加入小的全连接层,微调只学习新加的全连接层参数。
2)Soft Prompts--常见的Prompts方法是在输入中构造Prompts模板,如何构造是一门学问,Soft Prompts直接在输入的embedding中加向量作为soft prompts,并对这些向量的参数进行微调,避免构造Prompts模板。
-
Selective类:选择模型中的部分层比如最后几层、或偏置项进行微调。
-
Reparametrization-based类:利用低秩表征(low-rank representations)来最小化可训练的参数,本质上就是认为大量的参数中,仅仅一部分起到关键作用,在这个起关键作用的子空间中去寻找参数进行微调。
-
Hybrid类:混合了多种类别的方法。
PEFT方法效率统计
参数效率(Parameter Efficiency,PE)从广泛的概念讲,包括存储、内存、计算和性能的效率,其中计算效率主要包括微调时反向传播的计算和推理的计算效率。下面是对已收集的方法(论文)从这几个维度进行的统计:
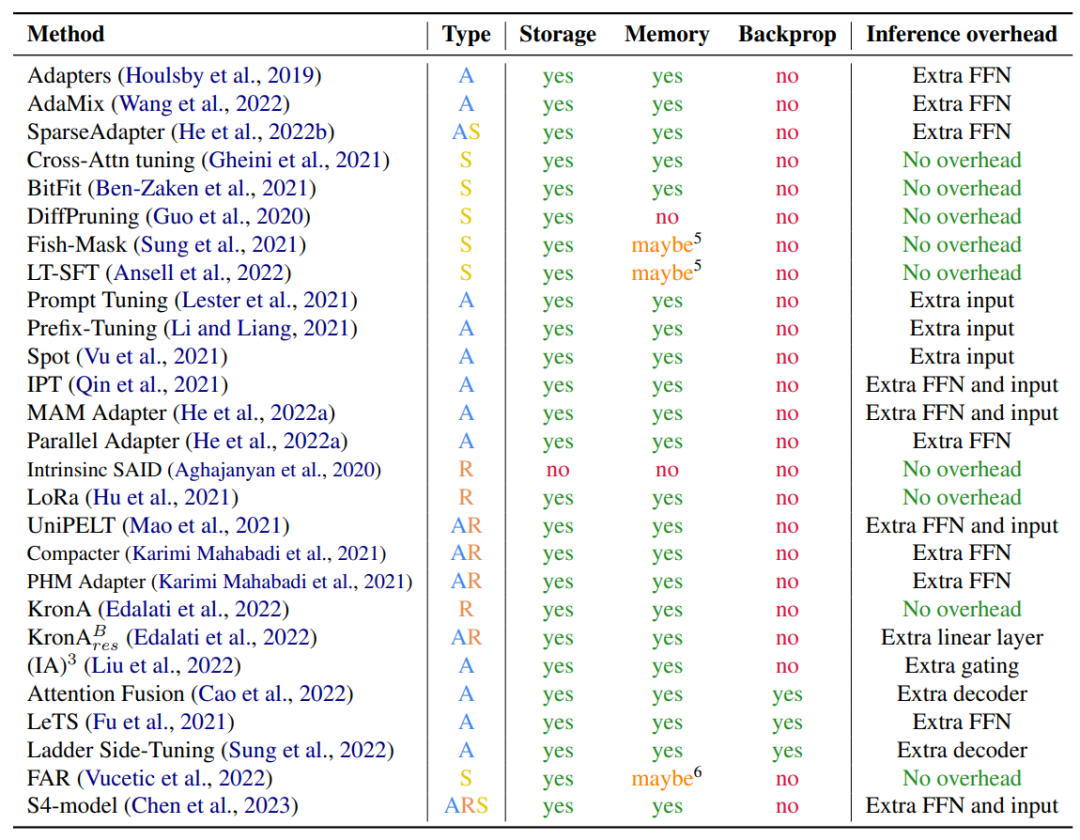
表1. 各种方法的效率统计
其中,Type表示该方法属于Additive、Selective、Reparametrization-based哪一类,Storage、Memroy表示该方法和全部参数微调比较是否节约了存储、内存。Backprop表示是否减小了反向传播计算开销,Inference overhead表示推理时是否增加了开销,比如常见的增加了全连接层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











